cnfsat: predictive models, dimensional reduction, and ...npslagle.info/articles/cnfsat.pdf ·...
TRANSCRIPT

CNFSAT: Predictive Models, Dimensional Reduction, and Phase
Transition
Neil P. SlagleCollege of Computing
Georgia Institute of TechnologyAtlanta, GA
Abstract
CNFSAT embodies the P versus NP computational dilemma. Most machine learning research on CNFSAT applies randomized optimization techniques to specific problem instances in search of a satisfying assignment. A novel approach is treating CNFSAT as a supervised learning and dimension reduction problem in search of models capable of predicting satisfiability with a relatively low number of features. Herein we present some empirical results after applying decision trees to three representations of CNFSAT over four and five variables and linear regression to three representations of MAXSAT and the CNFSAT solution count (SATSOL) problem over four and five variables. The representations are bit vectors indicating the clauses included in the formulas, principal component analysis applied to the previous representation, and a simple clause count and variable hit representation. Significantly, the first principal component exhibits the number of clauses in instances, and decision trees on CNFSAT and linear regression on MAXSAT and SATSOL empirically offer a 20% improvement in error rates after preprocessing the data with PCA, baselining against the full bit vector representation. The clause count and variable hit representation gives the lowest error rates observed in the experiments. Thus, feature selection demonstrates a reduction in error using decision trees and linear regression as prediction models. Notably, PCA and the clause count and variable hit representations reduce the representation size from O(3n) to O(n2) and O(n), respectively, where n is the number of variables, while reducing predictive error. Also of interest, the linear regression prediction model exhibits the phase transition of MAXSAT and SATSOL appearing in randomized optimization approaches applied to MAXSAT; that is, decision trees, linear regression, and PCA applied to these problems encounter difficulty in prediction over regions where randomized optimization algorithms encounter difficulty in solving formulas.

1 Background and related work
CNFSAT, or conjunctive normal form satisfiability, first shown to be NP-complete by Cook [1], is the problem of determining whether a Boolean formula in conjunctive normal form is satisfiable. Much of the research on CNFSAT applies randomized optimization techniques to specific problem instances [2]. MAXSAT is the problem of determining the maximum number of clauses satisfiable in a given instance of CNFSAT. The maximum number of satisfiable clauses in a given instance of CNFSAT is at least 50% the number of clauses in the instance; we can characterize the MAXSAT output as a fraction of clauses satisfiable. MAXSAT, like CNFSAT, is NP-hard [3], and similarly, much of the existing research applies stochastic optimization [4]. Counting the number of solutions (SATSOL) in a given instance of CNFSAT is a #P problem (defined in [5]).
The phase transition of CNFSAT and MAXSAT appears in [4], [6], and [7]. Phase transitions in combinatorial problems exhibit regions containing hard and easy problem instances with respect to some key parameter [6]. In CNFSAT, MAXSAT, and, based on results herein, SATSOL, a key parameter is the number of clauses [4].
Finally, motivating the approaches1 discussed herein is that existing machine learning research on these problems applies randomized optimization to instances of problems rather than building supervised learning models for and applying feature selection algorithms to large collections of instances as data sets [2], [4]. That is, little or no research exists attempting to transform these problems into instances of supervised learning.
2 Representing CNFSAT, MAXSAT, and SATSOL as data
To represent CNFSAT, MAXSAT, and SATSOL as data, we create bit vectors indicating the hash values of the clauses present in a formula, a dimensionally-compressed space over the bit vectors using PCA, and a restrictive clause count and variable hit representation.
2.1 The bit vectors
The bit vector representation is isomorphic to the formula space; that is, we can recover the original formula using this representation. Though the bit vectors capture the complexity of the formulas and thus become infeasible for even low variable counts, we can leverage them to generate the second representation and as a baseline for comparing performance of the predictive models.
The space of formulas containing up to n variables contains 3n-1 distinct clauses, assuming no clause contains a particular variable more than once.2 Bit vectors over four variables require 80 entries in addition to the label; bit vectors over five variables require 242 entries in addition to the label.
To represent a particular formula in the bit vector, we hash the clauses of the formula so that clauses over, say the j lowest variables, ordered by indices, exhibit the same hash values irrespective of the value of n. More formally, given the hash function H:clauses→Z+ and some clause C over x1, …, xn-1,
1 We previously applied other supervised learning techniques (SVMs, kNN, boosting, ANNs) with insignificant results; decision trees and linear regression offer attractive results.
2 Each variable can appear one of three ways in a clause: absent, a positive literal, or a negative literal. Subtracting one for the empty clause, we obtain 3n-1 possible clauses.

• H(C Ⅴ xn) = H(C) + 3n-1 – 1,
• H(C Ⅴ ~xn) = H(C) + 2(3n-1 – 1),
• H(xn) = 3n – 2,
• H(~xn) = 3n – 1, where
• H(x1) = 1, and
• H(~x1) = 2.
Defined recursively, this hashing mechanism allows formulas over n variables to subsume formulas over smaller subsets of more lowly indexed variables in a natural way. That is, if Fn is the bit vector representing a formula F over x1, …, xn, then in the space of formulas over x1, …, xn+1, F's bit vector Fn+1 appears identical to Fn in the first 3n – 1 entries.
As a bit vector example, suppose a formula over simply three variables is
x1vx2^~x1vx3^~x3.
Then the bit vector representations is
0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1, 1 (CNFSAT)
0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1, 3/3 (MAXSAT)
0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1, 1 (SATSOL).
Since a three variable formula can contain any of 26 clauses, the length of the vector sans the label is 26. The location of the ones in the bit vector indicate the hash values of the clauses in the given formula. The final entry is the label; for CNFSAT, this label is a zero or one, indicating whether the formula represented by the bit vector is satisfiable; for MAXSAT, the label is a floating precision number indicating the ratio of the maximum number of clauses satisfiable to the number of clauses in said formula; for SATSOL, the label indicates the number of solutions of said formula.
2.2 The bit vectors, reduced by PCA
The PCA representations we obtain by multiplying the principal component matrix PC p×26 , where p is the number of principal components and each row represents a principal component, by the bit vector. Results below suggest good performance where p is O(n2).
2.3 Clause count and variable hits
The clause count and variable hit representation for this instance is
3 1 1 1 1 0 1, 1 (CNFSAT),
3 1 1 1 1 0 1, 3/3 (MAXSAT)
3 1 1 1 1 0 1, 1 (SATSOL).
The first entry is the number of clauses, the second to fourth indicate the number of clauses containing the positive literals x1, x2, and x3, respectively, and the fifth to seventh indicate the number of clauses containing the negative literals ~x1, ~x2, and ~x3, respectively. If n is the number of variables, this representation contains 2n+1, or O(n) entries.
3 Collecting the data
As stated earlier, the space of formulas containing up to n variables contains 3n-1 possible clauses, assuming no clause can contain a variable more than once. To generate data over n variables, we randomly select a

number of clauses for a particular formula using an exponential distribution with some user-selected mean representing the average ratio of clauses present, say 0.3 or 0.4. The exponential distribution, defined over a positive domain, guarantees that all clause counts are possible while depressing the formula lengths more toward O(n2), yielding a 30-35% ratio of positive examples.3 Next, we randomly select clauses to add to the formula from the set of 3n-1 clauses until the formula is of the specified length. We determine satisfiability, the maximum number of satisfiable clauses, and the number of solutions of each formula using a brute force search of the 2n possible solutions. Finally, we collect 10,000 data points each from problem spaces in which n is four and five4.
4 The principal components
Significantly, the first principal component seems always to measure linearly to the number of clauses in the formula, a value we can calculate easily in polynomial time. Based on empirical results, we postulate that the first principle component of the data set over n variables is approximately the 3n-1 dimensional vector
• PC1=⟨± 1
3n−1
, ... ,±1
3n−1 ⟩ .
After subtracting the approximate average vector X avg=⟨ 12 ,... ,12 ⟩ over
the data X from Xi, a bit vector representing a formula with m clauses, the new data vector transformed by the principle component gives
• PC1⋅X i−Xavg=±2m−3n
−1
23n−1
.
Clearly, a simple linear transformation recovers m from this form.
The change in empirical variance5 before and after subtracting the first PC is often considerably larger than the corresponding changes for subsequently calculated PCs. For example, for the data set over four variables, the empirical differences in variances are 74295, 1435, 1410, 1430, and 1431 for the first five components. The other data sets exhibit similar behavior, suggesting that PCA interprets the number of clauses to be the most significant feature of a formula.
Despite the easy empirical interpretation of the first PC, similar interpretations of higher order PCs are not so easily forthcoming, despite the natural subsumption6 of lower degree formulas into higher degree formulas.
The number of PCs necessary to outperform the bit vector representation is surprisingly low. In fact, in the four variable case, PCs between sizes
3 In earlier experiments, we applied a uniform distribution; unfortunately, the spread of formula sizes significantly diminished the number of satisfiable formulas generated, frustrating supervised learning. Both distributions exhibit the significant PCA result described in the PCA section of the paper.
4 2SAT isn't NP-complete and contains only 255 formulas; all formulas in 3SAT fit on a typical hard-drive, whereas generating all of 4SAT, space notwithstanding, could require 2700 times the eight hours required to generate all of 3SAT. Thus, prediction becomes more essential once n >3.
5 The change in variance exhibits the eigenvalues for the given eigenvectors (principal components.)
6 See the hash description above.
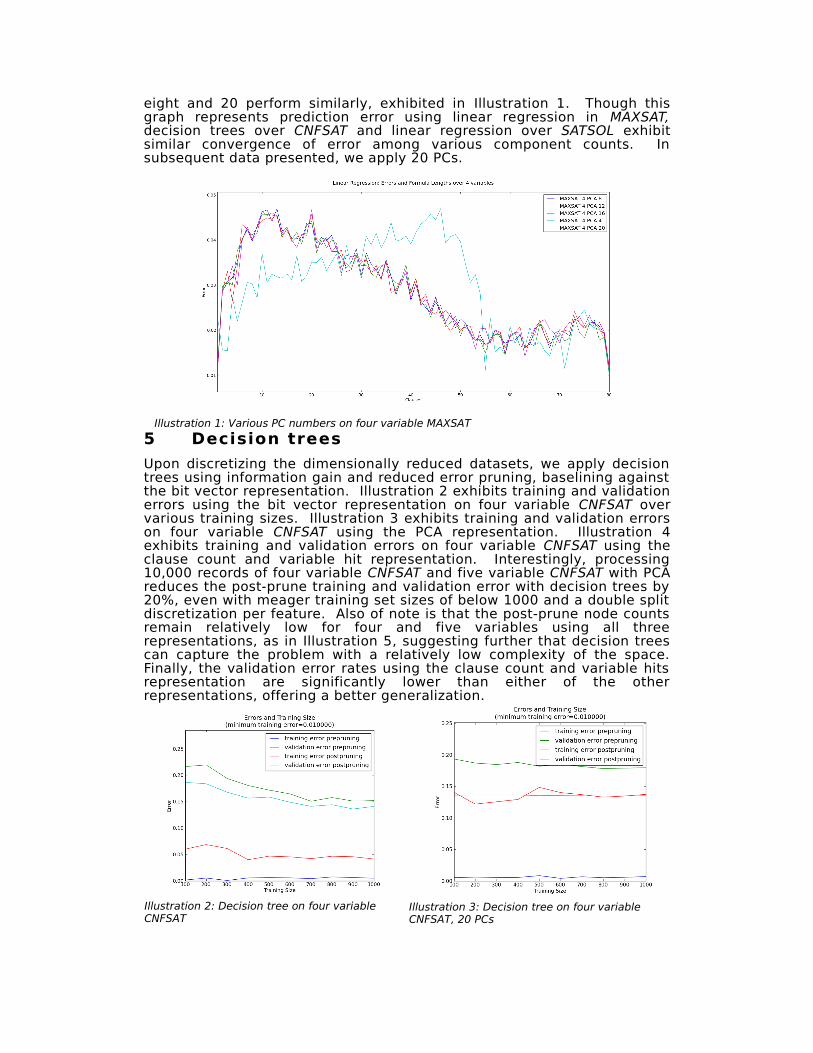
eight and 20 perform similarly, exhibited in Illustration 1. Though this graph represents prediction error using linear regression in MAXSAT, decision trees over CNFSAT and linear regression over SATSOL exhibit similar convergence of error among various component counts. In subsequent data presented, we apply 20 PCs.
5 Decision trees
Upon discretizing the dimensionally reduced datasets, we apply decision trees using information gain and reduced error pruning, baselining against the bit vector representation. Illustration 2 exhibits training and validation errors using the bit vector representation on four variable CNFSAT over various training sizes. Illustration 3 exhibits training and validation errors on four variable CNFSAT using the PCA representation. Illustration 4 exhibits training and validation errors on four variable CNFSAT using the clause count and variable hit representation. Interestingly, processing 10,000 records of four variable CNFSAT and five variable CNFSAT with PCA reduces the post-prune training and validation error with decision trees by 20%, even with meager training set sizes of below 1000 and a double split discretization per feature. Also of note is that the post-prune node counts remain relatively low for four and five variables using all three representations, as in Illustration 5, suggesting further that decision trees can capture the problem with a relatively low complexity of the space. Finally, the validation error rates using the clause count and variable hits representation are significantly lower than either of the other representations, offering a better generalization.
Illustration 2: Decision tree on four variable CNFSAT
Illustration 3: Decision tree on four variable CNFSAT, 20 PCs
Illustration 1: Various PC numbers on four variable MAXSAT
6 Linear regression, phase transition
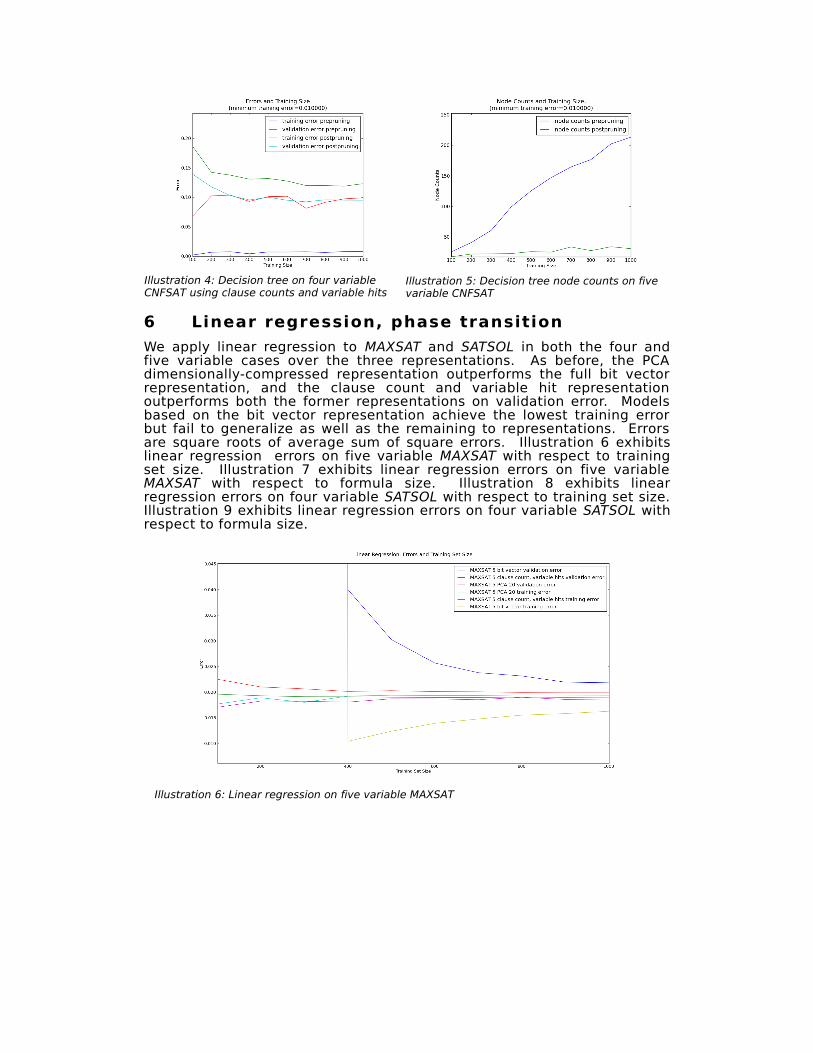
We apply linear regression to MAXSAT and SATSOL in both the four and five variable cases over the three representations. As before, the PCA dimensionally-compressed representation outperforms the full bit vector representation, and the clause count and variable hit representation outperforms both the former representations on validation error. Models based on the bit vector representation achieve the lowest training error but fail to generalize as well as the remaining to representations. Errors are square roots of average sum of square errors. Illustration 6 exhibits linear regression errors on five variable MAXSAT with respect to training set size. Illustration 7 exhibits linear regression errors on five variable MAXSAT with respect to formula size. Illustration 8 exhibits linear regression errors on four variable SATSOL with respect to training set size. Illustration 9 exhibits linear regression errors on four variable SATSOL with respect to formula size.
Illustration 6: Linear regression on five variable MAXSAT
Illustration 4: Decision tree on four variable CNFSAT using clause counts and variable hits
Illustration 5: Decision tree node counts on five variable CNFSAT
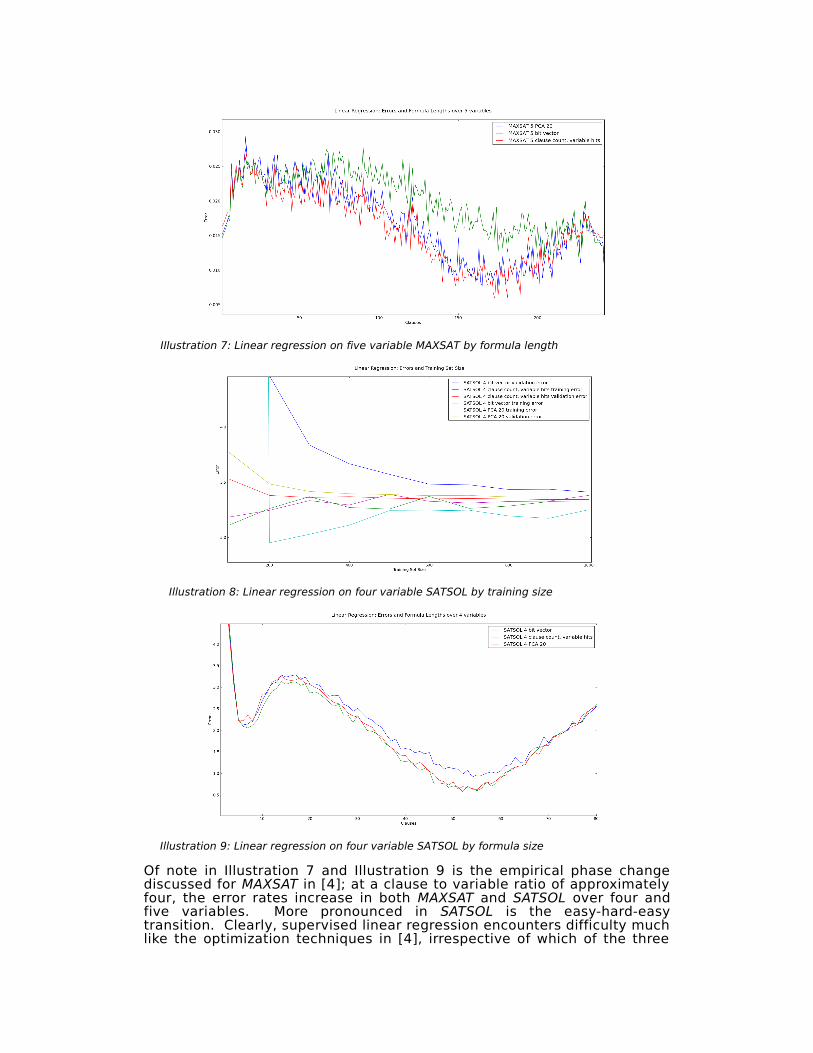
Of note in Illustration 7 and Illustration 9 is the empirical phase change discussed for MAXSAT in [4]; at a clause to variable ratio of approximately four, the error rates increase in both MAXSAT and SATSOL over four and five variables. More pronounced in SATSOL is the easy-hard-easy transition. Clearly, supervised linear regression encounters difficulty much like the optimization techniques in [4], irrespective of which of the three
Illustration 7: Linear regression on five variable MAXSAT by formula length
Illustration 8: Linear regression on four variable SATSOL by training size
Illustration 9: Linear regression on four variable SATSOL by formula size

representations we apply. This suggests a uniformity of difficulty across isolating single solutions using randomized optimization and predicting using supervised learning.
7 Conclusions and further work
The results herein demonstrate that the novel approach of treating CNFSAT and constituent problems as instances of supervised learning could be significant, not just in reduction of space complexity but also that this reduction in space complexity corresponds to a reduction in prediction error. The first principal component representing essentially the number of clauses is significant, and further study might demonstrate similar interpretations of the subsequent principal components and whether this result generalizes to instances containing more than five variables.
The dimensionally reduced representations outperform the full bit vector representation in generalization over decision trees and linear regression. And even if the models achieved merely comparable generalization error, the PCA dimensionally-compressed representation and the clause count and variable hit representation are still superior since their respective feature spaces are considerably smaller; that is, if the number of features is essentially polynomial in the number of variables, say O(n2), then comparable prediction error with the full, O(3n), representation is significant. The PCA count of 20 realizes O(n2). The clause count and variable hits representation realizes O(n). This suggests that prediction of satisfiability, the maximum number of satisfiable clauses, and the number of solutions, might require much less complexity than that of the bit vector representation.
The phase transition appearing in both randomized optimization of specific instances and the predictive models discussed herein suggests some uniformity of difficulty across approaches, entreating further study.
Acknowledgments
I would like to acknowledge Professor H. Venkateswaran of the Georgia Institute of Technology for his interest in these topics; he graciously participated in many discussions related to this paper.
References
[1] Cook, S. A. (1971). The complexity of theorem-proving procedures. STOC '71 Proceedings of the third annual ACM symposium on Theory of computing. ACM: New York, NY, USA.
[2] Schoning, T. (1999). A probabilistic algorithm for k-SAT and constraint satisfaction problems. IEEE Computer Society. IEEE Computer Society: Washington, DC, USA.
[3] Krentel, M. (1986). The Complexity of Optimization Problems. Journal of Computer and System Sciences - Structure in Complexity Theory Conference : Orlando, FL, USA.
[4] Qasem, M., Prugel-Bennett, A. (2008). Complexity of MAX-SAT Using Stochastic Algorithms. GECCO: New York, NY, USA.
[5] Valiant, L. (1979). The Complexity of Computing the Permanent. Theoretical Computer Science. Elsevier Science Publishers: Essex, UK.
[6] Istrate, G. (1999). The phase transition in random Horn satisfiability and its algorithmic implications. Random Structures & Algorithms. John Wiley & Sons, Inc.: New York, NY, USA.
[7] Istrate, G. (2005). Coarse and Sharp Thresholds of Boolean Constraint Satisfaction Problems. Discrete Applied Mathematics - Special issue: Typical case complexity and phase transitions. Elsevier Science Publishers: Amsterdam, The Netherlands.