cognitiveclouds: ecommerce crawling & scraping infrastructure
TRANSCRIPT

White Paper | eCommerce Crawling & Scraping Infrastructure
How do you accurately and cost effectively crawl 100’s of millions of eCommerce retail products?
We’ve built crawling infrastructure that accurately screen scrapes data from large eCommerce websites for customers like cdscience.com, wishclouds.com, and adchemy.com (acquired by WalmartLabs). Through these consulting projects we’ve learned a lot and we’ve designed a new technical architecture with superior scalability and a lower total cost of ownership. In this white paper, we provide an overview of the problem and our solution.
The problem
It’s easy to build a basic one-off screen scraper. In fact, many software engineers build simple screen scrapers early in their career because a project they are working on needs to fetch data from a third-party website that doesn’t have an API. The problem is one of scale.
When you crawl 100’s of millions of product pages daily, you need crawling infrastructure that’s highly configurable and cost efficient. As an example, most architectures don’t accurately maintain the state of the crawler, which tracks how many
pages have been crawled and how many pages still need to be crawled. You need to understand the state of the crawler when it fails in order to quickly debug it.
The solution
The crawling architecture we’ve defined solves the core problems faced by crawlers that scrape 100’s of millions of eCommerce products.
‣ Machine learning is used to scrape standard product data
‣ Error handling and debugging tools speed up the process of writing new crawlers and debugging existing ones
‣ Requests to each website are throttled to avoid DOS attacks
‣ Settings are configurable per eCommerce retailer to maximize the requests per second, saving you money on infrastructure costs
‣ The architecture scales horizontally to accomplish jobs of any size
Technical architecture
Our solution is composed of two applications:
‣ A web crawling application that scrapes product data
‣ An API application that serves the products
Solution at a glance You want to
‣ Crawl, scrape and index 100’s of millions of products daily
We help you
‣ Architect and build scalable crawling infrastructure that improves your data quality and reduces your infrastructure costs

White Paper | eCommerce Crawling & Scraping Infrastructure
The web crawling application
Because requirements can vary from customer-to-customer and the available data varies from retailer-to-retailer, we’ve divided the crawling application that populates the database with product data from eCommerce websites into eight configurable de-coupled steps.
1) Crawl eCommerce websites
We start with a list of eCommerce URLs that you provide via API or spreadsheet (if you only have a limited number of websites you’d like us to crawl). Then, we identify and store a list of product URLs and product meta data for each eCommerce website.
‣ A breadth-first search (BFS) or a Depth-first search (DFS) — based on the situation — crawl ensures that we generate a complete list of all URLs belonging to each eCommerce website
‣ Jobs are run in parallel using event loops
‣ Product URLs are identified, stored along with the metadata in the data store and placed into a Queue for batch processing
‣ PhantomJS is a headless browser we use to crawl some HTTPS websites
‣ Our crawler framework provides the ability to configure the maximum concurrent requests to a particular retailer to avoid DOS attacks
‣ Sites like amazon.com can handle 50 or more requests per second, but less established sites like fancy.com can only handle 1-5 requests per second
‣ Our exception management system enables developers to easily debug crawlers when they fail
‣ Asynchronous
‣ Separate log file for errors
‣ Tagged with job-id, retailer-id and URL
‣ Stored to the disk in the database
2) Fetch product pages
In this phase, the web crawling application grabs the next product URL from the Queue and fetches the HTML for each product page with an HTTP request.
‣ We use workers to fetch the HTML for each product page
‣ The HTML is compressed and stored to the disk
‣ We utilize Amazon S3 as the database to store the HTML pages for each retailer
3) Fetch images
A separate process parses the HTML pages and fetches each product’s images, which are processed and stored in Amazon S3. A configurable job can batch process all the product images to normalize image type and size. By normalizing all the product images, users in developing countries with slower average internet speeds will experience faster page loads.
4) Business logic (mining)
A separate worker / daemon fetches the HTML pages from the data store and extracts the required fields. We utilize a standardized data model like STEP to map the data extracted from each HTML product page to the database. Once extracted, the data is stored in a data store.
5) Check product prices
The price check process enables us to track the price of a specific product on an eCommerce website over time. It can be configured to check the price of a product as often as every day, so you can tell your customers the moment a product goes on sale. This is a separate process that fetches the price from the HTML pages and updates the data store.
White Paper | eCommerce Crawling & Scraping Infrastructure
6) Link products across retailers
To enable you to offer price comparison features like shopzilla.com and Google Shopping, we use several different variables to determine the probability that two products are the same. We start by looking for the manufacturer’s product ID in the meta data and HTML scraped from each site. If the retailer creates their own SKU numbers for each product, we’ll do entity recognition on the product title. We’ll continue to add variables until we achieve an acceptable statistical confidence that two products are the same. A relationship is created in the data store once we’re confident that we’ve found the same product sold at multiple retailers.
7) Update products
Because the processes are decoupled, we can update the entire product catalog from an eCommerce retailer as often as once a day.
8) Exception handling
All errors are logged and stored in a temporary data store so the errors can be easily reviewed and fixed. Errors are tagged with job-id, phase (crawl, fetch, mine), URL, and message.
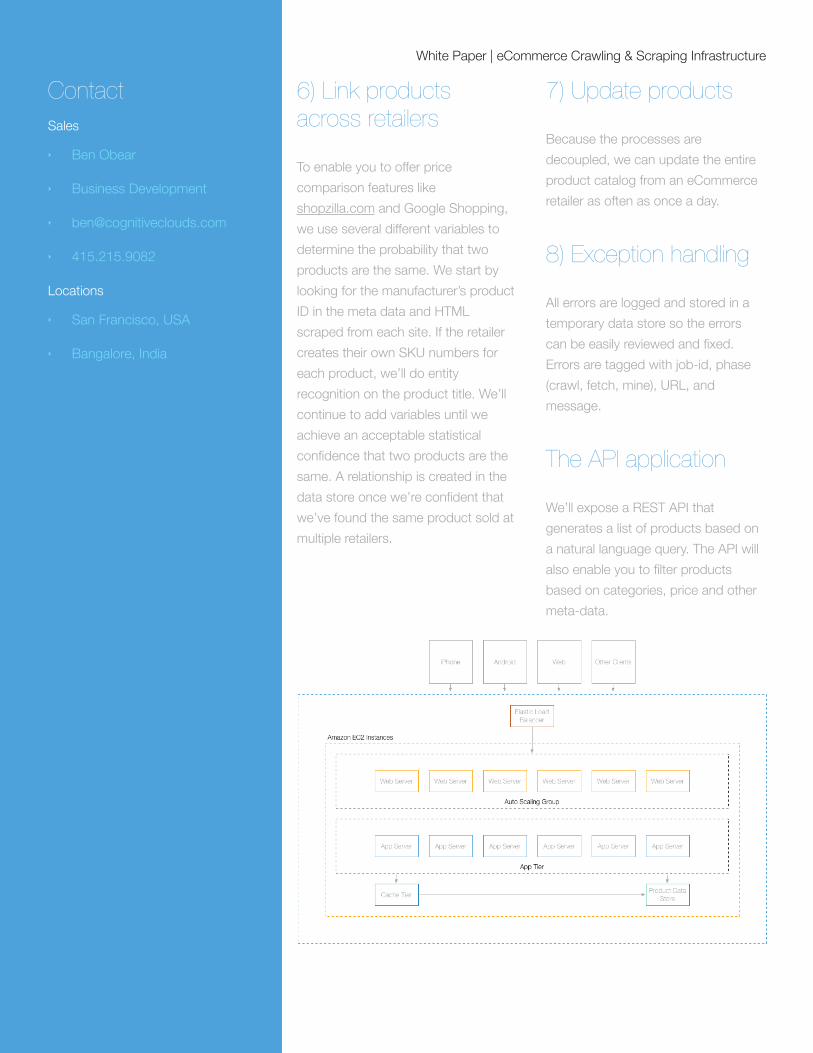
The API application
We’ll expose a REST API that generates a list of products based on a natural language query. The API will also enable you to filter products based on categories, price and other meta-data.
Contact Sales
‣ Ben Obear
‣ Business Development
‣ 415.215.9082
Locations
‣ San Francisco, USA
‣ Bangalore, India

Case Study | First Version Native Mobile Apps for Yatra
Proposal v01
We’re not just another app developer. We create connected experiences that stick.
CognitiveClouds’ team has worked on complex stuff like database B-trees, document management systems, compilers, security systems, operating systems, video platforms, telecom switches, mobile risk management platforms and enterprise applications.
We utilize a mobile first engineering methodology to craft robust products your users love. Products we build are always production-ready, which means you can base your decision to go live on business factors and not technical ones.
PROCESS Our agile development process is proven with distributed teams. DISCOVER Meet face-to-face with your team and ensure they understand your vision. We evaluate technologies. PLAN We deliver a project plan and technical architecture. PROTOTYPE We deliver a functional prototype with your product’s core features. SHIP Receive weekly product builds as we add features and optimize. Your product goes live. LEARN We measure analytic and user feedback and prioritize iterations. MAINTAIN Our operations team maintains and upgrades your infrastructure.
COMMUNICATION Excellent communication ensures timely completion of deliverables. TEAM STRUCTURE Your product manager is your main point of contact. After kickoff, you’re encouraged to maintain the relationship you’ve built with your technical lead and software engineers. TEAM LOCATION People on your team are located in the USA and India. DAILY SCRUMS Participate in daily scrums to provide input or gain visibility. SPRINT BUILDS After prototype completion, get weekly product builds. TOOLS We use cloud productivity tools like Basecamp for communication and Pivotal Tracker for Scrum user stories.
PARTNERSHIP As a partner, our success is dependent upon your success. LONG-TERM All engagements start with the goal of building a long-term relationship with you and your team. Your best interests are in mind when we provide advice and strategic recommendations. EXTENDED-TEAM Our team is your team and that’s why we recommend you meet face-to-face with the people building your product. BEST IDEAS We share our best ideas to help you build a better product. SUCCESS METRICS Success is measured by how the product we build is received by your customers. When you meet your goals, we meet our goals.
DISCOVER MAINTAINPLAN PROTOTYPE SHIP LEARN
Company Overview