core-selectability in chip-multiprocessors
DESCRIPTION
Core-Selectability in Chip-Multiprocessors. Hashem H. Najaf-abadi Niket K. Choudhary Eric Rotenberg. Dividing the Design A definition. Processing Cores. All levels of cache Interconnect Ports to Memory and IO. What this Talk is About. How to improve performance of a CMP. - PowerPoint PPT PresentationTRANSCRIPT

Core-Selectability in Chip-Multiprocessors
Hashem H. Najaf-abadiNiket K. Choudhary
Eric Rotenberg

Dividing the DesignA definition
Processing Cores
All levels of cache Interconnect Ports to Memory and IO

What this Talk is About
How to improve performance of a CMP
by improving the processingthe interconnect is not fully utilized by all workloadsif it is, there’s nothing to gain if it is, there’s nothing to gain here here
by enabling exploitation of the full potential of the interconnection

The Provisioning Factor Balance in provisioned resources
need ports need ports to the to the interconnecinterconnectt
If the same interconnect is enough for a quad-core, then it was over-provisioned for a dual-core.

The Provisioning Factor Balance in provisioned resources
If the design is well provisioned with the same interconnect, then it must have been over-provisioned in the baseline.
some some
technique technique
that boosts that boosts
general general
performanceperformance

The Underutilization Factor Interconnect not fully utilized by all applications
workloads that depend the workloads that depend the
most on interconnect have a most on interconnect have a
louder say in what a well-louder say in what a well-
provisioned design provisioned design
constitutesconstitutes

He’s not much for a conversation. He’s not much for a conversation. But if he was, it But if he was, it would be a conversation about would be a conversation about saving you execution time.saving you execution time.
The One-size-fits-all Factor A single solution has limited performance
RISC v. CISCRISC v. CISC
wide v. narrow wide v. narrow issuing issuing
deep v. shallow deep v. shallow pipeliningpipelining
large v. small large v. small issue queueissue queue
Changing these trade-offs will improve performance for some workloads and degrade it for others.

The Shrinking Factor Progressively less die area for the cores
`
better return better return
on increasing on increasing
the the
interconnectiointerconnectio
n resourcesn resources

The Shrinking Factor Progressively less die area for the cores

10%
20%
30%
40%
50%
60%
70%
80%
90%
100% Intel386
1990 2010
Niagara-1
Intel Pentium
2000 2005
IBM Power4
IBM Power5
IBM Power6
IBM Power3
Niagara-2-
Intel 8086
Intel 8088
Intel 80286 Intel 486DX
Intel
Pentium III
Intel Core Duo
Intel Pentium IV
1995
-
The Shrinking Factor Progressively less die area for the cores

Program 1Program 2
Single Core Design:
Optimized for all workloads
The Diversity Factor Can provide diversity in the core designs

Code 2
Code 1
Heterogeneous Cores:
Optimized for workload
The Diversity Factor Can provide diversity in the core designs

Program 1Program 2
Core-Selectability:
Optimized for workload.
Core-Selectability

Core-Selectability
Selectability

Recap
can reduce verification effort by splitting up workload space
can improve performance without increasing power density
results in a homogeneous design
Provisioning Factor One-size-fits-all Factor
Shrinking Factor
Underutilization Factor
Diversity Factor
Core-Selectability
Port Sharing

Core-SelectabilityRemains homogeneous at a high level
CMP

Empirical EvaluationBased on Fabscalar
A library of the synthesized implementation of different configurations for different microarchitectural units of a contemporary superscalar processor.

The selection of coresCore-U Core-A Core-B
FETCH STAGES 4 3 5
DECODE STAGES 1 1 1
RETIRE STAGES 2 2 2
ISSUE WIDTH 3 2 5
ROB SIZE 512 1024 512
IWINDOW SIZE 64 128 32
Clock period .6ns .6ns .6ns
0
0.2
0.4
0.6
0.8
1
1.2
1.4Core-UCore-ACore-B
norm
aliz
ed e
xec.
tim
e
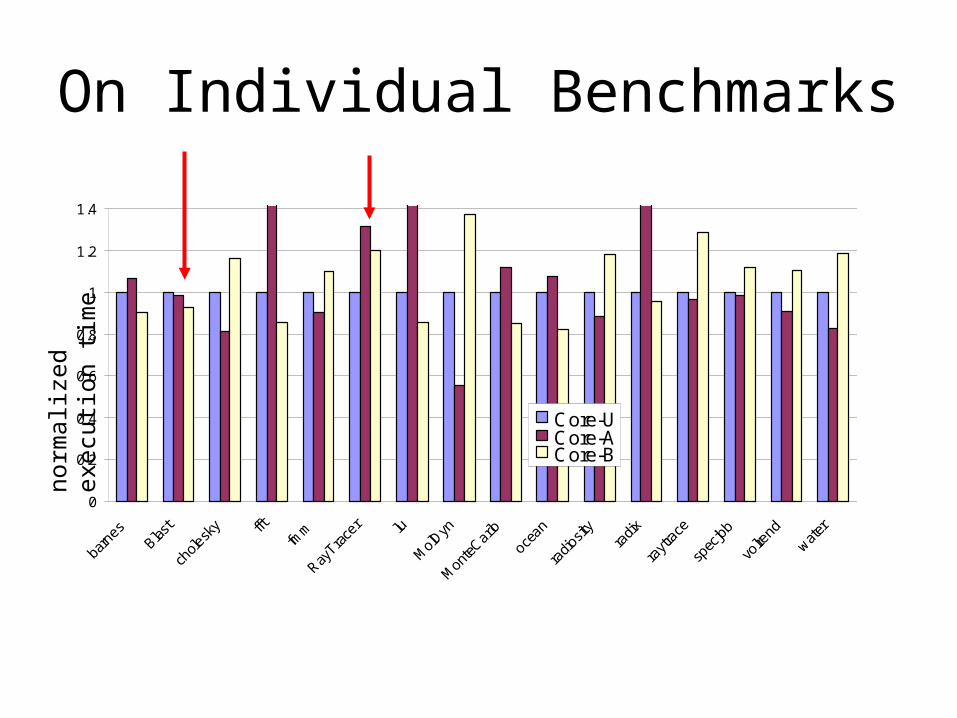
On Individual Benchmarks
0
0.2
0.4
0.6
0.8
1
1.2
1.4
barn
esBlas
t
chole
sky fft
fmm
RayTra
cer lu
MolD
yn
Mon
teCar
lo
ocea
n
radio
sity
radix
raytr
ace
spec
jbb
volre
ndwat
er
Core-UCore-ACore-B
norm
aliz
ed e
xecu
tion
time

The Effect of Selectability
0.8
0.85
0.9
0.95
1
Core-USel. Core-A/Core-BSel. Core-U/Core-ASel. Core-U/Core-BSel. Core-U/Core-A/Core-B
norm
aliz
ed e
xec.
tim
e

Under Different Task Arrival Patterns
00.5
11.5
22.5
33.5
4
4.55
Average task arrival rate (Hz)
Ave
rag
e tu
rnar
ou
nd
tim
e (S
ec.)
Quad core (all Core-U)Quad core (tw o Core-A, 2 Core-B)
00.5
11.5
22.5
3
3.54
4.55
0.01
10.
231
0.45
10.
671
0.89
11.
111
1.33
11.
551
Average task arrival rate (Hz)A
vera
ge
turn
aro
un
d t
ime
(Sec
.)
Quad core (all Core-U)Quad core (2 Core-A, 2 Core-B)
Average task turnaround time for (a) normal traffic, and (b) bursty traffic.

Overhead of Reconfigurability
Issue-Q size Wakeup Delay Select Delay Wake & Select Delay Reconfig. Delay
16 0.55ns 0.54ns 1.09ns 1.55ns
32 0.63ns 0.59ns 1.38ns 1.89ns
64 0.67ns 0.65ns 1.62ns 2.10ns
128 0.82ns 0.76ns 2.00ns 2.30ns

Implementation of Port Sharing
L1 Data Cache
core-selection
Core A Core B
extra switchingextra wire (100fF)
26ps added propagation delay

Overhead of Reconfigurability
• With reconfigurability, change is implemented within a core – with complex coupling between pipeline stages.
• With Core-Selectability, change is implemented at the core level – with less complex coupling between core and interconnect.

Thank you
It’s as if he knows you like It’s as if he knows you like to save execution time.to save execution time.