clustering - smckearney.com · • clustering is a method of storing data on a disc. • a cluster...
TRANSCRIPT

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 1
Clustering
Oracle Server Concepts Manual
Database Systems Concepts
Silberschatz/ Korth
Sec. 10.7
Fundamentals of Database Systems
Elmasri/Navathe
Sec. 5.10

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 2
2
Overview
Definition
Intra-file Clustering
Inter-file Clustering
Clustering inPages
UnclusteredRelations
ClusteredRelations
Advantages Disadvantages
Applications
ClusteringIndex
Clustering inOracle
Criteria forClustering
Comparison
What types ofclustering exist?
How does clustering
work?
Compareclustered andunclustered?
Advantages &Disadvantages?
When is it used?
How is it implemented?How is it implemented
in Oracle?
How do you decideto cluster data?
How does clusteringcompare to B+-Trees?

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 3
3
Definition
“Clustering means that records related to eachother are stored physically beside each other.”
Frank
• Clustering is a method of storing data on a disc.
• A cluster is used to store tuples from one or more relations physicallyclose to other tuples in the database.
• The purpose of clustering is to speed up the performance of certain typesof queries.
• When tuples that are physically close to each other are retrievedthey are retrieved more quickly than tuples that are not physicallyclose to each other.
• Because clustering affects how the data is actually stored on the disc, thedecision to use clustering in the database is part of the physical databasedesign process.
• Clustering does not affect the applications that access the relations whichhave been clustered. Clustered and unclustered relations appear the sameto users of the system.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 4
4
Intra-file Clustering
• Data items in a single file are stored together.
Supplier 1
Supplier 2
Supplier 3
Supplier n
Suppliers are stored in the order they are most often retrieved
• In intra-file clustering records in a single file are stored close to relatedrecords in the same file.
• For example, if suppliers are normally ordered by their supplier numberthen each supplier would be stored to the supplier with the next highestsupplier number.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 5
5
Inter-file Clustering
• Data items in two or more files are storedtogether.
Supplier 1
Supplier 2
Supplier 3
Shipment G
Shipment A
Shipment B
Shipment C
Shipment D
Shipment E
Shipment F
Shipments from one file are stored beside suppliers in another file.
• In inter-file clustering records from one file are stored close to recordsfrom another file.
• For example, a shipment from a shipments file would be stored close tothe supplier of the shipment.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 6
6
Overview
Definition
Intra-file Clustering
Inter-file Clustering
Clustering inPages
UnclusteredRelations
ClusteredRelations
Advantages Disadvantages
Applications
ClusteringIndex
Clustering inOracle
Criteria forClustering
Comparison
What types ofclustering exist?
How does clustering
work?
Compareclustered andunclustered?
Advantages &Disadvantages?
When is it used?
How is it implemented?How is it implemented
in Oracle?
How do you decideto cluster data?
How does clusteringcompare to B+-Trees?

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 7
7
Clustering Data in Pages
These pages willbe slower toretrieve.
The disc mustrotate further toread each page.
These pages willbe quicker toretrieve.
The disc mustrotate less to readeach page.
Data that is stored close together will be quicker to retrieve.
Disc
• Clustering affects the physical position of data on the disc.
• When two data items are stored on the same page on the disc, they can beread with one page read operation.
• Because the computer reads one page at a time, data itemsstored on the same page will be read at the same time.
• When two data items are stored on pages that are close to each other onthe disc, they can be read with two page read operations.
• Because the pages occur one after another there is no disc headmovement between reads (no seek time).
• When two data items are stored in separate locations on the disc, they canbe read with two page read operations and a seek operation.
• Because the pages occur at separate locations on the disc thedisc head must move to a new position on the disc to read thesecond page.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 8
8
Unclustered Relations
Adapted from ‘Oracle7 Concepts Server Manual’
• Unclustered relations are stored in their own pages on the disc. That is,each page will contain tuples from one relation only. The pages may bepositioned anywhere on the disc.
• Therefore, to join two relations at least two pages must be read from thedisc - one page for each relation.
• For example, in the above example, the emp relation (table) is stored atone location on the disc and the dept relation (table) is stored at anotherlocation.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 9
9
Clustered Relations
Adapted from ‘Oracle7 Concepts Server Manual’
• Clustered relations are stored using a cluster key. Each relation belongingto the cluster has an attribute corresponding to the cluster key. Each blockwill store tuples with a particular cluster key value.
• For example, in the above example, the cluster key is deptno and all thedepartments and employees with deptno=10 are stored together.
• This type of cluster will improve the performance of queries that join theemp and the dept relations.
• Note that the cluster key value is only stored once for each distinct value.For example, the value deptno=10 is only stored once and all tuples withdeptno=10 are stored together.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 10
10
Overview
Definition
Intra-file Clustering
Inter-file Clustering
Clustering inPages
UnclusteredRelations
ClusteredRelations
Advantages Disadvantages
Applications
ClusteringIndex
Clustering inOracle
Criteria forClustering
Comparison
What types ofclustering exist?
How does clustering
work?
Compareclustered andunclustered?
Advantages &Disadvantages?
When is it used?
How is it implemented?How is it implemented
in Oracle?
How do you decideto cluster data?
How does clusteringcompare to B+-Trees?

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 11
11
Advantages
• Advantages– Speeds up some queries
– Uses less space
Supplier 1
Supplier 2
Supplier 3
Shipment G
Shipment A
Shipment B
Shipment C
Shipment D
Shipment E
Shipment F
A query for ‘all shipmentsof supplier 1’ will be quickbecause all the shipmentsfor supplier 1 followimmediatelyafter supplier 1.
These shipmentsarefor supplier 1.
• Clustering will speed up some database queries. For example, a clusterconsisting of suppliers and shipments will speed up queries that request allthe shipments for a particular supplier.
• The cluster improves the supplier/shipment query because the datafor each shipment is stored on the same page as the correspondingsupplier. Hence, when the supplier record is read the set ofshipments is also read.
• The cluster key value that is used to cluster relations is only stored once ineach page. This may save disc space.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 12
12
Disadvantages
• Disadvantages– Slows down some queries
– Slows down writes
Supplier 1
Supplier 2
Supplier 3
Shipment G
Shipment A
Shipment B
Shipment C
Shipment D
Shipment E
Shipment F
A query for all shipmentswill be slow because theshipmentsare not stored together on thedisc.
To read all theshipmentrecords the supplierrecords must also beread.
• Clustering will slow down certain types of queries. For example, thecluster on suppliers and shipments will slow down queries that ask for allshipments.
• The cluster slows down the ‘all shipments’ query because theshipments are stored with each supplier. To read all the shipmentsthe DBMS must also read the supplier data.
• Inserting new records into a cluster may also be slow. For example,adding a new shipment for supplier 1 will involve making space aftershipment B.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 13
13
Overview
Definition
Intra-file Clustering
Inter-file Clustering
Clustering inPages
UnclusteredRelations
ClusteredRelations
Advantages Disadvantages
Applications
ClusteringIndex
Clustering inOracle
Criteria forClustering
Comparison
What types ofclustering exist?
How does clustering
work?
Compareclustered andunclustered?
Advantages &Disadvantages?
When is it used?
How is it implemented?How is it implemented
in Oracle?
How do you decideto cluster data?
How does clusteringcompare to B+-Trees?

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 14
14
Applications 1 - Hierarchies
Customer Order Order Line
Customer 1
Order 1 Order 2 Order 3
Order Line 1 Order Line 2 Order Line 1 Order Line 2 Order Line 1 Order Line 2
A hierarchy of customer to orders to order lines.
Customer 1
Order Line 2
Order 3
Customer 2
Order 1
Order Line 1
Order 2
Order Line 1
Order Line 2
Order Line 1
ClusterER Diagram
ER Instance
• Clustering is used when the data has a hierarchical structure. Forinstance, in the example above, the cluster would be used when the mostcommon queries will retrieve all the orders and order lines for a customer.
• A cluster to store the above structure would cluster all the order lines withtheir corresponding orders and then the orders and order lines would bestored with their corresponding customer.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 15
15
Applications 2 - Lists
Product 1 Product 2 Product 3
Product 1
Product 3
Product 2
List of Products Cluster
• A cluster may be used when queries will retrieve lists of data items. Forexample, in the above example, the cluster of products will improvequeries requesting all the products.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 16
16
Applications 3 - SQL Joins
• Equi-joins
SELECT name, address, deptname
FROM emp, dept
WHERE emp.deptno = dept.deptno
The emp and dept relations may be clustered on the deptno attribute.
• A cluster may be used to cluster relations that are frequently joinedtogether.
• In the above example, the relations emp and dept may be clustered on thedeptno attribute. The value of each deptno will be stored once togetherwith all the corresponding emp and dept tuples.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 17
17
Overview
Definition
Intra-file Clustering
Inter-file Clustering
Clustering inPages
UnclusteredRelations
ClusteredRelations
Advantages Disadvantages
Applications
ClusteringIndex
Clustering inOracle
Criteria forClustering
Comparison
What types ofclustering exist?
How does clustering
work?
Compareclustered andunclustered?
Advantages &Disadvantages?
When is it used?
How is it implemented?How is it implemented
in Oracle?
How do you decideto cluster data?
How does clusteringcompare to B+-Trees?

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 18
18
Clustering Index
Deptno
10 Dept
Employee
Employee
Employee
20 Dept
Employee
Employee
Employee
30 Dept
Employee
Employee
Employee
10
20
30
Index on Deptno
Records
All recordswith deptno=10
All recordswith deptno=20
All recordswith deptno=30
Page P1
Page P2
Page P3
• The DBMS uses a clustering index when it implements a cluster.
• The clustering index is used to index the cluster key. This allows theDBMS to efficiently access the data in the cluster.
• The cluster index contains an entry for each cluster key value. The indexmay be a B+-Tree
Ref: Elmasri, sec 6.1.2

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 19
19
Clustering in Oracle
• Create a cluster– CREATE CLUSTER emp_dept (deptno NUMBER(3));
• Create a cluster index– CREATE INDEX emp_dept_index ON CLUSTER emp_dept;
• Create Tables– CREATE TABLE dept (deptno NUMBER(3), … )
CLUSTER emp_dept (deptno)
PRIMARY KEY (deptno);
– CREATE TABLE emp (empno NUMBER(5),
deptno NUMBER(3), … )
CLUSTER emp_dept (deptno)
FOREIGN KEY (deptno) REFERENCES dept;
• There are three steps required to create a cluster in Oracle:
1. Create the cluster The space for the cluster is allocated on thedisc.
2. Create the cluster index Oracle requires a cluster index to be ableto access the cluster. Therefore, the cluster index must existbefore data can be added to the cluster.
3. Create the tables When the tables are created a parameter isadded to the CREATE TABLE command indicating the cluster towhich the table will belong.
• Once the cluster has been created the normal data manipulationcommands (INSERT, DELETE, UPDATE, SELECT) may be used.Therefore, using a cluster to improve the performance of a database doesnot affect the application programs that access the data.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 20
20
Overview
Definition
Intra-file Clustering
Inter-file Clustering
Clustering inPages
UnclusteredRelations
ClusteredRelations
Advantages Disadvantages
Applications
ClusteringIndex
Clustering inOracle
Criteria forClustering
Comparison
What types ofclustering exist?
How does clustering
work?
Compareclustered andunclustered?
Advantages &Disadvantages?
When is it used?
How is it implemented?How is it implemented
in Oracle?
How do you decideto cluster data?
How does clusteringcompare to B+-Trees?

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 21
21
Criteria for Clustering
• Query Requirements– Joins
– Lists
– Hierarchies
• Space Requirements– Clustering may save space
• Update Requirements– Clustering may slow updates
• Deciding to cluster a set of relations depends on three factors:
• Query requirements Clustering improves joins between relationsbecause it stores related tuples together in the same page. When themost common queries involve joining two relations, a cluster mayimprove performance.
• Space requirements Because each cluster key value is only storedonce, storing relations in a cluster can use less storage space thanstoring the same relations separately. If storage space is restrictedclustering the data may save space.
• Update requirements Cluster are difficult to update because spacemust be left to allow for additional clustered tuples. If space is notavailable, it may be necessary to move tuples between pages.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 22
22
Comparison with Other Techniques• B+-Tree
– Fast access to individualtuples
– Does not affect the orderof data
– Can be ignored if notuseful
– Easy to create and delete
• Cluster– Fast access across
relations
– Changes the order of thedata
– Must be searched toaccess data
– Difficult to create anddelete
• A B+-Tree is designed to provide fast access to individual tuples in arelation. A cluster is designed to improve the performance of queries thatjoin two or more relations together.
• A B+-Tree does not affect the order of the actual data. Although theindex may be ordered, the actual data remains unordered. A clusterorders the actual data.
• A B+-Tree does not have to be used to answer a query. It is possible toaccess the data directly if using the B+-Tree is too inefficient. As acluster affects the physical ordering of the data, the cluster must beaccessed to retrieve the data. Hence, a cluster will slow down certainqueries.
• A B+-Tree index is easy to create and delete because it is separate fromthe data. A cluster is difficult to create or change because it must becreated before the data is added to the database. Deleting a cluster willdestroy the data.

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 23
23
Partitioned Table
CREATE TABLE sales ( acct_no NUMBER(5), acct_name C HAR(30), amount_of_sale NUMBER(6), week_no INTEGER )
PARTITION BY RANGE ( week_no ). (PARTITION sales1 VALUES LESS THAN ( 4 ) TABLESPACE ts0, PARTITION sales2 VALUES LESS THAN ( 8 ) TABLESPACE ts1, ... PARTITION sales13 VALUES LESS THAN ( 52 ) TABLESPACE ts12 );
Oracle Concepts Manual

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 24
24
Partitioned Index 1
Oracle Concepts Manual
BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 25
25
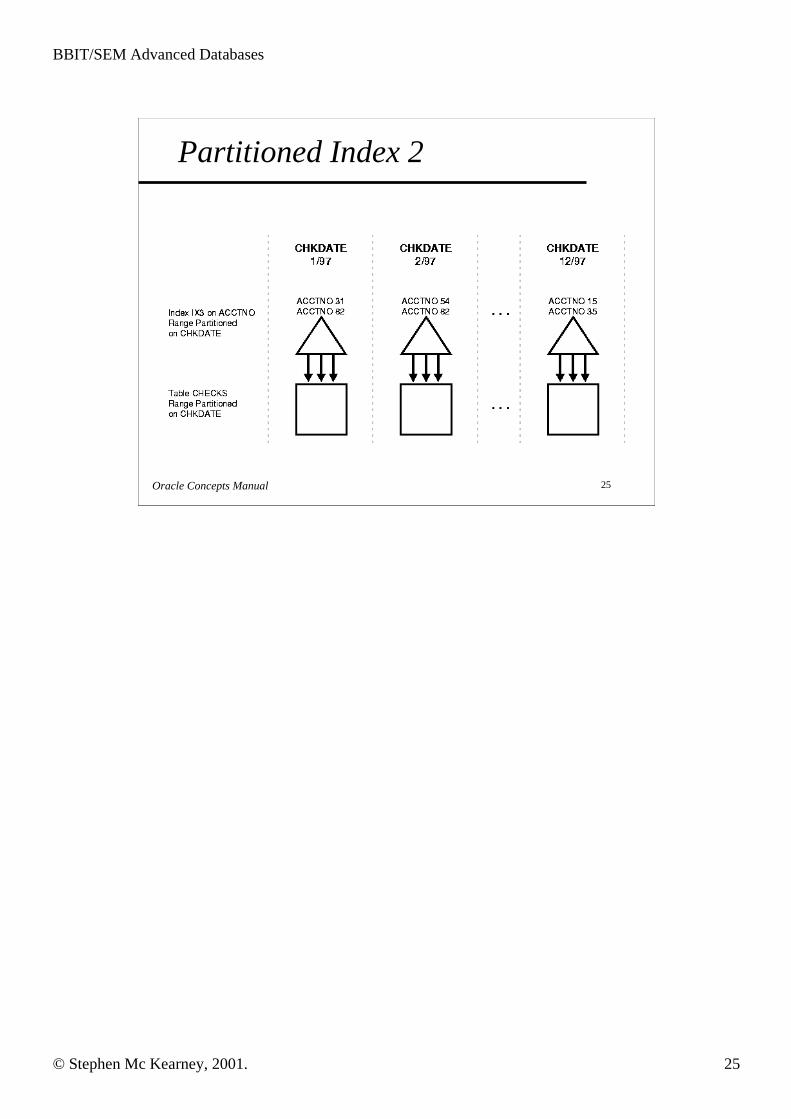
Partitioned Index 2
Oracle Concepts Manual

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 26
26
Partitioned Index 3
Oracle Concepts Manual

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 27
27
Equipartitioned Tables
Better availability and reliabilityOracle Concepts Manual

BBIT/SEM Advanced Databases
© Stephen Mc Kearney, 2001. 28
28
Disc Striping
Oracle Concepts Manual