course 395: machine learning - lectures...stefanos zafeiriou machine learning (395) neural networks...
TRANSCRIPT

Stefanos Zafeiriou Machine Learning (395)
Course 395: Machine Learning - Lectures • Lecture 1-2: Concept Learning (M. Pantic)
• Lecture 3-4: Decision Trees & CBC Intro (M. Pantic)
• Lecture 5-6: Artificial Neural Networks (S.Zafeiriou)
• Lecture 7-8: Instance Based Learning (M. Pantic)
• Lecture 9-10: Genetic Algorithms (M. Pantic)
• Lecture 11-12: Evaluating Hypotheses (THs)
• Lecture 13-14: Bayesian Learning (S. Zafeiriou)
• Lecture 15-16: Dynamic Bayesian Networks (S. Zafeiriou)
• Lecture 17-18: Inductive Logic Programming (S. Muggleton)

Stefanos Zafeiriou Machine Learning (395)
Neural Networks
Neural Networks
The Perceptron (1958)
Multilayer Neural Networks (50’s, 60’s)
Reading:
•Machine Learning (Tom Mitchel) Chapter 4
•Pattern Recognition and Machine Learning by Christopher M.
Bishop, Springer, 2006 (chapter: 5)
Further Reading: •Neural Networks (Haykin)
•Neural Networks for Pattern Recognition (Chris M. Bishop)

Stefanos Zafeiriou Machine Learning (395)
What are Neural Networks?
The real thing! 10 billion neurons
Local computations on interconnected elements (neurons)
Parallel computation • neuron switch time 0.001sec • recognition tasks performed in 0.1 sec.

Stefanos Zafeiriou Machine Learning (395)
Biological Neural Networks
A network of interconnected biological neurons.
Connections per neuron 104 - 105

Stefanos Zafeiriou Machine Learning (395)
Biological vs Artificial Neural Networks

Stefanos Zafeiriou Machine Learning (395)
Architecture
How are the neurons connected
The Neuron
How information is processed in each unit. output = f(input)
Learning algorithms
How a Neural Network modifies its weights in order to solve a
particular learning task in a set of training examples
The goal is to have a Neural Network that generalizes well, that is, that
it generates a ‘correct’ output on a set of test/new examples/inputs.
Artificial Neural Networks: the dimensions

Stefanos Zafeiriou Machine Learning (395)
What are Neural Networks
The Perceptron
Multilayer Neural Networks
Neural Networks

Stefanos Zafeiriou Machine Learning (395)
Neural Networks
What are Neural Networks
The Perceptron
The architecture
The neuron
The learning algorithm
Multilayer Neural Networks
Neural Networks

Stefanos Zafeiriou Machine Learning (395)
• Perceptron was invented by Rosenblatt
• Principles of Neurodynamics, 1961
Perceptron: Introduction

Stefanos Zafeiriou Machine Learning (395)
• Marvin Minsky • Seymour Papert
• A famous book was published in 1969: Perceptrons
• Caused a significant decline in interest and funding of neural network research
Perceptron: Introduction

Stefanos Zafeiriou Machine Learning (395)
• We consider the architecture: feed-forward NN with one layer
• It is sufficient to study single layer perceptrons with just one neuron:
Perceptron: Architecture
I
n
p
u
t
s
Output

Stefanos Zafeiriou Machine Learning (395)
• Generalization to single layer perceptrons with more neurons is
easy because:
• The output units are mutually independent
• Each weight only affects one of the outputs
Perceptron: Architecture

Stefanos Zafeiriou Machine Learning (395)
• The (McCulloch-Pitts) perceptron is a single layer NN with a
non-linear activation function , the step function
(bias)
Perceptron: The neuron

Stefanos Zafeiriou Machine Learning (395)
Activation functions

Stefanos Zafeiriou Machine Learning (395)
• Given training examples of classes , train the perceptron
in such a way that it classifies correctly the training examples:
– If the output of the perceptron is 1 then the input is
assigned to class (i.e. if )
– If the output is 0 then the input is assigned to class
• Geometrically, we try to find a hyper-plane that separates the
examples of the two classes. The hyper-plane is defined by the
linear function
Perceptron for classification

Stefanos Zafeiriou Machine Learning (395)
Perceptron: Geometric view
(Note that q = w0)

Stefanos Zafeiriou Machine Learning (395)
, ..., , ...,
if
• A sequence examples and of labels (1,-1)
• The perceptron algorithm
• Initialise
• For k=1,..,n
end
Perceptron: First Learning Rule

Stefanos Zafeiriou Machine Learning (395)
Distance from the point
and the hyperplane
• Our data have bounded Euclidean norms, i.e.
• We assume that the data are linearly separable, i.e.
• Convergence Proof: Assumptions
Geometric margin
Perceptron: Proof of Convergence

Stefanos Zafeiriou Machine Learning (395)
Proof comprises three steps
• The inner product increases linearly with each
update
• The squared norm increases at most linearly in the
number of updates
•By combining the two => the cosine of the angle between
and has to increase by a finite increment due to each
update.
Perceptron: Proof of Convergence

Stefanos Zafeiriou Machine Learning (395)
In mathematical terms, we show that after k updates (mistakes):
1.
2.
3.
Perceptron: Proof of Convergence

Stefanos Zafeiriou Machine Learning (395)
1.
Let the k-th mistake be on the i-th sample
Perceptron: Convergence

Stefanos Zafeiriou Machine Learning (395)
2.
Perceptron: Convergence

Stefanos Zafeiriou Machine Learning (395)
or
•The result does not depend (directly) on the dimension d of
the examples, nor the number of training examples n.
• A bound on the number of mistakes
Perceptron: Convergence

Stefanos Zafeiriou Machine Learning (395)
• Drawback: The data should be linearly separable
Perceptron: Gradient Descent Learning rule

Stefanos Zafeiriou Machine Learning (395)
• Remedy: Minimise an error function for learning the
weights
• Error function:
• Vector of training outputs:
• Vector of networks outputs:
Perceptron: Gradient Descent Learning rule

Stefanos Zafeiriou Machine Learning (395)
Perceptron: Gradient Descent Learning rule
• Remember that during training we present the NN with pairs
( , ), p = 1,…P
• Make small adjustments to the weights that reduce the
difference between the actual and the desired outputs of the
perceptron. Choose the initial weights randomly and then
update so that for each training example we obtain
output that is similar to the desirable output for the
example in question.
•Choose a policy for reducing the error:

Stefanos Zafeiriou Machine Learning (395)
• To understand consider a linear activation function
• Task: Learn wi that minimises the sum of the squared errors
where P is the number of training examples
Perceptron: Gradient Descent Learning rule
• A general, effective way for estimating parameters (e.g. )
that minimise error functions

Stefanos Zafeiriou Machine Learning (395)
Gradient descent method: take a step in the direction
that decreases the error E. This direction is the opposite
of the gradient of E.
Gradient direction E
Can be shown that
Perceptron: Gradient Descent Learning rule

Stefanos Zafeiriou Machine Learning (395)
•
•
Perceptron: Gradient Descent Learning rule

Stefanos Zafeiriou Machine Learning (395)
Initialize w with small random values;
while (a termination condition is not met)
• Initialise Dwi to zero
• For p = 1:P
– Select a training example
– Calculate
– Set
– Update weights
• end-while;
Perceptron: Gradient Descent Learning rule

Stefanos Zafeiriou Machine Learning (395)
Perceptron: The limits of perceptron
• The XOR is not linearly separable.
• This was a terrible blow to the field

Stefanos Zafeiriou Machine Learning (395)
Neural Networks
What are Neural Networks
The Perceptron
Multilayer Neural Networks
Neural Networks

Stefanos Zafeiriou Machine Learning (395)
Neural Networks
What are Neural Networks
The Perceptron
Multilayer Neural Networks
The architecture
The neuron
The learning algorithm
Neural Networks

Stefanos Zafeiriou Machine Learning (395)
Input
layer
Output
layer
Hidden Layer
We consider a more general network architecture: between the input and output
layers there are hidden layers, as illustrated below.
Hidden nodes do not directly receive inputs nor send outputs to the external
environment.
FFNNs overcome the limitation of single-layer NN: they can handle non-linearly
separable learning tasks.
Multilayer Feed Forward Neural Network
Stefanos Zafeiriou Machine Learning (395)
1
0 1
x2
x1 x1
x2
-0.5
+1
+1 +1
+1 -1
-1
-0.5
0.1
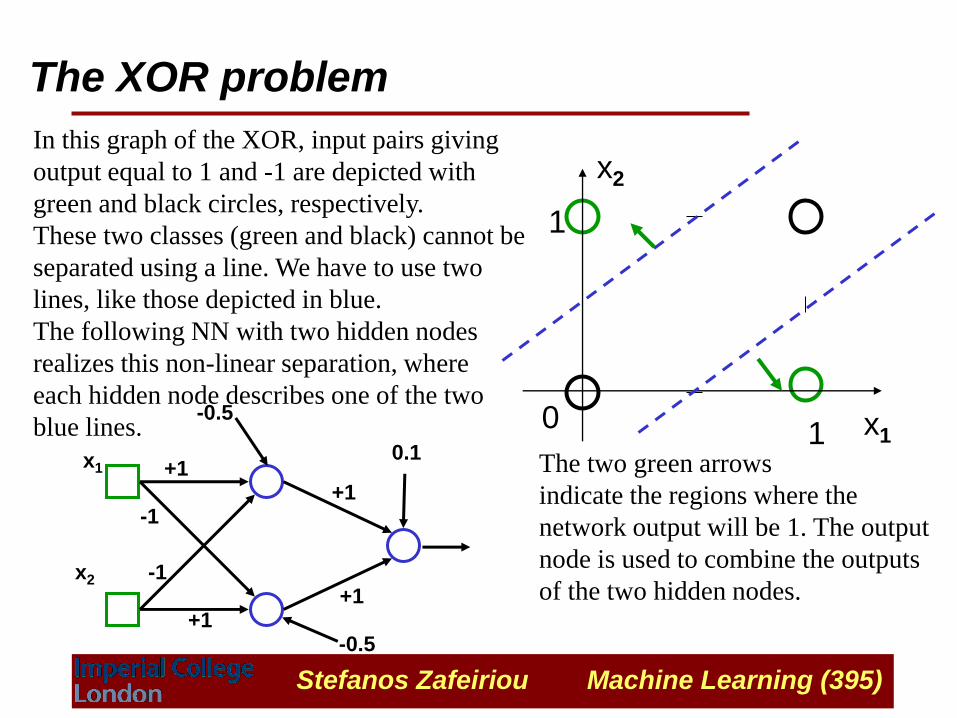
In this graph of the XOR, input pairs giving
output equal to 1 and -1 are depicted with
green and black circles, respectively.
These two classes (green and black) cannot be
separated using a line. We have to use two
lines, like those depicted in blue.
The following NN with two hidden nodes
realizes this non-linear separation, where
each hidden node describes one of the two
blue lines.
The two green arrows
indicate the regions where the
network output will be 1. The output
node is used to combine the outputs
of the two hidden nodes.
The XOR problem

Stefanos Zafeiriou Machine Learning (395)
022110 xwxww
022110 xwxwwx1
1
x2 w2
w1
w0
Convex
region
L1 L2
L3 L4 -3.5
Network
with a single
node
One-hidden layer network that
realizes the convex region: each
hidden node realizes one of the
lines bounding the convex region
P1 P2
P3
1
1
1
1
1
x1
x2
1
1.5
two-hidden layer network that
realizes the union of three convex
regions: each box represents a one
hidden layer network realizing
one convex region
1
1
1
1
x1
x2
1
Decision boundaries

Stefanos Zafeiriou Machine Learning (395)
• A continuous approximation of the step (threshold)
function is the Sigmoid Function. The activation function for node j is:
• where
• weigh of link between i and j node
and output of node i
• Nice property: -10 -8 -6 -4 -2 2 4 6 8 10
1
Increasing
Neuron: Sigmoid activation function

Stefanos Zafeiriou Machine Learning (395)
Decision boundaries (sigmoid function)
F1
F2
would
hood
.
.
.

Stefanos Zafeiriou Machine Learning (395)
• The Backprop algorithm searches for weight values that
minimize the total squared error of the network over the set
of P training examples (training set).
• Use gradient descent algorithm
Input
layer
Output
layer
Learning: The backpropagation algorithm

Stefanos Zafeiriou Machine Learning (395)
• Backpropagation consists of the repeated application of the
following two passes:
– Forward pass: in this step the network is activated on
one example and the error of (each neuron of) the output
layer is computed.
– Backward pass: in this step the network error is used for
updating the weights (credit assignment problem). This
process is complex because hidden nodes are linked to
the error not directly but by means of the nodes of the
next layer. Therefore, starting at the output layer, the
error is propagated backwards through the network, layer
by layer.
Learning: The backpropagation algorithm

Stefanos Zafeiriou Machine Learning (395)
Multilayer Feed Forward NN
i j k

Stefanos Zafeiriou Machine Learning (395)
• First Case: the weights of the outmost layer.
Backpropagation: Gradient Descent

Stefanos Zafeiriou Machine Learning (395)
• Chain rules
•
•
Backpropagation: Gradient Descent

Stefanos Zafeiriou Machine Learning (395)
•
•
•
Backpropagation: Gradient Descent

Stefanos Zafeiriou Machine Learning (395)
• Since
• Hence, from chain rule
• The update is
Backpropagation: Gradient Descent

Stefanos Zafeiriou Machine Learning (395)
•
•
• First Case: the weights of the inner layers.
Backpropagation: Gradient Descent

Stefanos Zafeiriou Machine Learning (395)
•
•
Backpropagation: Gradient Descent

Stefanos Zafeiriou Machine Learning (395)
Forward activation step
• Activate the Feed Forward Neural Network by applying
the inputs ,…,
and desired outputs ,…,
• A) Calculate the activation at the hidden layer
B) Calculate the activation at the output layer
where j are indexes to neurons at the hidden layer
and k are indexes to neurons at the output layer

Stefanos Zafeiriou Machine Learning (395)
Update the weights in the network by backpropagating the
errors associated to the output neurons
A) Calculate the error term at the neurons at the output layer.
At neuron m:
B) Calculate the error gradient at the m-th neurons at the
hidden layer (backpropagating the errors associated to the
output neurons)
Backpropagation step

Stefanos Zafeiriou Machine Learning (395)
Backpropagation step (continued)
4. Update the weights in the network.
Summary:
• Initialization of the weights to small values
• While (some stopping criterion is not met)
• Choose a training example
• Apply the Forward Activation step (ie find the activation
of the network)
• Apply the Backward Error propagation step (i.e. adjust
the weights)
• End-while

Stefanos Zafeiriou Machine Learning (395)
Backpropagation: Convergence
• Converges to a local minimum of the error function
• … can be retrained a number of times
• Minimises the error over the training examples
• …will it generalise well over unknown examples?
• Training requires thousands of iterations (slow)
• … but once trained it can rapidly evaluate output

Stefanos Zafeiriou Machine Learning (395)
Backpropagation: Convergence
• Error might decrease in the training set but increase in the
‘validation’ set (overfitting!)
• Stop when the error in the validation set increases (but
not too soon!)

Stefanos Zafeiriou Machine Learning (395)
Automated driving at 70 mph on a public highway
Camera image
30x32 pixels as inputs
30 outputs for steering 30x32 weights
into one out of four hidden unit
4 hidden units
ALVINN

Stefanos Zafeiriou Machine Learning (395)
Neural Networks
Reading:
•Machine Learning (Tom Mitchel) Chapter 4
•Pattern Recognition and Machine Learning by Christopher M.
Bishop, Springer, 2006 (chapter: 5)
Further Reading: •Neural Networks (Haykin)
•Neural Networks for Pattern Recognition (Chris M. Bishop)

Stefanos Zafeiriou Machine Learning (395)
• Lecture 1-2: Concept Learning (M. Pantic)
• Lecture 3-4: Decision Trees & CBC Intro (M. Pantic)
• Lecture 5-6: Artificial Neural Networks (S.Zafeiriou)
• Lecture 7-8: Instance Based Learning (M. Pantic)
• Lecture 9-10: Genetic Algorithms (M. Pantic)
• Lecture 11-12: Evaluating Hypotheses (THs)
• Lecture 13-14: Bayesian Learning (S. Zafeiriou)
• Lecture 15-16: Dynamic Bayesian Networks (S. Zafeiriou)
• Lecture 17-18: Inductive Logic Programming (S. Muggleton)
Course 395: Machine Learning - Lectures