common design elements for data movement eli dart
TRANSCRIPT

Common Design Elements for Data Movement
Eli Dart, Network Engineer ESnet Science Engagement Lawrence Berkeley Na<onal Laboratory
Cosmology CrossConnects Workshop
Berkeley, CA
February 11, 2015

Overview
2/10/15 2
• Context • Design paJerns • What do we need to do?

Context
• Data-‐intensive science con<nues to need high-‐performance data movement between geographically distant loca<ons – Observa<on (or instrument) to analysis – Distribu<on of data products to users – Aggrega<on of data sets for analysis – Replica<on to archival storage
• Move computa<on to data? Of course! Except when you can’t… – A liquid market in fungible compu<ng alloca<ons does not exist – Users get an alloca<on of <me on a specific compute resource – if the data isn’t there already, it needs to be put there
– If data can’t be stored long-‐term where it’s generated, it must be moved – Other reasons too – the point is we have to be able to move Big Data
• Given the need for data movement, how can we reliably do it well?
2/10/15 3

The Task of Large Scale Data Movement
• Several different ways to look at a data movement task • People perspec<ve:
– I am a member of a collabora<on – Our collabora<on has accounts with compute alloca<ons and data storage alloca<ons at a set of sites
– I need to move data between those sites • Organiza<on/facility perspec<ve:
– ANL, NCSA, NERSC, ORNL and SDSC are all used by the collabora<on – All these sites must have data transfer tools in common – I must learn what tools and capabili<es each site has, and apply those tools to my task
• Note that the integra<on burden is on the scien<st!
2/10/15 4

Service Primi<ves
• There is another way to look at data movement • All large-‐scale data movement tasks are composed of a set of primi<ves
– Those primi<ves are common to most such workflows – If major sites can agree on a set of primi<ves, all large-‐scale data workflows will benefit
• What are the common primi<ves? – Storage systems (filesystems, tape archives, etc.) – Data transfer applica<ons (Globus, others) – Workflow tools, if automa<on is used – Networks
• Local networks • Wide area networks
• What if these worked well together in the general case? • Compose them into common design paJerns
2/10/15 5

The Central Role of the Network
• The very structure of modern science assumes science networks exist: high performance, feature rich, global scope
• What is “The Network” anyway? – “The Network” is the set of devices and applica<ons involved in the use of a remote resource • This is not about supercomputer interconnects • This is about data flow from experiment to analysis, between facili<es, etc.
– User interfaces for “The Network” – portal, data transfer tool, workflow engine – Therefore, servers and applica<ons must also be considered
• What is important? Ordered list: 1. Correctness 2. Consistency 3. Performance
© 2014, Energy Sciences Network 6 – ESnet Science Engagement ([email protected]) - 2/10/15

TCP – Ubiquitous and Fragile
• Networks provide connec<vity between hosts – how do hosts see the network? – From an applica<on’s perspec<ve, the interface to “the other end” is a socket
– Communica<on is between applica<ons – mostly over TCP
• TCP – the fragile workhorse – TCP is (for very good reasons) <mid – packet loss is interpreted as conges<on
– Packet loss in conjunc<on with latency is a performance killer – Like it or not, TCP is used for the vast majority of data transfer applica<ons (more than 95% of ESnet traffic is TCP)
© 2014, Energy Sciences Network 7 – ESnet Science Engagement ([email protected]) - 2/10/15

A small amount of packet loss makes a huge difference in TCP performance
Metro Area
Local (LAN)
Regional
Con<nental
Interna<onal
Measured (TCP Reno) Measured (HTCP) Theoretical (TCP Reno) Measured (no loss)
With loss, high performance beyond metro distances is essentially impossible
© 2014, Energy Sciences Network 8 – ESnet Science Engagement ([email protected]) - 2/10/15

Design PaGern – The Science DMZ Model
• Design paJerns are reusable solu<ons to design problems that recur in the real world – High performance data movement is a good fit for this – Science DMZ model
• Science DMZ incorporates several things – Network enclave at or near site perimeter – Sane security controls
• Good fit for high-‐performance applica<ons • Specific to Science DMZ services
– Performance test and measurement – Dedicated systems for data transfer (Data Transfer Nodes)
• High performance hosts • Good tools
• Details at hJp://fasterdata.es.net/science-‐dmz/
2/10/15 9

Context: Science DMZ Adop<on • DOE Na<onal Laboratories
– Both large and small sites – HPC centers, LHC sites, experimental facili<es
• NSF CC-‐NIE and CC*IIE programs leverage Science DMZ – $40M and coun<ng (third round awards coming soon, es<mate addi<onal $18M to $20M) – Significant investments across the US university complex, ~130 awards – Big shoutout to Kevin Thompson and the NSF – these programs are cri<cally important
• Na<onal Ins<tutes of Health – 100G network infrastructure refresh
• US Department of Agriculture – Agricultural Research Service is building a new science network based on the Science DMZ model – hJps://www.ro.gov/index?s=opportunity&mode=form&tab=core&id=a7f291f4216b5a24c1177a5684e1809b
• Other US agencies looking at Science DMZ model – NASA – NOAA
• Australian Research Data Storage Infrastructure (RDSI) – Science DMZs at major sites, connected by a high speed network – hJps://www.rdsi.edu.au/dashnet – hJps://www.rdsi.edu.au/dashnet-‐deployment-‐rdsi-‐nodes-‐begins
• Other countries – Brazil – New Zealand – More
2/10/15 10

Context: Community Capabili<es
• Many Science DMZs directly support science applica<ons – LHC (Run 2 is coming soon) – Experiment opera<on (Fusion, Light Sources, etc.) – Data transfer into/out of HPC facili<es
• Many Science DMZs are SDN-‐ready – Openflow-‐capable gear – SDN research ongoing
• High-‐performance components – High-‐speed WAN connec<vity – perfSONAR deployments – DTN deployments
• Metcalfe’s Law of Network U<lity – Value propor<onal to the square of the number of DMZs? n log(n)? – Cyberinfrastructure value increases as we all upgrade
2/10/15 11

Strategic Impacts • What does this mean?
– We are in the midst of a significant cyberinfrastructure upgrade – Enterprise networks need not be unduly perturbed J
• Significantly enhanced capabili<es compared to 3 years ago – Terabyte-‐scale data movement is much easier – Petabyte-‐scale data movement possible outside the LHC experiments
• 3.1Gbps = 1PB/month • (Try doing that through your enterprise firewall!)
– Widely-‐deployed tools are much beJer (e.g. Globus) • Raised expecta<ons for network infrastructures
– Scien<sts should be able to do beJer than residen<al broadband • Many more sites can now achieve good performance • Incumbent on science networks to meet the challenge – Remember the TCP loss characteris<cs – Use perfSONAR
– Science experiments assume this stuff works – we can now meet their needs
2/10/15 12

High Performance Data Transfer -‐ Requirements
• There is a set of things required for reliable high-‐performance data transfer – Long-‐haul networks
• Well-‐provisioned • High-‐performance
– Local networks • Well-‐provisioned • High-‐performance • Sane security
– Local data systems • Dedicated to data transfer (else too much complexity) • High-‐performance access to storage
– Good data transfer tools • Interoperable • High-‐performance
– Ease of use • Usable by people • Usable by workflows • Interoperable across sites (remove integra<on burden)
2/10/15 13

Long-‐Haul Network Status
• 100 Gigabit per second networks deployed globally – USA/DOE Na<onal Laboratories – ESnet – USA/.edu – Internet2 – Europe – GEANT – Many state and regional networks have or are deploying 100Gbps cores
• What does this mean in terms of capability? – 1TB/hour requires less than 2.5Gbps (2.5% of 100Gbps network) – 1PB/week requires less than 15Gbps (15% of 100Gbps network) – hJp://fasterdata.es.net/home/requirements-‐and-‐expecta<ons – The long-‐haul capacity problem is now solved, to first order
• Some networks are s<ll in the middle of upgrades • However, steady progress is being made
2/10/15 14

Local Network Status
• Many ESnet sites now have 100G connec<ons to ESnet – 2x100G: BNL, CERN, FNAL – 1x100G: ANL, LANL, LBNL, NERSC, ORNL, SLAC
• Capacity provisioning is much easier in a LAN environment
• Security requires aJen<on (see Science DMZ)
• Major DOE compu<ng facili<es have a lot of capacity deployed to their data systems – ANL: 60Gbps – NERSC: 80Gbps – ORNL: 20Gbps
• Big win if sites use Science DMZ model
2/10/15 15

Progress So Far
• There is a set of things required for reliable high-‐performance data transfer – Long-‐haul networks
• Well-‐provisioned • High-‐performance
– Local networks • Well-‐provisioned • High-‐performance • Sane security
– Local data systems • Dedicated to data transfer (else too much complexity) • High-‐performance access to storage
– Good data transfer tools • Interoperable • High-‐performance
– Ease of use • Usable by people • Usable by workflows • Interoperable across sites (remove integra<on burden)
2/10/15 16

Local Data Systems
• Science DMZ model calls these Data Transfer Nodes – Dedicated to high-‐performance data transfer tasks – Short, clean path to outside world
• At HPC facili<es, they mount the global filesystem – Transfer data to the DTN – Data available on HPC resource
• High-‐performance data transfer tools – Globus Transfer – Command-‐line globus-‐url-‐copy – BBCP
• These are deployed now at many HPC facili<es – ANL, NERSC, ORNL – NCSA, SDSC
2/10/15 17

Data Transfer Tools
• Interoperability is really important – Remember, scien<sts should not have to do the integra<on – HPC facili<es should agree on a common toolset – Today, that common toolset has a few members
• Globus Transfer • SSH/SCP/Rsync (yes, I know – ick!) • Many niche tools
• Globus appears to be the most full-‐featured – GUI, data integrity checks, fault recovery – Fire and forget – API for workflows
• Globus is also widely deployed – ANL, NERSC, ORNL – NCSA, SDSC (all of XSEDE) – Many other loca<ons
2/10/15 18

More Progress
• There is a set of things required for reliable high-‐performance data transfer – Long-‐haul networks
• Well-‐provisioned • High-‐performance
– Local networks • Well-‐provisioned • High-‐performance • Sane security
– Local data systems • Dedicated to data transfer (else too much complexity) • High-‐performance access to storage
– Good data transfer tools • Interoperable • High-‐performance
– Ease of use • Usable by people • Usable by workflows • Interoperable across sites (remove integra<on burden)
2/10/15 19

Mission Scope and Science Support
• Resource providers each have their own mission – ESnet: high-‐performance networking for science – ANL, NERSC, ORNL: HPC for DOE science users – NCSA, SDSC, et. al.: HPC for NSF users – Globus: full-‐featured, high-‐performance data transfer tools
• No responsibility for individual science projects – Resource provider staff usually not part of science projects – Science projects have to do their own integra<on (see beginning of talk)
• However, resource providers are typically responsive to user requests – If you have a problem, it’s their job to fix it – I propose we use this to get something done
2/10/15 20

Hypothe<cal: HPC Data Transfer Capability
• This community has significant data transfer needs – I have worked with some of you in the past – Simula<ons, sky surveys, etc. – Expecta<on over <me that needs will increase
• Improve data movement capability – ANL, NERSC, ORNL – NCSA, SDSC – This is an arbitrary list, based on my incomplete understanding – Should there be others?
• Goal: per-‐Globus-‐job performance of 1PB/week – I don’t mean we have to transfer 1PB every week – But, if we need to, we should be able to – Remember, this only takes 15% of a 100G network path
2/10/15 21

What Would Be Required?
• We would need several things: – Specific workflow (move dataset D of size S from A to Z, frequency F) – A commitment by resource providers to see it through
• ESnet (+ other networks if needed) • Compu<ng facili<es • Globus
• Is it 100% plug-‐and-‐play? No. – There are almost certainly some wrinkles – However, most of the hard part is done
• Networks • Data transfer nodes • Tools
• Let’s work together and make this happen!
2/10/15 22

Ques<ons For You
• Would an effort like this be useful? (I think so)
• Does this community need this capability? (I think so)
• Are there obvious gaps? (probably, e.g. performance to tape)
• Which sites would be involved?
• Am I crazy? (I think not)
2/10/15 23

Thanks!
Eli Dart Energy Sciences Network (ESnet) Lawrence Berkeley Na<onal Laboratory
hJp://fasterdata.es.net/
hJp://my.es.net/
hJp://www.es.net/

Extra Slides
2/10/15 25

Support For Science Traffic
• The Science DMZ is typically deployed to support science traffic – Typically large data transfers over long distances – In most cases, the data transfer applica<ons use TCP
• The behavior of TCP is a legacy from the conges<on collapse of the Internet in the 1980s – Loss is interpreted as conges<on – TCP backs off to avoid conges<on à performance degrades – Performance hit related to the square of the packet loss rate
• Addressing this problem is a dominant engineering considera<on for science networks – Lots of design effort – Lots of engineering <me – Lots of troubleshoo<ng effort
2/10/15 26
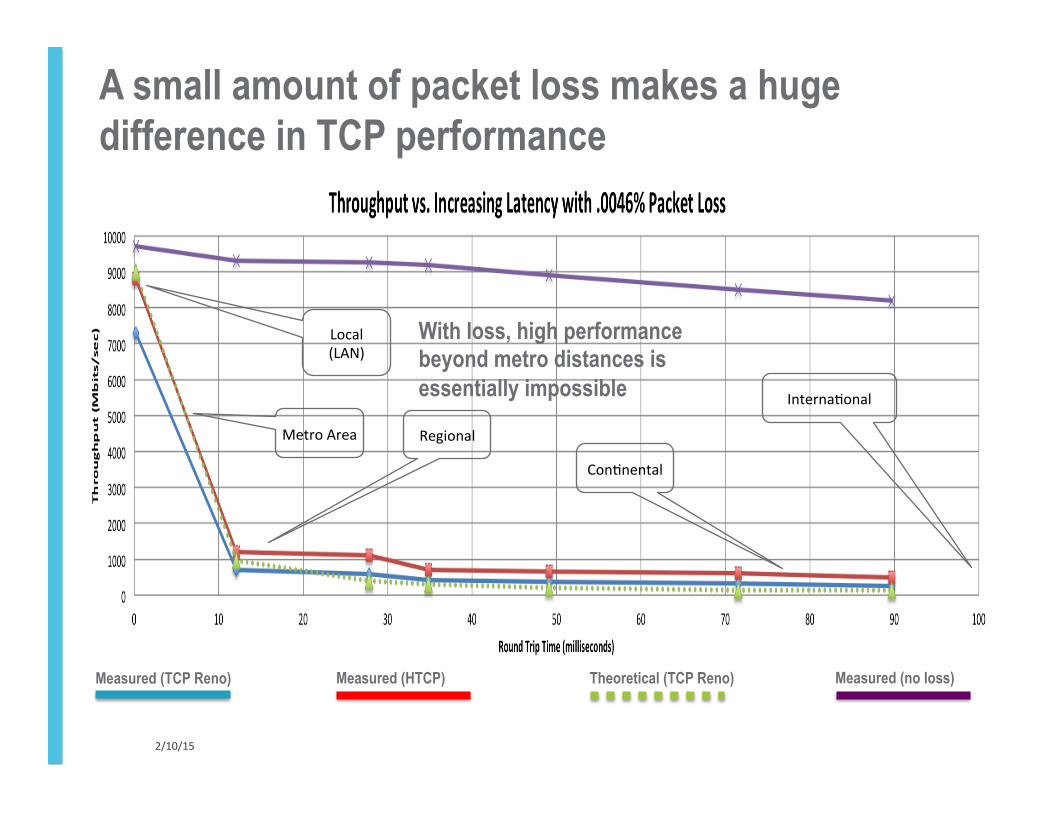
A small amount of packet loss makes a huge difference in TCP performance
2/10/15
Metro Area
Local (LAN)
Regional
Con<nental
Interna<onal
Measured (TCP Reno) Measured (HTCP) Theoretical (TCP Reno) Measured (no loss)
With loss, high performance beyond metro distances is essentially impossible