climbing the kaggle leaderboard by exploiting the log-loss...
TRANSCRIPT

Climbing the Kaggle Leaderboard by Exploiting
the Log-Loss OracleJacob Whitehill
[email protected] Polytechnic Institute
AAAI’2018 Workshop Talk

• Data-mining competitions (Kaggle, KDDCup, DrivenData, etc.) have become a mainstay of machine learning practice.
• They help ensure comparability and reproducibility by providing a common test set and common rules.
Machine learning competitions

• They can help incentivize machine learning innovations in specific application domains:• Cervical cancer diagnosis from images• Restaurant visitor forecasting• …
• Ancillary benefit: provide credibility to new data scientists when searching for a job.
Machine learning competitions

Machine learning competitions
4
Competition organizerTraining data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
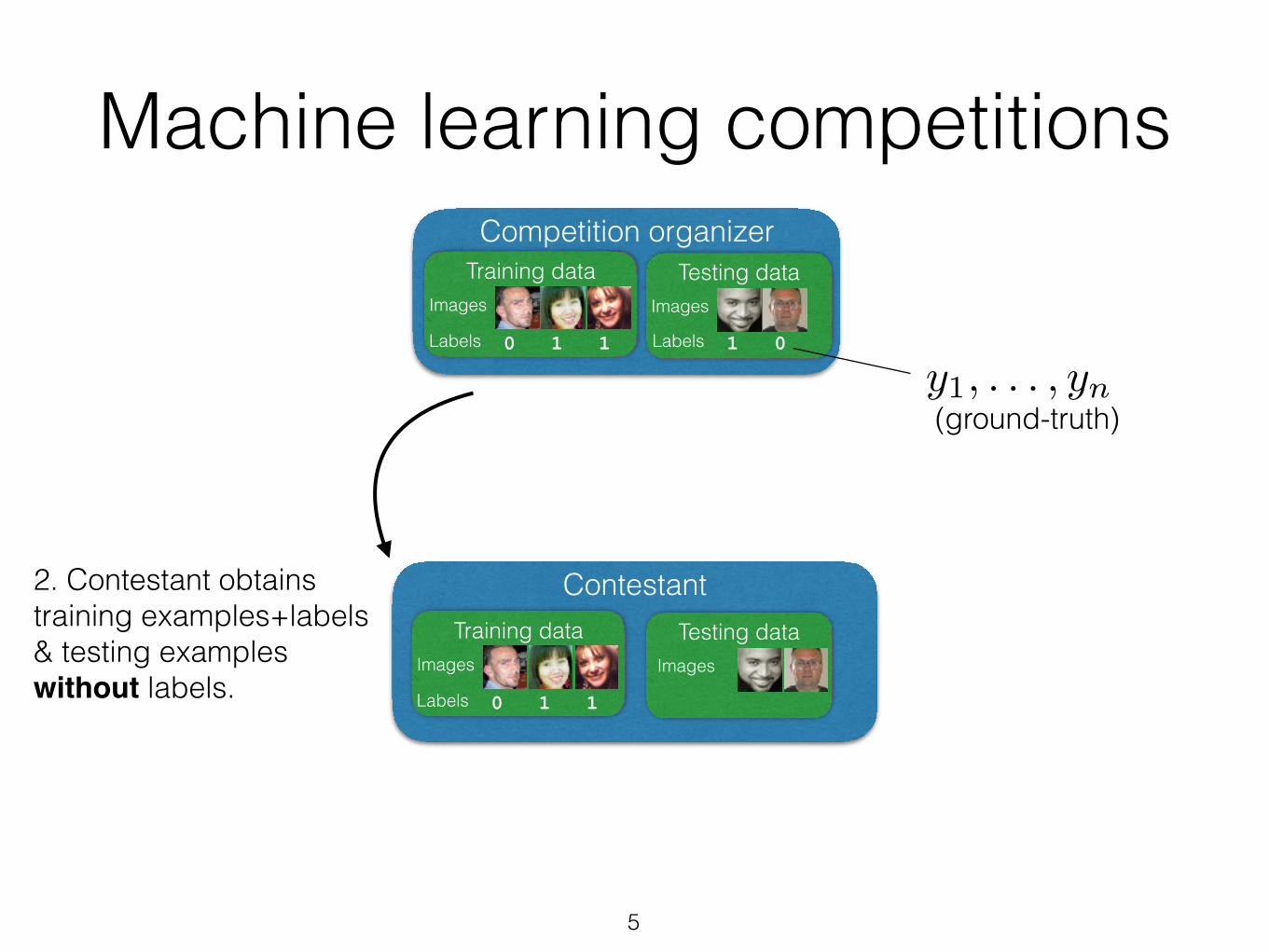
1. Competition organizer assembles training & testing data.
y1, . . . , yn(ground-truth)
Competition organizer
Machine learning competitions
5
ContestantTraining data
0 1 1
Images
Labels
Testing dataImages
Training data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
2. Contestant obtains training examples+labels & testing examples without labels.
y1, . . . , yn(ground-truth)

Competition organizer
Machine learning competitions
6
ContestantTraining data
0 1 1
Images
Labels
Testing dataImages
Training data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
Guesses 0.8 0.4
(guesses)
Machine learning
3. Contestant uses machine learning to guess the test labels.
y1, . . . , yn
y1, . . . , yn
(ground-truth)
Competition organizer
Machine learning competitions
7
ContestantTraining data
0 1 1
Images
Labels
Testing dataImages
Training data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
Guesses 0.8 0.4
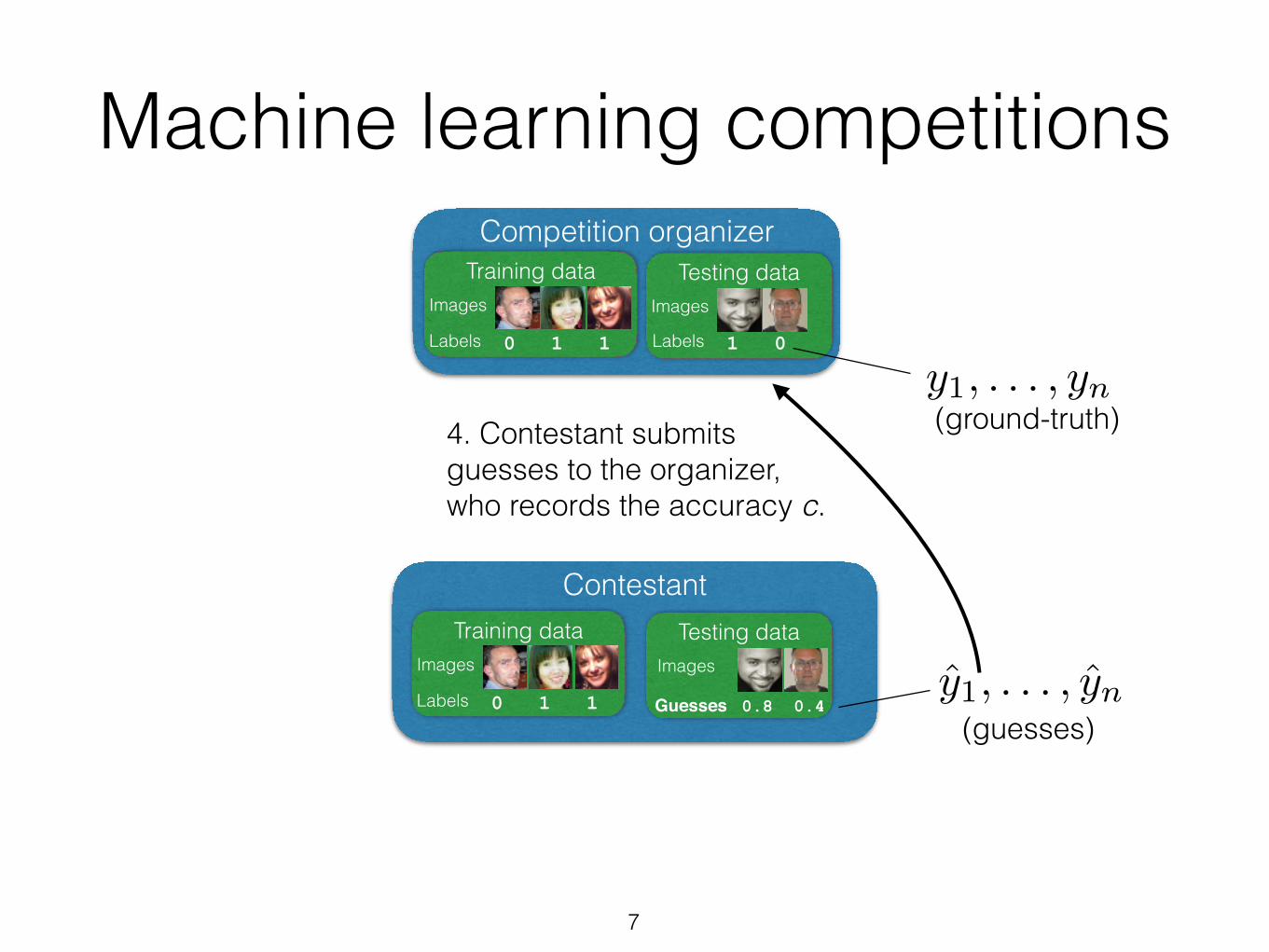
4. Contestant submits guesses to the organizer, who records the accuracy c.
y1, . . . , yn
y1, . . . , yn(guesses)
(ground-truth)

Competition organizer
Machine learning competitions
8
Contestant A
Training data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
5. When competition is over, the organizer reports which contestant won the contest.
Contestant B
Contestant C …
c=0.9201 c=0.9205 c=0.8982
Competition organizer
Machine learning competitions
9
ContestantTraining data
0 1 1
Images
Labels
Testing dataImages
Training data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
Guesses 0.8 0.4
Oracle
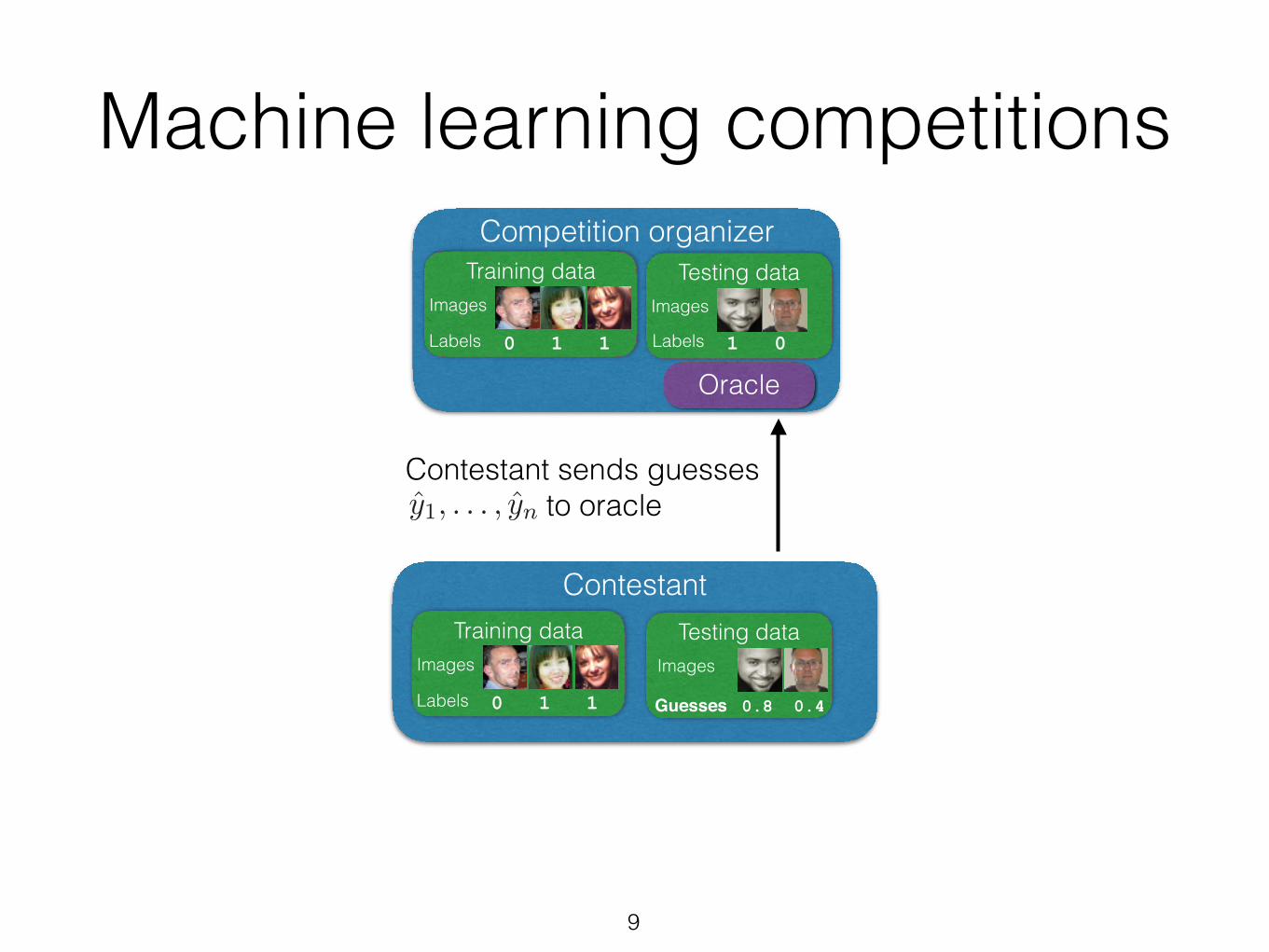
y1, . . . , ynContestant sends guesses to oracle

Competition organizer
Machine learning competitions
10
ContestantTraining data
0 1 1
Images
Labels
Testing dataImages
Training data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
Guesses 0.8 0.4
Oracle
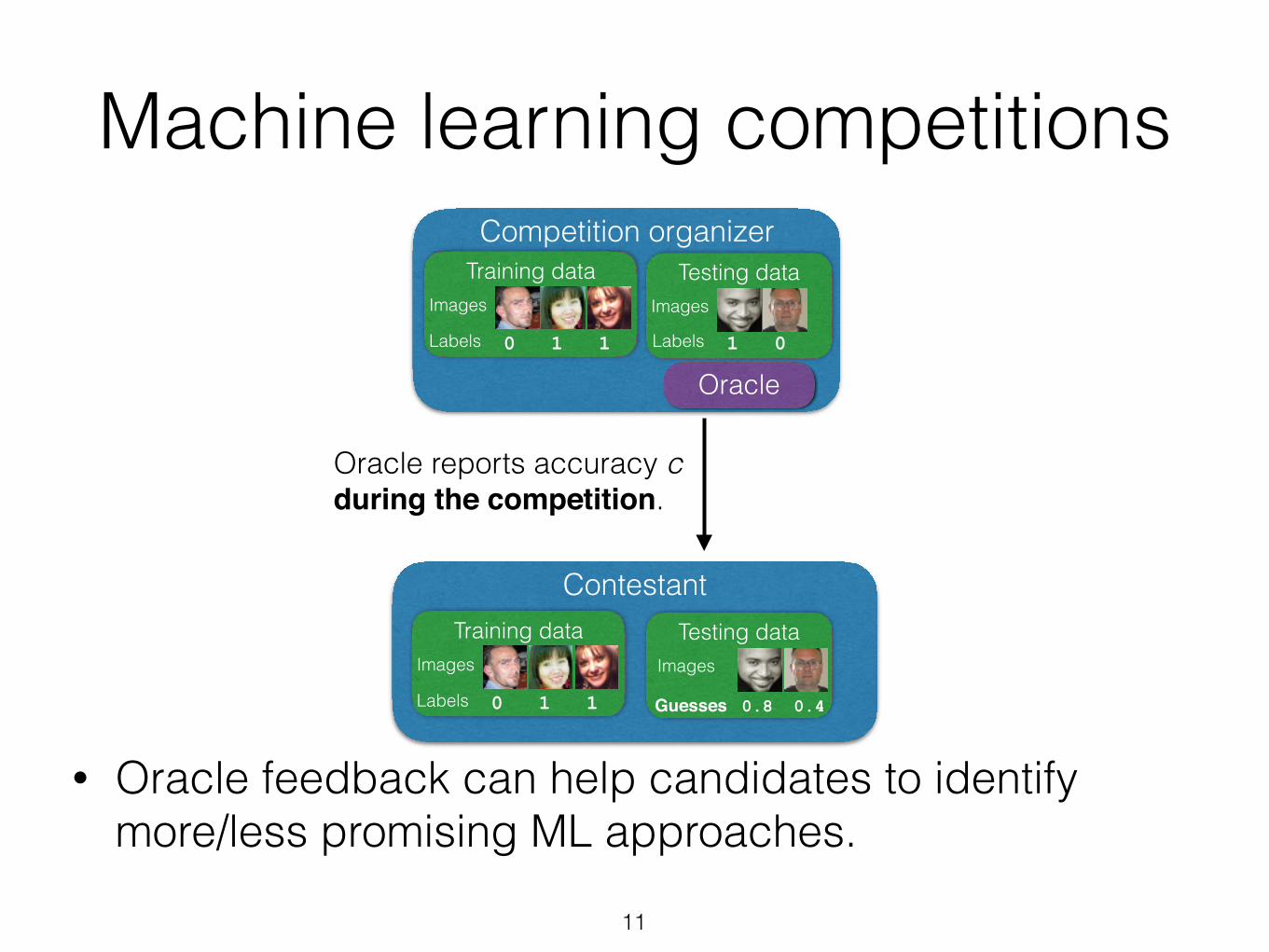
Oracle reports accuracy c during the competition.
Competition organizer
Machine learning competitions
11
ContestantTraining data
0 1 1
Images
Labels
Testing dataImages
Training data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
Guesses 0.8 0.4
Oracle
Oracle reports accuracy c during the competition.
• Oracle feedback can help candidates to identify more/less promising ML approaches.

Competition organizer
Machine learning competitions
12
ContestantTraining data
0 1 1
Images
Labels
Testing dataImages
Training data
0 1 1
Images
Labels
Testing dataImages
1 0Labels
Guesses 0.8 0.4
Oracle
Oracle reports accuracy c during the competition.
• Question: can the oracle be exploited to deduce the true labels illicitly?
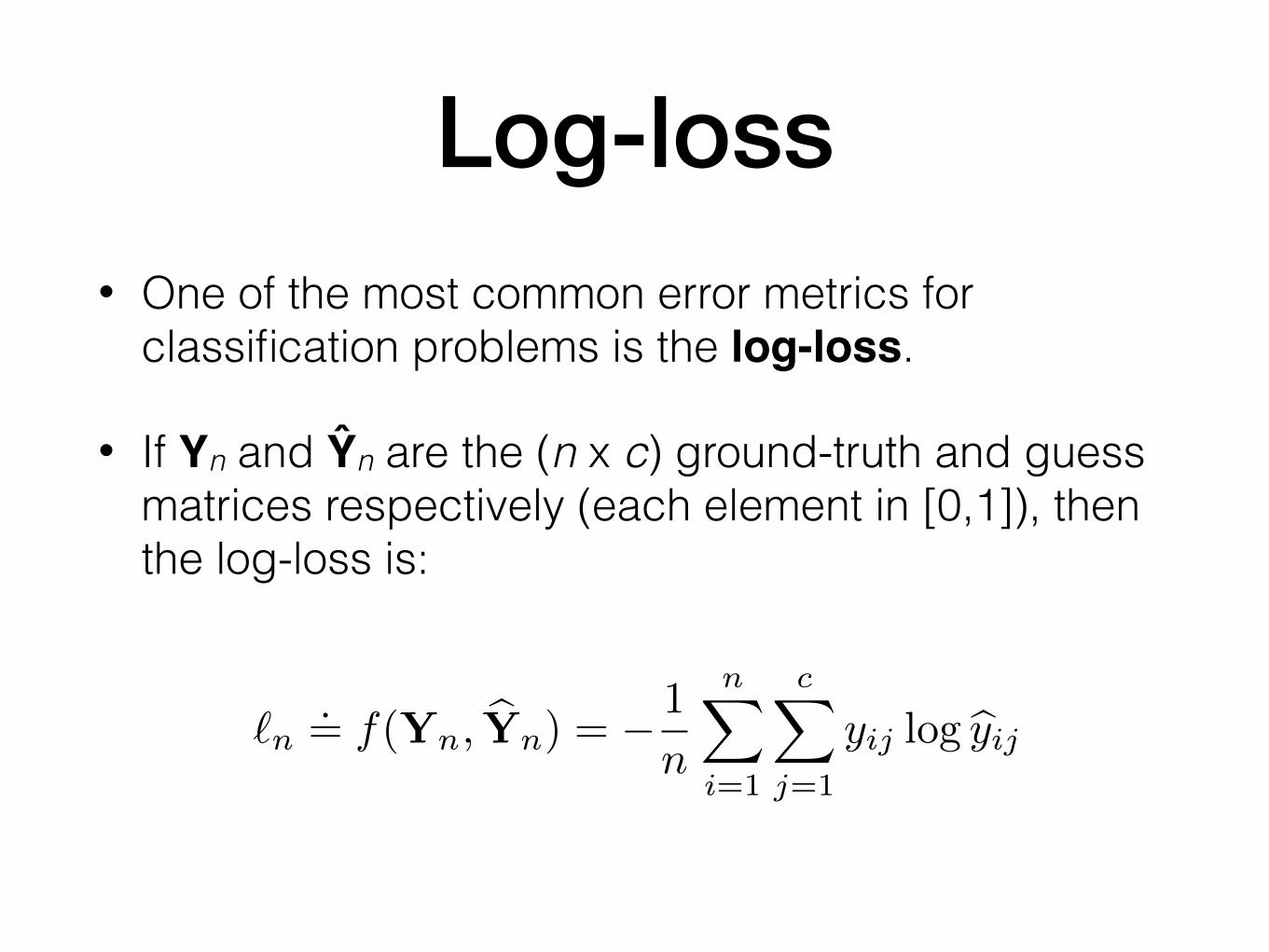
Log-loss• One of the most common error metrics for
classification problems is the log-loss.
• If Yn and Ŷn are the (n x c) ground-truth and guess matrices respectively (each element in [0,1]), then the log-loss is:
`n.= f(Yn, bYn) = � 1
n
nX
i=1
cX
j=1
yij log byij

Example• Suppose there are 2 examples and 3 classes, and the
contestant submits the following guesses to the oracle:
bY2 =
e�2 e�1 1� e�2 � e�1
e�8 e�4 1� e�8 � e�4
�
Y2 =
1 0 00 1 0
�
f(Y2, bY2) = �1
2
2X
i=1
3X
j=1
yij log byij = 3
• Suppose the oracle reports that:
• By iterating over all 32 possible ground-truths, we can easily determine that:

• In general, there are cn possible ground-truths for n examples — too many to be tractable.
• However: because the log-loss decomposes across examples, we can iteratively apply brute-force search over small batches of size m≪n.
• Over batches, we can deduce the ground-truth labels of the entire test set.
Exploiting the log-loss
l n
m
m
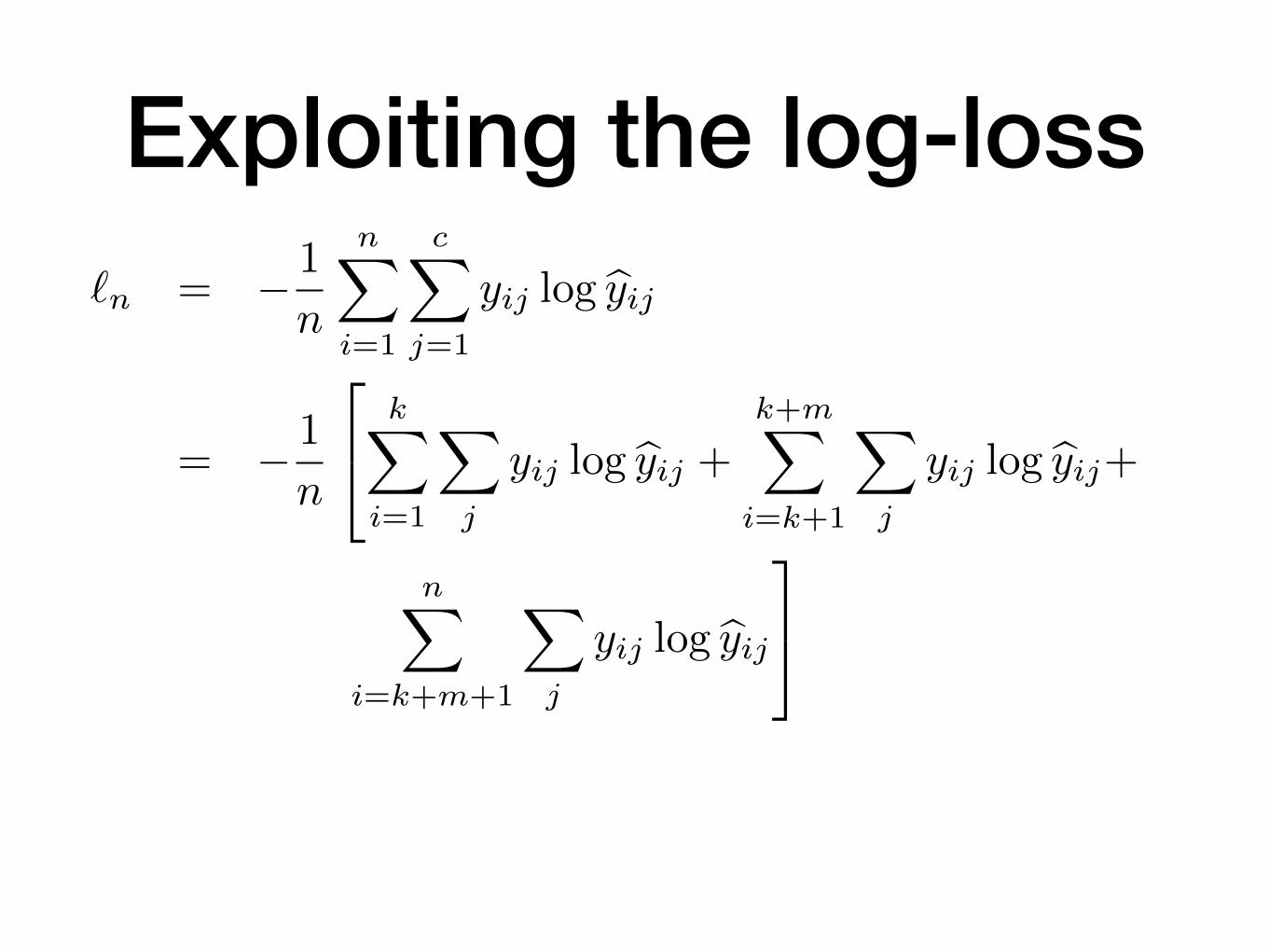
`n = � 1
n
nX
i=1
cX
j=1
yij log byij
= � 1
n
2
4kX
i=1
X
j
yij log byij +k+mX
i=k+1
X
j
yij log byij+
nX
i=k+m+1
X
j
yij log byij
3
5
Exploiting the log-loss
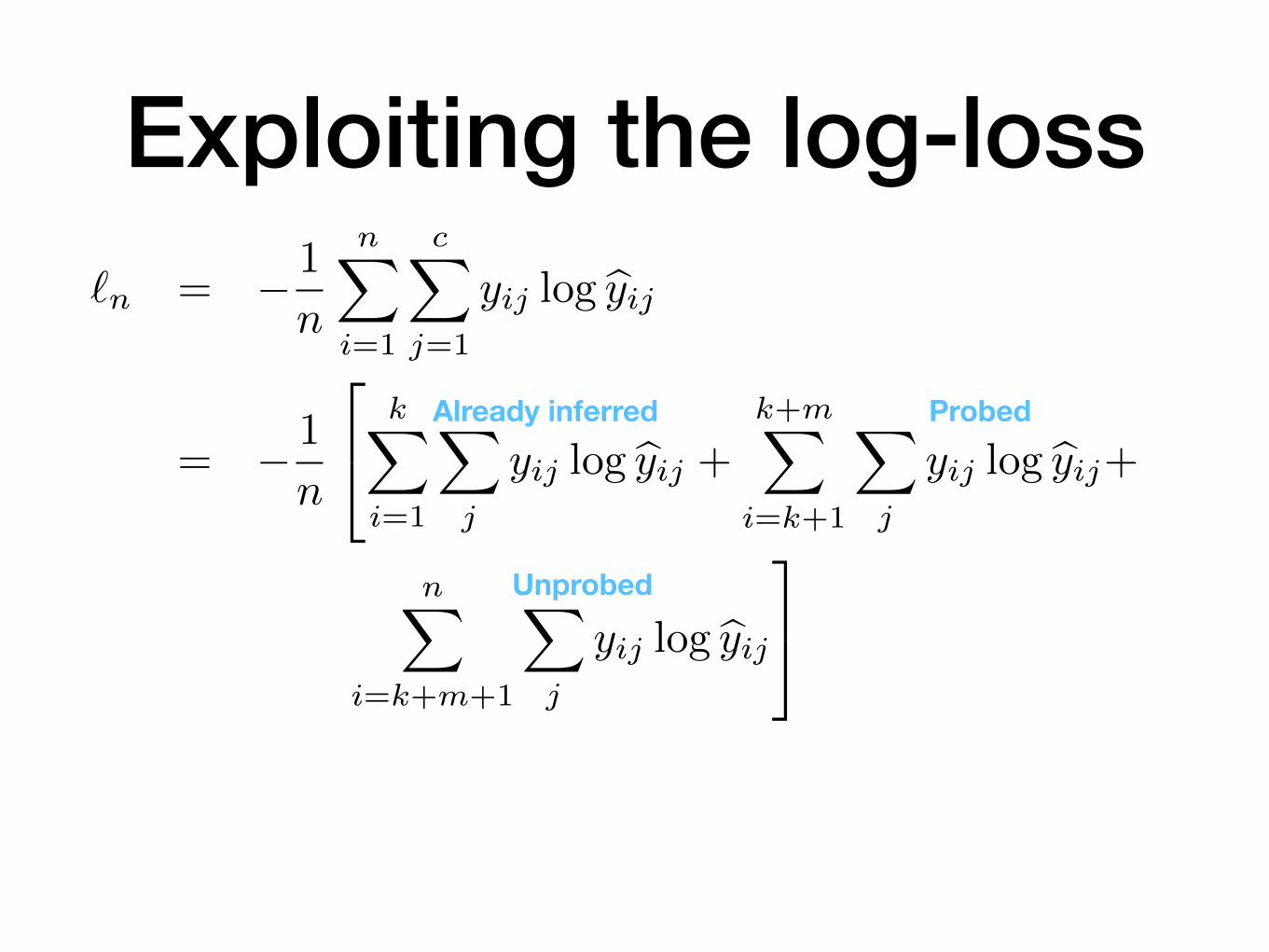
`n = � 1
n
nX
i=1
cX
j=1
yij log byij
= � 1
n
2
4kX
i=1
X
j
yij log byij +k+mX
i=k+1
X
j
yij log byij+
nX
i=k+m+1
X
j
yij log byij
3
5
Exploiting the log-loss
Already inferred
Unprobed
Probed
`n = � 1
n
nX
i=1
cX
j=1
yij log byij
= � 1
n
2
4kX
i=1
X
j
yij log byij +k+mX
i=k+1
X
j
yij log byij+
nX
i=k+m+1
X
j
yij log byij
3
5
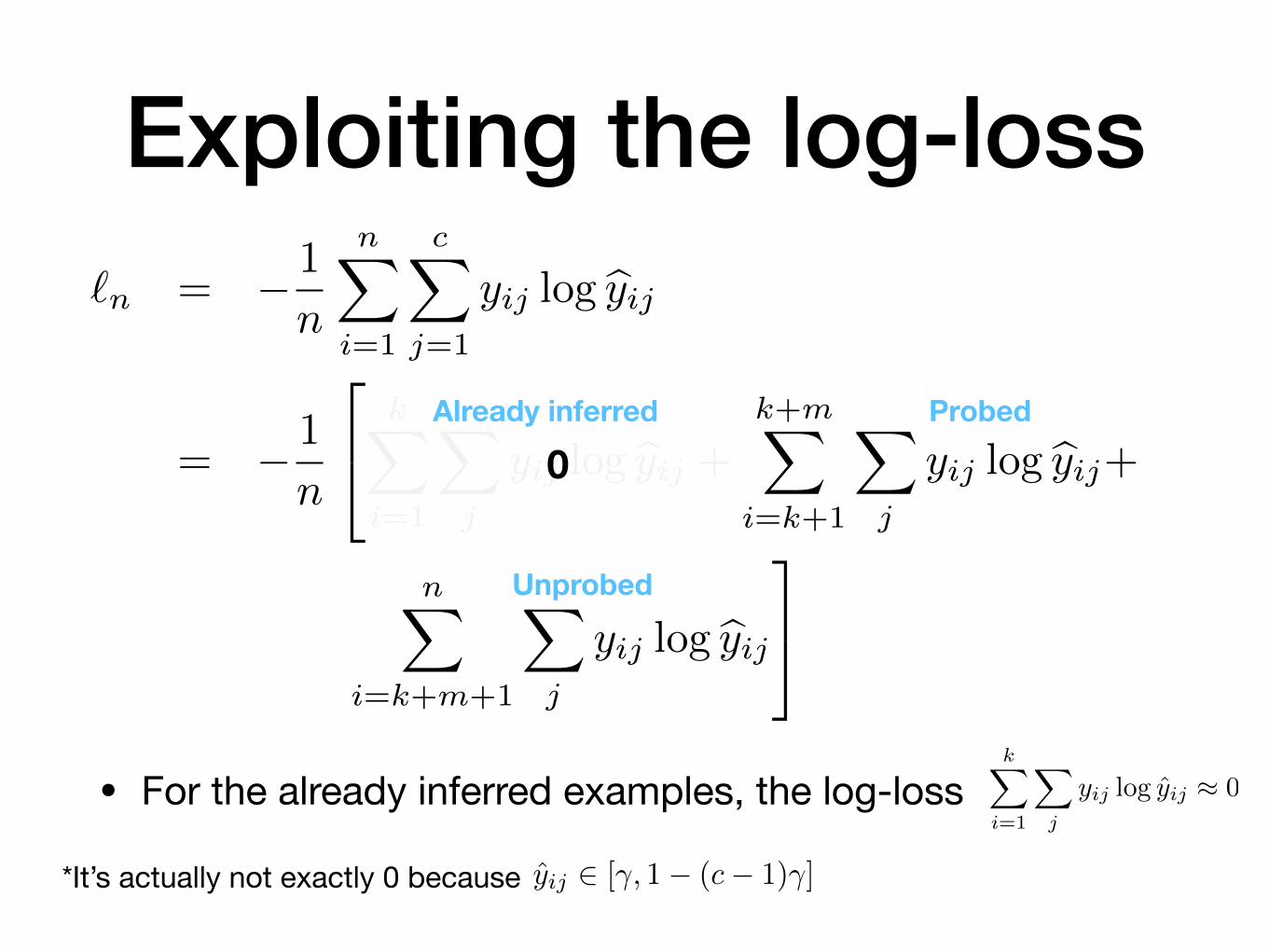
Already inferred
Exploiting the log-loss
Unprobed
Probed
kX
i=1
X
j
yij log yij ⇡ 0• For the already inferred examples, the log-loss
*It’s actually not exactly 0 because yij 2 [�, 1� (c� 1)�]
0

`n = � 1
n
nX
i=1
cX
j=1
yij log byij
= � 1
n
2
4kX
i=1
X
j
yij log byij +k+mX
i=k+1
X
j
yij log byij+
nX
i=k+m+1
X
j
yij log byij
3
5
Already inferred
Exploiting the log-loss
Probed
• For each unprobed example i, if we set ŷij = 1/c for all j, then the log-loss for example i is just -log c:
Unprobed
0
n(n�m�k) log 1/c

• Hence, the log-loss due to just the m probed examples is:
Exploiting the log-loss
`m.=
1
m
k+mX
i=k+1
X
j
yij log byij
=1
m((n�m� k) log c� n⇥ `n) (1)
`m
Log-loss over all n examples.
Returned by the oracle.

• Now that we know the log-loss on just the batch of examples, we can apply brute-force optimization over Ym.
• For any possible ground-truth Ym of the probed examples, define the estimation error:
• Select the Ym that minimizes 𝜀.
Exploiting the log-loss
✏.= |`m � f(Ym, bYm))|

• But how to choose the guesses Ŷm?
• If the oracles’s floating-point precision was infinite, then we could just choose a random real-valued matrix Ŷm.
• With probability 1, the log-loss would be different for every possible ground-truth, and we could recover Ym unambiguously.
Choosing the guesses Ŷm
`m

• In practice, the oracle’s floating-point precision is finite, e.g., 5th decimal place.
• Collisions can occur: different Ym that result in very similar log-loss values .
Choosing the guesses Ŷm
`m

Q( bYm).= min
Ym 6=Y0m
|f(Ym, bYm)� f(Y0m, bYm)| (1)
Choosing the guesses Ŷm
• To avoid collisions, we want to choose Ŷm so that no two distinct ground-truths Ym and Ym' result in a similar loss:
• We want to maximize Q(Ŷm):
• This is a constrained minimax (maximin) optimization problem.
bY⇤m
.= arg maxQ( bYm)

• Special optimization algorithms do exist for constrained minimax problems.
• However, in our case they are impractical because the number of constraints grows exponentially with m.
• In practice, we employed an ad-hoc heuristic to maximize Q w.r.t. Ŷm.
Choosing the guesses Ŷm

Upper bound on quality
• For m=6, we found a Ŷm that worked well in practice.

Intel-MobileODT Kaggle competition
• We applied this algorithm to “climb the Kaggle leaderboard” for the Intel-MobileODT Kaggle (2017) competition.
• Topic: diagnosis of cervical cancer from medical images.
• Competition structure:
• 1st phase: test set of 512 examples
• 2nd phase: test set of 4018 examples (including original 512)

Intel-MobileODT Kaggle competition
• We applied this algorithm to “climb the Kaggle leaderboard” for the Intel-MobileODT Kaggle (2017) competition.
• Topic: diagnosis of cervical cancer from medical images.
• Competition structure:
• 1st phase: test set of 512 examples
• 2nd phase: test set of 4018 examples (including original 512)
Mostly for informational purposes
Used to decide who wins $100K

1. We receive the log-loss from the oracle:
2. We calculate the loss on just the probed examples:
4. We conduct brute-force optimization to identify Ym:
Procedure
`n = 1.10063
`m = 1.63153241132
2
664
0, 1, 01, 0, 00, 0, 10, 0, 1
3
775
1.jpg 2.jpg 3.jpg 4.jpg

Kaggle MobileODT competition (1st stage)
• We repeat this process until we’ve inferred the labels of all 512 examples…

Kaggle MobileODT competition (1st stage)
• We repeat this process until we’ve inferred the labels of all 512 examples…

Kaggle MobileODT competition (1st stage)
• We repeat this process until we’ve inferred the labels of all 512 examples…
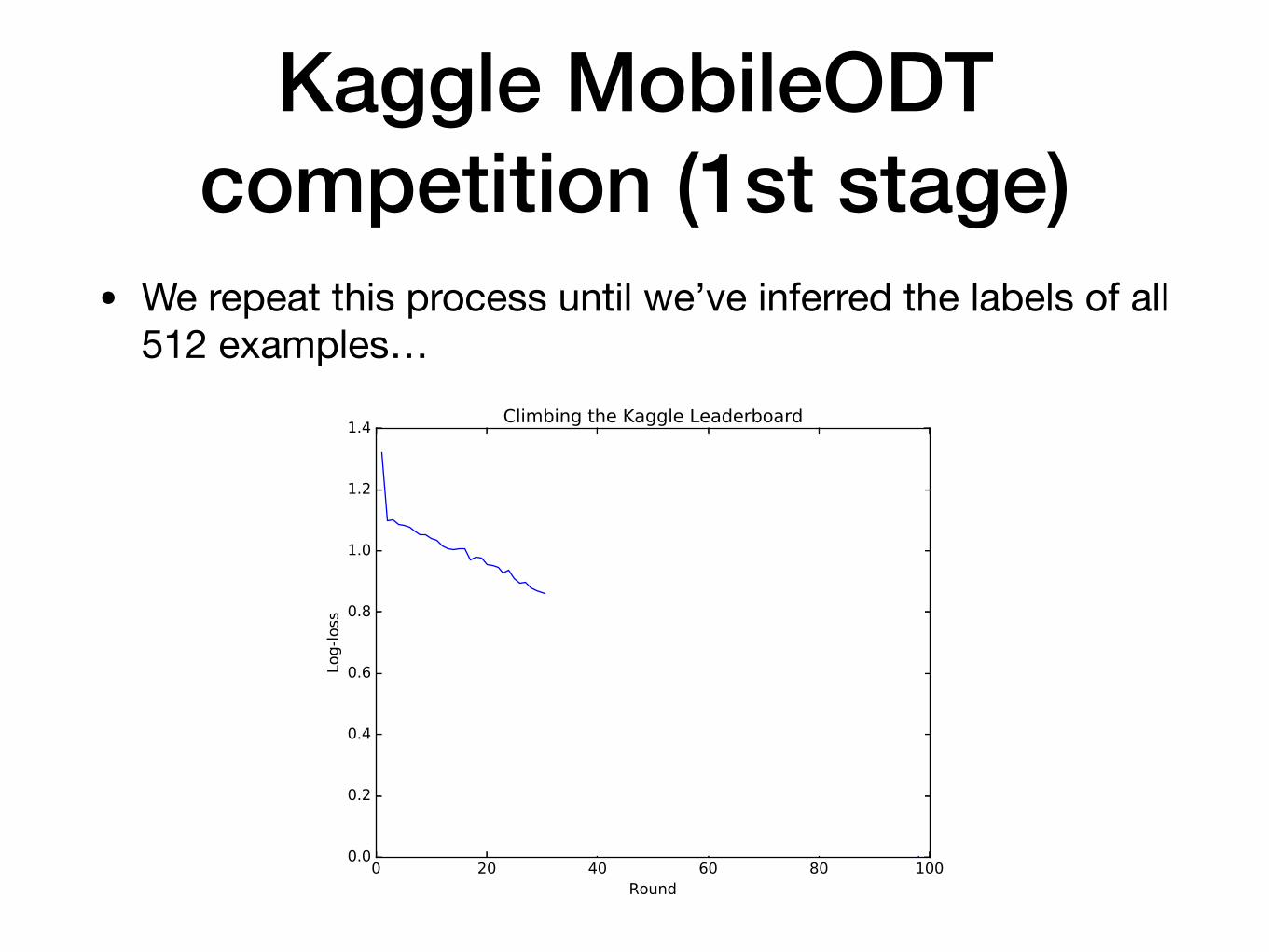
Kaggle MobileODT competition (1st stage)
• We repeat this process until we’ve inferred the labels of all 512 examples…
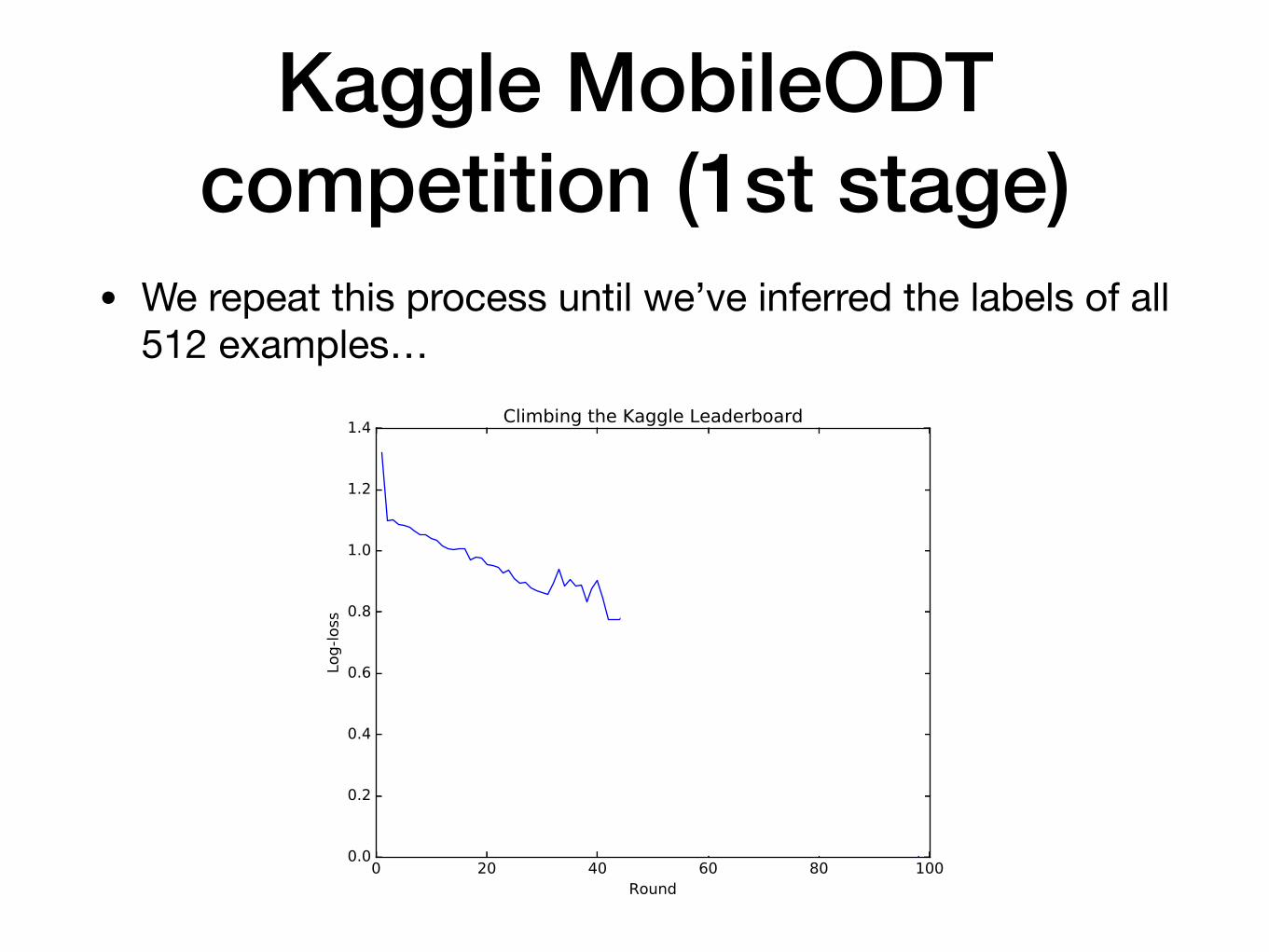
Kaggle MobileODT competition (1st stage)
• We repeat this process until we’ve inferred the labels of all 512 examples…

Kaggle MobileODT competition (1st stage)
• We repeat this process until we’ve inferred the labels of all 512 examples…

Kaggle MobileODT competition (1st stage)
• Eventually, we achieved a log-loss of 0 and climbed to rank #4 on the leaderboard…without doing any real machine learning.

• To be clear: the 2nd stage of the competition (which we did not win) was the basis for awarding the $100K prize.
• Our 2nd-stage rank was 225 out of 884 contestants (top 30%), since 512 out of 4018 examples were the same as in 1st stage.
Kaggle MobileODT competition (1st stage)

• Some other data-mining competition sites, such as DataDriven, host competitions that have no 2nd stage.
• In light of potential attacks, this seems dangerous.
• There might be some ancillary value in performing well even without winning actual prize money.
• “Bragging rights”, useful for getting a job interview?
Kaggle MobileODT competition (1st stage)

Foiling the log-loss attack

Adaptive data analysis
• The previous log-loss attack is an example of (malicious) adaptive data analysis — we use the performance of a previous analysis to inform the next one.
• Other forms of adaptive data analysis also exist, e.g., overfitting to test data by changing hyperparameters.
• Recent research on privacy-preserving machine learning and complexity theory has sought to find remedies.

Ladder algorithm(Blum & Hardt 2015)
• Problem (for ML community) with log-loss attack:
• The “classifier” does very well on the test set, but is useless on the true data distribution.

Ladder algorithm(Blum & Hardt 2015)
• Ladder algorithm (Blum & Hardt 2015): goal is to ensure that leaderboard accuracies reflect each classifier’s true loss w.r.t. entire data distribution, not just the empirical (test-set) loss.
• In essence:
• “Accept” a new submission only if its accuracy is significantly better than the current best.
• Oracle will not report the new accuracy if it’s only slightly better.

• Indeed, in simulation we can verify that the Ladder mechanism foils our log-loss attack:
• In practice, Ladder seems not (yet?) to be used widely (or at all?).
• Might be unpopular with contestants since a small improvement in the true loss might be rejected.
• In any case, Ladder is designed to prevent sequential probing — but what about one-shot attacks?
Ladder algorithm(Blum & Hardt 2015)

Exploiting an Oracle That Reports AUC Scores in
Machine Learning Contests Whitehill (2016), AAAI.

AUC metric• One of the most widely used accuracy metrics for
binary classification problems is the Area Under the receiver operating characteristics Curve (AUC).
45
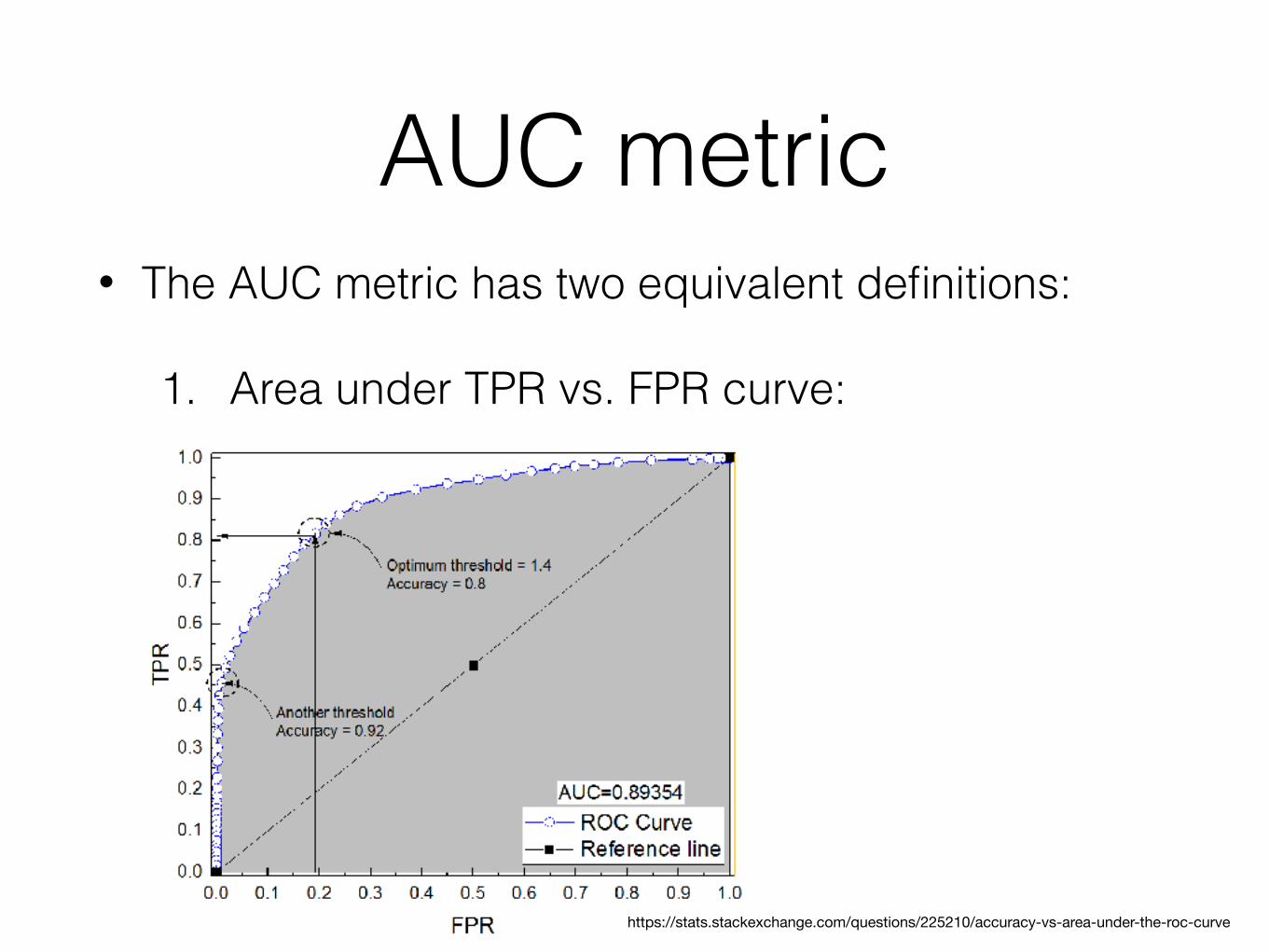
AUC metric• The AUC metric has two equivalent definitions:
1. Area under TPR vs. FPR curve:
46https://stats.stackexchange.com/questions/225210/accuracy-vs-area-under-the-roc-curve

AUC metric• The AUC metric has two equivalent definitions:
2. Probability of correct response in a 2-alternative forced choice task (one + example, one - example):
47

AUC attacks• Since the AUC is a fraction of pairs, it is a rational
number.
• Let AUC c = p/q.
• If contestant knows p/q exactly, what can she/he infer about the ground-truth labels?
48

Attack 1:Infer knowledge of n0, n1
• Based on AUC c=p/q and test set size n, we can infer the set of possible values for (n0, n1):
• q must divide n0n1.
• n0+n1 must equal n.
49
S

Example
• Suppose n = 100 and c = 0.985 = p/q = 197/200.
• Then since n0+n1=n and since 200 | n0n1, we know = {(20, 80), (40, 60), (60, 40), (80, 20)}.
50
S

Attack 2• Suppose contestant knows that .
• Suppose contestant’s guesses obtain AUC c.
• Then if for all , then the first k examples according to the rank order of must be negatively labeled.
51
y1, . . . , yn
y1, . . . , yn
n1 2 S
n1 2 S

• Suppose contestant knows that .
• Suppose contestant’s guesses obtain AUC c.
• Then if for all , then the first k examples according to the rank order of must be negatively labeled.
• Intuition: these are the guesses on which the classifier is most confident are negatively labeled. If the classifier were wrong about any of them, the AUC would be much lower.
52
y1, . . . , yn
y1, . . . , yn
n1 2 S
n1 2 S
Attack 2

• Suppose contestant knows that .
• Suppose contestant’s guesses obtain AUC c.
• Then if for all , then the first k examples according to the rank order of must be negatively labeled.
• Intuition: these are the guesses on which the classifier is most confident are negatively labeled. If the classifier were wrong about any of them, the AUC would be much lower.
• Analogous result holds for the last few examples being positive.
53
y1, . . . , yn
y1, . . . , yn
n1 2 S
n1 2 S
Attack 2

Example• Suppose n=100, c=0.99, and the contestant knows
that between 25% and 75% of examples are positive.
• Then the first* 5 examples must be negative, and the last* 5 examples must be positive.
54
y1, . . . , yn* according to rank order of

Example• Suppose n=100, c=0.99, and the contestant knows
that between 25% and 75% of examples are positive.
• Then the first* 5 examples must be negative, and the last* 5 examples must be positive.
• The contestant can deduce the identity of 10% of the test examples.
55
y1, . . . , yn* according to rank order of

Attack 3• Search for all possible ground-truths for
which the AUC of the guesses is some fixed value c.
56
y1, . . . , yn

Example
• Consider a tiny test set of just 4 examples.
• Suppose your guesses are
• Suppose the oracle says the accuracy (AUC) for these guesses is c=0.75.
57
y1 = 0.5, y2 = 0.6, y3 = 0.9, y4 = 0.4

Example
58
AUC for different labelingsy1 y2 y3 y4 AUC0 0 0 0 –0 0 0 1 0.000 0 1 0 1.000 0 1 1 0.500 1 0 0 ⇡ 0.670 1 0 1 0.250 1 1 0 1.000 1 1 1 ⇡ 0.671 0 0 0 ⇡ 0.331 0 0 1 0.001 0 1 0 0.751 0 1 1 ⇡ 0.331 1 0 0 0.501 1 0 1 0.001 1 1 0 1.001 1 1 1 –
Table 1: Accuracy (AUC) achieved when a contestant’sreal-valued guesses of the test labels are y1 = 0.5, y2 =0.6, y3 = 0.9, y4 = 0.4, shown for each possible ground-truth labeling. Only for one possible labeling (highlighted)do the contestant’s guesses achieve AUC of exactly 0.75.
Attack 1: Deducing Highest/Lowest-RankedLabels with Certainty
In this section we describe how a contestant, whose guessesare already very accurate (AUC close to 1), can orchestratean attack to infer a few of the test set labels with completecertainty. This could be useful for several reasons: (1) Eventhough the attacker’s AUC is close to 1, he/she may notknow the actual test set labels – see Table 1 for an example.If the same test examples were ever re-used in a subsequentcompetition, then knowing their labels could be helpful. (2)Once the attacker knows some of the test labels with cer-tainty, he/she can now use these examples for training. Thiscan be especially beneficial when the test set is drawn froma different population than the training set (e.g., different setof human subjects’ face images (Valstar et al. 2011)). (3) Ifmultiple attackers all score a high AUC but have very dif-ferent sets of guesses, then they could potentially collude toinfer the labels of a large number of test examples.
The attack requires rather strong prior knowledge of theexact number of positive and negative examples in the testset (n1 and n0, respectively).Proposition 1. Let D be a dataset with labels y1, . . . , yn, of
which n0 are negative and n1 are positive. Let y1, . . . , yn be
a contestant’s real-valued guesses for the labels of D such
that yi = yj () i = j. Let c = f(y1:n, y1:n) denote the
AUC achieved by the real-valued guesses with respect to the
ground-truth labels. For any positive integer k n0, if c >1� 1
n1+ k
n0n1, then the first k examples according to the rank
order of y1, . . . , yn must be negatively labeled. Similarly, for
any positive integer k n1, if c > 1� 1n0
+ kn0n1
, then the
last k examples according to the rank order of y1, . . . , ynmust be positively labeled.
Proof. Without loss of generality, suppose that the indicesare arranged such that the yi are sorted, i.e., y1 < . . . < yn.Suppose, by way of contradiction, that m of the first k ex-amples were positively labeled, where 1 m k. For eachsuch possible m, we can find at least m(n0�k) pairs that aremisclassified according to the real-valued guesses by pairingeach of the m positively labeled examples within the indexrange {i : 1 i k} with each of (n0 � k) negatively la-beled examples within the index range {j : k+1 j n}.In each such pair (i, j), yi = 1 and yj = 0, and yet yi < yj ,and thus the pair is misclassified. The minimum number ofmisclassified pairs, over all m in the range {1, . . . , k}, isclearly n0 � k (for m = 1). Since there are n0n1 total pairsin D consisting of one positive and one negative example,and since the AUC is maximized when the number of mis-classified pairs is minimized, then the maximum AUC thatcould be achieved when m � 1 of the first k examples arepositively labeled is
1� n0 � k
n0n1= 1� 1
n1+
k
n0n1
But this is less than c. We must therefore conclude that m =0, i.e., all of the first k examples are negatively labeled.
The proof is exactly analogous for the case when c >1� 1
n0+ k
n0n1.
ExampleSuppose that a contestant’s real-valued guesses y1, . . . , ynachieve an AUC of c = 0.985 on a dataset containing n0 =45 negative and n1 = 55 positive examples, and that n0 andn1 are known to him/her. Then the contestant can concludethat the labels of the first (according to the rank order ofy1, . . . , yn) 7 examples must be negative and the labels ofthe last 17 examples must be positive.
Attack 2: Integration over Satisfying SolutionsThe second attack that we describe treats the AUC reportedby the oracle as an observed random variable in a standardsupervised learning framework. In contrast to Attack 1, noprior knowledge of n0 or n1 is required. Note that the attackwe describe uses only a single oracle query to improve an ex-isting set of real-valued guesses. More sophisticated attacksmight conceivably refine the contestant’s guesses in an itera-tive fashion using multiple queries. Notation: In this sectiononly, capital letters denote random variables and lower-caseletters represent instantiated values.
Consider the graphical model of Fig. 1, which depicts atest set containing n examples where each example i is de-scribed by a vector Xi 2 Rm of m features (e.g., imagepixels). Under the model, each label Yi 2 {0, 1} is gen-erated according to P (Yi = 1 | xi, ✓) = g(xi, ✓), whereg : Rm ⇥ Rm ! [0, 1] could be, for example, the sigmoidfunction of logistic regression and ✓ 2 Rm is the classifierparameter. Note that this is a standard probabilistic discrim-inative model – the only difference is that we have createdan intermediate variable Yi 2 [0, 1] to represent g(xi, ✓) ex-plicitly for each i. Specifically, we define:
P (yi | xi, ✓) = �(yi � g(xi, ✓))
P (Yi = 1 | yi) = yi
y1 = 0.5, y2 = 0.6, y3 = 0.9, y4 = 0.4
For guesses:

Example
59
AUC for different labelingsy1 y2 y3 y4 AUC0 0 0 0 –0 0 0 1 0.000 0 1 0 1.000 0 1 1 0.500 1 0 0 ⇡ 0.670 1 0 1 0.250 1 1 0 1.000 1 1 1 ⇡ 0.671 0 0 0 ⇡ 0.331 0 0 1 0.001 0 1 0 0.751 0 1 1 ⇡ 0.331 1 0 0 0.501 1 0 1 0.001 1 1 0 1.001 1 1 1 –
Table 1: Accuracy (AUC) achieved when a contestant’sreal-valued guesses of the test labels are y1 = 0.5, y2 =0.6, y3 = 0.9, y4 = 0.4, shown for each possible ground-truth labeling. Only for one possible labeling (highlighted)do the contestant’s guesses achieve AUC of exactly 0.75.
Attack 1: Deducing Highest/Lowest-RankedLabels with Certainty
In this section we describe how a contestant, whose guessesare already very accurate (AUC close to 1), can orchestratean attack to infer a few of the test set labels with completecertainty. This could be useful for several reasons: (1) Eventhough the attacker’s AUC is close to 1, he/she may notknow the actual test set labels – see Table 1 for an example.If the same test examples were ever re-used in a subsequentcompetition, then knowing their labels could be helpful. (2)Once the attacker knows some of the test labels with cer-tainty, he/she can now use these examples for training. Thiscan be especially beneficial when the test set is drawn froma different population than the training set (e.g., different setof human subjects’ face images (Valstar et al. 2011)). (3) Ifmultiple attackers all score a high AUC but have very dif-ferent sets of guesses, then they could potentially collude toinfer the labels of a large number of test examples.
The attack requires rather strong prior knowledge of theexact number of positive and negative examples in the testset (n1 and n0, respectively).Proposition 1. Let D be a dataset with labels y1, . . . , yn, of
which n0 are negative and n1 are positive. Let y1, . . . , yn be
a contestant’s real-valued guesses for the labels of D such
that yi = yj () i = j. Let c = f(y1:n, y1:n) denote the
AUC achieved by the real-valued guesses with respect to the
ground-truth labels. For any positive integer k n0, if c >1� 1
n1+ k
n0n1, then the first k examples according to the rank
order of y1, . . . , yn must be negatively labeled. Similarly, for
any positive integer k n1, if c > 1� 1n0
+ kn0n1
, then the
last k examples according to the rank order of y1, . . . , ynmust be positively labeled.
Proof. Without loss of generality, suppose that the indicesare arranged such that the yi are sorted, i.e., y1 < . . . < yn.Suppose, by way of contradiction, that m of the first k ex-amples were positively labeled, where 1 m k. For eachsuch possible m, we can find at least m(n0�k) pairs that aremisclassified according to the real-valued guesses by pairingeach of the m positively labeled examples within the indexrange {i : 1 i k} with each of (n0 � k) negatively la-beled examples within the index range {j : k+1 j n}.In each such pair (i, j), yi = 1 and yj = 0, and yet yi < yj ,and thus the pair is misclassified. The minimum number ofmisclassified pairs, over all m in the range {1, . . . , k}, isclearly n0 � k (for m = 1). Since there are n0n1 total pairsin D consisting of one positive and one negative example,and since the AUC is maximized when the number of mis-classified pairs is minimized, then the maximum AUC thatcould be achieved when m � 1 of the first k examples arepositively labeled is
1� n0 � k
n0n1= 1� 1
n1+
k
n0n1
But this is less than c. We must therefore conclude that m =0, i.e., all of the first k examples are negatively labeled.
The proof is exactly analogous for the case when c >1� 1
n0+ k
n0n1.
ExampleSuppose that a contestant’s real-valued guesses y1, . . . , ynachieve an AUC of c = 0.985 on a dataset containing n0 =45 negative and n1 = 55 positive examples, and that n0 andn1 are known to him/her. Then the contestant can concludethat the labels of the first (according to the rank order ofy1, . . . , yn) 7 examples must be negative and the labels ofthe last 17 examples must be positive.
Attack 2: Integration over Satisfying SolutionsThe second attack that we describe treats the AUC reportedby the oracle as an observed random variable in a standardsupervised learning framework. In contrast to Attack 1, noprior knowledge of n0 or n1 is required. Note that the attackwe describe uses only a single oracle query to improve an ex-isting set of real-valued guesses. More sophisticated attacksmight conceivably refine the contestant’s guesses in an itera-tive fashion using multiple queries. Notation: In this sectiononly, capital letters denote random variables and lower-caseletters represent instantiated values.
Consider the graphical model of Fig. 1, which depicts atest set containing n examples where each example i is de-scribed by a vector Xi 2 Rm of m features (e.g., imagepixels). Under the model, each label Yi 2 {0, 1} is gen-erated according to P (Yi = 1 | xi, ✓) = g(xi, ✓), whereg : Rm ⇥ Rm ! [0, 1] could be, for example, the sigmoidfunction of logistic regression and ✓ 2 Rm is the classifierparameter. Note that this is a standard probabilistic discrim-inative model – the only difference is that we have createdan intermediate variable Yi 2 [0, 1] to represent g(xi, ✓) ex-plicitly for each i. Specifically, we define:
P (yi | xi, ✓) = �(yi � g(xi, ✓))
P (Yi = 1 | yi) = yi
y1 = 0.5, y2 = 0.6, y3 = 0.9, y4 = 0.4
For guesses:
The true labels must be:y1 = 1, y2 = 0, y3 = 1, y4 = 0

Example
60
AUC for different labelingsy1 y2 y3 y4 AUC0 0 0 0 –0 0 0 1 0.000 0 1 0 1.000 0 1 1 0.500 1 0 0 ⇡ 0.670 1 0 1 0.250 1 1 0 1.000 1 1 1 ⇡ 0.671 0 0 0 ⇡ 0.331 0 0 1 0.001 0 1 0 0.751 0 1 1 ⇡ 0.331 1 0 0 0.501 1 0 1 0.001 1 1 0 1.001 1 1 1 –
Table 1: Accuracy (AUC) achieved when a contestant’sreal-valued guesses of the test labels are y1 = 0.5, y2 =0.6, y3 = 0.9, y4 = 0.4, shown for each possible ground-truth labeling. Only for one possible labeling (highlighted)do the contestant’s guesses achieve AUC of exactly 0.75.
Attack 1: Deducing Highest/Lowest-RankedLabels with Certainty
In this section we describe how a contestant, whose guessesare already very accurate (AUC close to 1), can orchestratean attack to infer a few of the test set labels with completecertainty. This could be useful for several reasons: (1) Eventhough the attacker’s AUC is close to 1, he/she may notknow the actual test set labels – see Table 1 for an example.If the same test examples were ever re-used in a subsequentcompetition, then knowing their labels could be helpful. (2)Once the attacker knows some of the test labels with cer-tainty, he/she can now use these examples for training. Thiscan be especially beneficial when the test set is drawn froma different population than the training set (e.g., different setof human subjects’ face images (Valstar et al. 2011)). (3) Ifmultiple attackers all score a high AUC but have very dif-ferent sets of guesses, then they could potentially collude toinfer the labels of a large number of test examples.
The attack requires rather strong prior knowledge of theexact number of positive and negative examples in the testset (n1 and n0, respectively).Proposition 1. Let D be a dataset with labels y1, . . . , yn, of
which n0 are negative and n1 are positive. Let y1, . . . , yn be
a contestant’s real-valued guesses for the labels of D such
that yi = yj () i = j. Let c = f(y1:n, y1:n) denote the
AUC achieved by the real-valued guesses with respect to the
ground-truth labels. For any positive integer k n0, if c >1� 1
n1+ k
n0n1, then the first k examples according to the rank
order of y1, . . . , yn must be negatively labeled. Similarly, for
any positive integer k n1, if c > 1� 1n0
+ kn0n1
, then the
last k examples according to the rank order of y1, . . . , ynmust be positively labeled.
Proof. Without loss of generality, suppose that the indicesare arranged such that the yi are sorted, i.e., y1 < . . . < yn.Suppose, by way of contradiction, that m of the first k ex-amples were positively labeled, where 1 m k. For eachsuch possible m, we can find at least m(n0�k) pairs that aremisclassified according to the real-valued guesses by pairingeach of the m positively labeled examples within the indexrange {i : 1 i k} with each of (n0 � k) negatively la-beled examples within the index range {j : k+1 j n}.In each such pair (i, j), yi = 1 and yj = 0, and yet yi < yj ,and thus the pair is misclassified. The minimum number ofmisclassified pairs, over all m in the range {1, . . . , k}, isclearly n0 � k (for m = 1). Since there are n0n1 total pairsin D consisting of one positive and one negative example,and since the AUC is maximized when the number of mis-classified pairs is minimized, then the maximum AUC thatcould be achieved when m � 1 of the first k examples arepositively labeled is
1� n0 � k
n0n1= 1� 1
n1+
k
n0n1
But this is less than c. We must therefore conclude that m =0, i.e., all of the first k examples are negatively labeled.
The proof is exactly analogous for the case when c >1� 1
n0+ k
n0n1.
ExampleSuppose that a contestant’s real-valued guesses y1, . . . , ynachieve an AUC of c = 0.985 on a dataset containing n0 =45 negative and n1 = 55 positive examples, and that n0 andn1 are known to him/her. Then the contestant can concludethat the labels of the first (according to the rank order ofy1, . . . , yn) 7 examples must be negative and the labels ofthe last 17 examples must be positive.
Attack 2: Integration over Satisfying SolutionsThe second attack that we describe treats the AUC reportedby the oracle as an observed random variable in a standardsupervised learning framework. In contrast to Attack 1, noprior knowledge of n0 or n1 is required. Note that the attackwe describe uses only a single oracle query to improve an ex-isting set of real-valued guesses. More sophisticated attacksmight conceivably refine the contestant’s guesses in an itera-tive fashion using multiple queries. Notation: In this sectiononly, capital letters denote random variables and lower-caseletters represent instantiated values.
Consider the graphical model of Fig. 1, which depicts atest set containing n examples where each example i is de-scribed by a vector Xi 2 Rm of m features (e.g., imagepixels). Under the model, each label Yi 2 {0, 1} is gen-erated according to P (Yi = 1 | xi, ✓) = g(xi, ✓), whereg : Rm ⇥ Rm ! [0, 1] could be, for example, the sigmoidfunction of logistic regression and ✓ 2 Rm is the classifierparameter. Note that this is a standard probabilistic discrim-inative model – the only difference is that we have createdan intermediate variable Yi 2 [0, 1] to represent g(xi, ✓) ex-plicitly for each i. Specifically, we define:
P (yi | xi, ✓) = �(yi � g(xi, ✓))
P (Yi = 1 | yi) = yi
y1 = 0.5, y2 = 0.6, y3 = 0.9, y4 = 0.4
For guesses:
The true labels must be:y1 = 1, y2 = 0, y3 = 1, y4 = 0
Contestant can now re-submit and obtain a perfect score in one shot.

Attack 3
• How many different ground-truth vectors are there such that the AUC of the guesses is some fixed number c?
61

Number of satisfying labelings grows exponentially in n for every AUC xxxxx
• For every fixed AUC on a test set of size n=4q, the number of different labelings such that is at least:
62
c 2 (0, 1)
(2� 2|c� 0.5|)n/4y1, . . . , yn f(y1:n, y1:n) = c
c = p/q 2 (0, 1)

Number of satisfying labelings grows exponentially in n for every AUC xxxxx
• For every fixed AUC on a test set of size n=4q, the number of different labelings such that is at least:
• What about for n ≠ 4q?
• Open question: Might there be some pathological combination of p, q, n0, n1 (for non-trivial n) such that the number of satisfying labelings is small?
63
c 2 (0, 1)
(2� 2|c� 0.5|)n/4y1, . . . , yn f(y1:n, y1:n) = c
c = p/q 2 (0, 1)

Conclusions• Given that Ladder is rarely implemented, ML practitioners
(and job recruiters) should be aware of the danger of log-loss attacks in data-mining competitions.
• The AUC admits fundamentally different attacks from log-loss:
• Log-loss: decomposes across single examples.
• AUC: decomposes across pairs (one +, one -) of examples.
• Greater goal of this work is to raise awareness of the potential for cheating in machine learning contests.
64

Thank you
65