clustering de documentos. equipe diogo philippini pontual branco flavio de holanda cavalcanti junior...
TRANSCRIPT

Clustering de Documentos

Equipe
Diogo Philippini Pontual Branco
Flavio de Holanda Cavalcanti Junior
José Paulo Henrique de Melo Fernandes
Luana Martins dos Santos

Roteiro Motivação Clustering x Classificação Métodos K-means Arquitetura de Mozer Adaptive Information Retrival (AIR) Adaptive Resonance Theory (ART) Aplicações Conclusão

Motivação

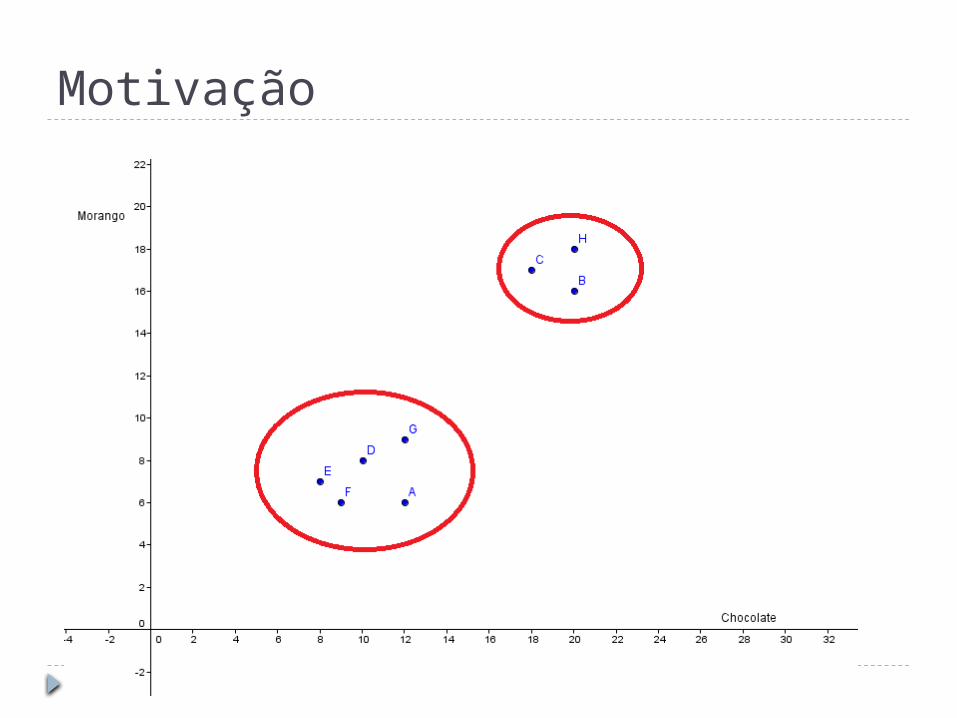
Motivação Agrupar documentos semelhantes em classes
não-conhecidas a priori.

Motivação

Motivação
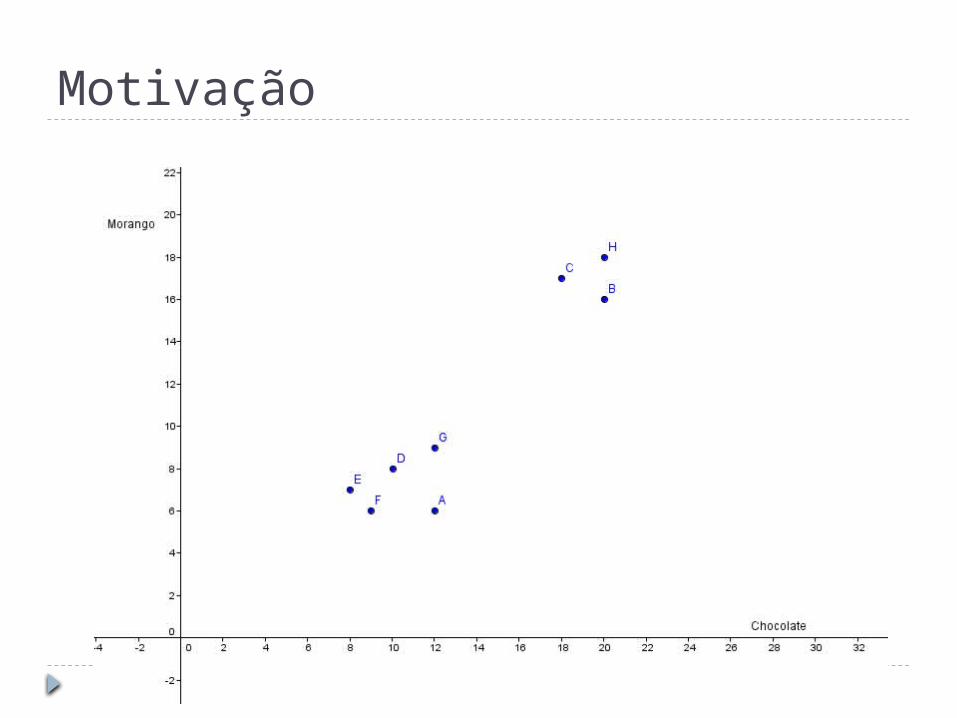
Loja
Chocolate
Morango
A 12 6
B 20 16
C 18 17
D 10 8
E 8 7
F 9 6
G 12 9
H 20 18
Motivação
Motivação

Motivação

O que é Clustering?
Antropologia (Driver e Kroeber, 1932)
"Encontrar grupos de objetos tais que objetos em um mesmo grupo sejam similares entre si e diferentes de objetos em outros grupos."
Não é um algoritmo!

Como pode me ajudar?
Identificação de grupos
Identificação de relacionamentos
Simplificação de informação

E na RI?
Cluster Hypothesis(Van Rijsbergen - 1979): “Dois documentos similares têm maior
probabilidade de serem relevantes para uma mesma pesquisa.”
Relevância!
Organização de resultados

E na RI?
Documentos similares são adicionados ao mesmo cluster
Aumentar a cobertura
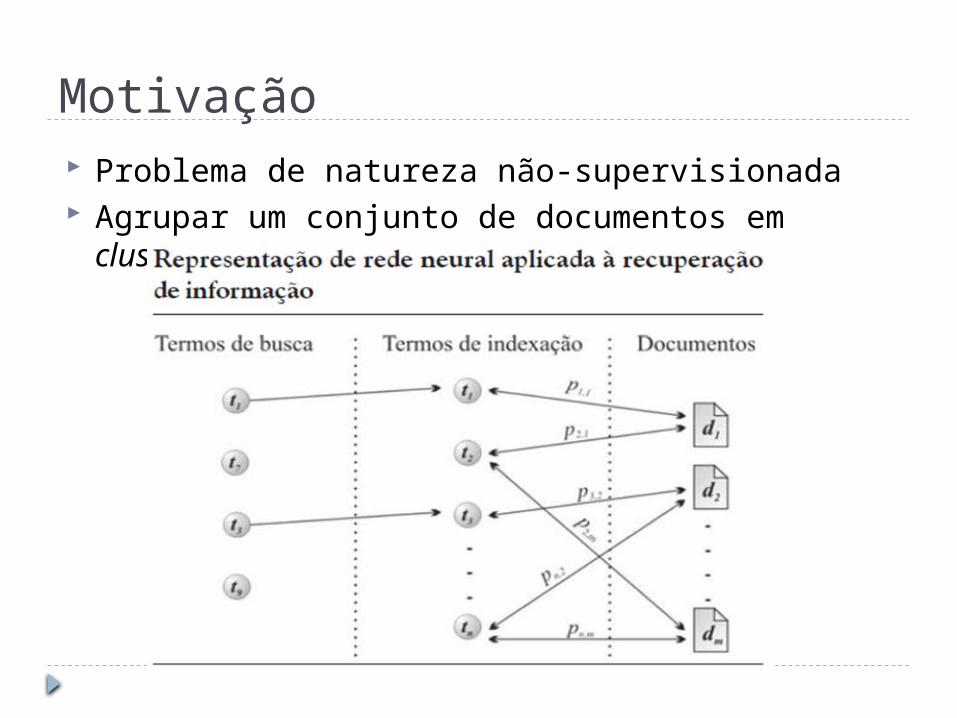
Motivação Problema de natureza não-supervisionada Agrupar um conjunto de documentos em clusters

Classificação X Clustering

Relembrando Classificação "A classificação de textos é a tarefa de associar
textos em linguagem natural a rótulos pré-definidos, a fim de agrupar documentos semanticamente relacionados"

E as diferenças? Clustering
Criar grupos de documentos Classes definidas pelo algoritmo
Classificação Classes definidas previamente Determinar a qual classe pertence o
documento

Métodos de Clustering

Métodos de ClusteringAssociatividade dos membros: Hard Clustering: Clusters isolados Soft Clustering (Fuzzy Clustering): Função de
pertinência
Modelos de clustering: Connectivity models: Definido pela distância. Centroid models: Definido por centróides. Density models: Definido por regiões densas.

Modelos Incompatíveis
Modelo Centróide (K-means)
Modelo Densidade (DBSCAN)
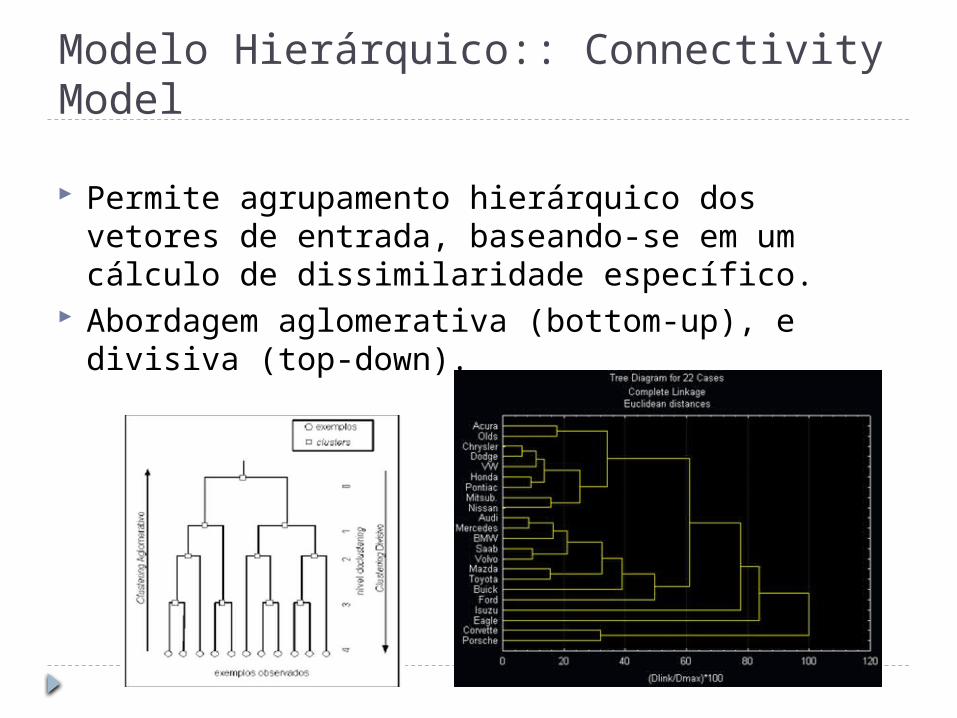
Modelo Hierárquico:: Connectivity Model
Permite agrupamento hierárquico dos vetores de entrada, baseando-se em um cálculo de dissimilaridade específico.
Abordagem aglomerativa (bottom-up), e divisiva (top-down).

Escolha da Referência
Formas diferentes de tomar a distância euclidiana como discriminante para formação de agrupamentos:
Single linkage Complete linkage Average linkage
dm = ( d(1,3) + d(1,4) + (d1,5) + d(2,3) + d(2,4) + d(2,5) ) / 6

Single Linkage vs. Complete Linkage

Desvantagens
Conjunto de clusters relevantes não definidos Não leva em conta outliers
(ruído/discrepâncias) Chaining phenomenon
“Data Mining” reconhece o método como um fundamento teórico inspirador, porém obsoleto.

K-means:: Centroid Model
Algoritmo simples com muitas variações. Define uma classe de algoritmos.
Algoritmo:1. Escolher os centros iniciais dos k clusters
desejados randomicamente.2. Repetir enquanto não houver alteração nos
clusters:1. Associar cada vetor ao cluster de centro mais próximo.2. Calcular o novo centro de cada cluster como a média
aritmética de seus vetores.

Exemplo
• Exemplo K = 3
1. Escolher os centros iniciais.
2. Associar cada vetor ao cluster mais próximo.
3. Determinar os novos centros.
4. Associar cada vetor ao cluster mais próximo.
5. Determinar os novos centros.
6. Associar cada vetor ao cluster mais próximo.
7. Não houve alterações.
c2
c1

Intenção do K-means
Minimiza Variância intra-grupos Maximiza Variância inter-grupos

Desvantagens
K especificado previamente Clusters de tamanho similar Roda diversas vezes, com inicializações
aleatórias diferentes (Otimizações podem sugerir as melhores configurações iniciais a serem testadas. Ex: K-means++)

K-means:: Otimização do K-Means
1. Escolha aleatoriamente um ponto do conjunto de dados como um centro de cluster.
2. Para cada ponto x, compute a distância D(x) entre ele e o centro de cluster mais próximo.
3. Escolha aleatoriamente um novo ponto como centro de cluster, tal que a probabilidade de um ponto x ser escolhido como centro é proporcional à distância D(x)2.
4. Repita os passos 2 e 3, até que k centros tenham sido escolhidos.
5. Agora execute o procedimento K-means para os centros escolhidos.

DBSCAN:: Density Model
Número mínimo de pontos vizinhos para formar um cluster
Raio da vizinhança de um membro do cluster

DBSCAN:: Density Model

Arquitetura de Mozer

Rede Neural

Rede Neural

Arquitetura de Mozer Conexões Excitatórias
ligações entre termos de indexação e documentos;
Conexões Inibitórias ligações entre pares de documentos.

Arquitetura de Mozer

Arquitetura de Mozer Consulta: "programação linguística"

Arquitetura de Mozer

Arquitetura de Mozer

Arquitetura de Mozer
“Bein e Smolensky (1988) implementaram e testaram esse modelo de rede neural proposta por Mozer utilizando 12.990 documentos e 6.832 termos de indexação. Eles avaliaram os resultados apresentados como satisfatórios e sugeriram novos testes utilizando bases de dados maiores e com características diversas.” Redes neurais e sua aplicação em sistemas de recuperação de informação –
Edberto Ferneda (USP)

Arquitetura de Mozer Vantagens
Implementação simples Habilidade de produzir resultados não esperados
Desvantagens Não aprende

AIR
Adaptive Information Retrieval

Adaptive Information Retrival Criado por Belew em 1989 Aprendizado não-supervisionado Redes "flexíveis“ Feedback do usuário influencia a resposta da
rede Implantável só em ambientes nos quais os
usuários possuam interesses comuns

Adaptive Information Retrival
Fonte: [1]

Adaptive Information Retrieval Vantagens
É capaz de aprender, como toda RN A arquitetura da rede é flexível
Desvantagens Só funciona em ambientes onde os usuários
possuem interesses em comum

ART
Adaptive Ressonance Theory

Adaptive Resonance Theory Proposto por Grossberg e Gail Carpenter Tenta agrupar os dados a partir deles próprios Dilema da Plasticidade-Estabilidade Sensível ao contexto
Descrimina dados irrelevantes ou repetidos Rede é implementada em três versões
ART1, ART2 e ART3

ART1 Características
Aprendizado não-supervisionado Só aceita entradas binárias Deve-se definir a priori o limiar de vigilância
O tamanho dos clusters

ART1 Arquitetura
Fonte: [2]
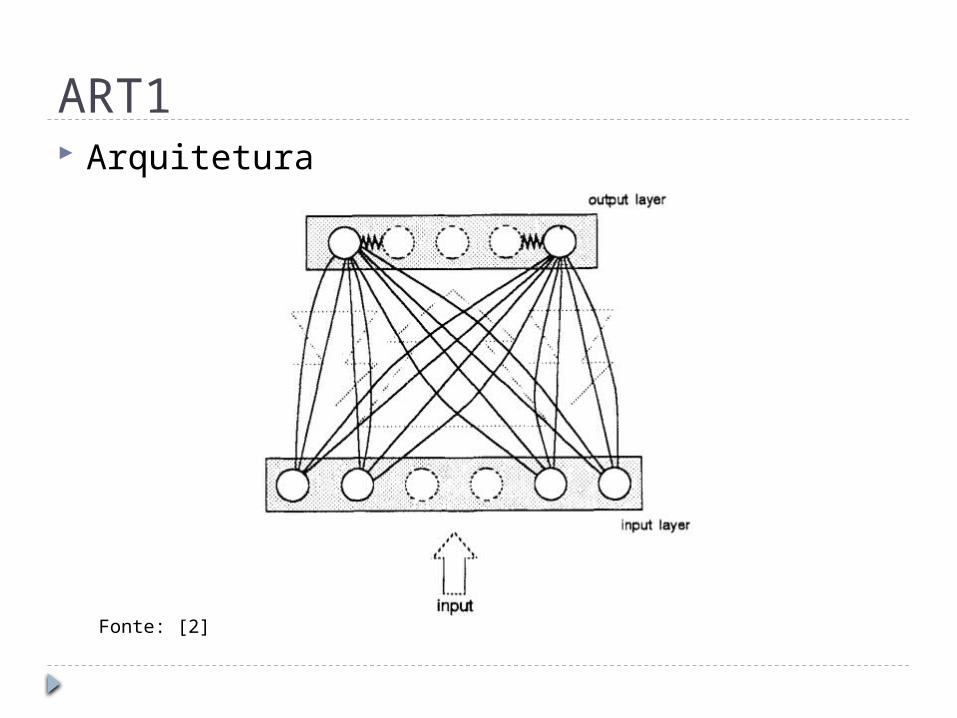
ART1 Arquitetura
Fonte: [2]

ART1 Funcionamento
Inicialização Reconhecimento Comparação Limiar de vigilância Busca

ART1 Inicialização
Fonte: [2]

ART1 Reconhecimento
Fonte: [2]
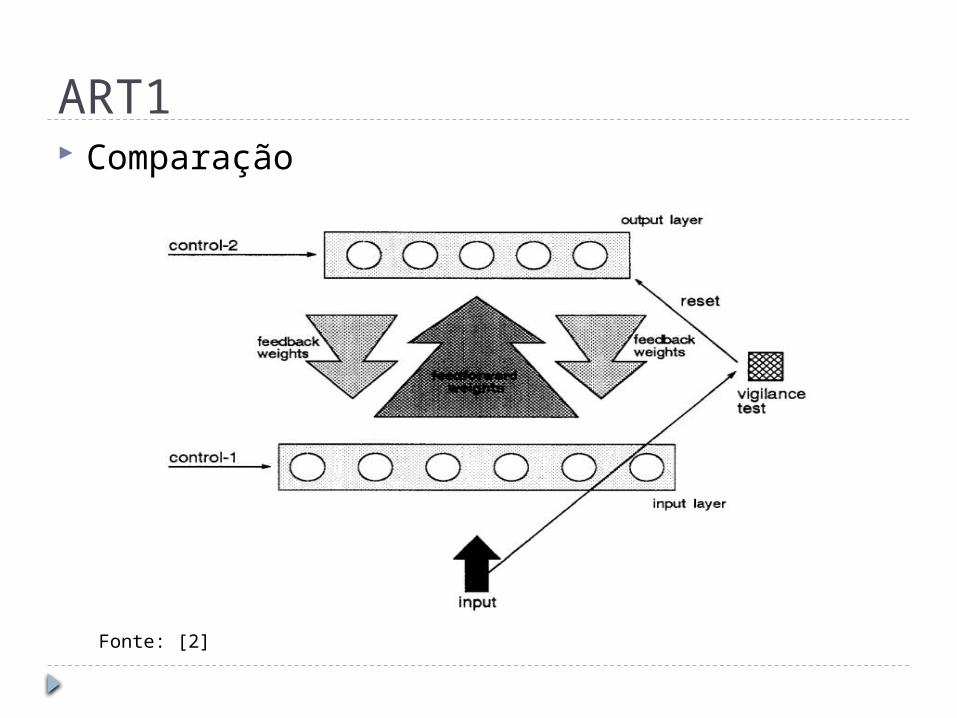
ART1 Comparação
Fonte: [2]
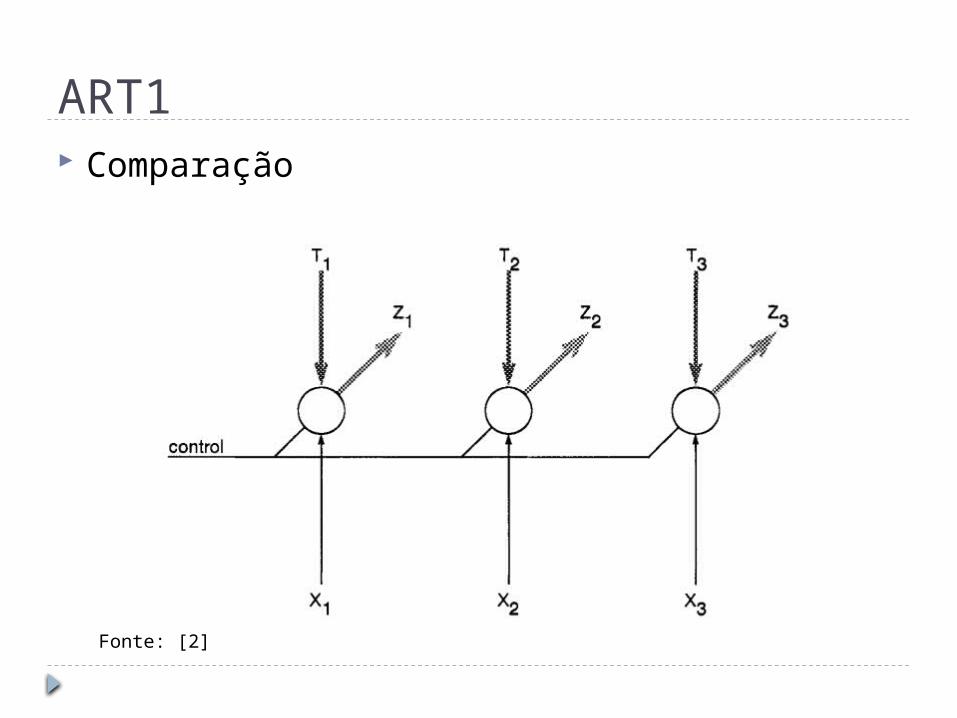
ART1 Comparação
Fonte: [2]

ART1 Limiar de vigilância
Fonte: [2]

ART1 Busca
Fonte: [2]

ART1 Para visualizar melhor:
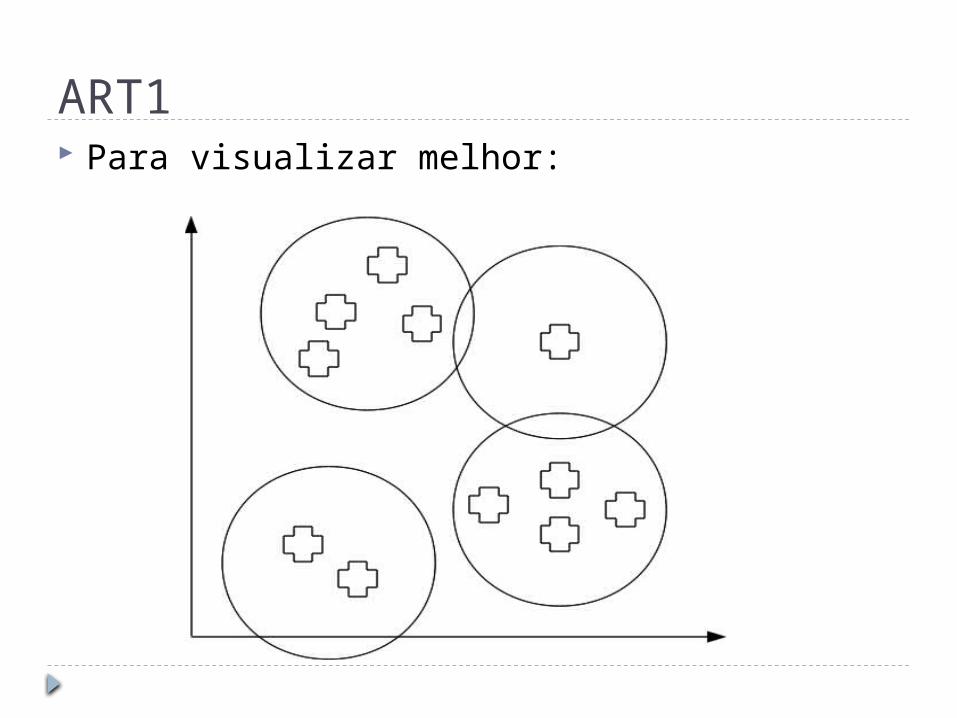
ART1 Para visualizar melhor:

ART1 Para visualizar melhor:

ART2 Estende as capacidades do ART1
Permite o uso de entradas contínuas Possui todas as características da ART1 É preciso definir mais parâmetros Introduz o conceito de STM e LTM
STM - Short-term memory LTM - Long-term memory

ART2 - Arquitetura
Fonte: [3]

ART Na verdade, ART possui diversas variações:
ART2-A ART3 Fuzzy ART ARTMAP Fuzzy ARTMAP

Aplicações

Nuvem de tags

Resultados de busca agrupados

Sistemas de Recomendação

Análise de Redes Sociais

Navegação Hierárquica

Bioinformática

Conclusões

Conclusões Redução do espaço de busca As técnicas utilizadas são consolidadas na
área de IA Computacionalmente mais caro Pode incluir documentos irrelevantes no
resultado da busca

Referências

Referências
1. F. Edberto, Neural networks and its application in information retrival systems, jan./abr. 2006
2. R.Beale and T.Jackson, “Neural Computing: An Introduction”, Department of Computer Science, University of York. 1990
3. Gail A. Carpenter and Stephen Grossberg, “ART2: Self-organization of stable category recognition codes for analog input patterns”, Center for Adptive Systems, Boston University, 11/06/1987
4. “http://en.wikipedia.org/wiki/Adaptive_resonance_theory”, access on 13/07/2013
5. Apresentação do grupo de 20106. http://www.inf.ufsc.br/~patrec/agrupamentos.html

Dúvidas