cooperation enforcement and learning for optimizing packet forwarding in autonomous wireless
TRANSCRIPT

3150 IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, VOL. 7, NO. 8, AUGUST 2008
Cooperation Enforcement and Learning forOptimizing Packet Forwarding inAutonomous Wireless Networks
Charles Pandana, Zhu Han, and K. J. Ray Liu
Abstract—In wireless ad hoc networks, autonomous nodesare reluctant to forward others’ packets because of the nodes’limited energy. However, such selfishness and noncooperationdeteriorate both the system efficiency and nodes’ performances.Moreover, the distributed nodes with only local information maynot know the cooperation point, even if they are willing tocooperate. Hence, it is crucial to design a distributed mechanismfor enforcing and learning the cooperation among the greedynodes in packet forwarding. In this paper, we propose a self-learning repeated-game framework to overcome the problemand achieve the design goal. We employ self-transmission effi-ciency as the utility function of individual autonomous node.The self transmission efficiency is defined as the ratio of thepower for self packet transmission over the total power for selfpacket transmission and packet forwarding. Then, we propose aframework to search for good cooperation points and maintainthe cooperation among selfish nodes. The framework has twosteps: First, an adaptive repeated game scheme is designed toensure the cooperation among nodes for the current cooperativepacket forwarding probabilities. Second, self-learning algorithmsare employed to find the better cooperation probabilities thatare feasible and benefit all nodes. We propose three learningschemes for different information structures, namely, learningwith perfect observability, learning through flooding, and learn-ing through utility prediction. Starting from noncooperation,the above two steps are employed iteratively, so that bettercooperating points can be achieved and maintained in eachiteration. From the simulations, the proposed framework is ableto enforce cooperation among distributed selfish nodes and theproposed learning schemes achieve 70% to 98% performanceefficiency compared to that of the optimal solution.
Index Terms—Game theory, cooperation, wireless (ad-hoc)networks, intelligent sensors.
I. INTRODUCTION
SOME wireless networks such as ad-hoc networks consistof autonomous nodes without centralized control. In such
autonomous networks, the nodes may not be willing to fullycooperate and accomplish the network task. Specifically forthe packet forwarding problem, forwarding the others’ packets
Manuscript received February 22, 2007; revised November 3, 2007; ac-cepted January 5, 2008. The associate editor coordinating the review of thispaper and approving it for publication was Y. Fang. This work is partiallysupported by MURI AFOSR F496200210217.
C. Pandana is with Arraycomm, San Jose, CA 95131 (e-mail: [email protected]).
Z. Han is currently with the Department of Electrical and ComputerEngineering, University of Houston, Houston, Texas, 77204.
K. J. Ray Liu is with the Department of Electrical and ComputerEngineering, University of Maryland, College Park, MD 20742 (e-mail:[email protected]).
Digital Object Identifier 10.1109/TWC.2008.070213.
consumes the node’s limited battery resource. Therefore, itmay not be of the node’s best interest to forward others’arriving packets. However, rejection of forwarding others’packets non-cooperatively will severely affect the networkfunctionality and impair the nodes’ own benefits. Hence, it iscrucial to design a mechanism to enforce cooperation amonggreedy nodes. In addition, the randomly located nodes withlocal information may not know how to cooperate, even ifthey are willing to cooperate.
The packet forwarding problem in ad hoc networks hasbeen extensively studied in the literature. The fact that nodesact selfishly to optimize their own performances has moti-vated many researchers to apply the game theory [1], [2]in solving this problem. Broadly speaking, the approachesused in encouraging the packet forwarding task can be cat-egorized into two methods. The first type of methods makesuse of virtual payment. Virtual currency, pricing, and creditbased method [3], [4] fall into this first type. The secondtype of approaches is related to personal and communityenforcement to maintain the long-term relationship amongnodes. Cooperation is sustained because defection against onenode causes personal retaliation or sanction by others. Thissecond approach includes the following works. Marti et al. [5]propose mechanism called watchdog and pathrater to identifythe misbehaving nodes and deflect the traffic around them.Buchegger et al. [6] define protocols based on reputationsystem. Altman et al. [7] consider a punishment policy toshow cooperation among participating nodes. In [8], Han etal. propose learning repeated game approaches to enforcecooperation and obtain better cooperation solutions. Someother works using game theory in solving communicationproblems can be found in [9], [10], and [11].
Since in some wireless networks, it is difficult to imple-ment the virtual payment system because of the practicalimplementation challenges such as enormous signaling. In thispaper, we concentrate on the second type of approaches anddesign a mechanism such that cooperation can be enforced ina distributed way. In addition, unlike the previous works whichassume the nodes know the cooperation points or other nodes’behaviors, we argue that randomly deployed nodes with localinformation may not know how to cooperate even if they arewilling to do so. Motivated by these facts, we propose a self-learning repeated-game framework for cooperation enforcingand learning.
We define the self-transmission as the transmission of a
1536-1276/08$25.00 c© 2008 IEEE

PANDANA et al.: COOPERATION ENFORCEMENT AND LEARNING FOR OPTIMIZING PACKET FORWARDING IN AUTONOMOUS WIRELESS NETWORKS 3151
learning learningmaintaincooperation
maintaincooperation
n n+k n+Kn+k+1 n+K+1
Fig. 1. Illustration of time-slotted transmission to two alternative stages.
user’s own packets. We quantify the node’s utility as its self-transmission efficiency, which is defined as the ratio of thepower for successful self transmission over the total powerused for self transmission and packet forwarding. The goalof the node is to maximize the long-term average efficiency.Using this utility function, a distributed self-learning repeated-game framework is proposed to ensure cooperation amongautonomous nodes. The framework consists of two steps: First,the repeated game enforces cooperation in packet forwarding.This first step ensures that any cooperation equilibrium thatis more efficient than the Nash Equilibrium (NE) of theone stage game can be sustained. The repeated game allowsnodes to consider the history of actions/reactions of theiropponents in making the decision. The cooperation can beenforced/sustained using the repeated game, since any devia-tion causes the punishment from other nodes in the future.The second step utilizes the learning algorithm to achievethe desired efficient cooperation equilibrium. We proposethree learning algorithms for different information structures,namely, learning with perfect observability, learning throughflooding, and learning through utility prediction. Starting fromthe non-cooperation point, the two proposed steps are appliediteratively. A better cooperation is discovered and maintainedin each iteration, until no more efficient cooperation pointcan be achieved. From the simulation results, our proposedframework is able to enforce cooperation among selfish nodes.Moreover, compared to the optimal solution obtained bya centralized system with global information, our proposedlearning algorithms achieve similar performances in the sym-metric network. Depending on learning algorithms and theinformation structures, our proposed schemes achieve near-optimal solution in the random network.
This paper is organized as follows: In Section II, wegive the system model and explain the design challenge.In Section III, we propose and analyze the repeated-gameframework for packet forwarding under different informationstructures. In Section IV, we construct self-learning algorithmscorresponding to different information structures in details.In Section V, we evaluate the performances of our proposedscheme using extensive simulations. Finally, the conclusionsare drawn in Section VI.
II. SYSTEM MODEL AND DESIGN CHALLENGE
We consider a network with N nodes. Each node is battery-powered and has transmit power constraint. This implies thatonly nodes within the transmission range are neighbors. Thepacket delivery typically requires more than one hop. In eachhop, we assume transmission occurs in a time-slotted manneras illustrated in Figure 1. The source, the relays (intermediatenodes), and the destination constitute an active route. Weassume an end-to-end mechanism that enables a source node toknow if the packet is delivered successfully. The source node
can observe whether there is a packet drop in one particularactive path. However, the source node may not know wherethe packet is dropped. Finally, we assume that routing decisionhas already been done before optimizing the packet forwardingprobabilities1.
Let’s denote the set of sources and destinations as {Si,Di}, for i = 1, 2, · · · , M , where M represents the numberof source-destination pairs that are active in the network.Suppose the shortest path for each source-destination pairhas been discovered. Let’s denote the route/path as Ri =(Si, f
1Ri
, f2Ri
, · · · , fnRi
, Di), where Si denotes the source node,Di denotes the destination node, and {f1
Ri, f2
Ri, · · · , fn
Ri} is
the set of intermediate/relay nodes, thus, there are n +1 hopsfrom source node to the destination node. Let V = {Ri : i =1, · · · , M} be the set of routes corresponding to all source-destination pairs. Let’s denote further the set of routes wherenode j is the source as V s
j = {Ri : S(Ri) = j, i = 1 . . .M},where S(Ri) represents the source of route Ri. The powerexpended in node i for transmitting its own packet is
P (i)s =
∑r∈V s
i
μS(r) · K · d(S(r), n(S(r), r))γ , (1)
where μS(r) is the transmission rate of source node S(r), Kis the transmission constant, d(i, j) is the distance betweennode i and node j, n(i, r) denotes the neighbor of node ion route r, and γ is the transmission path-loss coefficient.For the link from node i to its next hop n(i, r) on route r,K ·d(i, n(i, r))γ describes the reliable successful transmissionpower per bit transmission. We note that equation (1) canalso be interpreted as the average signal power required forsuccessful transmission of certain rate μS(r). This implies thatthe transmission failure due to the channel fading has beentaken into account by the transmission constant K .
Let αi for i = 1, · · · , N be the packet forwarding proba-bility for node i. Here, we use the same packet forwardingprobability for every source-destination pairs because of thefollowing reasons. First, based on the greedy assumption ofthe nodes, there is no reason for one particular node toforward some packets on some routes and reject forwardingother packets on other routes. Second, the use of differentpacket forwarding probability on different routes will onlycomplicate the deviation detection of a node and it will notchange the optimization framework proposed in this paper. Soin our first step to analyze the problem, we assume the sameforwarding probability on every route. In the future work,we are also exploring the case where the nodes use differentpacket forwarding probability for different routes.
Clearly, probability of successful transmission from nodei to its destination depends on the forwarding probabilitiesemployed in the intermediate nodes and it can be representedas
P iTx,r =
∏j∈(r\{S(r)=i,D(r)})
αj , (2)
where D(r) is the destination of route i and (r \ {S(r) =i, D(r)}) is the set of nodes on route r excluding the source
1We note that it is always possible for nodes to do manipulation in therouting layer. However, it is beyond the scope of this paper. For moreinformation, please refer to [16]

3152 IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, VOL. 7, NO. 8, AUGUST 2008
and destination. Let’s define the good power consumed intransmission node i, P
(i)s,good as the product of the power used
for transmitting node i’s own packet and the probability ofsuccessful transmission from node i to its destination,
P(i)s,good =
∑r∈V s
i
μS(r) · K · d(S(r), n(S(r), r))γP iTx,r. (3)
Moreover, let the set of routes where node j is the forward-ing node be Wj . The power used to forward others’ packetsis given by
P(i)f = αi · K ·
∑r∈Wi
d(i, n(i, r))γμS(r)PiF,r, (4)
where P iF,r is the probability that node i receives the packet
to forward in route r, and∑
r∈WiμS(r) P i
F,r is the total ratethat node i receives for packet forwarding. The probability thatnode i receives the forward packet in route r is representedas
P iF,r =
∏j∈{f1
r ,f2r ,··· ,fm−1
r }αj , (5)
where r = {S(r), f1r , · · · , fm−1
r , fmr = i, · · · , fn
r , D(r)} isthe n + 1 hops route from source S(r) to destination D(r),and the mth forwarding node fm
r is node i. P iF,r depends on
the packet forwarding probabilities of the nodes on the router before node i.
We refer to the task of transmitting the node own infor-mation as self-transmission and the task of relaying others’packets as packet forwarding. We focus on maximizing theself-transmission efficiency, which is defined as the ratio ofsuccessful self-transmission power (good power) over thetotal power used for self-transmission and packet forwarding.Therefore, the stage utility function for node i can be repre-sented as
U (i)(αi, α−i) =P
(i)s,good
P(i)s + P
(i)f
. (6)
where αi is node i’s packet forwarding probability, α−i =(α1, · · · , αi−1, αi+1, · · · , αN )T are the other nodes’ forward-ing probability. Putting (1), (3) and (4) into (6), we have (7) (atthe top of the next page). Since the power for successful self-transmission depends on the packet forwarding used by othernodes, the self-transmission efficiency captures the trade-offbetween the power used for packet transmission of its owninformation and packet forwarding for the other nodes.
The problem in packet forwarding arises because the au-tonomous nodes such as in ad-hoc networks have their ownauthorities to decide whether to forward the incoming packets.Under this scenario, it is very natural to assume that eachnode selfishly optimizes its own utility function. In parallel to(7), node i selects αi in order to maximize the transmissionefficiency U (i)(αi, α−i). This implies that node i will selfishlyminimize P
(i)f , the portion of energy used to forward others’
packets. In the game theory literature [1], [2], Nash Equilib-rium (NE) is a well-known concept, which states that in theequilibrium every node selects the best response strategy tothe other nodes’ strategies. The formal definition of NE isgiven as follow
Definition 1: Define feasible range Ω as [0, 1]. Nash Equi-librium [α∗
1, · · · , α∗N ]T is defined as:
U (i)(α∗i , α
∗−i) ≥ U (i)(αi, α
∗−i), ∀i, ∀αi ∈ Ω, (8)
i.e., given that all nodes play NE, no node can improveits utility by unilaterally changing its own packet forwardprobability. Here α∗
−i = (α∗1, · · · , α∗
i−1, α∗i+1, · · · , α∗
N )T .Unfortunately, the NE for the packet forwarding game de-
scribed in (7) is α∗i = 0, ∀i. This can be verified by finding the
forwarding probability αi ∈ [0, 1] such that U (i) is unilaterallymaximized. To maximize the transmission efficiency of nodei, the node can only make the forwarding energy P
(i)f as
small as possible. This is equivalent to setting αi as smallas possible, since the successful probability of its own packettransmission in (2) depends only on the other nodes’ willing-ness to forward the packets. By greedily dropping its packetforwarding probability, node i reduces its total transmissionpower used for forwarding others’ packets, therefore, increasesits instantaneous efficiency. However, if all nodes play thesame strategy, this causes zero efficiency in all nodes, i.e.,U (i)(α∗
1 . . . α∗N ) = 0, ∀i. As the result, the network breaks
down. Hence, playing NE is inefficient not only from thenetwork point of view but also for the individual’s own benefit.It is very important to emphasize that the inefficiency of NE isindependent to the utility function in (7). This inefficiency ismerely the result of greedy optimization unilaterally done byeach of the nodes. In the next two sections, we propose a self-learning repeated-game framework and show how cooperationcan be enforced using our proposed scheme.
III. REPEATED-GAME FRAMEWORK AND PUNISHMENT
ANALYSIS
As demonstrated in Section II, the packet forwarding gamehas α∗
i = 0, ∀i as its unique Nash equilibrium if the game isonly played once. This implies that all nodes in the networkwon’t be cooperating in forwarding the packets. In practice,nodes typically participate in the packet forwarding game fora certain duration of time, and this is more suitably modelledas a repeated game (a game that is played in multiple times).If the game never ends, it is called infinite repeated gamewhich we will use in this paper. In fact, the repeated gamemay not be necessarily infinite. The important point is that thenodes/players do not know when the game ends. In this sense,the properties of the infinitely repeated game can still be valid.In this paper, we employ the normalized average discountedutility with discounting factor δ given by:
U (i)∞ = lim
t′→∞U
(i)t′ = (1 − δ)
∞∑t=1
δ(t−1)U (i)(�α(t)), (9)
where �α(t) = (α1, . . . , αN )T , U (i)(�α(t)) is the utility ofnode i at each stage game (7) played at time t, and U
(i)t′
is the normalized average discounted utility from time 1 totime t′. Unlike the one-time game, the repeated game allowsa strategy to be contingent on the past moves and results inthe reputation and retribution effects, so that cooperation canbe sustained [2], [13], [14]. We also note that the utilities in(7) and (9) are indeed heterogeneous in the sense that theycarry the information about the channel, routing, and node

PANDANA et al.: COOPERATION ENFORCEMENT AND LEARNING FOR OPTIMIZING PACKET FORWARDING IN AUTONOMOUS WIRELESS NETWORKS 3153
U (i) =
∑r∈V s
iμS(r)d(S(r), n(S(r), r))γ
∏j∈(r\{S(r)=i,D(r)}) αj∑
r∈V si
μS(r)d(S(r), n(S(r), r))γ + αi
∑r∈Wi
d(i, n(i, r))γμS(r)
∏j∈{f1
r ,··· ,fm−1r } αj
(7)
behaviors. In other words, the utility functions in (7) and(9) reflect different energy consumption according to differentdistance, rate, and route between nodes.
A. Design of Punishment Scheme under Perfect Observability
In this subsection, we analyze a class of punishment policyunder the assumption of perfect observability. Perfect observ-ability means that each node is able to observe actions takenby other nodes along the history of the game. This implies thatnode knows which node drops the packet and is aware of theidentity of other nodes. This condition allows every node todetect any defection of other nodes and it also allows nodes toknow if any node does not follow the game rule. The perfectobservability is the ideal case and serves as the performanceupper bound. In the next subsection, this assumption is relaxedto a more practical situation, where an individual node onlyhas limited local information.
Let’s denote the NE in one stage forwarding game as�α∗ = (α∗
1, · · · , α∗N )T , and the corresponding utility functions
as (v∗1 , · · · , v∗N )T = (U (1)(�α∗), · · · , U (N)(�α∗))T . We alsodenote
U = {(v1, · · · , vN )| ∃�α ∈ ΩN (10)
s.t. (v1, · · · , vN ) = (U (1)(�α), · · · , U (N)(�α))},V = convex hull of U, (11)
V† = {(v1, · · · , vN ) ∈ V| vi > v∗i , ∀i}. (12)
We note that V consists of all feasible utilities, and V†
consists of feasible utilities that Pareto-dominate the one stageNE, this set is also known as the individually rational utilityset [1], [2]. The Pareto-dominant utilities denote all utilitiesthat are strictly better than the one stage NE. From the gametheory literature [2], [13], [14], the existence of equilibria thatPareto-dominate the one stage NE is given by the Folk theorem[14].
Theorem 1 (Folk Theorem [14]): Assume that the dimen-sionality of V† equals to N . Then, for any (v1, · · · , vN )in V†, there exists δ ∈ (0, 1) such that for all δ ∈ (δ, 1),there exists an equilibrium of the infinitely repeated game withdiscounted factor δ in which player i’s average utility is vi.
Before we give the application of Folk theorem in thepacket forwarding game, it is useful to recall the notionof dependency graph. Given the routing algorithm and thesource-destination pairs, the dependency graph is the directedgraph that is constructed as follows. The number of nodes inthe dependency graph is the same as the number of nodesin the network. When node i sends packets to node j vianodes f1, · · · , fn, then there exist directed edges from nodei to nodes f1, · · · , fn. The resulting dependency graph is adirected graph, which describes the node dependency in per-forming the packet forwarding task. Let’s define degin(i) anddegout(i) as the number of edges going into node i and comingout from node i, respectively. Obviously, degin(i) indicates ofthe number of nodes whose packets are forwarded by node
i and degout(i) is the number of nodes that help forwardnode i’s packets. Using the notation of the correspondingdependency graph, the application of Folk theorem in packetforwarding game is stated as follow:
Theorem 2: (Existence of Pareto-dominant forwardingequilibria under perfect observability)
Under the following conditions
1. the game is perfectly observable;2. the corresponding dependency graph satisfies the
conditiondegout(i) > 0, ∀i; (13)
3. V† has full dimensionality (V† has dimensionalityof N ). We note that V† has dimensionality of Nimplies that the space formed by all points in V†
has the dimensionality of N .
Then, for any (v1, · · · , vn) ∈ V†, there exists δ ∈ (0, 1),such that for all δ ∈ (δ, 1), there exists an equilibrium of theinfinitely repeated game with node i’s average utility vi.
Proof: Let �α = (α1, · · · , αN )T be the joint strategyresults in (U (1)(�α), · · · , U (N)(�α)). The full dimensionalitycondition ensures the set
(U (1)(�α), · · · , U (j−1)(�α), U (j)(�α)−
ε, U (j+1)(�α), · · · , U (N)(�α))
for any ε > 0, is in V†. Letnode i’s maximum utility be vi = max�α U (i)(�α), ∀i. Thismaximum utility is obtained when all nodes try to maxi-mize node i’s utility. Let the cooperating utility be vi =U (i)(�α) ∈ V†, ∀i. The cooperating utilities are obtained whenall nodes play the agreed packet forwarding probabilities. Letthe maximum utility node i can get when it is punished bevi = maxαi minα−i U (i)(�α). Let’s denote node j’s utilitywhen punishing node i as wi
j . We note that from (7), themax-min utility vi coincides with the one stage NE. If thereexist ε and the punishment period for node i, Ti, such that
vi
U (i) − ε< (1 + Ti), (14)
then the following rules ensure any individually rational util-ities can be enforced.
1) Condition I: All nodes play cooperation strategiesif there is no deviation in the last stages. After anydeviations go to Condition II (Suppose node j deviates).
2) Condition II: Nodes that can punish the deviating node(node j) play the punishing strategies for the punishmentperiod. The rest of the nodes keep playing cooperatingstrategies. If there is any deviation in Condition II,restart Condition II and punish the deviating node. If anypunishing node does not play punishment in the punish-ment period, the other nodes will punish that particularnode during the punishment period. Otherwise, after theend of the punishment period, go to Condition III.
3) Condition III: Play strategy that results in utility(U (1), · · · , U (j−1), U (j) − ε, U (j+1), · · · , U (N)
). If
there is any deviation in Condition III, start ConditionII and punish the deviating node.

3154 IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, VOL. 7, NO. 8, AUGUST 2008
First, the cooperating strategy is the strategy that all nodesagree upon. In contrast, the punishing node i strategy, isthe strategy that results in max-min utility in node i, vi =maxαi minα−i U (i)(�α). In the sequel, we show that under theproposition’s assumptions:
• the average efficiency gained by the deviating node issmaller than the cooperating efficiency,
• the average efficiency gained by the punishing node thatdoes not play the punishment strategy in the punishmentstage is worse than the efficiency gained by that nodewhen it conforms to the punishing strategy.
If node j deviates in Condition I and then conforms, itreceives at most vj when it deviates, vj for Tj periodswhen it is punished, and (U (j) − ε) after it conforms to thecooperative strategy. The average discounted deviation utilitycan be expressed as:
U (j)∞ = vj +
δ(1 − δTj )1 − δ
vj +δTj+1
1 − δ(U (j) − ε). (15)
Since if the node conforms throughout the game, it has theaverage discounted utility of 1
1−δ U (j). So the gain of deviationis given by:
ΔU (j) = U (j)∞ − 1
1 − δU (j)
< vj +δ(1 − δTj )
1 − δvj −
1 − δTj+1
1 − δ(U (j) − ε). (16)
We note that vj coincides with the one stage NE, which is
vj = 0, ∀j. As δ → 1, 1−δTj+1
1−δ tends to 1 + Tj . Under thecondition of (14), the deviation gain in (16) will be strictlyless than zero. This indicates that the average cooperatingefficiency is strictly larger than the deviation efficiency. Hence,any rational node will not deviate from the cooperation point.
If the punished node still deviates in the punishment period,the punishment period (Condition II) restarts and the punish-ment duration experienced by the punished node is lengthened.As the result, deviation in the punishment period postponesthe punished node from receiving the strictly better utility(U (j) − ε) in Condition III. Hence, it is better not to deviatein the punishment stage.
On the other hand, if punishing node i does not play thepunishing strategy during the punishment of node j, node ireceives at most
U (i)∞ = vi +
δ(1 − δT )1 − δ
vi +δT+1
1 − δ(U (i) − ε). (17)
However, if node i conforms with the punishment strategy, itwill receive at least
U (i)∞ =
(1 − δT )1 − δ
wji +
δT+1
1 − δU (i). (18)
Here wji is the utility of node i to punish node j. Therefore,
node i’s reward for carrying out the punishment is (18) minus(17),
U (i)∞ − U (i)
∞ =(1 − δT )
1 − δ(wj
i − δvi) − vi +δT+1ε
1 − δ. (19)
Using vi = 0, ∀i and let δ → 1, the expression (19) isequivalent to
U (i)∞ − U (i)
∞ = T · wji − vi +
ε
1 − δ. (20)
Fig. 2. Example of the punishment scheme under perfect observability.
By selecting δ close to one, this expression can be alwayslarger than zero. As the result, the punishing node alwaysconforms to the punishment strategy in the punishment stage.
The same argument of no node deviating in Condition Ican be used to show that no nodes deviates in Condition III.Therefore, we conclude that deviations in all Conditions arenot profitable.
The proof above is based on two conditions: First, theproof assumes that there always exist nodes that can punishthe deviating nodes, this is guaranteed by the assumptiondegout(i) > 0 in the corresponding dependency graph. Sec-ondly, nodes are able to identify which node is defectingand which node does not carry out the punishment. Thisis guaranteed by the perfect observability assumption. Thestrategy of punishing those who misbehave and those who donot punish the misbehaving nodes can be an effective strategyto cope with the collusion attack.
Now let’s consider the following example to understand thepunishment behavior. We assume μS(r) = 1, K = 1, andd(i, j) = 1. The resulting utilities are shown in Figure 2.Each node has the one stage utility as:
U (i) =αmod(i−2,6)+1 + αmod(i,6)+1
2 + 2αi. (21)
By selecting the discounted factor, δ = 0.9 and T = 2appropriately, all nodes are better-off when they are co-operating in packet forwarding by setting αi = 1, ∀i. Ifall nodes conform to the cooperative strategies, the 6-stagenormalized average discounted utilities defined in (9) are givenby U
(i)6 = 0.2343, ∀i. In Figure 2, we plot the utility functions
and forwarding probabilities of all nodes. The x-axis of theplot denotes the round of game, the left y-axis denotes thevalue of node’s utility, and the right y-axis denotes the value offorwarding probability. The forwarding probability is denotedby the squared plot and the utility function is denoted by theplot with stars.
In Figure 2, we show that node 1 is deviating in the secondround of the game by setting its forwarding probability to zero.At this time, node 1’s utility changes from 0.5 to 1 as seen inthe figure. As the consequence, node 2 and node 6 are punish-

PANDANA et al.: COOPERATION ENFORCEMENT AND LEARNING FOR OPTIMIZING PACKET FORWARDING IN AUTONOMOUS WIRELESS NETWORKS 3155
ing node 1 at the following T = 2 stages by setting their for-warding probabilities to zeros. In the third round of the game,node 1 has to return to cooperation. Otherwise, the punishmentfrom others restarts and consequently the average discountedutility will be further lowered. After the punishment, all nodescome back to the cooperative forwarding probabilities (asshown in the figure). The resulting 6-stage normalized averageutilities are as follows U
(1)6 = 0.2023, U
(2)6 = U
(6)6 = 0.2887,
U(3)6 = U
(5)6 = 0.1958, and U
(4)6 = 0.2343. So node 1 has
less utility by deviation than by cooperation. Moreover, if bothnode 2 and node 6 fail to punish node 1, they will be punishedby other nodes during the following T periods of game. Theresulting normalized average utilities are U
(1)6 = 0.3485,
U(2)6 = U
(6)6 = 0.1425, U
(3)6 = U
(5)6 = 0.3035, and
U(4)6 = 0.165. Therefore, node 2 and node 6 will carry out
the punishment, since otherwise they will in turn be punishedand have less utility. The same argument can be used toprevent nodes deviating from the punishment strategy. We notethat in this example the corresponding dependency graph hasdegin(i) = degout(i) = 2, ∀i. Therefore, there are alwayspunishing nodes available whenever any node deviates.
Finally, we discuss the discounting factor δ which representsthe importance of the future. In the case where the discountingfactor is small, the future is less important. This will causethe pathological situation where the instantaneous deviationgain of the defecting node exceeds any future punishmentby the other nodes. Therefore, it is better-off for the nodeto deviate rather than to cooperate and it becomes very hard(if not impossible) to encourage all nodes to cooperate inthis scenario. We also note that the selfish nodes are better-off to choose the δ approaching to one. Since if the nodechooses δ that closes to zero, this implies that the future isnot important to the node, the node will definitely ask othernodes for transmitting his own packet at very beginning ofthe game and stop forwarding others’ packets afterward. Thiswill invoke punishment from its neighboring nodes by notforwarding that particular node’s packets. This implies thatthat node will automatically be excluded from the network.Therefore, it is better-off for nodes in the network to chooseδ approaching to one.
B. Design of Punishment Scheme under Imperfect Local Ob-servability
We have shown that under the perfect observability assump-tion, the packet forwarding game along with the punishmentscheme can achieve any Pareto-dominant efficiency. However,the perfect observability may be difficult to implement in ad-hoc networks, due to the enormous overheads and signaling.Therefore, we try to relax the condition of the perfect ob-servability in this subsection. There are many difficulties inremoving the perfect observability assumption. Suppose eachnode observes only its own history of stage utility function.In this situation, the node knows nothing about what hasbeen going on in the rest of the network. The node onlyknows the deviation of nodes on which it relies on to dopacket forwarding. And it cannot detect the deviation in theother part of the network, even though it can be the one thatcan punish the deviating node. Therefore, it is impossible
to implement the Folk Theorem in this information limitedsituation. Moreover, nodes may not know if the system is inpunishment stage or not. As soon as one of the nodes sees thedeviation, it starts the punishment period. This will quicklystart another punishment stage by other nodes, since the nodescannot differentiate if the change in stage efficiency is causedby the punishment stage or the deviating node. As the result,the defection spreads like an epidemic and cooperation in thewhole network breaks down. This is known as the contagiousequilibrium [13]. Indeed, the only equilibrium in this situationis the one stage NE.
The main reason of the contagious equilibrium is that allnodes have the inconsistent beliefs about the state of thesystem, they do not know whether the system is currentlyin the punishment stage, the deviation state, or the end ofpunishment stage. Therefore, any mistake in invoking thepunishment stage can cause the contagious equilibrium. Thelack of the consistent knowledge of the system state can bemitigated using communications between nodes. Suppose eachnode observes only a subset of the other nodes’ behaviors.The communication is introduced by assuming that each nodemakes a public announcement about the behaviors of the nodesit observes. This public announcement can be implementedby having the nodes exchange the behaviors of nodes theyobserve through broadcasting. The intersection of these an-nouncements can be utilized to identify the deviating node.At the end of each stage game, the nodes report either nonodes deviate or the identity of the deviating node. Since theseannouncements can be exchanged in a relatively low frequencyand only to the related nodes, the communication overheadsare limited. Under this local observability assumption, thefollowing theorem inspired by the Folk Theorem for privatelymonitoring with communication [15] is proposed
Theorem 3: Suppose V† has N dimensionality (full dimen-sionality), where N is the number of nodes in the network.If every node i is monitored by at least two other nodes, thisimplies the following:
1. If node i participates in the routes that have only 2hops, then degin(i) ≥ 2 is sufficient.
2. If node i participates in the routes which one ofthe routes has only 2 hops, then degin(i) ≥ 3 issufficient.
3. If node i participates in the routes which have morethan 2 hops, then degin(i) ≥ 4 is sufficient.
Also, there always exists a node that can punish the deviatingnode, i.e.,
degout(i) > 0, ∀i. (22)
Moreover, the monitoring nodes can exchange the observa-tions. Then, for every v in the interior of V†, there existδ ∈ (0, 1), such that for all δ ∈ (δ, 1), v = (v1, · · · , vN ) is anequilibrium of an infinitely repeated game in which node i’saverage utility is vi.
Proof: Suppose there exist ε, δ and punishment period

3156 IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, VOL. 7, NO. 8, AUGUST 2008
Ti such that (14) holds and
maxi{Ti}−1∑t=0
δt maxi
{max(α,α′)
(vi(α) − vi(α′)
)}
<
∞∑t=maxi{Ti}
δtε, (23)
then the following rules of the game (Condition I to III)achieves the equilibrium when degin(i) = 2, ∀i.
Condition I: If there is no announcement of the deviatingnodes
a. If the previous stage is in cooperating state, continue thecooperating state.
b. If the nodes play the following strategy in the previousstage(
U (1), · · · , U (k−1), U (k) − ε, U (k+1), · · · , U (N))
for k ∈ {1, · · · , N}, continue the previous state.c. If the previous stage is in punishing node k state and the
punishment has not ended, then continue the punishing.Otherwise, switch to strategy that results in(
U (1), · · · , U (k−1), U (k) − ε, U (k+1), · · · , U (N)).
Condition II: If node j is incriminated by both of its moni-tors j1 and j2
a. If the previous stage’s strategy is either in thefollowing states: punishing node j, implementing(U (1), · · · , U (j−1), U (j) − ε, U (j+1), · · · , U (N)
), imple-
menting(U (1), · · · , U (j) − ε, · · · , U (l) − ε, · · · , U (N)
),
for some l �= j, or in implementing(U (1), · · · , U (l) +
ε, · · · , U (j) − ε, · · · , U (N)), for some l �= j, then start
the punishment stage for punishing node j.b. If the previous stage’s strategy is in punishing
node j1, then switch to the strategy that results in(U (1), · · · , U (j2)+ε, · · · , U (j)−ε, · · · , U (N)
). The sim-
ilar argument is applied to increase node j1’s utility byε when node j2 is punished in the previous stage.
Condition III: If there is any inconsistent announcementby node j1 and j2. We note that the inconsistentannouncement happens when there are at least twoannouncements of the deviation node, but the devi-ation nodes in the announcements are different.
a. If the previous state is punishing node j1 or node j2, thenrestart the punishment stage.
b. Otherwise, implement(U (1), · · · , U (j1)−ε, · · · , U (j2)−
ε, · · · , U (N)).
In the above rules, we consider three different conditions,namely when no announcement of deviating node (ConditionI), when the announcements are consistent (Condition II),and when the announcements are inconsistent (Condition III).Then we discuss the different strategies for different stateswithin each Condition. We note that only the nodes whosepackets are forwarded by node j have the potential ability ofdetecting the deviation of node j. The above game rule ensuresthat if every nodes in the network are monitored by at leasttwo other nodes and there always exist nodes to punish thedeviating node, then any v ∈ V† can be realized.
If both the monitors (node j1 and node j2) of node jincriminate node j, then node j is punished in the similarway to the punishment in Theorem 1. The deviator (node j)is punished for a certain period of time if the previous stateis in one of the following states: punishing node j state (thisimplies that the punishment stage will be restarted), finishedpunishing node j state (i.e. in the state with utility functionas U (1), · · · , U (j−1), U (j) − ε, U (j+1), · · · , U (N)), after pe-nalizing nodes that make inconsistent announcements (i.e. instate with utility U (1), · · · , U (k)−ε, · · · , U (l)−ε, · · · , U (N)),where node k and l are the nodes that previously make incon-sistent announcements, or in state with utility U (1), · · · , U (l)+ε, · · · , U (k) − ε, · · · , U (N). In all these states, the deviator(node j) will be punished for a certain period of time(Condition IIa). However, if the previous state is in punishingnode j1, then the system switches to strategy that results inU (1), · · · , U (j2) + ε, · · · , U (j) − ε, · · · , U (N) (Condition IIb).This strategy gives additional incentives (U (j2) + ε) for nodej2 to punish to node j. Obviously, node j1 has the incentive toannounce if node j deviates, since this announcement will endnode j1 punishment. Because of the possible early terminationof the punishment period, node j1 also has the incentiveto wrongly incriminate node j, this particular case will beprevented by Condition IIIa. Condition IIb is also used toavoid the situation where node j2 lies on its announcementeven though it observes that node j deviates. This conditionwill become obvious as we discuss the Condition III.
Next, we consider the case where there are incompatibleannouncements. We note that incompatible announcementsimply that there are two nodes or two groups of nodesthat make different announcements on the deviation. Theseannouncements can be in the forms of either node j isonly incriminated by one of the nodes (a group of nodes)or two different nodes are incriminated by two other nodes(two other groups of nodes). When there are incompatibleannouncements about node j (Condition III) and the previousstate is not in punishing node j1 or j2, the nodes that makeincompatible announcements will be penalized and they willreceive utility U (ji) − ε for i = 1, 2 (Condition IIIb). In thecase when node j1 is being punished in the previous stage, theCondition IIIa prevents node j1 from falsely accusing node j.Condition IIIa and Condition IIIb are sufficient to avoid lyingin announcement. However, including Condition IIIa createsthe situation where node j2 enjoy punishing node j1. Thismeans that when node j1 is being punished and in the casenode j has really deviated, node j2 has the incentive to lie in itsannouncement and announces that no nodes is deviating. Thisproblem is solved by Condition IIb that gives additional rewardfor node j2 to tell the truth and punish node j. Moreover (23)implies that this additional reward for node j2 outweighs thebenefit from punishing node j1. (23) can be thought as theincentives for the monitoring nodes to punish the deviatingnode when the announcements are inconsistent.
Previous arguments ensure that if every nodes in the net-work are monitored by at least two other nodes, then anyfeasible v ∈ V† can be realized. Next, we analyze the threecases listed in Theorem 3. In the first case, if all routes thatnode i participates have only 2 hops, and degin(i) ≥ 2, thisimplies that every node can be perfectly monitored by two or

PANDANA et al.: COOPERATION ENFORCEMENT AND LEARNING FOR OPTIMIZING PACKET FORWARDING IN AUTONOMOUS WIRELESS NETWORKS 3157
Fig. 3. Suppose the victim node, S, is in the edge of the network and everytransmission coming from node S should go through node f . Suppose nodef deviates and blocks the announcement from S. Node S can increase thetransmission power to bypass node f to broadcast the announcement.
more nodes. It is obvious that the above game rules can beapplied directly. In the second case when node i participatesin routes with one of the routes of exactly 2 hops, anddegin(i) ≥ 3, both the announcement from the source of the 2-hop route and the aggregate announcements from the sourcesof the rest of the routes serve as the final announcements.We note that the intersection of the aggregate announcementswill do the incrimination on a certain node. The node thatdoes not tell the truth can be determined by majority votingmethod. Finally, for the case where node i participates in theroutes which have more than 2 hops and degin(i) ≥ 4, thesources can form two groups and use the previous game ofrule. The lying node will be detected using majority voting.In summary, any potential deviation in the network satisfyingthe conditions of Theorem 3 can be detected. Moreover, thegame rules guarantee that any feasible rational utilities can beenforced.
We note that from the announcement forwarder perspec-tive, it faces two scenarios, namely either the announcementcontains negative information about the forwarder itself or itcontains negative information about the other nodes. In the firstcase, the forwarding node may not forward the announcement,however, even though that node itself does not forward theannouncement, there is only a small probability that theannouncement does not go through the whole network asillustrated in Figure 3. Moreover, the condition that every nodeis monitored by at least 2 nodes indicates that the illustratedcase is less probable. In the second case, the forwardingnodes do not have any immediate gain for not forwarding theannouncement, i.e., the forwarder is indifferent of forwardingthe announcement. However, the forwarding nodes are better-off to forward the truthful announcement in order to catchand punish the deviating node. Otherwise, the forwardingnodes may also become the victims of the deviation in thefuture. Moreover, the announcement consumes much lowerenergy compared to the packet transmission itself. Hence, byindifferent we meant, each node is better off while makinga truthful announcement, which will consume just a smallportion of the energy transmission rather than a bigger losswhen it is deviated by the deviating node.
Based on different information structures, analyses in Sec-tion III-A and Section III-B guarantee that any individuallyrational utilities can be enforced under some conditions.However, the individual distributed nodes need to know how tocooperate, i.e. what the good packet forwarding probabilitiesare. In the next section, we describe the learning algorithmsto achieve better utilities.
IV. SELF-LEARNING ALGORITHMS
From Section III, any Pareto dominant solutions betterthan one stage NE can be sustained. However, the analysisdoes not explicitly determine which cooperation point to besustained. In fact, the system can be optimized to differentcooperating points, depending on the system designer choices.For instance, the system can be designed to maximize theweighted sum of the average infinitely repeated game’s utilitiesas follow
Usys =N∑
i=1
w(i)U(i)
∞ , whereN∑
i=1
w(i) = 1. (24)
In particular, when w(i) = 1N , ∀i, maximize the average utility
per nodes is usually employed in network optimization
Usys =1N
N∑i=1
U(i)
∞ . (25)
We use (25) as an example, but we emphasize that anysystem objective function can be incorporated into the learningalgorithm in a similar way. From individual point of view, aslong as the cooperation can generate a better utility than thenon-cooperation, the autonomous node will participate. More-over, any optimization other than the system optimization canbe monitored by the other nodes as deviation. Consequently,the punishment can be explored in the future.
The basic idea of the learning algorithm is to search itera-tively the good cooperating forwarding probability. Similar tothe punishment design, we consider the learning schemes fordifferent information availability, namely, the perfect observ-ability and the local observability. In parallel with the systemmodel in Section II, we consider the time-slotted transmis-sion that interleaves the learning mode and the cooperationmaintenance mode as shown in Figure 1. In the learningmode, the nodes search for better cooperating points. In thecooperation maintenance mode, nodes monitor the actions ofother nodes and apply punishment if there is any deviation.In the learning mode, the nodes have no incentives to deviatesince they do not know if they can get benefits. So they donot want to miss the chance of obtaining the better utilitiesin the learning mode. It is also worth mentioning that if anode deviates just before a learning period, it will still bepunished in the following cooperation maintenance period. Sothe infinite repeated game assumption is still valid in this timeslotted transmission system.
A. Self-learning under the perfect observability
Under the perfect observability information structure, everynode is able to detect the deviation of any defecting node,and observe which nodes help forwarding others’ packets.This fact implies that every node is able to perfectly predictthe average efficiencies of other nodes and optimize thecooperating point based on the system criterion (25). The basicidea of the learning algorithm is to use the steepest-descent-like iterations. All nodes predict the average efficiencies of theothers and the corresponding gradients. The detailed algorithmis listed as in Table I. Learning with perfect observabilityassumes the perfect knowledge of utility functions of all nodes

3158 IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, VOL. 7, NO. 8, AUGUST 2008
TABLE ISELF-LEARNING REPEATED-GAME ALGORITHM UNDER PERFECT
OBSERVABILITY
For node i: Given �α−i, small increment β,and minimum forwarding probability αmin
Iteration: t = 1, 2, · · ·Calculate ∇Usys(�α(t − 1))Calculate �α(t) = �α(t − 1) − β∇Usys(�α(t − 1))Select αi(t) = min {max{[�α(t)]i, αmin}, 1}
in the network, and represents the best solution that anylearning algorithm can achieve.
B. Self-learning under the local observability
In this subsection, we focus on the learning algorithm withthe information structure available under local observability.Under this condition, the nodes may not have the completeinformation about the exact utility of others. Based on thisinformation structure, we develop two learning algorithms.The first algorithm is called learning through flooding. Thesecond algorithm makes prediction of the other nodes’ stageefficiency based on the flows that go through the predictingnode. We called the second algorithm as learning throughutility prediction.
1) Learning through Flooding: The basic idea of the learn-ing algorithm is as follow. Since the only information the nodecan observe is the effect of changing its forwarding probabilityonto its own utility function. The best way for the nodes tolearn the packet forwarding probability is to gradually increasethe probability and monitor if the utility function becomesbetter. If the utility becomes better, the new forwardingprobability will be employed. Otherwise, the old forwardingprobability will be kept. The algorithm lets all nodes changetheir packet forwarding probabilities simultaneously. This canbe done by flooding the instruction for changing the packetforwarding probability. After changing the packet forwardingprobability, the effect propagates throughout the network. Allnodes wait for a period of time until the network becomesstable. At the end of this period, the nodes obtain their newutilities. If the utilities are better than the original ones, thenthe new packet forwarding probabilities are employed. Other-wise, the old ones are kept. We note that the packet forwardingprobability increment is proportional to the increase in theutility function: the nodes with higher increment in their utilityfunctions increase their forwarding probability more comparedto the nodes with lower utility increment. Here, we introducethe normalization factor U (i),t−1(αt−1
i ) (the utility beforechanging the forwarding probability) in order to keep theupdates in forwarding probability bounded. The forwardingprobability increment depends on small increment constant ηand the normalization factor. The above process is performeduntil no improvement can be made. The detailed algorithm isshown in Table II.
We note that the time until the network is stable is definedas the time until all of the nodes do not observe fluctuationsin their utility functions as the result of flooding/changingforwarding probabilities in the previous round. In practice,this waiting time can be either predefined or adjusted online as
TABLE IISELF-LEARNING REPEATED-GAME ALGORITHM (FLOODING)
Initialization: t = 0αt
i = α0, ∀i. Choose small increment ξ, η.Iteration: t = 1, 2, · · ·
Calculate U (i),t−1(αt−1i ) and U (i),t−1(αt−1
i + ξ),Calculate ΔU (i),t−1 = U (i),t−1(αt−1
i + ξ)−U (i),t−1(αt−1
i ),For each i such that ΔU (i),t−1 > 0,
αti = αt−1
i + η ΔU(i),t−1
U(i),t−1(αt−1i )
,
αti = max(min(αt
i, 1), αmin).End when: No improvement.Keep monitoring the deviationStart punishment scheme if there is a deviation
follow: Depending on the size of the network, a waiting periodwill be set in each node. If the node observes that its utilityfunction fluctuates more than the preset period of time, thatnode can propose to prolong the preset time in the next roundof flooding, otherwise the old preset waiting time is employed.When a node observes requests to prolong the waiting time,it sets the maximum of the broadcasted waiting times andits own waiting time as the current waiting time. In thisway, nodes will wait until the effect of changing forwardingprobability propagates to the whole network before the nextflooding (changing of forwarding probability) happens. Themaximum delay can also be set to keep the delay timebounded.
2) Learning with utility prediction: In this second ap-proach, we observe that some of the routing information canbe used to learn the system optimal solution (25). We assumethat the routing decision has been made before performing thepacket forwarding task. For instance, in the route discoveryusing Dynamic Source Routing (DSR) [12] algorithm withoutroute caching, the entire selected route is included in thepacket header in the packet transmission. The intermediatenodes use the route (in packet header) to determine to whomthe packet will be forwarded. Therefore, it is clear that thetransmitting node knows where the packet goes through, therelaying nodes know where the packet comes from and headsto, and the receiving node knows where the packet comesfrom. The nodes use this information to predict the utilities ofothers’ nodes. We note that because not all nodes are involvedin all of the flows in the network, the utility prediction maynot be perfectly accurate. But from the simulation results,the performance degradation is minimal since only the nearbynodes matter.
The utility prediction is illustrated using an example shownin Figure 4, assuming μS(r) = 1, K = 1, and d(i, j) = 1. We
denote U(j)i as the utility of node j predicted by node i. From
the figure, node 1 receives flows from node 3, and node 4 andnode 4 receives flows from node 1 and node 2. It is obviousthat the flow from node 2 to node 4 is not perceived by node1. Hence, the utilities of node 2 and node 3 predicted by node1 are not the accurate ones. Similarly, the flow from node 3to node 1 is not perceived by node 4. Therefore, U
(2)4 and
U(3)4 are not accurate. The accuracy of the prediction depends

PANDANA et al.: COOPERATION ENFORCEMENT AND LEARNING FOR OPTIMIZING PACKET FORWARDING IN AUTONOMOUS WIRELESS NETWORKS 3159
Fig. 4. Example for learning with utility prediction.
on the flows. If all flows involving node i pass through nodej then U
(i)j will be accurate and vice versa as illustrated in
Figure 4. However, as we show by simulations the inaccuracyin the prediction does not affect the results of optimizationtoo much.
Since the objective of the optimization is to achieve thesystem optimal solution (25), the best node i can do is to findthe solution that minimizes the total average predicted utilityfunction, which is
min 1N
∑Nj=1 U
(j)i (α(1)
i , · · · , α(N)i ), (26)
s.t. αmin ≤ α(j)i ≤ 1, ∀j,
where α(j)i is the packet forwarding probability that node
j should employ as predicted by node i. The detailed ofthe algorithm is presented as in Table III. The algorithm inTable III imitates the steepest-descent algorithm based onthe predicted utility, where every node finds the gradientof the predicted utility and optimizes the predicted systemutility (26). After obtaining {α(i)}, each node sets its ownpacket forwarding probability as αt
i = α(i)i . We note that the
optimization problem (26) can be done in a distributed manner,since the optimization does not require the global knowledgeof the utility function. Each node does the optimization basedon its own prediction and sets its packet forwarding probabilityaccording to the optimized predicted average utility.
Finally, we discuss how to handle the mobility of nodes.We note that the scheme will work well in moderate nodemobility when the neighbors of each node do not changevery often. Under this condition, the long-term relationshipbetween nodes can be established by means of the repeatedgame and reputation announcement as described in SectionIII. As a result, the cooperation can be learned and enforced.
Obviously, the long-term relationship may be hard to estab-lish in the case where there is a node that deviates in one partof the network, moves quickly to the other part of the network,deviates again and so on so forth. In this case, there are twopossible solutions. First, when the node moves to a new place,in order for the node to transmit, some background check isnecessary. This can be done in two ways: first, if the nearbynodes can share the announcement, then the neighbors of the
TABLE IIISELF-LEARNING REPEATED-GAME ALGORITHM WITH UTILITY
PREDICTION
Initialization: t = 0α
(i),tj = α0, ∀i, j. Choose small increment ζ.
Iteration: t = 1, 2, · · ·For each node j = 1, · · · , N
Calculate
[∇(1)j , · · · ,∇(N)
j ] =[
∂∑ N
n=1 U(n)j
N∂α(1),tj
, · · · ,∂
∑ Nn=1 U
(n)j
N∂α(N),tj
]
Calculate α(i),tj = α
(i),t−1j + ζ∇(i)
j
Set α(i),tj = max(min(α(i),t
j , 1), αmin).End when:
No improvement and return α(i)j = α
(i),tj , ∀i, j.
Keep monitoring the deviation, and go topunishment scheme whenever there is a deviation.
node can obtain the announcement from the node’s previousneighbors. And the new neighbors will know the reputationof this new node. The analogy of this case in the real life iswhen someone applies for a new job, the new employer alwaysasks for the references from the old employers. And bothemployers can work harmoniously in a distributed manner.In the literature, the above idea is implemented in the trustestablishment for ad hoc network such as [16].
The other solution is by increasing the sampling of thelearning algorithm. As long as the node mobility does notchange the relationship between neighboring nodes drastically,the effect of mobility to the learning algorithm can be lever-aged by putting more frequent learning period in the slottedtransmission as in Figure 1. This case is similar to trackingnon-stationary channel; the faster the channel changes themore frequent the training sequence transmission is required.
V. SIMULATION RESULTS
To investigate effectiveness of our proposed framework, weperform simulations with the following settings. We generatetwo networks with 25 nodes: the ring-25 network and random-25 network. The ring-25 network consists of 25 nodes thatare arranged in a circle with radius 1000m. The random-25network consists of 25 nodes that are uniformly distributed inthe area of 1000m×1000m. We define the maximum distancedmax, such that two nodes are connected if the distancebetween two nodes is less than dmax. We select the maximumdistance between two nodes to ensure connectivity of thewhole network. In the ring-N network, the angle separationbetween two neighboring nodes is 2π
N . And, the distancebetween two neighboring nodes is 2r sin( 2π
2N ), where r is theradius of the circle. In particular, the maximum distance forthe ring-25 network can be calculated as 2000 sin
(2π50
)m =
250.7m. In the random-25 network, the maximum distancebetween two nodes is 350m to ensure connectivity of thewhole network with a high probability.
We also define the flows as source-destination (SD) pairs.We assume that the routing decision has been made beforeperforming packet forwarding optimization. The shortest pathrouting is employed in the simulations. In the random-25

3160 IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, VOL. 7, NO. 8, AUGUST 2008
0 5 10 15 20 25 300
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9U(3) in ring−25 network
time
stag
e ef
ficie
ncy
Stage efficiency
Average efficiency with deviation
Average efficiency without deviation
(a) Ring network
0 5 10 15 20 25 30 35 400
0.1
0.2
0.3
0.4
0.5
0.6
0.7U(10) in random network with 16 nodes
time
Stag
e ef
ficie
ncy
Stage efficiencyAverage efficiency with deviationAverage efficiency without devation
(b) Random network
Fig. 5. Punishment of repeated game in the ring network and the randomnetwork.
network, we vary the number of SD pairs. When there aretraffic flows from all nodes to all other nodes, we called thistraffic as dense flow that implies that each node has packetsdestined to the rest of nodes in the network. Obviously, thedense flow has N × (N −1) SD pairs in the N -node network.When the total flow is less than the dense flow, the SD pairsare determined randomly. In the ring-25 network, the numberof SD pairs is defined in the following way. The (K ·N) SDpairs are obtained when every node i sends packets to nodes({mod(i + 2, 25), · · · , mod(i + K + 1, 25)}. For instance, 25SD pairs are obtained when every node i transmits packetsto node mod(i + 2, 25), 50 SD pairs are obtained when everynode i sends packets to nodes {mod(i+2, 25), mod(i+3, 25)},etc. The rest of the simulation parameters are given as follows,transmission rate of source i as μi = 1, ∀i, transmissionconstant K = 1, distant attenuation coefficient γ = 4. Wecompare three learning algorithms according to the informa-
0 100 200 300 400 500 6000
0.05
0.1
0.15
0.2
0.25
simulation time
Ave
rage
eff
icie
ncy
per n
ode
Learning curve for different algorithm with different number of SD−pairs
Learning perfect 100 SDpairsOptimal solution 100 SDpairsFlooding 100 SDpairsUtility Prediction 100 SDpairsLearning perfect 200 SDpairsOptimal solution 200 SDpairsFlooding 200 SDpairsUtility Prediction 200 SDpairsLearning perfect 275 SDpairsOptimal solution 275 SDpairsFlooding 275 SDpairsUtility Prediction 275 SDpairs
ring 25 Nodes, 100 SDpairs
ring 25 Nodes, 200 SDpairs
ring 25Nodes,275SDpairs
Fig. 6. Learned average efficiency per node for different traffic loads in thering network.
tion availability. The parameters for the learning algorithmsare listed as follows β = 0.05, ξ = 0.001, η = 1.0, andζ = 0.05. The minimum forwarding probability is set to beαmin = 0.1 and the maximum forwarding probability is setto be αmax = 1. Finally, all algorithms are initiated withα0 = 0.5, ∀i. We note that in the following simulations, weemploy the average efficiency per node defined in (25) as ourperformance metric.
Figure 5(a) shows the average efficiency of the deviationnode in the ring-25 network when the number of source-destination is 75 with the discounted factor δ = 0.9. In thefigure, node 3 deviates at time instant 10. This deviation causesthe stage efficiencies of node 1, 2 and 25 become lower. Fromthe route, node 1, node 2 and node 25 suspect that nodesin {2, 3, 4}, {3, 4, 5} and {1, 2, 3} are deviating, respectively.The nodes in the network know that node 3 is consistent tobe incriminated for deviation and start the punishment stage(Here, the punishment period is set to 3). The punishmentscheme results in lower average stage efficiency as describedin Figure 5(a). From the figure, the average efficiency withoutdeviation is better than the average efficiency with deviation.It is clear that it is better off for node 3 to conform to thepreviously agreed cooperation point. As the result, no nodewants to deviate, since the deviation results in worse averageefficiency. Similarly, Figure 5(b) shows the average utilities ofdeviating node and other nodes in the random network with16 nodes with the discounted factor 0.9. At time instant 11,node 10 in the network deviates. At the next time instant, allrelated nodes that detect deviation exchange the list of theincriminated nodes. The consistent incriminated node (in thiscase node 10) is punished for a certain period of time (in thisfigure, 8 period of time). From the figure, it is clear that node10 will have higher average efficiency when it conforms. Sofrom Figure 5(a) and Figure 5(b), the proposed repeated gamecan enforce the cooperation among autonomous greedy nodes.
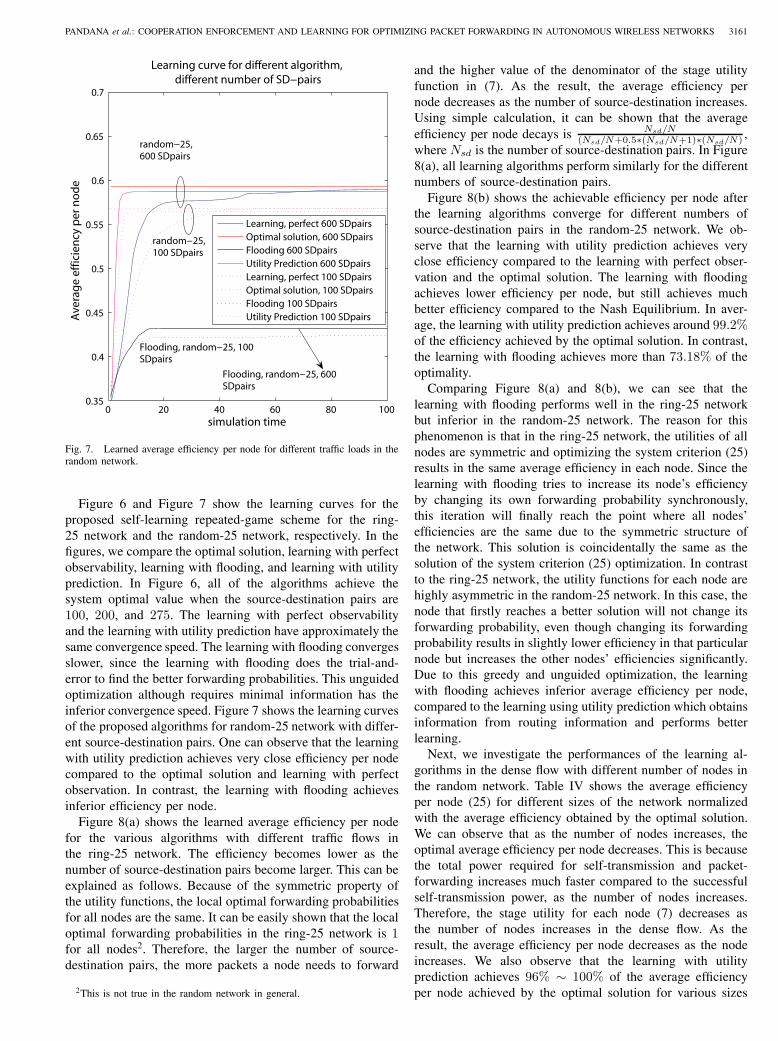
PANDANA et al.: COOPERATION ENFORCEMENT AND LEARNING FOR OPTIMIZING PACKET FORWARDING IN AUTONOMOUS WIRELESS NETWORKS 3161
0 20 40 60 80 1000.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
simulation time
Ave
rage
eff
icie
ncy
per n
ode
Learning curve for different algorithm, different number of SD−pairs
Learning, perfect 600 SDpairsOptimal solution, 600 SDpairsFlooding 600 SDpairsUtility Prediction 600 SDpairsLearning, perfect 100 SDpairsOptimal solution, 100 SDpairsFlooding 100 SDpairsUtility Prediction 100 SDpairs
random−25,600 SDpairs
random−25,100 SDpairs
Flooding, random−25, 100SDpairs
Flooding, random−25, 600SDpairs
Fig. 7. Learned average efficiency per node for different traffic loads in therandom network.
Figure 6 and Figure 7 show the learning curves for theproposed self-learning repeated-game scheme for the ring-25 network and the random-25 network, respectively. In thefigures, we compare the optimal solution, learning with perfectobservability, learning with flooding, and learning with utilityprediction. In Figure 6, all of the algorithms achieve thesystem optimal value when the source-destination pairs are100, 200, and 275. The learning with perfect observabilityand the learning with utility prediction have approximately thesame convergence speed. The learning with flooding convergesslower, since the learning with flooding does the trial-and-error to find the better forwarding probabilities. This unguidedoptimization although requires minimal information has theinferior convergence speed. Figure 7 shows the learning curvesof the proposed algorithms for random-25 network with differ-ent source-destination pairs. One can observe that the learningwith utility prediction achieves very close efficiency per nodecompared to the optimal solution and learning with perfectobservation. In contrast, the learning with flooding achievesinferior efficiency per node.
Figure 8(a) shows the learned average efficiency per nodefor the various algorithms with different traffic flows inthe ring-25 network. The efficiency becomes lower as thenumber of source-destination pairs become larger. This can beexplained as follows. Because of the symmetric property ofthe utility functions, the local optimal forwarding probabilitiesfor all nodes are the same. It can be easily shown that the localoptimal forwarding probabilities in the ring-25 network is 1for all nodes2. Therefore, the larger the number of source-destination pairs, the more packets a node needs to forward
2This is not true in the random network in general.
and the higher value of the denominator of the stage utilityfunction in (7). As the result, the average efficiency pernode decreases as the number of source-destination increases.Using simple calculation, it can be shown that the averageefficiency per node decays is Nsd/N
(Nsd/N+0.5∗(Nsd/N+1)∗(Nsd/N) ,where Nsd is the number of source-destination pairs. In Figure8(a), all learning algorithms perform similarly for the differentnumbers of source-destination pairs.
Figure 8(b) shows the achievable efficiency per node afterthe learning algorithms converge for different numbers ofsource-destination pairs in the random-25 network. We ob-serve that the learning with utility prediction achieves veryclose efficiency compared to the learning with perfect obser-vation and the optimal solution. The learning with floodingachieves lower efficiency per node, but still achieves muchbetter efficiency compared to the Nash Equilibrium. In aver-age, the learning with utility prediction achieves around 99.2%of the efficiency achieved by the optimal solution. In contrast,the learning with flooding achieves more than 73.18% of theoptimality.
Comparing Figure 8(a) and 8(b), we can see that thelearning with flooding performs well in the ring-25 networkbut inferior in the random-25 network. The reason for thisphenomenon is that in the ring-25 network, the utilities of allnodes are symmetric and optimizing the system criterion (25)results in the same average efficiency in each node. Since thelearning with flooding tries to increase its node’s efficiencyby changing its own forwarding probability synchronously,this iteration will finally reach the point where all nodes’efficiencies are the same due to the symmetric structure ofthe network. This solution is coincidentally the same as thesolution of the system criterion (25) optimization. In contrastto the ring-25 network, the utility functions for each node arehighly asymmetric in the random-25 network. In this case, thenode that firstly reaches a better solution will not change itsforwarding probability, even though changing its forwardingprobability results in slightly lower efficiency in that particularnode but increases the other nodes’ efficiencies significantly.Due to this greedy and unguided optimization, the learningwith flooding achieves inferior average efficiency per node,compared to the learning using utility prediction which obtainsinformation from routing information and performs betterlearning.
Next, we investigate the performances of the learning al-gorithms in the dense flow with different number of nodes inthe random network. Table IV shows the average efficiencyper node (25) for different sizes of the network normalizedwith the average efficiency obtained by the optimal solution.We can observe that as the number of nodes increases, theoptimal average efficiency per node decreases. This is becausethe total power required for self-transmission and packet-forwarding increases much faster compared to the successfulself-transmission power, as the number of nodes increases.Therefore, the stage utility for each node (7) decreases asthe number of nodes increases in the dense flow. As theresult, the average efficiency per node decreases as the nodeincreases. We also observe that the learning with utilityprediction achieves 96% ∼ 100% of the average efficiencyper node achieved by the optimal solution for various sizes
3162 IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, VOL. 7, NO. 8, AUGUST 2008
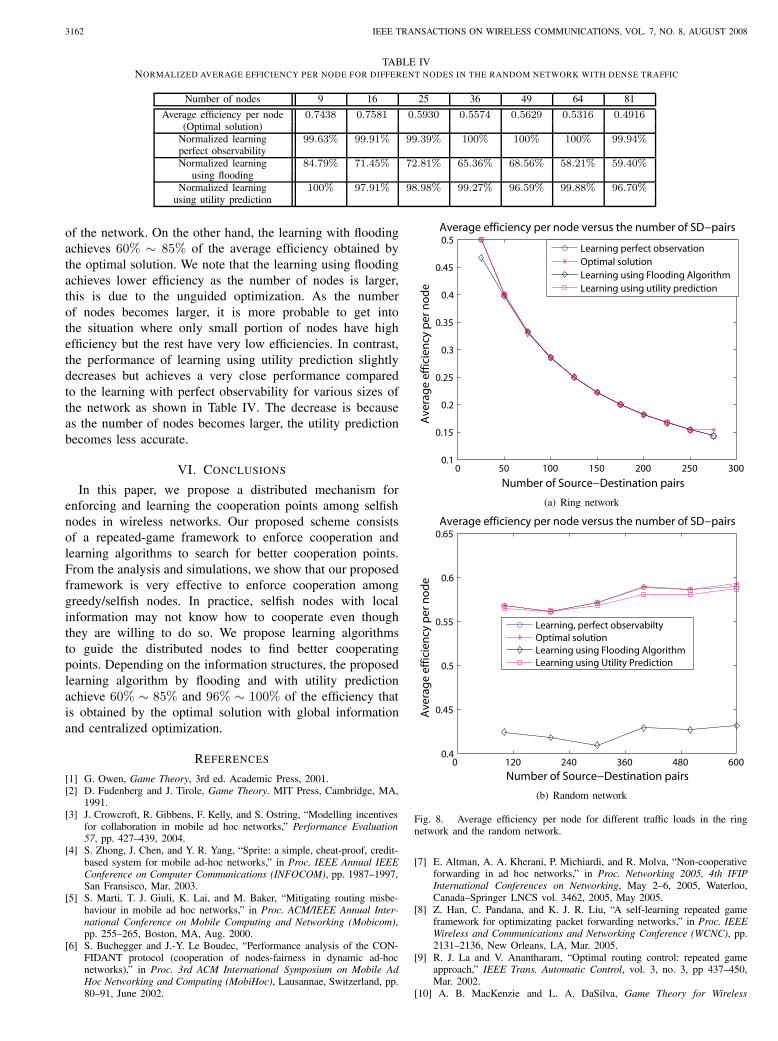
TABLE IVNORMALIZED AVERAGE EFFICIENCY PER NODE FOR DIFFERENT NODES IN THE RANDOM NETWORK WITH DENSE TRAFFIC
Number of nodes 9 16 25 36 49 64 81
Average efficiency per node 0.7438 0.7581 0.5930 0.5574 0.5629 0.5316 0.4916(Optimal solution)
Normalized learning 99.63% 99.91% 99.39% 100% 100% 100% 99.94%perfect observabilityNormalized learning 84.79% 71.45% 72.81% 65.36% 68.56% 58.21% 59.40%
using floodingNormalized learning 100% 97.91% 98.98% 99.27% 96.59% 99.88% 96.70%
using utility prediction
of the network. On the other hand, the learning with floodingachieves 60% ∼ 85% of the average efficiency obtained bythe optimal solution. We note that the learning using floodingachieves lower efficiency as the number of nodes is larger,this is due to the unguided optimization. As the numberof nodes becomes larger, it is more probable to get intothe situation where only small portion of nodes have highefficiency but the rest have very low efficiencies. In contrast,the performance of learning using utility prediction slightlydecreases but achieves a very close performance comparedto the learning with perfect observability for various sizes ofthe network as shown in Table IV. The decrease is becauseas the number of nodes becomes larger, the utility predictionbecomes less accurate.
VI. CONCLUSIONS
In this paper, we propose a distributed mechanism forenforcing and learning the cooperation points among selfishnodes in wireless networks. Our proposed scheme consistsof a repeated-game framework to enforce cooperation andlearning algorithms to search for better cooperation points.From the analysis and simulations, we show that our proposedframework is very effective to enforce cooperation amonggreedy/selfish nodes. In practice, selfish nodes with localinformation may not know how to cooperate even thoughthey are willing to do so. We propose learning algorithmsto guide the distributed nodes to find better cooperatingpoints. Depending on the information structures, the proposedlearning algorithm by flooding and with utility predictionachieve 60% ∼ 85% and 96% ∼ 100% of the efficiency thatis obtained by the optimal solution with global informationand centralized optimization.
REFERENCES
[1] G. Owen, Game Theory, 3rd ed. Academic Press, 2001.[2] D. Fudenberg and J. Tirole, Game Theory. MIT Press, Cambridge, MA,
1991.[3] J. Crowcroft, R. Gibbens, F. Kelly, and S. Ostring, “Modelling incentives
for collaboration in mobile ad hoc networks,” Performance Evaluation57, pp. 427–439, 2004.
[4] S. Zhong, J. Chen, and Y. R. Yang, “Sprite: a simple, cheat-proof, credit-based system for mobile ad-hoc networks,” in Proc. IEEE Annual IEEEConference on Computer Communications (INFOCOM), pp. 1987–1997,San Fransisco, Mar. 2003.
[5] S. Marti, T. J. Giuli, K. Lai, and M. Baker, “Mitigating routing misbe-haviour in mobile ad hoc networks,” in Proc. ACM/IEEE Annual Inter-national Conference on Mobile Computing and Networking (Mobicom),pp. 255–265, Boston, MA, Aug. 2000.
[6] S. Buchegger and J.-Y. Le Boudec, “Performance analysis of the CON-FIDANT protocol (cooperation of nodes-fairness in dynamic ad-hocnetworks),” in Proc. 3rd ACM International Symposium on Mobile AdHoc Networking and Computing (MobiHoc), Lausannae, Switzerland, pp.80–91, June 2002.
0 50 100 150 200 250 3000.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
Number of Source−Destination pairs
Ave
rage
eff
icie
ncy
per n
ode
Average efficiency per node versus the number of SD−pairs
Learning perfect observationOptimal solutionLearning using Flooding AlgorithmLearning using utility prediction
(a) Ring network
0 120 240 360 480 6000.4
0.45
0.5
0.55
0.6
0.65
Number of Source−Destination pairs
Ave
rage
eff
icie
ncy
per n
ode
Average efficiency per node versus the number of SD−pairs
Learning, perfect observabiltyOptimal solutionLearning using Flooding AlgorithmLearning using Utility Prediction
(b) Random network
Fig. 8. Average efficiency per node for different traffic loads in the ringnetwork and the random network.
[7] E. Altman, A. A. Kherani, P. Michiardi, and R. Molva, “Non-cooperativeforwarding in ad hoc networks,” in Proc. Networking 2005, 4th IFIPInternational Conferences on Networking, May 2–6, 2005, Waterloo,Canada–Springer LNCS vol. 3462, 2005, May 2005.
[8] Z. Han, C. Pandana, and K. J. R. Liu, “A self-learning repeated gameframework for optimizating packet forwarding networks,” in Proc. IEEEWireless and Communications and Networking Conference (WCNC), pp.2131–2136, New Orleans, LA, Mar. 2005.
[9] R. J. La and V. Anantharam, “Optimal routing control: repeated gameapproach,” IEEE Trans. Automatic Control, vol. 3, no. 3, pp 437–450,Mar. 2002.
[10] A. B. MacKenzie and L. A. DaSilva, Game Theory for Wireless

PANDANA et al.: COOPERATION ENFORCEMENT AND LEARNING FOR OPTIMIZING PACKET FORWARDING IN AUTONOMOUS WIRELESS NETWORKS 3163
Engineers. Morgan and Claypool Publishers, 2006.[11] Z. Han, Z. Ji, and K. J. R. Liu, “Dynamic distributed rate control
for wireless networks by optimal cartel maintenance strategy,” in Proc.IEEE Global Telecommunications Conference (Globecom), pp. 3742–3747, Dallas, TX, Dec. 2004.
[12] D. Johnson, D. Maltz, Y. C. Hu, and J. Jetcheva, “The dynamic sourcerouting protocol for mobil ad hoc networks (DSR),” IETF Internet Draft,Feb. 2002.
[13] M. Kandori, “Social norms and community enforcement,” Review ofEconomic Studies, vol. 59, no. 1, pp. 63–80, 1992.
[14] D. Fudenberg and E. Maskin, “The Folk theorem in repeated games withdiscounting or with incomplete information,” Econometrica, vol. 54, no.3, pp. 533–554, May 1986.
[15] E. Ben-Porath and M. Kahneman, “Communication in repeated gameswith private monitoring,” J. Economic Theory, vol. 70, pp. 281–297, 1996.
[16] Y. Sun, W. Yu, Z. Han, and K. J. Ray Liu, “Information theoreticframework of trust modeling and evaluation for ad hoc networks,” IEEEJ. Select. Areas Commun., vol. 24, no. 2, pp. 305–317, Feb. 2006.
Charles Pandana received his B.S. degree andM. S. degree in electronics engineering from theNational Chiao Tung University, Hsinchu, Taiwan,in 1998 and 2000, and the Ph.D. degree in elec-trical and computer engineering from Universityof Maryland in 2005. He is currently a systemresearch engineer in ArrayComm LLC. His researchinterests include stochastic modeling/learning andsystem level/network performance analysis for nextgeneration wireless networks. He is a member ofthe IEEE Signal Processing Society and the IEEE
Communication Society.
Zhu Han (S’01-M’04) received the B.S. degree inelectronic engineering from Tsinghua University, in1997, and the M.S. and Ph.D. degrees in electricalengineering from the University of Maryland, Col-lege Park, in 1999 and 2003, respectively.
From 2000 to 2002, he is an R&D Engineerof JDSU, Germantown, Maryland. From 2002 to2003, he was a Graduate Research Assistant at theUniversity of Maryland. From 2003 to 2006, he wasa Research Associate at the University of Maryland.From 2006 to 2008, he was an assistant professor
in Boise State University, Idaho. Currently, he is an Assistant Professor inElectrical and Computer Engineering Department at University of Houston,Texas. In June-August 2006, he was a visiting scholar in Princeton University.In May-August 2007, he was a visiting professor in Stanford University. InMay-August 2008, he was a visiting professor in University of Oslo, Norwayand Supelec, Paris, France. His research interests include wireless resourceallocation and management, wireless communications and networking, gametheory, wireless multimedia, and security.
Dr. Han is the MAC Symposium vice chair of IEEE Wireless Commu-nications and Networking Conference, 2008. Dr. Han is the Guest Editorfor Special Issue on Fairness of Radio Resource Management Techniques inWireless Networks, EURASIP Journal on Wireless Communications and Net-working, and Special Issue on Game Theory, EURASIP Journal on Advancesin Signal Processing. Dr. Han is a member of the Technical ProgrammingCommittee for the IEEE International Conference on Communications, theIEEE Vehicular Technology Conference, the IEEE Consumer Communica-tions and Networking Conference, the IEEE Wireless Communications andNetworking Conference, and the IEEE Globe Communication Conference.
K. J. Ray Liu (F’03) is Professor and AssociateChair, Graduate Studies and Research, of Electricaland Computer Engineering Department, and Distin-guished Scholar-Teacher of University of Maryland,College Park. He leads the Maryland Signals andInformation Group conducting research encompass-ing broad aspects of information technology includ-ing signal processing, communications, networking,information forensics and security, biomedical andbioinformatics.
Dr. Liu is the recipient of numerous honors andawards including best paper awards from IEEE Signal Processing Society(twice), IEEE Vehicular Technology Society, and EURASIP; IEEE SignalProcessing Society Distinguished Lecturer, EURASIP Meritorious ServiceAward, and National Science Foundation Young Investigator Award. Healso received various teaching and research recognitions from University ofMaryland including Invention of the Year Award and college-level Poole andKent Company Senior Faculty Teaching Award.
Dr. Liu is Vice President–Publications and on the Board of Governor ofIEEE Signal Processing Society. He was the Editor-in-Chief of IEEE SignalProcessing Magazine and the founding Editor-in-Chief of EURASIP Journalon Applied Signal Processing.
His recent books include Cooperative Communications and Networking(Cambridge University Press, 2008); Resource Allocation for Wireless Net-works: Basics, Techniques and Applications (Cambridge University Press,2008); Ultra-Wideband Communication Systems: The Multiband OFDM Ap-proach (IEEE-Wiley, 2007); Network-Aware Security for Group Communi-cations (Springer, 2007); Multimedia Fingerprinting Forensics for TraitorTracing (Hindawi, 2005).