computing geographical scopes of web resources
TRANSCRIPT

Computing Geographical Scopes of Web Resources
Junyan DingComputer Science Department
Columbia University
Luis GravanoComputer Science Department
Columbia University
Narayanan ShivakumarGigabeat, Inc.
Abstract
Many information resources on the web arerelevant primarily to limited geographicalcommunities. For instance, web sites contain-ing information on restaurants, theaters, andapartment rentals are relevant primarily toweb users in geographical proximity to theselocations. In contrast, other information re-sources are relevant to a broader geographicalcommunity. For instance, an on-line newspa-per may be relevant to users across the UnitedStates. Unfortunately, current web search en-gines largely ignore the geographical scope ofweb resources. In this paper, we introducetechniques for automatically computing thegeographical scope of web resources, based onthe textual content of the resources, as well ason the geographical distribution of hyperlinksto them. We report an extensive experimen-tal evaluation of our strategies using real webdata. Finally, we describe a geographically-aware search engine that we have built toshowcase our techniques.
1 Introduction
The World-Wide Web provides uniform access to in-formation available around the globe. Some web sitessuch as on-line stores and banking institutions are of“global” interest to web users world-wide, while manyweb sites contain information primarily of interest toweb users in a geographical community, such as the
Permission to copy without fee all or part of this material isgranted provided that the copies are not made or distributed fordirect commercial advantage, the VLDB copyright notice andthe title of the publication and its date appear, and notice isgiven that copying is by permission of the Very Large Data BaseEndowment. To copy otherwise, or to republish, requires a feeand/or special permission from the Endowment.
Proceedings of the 26th VLDB Conference,Cairo, Egypt, 2000.
Bay Area or Palo Alto. Over the past few years, webusers have been discovering web sites using web searchengines such as AltaVista 1 and Google 2. In practice,these engines are ineffective for identifying geographi-cally scoped web pages. For instance, finding restau-rants, theaters, and apartment rentals in or near spe-cific regions is a difficult task with these web searchengines.
Now consider the scenario in which we have adatabase with the geographical scope (e.g., a city, astate) of all “resources” (e.g., restaurants, newspapers)with a web presence. We can then exploit such in-formation for a variety of applications, including thefollowing:
• Personalized searching: Consider the case aresident in Palo Alto searches for “newspapers.”A geographically-aware search engine would firstidentify where the user is from (e.g., using a pro-file at my.yahoo.com or my.excite.com). Thesearch engine then uses this information to returnnewspapers that are relevant to the user’s loca-tion, rather than returning references to news-papers all over the world. For instance, the en-gine might recommend The New York Times asa “globally relevant” newspaper, and the Stan-ford Daily as a local newspaper. Note that thisstrategy is not equivalent to the user querying thesearch engine for “newspaper AND Palo Alto,”since such a query would miss references to TheNew York Times, a newspaper that is publishedin a city not in the vicinity of Palo Alto. Thisnewspaper even has the name of a specific city(“New York”) in its name, but is nevertheless ge-ographically relevant to the entire United States.
• Improved browsing: Web portals like Yahoo!already classify web resources manually accord-ing to their geographical scope 3. The techniquesthat we present in this paper will make it possible
1http://www.altavista.com2http://www.google.com3http://dir.yahoo.com/Regional/

to conduct such hierarchical categorization effortsautomatically, improving their scalability.
It is easy to build geographically aware applicationssuch as the above if we are supplied with a table thatlists the geographical scope of each resource. Unfortu-nately, no such table exists for web resources. In thispaper, we consider how to mine the web and automat-ically construct such a table using web hyperlinks andthe actual content of web pages. For example, we canmap every web page to a location based on where itshosting site resides. Then, we can consider the loca-tion of all the pages that point to, say, the StanfordDaily home page 4. By examining the distribution ofthese pointers we can conclude that the Stanford Dailyis of interest mainly to residents of the Stanford area,while The Wall Street Journal is of nation-wide inter-est. We can draw the same conclusion by analyzingthe geographical locations that are mentioned in thepages of the Stanford Daily and in those of The WallStreet Journal.
The primary contributions of this paper include:
1. Algorithms to estimate geographical scope:We propose a variety of algorithms that auto-matically estimate the geographical scope of re-sources, based on exploiting either the distribu-tion of HTML links to the resources (Section 3)or the textual content of the resources (Section 4).
2. Measures to evaluate quality of algorithms:We introduce evaluation criteria for our estima-tion algorithms, based on traditional information-retrieval metrics (Section 5).
3. Experimental study of techniques: We em-pirically evaluate our algorithms using real webdata (Section 6).
4. Implementation of a geographically awaresearch engine: We also discuss how we usedour algorithms in the implementation of a geo-graphically aware search engine for on-line news-papers, which is accessible at http://www.cs.-columbia.edu/~gravano/GeoSearch (Section 7).
Related Work
Traditional information-retrieval research has studiedhow to best answer keyword-based queries over col-lections of text documents [14]. These collections aretypically assumed to be relatively uniform in termsof, say, their quality and scope. With the advent ofthe web, researchers are studying other “dimensions”to the data that help separate useful resources from
4Citations from pages hosted on national access providers likeAmerica On Line would be ignored in this process, unless we canmap these citations to the physical location of their creator. Wediscuss this issue further in Section 6.1.
less-useful ones in an extremely heterogeneous envi-ronment like the web. Techniques for text-databaseselection [3, 8, 13, 10] decide what web databases touse to answer a user query, basing this decision on thetextual contents of the web databases.
Recent research has started to exploit web linksfor improving web-page categorization [4] and for webmining [6, 9, 5]. Notably, search engines such asGoogle [1] and HITS [6, 12] estimate the “importance”of web pages by considering the number of hyperlinksthat point to them. The rationale for their heuristicsis that the larger the number of web users who madea hyperlink to a web page, the higher must be the im-portance of the page. In essence, this work managesto capture an additional dimension to the web data,namely how important or authoritative the pages are.Unlike the new techniques that we introduce in this pa-per, HITS and Google ignore the spatial distributionof incoming links to a web resource.
In this paper, we propose to extract yet anothercrucial dimension of the web data, namely the geo-graphical scope of web resources. This new dimensioncan then be used to complement traditional informa-tion retrieval techniques and those used by Google andHITS to answer web queries in more effective ways.Some commercial web sites already manually classifyweb resources by their location, or keep directory in-formation that lists where each company or web site islocated (e.g., see http://www.iatlas.com). Quite re-cently, the NorthernLight search engine 5 has startedto extract addresses from web pages, letting users nar-row their searches to specific geographical regions (e.g.,to pages “originated” within a five-mile radius of agiven zip code). Users benefit from this informationbecause they can further filter their query results. Inreference [2], we discussed how to map a web site (e.g.,http://www-db.stanford.edu) to a geographical lo-cation (e.g., Palo Alto), and we also presented a toolto visualize such geographical web data. In this paper,we extend this preliminary work to a harder problem:how to automatically estimate the geographical scopeof a web resource? That is, which data is targeted to-wards residents of a city as opposed to the country, orthe world?
2 Geographical Scopes of Web Re-sources
Web resources are built with a target audience in mind.Sometimes this audience is geographically enclosed insome neighborhood (e.g., the target audience of theweb page of a local pizzeria that delivers orders tohouses up to 2 miles away from the store). Some othertimes, the target audience of a resource is distributedacross the country (e.g., the target audience of the webpage of the USA Today newspaper). In this section,
5http://www.northernlight.com/geosearch.html

. . . LA SF
��ll
CA . . .
Washington
DC . . .
Albany NYC . . .
��� TTHHHH
NY
((((((((((������ ��QQQ````````
USA
Figure 1: Portion of the hierarchy of geographical lo-cations for the United States.
we introduce the notion of the geographical scope ofa web resource, which captures the geographical dis-tribution of the target audience of a web resource.This notion is a subjective one, the same way thatthe information-retrieval notion of document relevanceis subjective [14].
Definition 1: The geographical scope of a web re-source w is the geographical area that the creator of wintends to reach.
Using this informal definition, the geographical scopeof our pizzeria above is the neighborhood where thepizzeria resides, whereas the geographical scope of theUSA Today newspaper is the entire United States.
For concreteness, in the rest of the paper we fo-cus on how to approximate the geographical scope ofweb resources within the United States. For this, wewill view the United States as a three-level locationhierarchy (Figure 1). The root of the hierarchy corre-sponds to the entire country. The next level down thehierarchy has one node for each of the 50 states, plusone node for the District of Columbia. Finally, theleaf level in the hierarchy has one node for each cityin the country. Using this hierarchy, a human expertmight specify that the geographical scope of the USAToday newspaper is the whole USA. In contrast, thegeographical scope of The Arizona Daily Star Onlineis the state of Arizona, since this state is the targetaudience of this newspaper. Finally, the geographicalscope of yet another newspaper, The Knoxville News-Sentinel, has the city of Knoxville as its geographicalscope. Of course, this three-level hierarchy can be ex-tended to span all the countries in the world, as well asto further localize resources in cities, to counties andboroughs. However, for simplicity this paper focusesonly on the three levels listed above.
Given our three-level hierarchy of geographical lo-cations in the United States, we can choose to definethe geographical scope of web resources in differentways. For example, instead of indicating that the geo-graphical scope of the USA Today newspaper is the topnode in the hierarchy (i.e., the whole United States),we could list all 50 states plus Washington D.C. ascomprising this geographical scope. Although it couldbe argued that this state-level formulation expressesthe same information as the country-level one, we will
always express geographical scopes using nodes thatare “as high” as possible in our three-level hierarchy.Thus, instead of aggregating the information that theUSA Today is a national newspaper out of the list ofstates of its geographical scope, we will state this factdirectly, and simply specify its scope to be the UnitedStates as a whole.
As mentioned above, the notion of geographicalscope is subjective. To capture this notion accu-rately, we could hand-classify each web resource ac-cording to its intended geographical scope. (Inciden-tally, this is the way that web portals like Yahoo!operate.) In this paper, we study scalable ways toautomatically approximate the resources’ geographicalscopes. Sections 3 and 4 describe two ways in whichwe can estimate the geographical scope of a web re-source. Later, Section 6 will report the experimentsthat show that our automatically-computed approxi-mations closely match the “ideal,” subjective defini-tion.
3 Exploiting Resource Usage
In this section, we show how we can estimate the geo-graphical scope of web resources by exploiting the linkstructure of the web. (We will present an alternativeestimation method that exploits the contents of theweb resources in Section 4.)
Consider a web resource whose geographical scope isthe entire United States (e.g., the USA Today newspa-per). Such a resource is likely to then attract interestacross the country. Our assumption in this section isthat this interest will translate in web pages across thecountry containing HTML links to this web resource. 6
Conversely, a resource with a much more limited ge-ographical scope will exhibit a significantly differentlink distribution pattern across the country. Hence apromising way to estimate the geographical scope ofa resource is to study the geographical distribution oflinks to the resource. More specifically, two conditionsthat a location ` will have to satisfy to be in the geo-graphical scope of a resource w are:
• A significant fraction of `’s web pages containlinks to w (Section 3.1).
• The web pages in ` that contain links to w aredistributed smoothly across ` (Section 3.2).
Below we show how to estimate the geographical scopeof a web resource w by identifying a set of candidatelocations ` that satisfy the two conditions above. Thisprocess results in the estimated geographical scope ofw. Our experiments of Section 6 will show that these
6Of course, if we knew who accesses each web resource wecould use this information for our problem. Unfortunately, webaccess logs for all resources whose geographical scopes we wouldlike to characterize are not easily available.

estimates are often a good approximation of the sub-jective geographical scopes that we discussed in Sec-tion 2.
3.1 Measuring Interest: Power
Intuitively, a location ` that is in the geographicalscope of a web resourcew should exhibit relatively high“interest” in w among its web pages. In other words,a relatively high fraction of the web pages originatedin ` should contain links to resource w. Power (w , `)measures the relative interest in w among the pages inlocation `:
Power (w , `) =Links(w, `)
Pages(`)(1)
where Links(w, `) is the number of pages in location `that contain a link to web resource w, and Pages(`) isthe total number of web pages in `. (We explain howwe compute these numbers in Section 6.1.)
3.2 Measuring Uniformity: Spread
Geographical locations can be decomposed into severalsub-locations. As an example, the United States con-sists of 50 states plus the District of Columbia, whilethe state of New York, in turn, comprises a number ofcities (e.g., Albany, New York City). As we discussedin the previous section, to include a location ` (e.g.,the state of New York) in the geographical scope of aweb resource w, there should be a sufficiently high “in-terest” in resource w in location ` (i.e., Power (w , `) ishigh). In addition, we need to ask that this interest bespread smoothly across the location. Thus, a resourcewith an unusually high number of links originating,say, in New York City, but with no links coming fromother New York state cities should not have the stateof New York in its geographical scope, but perhapsjust New York City instead.
To determine how uniform the distribution of linksto a web resource w is across a location `, we introducea second metric, Spread . Intuitively, Spread(w , `) willbe high whenever Power (w , `i) ∼ Power (w , `j ) for all“sub-locations” `i, `j that are children of ` in the loca-tion hierarchy of Section 2. In what follows, we providethree alternative definitions of Spread . These defini-tions are all built on this intuition, but will computethe value of Spread(w , `) using techniques borrowedfrom different fields. In Section 6 we experimentallycompare how these three definitions perform relativeto each other.
For our three definitions of Spread , Spread(w , `) willhave the maximum possible value (i.e., a value of 1) inthe following two special cases:
• ` is a leaf node of our location hierarchy: Inthis case, by definition, the distribution of Poweracross ` is completely uniform, because we regard
` as an “atomic” location. In this paper, theseatomic locations are the United States cities.
• Power (w , `)=0: In this case, there is no “interest”at all in resource w across location `. Since Spreadmeasures the uniformity of this interest across `,Spread(w , `) is trivially maximum in this case.
Next, we give three alternative definitions forSpread(w , `) for the case when ` is not a leaf nodein our location hierarchy and Power (w , `)> 0. In thedefinitions below, `1, . . . , `n are the children of ` in thehierarchy. Also, we associate with location ` vector~Pages = (p1, . . . , pn), which lists the number of pages
pi = Pages(`i) of each child `i of `. A second vec-tor associated with `, ~Links = (l1, . . . , ln), lists thenumber of pages li = Links(w, `i) that have a link toresource w at location `i, for i = 1, . . . , n. Finally,vector ~Power = (r1, . . . , rn) lists the value of Powerri = Power (w , `i) for each sub-location of `.
Vector-Space Definition of Spread
The first definition of Spread is inspired in the vector-space model from information retrieval [14]. Intu-itively, we will compute how “similar” vectors ~Pages
and ~Links are by computing the cosine of the anglebetween them. If the fraction of pages with links to wis mostly constant across all of `’s children `1, . . . , `n,then ~Pages and ~Links will be roughly scaled versionsof one another, and the cosine of the angle betweenthese vectors will be close to 1:
Spread(w , `) = ~Pages� ~Links
=∑ni=1 pi × li√∑n
i=1 p2i ·√∑n
i=1 l2i
(2)
Relative-Error Definition of Spread
Let R = (∑ni=1 li)/(
∑ni=1 pi). If the distribution of
interest in w were perfectly smooth, then ri = R forall i. To measure how far we are from this perfectlysmooth distribution, we compute how much each rideviates from the “target” value R. We can then givea definition of Spread based on computing the “relativeerror” for each `i with respect to R:
Spread(w , `) =1
1 + 1∑n
i=1pi
∑ni=1 pi ·
|R−ri|R
(3)
Entropy Definition of Spread
Our third and final definition for Spread is based onthe notion of entropy from information theory [11]. Togive this definition, we assume that there is an “infor-mation source” associated with web resource w andgeographical location `. The information source gen-erates symbols representing the different children of

`, namely `1, . . . , `n. Moreover, we assume that thisinformation source generates its symbols by infinitelyexecuting three steps:
1. Randomly select an `i.
2. Randomly select a web page located in `i.
3. If the web page has a link to web site w, thengenerate a symbol representing `i.
Intuitively, when ri = Power (w , `i) is uniform acrossthe `i sub-locations, the information source willachieve the maximum entropy available at geographi-cal location `, which is logn. To make this definitioncomparable across geographical locations with differ-ent numbers of sub-locations, we define Spread as fol-lows:
Spread(w , `) =−∑ni=1
ri∑n
j=1rj· log( ri∑
n
j=1rj
)
logn(4)
3.3 Estimating Geographical Scopes
The previous sections showed metrics to measure thestrength (Power (w , `)) and uniformity (Spread(w , `))of the interest in a web resource w at a location `.In this section we define how we can use Power andSpread to estimate what locations we should includein the geographical scope of a given web resource.
As a first step to estimate the geographical scopeof a web resource w, we identify the locations ` inour hierarchy of Section 2 with Spread(w , `)≥ τc, forsome given threshold 0 ≤ τc ≤ 1. These are the lo-cations with a relatively smooth distribution of linksto w across their sub-locations. Furthermore, we onlyinclude in CGS (w), the candidate geographical scopefor w, those locations that have no ancestor `′ withSpread(w , `′)≥ τc. In other words, CGS (w) containslocations with smooth distribution of links for w suchthat are not “subsumed” by any other ancestor loca-tion also in CGS (w):
Definition 2: The candidate geographical scopeCGS (w) of a web resource w is a set of nodes in thegeographical hierarchy. A location ` is in CGS (w) ifit satisfies the following two conditions, given a fixedthreshold τc:
• Spread(w , `)≥ τc.• For all `′ that is an ancestor of `, Spread(w , `′)<τc.
Given a web resourcew, we can compute CGS (w) witha simple algorithm that recursively visits the nodes inthe location hierarchy top-down. 7
7We have investigated an alternative, “stricter” definition ofCGS(w). According to this definition, ` ∈ CGS(w) if everylocation `′ in the location subtree rooted at ` has Spread(w , `′)≥τc. Our experimental results showed that the weaker definitionthat we give above outperformed this stricter definition. Forspace constraints, we then do not discuss this stricter versionfurther.
The candidate geographical scope of a resourcew, CGS (w), contains locations exhibiting relativelysmooth interest in w. However, as we discussed ear-lier, this interest could be quite small in some cases.In particular, a location ` with Power (w , `)=0 (e.g.,a leaf node) might be included in CGS (w), which isclearly undesirable. Consequently, we need to pruneour candidate geographical scopes to only include lo-cations with high enough Power in the final estimatedgeographical scope of a resource:
Definition 3: The estimated geographical scopeEGS (w) of a web resource w is a set of locations ob-tained from CGS (w) using one of the following scopepruning strategies:
• Top-k pruning: Given an integer k, EGS (w)consists of the top-k locations in CGS (w), in de-creasing order of their Power .
• Absolute-threshold pruning: Given a thresh-old τe, EGS (w) = {` ∈ CGS (w)|Power (w , `) ≥τe}.
• Relative-threshold pruning: Given a percent-age p, EGS (w) = {` ∈ CGS (w)|Power (w , `) ≥max Power (w) × p}, where max Power (w) =max{Power(w , `)|` ∈ CGS (w)}.
4 Exploiting Resource Contents
So far, we have used the distribution of links to a re-source to estimate the resource’s geographical scope.A natural question, however, is whether we can insteadjust examine the resource’s contents to accomplish thistask. In this section we explore this idea, and discusshow to use the resources’ text to estimate their geo-graphical scope.
Consider a resource whose geographical scope is,say, the state of New York. We may argue that thetext in such a resource is likely to mention New Yorkcities more frequently than locations corresponding toother states or countries. This is our main assumptionin this section. (Section 6 experimentally comparesthe resulting technique with our link-based strategy ofSection 3.) Hence an interesting direction to exploreto estimate the geographical scope of a resource is tostudy the distribution of locations that are mentionedin the resource. More specifically, two conditions thata location ` will have to satisfy to be in the geograph-ical scope of a resource w are:
• A significant fraction of all locations mentioned inw are either ` itself or a sub-location of `.
• The location references in w are distributedsmoothly across `.
Next, Section 4.1 shows that we can use the locationreferences in the contents of a web resource to define

a variation of the Power and Spread metrics of Sec-tion 3. We then estimate the geographical scopes com-pletely analogously as we did for the link-based strat-egy. Later, Section 4.2 addresses a fundamental stepin our content-based approach, namely how we can ef-fectively extract the location names from the text of aresource.
4.1 Estimating Geographical Scopes
To estimate whether a location ` is part of a re-source w’s geographical scope we will proceed ex-actly as in Section 3 and compute (modified ver-sions of) Power (w , `) and Spread(w , `). For this,we need to extract from w two numbers. The firstone, Locations(w), is the number of references to ge-ographical locations in w’s text. The second one,References(w, `), is the number of references to ` men-tioned in w’s text. 8 Given these counts, we can adaptour definition of Power from Section 3.1 in the follow-ing way:
Power (w , `) =References(w, `)
Locations(w)(5)
To adapt the definition of Spread of Section 3.2,we now define the following three vectors for a webresource w and a location ` with children `1, . . . , `n.First, vector ~Locations = (p1, . . . , pn) is a vectorwith every element having the same value pi =Locations(w), which is the number of references togeographical locations in w’s text. Second, vec-tor ~References = (l1, . . . , ln) lists the number ofreferences to each sub-location `i in w’s text, i.e.,li = References(w, `i). Finally, vector ~Power =(r1, . . . , rn) lists each sub-location’s Power value ri =Power (w , `i). These vectors will play a role that iscompletely analogous to those of the ~Pages, ~Links, and~Power vectors of Section 3, respectively, for defining
Spread(w , `). We can now use exactly the same defi-nitions for Spread that we used in Section 3 and cal-culate the estimated geographical scope EGS (w) for aweb resource w.
4.2 Extracting and Processing Location Ref-erences
To estimate the geographical scope of a web resourcew as in the previous section, we need to extract all ofthe locations that are mentioned in the textual con-tents of w. Furthermore, the technique above expectsthe list of cities that are mentioned in the text of theweb resources. In this section, we discuss the mainproblems involved in such an extraction process.
8We will discuss in Section 4.2 how we map references to,say, an entire state to references to individual cities within thestate, which is what we count in References and Locations .
Extracting Location Names from Plain Text
State-of-the-art named-entity taggers manage to iden-tify entities like people, organizations, and locationsin natural-language text with high accuracy. For theexperiments that we report in Section 6 we used theAlembic Workbench system developed at MITRE [7].
Normalizing and Disambiguating LocationNames
After the tagging phase in which we identify the loca-tions (e.g., “New York City,” “California”) mentionedin w, we should map each location to an unambiguouscity-state pair. Problems that arise when completingthis task include:
• Aliasing: Different names might be commonlyused for the same location. For example, SanFrancisco is often referred to as SF. It is rela-tively easy to address this problem at the coun-try or state level. (These aliases are indeedquite limited, and we compiled a list of them byhand.) For cities, though, we resorted to a web-accessible database of the United States PostalService (USPS) 9. For each zip code, this servicereturns a list of variations of the correspondingcity’s name. For example, if we use Columbia Uni-versity’s zip code, 10027, we obtain a list of namesfor New York City, including New York, Manhat-tan, New York City, NY City, NYC, and, interest-ingly enough, Manhattanville. (Incidentally, theUSPS standard form for this city is New York.)By repeatedly querying the USPS database withdifferent zip codes, we can build a list of city-namealiases, together with the corresponding “normalform” for each group.
• Ambiguity: Another problem when processing agiven city name is that it can refer to cities in dif-ferent states. For example, four states, Georgia,Illinois, Mississippi, and Ohio, have a city calledColumbus. A reference to such a city withouta state qualification is inherently ambiguous, un-less of course we could understand the context inwhich the reference was made. We have developedheuristics for managing this kind of ambiguous lo-cation references. Our technique starts by identi-fying the unambiguous location references in theweb resource at hand w, and uses them to disam-biguate the remaining references. Intuitively, ifw mentions mostly locations in the state of NewYork, for example, we will assume that a refer-ence to “Manhattan” is a reference to New YorkCity, not to Manhattan, Kansas. More specifi-cally, if w mentions an ambiguous city name C mtimes, and C can refer to a city in a number of
9http://www.usps.gov

states S1, . . . , Sk, then we “distribute” the m oc-currences of C among the k states proportionallyto the distribution of unambiguous cities in thesestates. Suppose that in our example 90% of theunambiguous cities that are mentioned in resourcew are in the state of New York, and the remaining10% are in the state of Kansas. Then, if w refersto Manhattan five times, we will assume that 4.5of these references correspond to New York, NY,and only 0.5 of them to Manhattan, KS.
Mapping Locations to City Names
A location name can refer to a city, a state, or a coun-try, for example. Our technique to estimate geograph-ical scopes analyzes the distribution of cities that arementioned at a web resourcew. Consequently, we needa way to map references to, say, states to city refer-ences that our technique can use. For this, we simply“push down” references to high-level locations in ourlocation hierarchy (Section 2). This way, a referenceto the state of New York will be pushed down as areference to every city in the state. When we propa-gate these references down, we also scale their weightby some constant α. (A value of α = 0.1 worked bestin our Section 6 experiments.)
5 Evaluating the Quality of the Esti-mated Geographical Scopes
In the previous sections we discussed two approachesto estimating the geographical scope of resources. Ofcourse, other approaches are possible (e.g., a “hybrid”strategy combining our two techniques). We now pro-pose measures to evaluate the quality of any such al-gorithm for estimating a web resource’s geographicalscope.
To evaluate the quality of our estimated geographi-cal scopes, we need to compare them against the ideal,subjective scopes. We could base our comparison onmetrics commonly used for classification tasks: for ex-ample, we could just compute the number of web re-sources in our testbed for which we managed to iden-tify their geographical scope perfectly. Such a metricwould not fully capture the nuances of our problem.For example, if the geographical scope of a resourcew is {California} and we compute EGS (w) as, say,{California, New York City}, this metric would markour answer as completely wrong. Similarly, considerthe case where our EGS (w) computation consists of,say, 90% of the California cities, but does not includeCalifornia as a whole state, which would have beenthe perfect answer. Traditional classification accuracymetrics would also consider our estimate as completelywrong, even when our technique managed to identifyonly cities in the right state as part of the geographicalscope of w.
With these observations in mind, we adapt the pre-cision and recall metrics from the information retrievalfield to yield metrics that we believe are appropriatefor our problem. More specifically, we will define pre-cision and recall for our problem as follows, after weintroduce an auxiliary definition. Given a set of loca-tions L, we will “expand” it by including all locationsunder a location ` ∈ L. Thus, Expanded(L) = {`′ lo-cation | `′ ∈ L or `′ is in the location subtree of some` ∈ L}. Now, let w be a web resource, Ideal be its“expanded” geographical scope, and Estimated be ourexpanded estimate, Expanded(EGS (w)). Then:
Precision(w) =|Ideal
⋂Estimated |
|Estimated |
Recall(w) =|Ideal
⋂Estimated ||Ideal |
Intuitively, precision measures the fraction of locationsin an estimated geographical scope that are correct,i.e., that are also part of the ideal geographical scope.(Perfect precision might be trivially achieved by al-ways returning empty geographical scopes.) Recallmeasures the fraction of the locations in the ideal ge-ographical scope that are captured in our estimatedgeographical scope. (Perfect recall might be triviallyachieved by always including all locations in the ge-ographical scopes.) Finally, to simplify the interpre-tation of our experiments, we combine precision andrecall into a single metric using the F -measure [15]:
F (w) =2× Precision(w) ×Recall(w)
Precision(w) + Recall(w)
6 Experimental Evaluation
Section 2 defined the “ideal,” subjective geographicalscope of a web resource w. Later, we showed how wecan automatically calculate the estimated geographicalscope EGS (w) by analyzing the geographical distribu-tion of HTML links to w (Section 3), or, alternatively,by analyzing the distribution of location names fromthe textual contents of w (Section 4). In this section,we experimentally evaluate how well our different tech-niques can approximate the ideal geographical scopesusing the evaluation criteria we discussed in Section 5.We describe our experimental setting in Section 6.1.We then report the results of our experiments, whichinvolved real web resources, in Section 6.2.
6.1 Experimental Setting
In this section we explain the main aspects of our ex-perimental setting. In particular, we describe the realweb resources that we used, and highlight some of thechallenging implementation issues that we had to ad-dress to carry out our study.

Web Resources
Ideally, to evaluate our techniques of Sections 3 and 4we should use a set of real web resources, each with itscorresponding geographical scope, as determined by ahuman expert. (Analogously, the information retrievalfield relies on human relevance judgments to evalu-ate the performance of search-engine algorithms [14].)For our experiments, we needed a list of web resourceswhose intended geographical scope was self-apparentand uncontested. Furthermore, we wanted our list tocover the different levels of our location hierarchy ofSection 2. In other words, we wanted resources whowould have the United States as their geographicalscope, but we also wanted resources whose geographi-cal scope was at the state and city levels. Finally, theresources that we picked needed to have a sufficientlylarge number of HTML links directed to them, so thatwe can apply our technique of Section 3. (We discusshow to handle resources with not enough references tothem in Section 8.) With the above goals in mind, wecollected a list of 150 web resources whose geographicalscopes span the three levels of our location hierarchy:
• National level: 50 of our web resources have theUnited States as their geographical scope. Theseresources are the 50 most heavily cited FederalGovernment web sites listed in the FedWorld website 10. (We determined the 50 most cited pagesby querying AltaVista to obtain the number ofpages with links to each of these resources.) Theseweb sites have the whole United States as theirintended audience, and include the web sites ofNASA 11 and the National Endowment for theArts 12, for example.
• State level: 50 of our web resources have a stateas their geographical scope. These resources arethe official web site of each state in the UnitedStates (e.g., http://www.state.ny.us (state ofNew York)), and have their corresponding stateas their geographical scope.
• City level: 50 of our web resources have a cityas their geographical scope. These resources arethe 50 most cited among the US cities’ official websites (e.g., http://www.ci.sf.ca.us (San Fran-cisco)), and have their corresponding city as theirgeographical scope. (We obtained a list of theUS cities’ official web sites from Piper Resources’“State and Local Government on the Net.” 13)
Implementation Issues
We now describe some interesting tasks that we hadto perform to run our experiments:
10http://www.fedworld.gov/locator.htm11http://www.nasa.gov12http://www.arts.endow.gov13http://www.piperinfo.com/state/states.html
• Mapping web pages to city names: Our tech-nique of Section 3 requires that we find all pageswith HTML links to a given web resource w. Af-ter identifying these pages, we need to place theirlocation so that we can study their geographicaldistribution and estimate w’s geographical scope.This is a challenging task, because we really needthe location of the author of a page, which mightbe quite different from the location of the site thathosts the page. For example, web pages with linksto w from, say, the aol.com domain are hardlyuseful for our task: If we examine just the lo-cation of the web site where these pages reside,we would most likely be misguided in determin-ing w’s geographic scope. (We elaborated on theseissues further and outlined alternative approachesto “placing web pages on the map” in [2].) A keyobservation that we exploit for our experimentsis that it suffices for our Section 3 technique tohave a reasonable sample of the pages with linksto resource w to estimate w’s geographical scope.Following this observation, we focussed on webpages whose author’s location we could determinereliably, and that would span the entire UnitedStates. More specifically, we analyzed link infor-mation from pages originating only in educationaldomains (e.g., from web sites with a .edu suffix,like www.columbia.edu). Given such a page, wequery the whois service to map the page’s website into its corresponding zip code. After this,we query the USPS zip-code server and obtain thestandard city name associated with the zip code.
• Refining our location hierarchy: Our ex-perimental setting considers links originating onlyin educational institutions. Unfortunately, not allcities have one such institution. Hence, we refinedour location hierarchy to include only cities witha university with a .edu web site. We furtherpruned our list by eliminating every city hostingfewer than 500 pages in .edu web sites, so that weanalyze only cities with a significant web presencein .edu domains. At the end of this process, weare left with a location hierarchy consisting of 673cities as leaf nodes, the 50 states and the Districtof Columbia as intermediate nodes, and the entireUnited States as the root node.
• Computing Pages(`) and Links(w, `): For eachcity ` in our location hierarchy, we need to ob-tain the number of pages from .edu domains thatare located in it. To get this number, we queryAltaVista and obtain the number of pages thateach educational institution in location ` hosts.By adding these numbers for each institution in` we compute Pages(`), which we need in Sec-tion 3. Similarly, we can identify how many ofthese pages have links to a specific web resource
w to compute Links(w, `).
• Obtaining the textual contents of a web re-source w: For our content-based technique ofSection 4, we download the full-text contents ofthe 150 web sites of our testbed, using Gnu’s wgetweb crawler. We then use the lynx browser toeliminate the HTML tags in the web pages andextract the plain-English text in them. As ex-plained in Section 4, after this we run the Alem-bic named-entity tagger [7] to extract the loca-tion names that are mentioned in the plain text.Finally, we resolve aliasing and ambiguity issues,map locations to city names, and estimate the ge-ographical scopes as outlined in Section 4. 14
6.2 Experimental Results
In Table 1 we summarize the algorithms we now eval-uate. In addition to the three different definitions ofSpread we discussed in Section 3.2, we also consider thefollowing two simple “baseline” algorithms for com-puting candidate geographical scopes. The first one,AllLeaves, always defines the candidate geographicalscope CGS (w) of a web resource w as consisting of allof the cities in our location hierarchy. In contrast, thesecond baseline technique, OnlyRoot, always definesCGS (w) as consisting of the United States only. Thecandidate geographical scope, obtained by any base-line technique or Spread definition, is then pruned byone of the three scope-pruning strategies to producethe estimated geographical scope as described in Sec-tion 3.3. Table 1 also summarizes the parameters in-volved with each of the different algorithms. For exam-ple, recall that k is a tunable parameter in the TopKscope-pruning strategy of Section 3.3.
We comprehensively evaluated the above algo-rithms to understand the impact of the differenttunable parameters on precision, recall, and the F -measure. Due to lack of space, we present a few sam-ple results to highlight some of our key observations.Specifically, we present our results for the relative-threshold pruning strategy RelThr . We evaluated ourresults for the TopK and for the AbsThr strategies aswell, and observed similar trends. Hence we do notdiscuss these further.
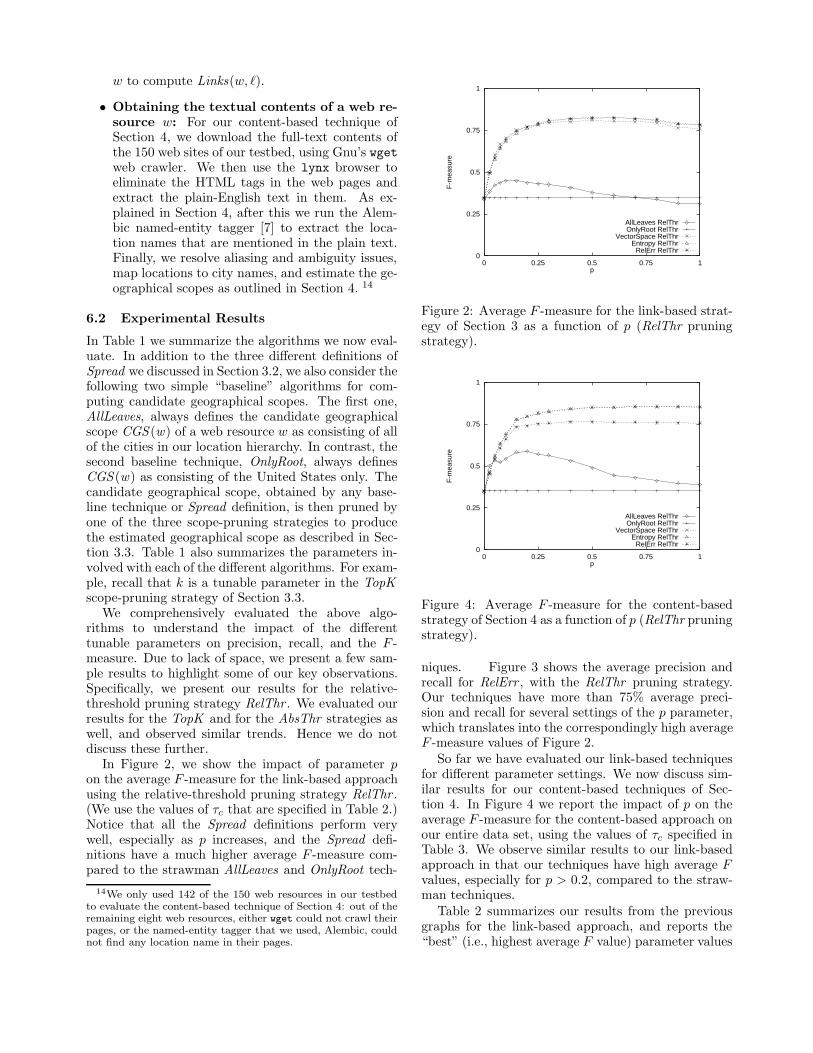
In Figure 2, we show the impact of parameter pon the average F -measure for the link-based approachusing the relative-threshold pruning strategy RelThr .(We use the values of τc that are specified in Table 2.)Notice that all the Spread definitions perform verywell, especially as p increases, and the Spread defi-nitions have a much higher average F -measure com-pared to the strawman AllLeaves and OnlyRoot tech-
14We only used 142 of the 150 web resources in our testbedto evaluate the content-based technique of Section 4: out of theremaining eight web resources, either wget could not crawl theirpages, or the named-entity tagger that we used, Alembic, couldnot find any location name in their pages.
0
0.25
0.5
0.75
1
0 0.25 0.5 0.75 1
F-m
easu
re
p
AllLeaves RelThrOnlyRoot RelThr
VectorSpace RelThrEntropy RelThr
RelErr RelThr
Figure 2: Average F -measure for the link-based strat-egy of Section 3 as a function of p (RelThr pruningstrategy).
0
0.25
0.5
0.75
1
0 0.25 0.5 0.75 1
F-m
easu
re
p
AllLeaves RelThrOnlyRoot RelThr
VectorSpace RelThrEntropy RelThr
RelErr RelThr
Figure 4: Average F -measure for the content-basedstrategy of Section 4 as a function of p (RelThr pruningstrategy).
niques. Figure 3 shows the average precision andrecall for RelErr , with the RelThr pruning strategy.Our techniques have more than 75% average preci-sion and recall for several settings of the p parameter,which translates into the correspondingly high averageF -measure values of Figure 2.
So far we have evaluated our link-based techniquesfor different parameter settings. We now discuss sim-ilar results for our content-based techniques of Sec-tion 4. In Figure 4 we report the impact of p on theaverage F -measure for the content-based approach onour entire data set, using the values of τc specified inTable 3. We observe similar results to our link-basedapproach in that our techniques have high average Fvalues, especially for p > 0.2, compared to the straw-man techniques.
Table 2 summarizes our results from the previousgraphs for the link-based approach, and reports the“best” (i.e., highest average F value) parameter values

Label Description Associated ParameterBaseline AllLeaves Scope consists of all USA cities –
Techniques OnlyRoot Scope consists of just USA –Spread VectorSpace Vector-space definition of Spread τc
Definition Entropy Entropy definition of Spread τc(Section 3.2) RelErr Relative-error definition of Spread τc
Scope-Pruning TopK Top-k pruning kStrategies AbsThr Absolute-threshold pruning τe
(Section 3.3) RelThr Relative-threshold pruning p
Table 1: The variations of our techniques that we use in our experiments, together with their associated param-eters.
0
0.25
0.5
0.75
1
0 0.25 0.5 0.75 1
Pre
cisi
on
p
AllLeaves RelThrOnlyRoot RelThr
RelErr RelThr
0
0.25
0.5
0.75
1
0 0.25 0.5 0.75 1
Rec
all
p
AllLeaves RelThrOnlyRoot RelThr
RelErr RelThr
(a) (b)
Figure 3: Average precision (a) and recall (b) for the link-based strategy of Section 3 as a function of p (τc = 0.57for RelErr; RelThr pruning strategy).
for each of our Spread definitions and scope-pruningstrategies. In Table 3, we report similar results forthe content-based approach. In general, we see thatthe relative-threshold strategy to pruning scope worksbest in practice. In our data set, the content-basedapproach has a slight advantage over the link-basedapproach. However, we should regard these two ap-proaches as complementary to each other for the fol-lowing reasons, which we already touched on in Sec-tion 6.1. Often, web sites restrict robots from crawl-ing their site (e.g., this is the case for The New YorkTimes newspaper). In such cases, we cannot applyour content-based approach for estimating geograph-ical scope, while we can still resort to the link-basedapproach. In other cases, the number of incoming linksto a web site may be limited. In these cases, we shoulduse our content-based approach, as long as any usefulgeographical information can be extracted from suchresources that are not heavily cited.
7 A Geographically Aware Search En-gine
Based on the techniques we developed in the previoussections, we have implemented a geographically awaresearch engine that downloads and indexes the full con-tents of 436 on-line newspapers based in the UnitedStates. Our search engine estimates the geographical
scope of the newspapers using the link-based techniqueof Section 3 with the Entropy definition for Spread andthe RelThr scope-pruning strategy. This search en-gine is available at http://www.cs.columbia.edu/-~gravano/GeoSearch.
Our search engine automatically pre-computes thegeographical scope of the 436 newspapers that it in-dexes. When users query the engine, they specify theirzip code in addition to their list of search keywords.Our system first uses just the keywords to rank thenewspaper articles on those keywords using a stan-dard, off-the-shelf text search engine called Swish. Oursystem then filters out all pages coming from newspa-pers whose geographical scope does not include theuser’s specified zip code. Furthermore, our engine re-computes the score for each surviving page and returnsthe pages ranked in the resulting order. A page’s newscore is a combination of the Swish-generated scorefor the page and the Power of the location in thegeographical scope of the page’s newspaper that en-closes the user’s zip code. Figure 5 shows the resultsfor query “startups business” with zip code 94043,which corresponds to Mountain View, California. Thefirst article is from The Nando Times, a national on-line newspaper. Our system has determined that thisnewspaper’s geographical scope is the whole country,hence the coloring of the map next to the correspond-

TopK AbsThr RelThrF τc k F τc τe F τc p
AllLeaves 0.34 – ∞ 0.51 – 0.0007 0.45 – 0.1OnlyRoot 0.35 – 1 0.35 – 0 0.35 – 0
VectorSpace 0.76 0.7 1 0.52 0.9 0.0007 0.81 0.7 0.5Entropy 0.78 0.8 1 0.51 0.8 0.0007 0.82 0.8 0.6RelErr 0.78 0.57 1 0.52 0.67 0.0007 0.83 0.57 0.6
Table 2: Best average F -measure results for different Spread definitions (Section 3.2) and scope-pruning strategies(Section 3.3), using the link-based strategy of Section 3.
TopK AbsThr RelThrF τc k F τc τe F τc p
AllLeaves 0.37 – 1 0.42 – 0.0007 0.59 – 0.2OnlyRoot 0.35 – 1 0.35 – 0 0.35 – 0
VectorSpace 0.85 0.6 1 0.82 0.6 0.1 0.86 0.6 0.7Entropy 0.85 0.8 1 0.82 0.8 0.1 0.85 0.8 0.7RelErr 0.76 0.57 1 0.72 0.50 0.1 0.76 0.57 0.5
Table 3: Best average F -measure results for different Spread definitions (Section 3.2) and scope-pruning strategies(Section 3.3), using the content-based strategy of Section 4.
ing article. The second article returned is from theSan Jose Mercury News, a newspaper based in SanJose, California, whose technology reports have fol-lowers across the country. Our search engine has clas-sified this newspaper as having a national geographicalscope. The last article returned originated in a news-paper whose geographical scope consists of the entirestate of California, which is marked with a solid coloron the map, plus a few cities scattered across the coun-try, indicated by placing a dot in their correspondingstates.
8 Conclusion
In this paper, we discussed how to estimate the geo-graphical scope of web resources, and how to exploitthis information to build geographically aware applica-tions. The main contributions of this paper include au-tomatic estimation algorithms based on web-page con-tent and HTML link information, metrics to evaluatethe quality of such algorithms, a comprehensive eval-uation of these techniques in a realistic experimentalscenario, and an implementation of a geographicallyaware search engine for newspaper articles. One ofthe key observations of this paper is that the content-based techniques and the link-based techniques havespecific advantages and disadvantages, and in fact canbe used as complementary estimators of the scope ofweb resources. In effect, some sites might not allowus to “crawl” their contents, preventing us from us-ing our content-based techniques. Some other sitesmight have a low number of incoming HTML links,preventing us from using our link-based techniques re-
liably. By combining these two approaches we can ac-curately estimate the geographical scope of many webresources, hence capturing a crucial dimension of webdata that is currently ignored by search engines.
Acknowledgments
This material is based upon work supported by theNational Science Foundation under Grants No. IIS-97-33880 and IRI-96-19124. We also thank Jon Oringerfor implementing the search engine of Section 7, andJun Rao and Vasilis Vassalos for useful comments onthe paper.
References
[1] S. Brin and L. Page. The anatomy of a large-scalehypertextual web search engine. In Proceedings ofthe Seventh International World Wide Web Con-ference (WWW7), Apr. 1998.
[2] O. Buyukkokten, J. Cho, H. Garcıa-Molina,L. Gravano, and N. Shivakumar. Exploiting ge-ographical location information of web pages. InProceedings of the ACM SIGMOD Workshop onthe Web and Databases (WebDB’99), June 1999.
[3] J. P. Callan, Z. Lu, and W. B. Croft. Searchingdistributed collections with inference networks. InProceedings of the Eighteenth ACM InternationalConference on Research and Development in In-formation Retrieval (SIGIR’95), July 1995.

Figure 5: Search results from our geographically-aware search engine.
[4] S. Chakrabarti, B. Dom, and P. Indyk. Enhancedhypertext categorization using hyperlinks. In Pro-ceedings of the 1998 ACM International Con-ference on Management of Data (SIGMOD’98),June 1998.
[5] S. Chakrabarti, B. Dom, S. R. Kumar, P. Ragha-van, S. Rajagopalan, A. Tomkins, D. Gibson, andJ. Kleinberg. Mining the web’s link structure.IEEE Computer Magazine, 32(8):60–67, 1999.
[6] S. Chakrabarti, B. Dom, P. Raghavan, S. Ra-jagopalan, D. Gibson, and J. Kleinberg. Auto-matic resource compilation by analyzing hyper-link structure and associated text. In Proceedingsof the Seventh International World Wide WebConference (WWW7), Apr. 1998.
[7] D. Day, J. Aberdeen, L. Hirschman, R. Kozierok,P. Robinson, and M. Vilain. Mixed-initiative de-velopment of language processing systems. InProceedings of the Fifth ACL Conference on Ap-plied Natural Language Processing, Apr. 1997.
[8] J. C. French, A. L. Powell, C. L. Viles, T. Em-mitt, and K. J. Prey. Evaluating database se-lection techniques: A testbed and experiment. InProceedings of the Twentyfirst ACM InternationalConference on Research and Development in In-formation Retrieval (SIGIR’98), Aug. 1998.
[9] D. Gibson, J. Kleinberg, and P. Raghavan. Infer-ring web communities from link topology. In Pro-ceedings of the Ninth ACM Conference on Hyper-text and Hypermedia, pages 225–234, June 1998.
[10] L. Gravano, H. Garcıa-Molina, and A. Tomasic.GlOSS: Text-source discovery over the Internet.ACM Transactions on Database Systems, 24(2),June 1999.
[11] R. W. Hamming. Coding and Information The-ory. Prentice-Hall, 1980.
[12] J. Kleinberg. Authoritative sources in a hyper-linked environment. In Proceedings of the NinthAnnual ACM-SIAM Symposium on Discrete Al-gorithms, pages 668–677, Jan. 1998.
[13] W. Meng, K.-L. Liu, C. T. Yu, X. Wang,Y. Chang, and N. Rishe. Determining textdatabases to search in the Internet. In Proceedingsof the Twenty-fourth International Conference onVery Large Databases (VLDB’98), Aug. 1998.
[14] G. Salton. Automatic Text Processing: The trans-formation, analysis, and retrieval of informationby computer. Addison-Wesley, 1989.
[15] C. J. Van Rijsbergen. Information Retrieval. But-terworths, 1979.