cloud resiliency - iaas
TRANSCRIPT

© 2009 IBM Corporation
Cloud Resiliency
Dr. Thomas Lumpp, IBM Deutschland Research & Development GmbH

© 2010 IBM Corporation2
Disclaimer
This document represents the author's views and opinions.
It does not necessarily represent IBM's position or strategy.

© 2010 IBM Corporation3
Contributor to this presentation
Gerd Breiter, Distinguished Engineer, Cloud Architecture
Juergen Schneider, Distinguished Engineer, TSAM Architecture
Bernd Jostmeyer, Lead Developer System Automation Application Manager
Isabell Schwertle, System Automation Development
Dominik Brugger, Content Security Engineering

© 2010 IBM Corporation4
Agenda
Part I: Introduction
Introduction Resiliency for the Cloud
Resiliency: Availability, High Availability, and Disaster Recovery
Recovery Time Objective and Recovery Point Objective
Part II: Cloud Resiliency
High Availability of the Common Cloud Management Platform
Excursus on “High Availability Nomenclature and Classification”
Stateless Applications, Stateful Application types (Warm-Standby, Hot-Standby, Active-Active)
High Availability of the Virtualized Infrastructure and Cloud Services
© 2010 IBM Corporation
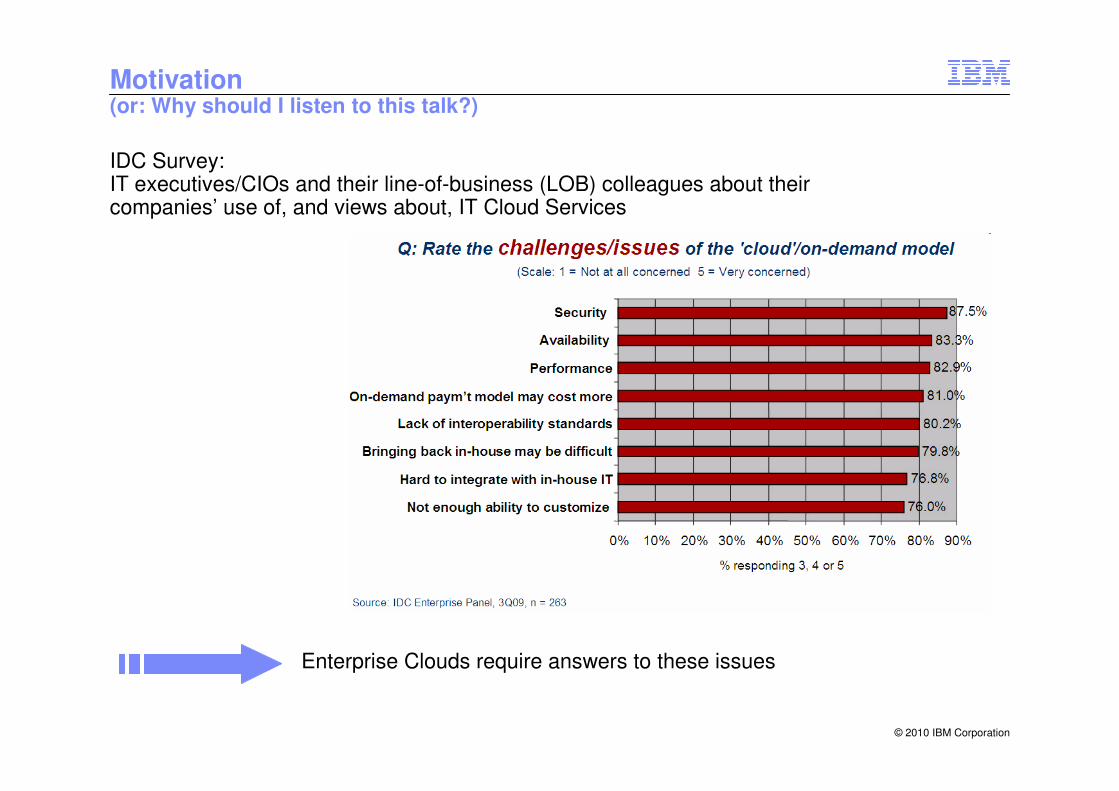
Motivation(or: Why should I listen to this talk?)
IDC Survey:IT executives/CIOs and their line-of-business (LOB) colleagues about their companies’ use of, and views about, IT Cloud Services
Enterprise Clouds require answers to these issues
© 2010 IBM Corporation
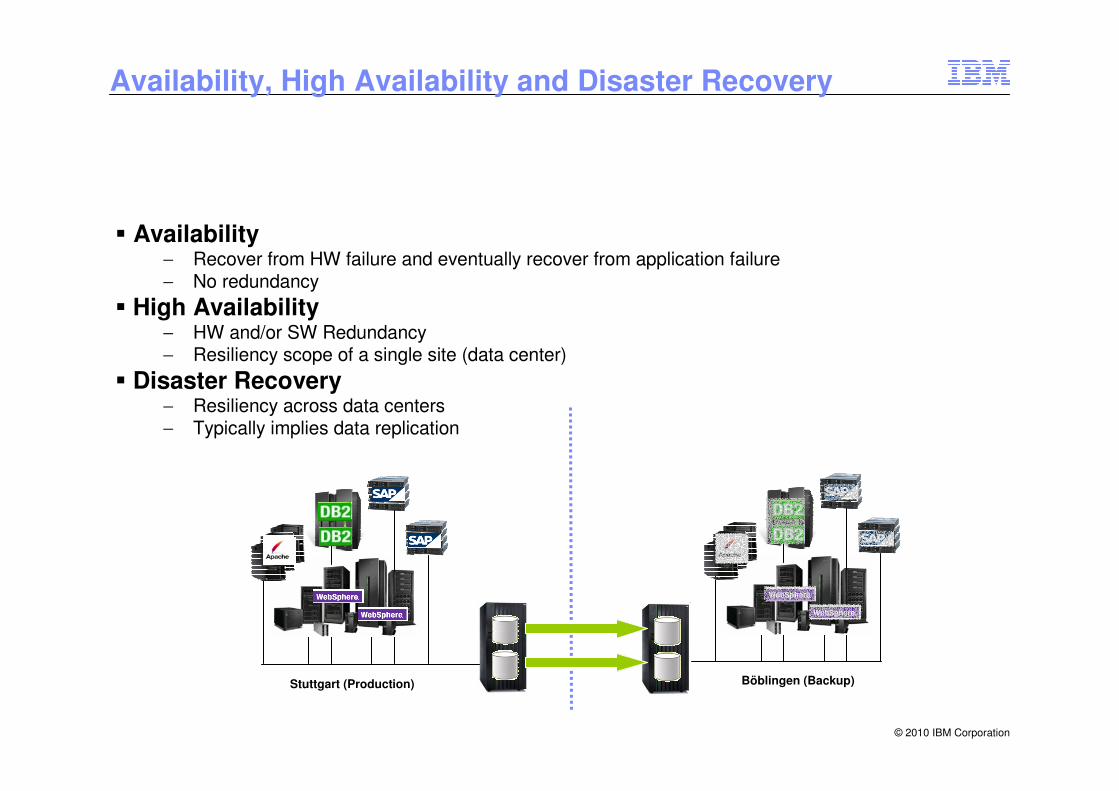
Availability, High Availability and Disaster Recovery
Stuttgart (Production) Böblingen (Backup)
� Availability − Recover from HW failure and eventually recover from application failure− No redundancy
� High Availability− HW and/or SW Redundancy− Resiliency scope of a single site (data center)
� Disaster Recovery− Resiliency across data centers− Typically implies data replication
© 2010 IBM Corporation
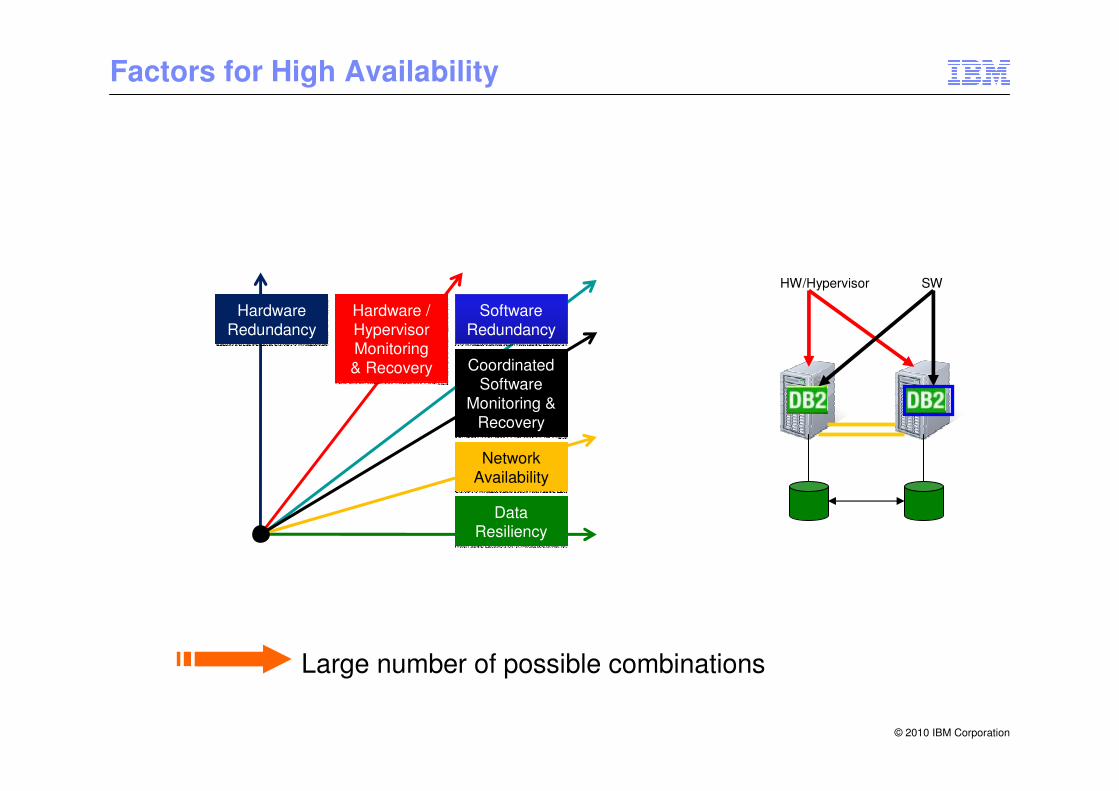
Factors for High Availability
Software Redundancy
Software Redundancy
Hardware Redundancy
Hardware Redundancy
Hardware / Hypervisor Monitoring& Recovery
Hardware / Hypervisor Monitoring& Recovery
Data Resiliency
Data Resiliency
Network Availability
Network Availability
Coordinated Software
Monitoring & Recovery
Coordinated Software
Monitoring & Recovery
Large number of possible combinations
HW/Hypervisor SW

© 2010 IBM Corporation
Business Relevance of Availability
� Commerce is handled over the internet and computing centers are growing
� At the same time businesses need to ensure that their systems are available 24/7
� Downtime can be directly translated into loss of revenue
� Average cost of 1 hour downtime: 42.000$
� Popular examples are Amazon, Google and Ebay
� Usual customers also include Banks, Insurance Providers and Computing Centers
5.26 minutes99,999%
31.5 seconds99.9999%
52.6 minutes99.99%
8.76 hours99.9%
3.65 days99%
18.25 days95%
36.5 days90%
Downtime per yearAvailability
© 2010 IBM Corporation
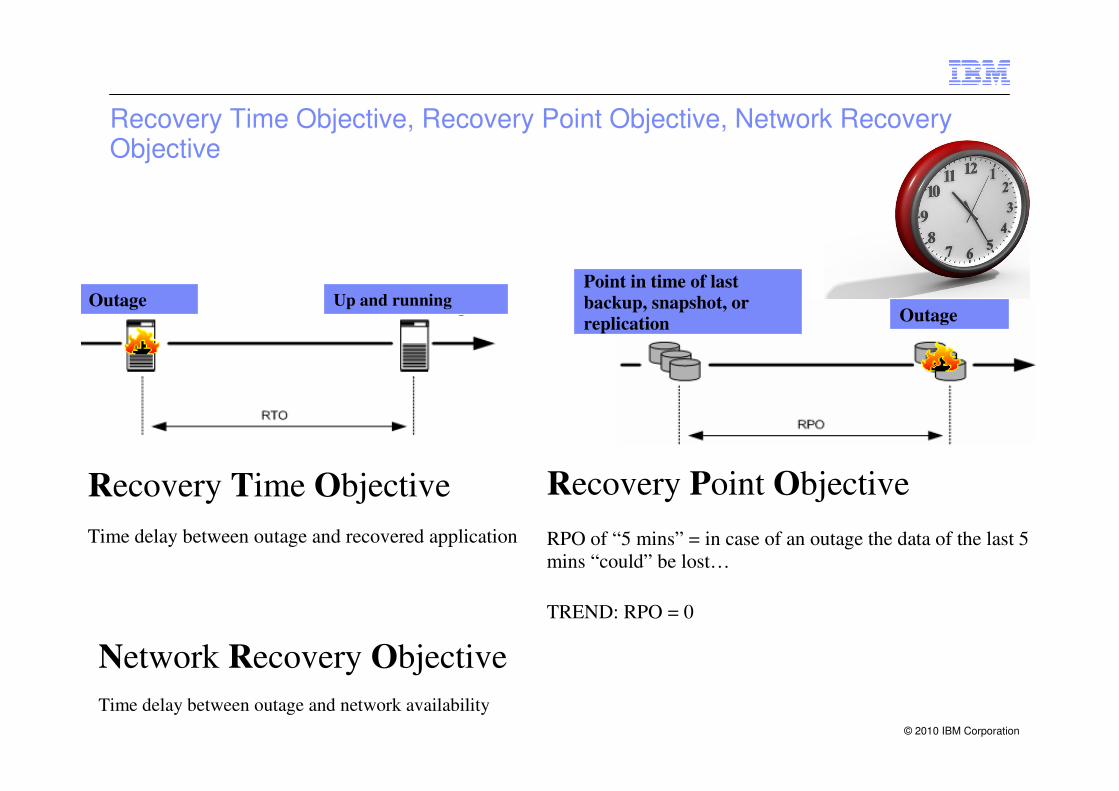
Recovery Time Objective, Recovery Point Objective, Network Recovery Objective
Recovery Time Objective
Time delay between outage and recovered application
Outage Up and runningOutage
Point in time of last
backup, snapshot, or
replication
Recovery Point Objective
RPO of “5 mins” = in case of an outage the data of the last 5
mins “could” be lost…
TREND: RPO = 0
Network Recovery Objective
Time delay between outage and network availability

© 2009 IBM Corporation
Part II: Cloud Resiliency
© 2009 IBM Corporation11
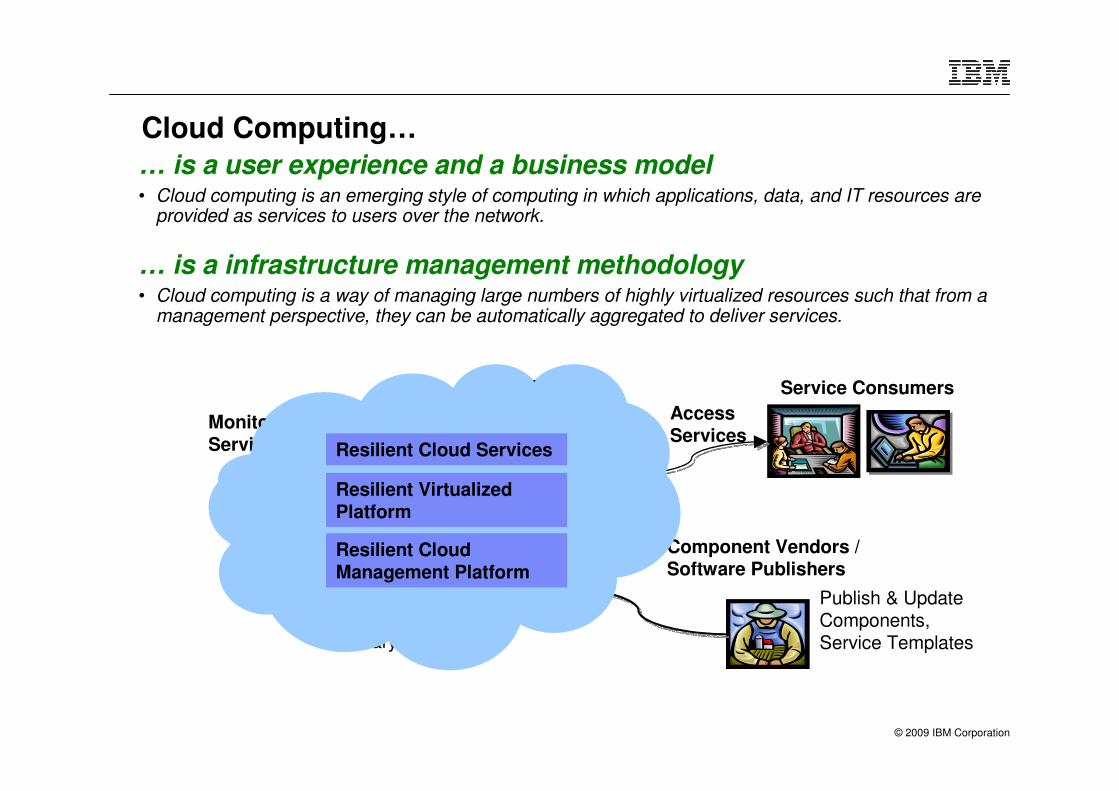
Cloud Computing…
… is a user experience and a business model• Cloud computing is an emerging style of computing in which applications, data, and IT resources are
provided as services to users over the network.
… is a infrastructure management methodology• Cloud computing is a way of managing large numbers of highly virtualized resources such that from a
management perspective, they can be automatically aggregated to deliver services.
Service Consumers
Service Catalog,ComponentLibrary
CloudAdministrator
DatacenterInfrastructure
Monitor & ManageServices & Resources
Component Vendors /Software Publishers
Publish & UpdateComponents,Service Templates
AccessServices
IT CloudResilient Cloud Management Platform
Resilient Virtualized Platform
Resilient Cloud Services
© 2010 IBM Corporation12
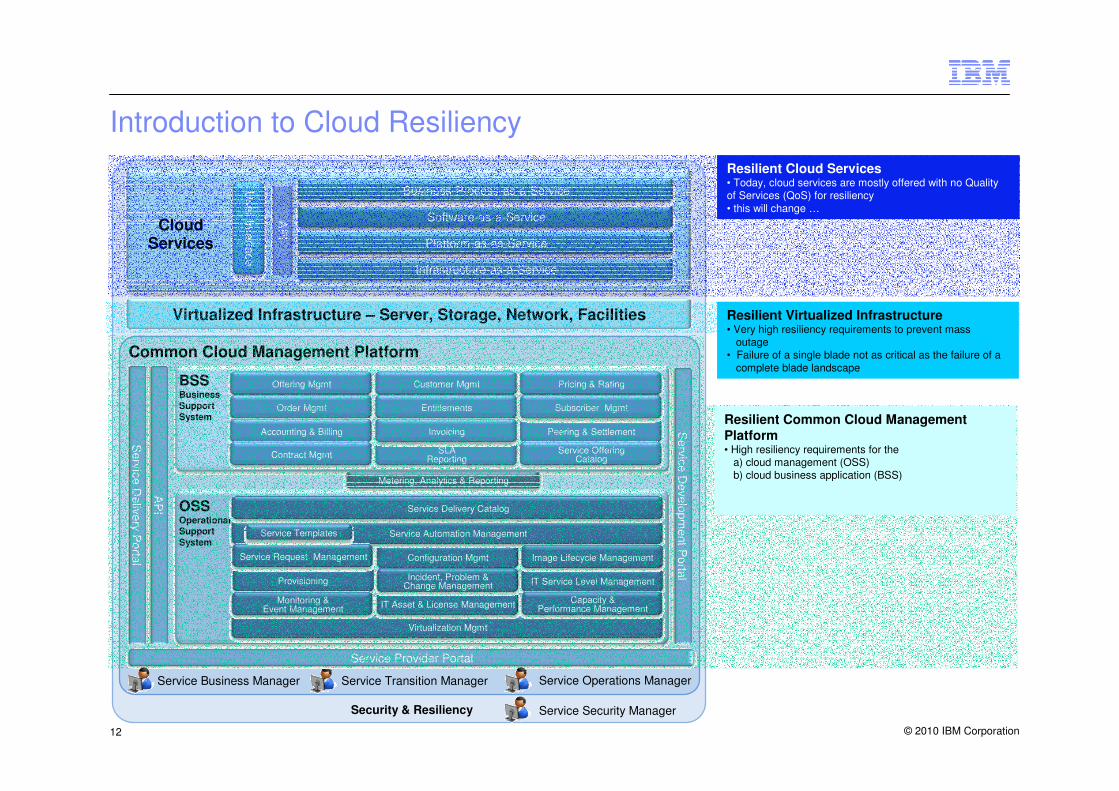
Introduction to Cloud Resiliency
Common Cloud Management Platform
Virtualized Infrastructure – Server, Storage, Network, Facilities
Service Business Manager Service Operations Manager
Cloud Services
Use
r Inte
rface
AP
I
Software-as-a-Service
Platform-as-as-Service
Infrastructure-as-a-Service
Business-Process-as-a-Service
Metering, Analytics & Reporting
Service Provider Portal
Configuration Mgmt
Offering Mgmt
Order Mgmt
Accounting & Billing
Customer Mgmt
Entitlements
Contract Mgmt SLAReporting
Pricing & Rating
Peering & Settlement
Subscriber Mgmt
Service OfferingCatalog
Invoicing
Service Automation Management
Virtualization Mgmt
Provisioning
Monitoring &Event Management
IT Asset & License Management
Service Request Management
IT Service Level Management
Image Lifecycle Management
Capacity &Performance Management
Incident, Problem &Change Management
BSSBusiness
Support
System
Se
rvice
De
velo
pm
ent P
orta
l
AP
I
Se
rvice
Delive
ry Po
rtal
OSSOperationalSupport
System
Service Transition Manager
Service Security Manager Security & Resiliency
Service Delivery Catalog
Service Templates
Resilient Virtualized Infrastructure• Very high resiliency requirements to prevent mass
outage• Failure of a single blade not as critical as the failure of a
complete blade landscape
Resilient Cloud Services• Today, cloud services are mostly offered with no Quality of Services (QoS) for resiliency• this will change …
Resilient Common Cloud Management
Platform• High resiliency requirements for the
a) cloud management (OSS) b) cloud business application (BSS)
© 2010 IBM Corporation13
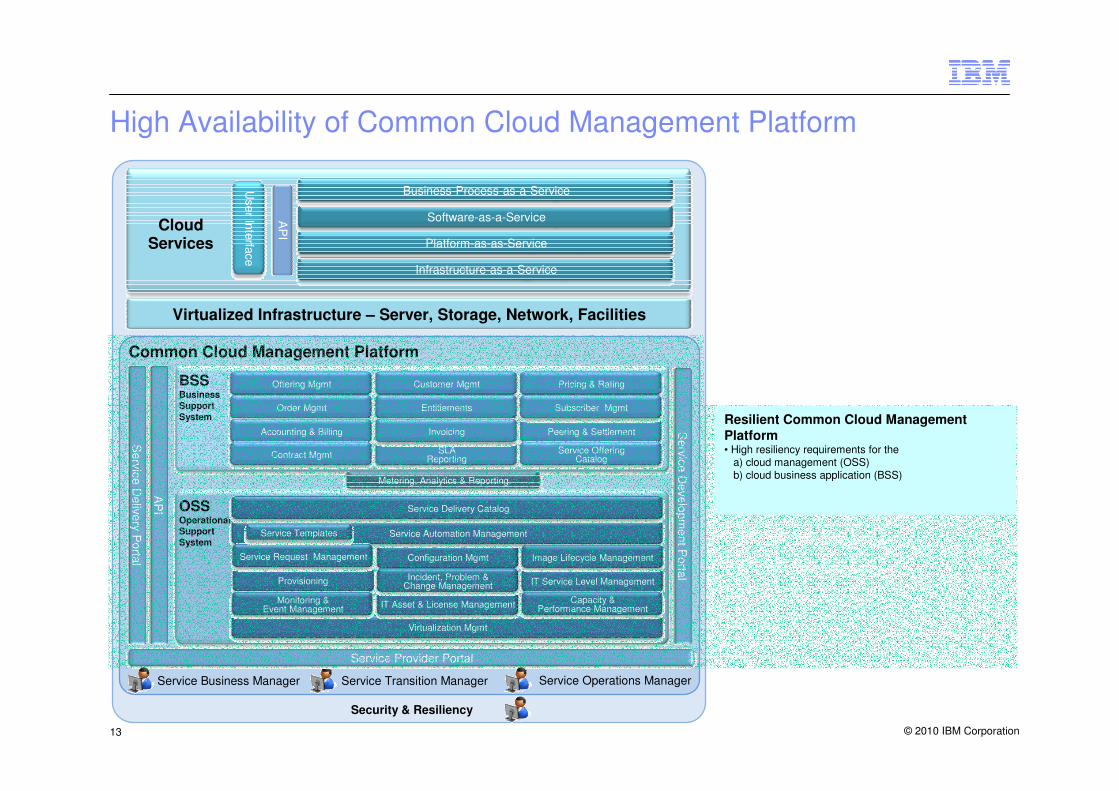
High Availability of Common Cloud Management Platform
Common Cloud Management Platform
Virtualized Infrastructure – Server, Storage, Network, Facilities
Service Business Manager Service Operations Manager
Cloud Services
Use
r Inte
rface
AP
I
Software-as-a-Service
Platform-as-as-Service
Infrastructure-as-a-Service
Business-Process-as-a-Service
Metering, Analytics & Reporting
Service Provider Portal
Configuration Mgmt
Offering Mgmt
Order Mgmt
Accounting & Billing
Customer Mgmt
Entitlements
Contract Mgmt SLAReporting
Pricing & Rating
Peering & Settlement
Subscriber Mgmt
Service OfferingCatalog
Invoicing
Service Automation Management
Virtualization Mgmt
Provisioning
Monitoring &Event Management
IT Asset & License Management
Service Request Management
IT Service Level Management
Image Lifecycle Management
Capacity &Performance Management
Incident, Problem &Change Management
BSSBusiness
Support
System
Se
rvice
De
velo
pm
ent P
orta
l
AP
I
Se
rvice
Delive
ry Po
rtal
OSSOperationalSupport
System
Service Transition Manager
Security & Resiliency
Service Delivery Catalog
Service Templates
Resilient Common Cloud Management
Platform• High resiliency requirements for the
a) cloud management (OSS) b) cloud business application (BSS)
© 2010 IBM Corporation14
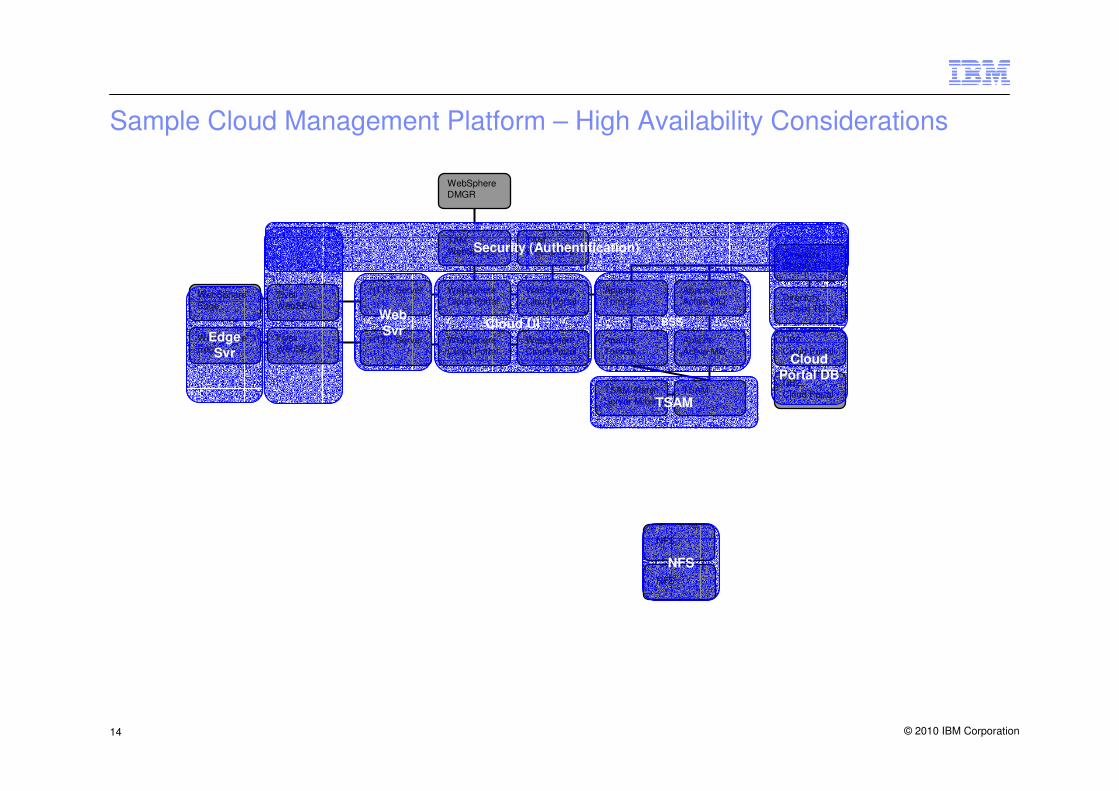
Sample Cloud Management Platform – High Availability Considerations
WebSphere Edge
WebSphere Edge
TivoliWebSEAL
TivoliWebSEAL
HTTP Server
HTTP Server
WebSphereDMGR
Tivoli AccessManager (TAM)
WebSphereCloud Portal
WebSphereCloud Portal
WebSphereCloud Portal
WebSphereCloud Portal
TAMWebSphere
Apache Tomcat
Apache Tomcat
Apache Active MQ
Apache Active MQ
TSAM
Directory Server TDS
Directory Server TDS
DB2 Cloud Portal
DB2Cloud Portal
TAMWebSphere
TSAM AdminServer Maximo
NFS
NFS
Cloud UI BSS
TSAM
Cloud
Portal DB
NFS
Edge
Svr
Web
Svr
Security (Authentification)

© 2010 IBM Corporation
Excursus: Application types
� High availability for applications is highly dependant on the application type
� Two general distinctions:– Stateless Application
means there is no record of previous interactions and each interaction request has to be handled based entirely on information that comes with it. Example: WebServer with static Web Page Serving
– HA Impact: Can be started without “reloading” any state
– Stateful Applicationmeans the computer or program keeps track of the state of interaction, usually by setting values in a storage field designated for that purpose.Stateful applications should implement transactional behaviour and need to maintain a state to be recoverable without loosing significant value
– Example: Databases (ongoing transaction is a state), MQSeries
– HA Impact: Cannot be restarted without knowledge of the previous state (from an application point of view)
–
© 2010 IBM Corporation16
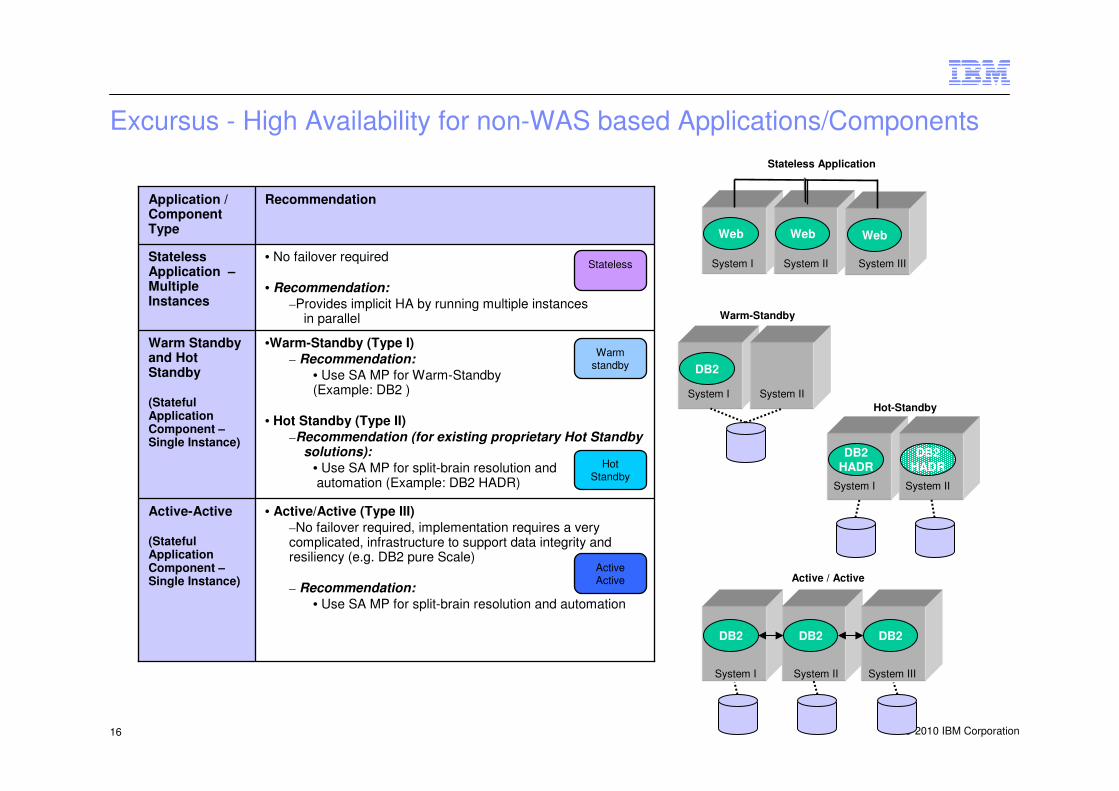
Excursus - High Availability for non-WAS based Applications/Components
•Warm-Standby (Type I)
– Recommendation:
• Use SA MP for Warm-Standby (Example: DB2 )
• Hot Standby (Type II)
–Recommendation (for existing proprietary Hot Standbysolutions):
• Use SA MP for split-brain resolution andautomation (Example: DB2 HADR)
Warm Standby and Hot Standby
(StatefulApplication Component –Single Instance)
• No failover required
• Recommendation:
–Provides implicit HA by running multiple instancesin parallel
Stateless Application –Multiple Instances
• Active/Active (Type III)
–No failover required, implementation requires a very complicated, infrastructure to support data integrity and resiliency (e.g. DB2 pure Scale)
– Recommendation:
• Use SA MP for split-brain resolution and automation
Active-Active
(StatefulApplication Component –Single Instance)
RecommendationApplication / Component Type
Stateless
Warmstandby
HotStandby
ActiveActive
Web Web Web
System I System II System III
DB2
Warm-Standby
DB2HADR
DB2HADR
Hot-Standby
System IISystem I
System I System II
DB2 DB2 DB2
Active / Active
System I System II System III
Stateless Application
© 2010 IBM Corporation17
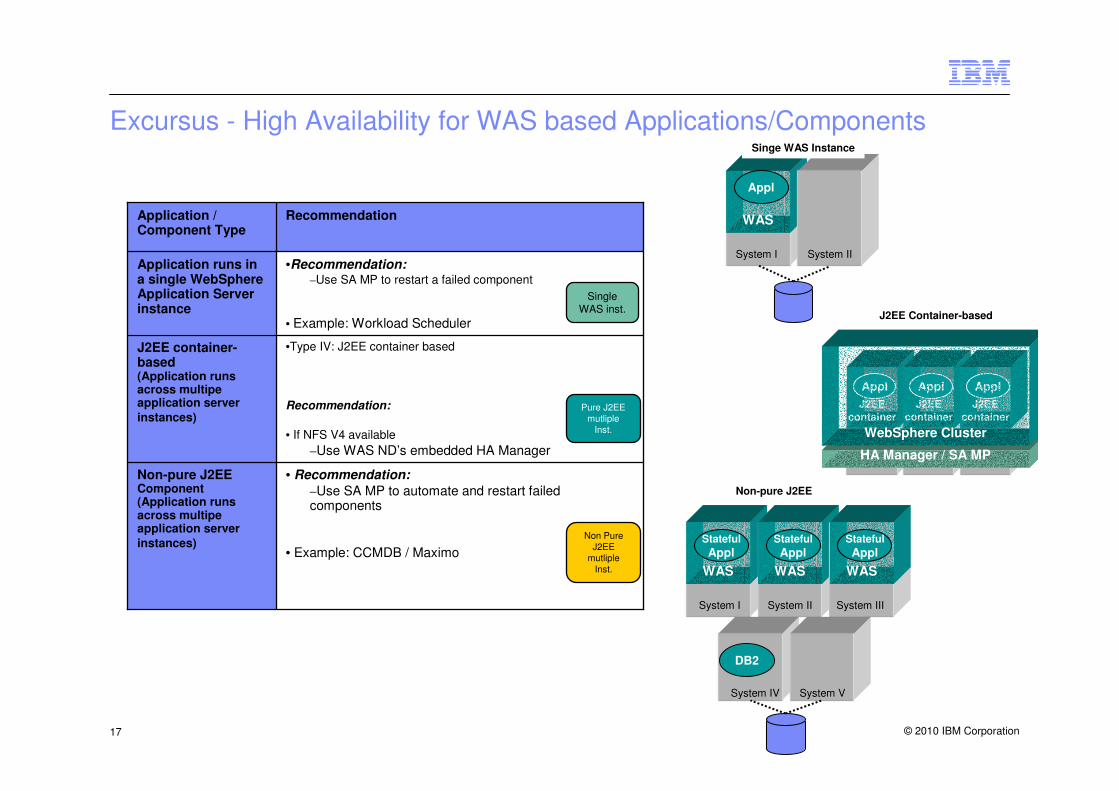
Excursus - High Availability for WAS based Applications/Components
•Type IV: J2EE container based
Recommendation:
• If NFS V4 available
–Use WAS ND’s embedded HA Manager
J2EE container-based(Application runs across multipe application server
instances)
•Recommendation:–Use SA MP to restart a failed component
• Example: Workload Scheduler
Application runs in a single WebSphere Application Server instance
• Recommendation:
–Use SA MP to automate and restart failed components
• Example: CCMDB / Maximo
Non-pure J2EE Component (Application runs across multipe application server
instances)
RecommendationApplication / Component Type
Single WAS inst.
Pure J2EE mutliple
Inst.
Non Pure J2EE
mutliple Inst.
WAS
Appl
J2EEcontainer
Appl
J2EEcontainer
Appl
J2EEcontainer
Appl
HA Manager / SA MP
WebSphere Cluster
WAS
Stateful
Appl
WAS
Stateful
Appl
WAS
Stateful
Appl
DB2
System IISystem I
System I System II System III
System IV System V
Singe WAS Instance
J2EE Container-based
Non-pure J2EE
© 2010 IBM Corporation
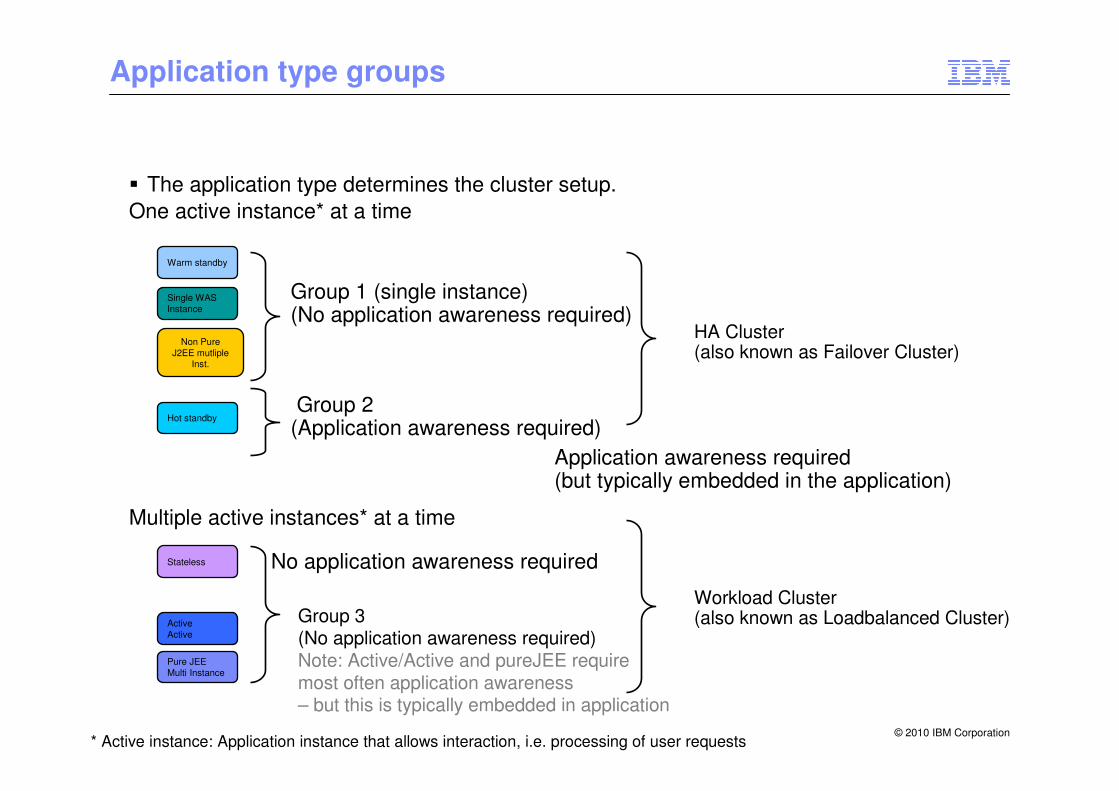
Application type groups
� The application type determines the cluster setup.
Pure JEE Multi Instance
Single WAS Instance
Stateless
Warm standby
Hot standby
ActiveActive
Group 1 (single instance) (No application awareness required)
* Active instance: Application instance that allows interaction, i.e. processing of user requests
Group 2 (Application awareness required)
No application awareness required
One active instance* at a time
Multiple active instances* at a time
Application awareness required (but typically embedded in the application)
Non Pure J2EE mutliple
Inst.
HA Cluster (also known as Failover Cluster)
Workload Cluster (also known as Loadbalanced Cluster)Group 3
(No application awareness required)Note: Active/Active and pureJEE requiremost often application awareness – but this is typically embedded in application
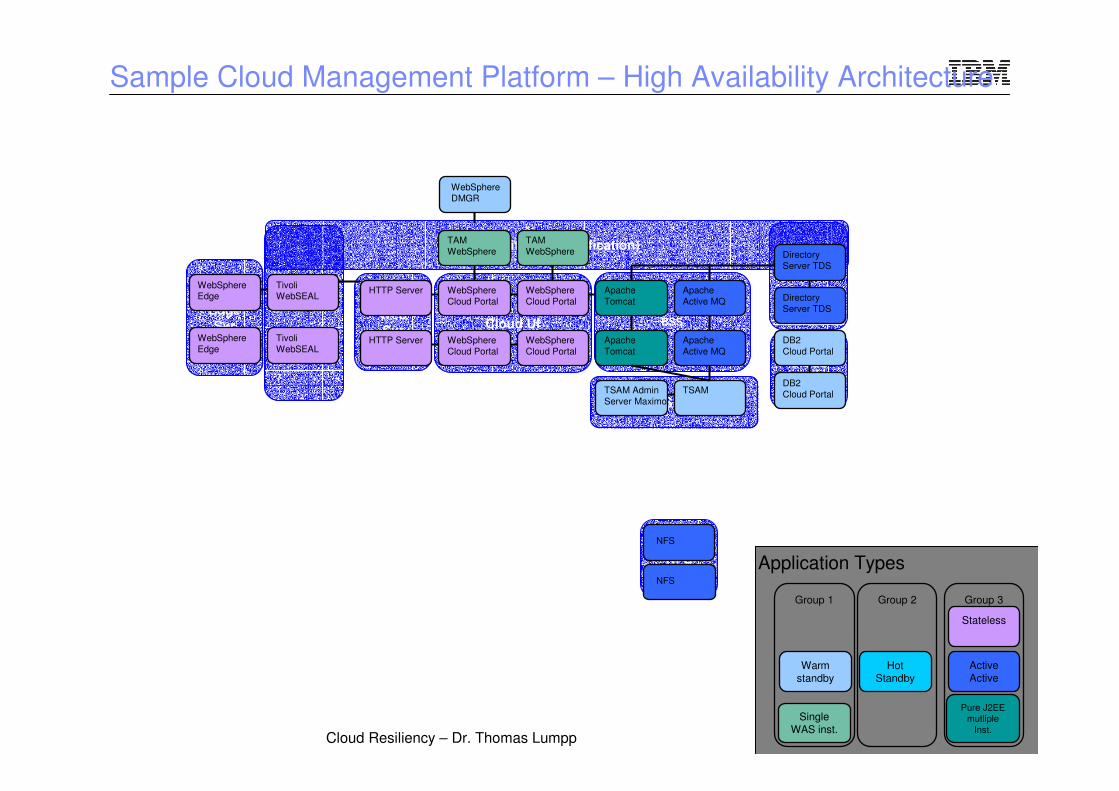
© 2009 IBM CorporationCloud Resiliency – Dr. Thomas Lumpp
BSS
NFS
Cloud
Portal DB
Cloud UI
TSAM
Security (Authentification)
Web
Svr
Edge
Svr
Sample Cloud Management Platform – High Availability Architecture
WebSphere Edge
WebSphere Edge
TivoliWebSEAL
TivoliWebSEAL
HTTP Server
HTTP Server
Tivoli AccessManager (TAM)
WebSphereCloud Portal
WebSphereCloud Portal
WebSphereCloud Portal
WebSphereCloud Portal
TAMWebSphere
Apache Tomcat
Apache Tomcat
Apache Active MQ
Apache Active MQ
TSAM
Directory Server TDS
Directory Server TDS
DB2Cloud Portal
DB2Cloud Portal
TAMWebSphere
TSAM AdminServer Maximo
NFS
NFS
WebSphereDMGR
Warmstandby
Stateless
HotStandby
Single WAS inst.
Pure J2EE mutliple
Inst.
ActiveActive
Application Types
Group 1 Group 2 Group 3
© 2009 IBM CorporationCloud Resiliency – Dr. Thomas Lumpp20
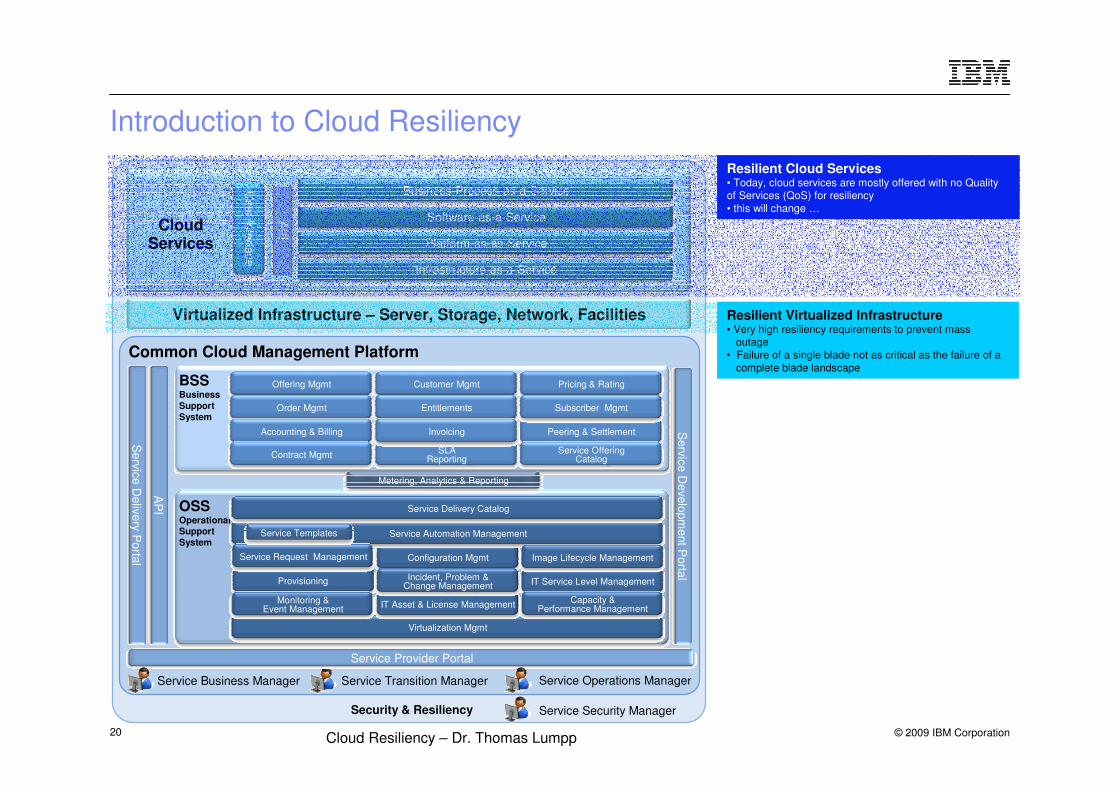
Introduction to Cloud Resiliency
Common Cloud Management Platform
Virtualized Infrastructure – Server, Storage, Network, Facilities
Service Business Manager Service Operations Manager
Cloud Services
Use
r Inte
rface
AP
I
Software-as-a-Service
Platform-as-as-Service
Infrastructure-as-a-Service
Business-Process-as-a-Service
Metering, Analytics & Reporting
Service Provider Portal
Configuration Mgmt
Offering Mgmt
Order Mgmt
Accounting & Billing
Customer Mgmt
Entitlements
Contract Mgmt SLAReporting
Pricing & Rating
Peering & Settlement
Subscriber Mgmt
Service OfferingCatalog
Invoicing
Service Automation Management
Virtualization Mgmt
Provisioning
Monitoring &Event Management
IT Asset & License Management
Service Request Management
IT Service Level Management
Image Lifecycle Management
Capacity &Performance Management
Incident, Problem &Change Management
BSSBusiness
Support
System
Se
rvice
De
velo
pm
ent P
orta
l
AP
I
Se
rvice
Delive
ry Po
rtal
OSSOperationalSupport
System
Service Transition Manager
Service Security Manager Security & Resiliency
Service Delivery Catalog
Service Templates
Resilient Virtualized Infrastructure• Very high resiliency requirements to prevent mass
outage• Failure of a single blade not as critical as the failure of a
complete blade landscape
Resilient Cloud Services• Today, cloud services are mostly offered with no Quality of Services (QoS) for resiliency• this will change …

© 2010 IBM Corporation
Resilient Cloud Services: Relevance for the Cloud
� Status Quo:– Cloud Services are cheap, but not reliable*
� Trend– Customers starting to move from pure development/test cloud usage to production
usage– As soon as business critical workload will be moved to the cloud, demand for robust,
resilient and highly available cloud services will increase
� * Reliability is influenced by various parts, see later

© 2010 IBM Corporation22
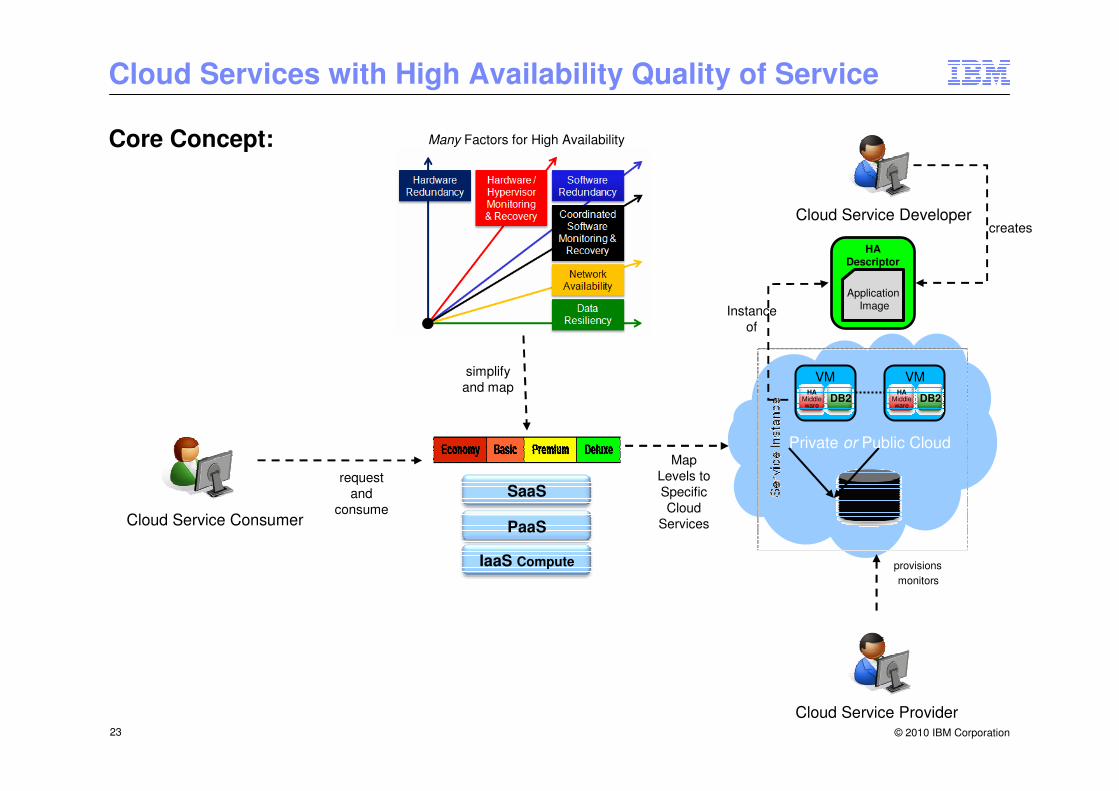
Cloud Services with High Availability QoS
Idea:
• Service provider offers cloud services with simplified High Availability QoSs (e.g. Basic, Premium, Deluxe)
• Customer does not necessarily need to understand the technical details
Criterias of QoS for Cloud Service High Availability
• Detection and recovery from HW, hypervisor, or OS failure by ...– restarting OS image or – failover OS image to another running hypervisor
• Detection and recovery from application failure
• Introduce Redundancy (HW/SW) according to requested High Availability QoS (gold, ...)– E.g. select appropriate application type (warm standby, hot standby, active-active, ...)
• (note: data is not in scope)
© 2010 IBM Corporation
Cloud Services with High Availability Quality of Service
Cloud Service Consumer
request and
consume
SaaS
PaaS
IaaS Compute
simplify and map
23
Many Factors for High Availability
Private or Public Cloud
VM
DB2HA
Middleware
VM
DB2HA
Middleware
Core Concept:
Map Levels to Specific Cloud
Services
provisions
monitors
Cloud Service Provider
Cloud Service Developer
HA Descriptor
ApplicationImageInstance
of
creates
© 2010 IBM Corporation24
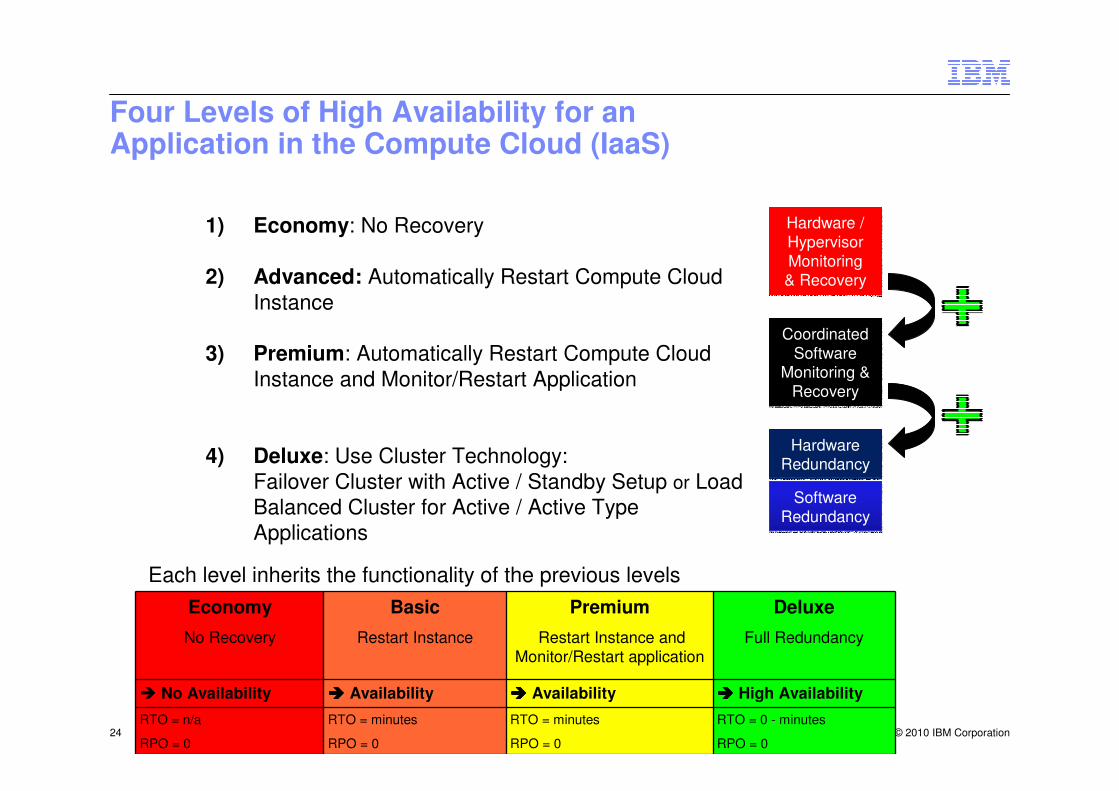
Four Levels of High Availability for anApplication in the Compute Cloud (IaaS)
1) Economy: No Recovery
2) Advanced: Automatically Restart Compute Cloud Instance
3) Premium: Automatically Restart Compute Cloud Instance and Monitor/Restart Application
4) Deluxe: Use Cluster Technology:Failover Cluster with Active / Standby Setup or Load Balanced Cluster for Active / Active Type Applications
Hardware / Hypervisor Monitoring& Recovery
Hardware / Hypervisor Monitoring& Recovery
Coordinated Software
Monitoring & Recovery
Coordinated Software
Monitoring & Recovery
Software Redundancy
Software Redundancy
Hardware Redundancy
Hardware Redundancy
Economy
No Recovery
Basic
Restart Instance
Premium
Restart Instance and Monitor/Restart application
Deluxe
Full Redundancy
� No Availability ���� Availability ���� Availability ���� High Availability
RTO = n/a
RPO = 0
RTO = minutes
RPO = 0
RTO = minutes
RPO = 0
RTO = 0 - minutes
RPO = 0
Each level inherits the functionality of the previous levels
© 2010 IBM Corporation
VM1
A1
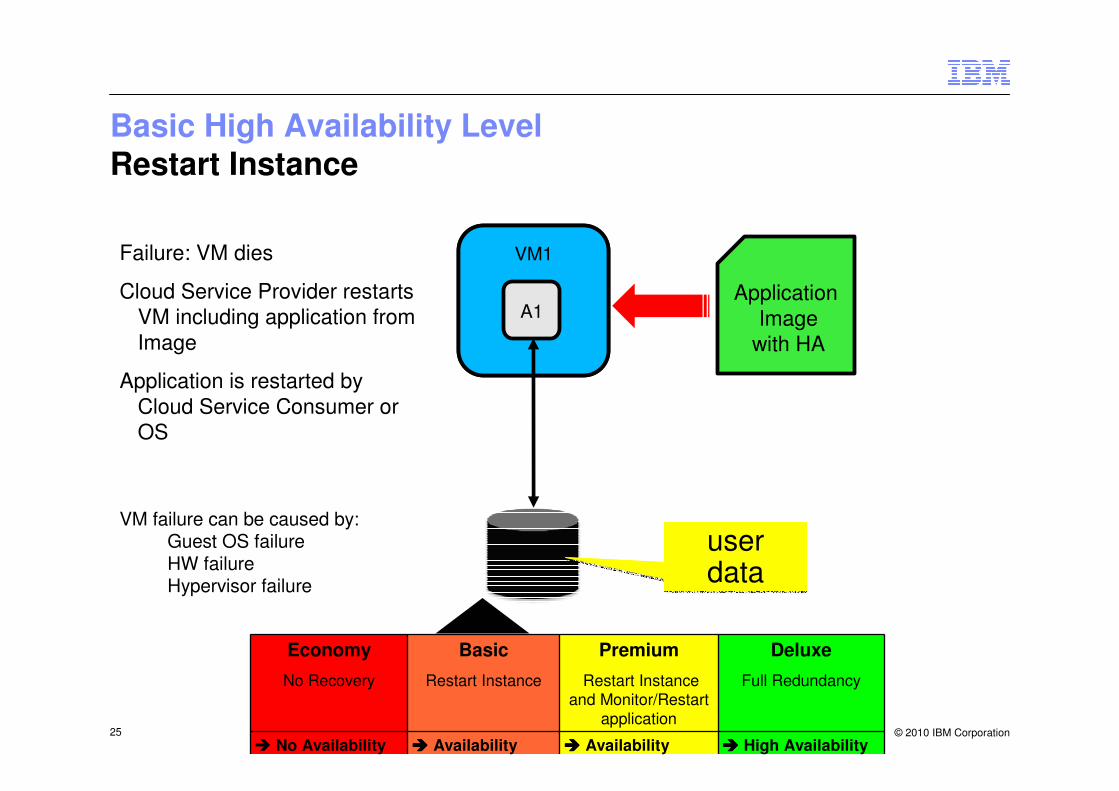
Basic High Availability LevelRestart Instance
VM1
A1Application
Imagewith HA
Failure: VM dies
Cloud Service Provider restarts VM including application from Image
Application is restarted by Cloud Service Consumer or OS
user datauser data
25
Economy
No Recovery
Basic
Restart Instance
Premium
Restart Instance and Monitor/Restart
application
Deluxe
Full Redundancy
� No Availability ���� Availability ���� Availability ���� High Availability
VM failure can be caused by:Guest OS failureHW failureHypervisor failure
© 2010 IBM Corporation
VM1
A1
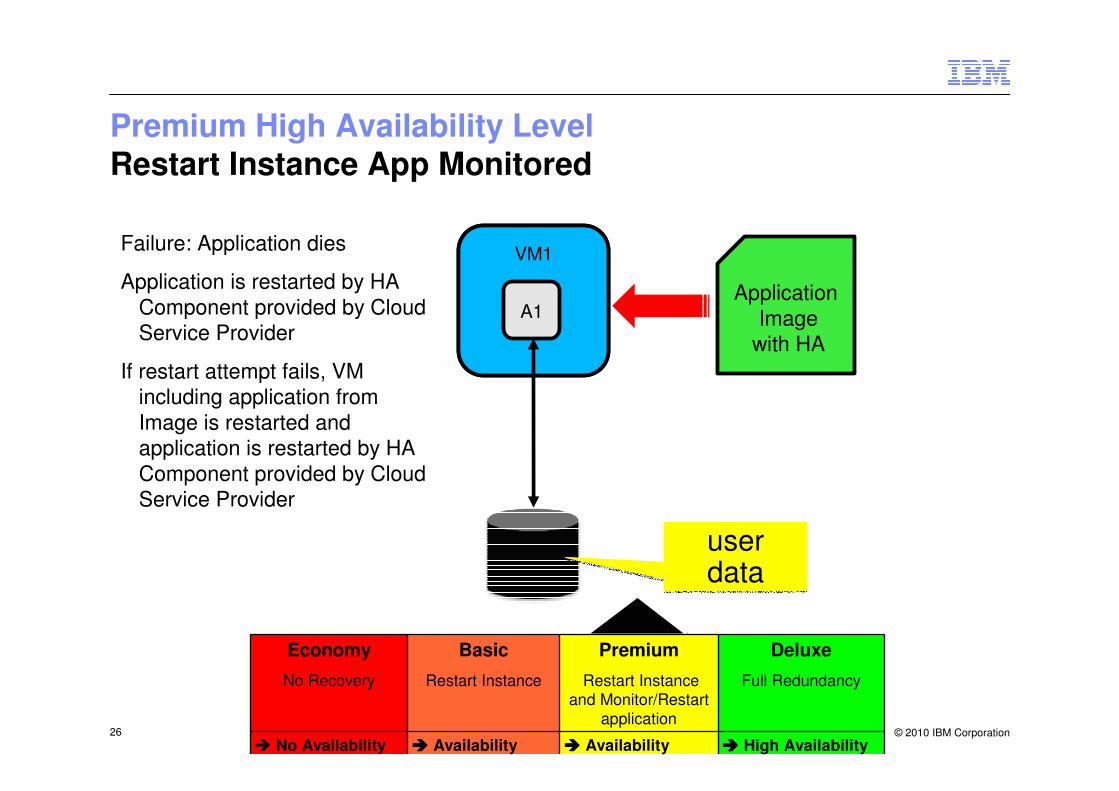
Premium High Availability LevelRestart Instance App Monitored
VM1
A1Application
Imagewith HA
Failure: Application dies
Application is restarted by HA Component provided by Cloud Service Provider
If restart attempt fails, VM including application from Image is restarted and application is restarted by HA Component provided by Cloud Service Provider
user datauser data
26
Economy
No Recovery
Basic
Restart Instance
Premium
Restart Instance and Monitor/Restart
application
Deluxe
Full Redundancy
� No Availability ���� Availability ���� Availability ���� High Availability

© 2010 IBM Corporation
Deluxe High Availability LevelUse Cluster Technology
27
Remember: Application type determines cluster type.
� Use either HA cluster or workload cluster
There must be a description of the required workflows of the cluster setup depending on the application type:
Economy
No Recovery
Basic
Restart Instance
Premium
Restart Instance and Monitor/Restart
application
Deluxe
Full Redundancy
� No Availability ���� Availability ���� Availability ���� High Availability
© 2010 IBM Corporation
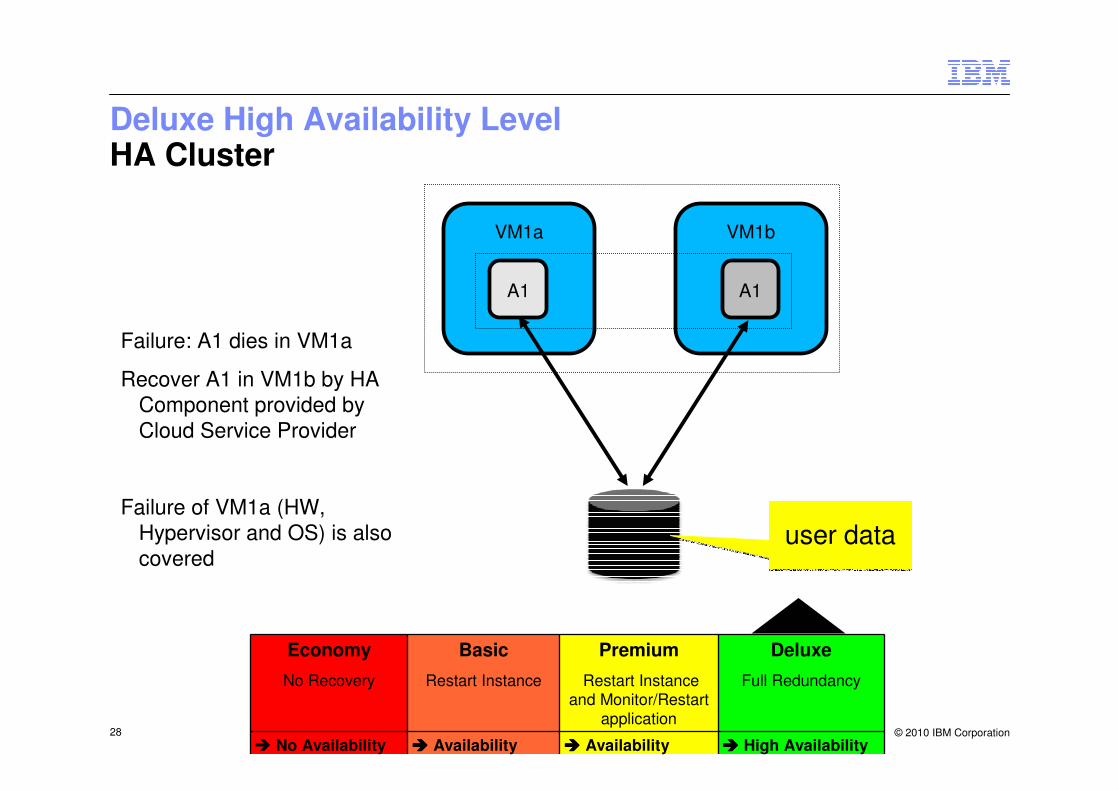
VM1a
A1
VM1b
A1
Failure: A1 dies in VM1a
Recover A1 in VM1b by HA Component provided by Cloud Service Provider
Failure of VM1a (HW, Hypervisor and OS) is also covered
user datauser data
28
Deluxe High Availability LevelHA Cluster
Economy
No Recovery
Basic
Restart Instance
Premium
Restart Instance and Monitor/Restart
application
Deluxe
Full Redundancy
� No Availability ���� Availability ���� Availability ���� High Availability

© 2010 IBM Corporation29
■ The concept of load balancing and scaling can be leveraged to provide High Availability.
■ For High Availability, nodes need to be distributed across independent hardware resources
■ Different levels of High Availability can be achieved by using different thresholds of service utilization that trigger scale out (or scale in respectively).
■ To achieve Deluxe level, a large enough number of spare instances need to be provided at any time (e.g. factor 2).
Deluxe High Availability LevelWorkload Cluster
EconomyNo Recovery
BasicRestart Instance
PremiumRestart Instance and
Monitor/Restart application
DeluxeFull Redundancy
� No Availability ���� Availability ���� Availability ���� High Availability
© 2010 IBM Corporation
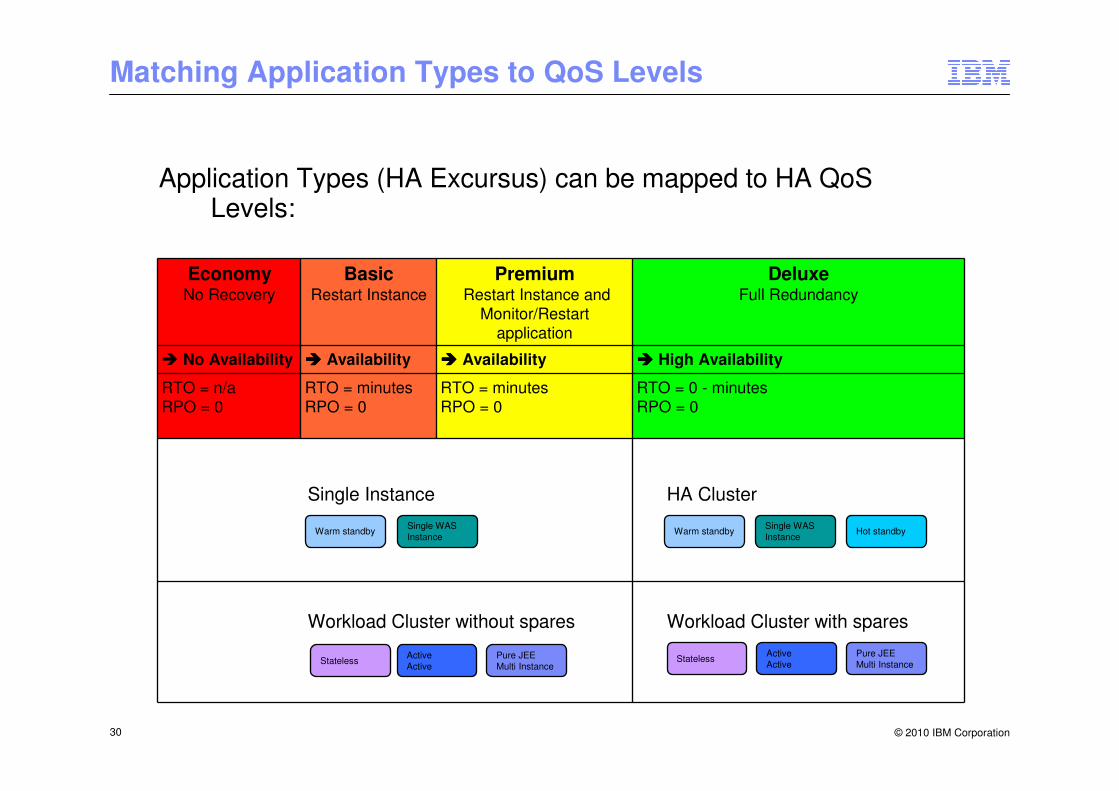
Matching Application Types to QoS Levels
Application Types (HA Excursus) can be mapped to HA QoSLevels:
EconomyNo Recovery
BasicRestart Instance
PremiumRestart Instance and
Monitor/Restart application
DeluxeFull Redundancy
� No Availability ���� Availability ���� Availability ���� High Availability
RTO = n/aRPO = 0
RTO = minutesRPO = 0
RTO = minutesRPO = 0
RTO = 0 - minutesRPO = 0
30
Stateless
Single WAS Instance
Warm standby
Active Active
Pure JEE Multi Instance
Single Instance
Workload Cluster without spares
Hot standbyWarm standbySingle WAS Instance
HA Cluster
Pure JEE Multi Instance
Workload Cluster with spares
Active ActiveStateless
© 2010 IBM Corporation
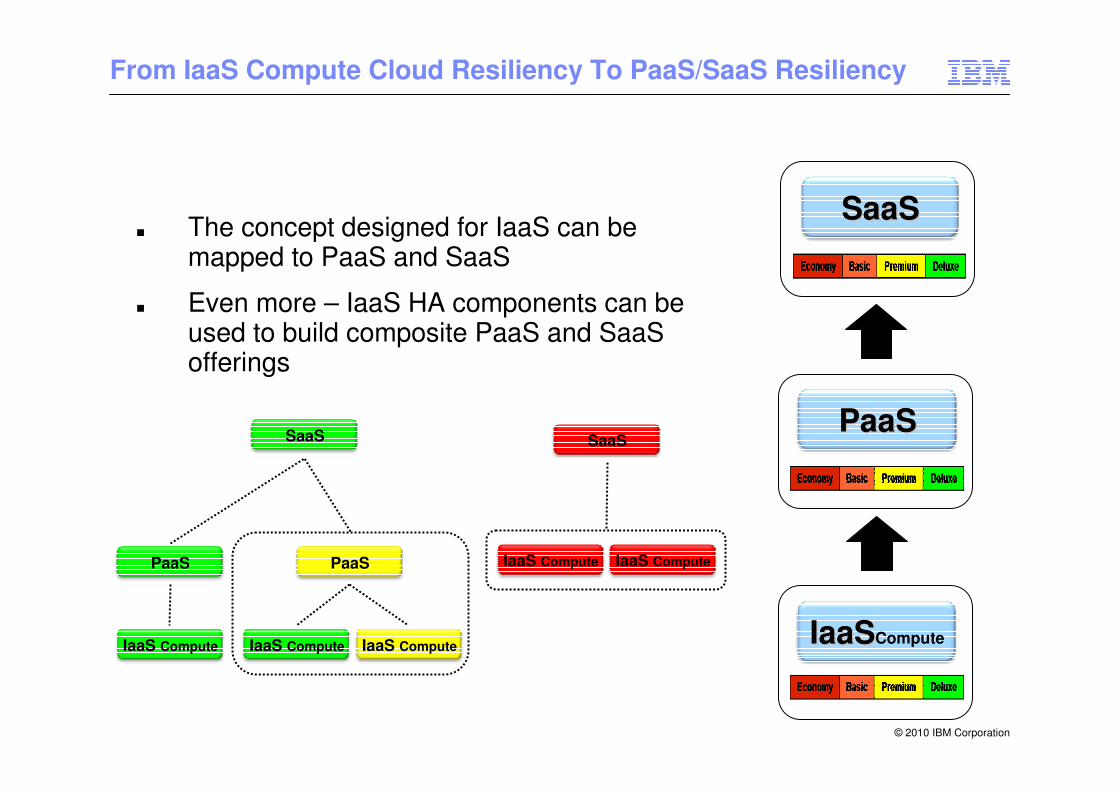
From IaaS Compute Cloud Resiliency To PaaS/SaaS Resiliency
IaaSIaaSCompute
PaaSPaaS
SaaSSaaS■ The concept designed for IaaS can be
mapped to PaaS and SaaS
■ Even more – IaaS HA components can be used to build composite PaaS and SaaSofferings
SaaS
PaaS
IaaS Compute IaaS Compute
PaaS
IaaS Compute
IaaS Compute IaaS Compute
SaaS
© 2010 IBM Corporation
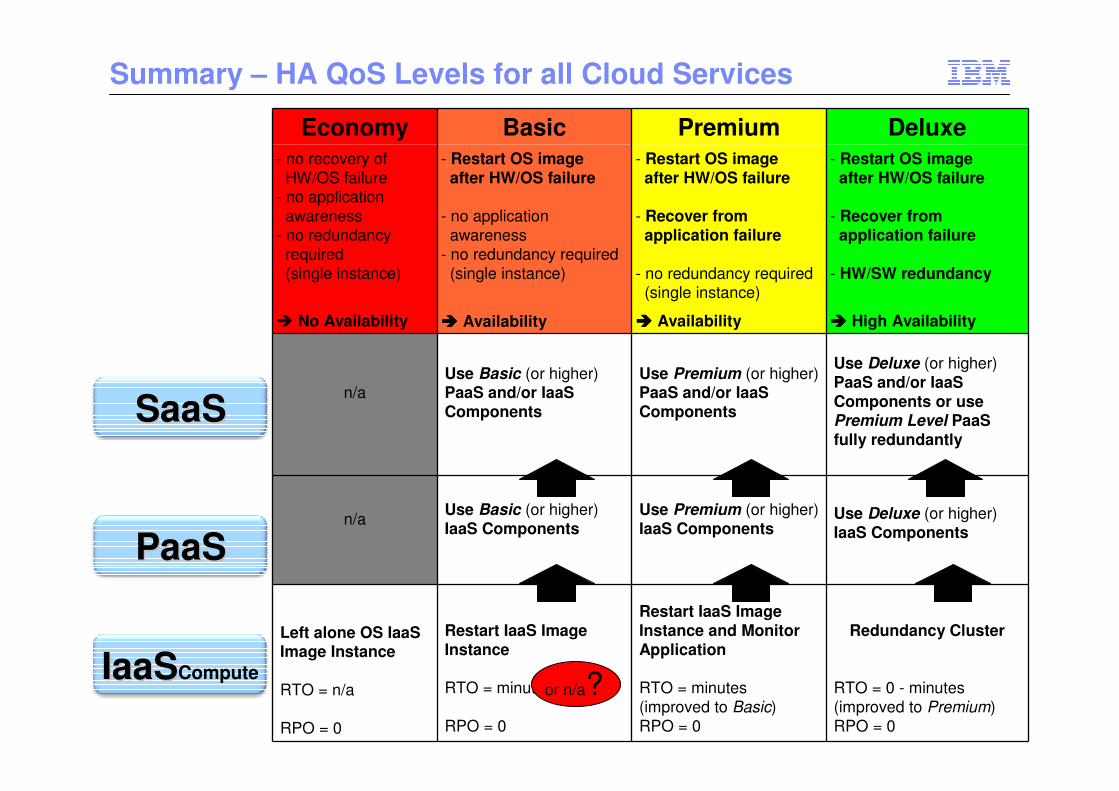
Summary – HA QoS Levels for all Cloud Services
Economy Basic Premium Deluxe- no recovery of
HW/OS failure- no application
awareness- no redundancy
required(single instance)
- Restart OS imageafter HW/OS failure
- no applicationawareness
- no redundancy required(single instance)
- Restart OS imageafter HW/OS failure
- Recover from application failure
- no redundancy required(single instance)
- Restart OS imageafter HW/OS failure
- Recover fromapplication failure
- HW/SW redundancy
� No Availability ���� Availability ���� Availability ���� High Availability
n/aUse Basic (or higher) PaaS and/or IaaSComponents
Use Premium (or higher) PaaS and/or IaaSComponents
Use Deluxe (or higher) PaaS and/or IaaSComponents or use Premium Level PaaSfully redundantly
n/aUse Basic (or higher)IaaS Components
Use Premium (or higher) IaaS Components
Use Deluxe (or higher) IaaS Components
Left alone OS IaaSImage Instance
RTO = n/a
RPO = 0
Restart IaaS Image Instance
RTO = minutes
RPO = 0
Restart IaaS Image Instance and Monitor Application
RTO = minutes(improved to Basic)RPO = 0
Redundancy Cluster
RTO = 0 - minutes(improved to Premium)RPO = 0
SaaSSaaS
PaaSPaaS
or n/a?IaaSIaaSCompute

© 2010 IBM Corporation
Summary
Due to the complexity of cloud environments, different strategies need to be appliedResiliency for the virtualized infrastructureResiliency for the cloud management partResiliency for the services offered in a cloud
Resiliency for cloud services needs to be easily adoptable and complexity needs to be hidden from the customer

© 2009 IBM Corporation
Thanks