cs 3343: analysis of algorithms lecture 26: string matching algorithms
TRANSCRIPT

CS 3343: Analysis of Algorithms
Lecture 26: String Matching Algorithms

Definitions
• Text: a longer string T• Pattern: a shorter string P• Exact matching: find all occurrence of P in T
abayababaxababb abayababaxababb
aba aba
T
P
length = m
Length = n

The naïve algorithm
abayababaxababb abayababaxababb
aba aba
aba aba
aba aba
aba aba
aba aba
aba aba
aba aba
aba aba
Length = mLength = n

Time complexity
• Worst case: O(mn)• Best case: O(m)
– aaaaaaaaaaaaaa vs. baaaaaaa• Average case?
– Alphabet size = k– Assume equal probability– How many chars do you need to compare before find
a mismatch?• In average: k / (k-1)• Therefore average-case complexity: mk / (k-1)• For large alphabet, ~ m
– Not as bad as you thought, huh?

Real strings are not random
T: aaaaaaaaaaaaaaaaaaaaaaaaaP: aaaab
Plus: O(m) average case is still bad for long strings!
Smarter algorithms:O(m + n) in worst casesub-linear in practice how is this possible?

How to speedup?
• Pre-processing T or P• Why pre-processing can save us time?
– Uncovers the structure of T or P– Determines when we can skip ahead without missing
anything– Determines when we can infer the result of character
comparisons without actually doing them.
ACGTAXACXTAXACGXAX
ACGTACA

Cost for exact string matching
Total cost = cost (preprocessing)
+ cost(comparison)
+ cost(output)
Constant
Minimize
Overhead
Hope: gain > overhead

String matching scenarios
• One T and one P– Search a word in a document
• One T and many P all at once– Search a set of words in a document– Spell checking
• One fixed T, many P– Search a completed genome for a short sequence
• Two (or many) T’s for common patterns
• Would you preprocess P or T?• Always pre-process the shorter seq, or the one
that is repeatedly used

Pattern pre-processing algs
– Karp – Rabin algorithm• Small alphabet and small pattern
– Boyer – Moore algorithm• The choice of most cases• Typically sub-linear time
– Knuth-Morris-Pratt algorithm (KMP)– Aho-Corasick algorithm
• The algorithm for the unix utility fgrep
– Suffix tree• One of the most useful preprocessing techniques• Many applications

Algorithm KMP
• Not the fastest
• Best known
• Good for “real-time matching”– i.e. text comes one char at a time– No memory of previous chars
• Idea– Left-to-right comparison– Shift P more than one char whenever possible

Intuitive example 1
• Observation: by reasoning on the pattern alone, we can determine that if a mismatch happened when comparing P[8] with T[i], we can shift P by four chars, and compare P[4] with T[i], without missing any possible matches.
• Number of comparisons saved: 6
abcxabcT
abcxabcdePmismatch
abcxabcT
abcxabcde
Naïve approach:
abcxabcdeabcxabcdeabcxabcde?

?
Intuitive example 2
• Observation: by reasoning on the pattern alone, we can determine that if a mismatch happened between P[7] and T[j], we can shift P by six chars and compare T[j] with P[1] without missing any possible matches
• Number of comparisons saved: 7
abcxabcT
abcxabcdePmismatch
abcxabcT
abcxabcde
Naïve approach:
abcxabcdeabcxabcdeabcxabcde
Should not be a c
abcxabcdeabcxabcde?

KMP algorithm: pre-processing
• Key: the reasoning is done without even knowing what string T is.• Only the location of mismatch in P must be known.
tt’P
t xT
y
tt’P y
z
z
Pre-processing: for any position i in P, find P[1..i]’s longest proper suffix, t = P[j..i], such that t matches to a prefix of P, t’, and the next char of t is different from the next char of t’ (i.e., y ≠ z)For each i, let sp(i) = length(t)
ij
ij

KMP algorithm: shift rule
tt’P
t xT
y
tt’P y
z
z
Shift rule: when a mismatch occurred between P[i+1] and T[k], shift P to the right by i – sp(i) chars and compare x with z.
This shift rule can be implicitly represented by creating a failure link between y and z. Meaning: when a mismatch occurred between x on T and P[i+1], resume comparison between x and P[sp(i)+1].
ij
ijsp(i)1
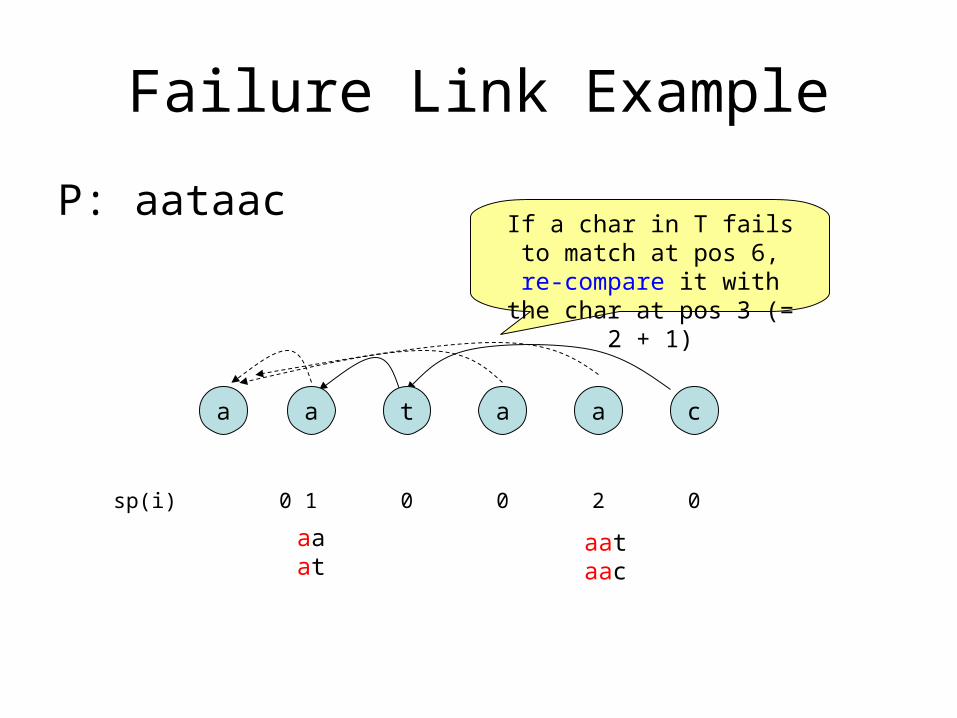
Failure Link Example
P: aataac
a a t a a c
sp(i) 0 1 0 0 2 0
aaat
aataac
If a char in T fails to match at pos 6, re-compare it with the
char at pos 3 (= 2 + 1)

Another example
P: abababc
a b a b a b c
Sp(i) 0 0 0 0 0 4 0
ababaababc
If a char in T fails to match at pos 7, re-compare it with the char at pos 5 (= 4 + 1)
abab
abababab

KMP Example using Failure Link
a a t a a c
aataac^^*
T: aacaataaaaataaccttacta
aataac.*aataac^^^^^*
aataac..*aataac.^^^^^
Time complexity analysis:• Each char in T may be compared up to n
times. A lousy analysis gives O(mn) time.• More careful analysis: number of
comparisons can be broken to two phases:• Comparison phase: the first time a char in T
is compared to P. Total is exactly m.• Shift phase. First comparisons made after a
shift. Total is at most m.• Time complexity: O(2m)
Implicitcomparison

KMP algorithm using DFA (Deterministic Finite Automata)
P: aataac
1 2 3 4 50a a t a a c
6
a t
If the next char in T is t after matching 5 chars, go to state 3
a a t a a c
If a char in T fails to match at pos 6, re-compare it with
the char at pos 3
a
Failure link
DFA
a
All other inputs goes to state 0.

DFA Example
T: aacaataataataaccttacta
Each char in T will be examined exactly once.
Therefore, exactly m comparisons are made.
But it takes longer to do pre-processing, and needs more space to store the FSA.
1201234534534560001001
1 2 3 4 50a a t a a c
6
a t
a
DFA
a

Difference between Failure Link and DFA
• Failure link– Preprocessing time and space are O(n), regardless of
alphabet size– Comparison time is at most 2m (at least m)
• DFA– Preprocessing time and space are O(n ||)
• May be a problem for very large alphabet size• For example, each “char” is a big integer• Chinese characters
– Comparison time is always m.

The set matching problem
• Find all occurrences of a set of patterns in T• First idea: run KMP or BM for each P
– O(km + n)• k: number of patterns• m: length of text• n: total length of patterns
• Better idea: combine all patterns together and search in one run

A simpler problem: spell-checking
• A dictionary contains five words:– potato– poetry– pottery– science– school
• Given a document, check if any word is (not) in the dictionary– Words in document are separated by special chars.– Relatively easy.

Keyword tree for spell checking
• O(n) time to construct. n: total length of patterns.• Search time: O(m). m: length of text• Common prefix only need to be compared once. • What if there is no space between words?
p
o
t
a
t
o
e
tr
y
t
er
y
s
c
i
e
n
c
e
h o o l
1
2
3
4
5
This version of the potato gun was inspired by the Weird Science team out of Illinois

Aho-Corasick algorithm
• Basis of the fgrep algorithm
• Generalizing KMP– Using failure links
• Example: given the following 4 patterns:– potato– tattoo– theater– other

Keyword tree
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e

Keyword tree
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
potherotathxythopotattooattoo

Keyword tree
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
O(mn) m: length of text. n: length of longest pattern
potherotathxythopotattooattoo

Keyword Tree with a failure link
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
potherotathxythopotattooattoo

Keyword Tree with a failure link
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
potherotathxythopotattooattoo

Keyword Tree with all failure links
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e

Example
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
potherotathxythopotattooattoo

Example
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
potherotathxythopotattooattoo

Example
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
potherotathxythopotattooattoo

Example
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
potherotathxythopotattooattoo

Example
p
o
t
a
t
o
t
e
r
0t
he
r
1
2 3
4
a
t
t
o
o
h
a
t
e
potherotathxythopotattooattoo

Aho-Corasick algorithm
• O(n) preprocessing, and O(m+k) searching. – n: total length of patterns. – m: length of text– k is # of occurrence.
• Can create a DFA similar as in KMP. – Requires more space, – Preprocessing time depends on alphabet size– Search time is constant

Suffix Tree
• All algorithms we talked about so far preprocess pattern(s)– Karp-Rabin: small pattern, small alphabet– Boyer-Moore: fastest in practice. O(m) worst case.– KMP: O(m)– Aho-Corasick: O(m)
• In some cases we may prefer to pre-process T– Fixed T, varying P
• Suffix tree: basically a keyword tree of all suffixes

Suffix tree
• T: xabxac
• Suffixes:1. xabxac
2. abxac
3. bxac
4. xac
5. ac
6. c
a
bx
ac
bxa
c
c
c
x a b x a cc 1
2 3
4
5
6
Naïve construction: O(m2) using Aho-Corasick.
Smarter: O(m). Very technical. big constant factor
Difference from a keyword tree: create an internal node only when there is a branch

Suffix tree implementation
• Explicitly labeling seq end
• T: xabxa T: xabxa$
a
bx
a
bxa
x a b x a1
2 3
a
bx
a
bxa
x a b x a1
2 3
$
$$
$
$4
5

Suffix tree implementation
• Implicitly labeling edges
• T: xabxa$
a
bx
a
bxa
x a b x a1
2 3
$
$$
$
$4
5
2:2
3:$ 3:$
1
2 3
$
$4
5
1:23:$

Suffix links
• Similar to failure link in a keyword tree
• Only link internal nodes having branchesx
ab
cd
ef
g
h
ij
ab
c
de
fg
h
i
j
xabcff

Suffix tree construction
1:$
1
1234567890acatgacatt

Suffix tree construction
2:$
2
1234567890acatgacatt
1:$
1
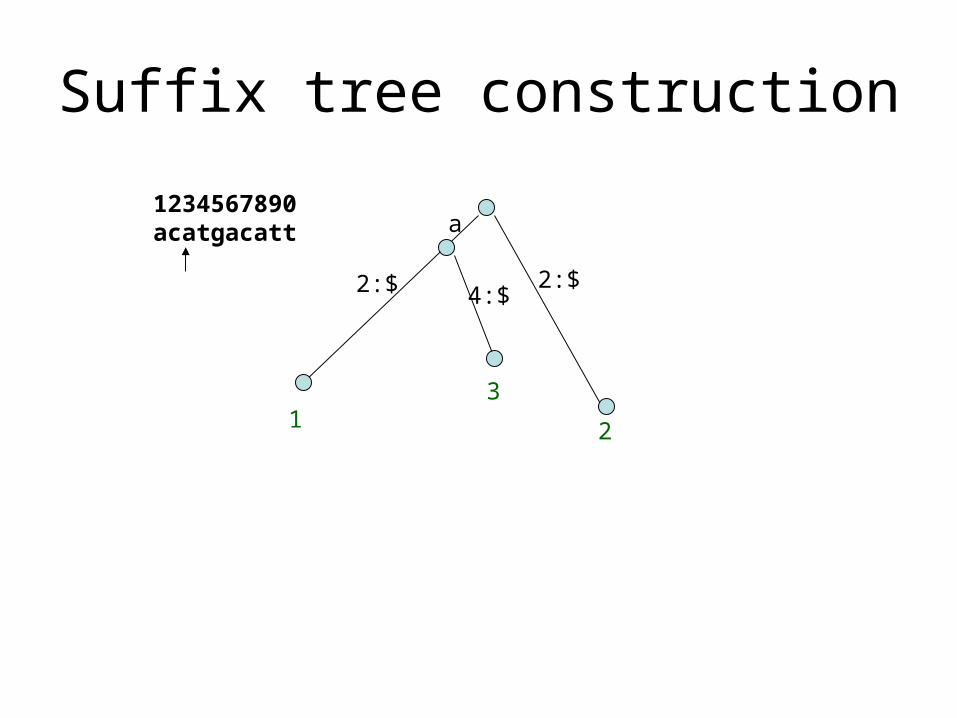
Suffix tree construction
2:$
a
4:$
2
3
1234567890acatgacatt
2:$
1

Suffix tree construction
2:$
2
4:$
4
1234567890acatgacatt a
4:$
3
2:$
1

Suffix tree construction
2:$
2
4:$
4
1234567890acatgacatt
5:$ 5a
4:$
3
2:$
1

Suffix tree construction
2:$
2
4:$
4
1234567890acatgacatt
5:$
ca
tt
5
6
a
4:$
3
5:$
1
$

Suffix tree construction
5:$
2
4:$
4
1234567890acatgacatt
5:$ 5cat
t
7
ca
t
t
6
a
4:$
3
5:$
1
$

Suffix tree construction
5:$
2
4:$
4
1234567890acatgacatt
5:$ 5cat
t
7
ca
t
t
6
a
5:$
3
5:$
1
t
8
t
$

Suffix tree construction
5:$
2
5:$
4
1234567890acatgacatt
5:$ 5cat
t
7
ca
t
t
6
a
5:$
3
5:$
1
t
8
tt
t
9
$

Suffix tree construction
5:$
2
5:$
4
1234567890acatgacatt
5:$ 5cat
t
7
ca
t
t
6
a
5:$
3
5:$
1
t
8
tt
t
9
10$
$

ST Application 1: pattern matching
• Find all occurrence of P=xa in T– Find node v in the ST that
matches to P– Traverse the subtree
rooted at v to get the locations
a
bx
ac
bxa
c
c
c
x a b x a cc 1
2 3
4
5
6
T: xabxac
• O(m) to construct ST (large constant factor)
• O(n) to find v – linear to length of P instead of T!
• O(k) to get all leaves, k is the number of occurrence.
• Asymptotic time is the same as KMP. ST wins if T is fixed. KMP wins otherwise.

ST Application 2: set matching
• Find all occurrences of a set of patterns in T– Build a ST from T– Match each P to ST
a
bx
ac
bxa
c
c
c
x a b x a cc 1
2 3
4
5
6
T: xabxacP: xab
• O(m) to construct ST (large constant factor)
• O(n) to find v – linear to total length of P’s
• O(k) to get all leaves, k is the number of occurrence.
• Asymptotic time is the same as Aho-Corasick. ST wins if T fixed. AC wins if P’s are fixed. Otherwise depending on relative size.

ST application 3: repeats finding
• Genome contains many repeated DNA sequences
• Repeat sequence length: Varies from 1 nucleotide to millions– Genes may have multiple copies (50 to 10,000) – Highly repetitive DNA in some non-coding regions
• 6 to 10bp x 100,000 to 1,000,000 times
• Problem: find all repeats that are at least k-residues long and appear at least p times in the genome

Repeats finding
• at least k-residues long and appear at least p times in the seq– Phase 1: top-down, count label lengths (L)
from root to each node– Phase 2: bottom-up: count # of leaves
descended from each internal node
(L, N)
For each node with L >= k, and N >= p, print all leaves
O(m) to traverse tree

Maximal repeats finding
1. Right-maximal repeat– S[i+1..i+k] = S[j+1..j+k], – but S[i+k+1] != S[j+k+1]
2. Left-maximal repeat– S[i+1..i+k] = S[j+1..j+k]– But S[i] != S[j]
3. Maximal repeat– S[i+1..i+k] = S[j+1..j+k]– But S[i] != S[j], and S[i+k+1] != S[j+k+1]
acatgacatt
1. cat2. aca3. acat

Maximal repeats finding
• Find repeats with at least 3 bases and 2 occurrence– right-maximal: cat– Maximal: acat– left-maximal: aca
5:e
2
5:e
4
1234567890acatgacatt
5:e 5cat
t
7
ca
t
t
6
a
5:e
3
5:e
1
t
8
tt
t
9
10$

Maximal repeats finding
• How to find maximal repeat?– A right-maximal repeats with different left chars
5:e
2
5:e
4
1234567890acatgacatt
5:e 5cat
t
7
ca
t
t
6
a
5:e
3
5:e
1
t
8
tt
t
9
10$
Left char = [] g c c a a

ST application 4: word enumeration
• Find all k-mers that occur at least p times– Compute (L, N) for each
node• L: total label length from
root to node • N: # leaves
– Find nodes v with L>=k, and L(parent)<k, and N>=y
– Traverse sub-tree rooted at v to get the locations
L<k
L>=k, N>=p
L = KL=k
This can be used in many applications. For example, to find words that appeared frequently in a genome or a document

Joint Suffix Tree
• Build a ST for many than two strings
• Two strings S1 and S2
• S* = S1 & S2
• Build a suffix tree for S* in time O(|S1| + |S2|)
• The separator will only appear in the edge ending in a leaf

• S1 = abcd
• S2 = abca
• S* = abcd&abca$a
bcd
&ab
ca
bc
d&abca
c
d&
abc
d
d & ab c
d
& a b c d
a aa
$
1,1
2,1
1,2
1,3
1,4
2,2
2,32,4
useless

To Simplify
• We don’t really need to do anything, since all edge labels were implicit.
• The right hand side is more convenient to look at
abc
d&
abc
a
bc
d&abca
c
d&
abc
d
d & ab c
d
& a b c d
a aa
$
1,1
2,1
1,2
1,3
1,4
2,2
2,32,4
uselessa
bcd
bc
d
c
d
d
a aa
$
1,12,1
1,21,3
1,4
2,2
2,32,4

Application of JST
• Longest common substring– For each internal node v,
keep a bit vector B– B[1] = 1 if a child of v is a
suffix of S1– Find all internal nodes with
B[1] = B[2] = 1– Report one with the longest
label– Can be extended to k
sequences. Just use a longer bit vector.
abc
d
bc
d
c
d
d
a aa
$
1,12,1
1,21,3
1,4
2,2
2,32,4
Not subsequence

Application of JST
• Given K strings, find all k-mers that appear in at least d strings
L< k
L >= k B = (1, 0, 1, 1)cardinal(B) >= d
1,x3,x 3,x
4,x

Many other applications
• Reproduce the behavior of Aho-Corasick• Recognizing computer virus
– A database of known computer viruses– Does a file contain virus?
• DNA finger printing– A database of people’s DNA sequence– Given a short DNA, which person is it from?
• …• Catch
– Large constant factor for space requirement– Large constant factor for construction– Suffix array: trade off time for space

Summary
• One T, one P– Boyer-Moore is the choice– KMP works but not the best
• One T, many P– Aho-Corasick– Suffix Tree
• One fixed T, many varying P– Suffix tree
• Two or more T’s– Suffix tree, joint suffix tree, suffix array
Alphabet independent
Alphabet dependent

Pattern pre-processing algs
– Karp – Rabin algorithm• Small alphabet and small pattern
– Boyer – Moore algorithm• The choice of most cases• Typically sub-linear time
– Knuth-Morris-Pratt algorithm (KMP)– Aho-Corasick algorithm
• The algorithm for the unix utility fgrep
– Suffix tree• One of the most useful preprocessing techniques• Many applications

Karp – Rabin Algorithm
• Let’s say we are dealing with binary numbersText: 01010001011001010101001
Pattern: 101100
• Convert pattern to integer101100 = 2^5 + 2^3 + 2^2 = 44

Karp – Rabin algorithm
Text: 01010001011001010101001Pattern: 101100 = 44 decimal
10111011001010101001= 2^5 + 0 + 2^3 + 2^2 + 2^1 = 4610111011001010101001= 46 * 2 – 64 + 1 = 2910111011001010101001= 29 * 2 - 0 + 1 = 5910111011001010101001= 59 * 2 - 64 + 0 = 5410111011001010101001
= 54 * 2 - 64 + 0 = 44Θ(m+n)

Karp – Rabin algorithmWhat if the pattern is too long to fit into a single integer? Pattern: 101100. What if each word in our computer has only 4 bits?Basic idea: hashing. 44 % 13 = 5
10111011001010101001= 46 (% 13 = 7)10111011001010101001= 46 * 2 – 64 + 1 = 29 (% 13 = 3)10111011001010101001= 29 * 2 - 0 + 1 = 59 (% 13 = 7)10111011001010101001= 59 * 2 - 64 + 0 = 54 (% 13 = 2)10111011001010101001= 54 * 2 - 64 + 0 = 44 (% 13 = 5)
Θ(m+n) expected running time

Boyer – Moore algorithm
• Three ideas:– Right-to-left comparison– Bad character rule– Good suffix rule

Boyer – Moore algorithm
• Right to left comparison
x
y
y
Skip some chars without missing any occurrence.
But how?

Bad character rule
0 1 12345678901234567T:xpbctbxabpqqaabpqP: tpabxab *^^^^What would you do now?

Bad character rule
0 1 12345678901234567T:xpbctbxabpqqaabpqP: tpabxab *^^^^P: tpabxab

Bad character rule
0 1 123456789012345678T:xpbctbxabpqqaabpqzP: tpabxab *^^^^P: tpabxab *P: tpabxab

Basic bad character rule
char Right-most-position in P
a 6
b 7
p 2
t 1
x 5
tpabxab
Pre-processing:O(n)

Basic bad character rule
char Right-most-position in P
a 6
b 7
p 2
t 1
x 5
T: xpbctbxabpqqaabpqzP: tpabxab
*^^^^
P: tpabxab
When rightmost T(k) in P is left to i, shift pattern P to align T(k) with the rightmost T(k) in P
k
i = 3 Shift 3 – 1 = 2

Basic bad character rule
char Right-most-position in P
a 6
b 7
p 2
t 1
x 5
T: xpbctbxabpqqaabpqzP: tpabxab *
P: tpabxab
When T(k) is not in P, shift left end of P to align with T(k+1)
k
i = 7 Shift 7 – 0 = 7

Basic bad character rule
char Right-most-position in P
a 6
b 7
p 2
t 1
x 5
T: xpbctbxabpqqaabpqz
P: tpabxab *^^
P: tpabxab
When rightmost T(k) in P is right to i, shift pattern P one pos
k
i = 5 5 – 6 < 0. so shift 1

Extended bad character rule
char Position in P
a 6, 3
b 7, 4
p 2
t 1
x 5
T: xpbctbxabpqqaabpqz
P: tpabxab *^^
P: tpabxab
Find T(k) in P that is immediately left to i, shift P to align T(k) with that position
k
i = 5 5 – 3 = 2. so shift 2
Preprocessing still O(n)

Extended bad character rule
• Best possible: m / n comparisons
• Works better for large alphabet size
• In some cases the extended bad character rule is sufficiently good
• Worst-case: O(mn)
• What else can we do?

0 1 123456789012345678T:prstabstubabvqxrstP: qcabdabdab *^^
P: qcabdabdab
According to extended bad character rule

(weak) good suffix rule
0 1 123456789012345678T:prstabstubabvqxrstP: qcabdabdab *^^
P: qcabdabdab

(Weak) good suffix rule
tx
tyt’
tyt’
Preprocessing: For any suffix t of P, find the rightmost copy of t, denoted by t’.How to find t’ efficiently?
T
P
P

(Strong) good suffix rule
0 1 123456789012345678T:prstabstubabvqxrstP: qcabdabdab *^^

(Strong) good suffix rule
0 1 123456789012345678T:prstabstubabvqxrstP: qcabdabdab *^^P: qcabdabdab

(Strong) good suffix rule
0 1 123456789012345678T:prstabstubabvqxrstP: qcabdabdab *^^
P: qcabdabdab

(Strong) good suffix rule
• Pre-processing can be done in linear time• If P in T, searching may take O(mn)• If P not in T, searching in worst-case is O(m+n)
tx
tyt’
tyt’
In preprocessing: For any suffix t of P, find the rightmost copy of t, t’, such that the char left to t ≠ the char left to t’
T
P
P
z
z
z ≠ y

Example preprocessing
qcabdabdab
char Positions in P
a 9, 6, 3
b 10, 7, 4
c 2
d 8,5
q 1
q c a b d a b d a b1 2 3 4 5 6 7 8 9 10
0 0 0 0 0 0 0 2 0 0dab
cab
Bad char rule Good suffix rule
Where to shift depends on T Does not depend on T