coling 2016
TRANSCRIPT

THE 26TH INTERNATIONAL CONFERENCE ON COMPUTATIONAL LINGUISTICSDECEMBER 11-16, 2016OSAKA, JAPAN

COLING 2016

STATISTICS
• 3rd CoLing in Japan after Tokyo & Kyoto• ~1100 presenters in total• Almost 400 students
• 1039 papers submitted• 32% acceptance rate• 337 accepted papers• 135 presentations• 202 posters
• ~25% neural network papers

AREA-WISE ACCEPTANCE RATES
Area Total submissi
ons
Total (%) accepted
Paraphrasing, Textual Entailment 32 9 (28%)Sentiment Analysis, Computational Argumentation 85 22 (26%)Information Retrieval, Information Extraction, Question Answering
126 26 (21%)
Applications 76 28 (37%)Dialog Processing and Dialog Systems, Multimodal Interfaces
29 12 (41%)
Speech Recognition, Text-to-Speech, Spoken Language Understanding
24 11 (46%)
Machine Translation 88 31 (35%)Resources, Software and Tools 56 25 (45%)Under-resourced Languages 33 16 (48%)

ROBOTS

QUOTES
• Probably the last PBMT paper ever• People working on digital humanities don't really know what digital
humanities are…• Kids learn language having heard a very small amount – to further
advance AI we need to focus on low resourced conditions instead of big data• Home Made Restaurant Warmly• to make by hand taste


HYTRA 6SIXTH WORKSHOP ON HYBRID APPROACHES TO TRANSLATION

KEYNOTE: MARK SELIGMAN, SPOKEN TRANSLATION, INC.PERCEPTUALLY GROUNDED DEEP SEMANTICS IN FUTURE HYBRID MACHINE TRANSLATION
Nine Issues in Speech Translation– Discourse
– Speech acts– Topic tracking
– Domain– Prosody
– Pauses– Pitch, stress
– Translation mismatches– System architecture, data
structures
Improve Statistical MT
• User feedback + machine learning• More, better data• Parsing > hybrid MT

KEYNOTE: MARK SELIGMAN, SPOKEN TRANSLATION, INC.PERCEPTUALLY GROUNDED DEEP SEMANTICS IN FUTURE HYBRID MACHINE TRANSLATION
車_car
を_obj
運転_driving
する_do
人_person
Syntactic structure
NPVP
Semantic structure
PP V
N NP VN V
drive
person
person
car
mod
agt
obj
The Return of Semantics: Interlingua/Ontologies Grounded Semantics

MAIN CONFERENCEKEYNOTES:JOAKIM NIVRE, REIKO MAZUKA, DINA DEMNER-FUSHMAN, SIMONE TEUFEL

JOAKIM NIVREUPPSALA UNIVERSITY, SWEDEN
Universal Dependencies - Dubious Linguistics and Crappy Parsing?• Maximize parallelism – but don’t overdo it
• Don’t annotate the same thing in different ways• Don’t make different things look the same• Don’t annotate things that are not there
• Universal taxonomy with language-specific elaboration• Languages select from a universal pool of categories• Allow language-specific extensions

JOAKIM NIVREUPPSALA UNIVERSITY, SWEDEN
Manning's law1. UD needs to be satisfactory on linguistic analysis grounds for individual languages.2. UD needs to be good for linguistic typology, i.e., providing a suitable basis for bringing out
cross-linguistic parallelism across languages and language families.3. UD must be suitable for rapid, consistent annotation by a human annotator.4. UD must be suitable for computer parsing with high accuracy.5. UD must be easily comprehended and used by a non-linguist, whether a language learner
or an engineer with prosaic needs for language processing.6. UD must support well downstream language understanding tasks (relation extraction,
reading comprehension, machine translation, …).

JOAKIM NIVREUPPSALA UNIVERSITY, SWEDEN
Dubious linguistics?• Lexical dependencies and functional relations encoded in a single tree• Grounded in linguistic typology and dependency grammar traditionsCrappy parsing?• Not so bad with existing parsers, especially for cross-lingual parsing• Learn richer parsing models grounded in linguistic typology

REIKO MAZUKARIKEN BRAIN SCIENCE INSTITUTE, JAPAN
• 12month old babies are called 'old babies‘
• Medical stuff has lots of data, lots of problems
• … let alone …
DINA DEMNER-FUSHMANU.S. NATIONAL LIBRARY OF MEDICINE, U.S.A.
SIMONE TEUFELUNIVERSITY OF CAMBRIDGE, U.K.

PRESENTATIONSMAIN CONFERENCE

CHARNER: CHARACTER-LEVEL NAMED ENTITY RECOGNITIONOnur Kuru, Ozan Arkan Can, Deniz Yuret• Stacked bidirectional LSTMs• inputs characters• outputs tag probabilities for each character
• Probabilities are then converted to word level named entity tags using a Viterbi decoder• Close to state-of-the-art NER performance in seven languages with the same
basic model using only labeled NER data and no hand-engineered features or other external resources like syntactic taggers or Gazetteers

WHAT TOPIC DO YOU WANT TO HEAR ABOUT? A BILINGUAL TALKING ROBOT USING ENGLISH AND JAPANESE WIKIPEDIASGraham Wilcock, Kristiina Jokinen

PHRASE-BASED MACHINE TRANSLATION USING MULTIPLE PREORDERING CANDIDATES
Yusuke Oda, Taku Kudo, Tetsuji Nakagawa, Taro Watanabe

INTERACTIVE ATTENTION FOR NEURAL MACHINE TRANSLATIONFandong Meng, Zhengdong Lu, Hang Li, Qun Liu

INTERACTIVE ATTENTION FOR NEURAL MACHINE TRANSLATIONFandong Meng, Zhengdong Lu, Hang Li, Qun Liu• Models the interaction between the decoder and the
representation of source sentence during translation by both reading and writing operations• Can keep track of the interaction history and therefore
improve the translation performance

SUB-WORD SIMILARITY BASED SEARCH FOR EMBEDDINGS: INDUCING RARE-WORD EMBEDDINGS FOR WORD SIMILARITY TASKS AND LANGUAGE MODELLING
Mittul Singh, Clayton Greenberg, Youssef Oualil, Dietrich Klakow• Training good word embeddings requires large amounts of data.
Out-of-vocabulary words will still be encountered.• Existing methods use computationally-intensive morphological
analysis to generate embeddings• The proposed system applies a computationally-simpler sub-word
search on words that have existing embeddings• Up to 50% reduction in rare word perplexity in comparison to other
more complex language models

MULTI-ENGINE AND MULTI-ALIGNMENT BASED AUTOMATIC POST-EDITING AND ITS IMPACT ON TRANSLATION PRODUCTIVITYSantanu Pal, Sudip Kumar Naskar, Josef van Genabith• Parallel system combination in the APE stage of a sequential
MT-APE combination • Substantial translation improvements • automatic evaluation (+5.9%) • productivity in post-editing (21.76%)
• System combination on the level of APE alignments yields further improvements

POSTERSMAIN CONFERENCE

Achieves the state-of-the-art conversion Fscore 95.6





IMPROVING ATTENTION MODELING WITH IMPLICIT DISTORTION AND FERTILITY FOR MACHINE TRANSLATION

BEST PAPERS2+1

PREDICTING HUMAN SIMILARITY JUDGMENTS WITH DISTRIBUTIONAL MODELS: THE VALUE OF WORD ASSOCIATIONS Simon De Deyne, Amy Perfors, Daniel J Navarro• Internal language models, that are more closely aligned to
the mental representations of words• Count based model for text corpora• Predicting structure from text corpora using word embeddings• Count based model for word associations• A spreading activation approach to semantic structure
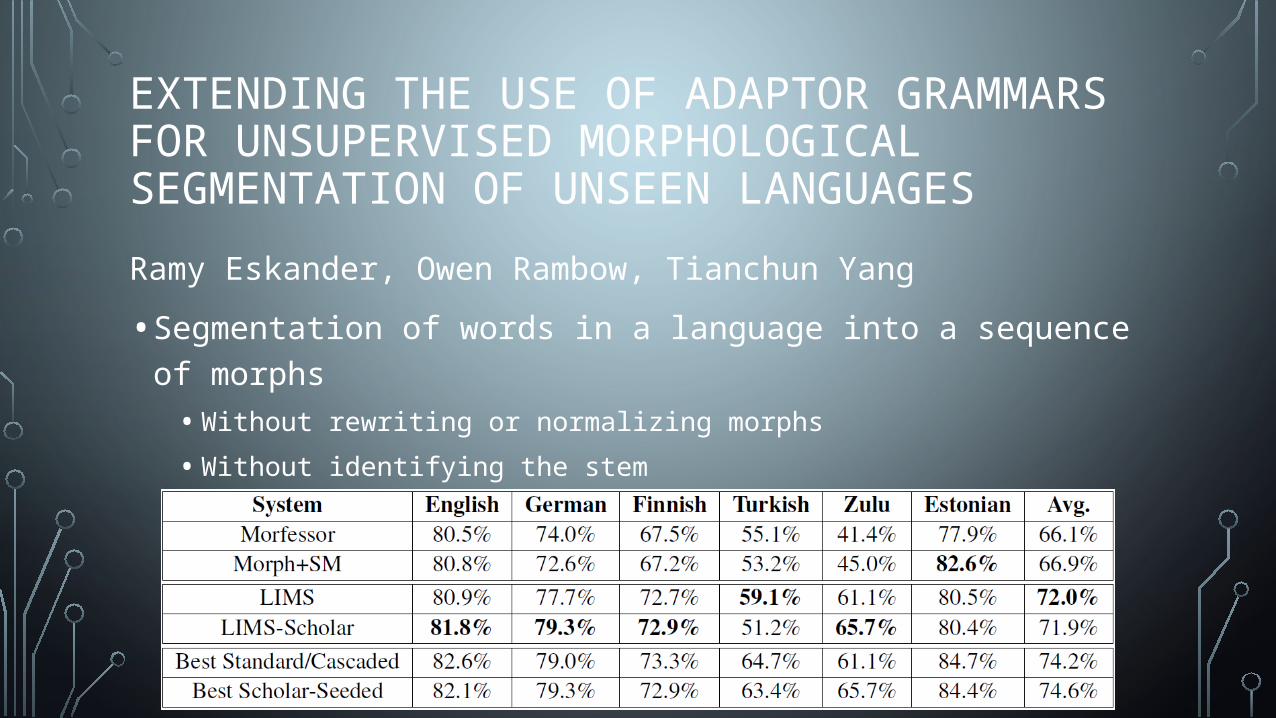
EXTENDING THE USE OF ADAPTOR GRAMMARS FOR UNSUPERVISED MORPHOLOGICAL SEGMENTATION OF UNSEEN LANGUAGESRamy Eskander, Owen Rambow, Tianchun Yang• Segmentation of words in a language into a sequence of
morphs• Without rewriting or normalizing morphs• Without identifying the stem• Without identifying morphological features

KEYSTROKE DYNAMICS AS SIGNAL FOR SHALLOW SYNTACTIC PARSING Barbara Plank• Runnuer-up for best paper

WHAT’S NEXTFUTURE COLING

2018
COLING 2018• Santa Fe, New Mexico, USA• August 20-25, 2018
LREC 2018• Miyazaki, Japan• May 7-12, 2018

LESS COLING & MORE OSAKAHTTP://LIELAKEDA.LV HTTP://EJ.UZ/COLING2016