collaborative science: a case study and model andy packard, michael frenklach mechanical engineering...
TRANSCRIPT

Collaborative Science: a case study and model
Andy Packard, Michael FrenklachMechanical Engineering
jointly with Ryan Feeley and Trent Russi
University of CaliforniaBerkeley, CA
Presented 10/28/2005 at CITRIS, Berkeley campusSupport from NSF grants: CTS-0113985 and CHE-0535542
Copyright 2005, Packard, Frenklach, Feeley, and, Russi. This work is licensed under the Creative Commons Attribution-ShareAlike License. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/2.0/ or send a letter to Creative Commons, 559 Nathan Abbott Way, Stanford, California 94305, USA.

Collaborators Pete Seiler (UCB, Honeywell)Adam Arkin and Matt Onsum (UCB)Greg Smith (SRI)
GRI-Mech Team: Michael Frenklach, Hai Wang, Michael Goldenberg, Nigel Moriarty, Boris Eiteener, Bill Gardiner, Huixing Yang, Zhiwei Qin, Tom Bowman, Ron Hanson, David Davidson, David Golden, Greg Smith, Dave Crossley
PrIMe Team: UCB: Michael Frenklach, Andy Packard, Zoran Djurisic, Ryan Feeley, Trent Russi, Tim SuenStanford: David Golden, Tom Bowman, …MIT: Bill Green, Greg McRae, …EU: Mike Pilling, …NIST: Tom Allision, Greg Rosasco, …ANL: Branko Ruscic, …CMCS…
Support from NSF grants: CTS-0113985 (ITR, 2001-2005)CHE-0535542 (CyberInfrastructure, 2005-2010)

Collaborative Science
Limit “science” to mean mechanism understanding through modeling and experimentation for the purpose of prediction
Applicability:–chemical kinetics modeling
–atmospheric chemistry modeling
–…
–systems biology
Goal of “collaboration”: quantify the joint information implicit in the community’s research portfolio.–Portfolio: diverse, and individually generated
–observed facts about behavior–parametrized models which explain/govern behavior
Quantification achieved through dissemination and discourse.–But dissemination of what and by what means?
focus on
Process models are complex, though physics based governing equations are widely accepted
Uncertainty in process behavior exists, but much is known regarding “where” the uncertainty lies in the governing equations (uncertain parameters)
Numerical simulations of process, with uncertain parameters “fixed” to certain values, may be performed “reliably”
Processes are studied experimentally in labs

Methane Combustion: CH4 + 2 O2 CO2 + 2 H2O
Methane reaction models have grown in complexity over time with the aim of improving predictions.
(~1970): 15 elementary reactions with 12 species
(~1980): 75 elementary reactions with 25 species
(Now): 300+ elementary reactions, 50+ species. Used to predict heat release and concentrations over a wide scale, from work production to pollutant formation.–ODE model called “GRI-Mech 3.0”
–several releases, now static…–used as a common benchmark Pathway diagram for methane combustion [Turns]

How did the GRI-Mech come about?
Each of the GRI-Mech ODE releases embody the work of many people, but not explicitly working together. How did the successful collaboration occur?
Informal mode?– assimilate conclusions of each paper sequentially– “read my paper”– “data is available on my website”
No. Didn’t/Doesn’t work – community tried it, but predictive capability of model did not reliably improve as more high-quality experiments were done.
– Papers tend to lump modeling and theory, experiments, analysis and convenience assumptions, leading to a concise text-based conclusion
– Conclusions are conditioned on additional assumptions necessary to make the conclusion concise.
– Impossible to anonymously “collaborate" since the convenience assumptions are unique to each paper.
– Goals of one paper are often the convenience assumptions of another.– Difficult/impossible to trace the quality of a conclusion reached sequentially
across papers– Posted data is often the text-based conclusion in e-form, little additional
information
authors stake professional reputation on these…
but if really, really pressed, perhaps not these

Traditional Reporting of Experimental ResultsThe canonical structure of a technical report (a paper) is:
• Description of experiment: apparatus, conditions, measured observable– flow-tube reactors, laminar premixed flames, ignition delay, flame speed
• Care in eliminating unknown biases, and assessing uncertainty in outcome measurement
• Informal description of transport and chemistry models that involve uncertain parameters
– momentum, diffusion, heat transfer
– 10-100’s reactions, uncertainty in the rate constant parameters
k(T)=ATn exp(-E/RT)
• Focus on parameter(s) resulting in high sensitivities on the outcome– evaluate (numerical sims) sensitivities at nominal parameter values
• Convenience assumptions on parameters not being studied– freeze low-sensitivity parameters at “nominal” values (obtained elsewhere)
• Predict one or two parameter values/ranges• Post values on website (rarely models, rarely “raw” data)
the science aspect

-1
-0.5
0
0.5
1
-1 -0.5 0 0.5 1
-1
-0.5
0
0.5
1
The most influential (linearized, at nominal) parameter for models 66 and 67 happens to be ρ44 (2nd most influential is ρ45). Look at slices of the feasible set for experiments 66 and 67 (all other parameters set to nominal). Following the simplistic paradigm…
Consequence: Mistakes and Artificial Controversies
E66 reports 0.3 ≤ ρ44 ≤ 1.0.
E67 reports -1.0 ≤ ρ44 ≤ 0.15,
which is a direct conflict…
or, perhaps E67 considers both 44 and 45 and then reads report E66. After doing so
E67 reports 0.2 ≤ 45 ≤ 1.0…
or, perhaps noting that for any α, 44=45= α is consistent with the data, so
E67 reports nothing!
In any case, all such reports are wrong!
A higher dimensional slice (but still a slice!), now including parameter ρ34 illustrates the inaccuracy.
Key problem: Geometry of feasible set (not a coordinate-aligned cube) is unappreciated.
E66
E67
ρ44
ρ45
ρ34
ρ44ρ45

Lessons LearnedChemical kinetics modeling is a form of
– high dimensional (mechanisms are complex),
– distributed (efforts of many, working separately)
system identification.
The effort of researchers yields complex, intertwined, factual assertions about the unfalsified values of the model parameters
– Handbook style of {parameter, nominal, range, reference} will not work
– Each individual assertion is usually not illuminating in the problem’s natural coordinates. Concise individual conclusions are actually rare.
– Information-rich, “anonymous” collaboration is necessary
– Machines must do the heavy lifting.
• Managing lists of assertions, reasoning and inference
– Useful role of journal paper: document methodology leading to assertion
The GRI-Mech approach departed from the informal mode– used all of the same information (but none of the “conclusions”)
– in a distributed fashion, successfully derived a model…
– but, it was a grassroots effort; an organized, community-wide effort/participation is needed now

Alternate model: Separate asserted facts from analysis
Two types of assertions: models and observed behavior – Assertion of models of physical processes (e.g., “if we knew the
parameter values, this parametrized mathematics would accurately model the process”)
– Assertion of measured outcomes of physical processes (e.g., “I performed experiment, and the process behaved as follows…”)
Together, these form constraints in "world"-parameter space of physical constants.
Analysis (global optimization) on the constraints– Check consistency of a collection of assertions
• Sensitivity of consistency to changes in a single assertion
• Discover highly informative (or highly suspect) assertions
– Explore the information implied by the assertions
• Prediction: determine possible range of different scalar functions on the feasible set
– (old standby) Generate parameter samples from the feasible set.
Data Collaboration

GRI-Mech: Successful Data Collaboration
Result:High quality, predictive Methane reaction model: 50+ Species/300+ Reactions
Based on:77 peer-reviewed, published Experiments/Measured Outcomes of ~25 groups
Infrastructure to use these did not exist– Grassroots effort of 4 groups– Decide on a common, “encompassing” list of species/reactions– Extract the information in each paper, not simply assimilate conclusions– Reverse-engineer assertions in light of the common reaction model
The rest was relatively “easy”– Optimization to get “best” fit single parameter vector– Validation (on ~120 other published results)
Features (www.me.berkeley.edu/gri_mech)– Only use "raw" scientific assertions - not the potentially erroneous conclusions
– “give me your information, not your conclusions…”– Treats the models/experiments as information, and combines them all.– Addresses the "lack-of-collaboration" in the post experimental data processing.– With the assertions now in place, much more can be inferred…
eliminating the incompatible convenience assumptions

GRI DataSet
d2 u2 d77 u77
d1 u1
300+ Reactions,50+ Species
Process P1
ProcessP2
ProcessP77
The GRI-Mech (www.me.berkeley.edu/gri_mech) DataSet is collection of 77 experimental reports, consisting of models and ``raw'' measurement data, compiled/arranged towards obtaining a complete mechanism for CH4 + 2O2 → 2H2O + CO2 capable of accurately predicting pollutant formation. The DataSet consists of:• Reaction model: 53 chemical species, 325 reactions, depending on…• Unknown parameters (): 102 active parameters, essentially the various rate constants. • Prior Information: Each normalized parameter is presumed known to lie between -1 and 1.• Processes (Pi): 77 widely trusted, high-quality laboratory experiments, all involving methane combustion, but under different physical manifestations, and different conditions.
• Process Models (Mi): 77 0-d, 1-d and 2-d numerical PDE models, coupled with the common reaction model.• Measured Data (di,ui) data and measurement uncertainty from 77 peer-reviewed papers reporting above experiments.
CH4 + 2O2
↓2H2O + CO2
•kth assertion associated with prior info:
•Assertions associated with ith dataset unit:
The prior information, models and measured data constitute assertions about possible parameter values.
100+ unknown parameterseach has -1≤ρk≤1
Chemistry() Transport 1M1()
Chemistry() Transport 2M2()
Chemistry() Transport 77M77()
Research portfolio expressed as deterministic constraintsSuitable for analysis, generally optimization over these

Opposition
There were/are criticisms of the overall GRI-Mech approach.– “I am unwilling to rely on flame measurements and optimization to extract some
fundamental reaction's properties -- I prefer to do that by isolating phenomena”– “No one can analyze my data better than me.”– “It's too early -- some fundamental knowledge is still lacking”
Causes for objection– engineering/science distinction– distributed effort dilutes any one specific contribution– protection of individual’s territory
Opposition to the GRI ODE release– “Not all relevant data was used to get the latest GRIMech release”– “The result (one particular rate constant) differs from my results”
Our perspective – deploy the data and the tools– let everyone “mine” the community information to uncover hidden reality – value will entice groups to contribute new assertions as they emerge– illustrate concepts with familiar examples

Manual management of uncertainty propagation
Informal, manual (journal paper/email) mode would require an efficient uncertainty description (linear in number of model parameters, say).
– But this is easy to do this wrong…– How about consistent, but simple?
For this, use “CRC-Handbook” type description:
– parameter values– plus/minus uncertainty
Equivalent to requiring a coordinate-aligned cube to contain feasible set.
Very ineffective in extracting the predictive capability of GRI data: ie., using assertions to predict the outcome (a range) of another model
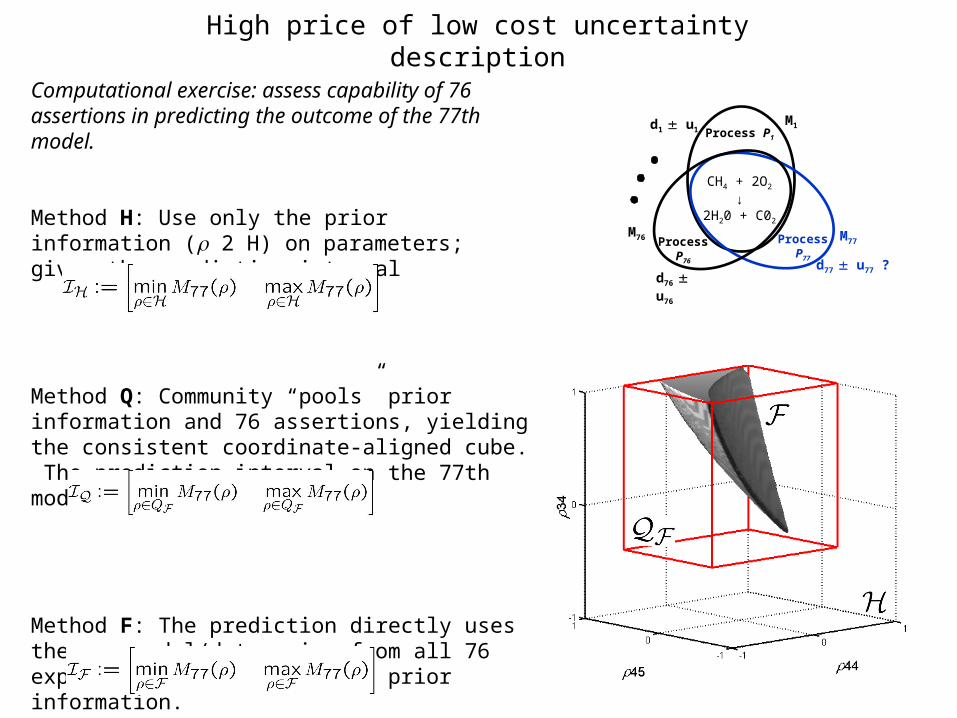
Computational exercise: assess capability of 76 assertions in predicting the outcome of the 77th model.
Method H: Use only the prior information ( 2 H) on parameters; gives the prediction interval
Method Q: Community “pools” prior information and 76 assertions, yielding the consistent coordinate-aligned cube. The prediction interval on the 77th model using this is
Method F: The prediction directly uses the raw model/data pairs from all 76 experiments, as well as the prior information.
High price of low cost uncertainty description
d1 u1 Process P1
CH4 + 2O2
↓2H20 + C02
d77 u77 ?
ProcessP77
M77
M1
d76 u76
ProcessP76
M76
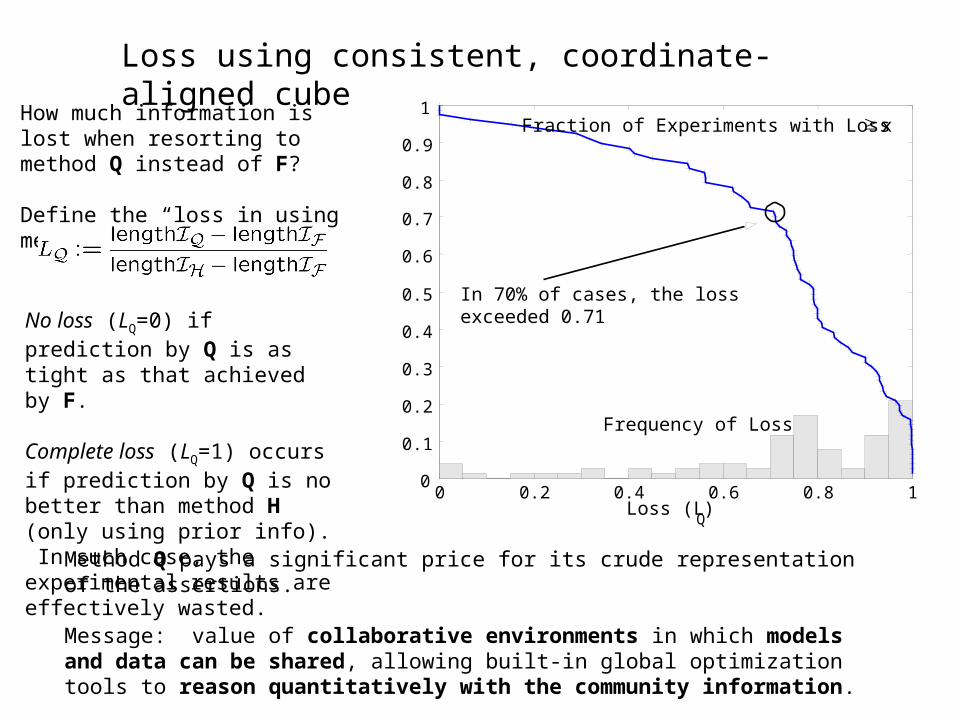
How much information is lost when resorting to method Q instead of F?
Define the “loss in using method Q''
No loss (LQ=0) if prediction by Q is as tight as that achieved by F.
Complete loss (LQ=1) occurs if prediction by Q is no better than method H (only using prior info). In such case, the experimental results are effectively wasted.
Method Q pays a significant price for its crude representation of the assertions.
Message: value of collaborative environments in which models and data can be shared, allowing built-in global optimization tools to reason quantitatively with the community information.
Loss using consistent, coordinate-aligned cube
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Loss (LQ
)
Fraction of Experiments with Loss x
Frequency of Loss
In 70% of cases, the loss exceeded 0.71

0 20 40 60 800
0.1
0.2
0.3
0.4
0.5
Experiment #
0 20 40 60 80 1000
0.1
0.2
0.3
0.4
0.5
Parameter # Experiment #0 20 40 60 80
0
0.1
0.2
0.3
0.4
0.5
Consistency results for GRI-DataSet assertions
Collection of 77 assertions is consistent.
Nevertheless, a quantitative consistency measure was found to be very sensitive (using multipliers from the dual form) to 2 particular experimental assertions, but not to the prior info.
0 20 40 60 80 1000
0.1
0.2
0.3
0.4
0.5
Parameter #
The scientists involved rechecked calculations, and concluded that reporting errors had been made.
Both reports were updated -- one measurement value increased, one decreased -- exactly what the consistency analysis had suggested (but without us telling them that).
Sensitivity of the consistency measure to individual assertions is greatly reduced, and spread more evenly across data set.

PrIMe: Process Informatics Model (www.primekinetics.org)
Combustion impacts everything– Economies– Politics– Environment
Predictive capability leads to informed decisions and policymaking
PrIMe: A community activity aimed at the development of predictive reaction models for combustion
Challenge– to meet immediate needs for predictive reaction models in combustion
engineering, the petrochemical industry, and pharmaceuticals– build reaction models in a consistent and systematic way incorporating all
data and including all members of the scientific community
Theme– "The scientific community builds the Process Informatics System and
Process Informatics builds the community“

I have an idea of how to measure the elusive reaction between C14H7
and C3H3 forming C16H8 and CH2. What impact would such a measurement have on the three competing hypotheses concerning the nucleation of interstellar dust?
If the rate coefficient is established to within 3% accuracy, I will be able to discriminate between hypotheses A and B.
I do not think my experiment can attain better that 10% accuracy. What is the next best thing I can do experimentally to advance knowledge of this subject?
Measure the reaction between C10H7 and C3H2; I can then discriminate between hypotheses B and C.
Chemist to PrIMe
PrIMe to Chemist
Chemist to PrIMe
PrIMe to Chemist
Sometime in 2008…
What fueling rate produces peak output power while holding NOx yields within the EPA prescribed limits in a HCCI engine running GTLprescribed fuel #22 with design and operating parameters: xx, yy, ...…
Engineer to PrIMe
Sometime in 2010…
How much longer will there be an Antarctic ozone hole?
…
Policymaker to PrIMe
Sometime in 2020…
PrIMe to Engineer
PrIMe to Policymaker

PrIMe
Theoretician
Experimentalist
Physical Modeler
Scientific Computing
Numerical Analyst
elements
species
reactions
experiments
tools
numerical models
Contributors
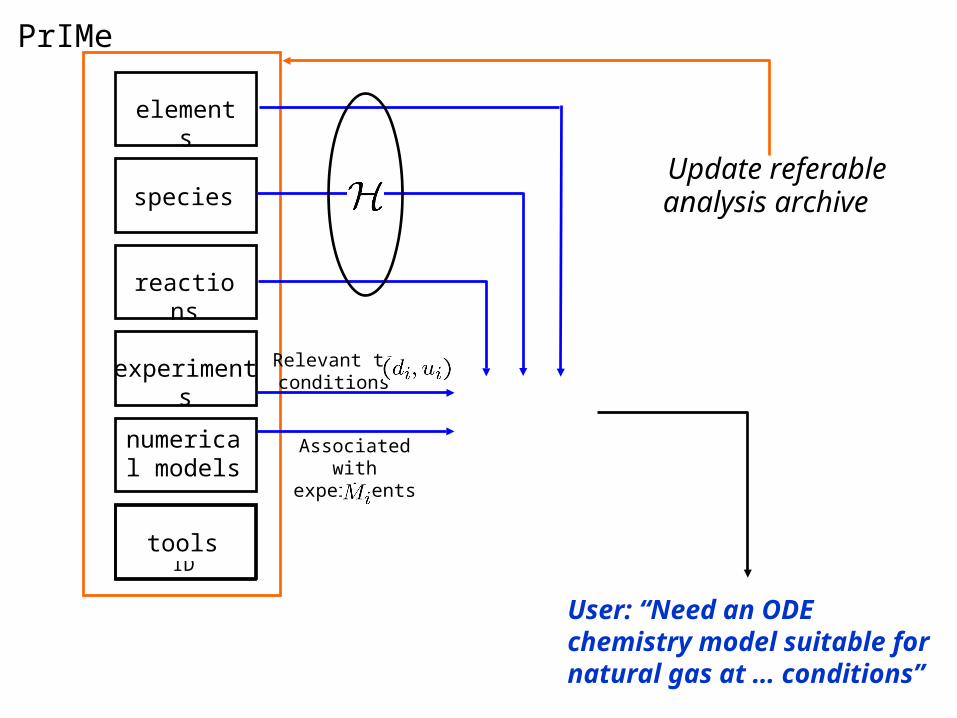
Parameter IDtools
PrIMe
elements
species
reactions
experiments
numerical models
User: “Need an ODE chemistry model suitable for natural gas at … conditions”
Relevant to conditions
Associated with experiments
Update referable analysis archive

Consistency Analysistools
PrIMe
elements
species
reactions
experiments
numerical models
User: “Check joint consistency of these experiments”
Associated with experiments
Update referable analysis archive
Specified by user

prediction
PrIMe
elements
species
reactions
experiments
tools
numerical models
User: “Predict range of ozone concentration at 40Km using NOAA model, using experiments …”
Specified by user
Associated with experiments
Update referable analysis archive
NOAA model

Alliance for Cellular Signaling (AfCS) Similar origin to GRI Mech – a few people, frustrated by the uncoordinated, tunnel vision (deliberately leaving out interactions for simplicity sake) of the signaling community
– brainchild of Gilman (UT Southwestern Medical Center)– saw the need for a large-scale examination/treatment of the problem
10 laboratories investigating basic questions in cell signaling– How complex is signal processing in cells?– What is the structure and dynamics of the network?– Can functional modules be defined?
Key Advantage of AfCS:– High quality data from single cell type– All findings/data available to signaling community (www.signaling-gateway.org)
from Henry Bourne, UCSF “The collaboration itself is the biggest experiment of all. After all, the scientific culture of biology is traditionally very individualistic and it will be interesting to see if scientists can work as a large and
complex exploratory expedition.” (http://www.nature.com/nature/journal/v420/n6916/full/420600a.html)
Vision paper in Nature talks about socialistic aspects of science (http://www.nature.com/nature/journal/v420/n6916/full/nature01304.html)

Calcium Signaling Application
Together with AfCS scientists, we extracted key, relevant features of calcium response to create 18 experimental assertions– Rise time, peak value, fall time
– 6 different stimuli levels
Published models constitute various model assertions– Goldbeter, Proc. Natl. Acad Sci. 1990
– Wiesner, American J. Physiology. 1996
– Lemon, J. Theor. Biology, 2003
Models are ODEs, each derived from the hypothesized network

Calcium Signaling Application
Results– Goldbeter, 6 states, 20 parameters, invalidated 30 minutes
– Wiesner, 8 states, 27 parameters
• 10 node “machine”
• Invalidated in 2 days
– Lemon, 8 states, 34 parameters
• Same 10-node cluster
• Feasible points found in ~8 hours
• New additional data led to invalidation
Conclusion: likely that more proteins and accompanying interactions are necessary to mathematically describe the signaling pathway.
These tools (eg., model-directed experimentation) were not part of the original AfCS mission, but the alliance is acquiring an appreciation of modeling and verification.

How are we computing? Invalidation Certificates
Consider invalidating the constraints (prior info, and N dataset units)
The invalidation certificate is a binary tree, with L leaves. At the i’th leaf – coordinate-aligned cube
– collection of polynomial (surrogate) models and error bounds, which satisfy
– sum of squares certificate proving the emptiness of
Moreover Caveat: with each Mj relatively complex, these error bounds are generally heuristic,
implicitly assuming regularity in Mj

How are we computing? Invalidation Certificates
Why do emptiness proofs on the algebraic models?
Easier. The original problem was
Could derive invalidation certificates directly for the ODEs, in principle– ODE reachability analysis using barrier (Lyapunov) functions
• ODE solution cannot get within of for any value of
– Use sum of squares certificates to bound reachability
– Sufficient conditions using semidefinite programming
– For the methane model, the SDPs would be almost unimaginably large
– Perhaps a fresh look could reveal a new approach…
In its simplest form, think of Mj(ρ) as the response at a fixed time, of an ODE model (with parameters ρ) from a
fixed initial condition

Error bounds: pragmatic issues
Recall, at the i’th leaf – coordinate-aligned cube– collection of polynomial models and error bounds, which satisfy
Error bounds are estimated statistically.
They are more likely “reliable” if M is well-behaved. So, through: – experience, and– domain-specific knowledge
the scientist is responsible to design/select experiments/features that are– measurable in the lab– reasonably well-behaved over the parameter space
Random experimental investigations could break the analysis, and lead nowhere… therefore…
Prudent experiment selection is critical to success

How are we computing? Summary
Transforming real models to polynomial/rational models– Large-scale computer “experimentation” on M().
• Random sampling and sensitivity calculations to determine active parameters
• Factorial design-of-experiments on active parameter cube
– Polynomial or rational (just stay in Sum-of-Squares hierarchy) fit
– Assess residuals, account for fit error
Assertions become polynomial/rational inequality constraints
Most analysis is optimization subject to these constraints– S-procedure, sum-of-squares (scalable emptiness proofs, outer bounds)
• Outer bounds are also interpreted as solutions to the original problem when cost is an expected value, constraints are only satisfied on average, and the decision variable is a random variable.
– Off-the-shelf constrained nonlinear optimization for inner bounds
• Use stochastic interpretation of outer bounds to aid search
– Branch & Bound (or increase order) to eliminate ambiguity due to fit errors
– Message: Overall, straightforward and brute force, parallelizes rather easily

Dissemination
PapersPete Seiler, Michael Frenklach, Andrew Packard and Ryan Feeley, “Numerical approaches for collaborative data processing,” to appear Optimization and Engineering, Kluwer, 2005.
Ryan Feeley, Pete Seiler, Andy Packard and Michael Frenklach, “Consistency of a reaction data set,” Journal of Physical Chemistry A, vol. 108, pp. 9573-9583, 2004.
Michael Frenklach, Andrew Packard, Pete Seiler and Ryan Feeley, “Collaborative data processing in developing predictive models of complex reaction systems,” International Journal of Chemical Kinetics, vol. 36, issue 1, pp. 57-66, 2004.
Michael Frenklach, Andy Packard and Pete Seiler, “Prediction uncertainty from models and data,” 2002 American Control Conference, pp. 4135-4140, Anchorage, Alaska, May 8-10, 2002.
Project websiteSlides, drafts, notes, proposal and related links, etc can be found at
http://jagger.me.berkeley.edu/~pack/nsfuncertainty

Collaborative science: Conclusions
GRI Mech, AfCS and PrIMe are domain specific examples
Requires–Data sharing
–Model sharing
–Math tools to infer
Benefits–Roadmap to reliable prediction
–Information transfer between disciplines and scales
Present challenges–Community involvement and participation
–Privacy versus Open/Communityuser may be willing to contribute some data (models, tools, etc.) but also wants to use the community infrastructure to analyze proprietary data.
–Convenient infrastructure
Is a rich, large-scale, practical problem that improves the
consistency in which scientific results are used to make decisions
and set policy.