corey: an operating system for many cores s. boyd-wickizer, h. chen, r. chen, y. mao, f. kaashoek,...
TRANSCRIPT

COREY: AN OPERATING SYSTEMFOR MANY CORES
S. Boyd-Wickizer, H. Chen, R. Chen, Y. Mao,F. Kaashoek, R. Morris, A. Pesterev, L. Stein,
M. Wu, Y. Dai, Y. Zhang, Z. ZhangMIT, Fudan U,
Microsoft Research Asia, Xi’an Jiaotong U

Overview
• Paper presents a technique allowing multicore architectures to overcome memory access bottlenecks
• Key idea is that applications should control sharing of main memory and kernel resources– Make them private by default– Let each application specify which resources it
want to share

What’s interesting
• It does increase system performance– Measured by microbenchmarks and
application benchmarks• It lets applications tell the kernel how to manage
the kernel resources they use– Just the opposite of what is normally done– Same approach as exokernels (xOK)

INTRODUCTION

Motivation (I)
• Most PCs have or will have multicore chips– Cache-coherent shared memory hardware is the
new standard• Performance of some OS services scales very
poorly with number of cores/processors– Contention for OS queues, core directory
lookups– Can dominate performance of some applications

Motivation (II)
• Main source of poor scalability is concurrent updates to shared data structures – Consistency overhead

An example
• Microbenchmark– Creates multiple threads within a process– Each thread creates a file descriptor then
repeatedly duplicates it and close the result• Shared resource is process file descriptor table
– Any modification to the table invalidates its cached copies

An example (II)

An example (III)
• Throughput of microbenchmark actually decreases with number of cores
• Problem caused by cache coherence protocol– Each iteration results in a cache miss– Resolving the miss requires access to a shared
data structure protected by spin locks– Increasing the number of threads attempting to
update the table introduces queuing delays

Common approaches
• Avoiding shared data structures • Allowing concurrent access to shared data
structures through– Fine-grain locking– Wait-free primitives
• Can use atomic operations ortransactional memory

Corey approach (I)
• Not all instances of a given resource type must be shared – Depends of application requirements
• Corey lets application tell kernel which instances of a particular resource type must be shared
• Assumes that other instances can remain private– OS does not incur unnecessary sharing costs

Corey
• Organized as an exokernel• Corey kernel provides
– Address ranges– Kernel cores– Shares
• Most higher services are implemented as library operating systems

What is an exokernel? (I)
• In most operating systems only privileged servers and the kernel can manage system resources
• The exokernel architecture delegates resource management to user applications.
• Applications that do not want this responsibility communicate with the exokernel through a “library OS”

What is an exokernel? (II)
Exokernelprotects but
does not managesystem resources
User process User process
libraryOS

MULTICORE CHALLENGES

Multicore organizations
• Often involve multiple chips– Say four chips with four cores per chip
• Have a cache hierarchy on each chip– L1, L2, L3 – Some caches are private, other are shared
• Accessing a cache on a chip is much faster than accessing a cache on another chip

Example (I)
• AMD 16-core system– Sixteen cores on four chips
• Each core has a 64-KB L1 and a 512-KB L2 cache
• Each chip has a 2-MB shared L3 cache

X/Y where X is latency in cyclesY is bandwidth in bytes/cycle

Example (II)
• Observe that access times are non-uniform– Takes more time to access L1 or L2 cache of
another core than accessing shared L3 cache– Takes more time to access caches in another
chip than local caches– Access times and bandwidths depend on
chip interconnect topology

Performance issues (I)
• Linux spin locks– Repeatedly access a shared lock variable
• MCS locks– (Mellor-Crummey and Scott , 1991)– Process requesting the lock inserts itself in a
possibly empty queue – Waiting processes do not interfere with each
other

Performance issues (II)

Performance issues (III)
• Spinlocks are better at low contention rates – Require three instructions to acquire and
release a lock– MCS locks require fifteen instructions
• MCS locks are much better at higher contention rates– Less synchronization overhead

Motivation for address ranges
• Most OSes let applications chose between– A single address space shared by all cores
• Threaded applications– One private address space per core
• Applications forking full processes• Neither of these two solutions is fully satisfactory

MapReduce applications
• Map phase:– Processes read parts of application’s inputs– Generate intermediary results and store them
locally
• Reduce phase:– Processors collate results produced by multiple
map instances– Produce the output

Single address space
Bad for map phase, very good for reduce phase

Separate address spaces
Very good for map phase, bad for reduce phase

Best of both worlds

COREY DESIGN

Address ranges (I)
• Let applications specify which parts of their address space are shared and which are private– Private address ranges will not incur any
consistency overhead– Shared address ranges can share their hardware
page tables• Minimizes soft page faults (when page is in
main memory but not mapped in the process page table)

Address ranges (II)
Application A Application B
Shared

Address ranges (III)
• Kernel-provided abstraction specifying a virtual-to-physical mapping for a range ofvirtual addresses
• If multiple cores include the same address range in their address space they will share the same mapping to the same physical pages
• Each core can freely manipulate and delete mapping in private address ranges w/o any consequences for other core performance

Kernel cores
• In most OS, system calls are executed on the core of the invoking process– Bad idea if the system call needs to access
large shared data structures• Kernel cores let applications dedicate cores to
run specific kernel functions– Avoids inter-core contention over the data
these functions access

Symmetric multiprocessing (I)
• Each core can execute both user and kernel code– No execution bottleneck
Useror kernel
code
Useror kernel
code...

Symmetric multiprocessing (II)
• Works very well unless too many kernel function instances access large shared data structures– Contention
Useror kernel
code
Useror kernel
code
Shareddata

The solution
• Run kernel functions that access large shared data structures
–No inter-core contention
Useror kernel
code
Useror kernel
code Shareddata
Kernel code

Shares (I)
• Many kernel operations involve looking up identifiers in tables to obtain a pointer to a given kernel data structure (file descriptor entry, …)
• Lookup tables for kernel objects that let applications specify which object identifiers are visible to other cores
• Each application core has a root share that is private to that core– Needs no locks since its private

Shares (II)
• If two cores want to “share a share,” they create one and add the share ID to either– Their private root shares or– A share reachable from these root shares
• Allows applications to restrict sharing to kernel structures that must be shared

Shares (II)
Shared: must use locks to provide mutual exclusion
A's table B's tablePrivate:no locks
Private:no locks

COREY KERNEL
(not discussed)

SYSTEM SERVICES
(not discussed)

Execution forking
• cfork(core_id) is an extension of UNIX fork() that creates a new process (pcore) on core core_id
• Application can specify multiple levels of sharing between parent and child– Default is copy-on-write

Network
• Applications can decide to run– Multiple network stacks– A single shared network stack

Buffer cache
• Shared buffer like regular UNIX buffer cache• Three modifications
– A lock-free tree allows multiple cores to locate cached blocks w/o contention
– A write scheme tries to minimize contention– A scalable read/write lock

APPLICATIONS

MapReduce applications
• Modified the Phoenix MapReduce implementation to take advantage of Cory features (Metis)– Each core has a separate address space with
• Private mappings for most data • Address ranges to share the output of the
map with other cores

Web server applications
• Corey web server is built from three components– Web daemons:
• Process HTTP requests and have their own TCP/IP stack
• Also referred as webd cores– Kernel cores (optional)– Applications


IMPLEMENTATION

Current status
• Runs on AMD Opterons and Intel Xeons• Implementation of address ranges is tailored to
architectures with hardware page tables– Would provide lesser benefits on
architectures where the kernel manages the page tables

EVALUATION

Evaluation of address ranges (I)
• Two micro benchmarks– memclone:
Has each core allocate its own 100 MB array and modify each page of the array
– mempass:Allocates a single 100MB array on one of the clones, touches each buffer page and passes it to the next core which repeats the process
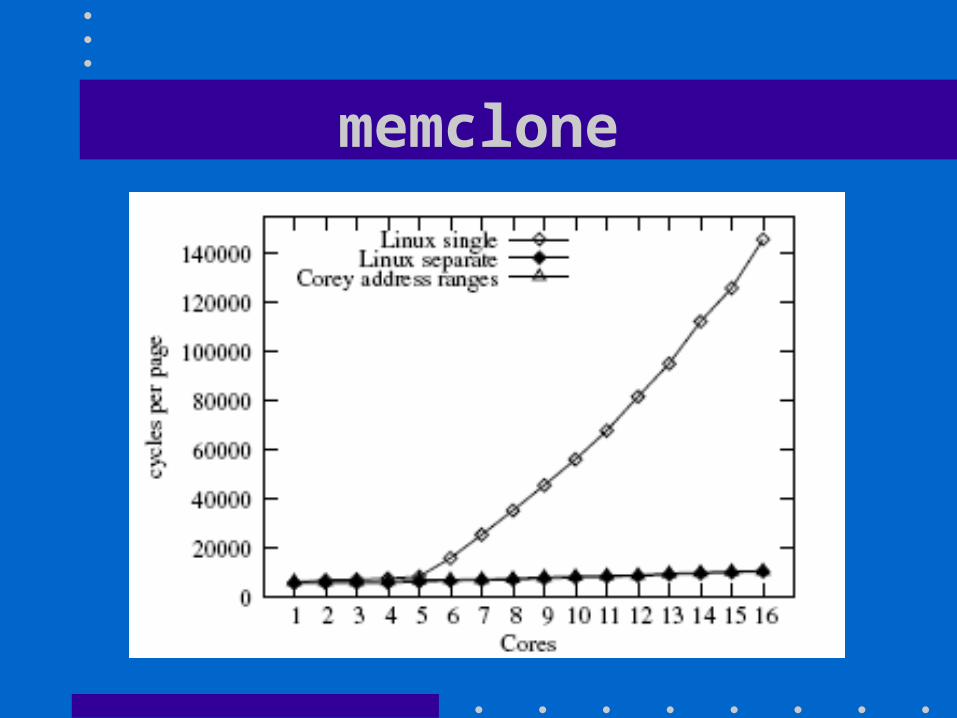
memclone

mempass

Evaluation of address ranges (II)
• Address ranges can support as well– Multicore applications requiring private
memory– Multicore applications requiring shared
memory

Evaluation of kernel cores (I)
• Simple TCP service– Accepts incoming connection requests– Writes 128 bytes to the connection then closes
it• Two configurations
– “Dedicated” uses a kernel core for all network processing
– “Polling” uses a kernel core only to poll for packet notifications and transmit completions

Throughput

L3 cache misses

Evaluation of kernel cores (II)
• “Dedicated” configuration– Reaches network device upper bound of
110,000 connections per second with five cores• Polling requires 11 cores
– Occasions much fewer L3 misses than “Polling” and regular Linux

Evaluation of shares (I)
• Two microbenchmarks– Each core calls share_addobj()to add
a per core segment to a global share then calls share_delobj()to delete that segment
– Same but per core segment is added to a local share

Throughput

L3 cache misses

More benchmarks
• Both MapReduce and Webd scale up much better with Corey than with Linux

CONCLUSIONS
• In order for applications to scale up on multicore architectures, they must control sharing
Since this new requirement greatly complicates the design of applications, it is best suited to application frameworks such as MapReduce