computer speech recognition: mimicking the human system
TRANSCRIPT

Computer Speech Recognition: Mimicking the Human System
Li DengMicrosoft Research, RedmondMicrosoft Research, Redmond
July 24, 2005Banff/BIRS

Fundamental Equations
• Enhancement (denoising):
• Recognition:
• Importance of speech modeling
ˆ argmax ( | ) argmax ( | ) ( )W W
W P W x P x W P W= =

Speech Recognition--- Introduction
• Converting naturally uttered speech into text and meaning• Conventional technology --- statistical modeling and
estimation (HMM)• Limitations
– noisy acoustic environments– rigid speaking style– constrained task– unrealistic demand of training data– huge model sizes, etc.– far below human speech recognition performance
• Trend: Incorporate key aspects of human speech processing mechanisms

Segment-Level Speech Dynamics

Production & Perception: Closed-Loop Chain
message
motor/articulators
Internalmodel
decodedmessage
ear/a
uditory
recep
tion
SPEAKER LISTENER
Speech Acoustics in
closed-loop chain

Encoder: Two-Stage Production Mechanisms
message
motor/articulators
Speech Acoustics
Phonology (higher level):•Symbolic encoding of linguistic message•Discrete representation by phonological features•Loosely-coupled multiple feature tiers•Overcome beads-on-a-string phone model•Theories of distinctive features, feature geometry& articulatory phonology
• Account for partial/full sound deletion/modificationin casual speech
SPEAKER
PhoneticsPhonetics (lower level):(lower level):••Convert discrete linguistic features toConvert discrete linguistic features tocontinuous acousticscontinuous acoustics
••Mediated by motor control & articulatory Mediated by motor control & articulatory dynamicsdynamics••Mapping from articulatory variables toMapping from articulatory variables toVT area function to acoustics VT area function to acoustics
••Account for coAccount for co--articulation and reduction articulation and reduction (target undershoot), etc.(target undershoot), etc.

Encoder: Phonological Modeling
message
motor/articulators
Speech Acoustics
Computational phonology:• Represent pronunciation variations asconstrained factorial Markov chain
• Constraint: from articulatory phonology• Language-universal representation
SPEAKER
Labial-closure
Alveolar constr.
gesture-iy
Nasality
Aspiration Voicing
LIPS:
TT:
TB:
VEL:
GLO:
Alveolar closure
gesture-eh
Alveolar closure
dentalconstr.
Nasality
Voicing
ten themes
/ t ε n ө i: m z /
TongueTip
TongueBody
High / FrontMid / Front

Encoder: Phonetic Modeling
message
motor/articulators
Speech Acoustics
SPEAKER
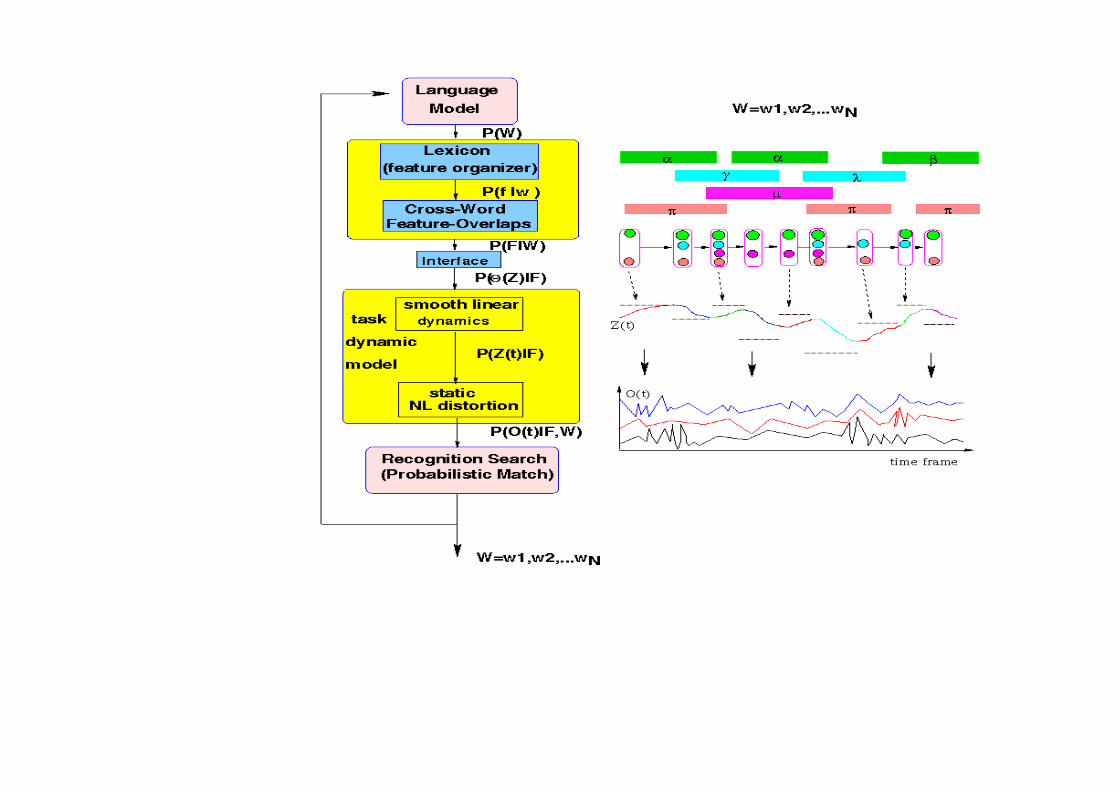
Computational phonetics:Computational phonetics:•• Segmental factorial HMM for sequential target Segmental factorial HMM for sequential target
in articulatory or vocal tract resonance domainin articulatory or vocal tract resonance domain•• Switching trajectory model for targetSwitching trajectory model for target--directeddirected
articulatory dynamicsarticulatory dynamics•• Switching nonlinear stateSwitching nonlinear state--space model forspace model for
dynamics in speech acousticsdynamics in speech acoustics•• Illustration:Illustration:

Phonetic Encoder: Computation
message
motor/articulators
Speech Acoustics
SPEAKER
1S 2S 3S4S KS�����.......
1t 2t 3t Kt4t
1z 2z 3zKz4z
1o 2o 3o Ko4o
1y 2y 3y Ky4y
1n2n 3n Kn
4n
1N 2N 3N KN4N
h
articulation
targets
distortion-free acoustics
distorted acoustics
distortion factors & feedback to articulation

Decoder I: Auditory Reception
message
motor/articulators
Internalmodel
decodedmessage
ear/a
uditory
recep
tion
LISTENER• Convert speech acoustic waves intoefficient & robust auditory representation
• This processing is largely independent of phonological units
• Involves processing stages in cochlea(ear), cochlear nucleus, SOC, IC,…, allthe way to A1 cortex
• Principal roles: 1) combat environmental acoustic
distortion;2) detect relevant speech features 3) provide temporal landmarks to aid
decoding• Key properties:
1) Critical-band freq scale, logarithmic compression,2) adapt freq selectivity, cross-channel correlation,3) sharp response to transient sounds4) modulation in independent frequency bands,5) binaural noise suppression, etc.

Decoder II: Cognitive Perception
message
motor/articulators
Internalmodel
decodedmessage
ear/a
uditory
recep
tion
LISTENER• Cognitive process: recovery of linguisticmessage
• Relies on 1) “Internal” model: structural knowledge of
the encoder (production system)2) Robust auditory representation of features3) Temporal landmarks
• Child speech acquisition process is one that gradually establishes the “internal” model
• Strategy: analysis by synthesis• i.e., Probabilistic inference on (deeply)
hidden linguistic units using the internalmodel
• No motor theory: the above strategy requires no articulatory recovery from speech acoustics

• On-line modification of speaker’s articulatory behavior (speaking effort, rate, clarity, etc.) based on listener’s “decoding” performance (i.e. discrimination)
• Especially important for conversational speech recognition and understanding
• On-line adaptation of “encoder” parameters• Novel criteria:
– maximize discrimination while minimizing articulation effort
• In this closed-loop model, the “effort” quantified as “curvature”of temporal sequence of articulatory vector zt.
• No such concept of “effort” in conventional HMM systems
Speaker-Listener Interaction

• xxx• xxx
Model synthesis in FT

Model synthesis in cepstraModel synthesis in cepstra
0 50 100 150 200 250
−1
−0.5
0
0.5
0 50 100 150 200 250
−0.5
0
0.5
0 50 100 150 200 250−2
−1
0
1
2
Frame (10ms)
C1
C2
C3
data
Model

Procedure --- N-best Evaluation
ssµµµµ
featureextraction
FIR
triphoneHMM
system
test data LPCC
+
-
2ssσσσσ
nonlinear mapping
table lookup
Hyp 1
Hyp 2
Hyp N
N-best list (N=1000); each hypothesis has phonetic xcript & time
………
GaussianScorer
table lookup
table lookup
FIR
FIR
nonlinear mapping
nonlinear mapping
-
-
+
+
GaussianScorer
GaussianScorer
H*=
arg Max { P
(H1), P
(H2),…
P(H
1000)}
………
sγγγγsT
………
………
………
………
parameterfree
(k) (k)

Results (recognition accuracy %)(work with Dong Yu)
30
40
50
60
70
80
90
100
1 101 10001
Acc%
. . .HMM
100111N in N-best
Models
New model
HMM system 72.5 72.5 72.5
75.1
Lattice Decode

• Human speech production/perception viewed as synergistic elements in a closed-looped communication chain
• They function as encoding & decoding of linguistic messages, respectively.
• In human, speech “encoder” (production system) consists of phonological (symbolic) and phonetic (numeric) levels.
• Current HMM approach approximates these two levels in a crude way: – phone-based phonological model (“beads-on-a-string”)– multiple Gaussians as phonetic model for acoustics directly– very weak hidden structure
Summary & Conclusion

• “Linguistic message recovery” (decoding) formulated as:– auditory reception for efficient & robust speech representation & for
providing temporal landmarks for phonological features– cognition perception using “encoder” knowledge or “internal model” to
perform probabilistic analysis by synthesis or pattern matching
• Dynamic Bayes network developed as a computational tool for constructing encoder and decoder
• Speaker-listener interaction (in addition to poor acoustic environment) cause substantial changes of articulation behavior and acoustic patterns
Summary & Conclusion (cont’d)

Issues for discussion
• Differences and similarities in processing/analysis techniques for audio/speech and image/video processing
• Integrated processing vs. modular processing
• Feature extraction vs. classification• Use of semantics (class) information for feature
extraction (dim reduction, discriminative features, etc.)• Arbitrary signal vs. structured signal (e.g. face image,
human body motion, speech, music)
ˆ argmax ( | ) argmax ( | ) ( )W W
W P W x P x W P W= =