cin/ufpe1 categorização de documentos (modificada) mariana lara neves flávia barros cin/ufpe
TRANSCRIPT

CIn/UFPE 1
Categorização de Documentos (modificada)
Mariana Lara NevesFlávia Barros
CIn/UFPE

CIn/UFPE 2
RoteiroIntroduçãoCategorização de DocumentosPreparação de DadosConstrução Manual do ClassificadorConstrução Automática do ClassificadorComparação das AbordagensReferências

CIn/UFPE 3
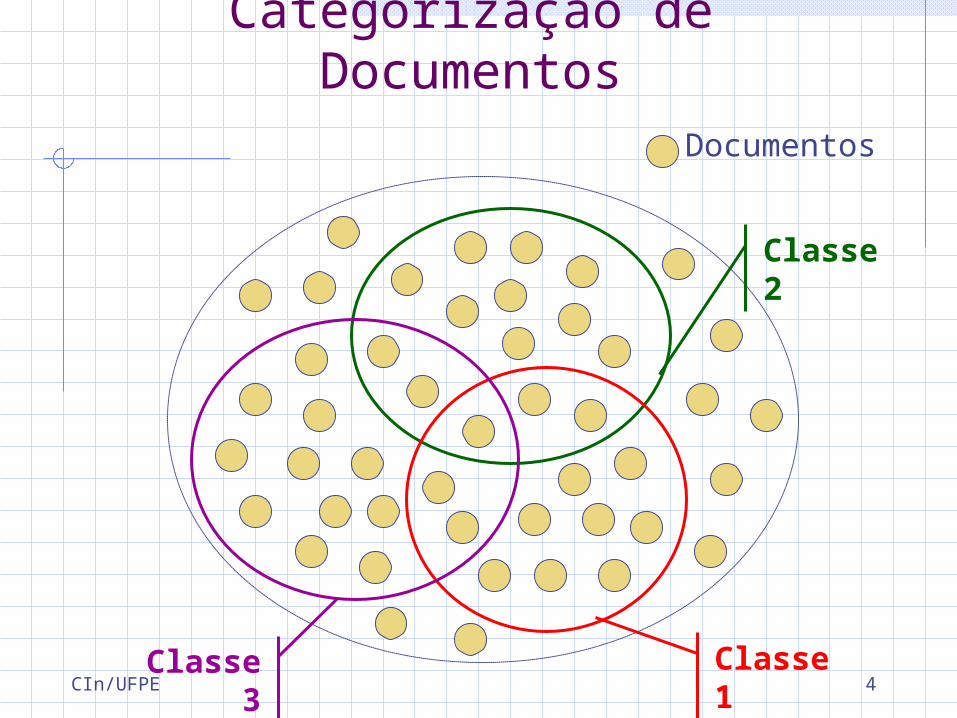
Categorização de DocumentosDefinição: atribuição de uma ou mais classes pré-
definidas aos documentos
Objetivos: Organizar os documentos Facilitar a sua busca automática
CIn/UFPE 4
Categorização de DocumentosDocumentos
Classe 1
Classe 2
Classe 3

CIn/UFPE 5
Categorização de DocumentosClassificação Manual: Leitura dos documentos por um
especialista
Construção Manual do Classificador: Sistemas baseados em conhecimento
Base de Regras escrita manualmente
Construção Automática do Classificador: Algoritmos de aprendizagem automática

CIn/UFPE 6
Construção do ClassificadorConjunto de treinamento: Aquisição do conhecimento ou
Treinamento do algoritmo Ajuste do sistema
Conjunto de teste: Diferente do conjunto de treinamento Avaliação do desempenho do sistema

CIn/UFPE 7
Construção Manual do Classificador
Sistema baseado em Conhecimento: Base de conhecimento Máquina de Inferência (ex.: JEOPS)
Testese
Validação
Nível deConhecimento
Aquisiçãodo
Conhecimento
Nível Lógico
Formulaçãoda Base de
Conhecimento
Nível deImplementação
Construçãoda Base de
Conhecimento

CIn/UFPE 8
Base de Conhecimento: Regras de Produção
Exemplo: Regras para o reconhecimento de um
bloco de citação em uma página de publicação (CitationFinder)
Construção Manual do Classificador
SE houver uma cadeia de Autores E houver uma cadeia de Intervalo de Páginas E houver uma cadeia de Trabalho Impresso E houver uma cadeia de Data ENTÃO o texto é uma citação (chance 1.0)
CIn/UFPE 9
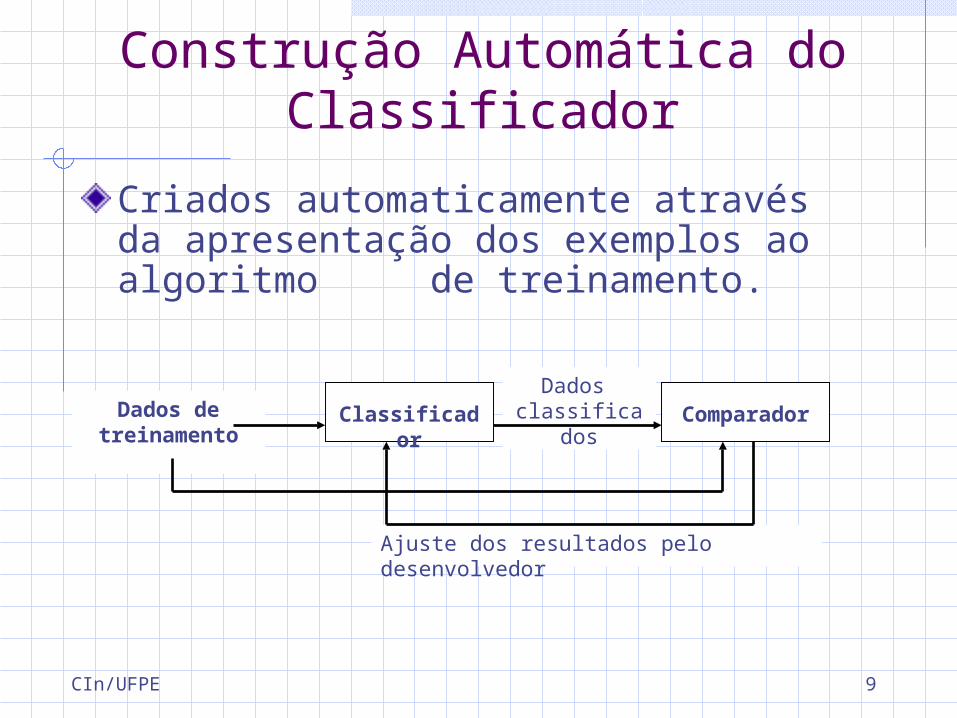
Construção Automática do Classificador
Criados automaticamente através da apresentação dos exemplos ao algoritmo de treinamento.
Ajuste dos resultados pelo desenvolvedor
Dados classificadosDados de
treinamentoClassificador Comparador

CIn/UFPE 10
Construção Automática do Classificador
DocumentosRepresentação Inicial
Redução da Dimensãoou
Seleção de Termos
Representação FinalIndução
ConhecimentoAdicional
Categorização

CIn/UFPE 11
Construção Automática do Classificador
Representação Inicial dos Documentos Utiliza pré-processamento com as
mesmas técnicas de recuperação de informação!!

CIn/UFPE 12
Pré-Processamento dos Documentos
Objetivo Criar uma representação computacional do
documento seguindo algum modeloFases Operações sobre o texto Criação da representação
“Se o desonesto soubesse a vantagem de ser honesto, ele seria honesto ao menos por desonestidade.”Sócrates
Doc original
desonesto / soubesse /vantagem / honesto /seria / honesto /menos/desonestidade/socrates
honesto 2desonesto 1soubesse 1vantagem 1seria 1menos 1desonestidade 1socrates 1
Operações de Texto Representação
Doc : www.filosofia.com Doc : www.filosofia.comDoc : www.filosofia.com
Pré-Processamento

CIn/UFPE 13
Pré-Processamento:Operações sobre o texto
Análise léxica Converte uma cadeia de caracteres em
uma cadeia de palavras/termosEliminação de stopwords Palavras consideradas irrelevantes
Ex.: artigos, pronomes, alguns verbos, “WWW”...
Pré-Processamento-

CIn/UFPE 14
Pré-Processamento:Operações sobre o texto
Stemming Redução de uma palavra ao seu radical
Geralmente, apenas eliminação de sufixos Possibilita casamento entre variações de
uma mesma palavra
engineer engineer engineer
engineering engineered engineer
Term Stem Regras de redução:ed -> 0ing -> 0

CIn/UFPE 15
Pré-Processamento:Representação do Documento
Texto Completo Difícil (caro) de manipular computacionalmente
Dado um documento, identificar os conceitos que melhor descrevem o seu conteúdoRepresentar o documento como um Centróide Lista de termos com pesos associados ou não Problema: perda da semântica
“Se o desonesto soubesse a vantagemde ser honesto, ele seria honestoao menos por desonestidade.”
Sócrates
honesto 2desonesto 1soubesse 1vantagem 1seria 1menos 1desonestidade 1socrates 1
Centróide

CIn/UFPE 16
Modelos de Representação de Documentos
Modelo Booleano Centróide sem pesos associados A representação indica apenas se o termo
está ou não presente no documentoModelo Espaço Vetorial Centróide com pesos associados
Outros modelos: Booleano Estendido, Difuso, Semântica
Latente, Probabilístico, etc…
CIn/UFPE 17
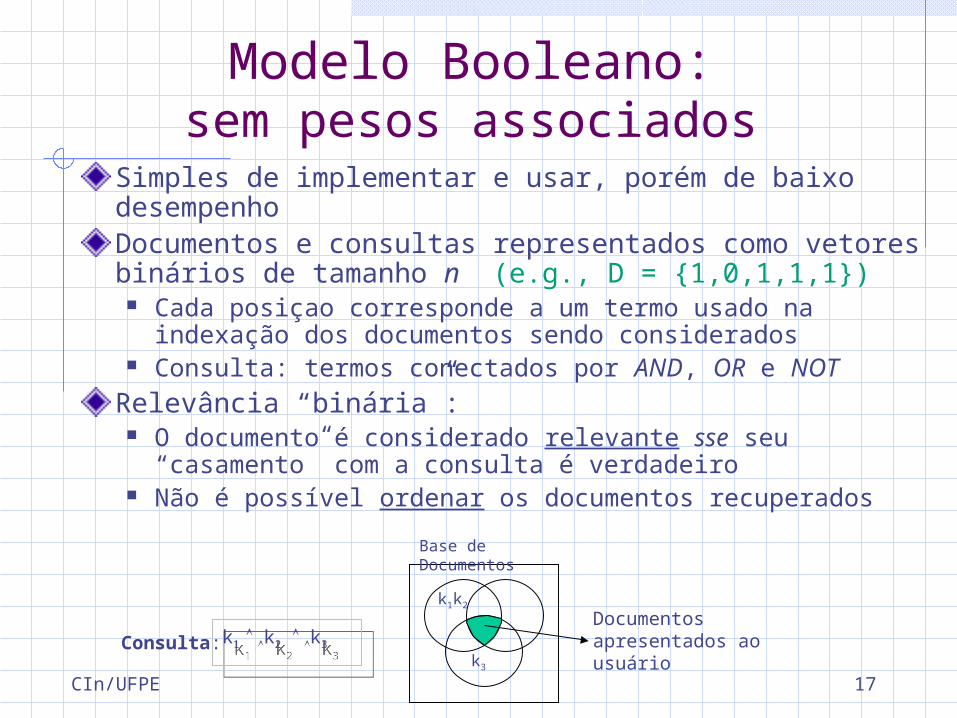
Modelo Booleano:sem pesos associados
Simples de implementar e usar, porém de baixo desempenhoDocumentos e consultas representados como vetores binários de tamanho n (e.g., D = {1,0,1,1,1})
Cada posiçao corresponde a um termo usado na indexação dos documentos sendo considerados
Consulta: termos conectados por AND, OR e NOTRelevância “binária”:
O documento é considerado relevante sse seu “casamento” com a consulta é verdadeiro
Não é possível ordenar os documentos recuperados
k1 k2 k3Consulta:Documentos apresentados ao usuário
k1k2
k3
Base de Documentos

CIn/UFPE 18Olimpíadas
Brasil
Sidney
d0.4
0.50.3
qBrasil Olimpíadas SidneyConsulta q :
Documento d :Brasil em Sidney 2000 O Brasil não foi bem no quadra das medalhas da Olimpíada de Sidney 2000 ...
Brasil 0.4Olimpíadas 0.3Sidney 0.3
Brasil 0.5Olimpíadas 0.3Sidney 0.2
Representação de q
Representação de d
Modelo Espaço Vetorial:com pesos associados
Consultas (q) e Documentos (d) são representados como vetores em um espaço n-dimensional
Onde n é o número total de termos usados para indexar os documentos sendo considerados
Relevância: co-seno do ângulo entre q e d Quanto maior o co-seno, maior é a relevância de d para q
Ordenação: dada pelo co-seno do ângulo entre q e d

CIn/UFPE 19
Representação do Documento com Pesos
Centróide Pesos associadas aos termos como indicação de
relevância: Freqüência de ocorrência do termo no documento TF-IDF = Term Frequency x Inverse Document
Frequency
TF-IDF também considera palavras com baixa ocorrência na base de documentos como melhores discriminantes
)(log)()(
DFD
TFTFIDFTF(w): freqüência da palavra w no doc.DF(w): freqüência de w em DD = total de documentos

CIn/UFPE 20
Representação do Documento com Pesos
Centróide Limitar tamanho do centróide em 50
mantendo apenas termos com maior peso Aumenta a eficiência do sistema Estudos mostram que isso não altera
muito o seu poder de representação do centróide

CIn/UFPE 21
Representação do Documento com Pesos
Enriquecendo a representação: Considerar formatação do texto como
indicação da importância dos termos título, início, negrito,...
Adicionar informação sobre a localização do termo no documento
Representação de documentos usada pelo Google
word : z - hit hit hit hitword : y - hit hit hit ...word : w - hit
Doc :xxx1bit capitalization; 3bit font size; 12 bit positionhit:

CIn/UFPE 22
Redução da Dimensão da Representação Inicial
Objetivo: Reduzir o tamanho dos centróides para
diminuir o risco de super-especialização do classificador gerado (overfitting)
Abordagens: Seleção de um subconjunto de termos Indução Construtiva
Tipos de Redução: Global: considera um conjunto de termos para
todas as classes Local: considera um conjunto de termos para
cada classes

CIn/UFPE 23
Seleção dos TermosCada termo recebe uma “relevância”, que é usada para ordenar a lista de termosOs “n” primeiros termos mais relevantes são utilizados para treinar o algoritmoVárias técnicas: Freqüência de ocorrência nos
documentos (redução global) Outras (redução local)
Entropia, Coeficiente de Correlação, 2 , ...

CIn/UFPE 24
Seleção dos Termos: Entropia (mutual information)
A relevância do termo Wi para a classe Cj é medida pela diferença de entropia dessa classe antes e depois do uso desse termo na sua predição
c
jjj CPCPH
12 )(log)(
c
jijij WCPWCPH
12 )|(log)|('
(incerteza inicial)
(incerteza final)
HHE ' (qtd. de incerteza removida)

CIn/UFPE 25
Seleção dos Termos: Coeficiente de Correlação
Coeficiente de Correlação entre o termo t e a classe Cj :
)()()()()(
nrnrnnrr
nrnr
NNNNNNNNNNNNNC
Nr+ = documentos relevantes para Cj que contêm o termo tNr- = documentos relevantes para Cj que não contêm t
Nn- = documentos não relevantes para Cj que não contêm tNn+ = documentos não relevantes para Cj que contêm t
χ2:mede a dependência entre um termo t e a classe Cj
22 C

CIn/UFPE 26
Indução ConstrutivaObjetivo: Obter novos termos (pela combinação dos termos
originais) que maximizem a precisão dos resultadosClustering: Técnica usada para agrupar termos originais de
acordo com o grau de relacionamento semântico entre eles O relacionamento pode ser dado, por exemplo, pela
co-ocorrência dos termos no conjunto de treinamento Cada cluster gerado passa a ser usado como um
novo “termo” Assim, termos redundantes são removidos

CIn/UFPE 27
Abordagem Simbólica: Árvores de Decisão Indução de Regras
Abordagem Numérica: Aprendizagem Bayesiana Redes Neurais Artificiais Aprendizagem Baseada em Instâncias
Construção Automática de Classificadores
CIn/UFPE 28
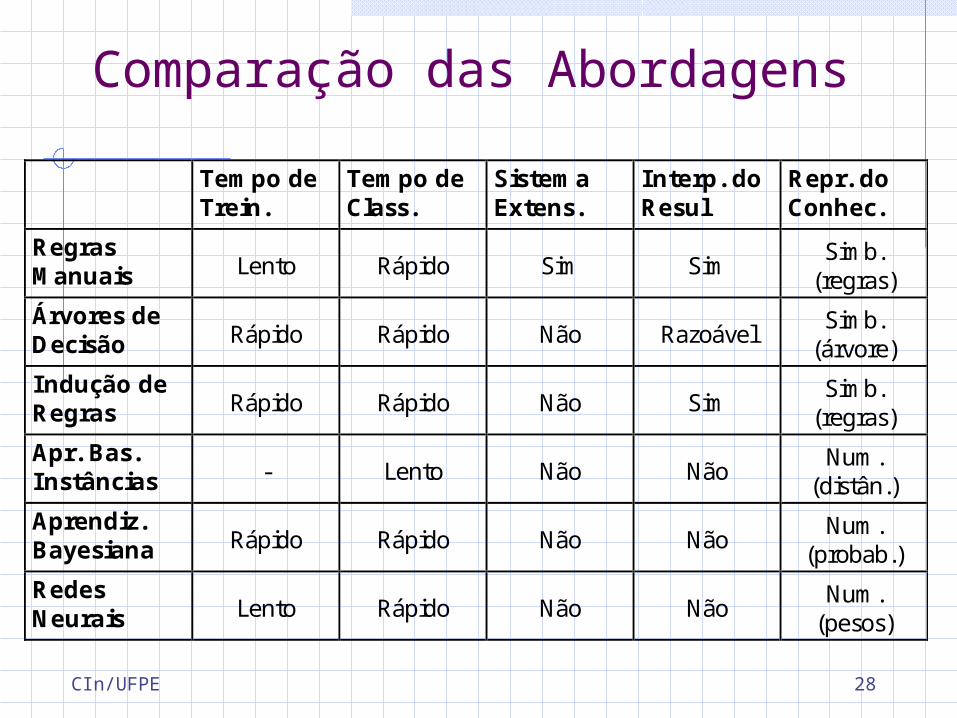
Comparação das AbordagensTempo deTrein.
Tempo deClass.
SistemaExtens.
Interp. doResul
Repr. doConhec.
RegrasManuais Lento Rápido Sim Sim Simb.
(regras)Árvores deDecisão Rápido Rápido Não Razoável Simb.
(árvore)Indução deRegras Rápido Rápido Não Sim Simb.
(regras)Apr. Bas.Instâncias - Lento Não Não Num.
(distân.)Aprendiz.Bayesiana Rápido Rápido Não Não Num.
(probab.)RedesNeurais Lento Rápido Não Não Num.
(pesos)

CIn/UFPE 29
ReferênciasCategorização de Documentos:
Sebastiani, F. A Tutorial on Automated Text Categorization. Analia Amandi and Alejandro Zunino (eds.), Proceedings of ASAI-99, 1st Argentinian Symposium on Artificial Intelligence, Buenos Aires, AR, pp. 7-35. 1999.
Moulinier, I. A Framework for Comparing Text Categorization Approaches. AAAI Spring Symposium on Machine Learning and Information Access, Stanford University, March 1996.
Sistemas Baseados em Conhecimento: Hayes, P. J. & Weinstein, S. P. Construe-TIS: A System for
Content-Based Indexing of a Database of News Stories. Second Annual Conference on Innovative Applications of Artificial Intelligence, pp. 48-64. 1990.
Neves, M. L. CitationFinder: Um Sistema de Meta-busca e Classificação de Páginas de Publicações na Web. Tese de Mestrado, Centro de Informática, UFPE, Fevereiro de 2001.

CIn/UFPE 30
ReferênciasAprendizagem de Máquina: Aprendizagem Bayesiana (Naive Bayes): McCallum, A. K.; Nigam, K.; Rennie, J. & Seymore, K. Automating
the Construction of Internet Portals with Machine Learning. Information Retrieval Journal, volume 3, pages 127-163. 2000.
Redes Neurais: Wiener, E.; Pedersen, J. O. & Weigend, A. S. A Neural Network
Approach to Topic Spotting. In Proceedings of the 4th Symposium on Document Analysis and Information Retrieval (SDAIR 95), pages 317-332, Las Vegas, NV, USA, April 24-26. 1995.
Aprendizagem Baseada em Instâncias: Masand, B; Linoff, G. & Waltz, D. Classifying News Stories using
Memory Based Reasoning. Proceedings of SIGIR-92, 15th ACM International Conference on Research and Development in Information Retrieval, pp. 59-65, Denmark. 1992.

CIn/UFPE 31
ReferênciasAprendizagem de Máquina (cont.): Árvores de Decisão: Lewis, D. D. & Ringuette, M. A Comparison of Two Learning Algorithms
for Text Categorization. In Third Annual Symposium on Document Analysis and Information Retrieval, pp. 81-93. 1994.
Indução de Regras: Apté, C.; Damerau, F. & Weiss, S. Automated Learning of Decision Rules
for Text Categorization. ACM Transactions on Information Systems, Vol. 12, No. 3, July 1994, pages 233-151. 1994.
Seleção de Termos: Ng, H. T.; Goh, W. B. & Low, K. L. Feature Selection, Perceptron learning
and a Usability Case Study for Text Categorization. Proceedings of SIGIR-97, 20th ACM International Conference on Research and Development in Information Retrieval, pp. 67-73, Philadelphia, PA, USA. 1997.
Maron, M. E. Automatic Indexing: An Experimental Inquiry. Journal of ACM, 8: 404-417. 1961.