common voting rules as maximum likelihood estimators vincent conitzer and tuomas sandholm carnegie...
Post on 21-Dec-2015
216 views
TRANSCRIPT

Common Voting Rules as Maximum Likelihood Estimators
Vincent Conitzer and Tuomas Sandholm Carnegie Mellon University, Computer Science Department

Voting (rank aggregation) rules
• Set of m candidates (alternatives) C• n voters; each voter ranks the candidates (the voter’s vote)
– E.g. b > a > c > d
• Voting rule f maps every vector of votes to either:– a winner in C, or– a complete ranking of C
• E.g. plurality: – every voter votes for a single candidate (equiv. we only consider
the candidate’s top-ranked candidate) – candidate with most votes wins/candidates are ranked by score

Two views of voting1. Voters’ preferences are idiosyncratic; only
purpose is to find a compromise winner/ranking2. There is some absolute sense in which some
candidates are better than others, independent of voters’ preferences; votes are merely noisy perceptions of candidates’ true quality
a“correct” outcome
aagents’ votes
a“correct” outcome
avote 1 avote 2 avote n…
conditional independence assumption
Goal: given votes, find maximum likelihood estimate of correct outcome
Different noise model different maximum likelihood estimator/voting rule
(outcome=winner or ranking)

History
• [Condorcet 1785] assumed noise model where voter ranks any two candidates correctly with fixed probability p > 1/2, independently– Gives cyclical rankings with some probability, but does not
affect MLE approach– Solved cases of 2 and 3 candidates
• Two centuries pass…• [Young 1995] solved case of arbitrary number of
candidates under the same model– Showed that it coincided with rule proposed by Kemeny
[Kemeny 1959]
• [Drissi & Truchon 2002] extend to the case where p is allowed to vary with the distance between two candidates in correct ranking

What is next?
• Does this suggest using Kemeny rule?– Many other noise models possible
– Some of these may correspond to other, better-known rules
• Goal of this paper: Classify which common rules are a maximum likelihood estimator for some noise model– Positive and negative results
– Positive results are constructive
• Motivation:– Rules corresponding to a noise model are more natural
– Knowing a noise model can give us insight into the rule and its underlying assumptions
– If we disagree with the noise model, we can modify it and obtain new version of the rule

Independence restriction
• Without any independence restriction, it turns out that any rule has a noise model:
• P(vote vector|outcome) > 0 if and only if f(vote vector)=outcome
a“correct” outcome
aagents’ votes
a“correct” outcome
avote 1 avote 2 avote n…
conditional independence assumption
• So, will focus on conditionally independent votes
• If a rule has a noise model in this setup we call it an– MLEWIV rule if producing winner– MLERIV rule if producing ranking– (IV = Independent Votes)

Any scoring rule is MLEWIV and MLERIV
• Scoring rule gives a candidate a1 points if it is ranked first, a2 points if it is ranked second, etc.
– plurality rule: a1 = 1, ai = 0 otherwise
– Borda rule: ai = m-i
– veto rule: am = 0, ai = 1 otherwise
• MLEWIV noise model: P(v|w) = 2al(v,w) where l(v,w) is the rank of w in v– want to choose w to maximize Πv 2al(v,w) = 2Σval(v,w)
• MLERIV noise model: P(v|r) = Π1≤i≤m(m+1-i)al(v,ri) where ri is the candidate ranked ith in r

Single Transferable Vote (STV) is MLERIV
• STV rule: Candidate ranked first by fewest voters drops out and is removed from rankings, final ranking is inverse of order in which they dropped out
• MLERIV noise model:– Let ri be the candidate ranked ith in r– Let δv(ri) = 1 if all the candidates ranked higher than ri
in v are ranked lower in r (i.e. they are all contained in {ri+1, ri+2, …, rm}), otherwise 0
– P(v|r) = Π1≤i≤mkiδv(ri) where ki+1 << ki < 1

Lemma to prove negative results
• For any noise model, if there is a single outcome that maximizes the likelihood of both vote vector 1 and vote vector 2, then it must also maximize the likelihood of vote vector 3
• Hence, a voting rule that produces the same outcome on both vector 1 and vector 2 but a different one on vector 3 cannot be a maximum likelihood estimator
correct outcome
vote 1 vote k vote k+1 vote n
vote vector 1 vote vector 2vote vector 3
… …

STV rule is not MLEWIV• STV rule: Candidate ranked first by fewest voters drops out and is removed from
rankings, final ranking is inverse of order in which they dropped out
• First vote vector: – 3 times c > a > b– 4 times a > b > c– 6 times b > a > c– c drops out first, then a wins
• Second vote vector:– 3 times b > a > c– 4 times a > c > b– 6 times c > a > b– b drops out first, then a wins
• But: taking all votes together, a drops out first! – (8 votes vs. 9 for the others)

Bucklin rule is not MLEWIV/MLERIV • Bucklin rule:
– For every candidate, consider the minimum k such that more than half of the voters rank that candidate among the top k
– Candidates are ranked (inversely) by their minimum k– Ties are broken by the number of voters by which the “half” mark is passed
• First vote vector: – 2 times a > b > c > d > e– 1 time b > a > c > d > e– gives final ranking a > b > c > d > e
• Second vote vector:– 2 times b > d > a > c > e– 1 time c > e > a > b > d– 1 time c > a > b > d > e– gives final ranking a > b > c > d > e
• But: taking all votes together gives final ranking b > a > c > d > e– (b goes over half at k=2, a does not)

Pairwise election graphs
• Pairwise election: take two candidates and see which one is ranked above the other in more votes
• Pairwise election graph has edge of weight k from a to b if a defeats b by k votes in the pairwise election
• E.g. votes a > b > c and b > a > c together produce pairwise election graph:
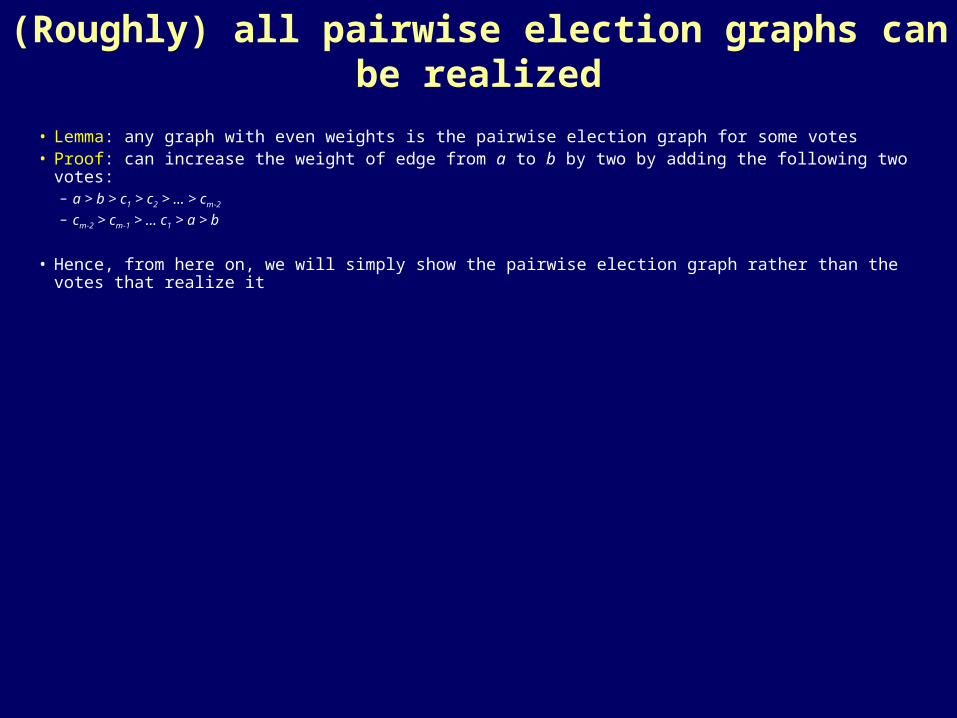
(Roughly) all pairwise election graphs can be realized
• Lemma: any graph with even weights is the pairwise election graph for some votes• Proof: can increase the weight of edge from a to b by two by adding the following two votes:
– a > b > c1 > c2 > … > cm-2
– cm-2 > cm-1 > … c1 > a > b
• Hence, from here on, we will simply show the pairwise election graph rather than the votes that realize it
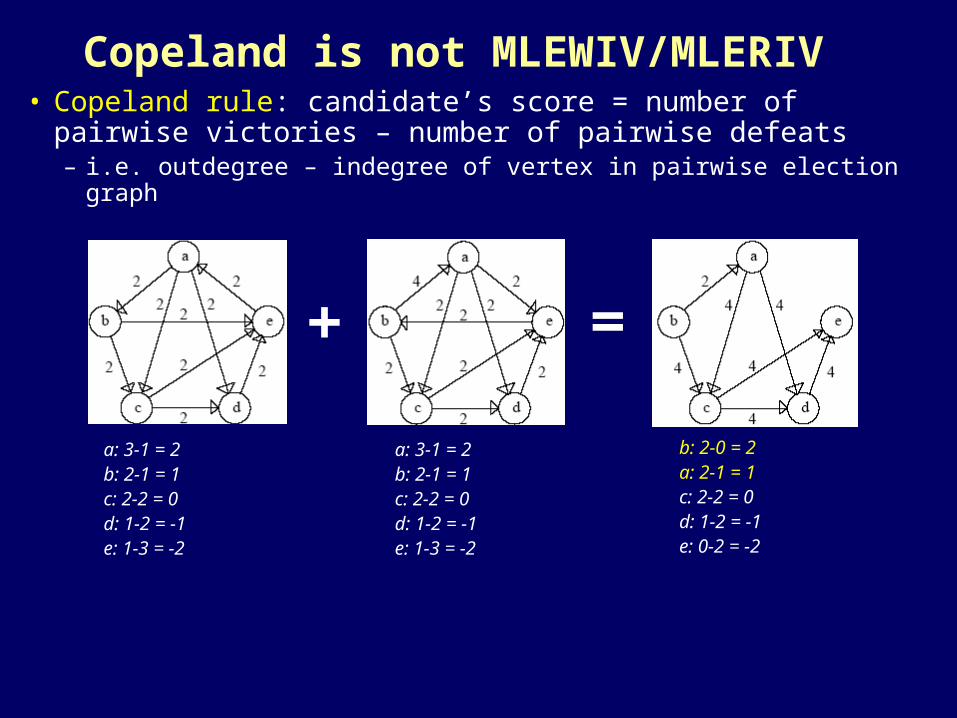
Copeland is not MLEWIV/MLERIV • Copeland rule: candidate’s score = number of pairwise
victories – number of pairwise defeats– i.e. outdegree – indegree of vertex in pairwise election graph
a: 3-1 = 2b: 2-1 = 1c: 2-2 = 0d: 1-2 = -1e: 1-3 = -2
a: 3-1 = 2b: 2-1 = 1c: 2-2 = 0d: 1-2 = -1e: 1-3 = -2
b: 2-0 = 2a: 2-1 = 1c: 2-2 = 0d: 1-2 = -1e: 0-2 = -2
+ =

Maximin is not MLEWIV/MLERIV • maximin rule: candidate’s score = score in worst pairwise
election– i.e. candidates are ordered inversely by weight of largest incoming edge
a: 6b: 8c: 10d: 12
+ =
a: 6b: 8c: 10d: 12
c: 2a: 4d: 6b: 8

Ranked pairs is not MLEWIV/MLERIV • ranked pairs rule: pairwise elections are locked in according by
margin of victory– i.e. larger edges are “fixed” first, an edge is discarded if it introduces a cycle
b > d fixeda > b fixedd > a discardedb > c fixedc > d fixedresult: a > b > c > d
+ =
a > c fixedc > d fixedd > a discardedb > c fixeda > b fixedresult: a > b > c > d
d > a fixedc > d fixeda > c discardedb > d fixeda > b discardedb > c fixedresult: b > c > d > a

Conclusions
MLERIV not MLERIV
MLEWIV scoring rules (incl. plurality, Borda, veto)
hybrids of MLEWIV and (not MLERIV) rules
not MLEWIV STV Bucklin, Copeland, maximin, ranked pairs
Thank you for your attention!
• We asked the question: which common voting rules are maximum likelihood estimators (for some noise model)?
• If votes are not independent given outcome (winner/ranking), any rule is MLE• If votes are independent given outcome, some rules are MLEWIV (MLE for winner), some are
MLERIV (MLE for ranking), some are both: