compilers and code optimization -...
TRANSCRIPT

Compilers and Code
Optimization EDOARDO FUSELLA

Contents
LLVM
The nu+ architecture and toolchain

3
LLVM

What is LLVM?
LLVM is a compiler infrastructure designed as a set of
reusable libraries with well‐defined interfaces
Implemented in C++
Several front‐ends
Several back‐ends
First release: 2003
Open source
http://llvm.org/

LLVM is a Compilation
Infra‐Structure
It is a framework that comes with lots of tools to
compile and optimize code.

LLVM vs GCC
clang/clang++ are very competitive when
compared with gcc. Some compilers are faster in
some benchmarks, and slower in others. Usually
clang/clang++ have faster compilation times.

Why to Learn LLVM?
Intensively used in the academia
Used by many companies
LLVM is maintained by Apple.
ARM, NVIDIA, Mozilla, Cray, etc
Clean and modular interfaces.
Open source
LLVM implements the entire compilation flow.
Front‐end, e.g., clang & clang++
Middle‐end, e.g., analyses and optimizations
Back‐end, e.g., different computer architectures

LLVM compilation flow
Like gcc, clang supports different levels of optimizations,
e.g., ‐O0 (default), ‐O1, ‐O2 and ‐O3

LLVM Intermediate
Representation
LLVM represents programs, internally, via its own
instruction set
The LLVM optimizations manipulate these
bytecodes.
We can program directly on them.
We can also interpret them.
Example taken from the slides of Gennady Pekhimenko "The LLVM Compiler Framework and Infrastructure"

LLVM Bytecodes are
Interpretable
Bytecode is a form of instruction set designed for efficient
execution by a software interpreter.
They are portable!
Example: Java bytecodes.
The tool lli directly executes programs in LLVM bitcode
format.
lli may compile these bytecodes just‐in‐time, if a JIT is
available.

How Does the LLVM IR
Look Like?
RISC instruction set, with usual opcodes
add, mul, or, shiR, branch, load, store, etc
Typed representation.
Static Single Assignment format
Compared to three-address code, all assignments in SSA are
to variables with distinct names; hence the term static single-
assigment.

Generating Machine Code
Once we have optimized
the intermediate program,
we can translate it to
machine code.
In LLVM, we use the llc
tool to perform this
translation. This tool is
able to target many
different architectures

13
Nu+ HTTP://NUPLUS.HOL.ES/

The Nu+ processor: current state Hardware:
~18000 lines of System Verilog code
Two versions: multi-core and single-core
Hardware multi-threading
Scalar and vector operations (SIMD)
Dynamic instruction scheduling (simple scoreboard)
ISA consolidated
32- and 64-bit operations
Masked operations, also used for control flow
Rollback stage (involves branches and loops)
High-performance cache hierarchy, support for DDR3
Private L1 cache for each core
Shared distributed L2 cache with coherence directory-based protocol
Non-coherent scratchpad memory
Handling variable latencies of SPM and Writeback stages
107450 LUT, 136516 FFs, 102 BRAMs, 146 DSP (1 core/8 threads, 16 HW Lanes, 64 registers per thread, Caches: 512 bit/4 ways/128 sets): resp, 8%, 5%, 8%, 6% on the Virtex7 2000T @75 MHz
Integrated with MANGO
Software/Compiler toolchain
LLVM-based toolchain
Builtins exposed to the C/C++ programmer
Integrated with MANGOLIB
Polyhedral analysis
(require external tools)
14
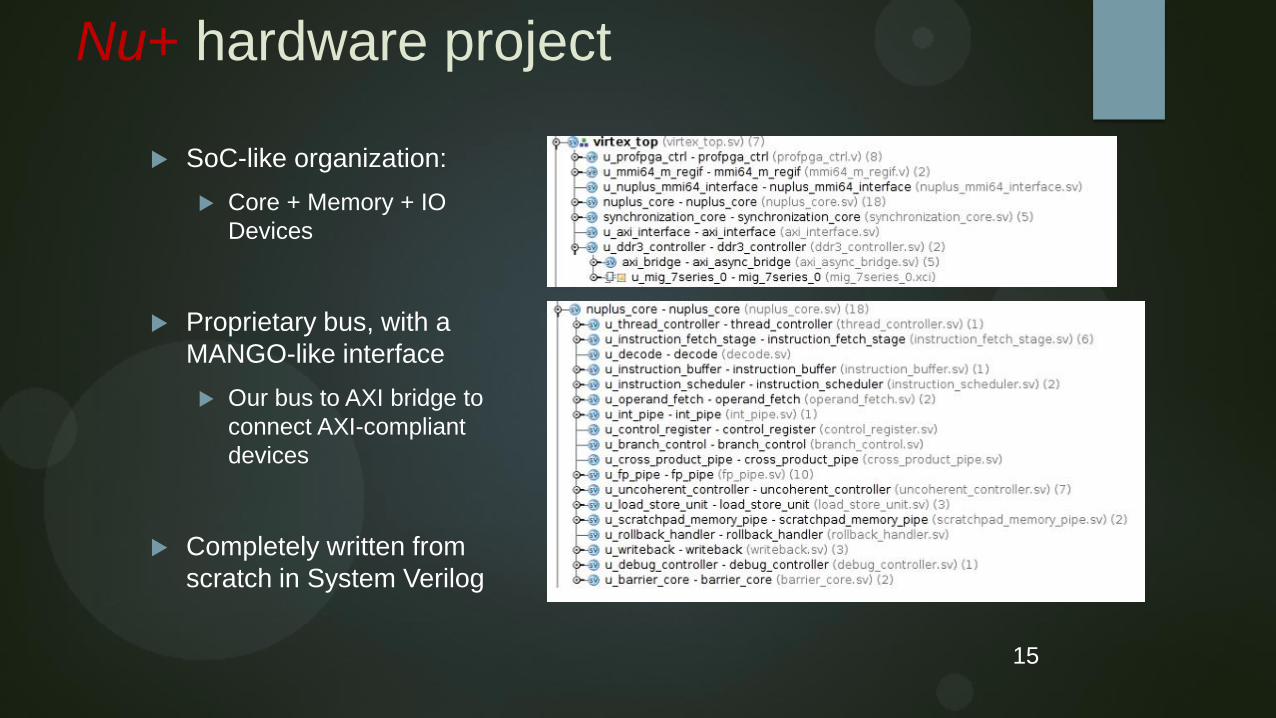
Nu+ hardware project
SoC-like organization:
Core + Memory + IO
Devices
Proprietary bus, with a
MANGO-like interface
Our bus to AXI bridge to
connect AXI-compliant
devices
Completely written from
scratch in System Verilog
15

Nu+ current microarchitecture
Can configure
Number of cores
Number of Threads
Number of hw lanes
Number of registers per Thread
Cache set-size
Number of ways
Number of 32-bit words in each line
SPM parameters:
Number/size of banks
Type of partitioning
16

Nu+ Configurability
Highly parameterizable
Thread numbers per Core
L1 and L2 Cache configuration options
Hardware SIMD lanes per thread
Number of registers
Scratchpad Memory parameters
IO Memory map address space
…
17

Nu+ Scratch-Pad Memory
A. Cilardo, M. Gagliardi, C. Donnarumma, "A Configurable Shared Scratchpad Memory for GPU-like Processors", Procs. of the International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, Springer, pp 3-14, 2016
Default
parameters:
SPM size:
8kB
Data bus width: 512 bit (16 lanes
accessing 32 bit operands)
• In absence of conflicts, 16
concurrent accesses
• Ultra-low latency In absence of
conflicts, 3 clock cycles
18

Nu+ Register file
Large register file
58 general purpose 32-bit scalar registers S0 - S57 configurable into 29
64-bit registers.
6 special registers
trap register TR
mask register RM
frame pointer FP
stack pointer SP
return address RA
64 general purpose 512-bit vector registers V0 - V63

Nu+ Instruction formats 1/2
Instructions are encoded in eight 32-bit formats:
R – arithmetic operations with Register/Register Encoding
I – arithmetic operations with Immediate Encoding
two registers and a 9-bit immediate value
MOVEI
MOVE instructions with a 16-bit immediate value
C – control operations (such as cache control)
J – jump operations
M – memory operations
Main memory and scratchpad memory

Nu+ Instruction formats 2/2
Bits 31-24: the most significant 8 bits are used to encode the format + opcode
Bit M is used in case of masked instructions
Bits FMT are used to specify if a certain operand is a scalar or a vector (one bit for every register in the format)
Bit L is high in case of "long" operations, i.e. operations that require long integers or double precision numbers
Bit S is high in case a load/store operation accesses the scratchpad memory
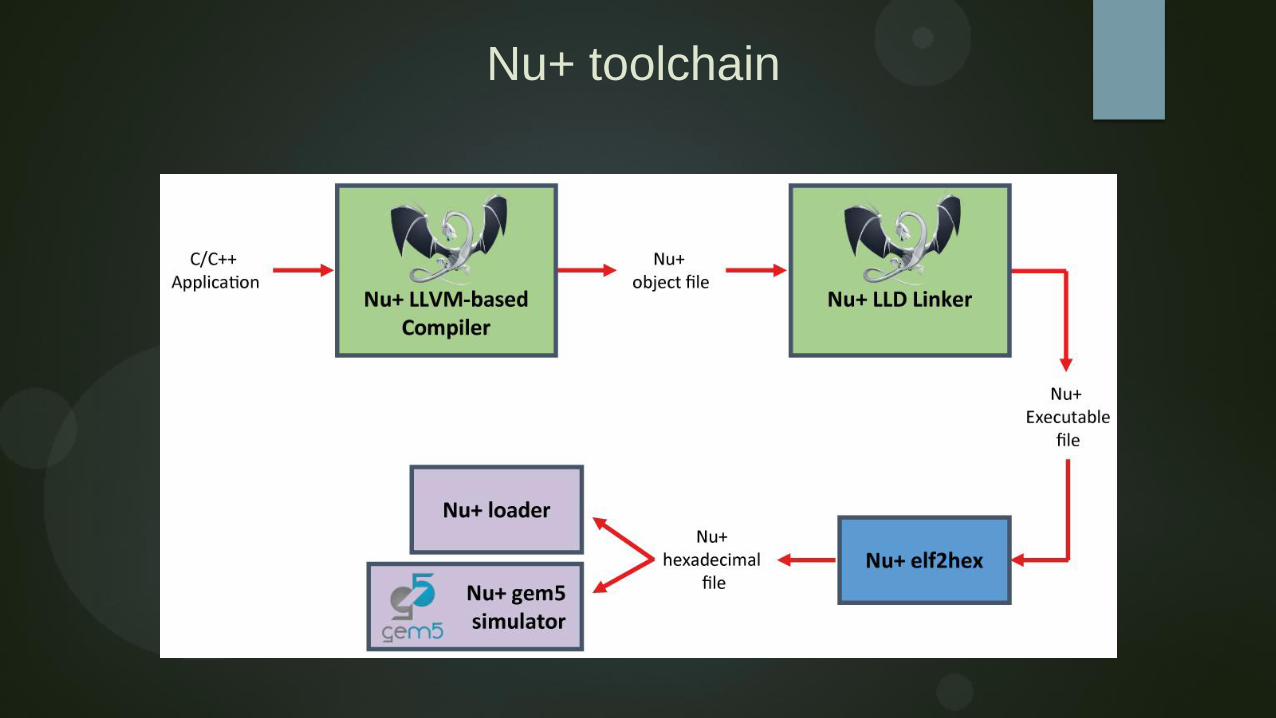
Nu+ toolchain

Features
Some interesting features handled by the compiler:
Native support for 32-bit and 64-bit operations, either floating point
operations (IEEE-754 compliant) or integer operations.
Native support for complex arithmetic and vector instructions (SIMD).
Vector instructions can be masked in order to operate on a subset of the
vector elements.
Native support to the scratchpad memory through specific load/store
instructions.

Arithmetic
The nu+ execution pipeline supports simultaneously:
16 single-precision floating point operations (IEEE-754 compliant) or 32-bit
integer operations.
8 double-precision floating point operations (IEEE-754 compliant) or 64-bit
integer operations.
Each vector lane has its own 32-bit operator
In case of a operation on 64-bit values, the bit L (instruction format) must be set
to one, adjacent lane pairs are merged in a single 64-bit wide operator

Vector arithmetic
The nu+ architecture includes
A separate vector register file with 64 512-bit vector registers V0 - V63
Each register is configurable to store vectors of
16 32-bit elements
8 64-bit elements.
In addition, it is also possible to store vectors of
16 16-bit and 8-bit elements
8 32-bit, 16-bit and 8-bit elements.
16x32 and 8x64 are natively supported by the hardware while the others
require a conversion/extension/truncation.
Native types when targeting performance
Non-native types when targeting memory footprint

stdint.h
We redefined the stdint.h header file in order to provide a set of typedefs that specify vector types
OpenCL-compliant: vector types are created using ext_vector_type attribute https://clang.llvm.org/docs/LanguageExtensions.html

Custom version of the following standard C libraries:
ctype.h
math.h
stdlib.h
Except dynamic memory management (calloc, free, malloc, realloc) and
environment (abort, atexit, at_quick_exit, exit, getenv, quick_exit, system)
functions
string.h
libc: custom implementation

Infeasible to show the backend code in this presentation
A few examples will show some interesting aspects of the nu+
architecture/toolchain
Note that the following code is generated without any optimization –O0
Nu+ is an open-source project and the whole compiler will be soon
available at
http://nuplus.hol.es/toolchain.html

NuPlusRegisterInfo.td –
Declarations

NuPlusRegisterInfo.td –
Registers

NuPlusRegisterInfo.td –
Register Classes

NuPlusInstrFormats.td –
class FR

NuPlusInstrInfo.td –
Arithmetic Integer Two
operands
Defined in
NuPlusInstrFormats.td

32-bit scalar constants
We never use the
constant pool in
case of scalar
constants
We rely on two
instructions of the
MOVEI format:
moveil, that moves
the lower 16 bits
moveih, that moves
the higher 16 bits
412810 = 0x1020
1235210 = 0x3040

64-bit scalar constants
64 bit constants are split
into two 32 bit constants
that are loaded with two
couples of moveil/moveih in
two 32-bit registers.
Then two 32-bit move
instructions are used to
move the contents of these
two 32-bit registers into the
lower and higher part of a
64-bit registers.

Natively supported vector
arithmetic v16i32+v16i32
Vectors are
placed in
the same
section as
the function
so they can
be
accessed
with PC
relative
addresses.
0x40
0x0

Non-natively supported vector
arithmetic v16i8+v16i8
Sign extend
instructions are
emitted to support the
promotion of each
element in the vector
Load/store instructions
still works on the
original vector types,
even after the
arithmetic operation
Save memory space

Different types vector arithmetic
v8i8+v8i64
Intrinsics are
required to explicitly
promote vector
types
After the promotion,
the information
related to the
original vector type
is lost

Scratchpad memory
We rely on GNU GCC attributes [1]
__scratchpad is defined as:
#define __ scratchpad
__attribute((scratchpad))
__attribute((scratchpad)) is made up of:
__attribute__((section(“scratchpad"))) that is
used to create a new section in the ELF
__attribute__((address_space(77))) that is
used to define a new address space
[1] https://gcc.gnu.org/onlinedocs/gcc-3.2/gcc/Variable-Attributes.html

programming Nu+: exploit parallelism
40
Three levels of exploitable
parallelism:
Vector lanes (SIMD)
Hardware multithreading
Multi-core
require custom vector types
require nu+
builtins

programming Nu+: vector support
Operators between vector types:
Arithmetic operators (+, -, *, /, %)
Relational operators (==, !=, <, <=, >, >=)
Bitwise operators (&, |, ^, ~, <<, >>)
Logical operators (&&, ||, !)
Assignment operators (=, +=, -=, *=, /=, %=, <<=, >>=, &=, ^=, |=)
41

vector support: from C to OpenCL
42
#include <stdint.h>
int a [16] __attribute__((aligned(64))) =
{1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
int main (){
vec16i32* va =
reinterpret_cast<vec16i32*>(&a);
}
• Conversion between int [16] and vec16i32
• Nu+ vector types are 64-byte aligned
• Conversion possible only if both types have the same alignment
• reinterpret_cast: compiler directive which instructs the compiler to treat the sequence of bits as if it had a different type.

vector support: vector and vector/scalar sums
43
#include <stdint.h>
int main (){
vec16i32 a;
vec16i32 b;
…
vec16i32 c = a+b;
}
Define two vectors of
16 integer elements
Compute the
vector sum a+b
#include <stdint.h>
int main (){
vec16i32 a;
int b;
…
vec16i32 c = a+b;
}
Define one vectors of 16 integer elements and a scalar
Compute the sum between vector a and scalar b

vector support: vector initialization
44
#include <stdint.h>
int main (){
const vec16i32 a = {
0, 1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13,
14, 15 };
}
• Vectors can be initialized using curly bracket syntax
a constant vector
#include <stdint.h>
int main (){
int x, y, z;
...
vec16i32 a = {
x, y, z, x, y, z,
x, y,
z, x, y, z, x, y,
z, x};
}
a non-constant vector

vector support: operator []
45
#include <stdint.h>
int main (){
vec16i32 a;
// assign some values:
for (int i=0; i<16; i++) a[i]=i;
int sum = 0;
// calculate sum
for (int i=0; i<16; i++) sum +=
a[i];
}
• the operator [] can be
used to access vector
elements

vector support: comparisons
46
#include <stdint.h>
int main (){
vec16i32 a;
vec16i32 b;
…
int c = __builtin_nuplus_mask_cmpi32_slt
(a, b)
}
• Two possibilities:
– relational operators
– Specific builtins (optimized for nu+)
• The integer c
will contain a
bitmap where
each bit will be
equal to 0 or 1
according to
the result of the
comparison.

vector support: handling SIMD control
flow
47
#include <stdint.h>
int main (){
vec16i32 a;
vec16i32 b;
…
int c = __builtin_nuplus_mask_cmpi32_slt (a,
b);
int rm_old =
__builtin_nuplus_read_mask_reg();
__builtin_nuplus_write_mask_reg(c);
do_something();
c = c^-1;
__builtin_nuplus_write_mask_reg(c);
do_somethingelse();
__builtin_nuplus_write_mask_reg(rm_old);
}
• At the beginning all lanes are enabled
• SIMD control flow through masking operations
Steps:
1. generate mask for a<b
2. save mask register
3. write mask register for a<b
4. generate mask for a>=b
5. write mask register for a>=b
6. restore the old mask

programming Nu+: multithreading
support
Explicitly handled by the programmer using builtins:
__builtin_nuplus_read_control_reg(2): for each hardware thread,
returns the thread id
__builtin_nuplus_barrier(int ID, int number_of_threads): thread
synchronization using hardware barrier
48

programming Nu+: multithreading
support TLP:
Independent stacks
Private register files
Shared Caches and SPM
Same entry point,
but different flows.
Programmers can specialize or span tasks over different threads using their IDs
Barrier synchronization support
49

programming Nu+: coherence
mechanism Policies:
__builtin_nuplus_write_control_reg(16,1): set write-through
__builtin_nuplus_write_control_reg(16,0): set write-back
High-performance
Require explicit flush of data to main memory through
__builtin_nuplus_flush(int data_address);
50
#include <stdint.h>
int main (){
vec16i32 a;
vec16i32 b;
…
vec16i32 c = a+b;
__builtin_nuplus_flush((int)(&c)
);
}

programming Nu+: Scratchpad memory
Variables declared with the __scratchpad attribute are placed in the
scratchpad using appropriate load/store instructions
Note that just global variable can be placed in the scratchpad memory
51

programming Nu+: Custom operations
Customizing nu+ with a
specific functional unit (SFU):
• Add the HDL code in the
hardware project
• The ISA is provided with
specific instructions to use
the SFU.
• Builtins are exposed to the
programmer to exploit the
SFU
Custom
hardware
Some builtins:
• int __builtin_nuplus_f1_int(int a, int b);
• float __builtin_nuplus_f1_float(float a, float
b);
• …
52