course outline introduction in algorithms and applications introduction in algorithms and...
TRANSCRIPT

Course Outline
Introduction in algorithms and applicationsIntroduction in algorithms and applications
Parallel machines and architecturesParallel machines and architectures
Overview of parallel machinesOverview of parallel machines
Cluster computers (Myrinet), BlueGeneCluster computers (Myrinet), BlueGene
Programming methods, languages, and environmentsProgramming methods, languages, and environments
Message passing (SR, MPI, Java)Message passing (SR, MPI, Java)
Higher-level languages: Linda, HPFHigher-level languages: Linda, HPF
ApplicationsApplications
N-body problems, search algorithmsN-body problems, search algorithms
Grid computingGrid computing

Approaches to Parallel Programming
Sequential language + librarySequential language + libraryMPI, PVMMPI, PVM
Extend sequential languageExtend sequential languageC/Linda, Concurrent C++C/Linda, Concurrent C++
New languages designed for parallel or distributed New languages designed for parallel or distributed programmingprogrammingSR, occam, Ada, OrcaSR, occam, Ada, Orca

Paradigms for Parallel Programming
Processes + shared variablesProcesses + shared variables
Processes + message passingProcesses + message passing
Concurrent object-oriented languagesConcurrent object-oriented languages
Concurrent functional languagesConcurrent functional languages
Concurrent logic languagesConcurrent logic languages
Data-parallelism (SPMD model)Data-parallelism (SPMD model)
Advanced communication modelsAdvanced communication models
--
SR and MPISR and MPI
JavaJava
- -
--
HPFHPF
LindaLinda

Interprocess Communicationand Synchronization based on
Message Passing

Overview
Message passingMessage passingGeneral issuesGeneral issues
Examples: rendezvous, Remote Procedure Calls, BroadcastExamples: rendezvous, Remote Procedure Calls, Broadcast
NondeterminismNondeterminismSelect statementSelect statement
Example language: SR (Synchronizing Resources)Example language: SR (Synchronizing Resources)Traveling Salesman Problem in SRTraveling Salesman Problem in SR
Example library: MPI (Message Passing Interface)Example library: MPI (Message Passing Interface)

Point-to-point Message Passing
Basic primitives: send & receiveBasic primitives: send & receiveAs library routines:As library routines:
send(destination, & MsgBuffer)send(destination, & MsgBuffer)
receive(source, &MsgBuffer)receive(source, &MsgBuffer)
As language constructsAs language constructs
send MsgName(arguments) to destinationsend MsgName(arguments) to destination
receive MsgName(arguments) from sourcereceive MsgName(arguments) from source

Issues in Message Passing
Naming the sender and receiverNaming the sender and receiverExplicit or implicit receipt of messagesExplicit or implicit receipt of messagesSynchronous versus asynchronous messagesSynchronous versus asynchronous messages

Direct naming
Sender and receiver directly name each otherSender and receiver directly name each otherS: S: sendsend M M toto R RR: R: receivereceive M M fromfrom S S
Asymmetric direct naming (more flexible):Asymmetric direct naming (more flexible):S: S: sendsend M M toto R RR: R: receivereceive M M
Direct naming is easy to implementDirect naming is easy to implementDestination of message is know in advanceDestination of message is know in advanceImplementation just maps logical names to machine addressesImplementation just maps logical names to machine addresses

Indirect naming
Indirect naming uses extra indirection levelIndirect naming uses extra indirection levelR: send M to P -- P is a port nameR: send M to P -- P is a port nameS: receive M from PS: receive M from P
Sender and receiver need not know each otherSender and receiver need not know each otherPort names can be moved around (e.g., in a message)Port names can be moved around (e.g., in a message)send ReplyPort(P) to U -- P is name of reply portsend ReplyPort(P) to U -- P is name of reply port
Most languages allow only a single process at a time to Most languages allow only a single process at a time to receive from any given portreceive from any given portSome languages allow multiple receivers that service Some languages allow multiple receivers that service messages on demand -> called a mailboxmessages on demand -> called a mailbox
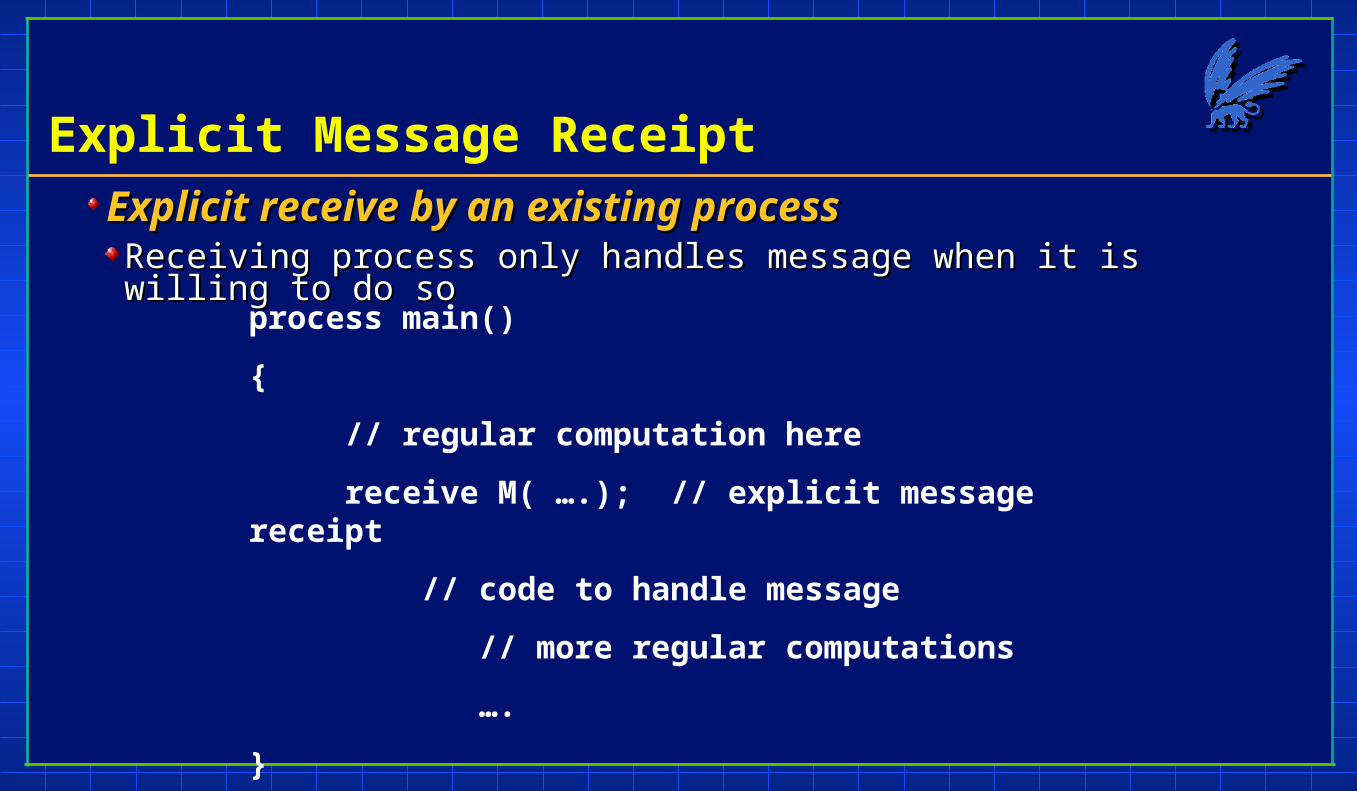
Explicit Message Receipt
Explicit receive by an existing processExplicit receive by an existing processReceiving process only handles message when it is willing to do soReceiving process only handles message when it is willing to do so
process main()
{
// regular computation here
receive M( ….); // explicit message receipt
// code to handle message
// more regular computations
….
}
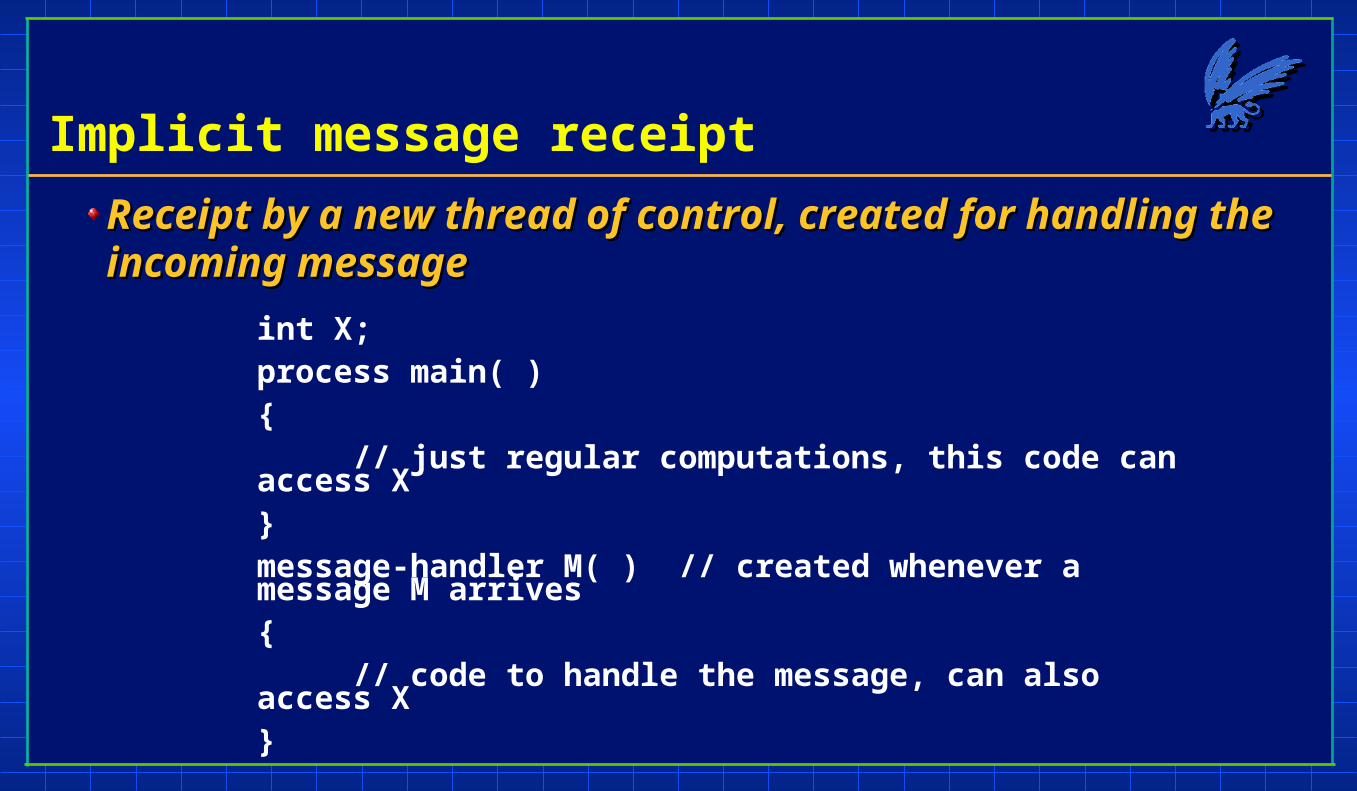
Implicit message receipt
Receipt by a new thread of control, created for handling the Receipt by a new thread of control, created for handling the incoming messageincoming message
int X;process main( ){
// just regular computations, this code can access X}message-handler M( ) // created whenever a message M arrives{
// code to handle the message, can also access X}
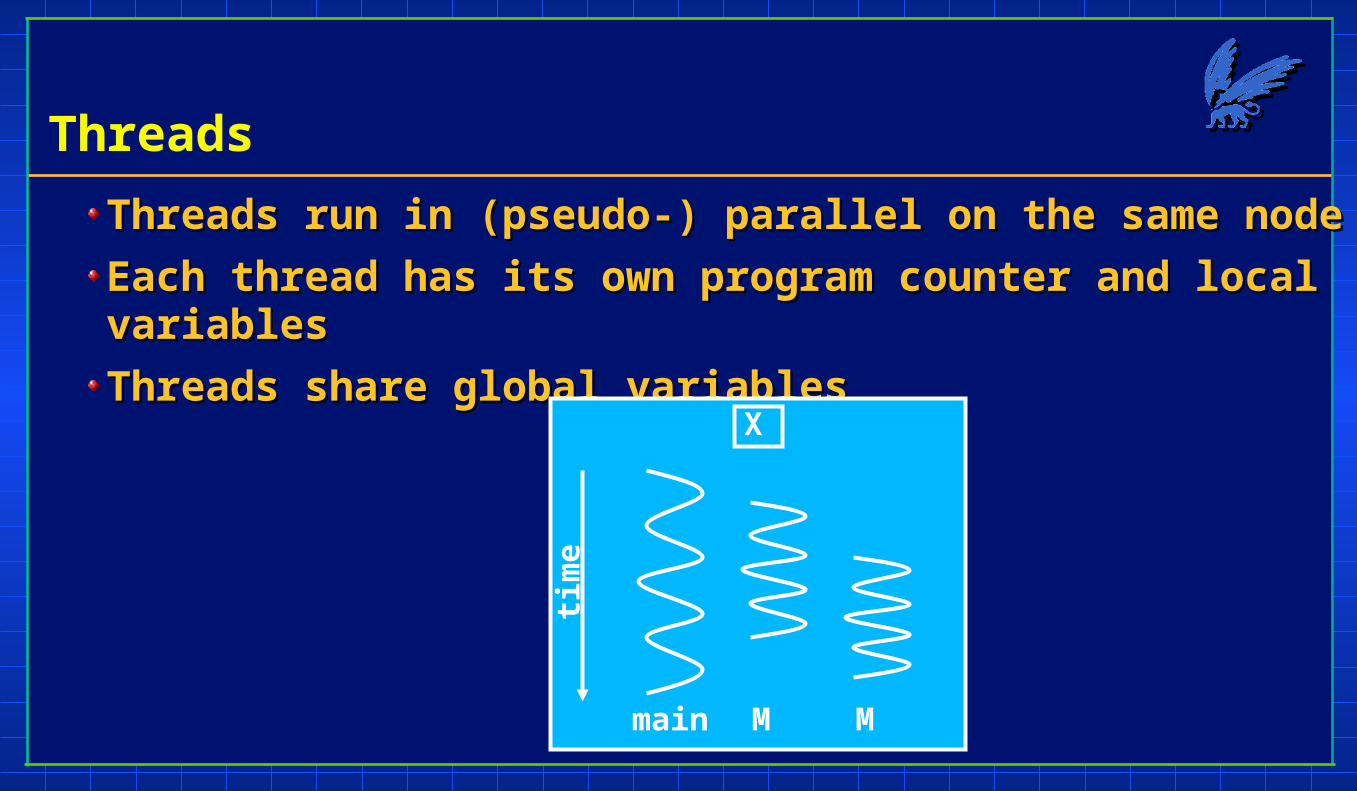
Threads
Threads run in (pseudo-) parallel on the same nodeThreads run in (pseudo-) parallel on the same node
Each thread has its own program counter and local variablesEach thread has its own program counter and local variables
Threads share global variablesThreads share global variables
main M M
X
tim
e

Differences (1)
Implicit receipt is used if it’s unknown when a message will Implicit receipt is used if it’s unknown when a message will arrive; example: request for remote dataarrive; example: request for remote data
int X;process main( ){
// regular computations}int message-handler readX( S){
send valueX(X) to S}
process main(){
int X;while (true) {
if (there is a message readX) {receive readX(S); send valueX(X) to S
}// regular computations
} }

Differences (2)
Explicit receive gives more control over when to accept Explicit receive gives more control over when to accept which messages; e.g., SR allows:which messages; e.g., SR allows:receive ReadFile(file, offset, NrBytes) by NrBytesreceive ReadFile(file, offset, NrBytes) by NrBytes
// sorts messages by (increasing) 3rd parameter, i.e. small reads go first// sorts messages by (increasing) 3rd parameter, i.e. small reads go first
MPI has explicit receive (+ polling for implicit receive)MPI has explicit receive (+ polling for implicit receive)
Java has implicit receive: Remote Method Invocation (RMI)Java has implicit receive: Remote Method Invocation (RMI)
SR has bothSR has both

Synchronous vs. asynchronous Message Passing
Synchronous message passing:Synchronous message passing:Sender is blocked until receiver has accepted the messageSender is blocked until receiver has accepted the message
Too restrictive for many parallel applicationsToo restrictive for many parallel applications
Asynchronous message passing:Asynchronous message passing:Sender continues immediatelySender continues immediately
More efficientMore efficient
Ordering problemsOrdering problems
Buffering problemsBuffering problems

Ordering with asynchronous message passingOrdering with asynchronous message passing
SENDER:SENDER: RECEIVER: RECEIVER:
send message(1)send message(1) receive message(N); print Nreceive message(N); print N
send message(2)send message(2) receive message(M); print Mreceive message(M); print M
Messages may be received in any order, depending on the Messages may be received in any order, depending on the protocolprotocol
Message ordering
message(1)
message(2)

Example: AT&T crash
P2P1
Are you still alive?
P2P1P1 crashes P1 is dead
P2P1
I’m back
Regular messageSomething’s wrong,I’d better crash!
P2P1P2 is dead

Message buffering
Keep messages in a buffer until the receive( ) is doneKeep messages in a buffer until the receive( ) is done
What if the buffer overflows?What if the buffer overflows?Continue, but delete some messages (e.g., oldest one), orContinue, but delete some messages (e.g., oldest one), or
Use flow control: block the sender temporarilyUse flow control: block the sender temporarily
Flow control changes the semantics since it introduces Flow control changes the semantics since it introduces synchronizationsynchronizationS: send zillion messages to R; receive messagesS: send zillion messages to R; receive messages
R: send zillion messages to S; receive messagesR: send zillion messages to S; receive messages
-> deadlock!-> deadlock!

Example communication primitives
Rendezvous (Ada)Rendezvous (Ada)
Remote Procedure Call (RPC)Remote Procedure Call (RPC)
BroadcastBroadcast

Rendezvous (Ada)
Two-way interactionTwo-way interactionSynchronous (blocking) sendSynchronous (blocking) send
Explicit receiveExplicit receive
Output parameters sent back to callerOutput parameters sent back to caller
Entry = procedure implemented by a task that can be called Entry = procedure implemented by a task that can be called remotelyremotely
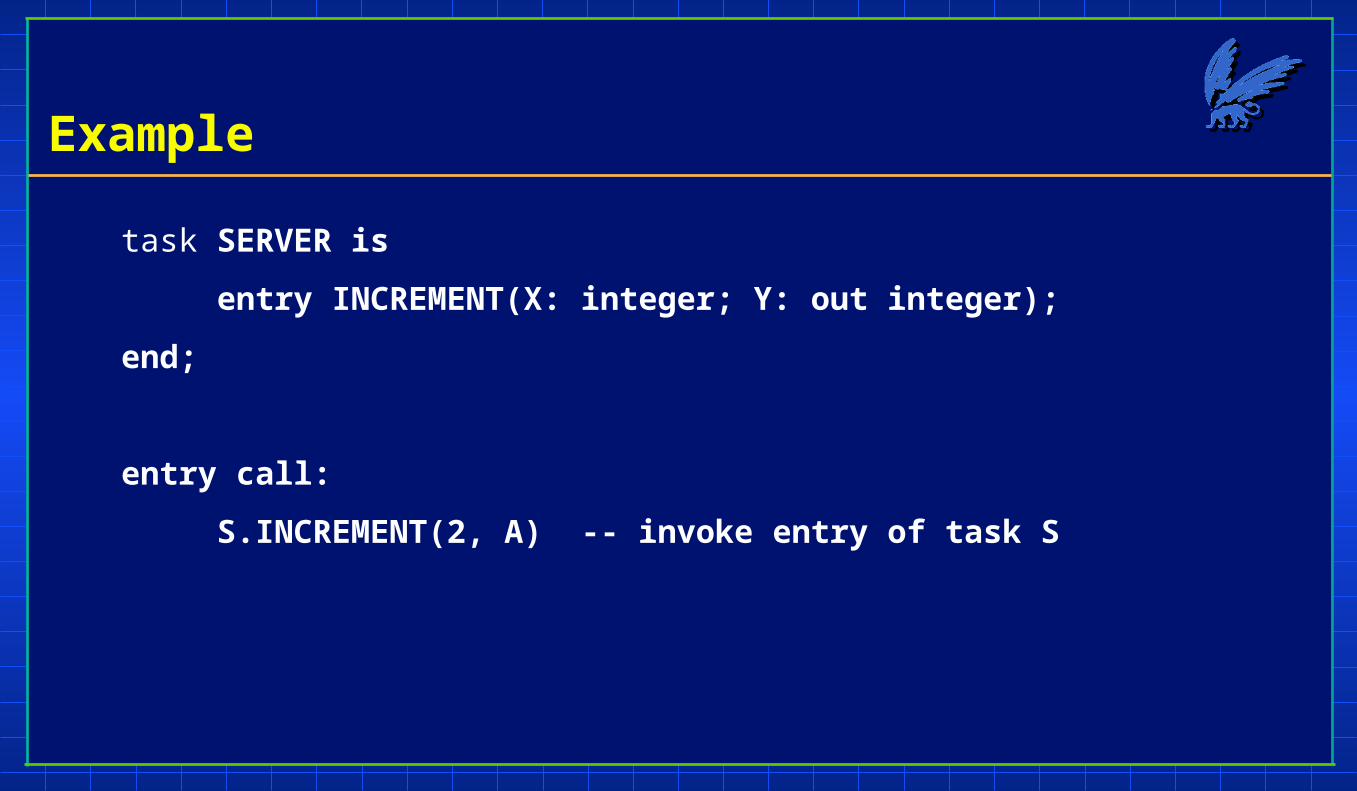
Example
task SERVER is
entry INCREMENT(X: integer; Y: out integer);
end;
entry call:
S.INCREMENT(2, A) -- invoke entry of task S

Accept statementtask body SERVER is
begin
accept INCREMENT(X: integer; Y: out integer) do
Y := X + 1; -- handle entry call
end;
…...
end;
Entry call is fully synchronousEntry call is fully synchronousInvoker waits until server is ready to acceptInvoker waits until server is ready to accept
Accept statement waits for entry callAccept statement waits for entry call
Caller proceeds after accept statement has been executedCaller proceeds after accept statement has been executed

Remote Procedure Call (RPC)
Similar to traditional procedure callSimilar to traditional procedure call
Caller and receiver are different processesCaller and receiver are different processesPossibly on different machinesPossibly on different machines
Fully synchronousFully synchronousSender waits for RPC to completeSender waits for RPC to complete
Implicit message receiptImplicit message receiptNew thread of control within receiverNew thread of control within receiver

Broadcast
Many networks (e.g., Ethernet) support:Many networks (e.g., Ethernet) support:broadcast: send message to all machinesbroadcast: send message to all machines
multicast: send messages to a set of machinesmulticast: send messages to a set of machines
Hardware multicast is very efficientHardware multicast is very efficientEthernet: same delay as for a unicastEthernet: same delay as for a unicast
Multicast can be made reliable using software protocolsMulticast can be made reliable using software protocols

Nondeterminism
Interactions may depend on run-time conditionsInteractions may depend on run-time conditionse.g.: wait for a message from either A or B, whichever comes firste.g.: wait for a message from either A or B, whichever comes first
Need to express and control nondeterminismNeed to express and control nondeterminismspecify when to accept which messagespecify when to accept which message
Example (bounded buffer):Example (bounded buffer):do simultaneouslydo simultaneously
when buffer not full: accept request to store messagewhen buffer not full: accept request to store message
when buffer not empty: accept request to fetch messagewhen buffer not empty: accept request to fetch message

Select statement
several alternatives of the form:several alternatives of the form:WHEN condition => ACCEPT message DO statementWHEN condition => ACCEPT message DO statement
Each alternative mayEach alternative maysucceed, if condition=true & a message is availablesucceed, if condition=true & a message is available
fail, if condition=falsefail, if condition=false
suspend, if condition=true & no message available yetsuspend, if condition=true & no message available yet
Entire select statement mayEntire select statement maysucceed, if any alternative succeeds -> pick one nondeterministicallysucceed, if any alternative succeeds -> pick one nondeterministically
fail, if all alternatives failfail, if all alternatives fail
suspend, if some alternatives suspend and none succeeds yetsuspend, if some alternatives suspend and none succeeds yet

Example: bounded buffer in Ada
selectwhen not FULL(BUFFER) =>
accept STORE_ITEM(X: INTEGER) do‘store X in buffer’
end;or
when not EMPTY(BUFFER) =>accept FETCH_ITEM(X: out INTEGER) do
X := ‘first item from buffer’end;
end select;

Synchronizing Resources (SR)
Developed at University of ArizonaDeveloped at University of Arizona
Goals of SR:Goals of SR:ExpressivenessExpressiveness
Many message passing primitivesMany message passing primitives
Ease of useEase of use
Minimize number of underlying conceptsMinimize number of underlying concepts
Clean integration of language constructsClean integration of language constructs
EfficiencyEfficiency
Each primitive must be efficientEach primitive must be efficient

Overview of SR
Multiple forms of message passingMultiple forms of message passingAsynchronous message passingAsynchronous message passing
Rendezvous (explicit receipt)Rendezvous (explicit receipt)
Remote Procedure Call (implicit receipt)Remote Procedure Call (implicit receipt)
MulticastMulticast
Powerful receive-statementPowerful receive-statementConditional & ordered receive, based on contents of messageConditional & ordered receive, based on contents of message
Select statementSelect statement
Resource = module run on 1 node (uni/multiprocessor)Resource = module run on 1 node (uni/multiprocessor)Contains multiple threads that share variablesContains multiple threads that share variables

Orthogonality in SR
The send and receive primitives can be combined in all 4 The send and receive primitives can be combined in all 4 possible wayspossible ways
Asynchronous send Synchronous call
Explicitreceive
1.asynchronousmessage passing
3. rendezvous
Implicitreceive
2. fork 4. RPC
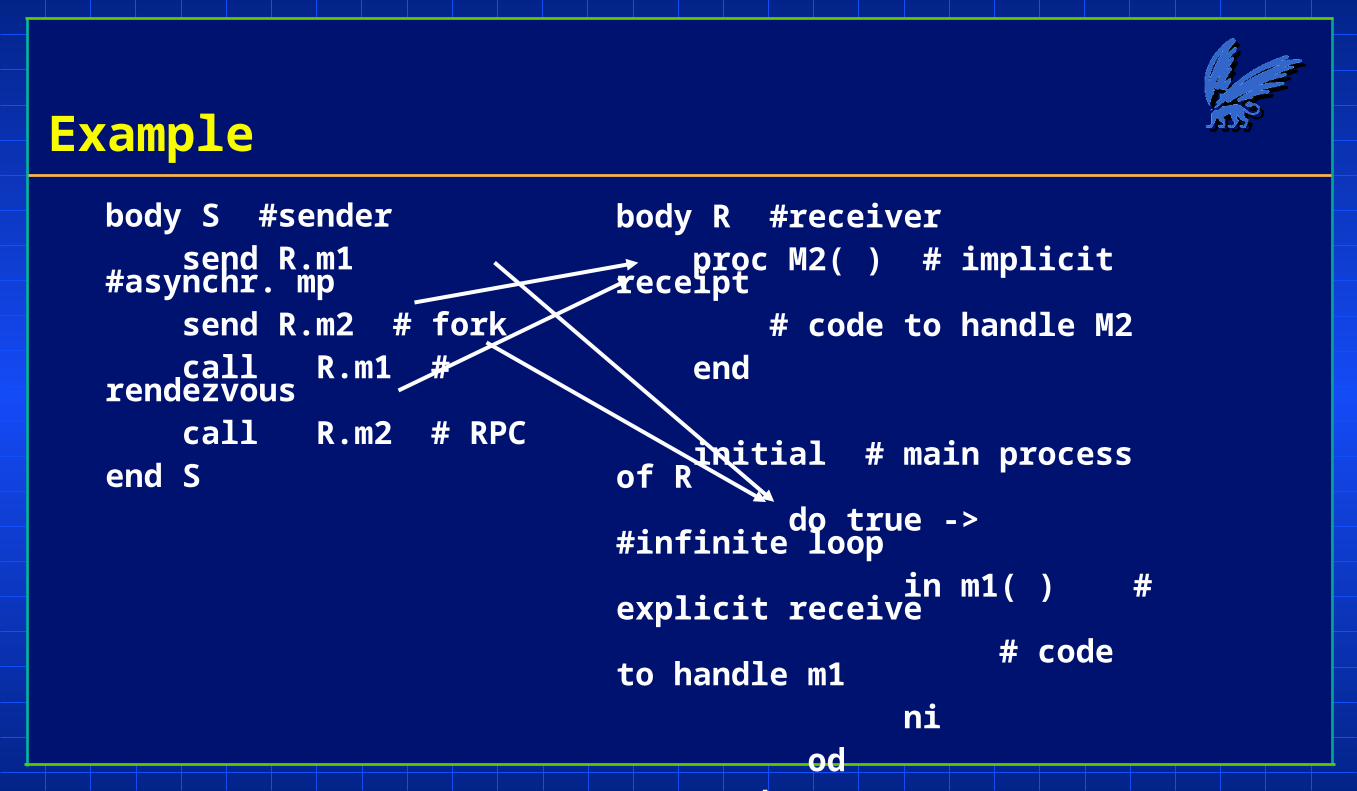
Example
body S #sender send R.m1 #asynchr. mp send R.m2 # fork call R.m1 # rendezvous call R.m2 # RPCend S
body R #receiver proc M2( ) # implicit receipt # code to handle M2 end
initial # main process of R do true -> #infinite loop in m1( ) # explicit receive # code to handle m1 ni od endend R
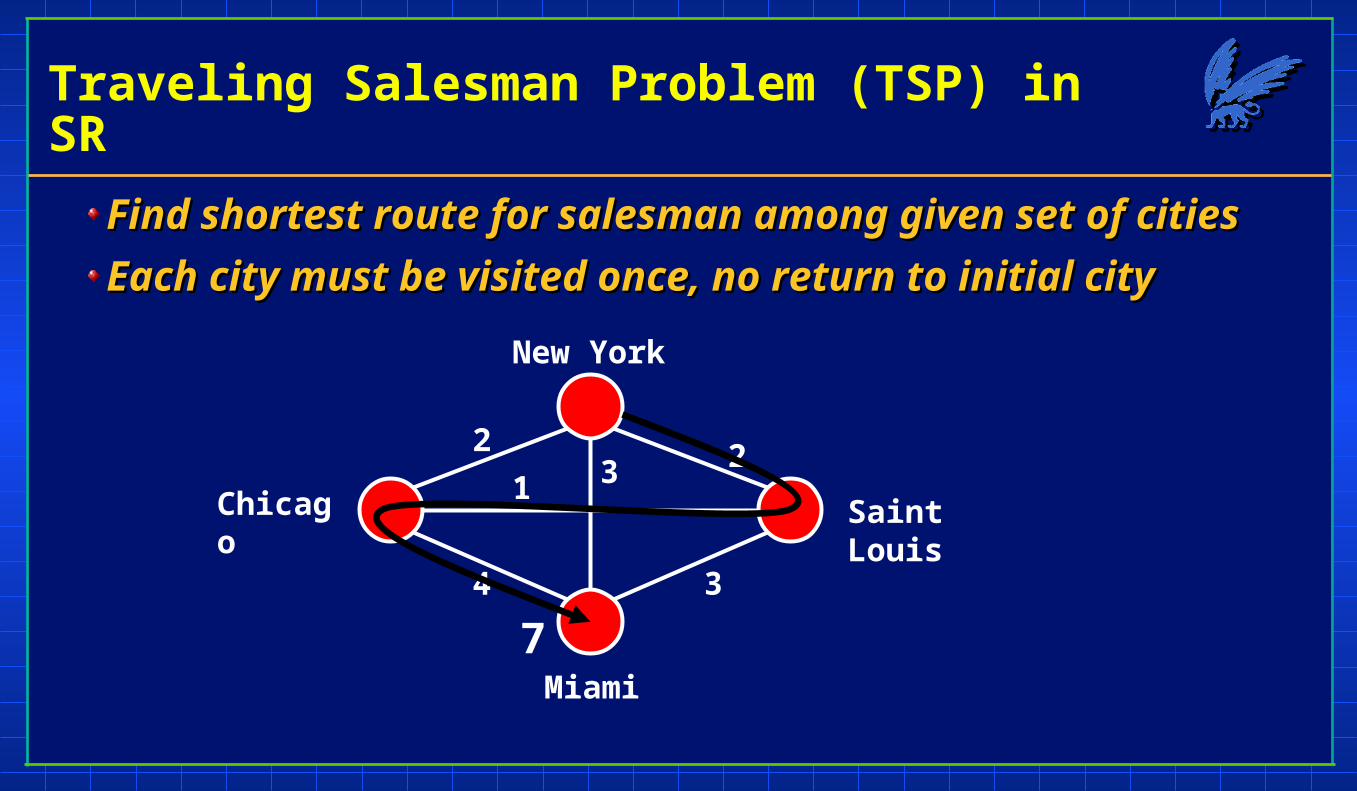
Traveling Salesman Problem (TSP) in SR
Find shortest route for salesman among given set of citiesFind shortest route for salesman among given set of cities
Each city must be visited once, no return to initial cityEach city must be visited once, no return to initial city
Saint Louis
Miami
Chicago
New York
2
4
3 21
3
7
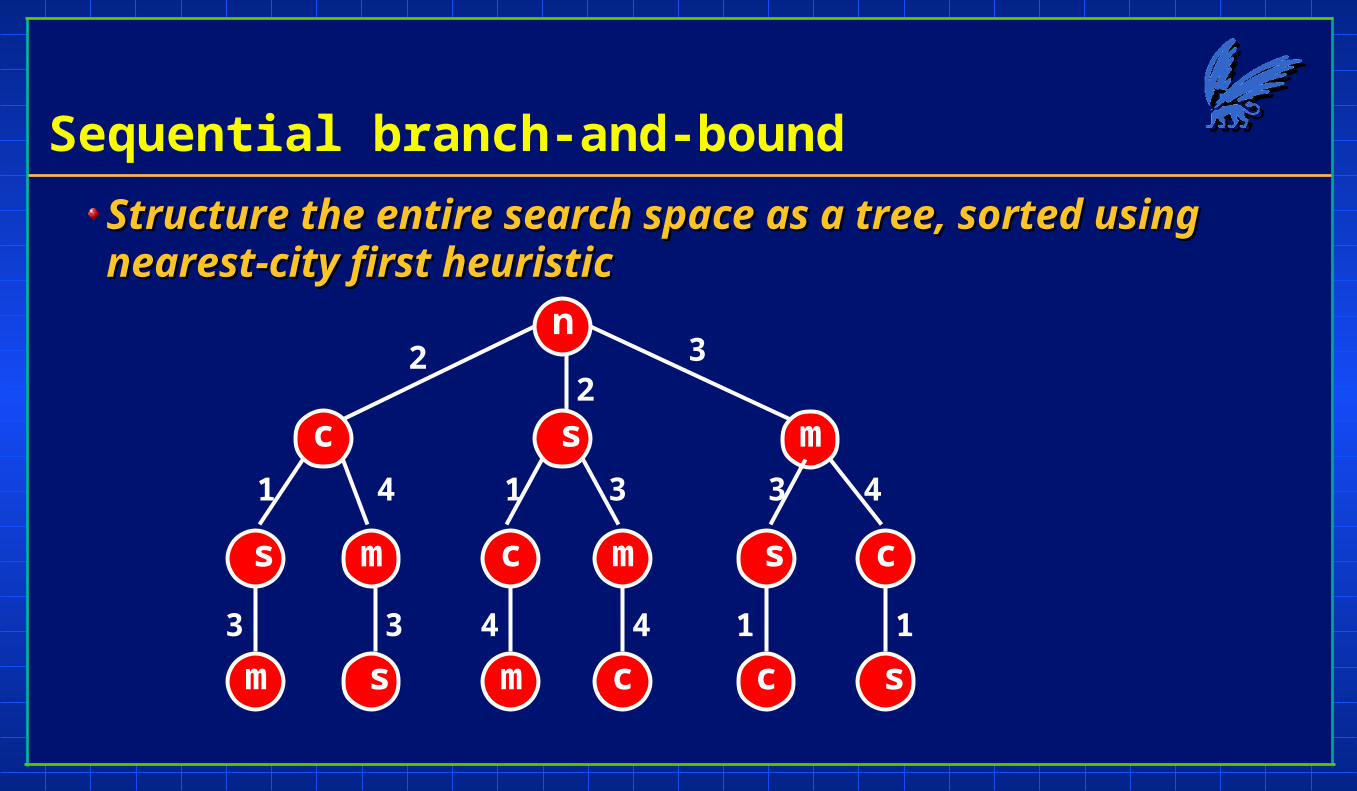
Sequential branch-and-bound
Structure the entire search space as a tree, sorted using Structure the entire search space as a tree, sorted using nearest-city first heuristicnearest-city first heuristic
n
csm
c s m
s m s cc
c
m
m s
22
3
33
3
4
3 44
4
1
1 1
1
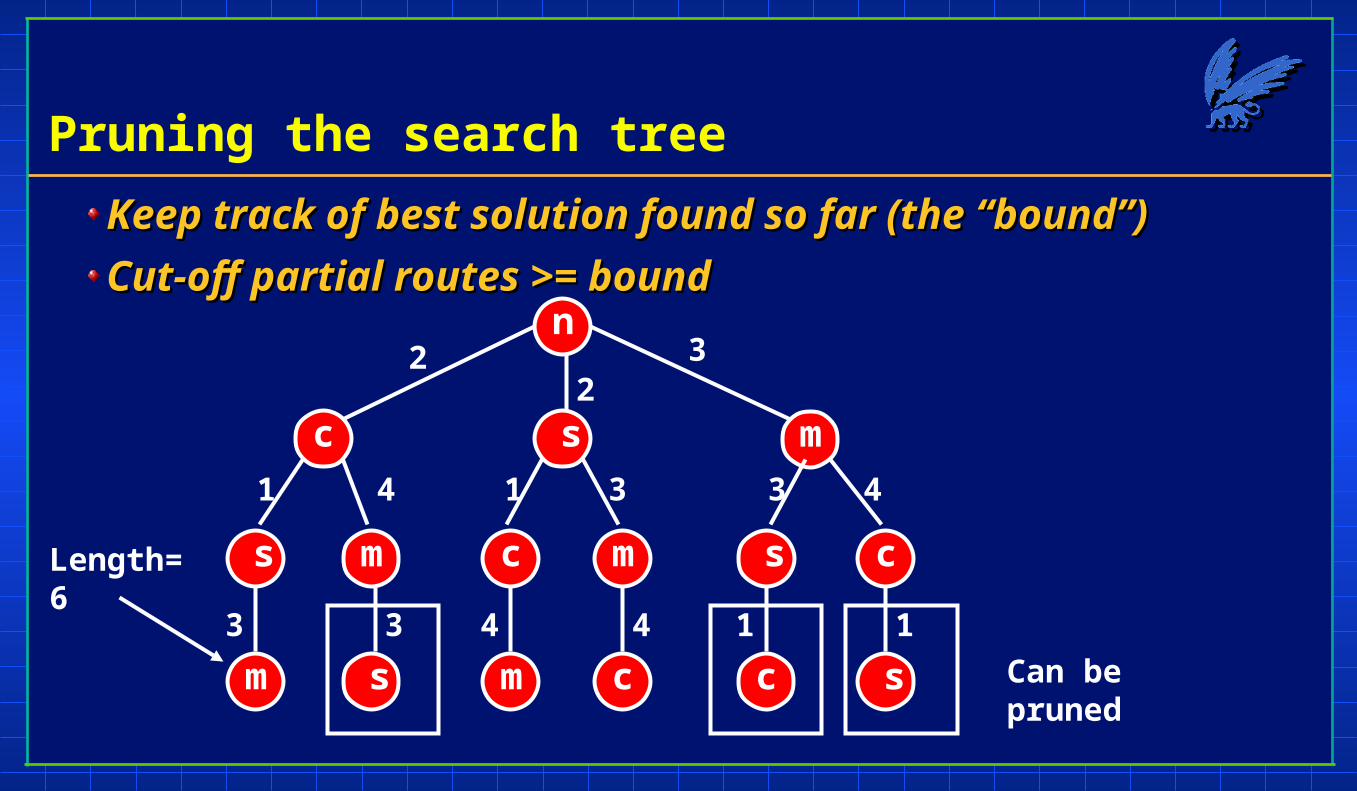
Pruning the search tree
Keep track of best solution found so far (the “bound”)Keep track of best solution found so far (the “bound”)
Cut-off partial routes >= boundCut-off partial routes >= boundn
csm
c s m
s m s cc
c
m
m s
22
3
33
3
4
3 44
4
1
1 1
1
Length=6
Can be pruned

Parallelizing TSP
Distribute the search tree over the CPUsDistribute the search tree over the CPUsCPUs analyze different routesCPUs analyze different routes
Results in reasonably large-grain jobsResults in reasonably large-grain jobs
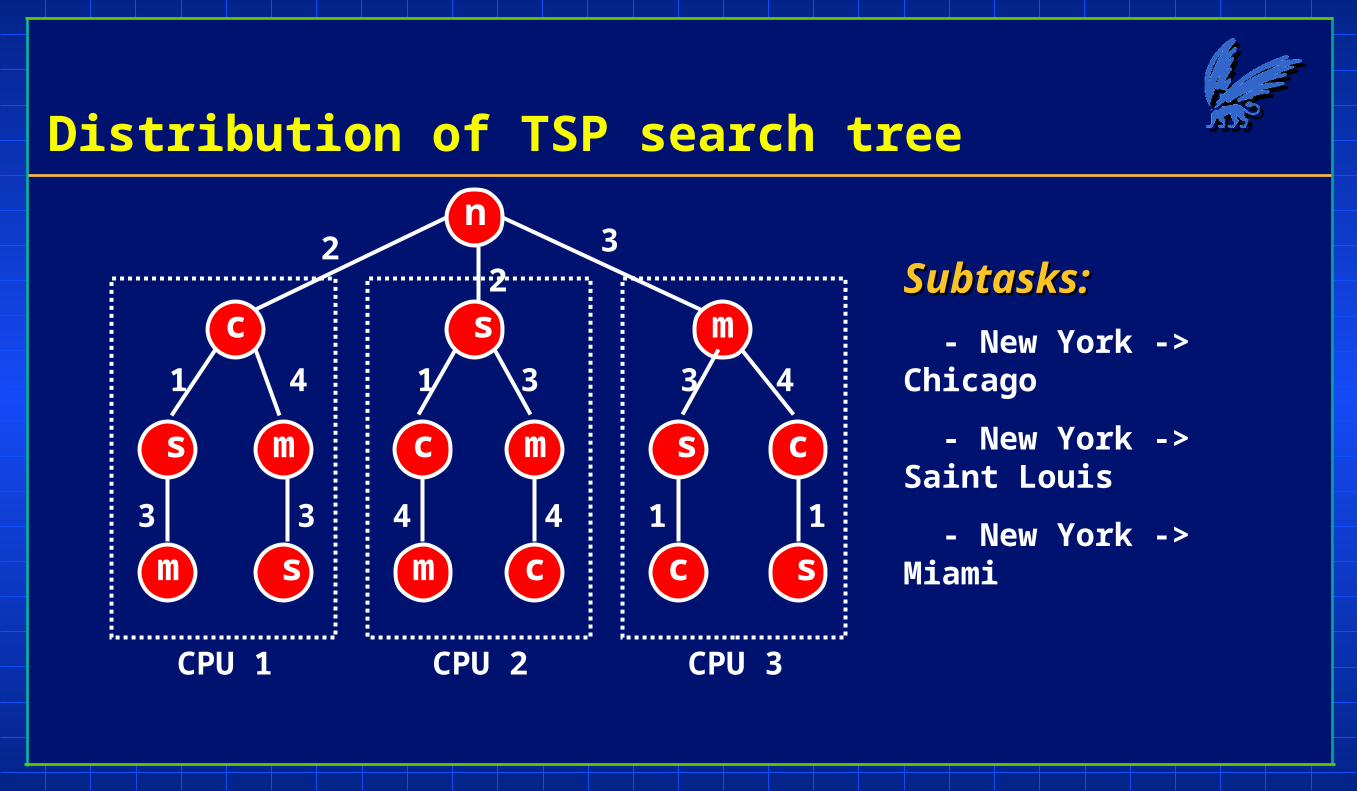
Distribution of TSP search tree
n
csm
c s m
s m s cc
c
m
m s
22
3
33
3
4
3 44
4
1
1 1
1
CPU 1 CPU 2 CPU 3
Subtasks:Subtasks:
- New York -> Chicago
- New York -> Saint Louis
- New York -> Miami
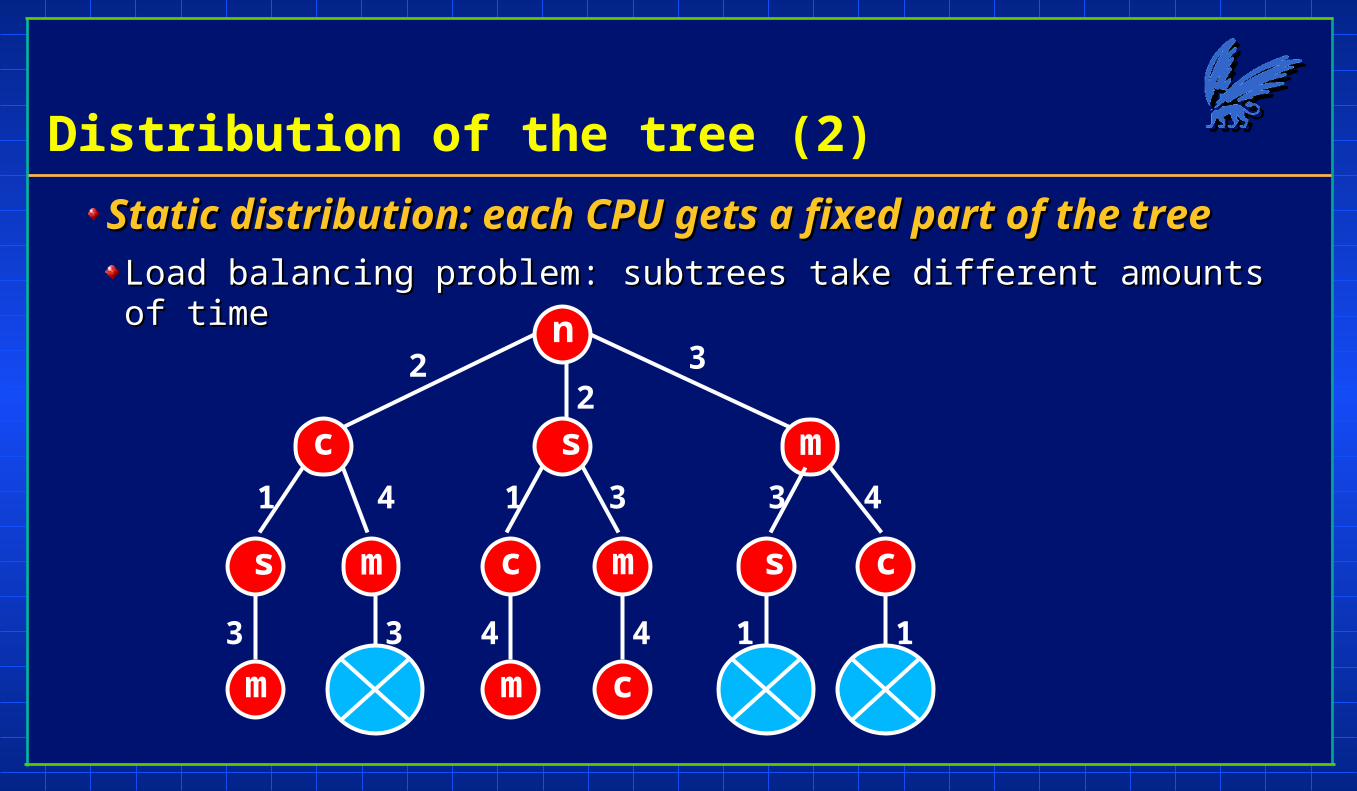
Distribution of the tree (2)
Static distribution: each CPU gets a fixed part of the treeStatic distribution: each CPU gets a fixed part of the treeLoad balancing problem: subtrees take different amounts of timeLoad balancing problem: subtrees take different amounts of time
n
csm
c s m
s m s cc
c
m
m
22
3
33
3
4
3 44
4
s
1
1 1
1

Dynamic distribution: Replicated Workers Model
Master process generates large number of jobs (subtrees) Master process generates large number of jobs (subtrees) and repeatedly hands them outand repeatedly hands them out
Worker processes (subcontractors) repeatedly take work Worker processes (subcontractors) repeatedly take work and execute itand execute it1 worker per processor1 worker per processor
General, frequently-used model for parallel processingGeneral, frequently-used model for parallel processing

Implementing TSP in SR
Need communication to distribute workNeed communication to distribute work
Need communication to implement global boundNeed communication to implement global bound
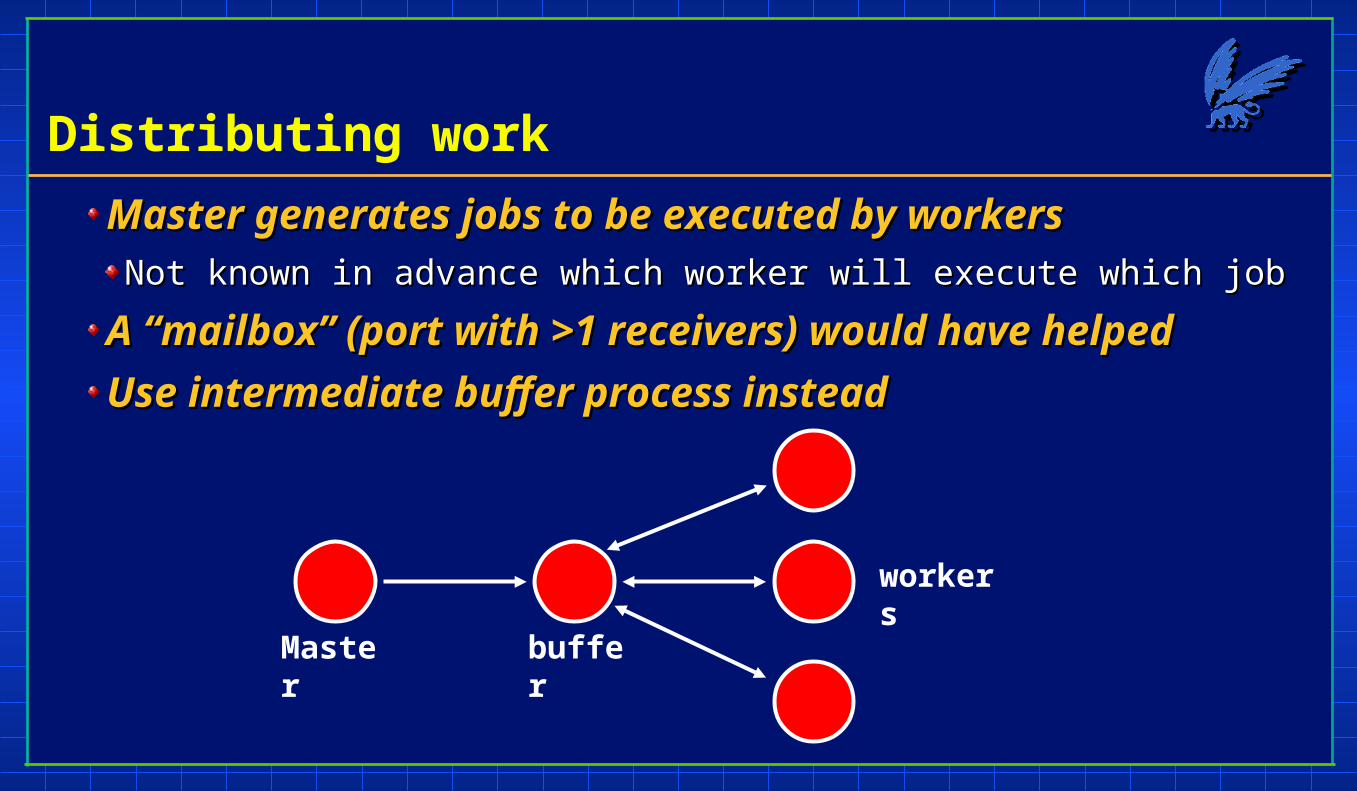
Distributing work
Master generates jobs to be executed by workersMaster generates jobs to be executed by workersNot known in advance which worker will execute which jobNot known in advance which worker will execute which job
A “mailbox” (port with >1 receivers) would have helpedA “mailbox” (port with >1 receivers) would have helped
Use intermediate buffer process insteadUse intermediate buffer process instead
Master buffer
workers

Implementing the global bound
Problem: the bound is a global variable, but it must be Problem: the bound is a global variable, but it must be implemented with message passingimplemented with message passing
The bound is accessed millions of times, but updated only The bound is accessed millions of times, but updated only when a better route is foundwhen a better route is found
Only efficient solution is to manually Only efficient solution is to manually replicatereplicate it it
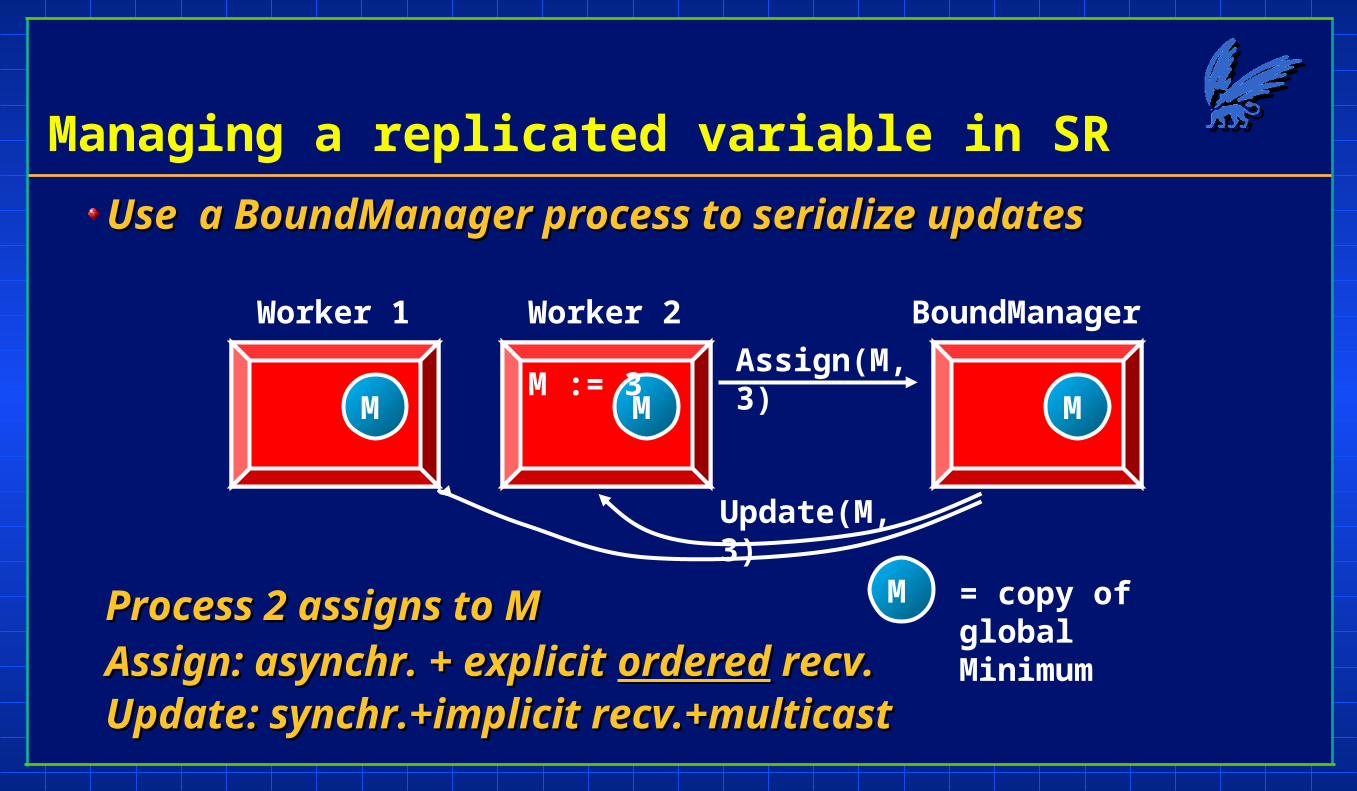
Managing a replicated variable in SR
Use a BoundManager process to serialize updatesUse a BoundManager process to serialize updates
BoundManagerWorker 1 Worker 2
M M M
M = copy of global Minimum
M := 3Assign(M,3)
Update(M,3)
Process 2 assigns to MProcess 2 assigns to M
Assign: asynchr. + explicit Assign: asynchr. + explicit orderedordered recv. recv.Update: synchr.+implicit recv.+multicastUpdate: synchr.+implicit recv.+multicast

SR code fragments for TSP
body worker var M: int := Infinite # copy of bound sem sema # semaphore proc update(value: int) P(sema) # lock copy M := value V(sema) # unlock end update
initial # main code for worker - can read M (using sema) - can use send BoundManager.Assign(value)
body BoundManager var M: int := Infinite do true -> # handle requests 1 by 1 in Assign(value) by value -> if value < M -> M := value co(i := 1 to ncpus) # multicast call worker[i].update(value) co fi ni odend BoundManager
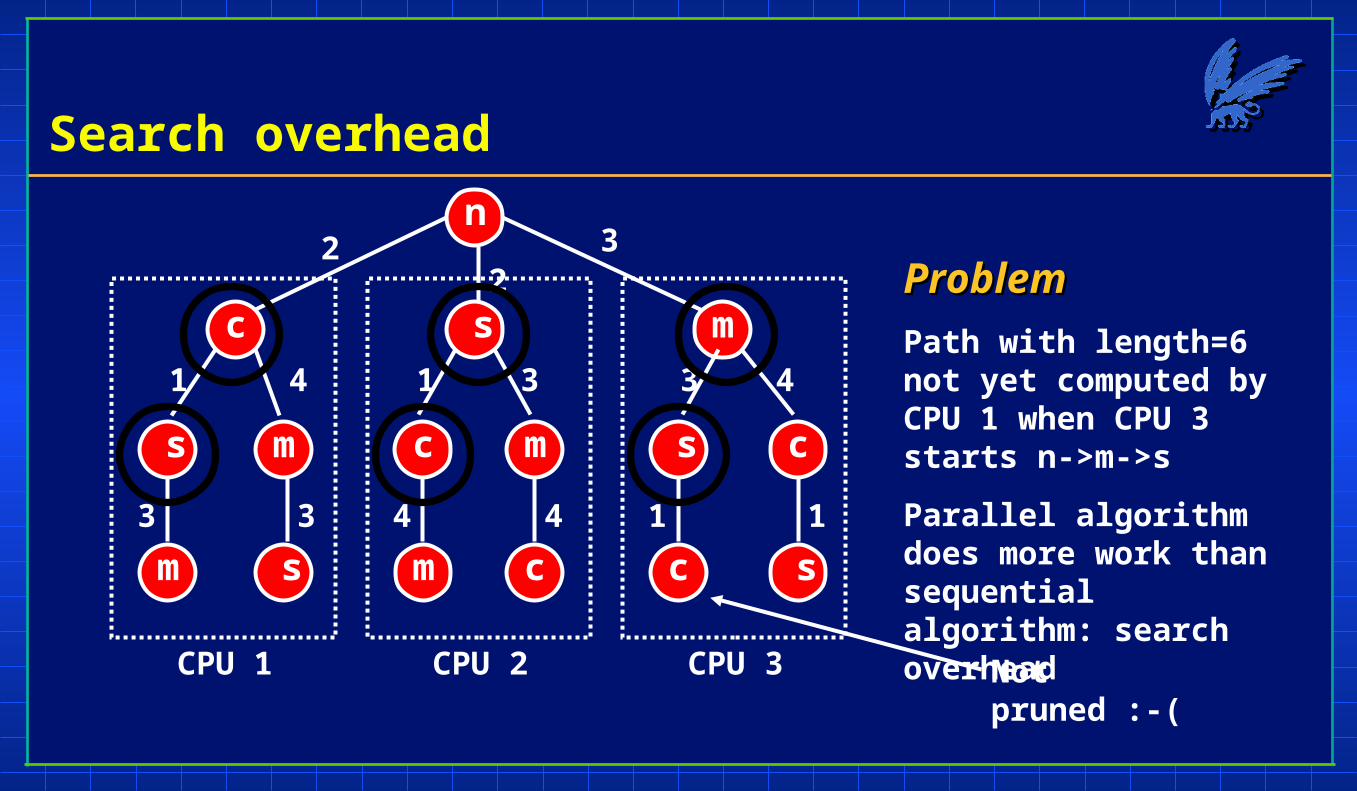
Search overhead
n
csm
c s m
s m s cc
c
m
m s
22
3
33
3
4
3 44
4
1
1 1
1
CPU 1 CPU 2 CPU 3
ProblemProblem
Path with length=6 not yet computed by CPU 1 when CPU 3 starts n->m->s
Parallel algorithm does more work than sequential algorithm: search overhead
Not pruned :-(

Performance of TSP in SR
Communication overheadCommunication overheadDistribution of jobs + updating the global bound (small overhead)Distribution of jobs + updating the global bound (small overhead)
Load imbalancesLoad imbalancesReplicated worker model has automatic load balancingReplicated worker model has automatic load balancing
Synchronization overheadSynchronization overheadMutual exclusion (locking) needed for accessing copy of boundMutual exclusion (locking) needed for accessing copy of bound
Search overheadSearch overheadMain performance problemMain performance problem
In practice: high speedups possibleIn practice: high speedups possible