coms e6125 web-enhanced information management (whim)
DESCRIPTION
COMS E6125 Web-enHanced Information Management (WHIM). Prof. Gail Kaiser Spring 2008. Today’s Topics. Web Search – partially adapted from Alexandros Biliris (adjunct here) Semantic Web – partially adapted from York Sure (University of Karlsruhe). Information Retrieval as a Field. - PowerPoint PPT PresentationTRANSCRIPT

25 March 2008 Kaiser: COMS E6125 1
COMS E6125 Web-COMS E6125 Web-enHanced Information enHanced Information Management (WHIM)Management (WHIM)
COMS E6125 Web-COMS E6125 Web-enHanced Information enHanced Information Management (WHIM)Management (WHIM)
Prof. Gail KaiserProf. Gail Kaiser
Spring 2008Spring 2008

25 March 2008 Kaiser: COMS E6125 2
Today’s Topics• Web Search – partially adapted
from Alexandros Biliris (adjunct here)
• Semantic Web – partially adapted from York Sure (University of Karlsruhe)

25 March 2008 Kaiser: COMS E6125 3
Information Retrieval as a Field
• An “old” field that addresses issues related to – Classification and categorization of documents– Systems and languages for searching for words– User interfaces and visualization of results
• Field was previously seen as of narrow interest – mainly, library search
• The advent of the Web brings IR to the forefront– The Web became a huge “library” and everybody
has free access to it (with no special training on “search”)
– No central editorial board

25 March 2008 Kaiser: COMS E6125
IR: A World of Words
• Typical IR model: The dataset consists of documents, each of which is a bag (multiset) of words (terms)
• IR functionality: map words to documents– Search for documents that contain – a given word– word1 AND word2– word1 AND word2 AND NOT word3– etc.

25 March 2008 Kaiser: COMS E6125
IR: A World of Words
• Detail 1: Stop Words– Certain words are considered irrelevant and not
placed in the bag, e.g., “and”, “the”, …
• Detail 2: “Stemming” and other content analysis– Using language-specific rules, convert words to
their basic form, e.g., “surfing”, “surfed” --> “surf”
– Deal with synonyms, misspellings, abbreviations

25 March 2008 Kaiser: COMS E6125 6
Rankings• Finding documents that are the
most relevant to a user’s query is quite imprecise
• A ranking is an ordering of the documents retrieved that (hopefully) reflects their relevance to the user query

25 March 2008 Kaiser: COMS E6125
IR vs. DBMS• IR
– Imprecise semantics– Keyword search– Text, unstructured
data– No transactions – Partial results (top k)– Relevance is built-in
• DBMS– Precise semantics– SQL– Structured data– Transactional
semantics– Generate full answer– Relevance is built on
top

25 March 2008 Kaiser: COMS E6125 8
Inverted indexes
• Permit fast search for individual terms
• For each term, you get a list consisting of:– document ID – frequency of term in doc (optional) – position of term in doc (optional)

25 March 2008 Kaiser: COMS E6125 9
Inverted indexes
• These lists can be used to solve Boolean queries:
•country -> d1, d2•manor -> d2•country AND manor -> d2
• Also used for statistical ranking algorithms

How Inverted Files Are Created
• Periodically rebuilt, static otherwise• Documents are parsed to extract
tokens
Now is the timefor all good men
to come to the aidof their country
Doc 1
It was a dark andstormy night in
the country manor. The time was past midnight
Doc 2
Term Doc #now 1is 1the 1
time 1for 1all 1good 1men 1to 1come 1to 1the 1aid 1
of 1their 1country 1it 2was 2a 2dark 2and 2stormy 2night 2
in 2the 2country 2manor 2the 2time 2was 2past 2midnight 2

How Inverted Files are Created
• After all documents have been parsed the inverted file is sorted alphabetically
Term Doc #a 2aid 1all 1
and 2come 1country 1country 2dark 2for 1good 1in 2is 1it 2
manor 2men 1midnight 2night 2now 1of 1past 2stormy 2the 1the 1
the 2the 2their 1time 1time 2to 1to 1was 2was 2
Term Doc #now 1is 1the 1
time 1for 1all 1good 1men 1to 1come 1to 1the 1aid 1
of 1their 1country 1it 2was 2a 2dark 2and 2stormy 2night 2
in 2the 2country 2manor 2the 2time 2was 2past 2midnight 2

How Inverted Files are Created
• Multiple term entries for a single document are merged
• Within-document term frequency information is compiled
Term Doc # Freqa 2 1aid 1 1all 1 1
and 2 1come 1 1country 1 1country 2 1dark 2 1for 1 1good 1 1in 2 1is 1 1it 2 1
manor 2 1men 1 1midnight 2 1night 2 1now 1 1of 1 1past 2 1stormy 2 1the 1 2the 2 2
their 1 1time 1 1time 2 1to 1 2was 2 2
Term Doc #a 2aid 1all 1
and 2come 1country 1country 2dark 2for 1good 1in 2is 1it 2
manor 2men 1midnight 2night 2now 1of 1past 2stormy 2the 1the 1
the 2the 2their 1time 1time 2to 1to 1was 2was 2

25 March 2008 Kaiser: COMS E6125 13
How Inverted Files are Created
• Finally, the file can be split into – A Dictionary or Lexicon file and – A Postings file

How Inverted Files are Created
Dictionary/Lexicon PostingsTerm Doc # Freqa 2 1aid 1 1all 1 1
and 2 1come 1 1country 1 1country 2 1dark 2 1for 1 1good 1 1in 2 1is 1 1it 2 1
manor 2 1men 1 1midnight 2 1night 2 1now 1 1of 1 1past 2 1stormy 2 1the 1 2the 2 2
their 1 1time 1 1time 2 1to 1 2was 2 2
Doc # Freq2 11 11 1
2 11 11 12 12 11 11 12 11 12 1
2 11 12 12 11 11 12 12 11 22 2
1 11 12 11 22 2
Term N docs Tot Freqa 1 1aid 1 1all 1 1
and 1 1come 1 1country 2 2dark 1 1for 1 1good 1 1in 1 1is 1 1it 1 1manor 1 1
men 1 1midnight 1 1night 1 1now 1 1of 1 1past 1 1stormy 1 1the 2 4their 1 1time 2 2
to 1 2was 1 2

25 March 2008 Kaiser: COMS E6125 15
Search Engine Characteristics
• Unedited data – anyone can enter content– Quality issues, spam
• Varied information types– Phone book, brochures, catalogs,
dissertations, news reports, weather, all in one place!

25 March 2008 Kaiser: COMS E6125 16
Search Engine Characteristics
• Different kinds of users– LexisNexis: Paid professional searchers– Online catalogs: Scholars searching
scholarly literature– Web: Every type of person with every type
of goal
• Scale– Hundreds of millions of searches/day– Billions of static documents– Tens of millions of Web servers

25 March 2008 Kaiser: COMS E6125 17
Directories vs. Search Engines
• Directories– Hand-selected
sites– Search over the
contents of the descriptions of the pages
– Organized in advance into categories
• Search Engines– All pages in all
sites – Search over the
contents of the pages themselves
– Organized in response to a query by relevance rankings or other scores

25 March 2008 Kaiser: COMS E6125 18
Inverted Indexes for Web Search Engines
• Inverted indexes are still used, even though the web is so huge.
• Some systems partition the indexes across different machines; each machine handles different parts of the data.
• Other systems duplicate the data across many machines; queries are distributed among the machines.
• Most do a combination of these.

Ranking Strategies
• Details proprietary and changing• Combining subsets of:
– IR-style relevance: Based on term frequencies, proximities, position (e.g., in title), font, etc.
– Popularity information - Frequently visited pages– Link analysis information - Which sites are linked
to by other sites– A variant of vector space ranking to combine these
• Make a vector of weights for each feature• Multiply this by the counts for each feature

25 March 2008 Kaiser: COMS E6125 20
Link Analysis for Ranking Pages
• Assumption: If the pages pointing to this page are good, then this is also a good page
• Draws upon earlier research in sociology and bibliometrics.– Kleinberg’s model includes “authorities”
(highly referenced pages) and “hubs” (pages containing good reference lists).
– Google model is a version with no hubs

25 March 2008 Kaiser: COMS E6125 21
Intuition• Authority comes from in-edges. • Being a good hub comes from
out-edges.• Better authority comes from in-
edges from good hubs. • Being a better hub comes from
out-edges to good authorities.
A H

25 March 2008 Kaiser: COMS E6125 22
Web Crawlers• How do the web search engines get all
of the items they index?• Main idea:
– Start with known sites– Record information for these sites– Follow the links from each site– Record information found at new sites– Repeat

25 March 2008 Kaiser: COMS E6125 23
Web Crawling Algorithm
1. Put a set of known sites on a queue2. Repeat the following until the queue is
empty:– Take the first page off of the queue– If this page has not yet been processed:
• Record the information found on this page• Add each link on the current page to the
queue• Record that this page has been processed

25 March 2008 Kaiser: COMS E6125 24
Robot Exclusion Protocol
• Polite crawlers first attempt to download the file robots.txt
• Created by the Web master to indicate which part of the site is off-limits to crawlers
User-agent: *
Disallow: /

25 March 2008 Kaiser: COMS E6125 25
Robot Exclusion Protocol
• robots META tag<HTML>
<HEAD>
<META NAME="robots" CONTENT="noindex,nofollow">
...
</HEAD>
...
</HTML>

25 March 2008 Kaiser: COMS E6125 26
Web Crawling Issues/Challenges
• Politeness: robots “keep out” signs • Freshness - Figure out which pages change
often, and re-crawl these often• Quantity (> 6B docs on > 60M Web servers)• Quality - Duplicates, virtual hosts, etc.
– Convert page contents with a hash function– Compare new pages to the hash table

25 March 2008 Kaiser: COMS E6125 27
Web Crawling Issues/Challenges
• Lots of other problems– Server unavailable; incorrect html; missing
links; attempts to “fool” search engine by giving crawler a version of the page with lots of spurious terms added ...
• Web crawling is difficult to do robustly!

25 March 2008 Kaiser: COMS E6125 28
The Deep (Hidden) Web
• Pages that do not actually exist as such: they are created dynamically as a result of a request/query to a specific application that most likely uses a DBMS
• Content in the deep Web is massive• For a Web page to be discovered by a
crawler, it must be static and linked

Perspective on Crawlers/Engines
• Web content is getting more – Volatile
• Frequent updates in content and/or location• New Web sites appear and existing ones
disappear on a daily basis– Dynamic
• Content produced by database-driven applications
• These are the same challenges faced by– Caching proxies– Content distribution networks

25 March 2008 Kaiser: COMS E6125 30
Today’s Topics• Web Search – partially adapted
from Alexandros Biliris (adjunct here)
• Semantic Web – partially adapted from York Sure (University of Karlsruhe)

25 March 2008 Kaiser: COMS E6125 31
Simplicity is Good• The World Wide Web contains huge amounts of
information created by many different organizations, communities and individuals for many different reasons
• Web users can easily access this information by specifying URI (Universal Resource Identifier) addresses or using a search engine, and following links to find other related resources
• This simplicity is a key aspect that made the Web so popular

25 March 2008 Kaiser: COMS E6125 32
Simplicity is Bad• The simplicity of the current Web has a price• It is very easy to get lost, or discover irrelevant
or unrelated information• For instance, if we search for courses taught by
a person named “Gail Kaiser”, we might find all kinds of other information
• http://www.google.com/search?q=courses+taught+by+gail+kaiser&sourceid=navclient-ff&ie=UTF-8&rlz=1B3GGGL_enUS253US253
• The problem is that the search engine does know what “courses” or “taught” means

Machine accessible meaning (What it’s like to be a machine)
CV
name
education
work
private

25 March 2008 Kaiser: COMS E6125 34
So what does this mean?
• What’s a “CV”?• What’s a “name”?• Etc.Need semantics

25 March 2008 Kaiser: COMS E6125 35
Semantic WebThe Semantic Web is not a separate web but an extension of the current web, in which information is given well-defined meaning, better enabling computers and people to work in co-operation.
[Berners-Lee et al., 2001]

Semantic Web Layers(T. Berners-Lee)

Start with XML, not HTML
<H1>WHIM</H1><UL>
<LI>Instructor: Gail Kaiser<LI>Students: George Bush
</UL>
<H1>WHIM</H1><UL>
<LI>Instructor: Gail Kaiser<LI>Students: George Bush
</UL>
HTML:
<course><title>WHIM</title><instructor>Gail Kaiser</instructor><students>George Bush</students>
</course>
<course><title>WHIM</title><instructor>Gail Kaiser</instructor><students>George Bush</students>
</course>
XML:

25 March 2008 Kaiser: COMS E6125 38
Why Not Use XML Tags For Semantics?
<title> … <title>• But what does “title” mean?• If we ask google, we get (on the 1st
page)– title element of an html document– a prefix or suffix added to a person's name – a company that sells boxing gear– a gym club for boxers

25 March 2008 Kaiser: COMS E6125 39
XML Limitations for Semantic Markup
• XML makes no commitment on: Domain-specific vocabulary Modeling primitives
• Requires pre-arranged agreement on &

25 March 2008 Kaiser: COMS E6125 40
XML Limitations for Semantic Markup
• Only feasible for closed collaboration– agents in a small & stable community– pages on a small & stable intranet
• Not suited for sharing Web resources

XML machine accessible meaning
CV
name
education
work
private
< >
< >
< >
< >
< >
< >
< >
<>
<>
<>

Semantic Web Layers
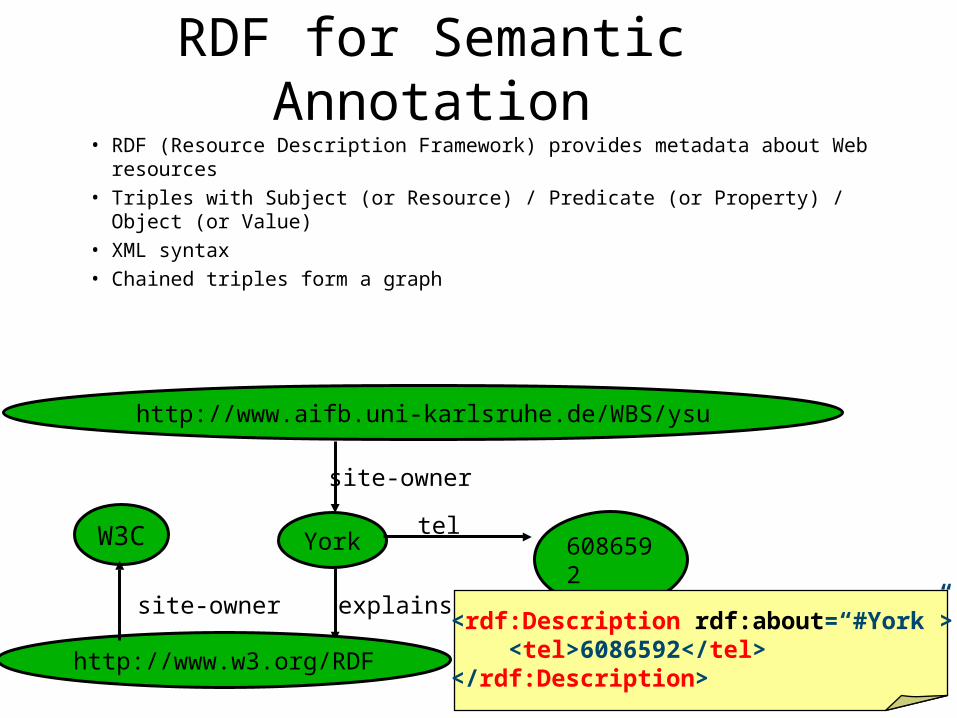
RDF for Semantic Annotation
• RDF (Resource Description Framework) provides metadata about Web resources
• Triples with Subject (or Resource) / Predicate (or Property) / Object (or Value)
• XML syntax• Chained triples form a graph
http://www.aifb.uni-karlsruhe.de/WBS/ysu
site-owner
York 6086592
telW3C
explains
http://www.w3.org/RDF
site-owner<rdf:Description rdf:about=“#York”> <tel>6086592</tel></rdf:Description>

RDF Schema
• Defines vocabulary for RDF• Organizes this vocabulary in a
typed hierarchy• Class, subClassOf, type• Property, subPropertyOf• domain, range
RudiYork
Person
PhDStud Professor
subClassOfsubClassOf
type
hasSuperVisordomain range
type
hasSuperVisor

RDF Schema Syntax in XML<rdf:Description ID="MotorVehicle"> <rdf:type resource="http://www.w3.org/...#Class"/> <rdfs:subClassOf rdf:resource="http://www.w3.org/...#Resource"/> </rdf:Description>
<rdf:Description ID="Truck"> <rdf:type resource="http://www.w3.org/...#Class"/> <rdfs:subClassOf rdf:resource="#MotorVehicle"/></rdf:Description>
<rdf:Description ID="registeredTo"> <rdf:type resource="http://www.w3.org/...#Property"/> <rdfs:domain rdf:resource="#MotorVehicle"/> <rdfs:range rdf:resource="#Person"/></rdf:Description>
<rdf:Description ID=”ownedBy"> <rdf:type resource="http://www.w3.org/...#Property"/> <rdfs:subPropertyOf rdf:resource="#registeredTo"/></rdf:Description>

25 March 2008 Kaiser: COMS E6125 46
Higher-order Statements• One can make RDF statements about other RDF
statements• Example: “Cinderella believes that the web
contains one billion documents”• Allow us to express beliefs (and other modalities)• Important for trust models, digital signatures, etc.• Constitute metadata about metadata• Represented by modeling RDF in RDF itself

Reification• Reification allows a computer to process an abstraction as if it
were any other datum • RDF is not really second-order• But it does provide a built-in predicate vocabulary for reification
http://www.w3.org/TR/REC-rdf-syntax “Eric Miller”dc:Creator
“Library of Congress”
dc:Creator
• The dotted box corresponds to the following statements• { x, rdf:predicate, “dc:creator” }• { x, rdf:subject, “http://www.w3.org/TR/REC-rdf-syntax }• { x, rdf:object, “Eric Miller” }• { x, rdf:type, “rdf:statement” }

Reification
pers05 ISBN...Author-of
NYT claims
<rdf:Description rdf:about=“#NYT”> <claims> <rdf:Description rdf:about=“#pers05”> <authorOf>ISBN...</authorOf> </rdf:Description> </claims></rdf:Description>
Any statement can be an object (graphs can be nested)

25 March 2008 Kaiser: COMS E6125 49
Conclusions about RDF• Next step up from plain XML
– modeling primitives– possible to define vocabulary
• However:– no precisely described meaning– no inference model

25 March 2008 Kaiser: COMS E6125 50
Where do we get the precisely defined
meaning?• Two databases may use different identifiers for
the same concept, such as zip code• A program that wants to compare or combine
information across the two databases has to know that these two terms mean the same thing
• The program must have a way to discover such common meanings for whatever databases it encounters
• A solution to this problem is provided by collections of information called ontologies

Semantic Web Layers

25 March 2008 Kaiser: COMS E6125 52
What is an Ontology?
• In philosophy, an ontology is a theory about the nature of existence, of what types of things exist; ontology as a discipline studies such theories
• Semantic Web researchers (and various other communities) have co-opted the term for their own jargon
• For semantic web researchers, an ontology is a document or file that formally defines the relations among terms
• The most typical kind of ontology for the Web has a taxonomy and a set of inference rules

25 March 2008 Kaiser: COMS E6125 53
What is a Taxonomy?
Taxonomy = Segmentation, classification and ordering of elements into a classification system according to their relationships between each other
Object
Person Topic Document
ResearcherStudent Semantics
OntologyDoctoral Student PhD Student F-Logic
Menu

25 March 2008 Kaiser: COMS E6125 54
Taxonomies• A taxonomy defines classes of objects and
relations among them• For example, an address may be defined as a
type of location, and city codes may be defined to apply only to locations
• If city codes must be of type city and cities generally have Web sites, we can discuss the Web site associated with a city code even if no database links a city code directly to a Web site
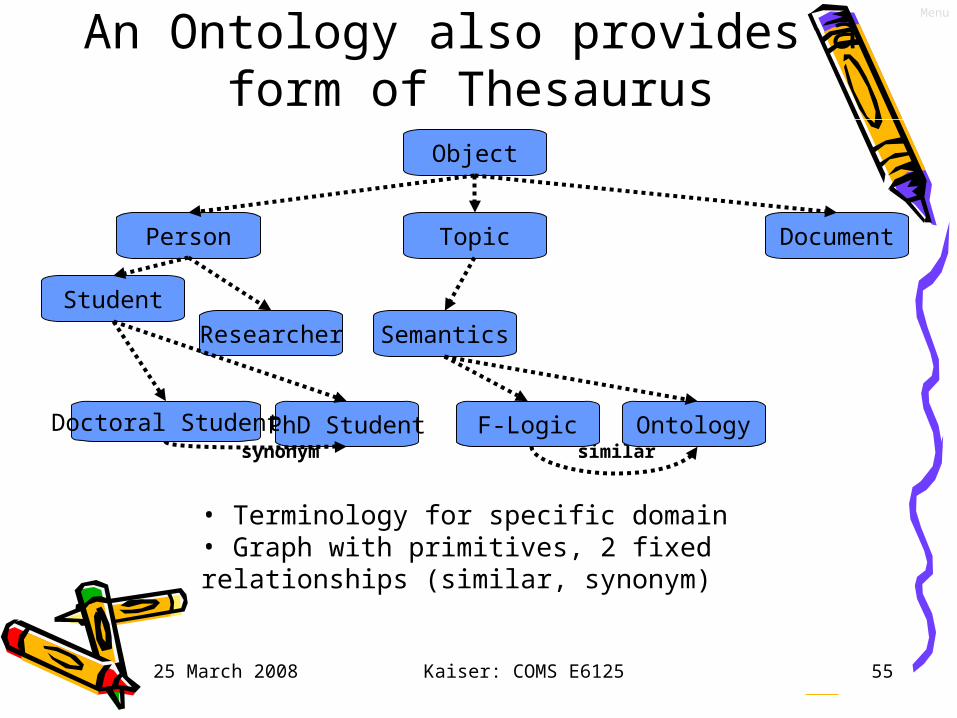
25 March 2008 Kaiser: COMS E6125 55
An Ontology also provides a form of Thesaurus
Object
Person Topic Document
Researcher
Student
Semantics
PhD StudentDoctoral Student
• Terminology for specific domain• Graph with primitives, 2 fixed relationships (similar, synonym)
similarsynonymOntologyF-Logic
Menu

25 March 2008 Kaiser: COMS E6125 56
An Ontology also provides a Topic Map
Object
Person Topic Document
ResearcherStudent Semantics
PhD StudentDoctoral Student
knows described_in
writes
AffiliationTel
• Topics (nodes), relationships and occurences (to documents)• Useful for navigation- and visualisation
OntologyF-Logic
similarsynonym
Menu

OntologyF-Logic
similar
OntologyF-Logic
similar
PhD StudentDoctoral Student
The Taxonomy is Augmented by Inference Rules
Object
Person Topic Document
Tel
Semantics
knows described_in
writes
Affiliation
described_in is_about
knowsP writes D is_about T P T
DT T D
Rules
subTopicOf
• W3C Ontologies: OWL = Web Ontology Language
ResearcherStudent
instance_of
is_a
is_a
is_a
Swapneel Sheth

25 March 2008 Kaiser: COMS E6125 58
Inference Rules• An ontology may express the rule “If a
city code is associated with a state code, and an address uses that city code, then that address has the associated state code”
• A program could then deduce, for instance, that a Columbia University address, being in New York City, must be in New York State, which is in the U.S., and therefore should be formatted to U.S. standards

25 March 2008 Kaiser: COMS E6125 59
Inference Rules• The computer doesn't truly
“understand” any of this information
• But it can now manipulate the terms much more effectively in ways that are useful and meaningful to the human user

25 March 2008 Kaiser: COMS E6125 60
Solution to Terminology Problems
• The meaning of terms or XML tags used on a Web page can be defined by pointers from the page to an ontology
• The same problems as before now arise if I point to an ontology that defines addresses as containing a zip code and you point to one that uses postal code
• This can be resolved if ontologies (or other Web services) provide equivalence relations: one or both of our ontologies may contain the information that my zip code is equivalent to your postal code

25 March 2008 Kaiser: COMS E6125 61
Using Ontologies• Ontologies can be used in a simple fashion to
improve the accuracy of Web searches• The search program can look for only those
pages that refer to a precise concept instead of all the ones using ambiguous keywords
• More advanced applications could use ontologies to relate the information on a page to the associated knowledge structures and inference rules

25 March 2008 Kaiser: COMS E6125 62
Example• Suppose you wish to find the Ms. Cook
you met at a trade conference last year• You don't remember her first name, but
you remember that she worked for one of your clients and that her brother was a student at your alma mater

25 March 2008 Kaiser: COMS E6125 63
Example• An intelligent search program can sift through
all the pages of people whose name is “Cook”• Sidestep all the pages relating to cooks,
cooking, the Cook Islands and so forth• Find the person’s named Cook who mention
working for a company that's on your client list
• And follow links to Web pages of their relatives to track down if any are in school at the right place

25 March 2008 Kaiser: COMS E6125 64
Another Example• When you answer your phone, other
sound is automatically turned down• Instead of having to program each specific
appliance, you could program such a function once and for all to cover every local device that advertises having a volume control — the TV, the DVD player, the media players on the laptop, …

25 March 2008 Kaiser: COMS E6125 65
Semantic Web Layers
RFC
Standard
Standard
Standard
Work in Progress

25 March 2008 Kaiser: COMS E6125 66
Semantic Web Layers• The top layers, Logic, Proof and Trust,
are “under development”• The Logic layer will enable the writing
of rules• The Proof layer will execute the rules • The Trust layer together with the Digital
Signature layer will provide mechanisms for applications to determine whether to trust the given proof or not

25 March 2008 Kaiser: COMS E6125 67
Summary• Semantic Web concepts may,
someday, dramatically improve Web search

25 March 2008 Kaiser: COMS E6125 68
Upcoming: Revised Project Proposal• Due Monday March 31st • No more than four (4) pages• Post in Revised Project Proposals
folder on CourseWorks

25 March 2008 Kaiser: COMS E6125 69
Revised Project Proposal: New or Extended System
• Explain what your system will “do”• Describe “value” to prospective user community• Sketch the top-level architecture, including
hosts, processes and major subsystems• Diagram and briefly explain the communications
flows, including protocols to be used and typical messaging sequences - including "error" cases
• Clarify any components that you are not implementing yourself (include URL)

25 March 2008 Kaiser: COMS E6125 70
Revised Project Proposal:
Comparison/Evaluation • Clearly indicate which system(s) you will be
evaluating (and how you will obtain)• Explain what you plan to measure and how
you will measure it (either quantitative or qualitative)
• Define what criteria you will use – and why are these significant or important
• Sketch the top-level architecture of those systems as they will operate during your experiments
• Discuss the design of your test application(s) and/or benchmark(s)

25 March 2008 Kaiser: COMS E6125 71
Revised Project Proposals
• Briefly discuss what you expect to be able to show in a <15 minute demo
• Schedule with your TA between April 22nd and May 6th
• TAs assigned per group – not necessarily same TA as for paper
• Final reports due Friday May 9th

Upcoming: StudentPresentations
• Topic can be paper, project, or something else relevant to class
• If project, coordinate with any other team members (e.g., schedule back-to-back)
• No more than 10 minutes• During class time April 1st, 8th, 15th, 22nd or 29th for on-
campus students• Contact instructor by email to schedule if not already
([email protected]) • Last year’s slides available at
http://bank.cs.columbia.edu/classes/cs6125-s07/presentations
• You need to provide the instructor with your slides, preferably at least 24 hours in advance, but in any case no later than 24 hours afterwards (needed by CVN students)

25 March 2008 Kaiser: COMS E6125 73
Reminders
• Revised project proposal due March 31st
• Schedule your presentation with the instructor - only 22nd or 29th still available for on-campus students (and any “local” CVN students who can come to class)
• CVN students should email instructor to arrange teleconference asap

25 March 2008 Kaiser: COMS E6125 74
COMS E6125 Web-COMS E6125 Web-enHanced Information enHanced Information Management (WHIM)Management (WHIM)
COMS E6125 Web-COMS E6125 Web-enHanced Information enHanced Information Management (WHIM)Management (WHIM)
Prof. Gail KaiserProf. Gail Kaiser
Spring 2008Spring 2008