cs 61c: great ideas in computer architecture lecture 18
TRANSCRIPT

CS61C:GreatIdeasinComputerArchitecture
Lecture18:ParallelProcessing– SIMD
KrsteAsanović &RandyKatz
http://inst.eecs.berkeley.edu/~cs61c

61CSurvey
Itwouldbenicetohaveareviewlectureeveryonceinawhile,actuallyshowingus
howthingsfitinthebiggerpicture
CS61c Lecture18:ParallelProcessing- SIMD 2

Agenda• 61C– thebigpicture• Parallelprocessing• Singleinstruction,multipledata• SIMDmatrixmultiplication• Amdahl’slaw• Loopunrolling• Memoryaccessstrategy- blocking• AndinConclusion,…CS61c Lecture18:ParallelProcessing- SIMD 3

61CTopicssofar…• Whatwelearned:
1. Binarynumbers2. C3. Pointers4. Assemblylanguage5. Datapath architecture6. Pipelining7. Caches8. Performanceevaluation9. Floatingpoint
• Whatdoesthisbuyus?− Promise:executionspeed− Let’scheck!
CS61c Lecture18:ParallelProcessing- SIMD 4

ReferenceProblem•Matrixmultiplication
−Basicoperationinmanyengineering,data,andimagingprocessingtasks
− Imagefiltering,noisereduction,…−Manycloselyrelatedoperations
§ E.g.stereovision(project4)•dgemm
−double-precisionfloating-pointmatrixmultiplication
CS61c Lecture18:ParallelProcessing- SIMD 5

ApplicationExample:DeepLearning• Imageclassification(cats…)•Pick“best”vacationphotos•Machinetranslation•Cleanupaccent•Fingerprintverification•Automaticgameplaying
CS61c Lecture18:ParallelProcessing- SIMD 6

Matrices
CS61c Lecture18:ParallelProcessing- SIMD 7
𝑖
𝑗N-1
N-1
0
0
• SquarematrixofdimensionNxN

MatrixMultiplication
CS61c 8
𝑖
𝑗
𝑘
𝑘C=A*BCij =Σk (Aik *Bkj)
A
B
C

Reference:Python• MatrixmultiplicationinPython
CS61c Lecture18:ParallelProcessing- SIMD 9
N Python[Mflops]32 5.4160 5.5480 5.4960 5.3
• 1MFLOP=1Millionfloating-pointoperationspersecond(fadd,fmul)
• dgemm(N…)takes2*N3 flops

C• c=a*b• a,b,careNxNmatrices
CS61c Lecture18:ParallelProcessing- SIMD 10

TimingProgramExecution
CS61c Lecture18:ParallelProcessing- SIMD 11

CversusPython
CS61c Lecture18:ParallelProcessing- SIMD 12
N C[GFLOPS] Python[GFLOPS]32 1.30 0.0054160 1.30 0.0055480 1.32 0.0054960 0.91 0.0053
Whichclassgivesyouthiskindofpower?Wecouldstophere…butwhy?Let’sdobetter!
240x!

Agenda• 61C– thebigpicture• Parallelprocessing• Singleinstruction,multipledata• SIMDmatrixmultiplication• Amdahl’slaw• Loopunrolling• Memoryaccessstrategy- blocking• AndinConclusion,…CS61c Lecture18:ParallelProcessing- SIMD 13

WhyParallelProcessing?• CPUClockRatesarenolongerincreasing
−Technical&economicchallenges§ Advancedcoolingtechnologytooexpensiveorimpracticalformostapplications
§ Energycostsareprohibitive
• Parallelprocessingisonlypathtohigherspeed−Compareairlines:
§ Maximumspeedlimitedbyspeedofsoundandeconomics§ Usemoreandlargerairplanestoincreasethroughput§ Andsmallerseats…
CS61c Lecture18:ParallelProcessing- SIMD 14

UsingParallelismforPerformance• Twobasicways:
−Multiprogramming§ runmultipleindependentprogramsinparallel§ “Easy”
−Parallelcomputing§ runoneprogramfaster§ “Hard”
•We’llfocusonparallelcomputinginthenextfewlectures
15CS61c Lecture18:ParallelProcessing- SIMD

New-SchoolMachineStructures(It’sabitmorecomplicated!)
• ParallelRequestsAssignedtocomputere.g.,Search“Katz”• ParallelThreadsAssignedtocoree.g.,Lookup,Ads• ParallelInstructions>[email protected].,5pipelinedinstructions• ParallelData>[email protected].,Addof4pairsofwords• HardwaredescriptionsAllgates@onetime• ProgrammingLanguages
16
SmartPhone
WarehouseScale
Computer
SoftwareHardware
HarnessParallelism&AchieveHighPerformance
LogicGates
Core Core…Memory(Cache)Input/Output
Computer
CacheMemory
CoreInstructionUnit(s) Functional
Unit(s)A3+B3A2+B2A1+B1A0+B0
Today’sLecture

Single-Instruction/Single-DataStream(SISD)
• Sequentialcomputerthatexploitsnoparallelismineithertheinstructionordatastreams.ExamplesofSISDarchitecturearetraditionaluniprocessormachines
E.g.ourtrustedRISC-Vpipeline
17
ProcessingUnit
CS61c Lecture18:ParallelProcessing- SIMD
Thisiswhatwediduptonowin61C

Single-Instruction/Multiple-DataStream(SIMDor“sim-dee”)
• SIMDcomputerexploitsmultipledatastreamsagainstasingleinstructionstreamtooperationsthatmaybenaturallyparallelized,e.g.,IntelSIMDinstructionextensionsorNVIDIAGraphicsProcessingUnit(GPU)
18CS61c Lecture18:ParallelProcessing- SIMD
Today’stopic.

Multiple-Instruction/Multiple-DataStreams(MIMDor“mim-dee”)
• Multipleautonomousprocessorssimultaneouslyexecutingdifferentinstructionsondifferentdata.• MIMDarchitecturesincludemulticoreandWarehouse-ScaleComputers
19
InstructionPool
PU
PU
PU
PU
DataPoo
l
CS61c Lecture18:ParallelProcessing- SIMD
TopicofLecture19andbeyond.
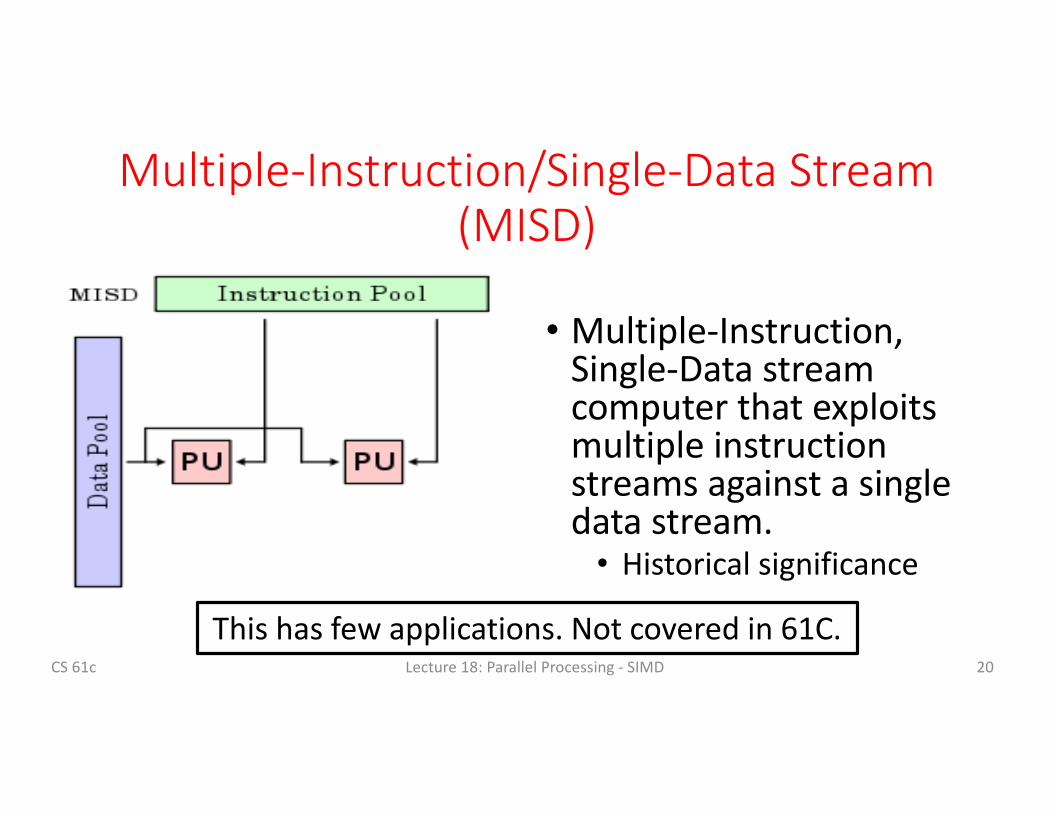
Multiple-Instruction/Single-DataStream(MISD)
• Multiple-Instruction,Single-Datastreamcomputerthatexploitsmultipleinstructionstreamsagainstasingledatastream.• Historicalsignificance
20CS61c Lecture18:ParallelProcessing- SIMD
Thishasfewapplications.Notcoveredin61C.

Flynn*Taxonomy,1966
• SIMDandMIMDarecurrentlythemostcommonparallelisminarchitectures– usuallybothinsamesystem!
• Mostcommonparallelprocessingprogrammingstyle:SingleProgramMultipleData(“SPMD”)− SingleprogramthatrunsonallprocessorsofaMIMD− Cross-processorexecutioncoordinationusingsynchronizationprimitives
21CS61c Lecture18:ParallelProcessing- SIMD

Agenda• 61C– thebigpicture• Parallelprocessing• Singleinstruction,multipledata• SIMDmatrixmultiplication• Amdahl’slaw• Loopunrolling• Memoryaccessstrategy- blocking• AndinConclusion,…CS61c Lecture18:ParallelProcessing- SIMD 22

SIMD– “SingleInstructionMultipleData”
23CS61c Lecture18:ParallelProcessing- SIMD

SIMDApplications&Implementations• Applications
− Scientificcomputing§ Matlab,NumPy
− Graphicsandvideoprocessing§ Photoshop,…
− BigData§ Deeplearning
− Gaming− …
• Implementations− x86− ARM− RISC-Vvectorextensions
CS61c Lecture18:ParallelProcessing- SIMD 24

25
FirstSIMDExtensions:MITLincolnLabsTX-2,1957
CS61c

x86SIMDEvolution
CS61c Lecture18:ParallelProcessing- SIMD 26
http://svmoore.pbworks.com/w/file/fetch/70583970/VectorOps.pdf
• Newinstructions• New,wider,moreregisters• Moreparallelism

LaptopCPUSpecs$ sysctl -a | grep cpuhw.physicalcpu: 2hw.logicalcpu: 4
machdep.cpu.brand_string: Intel(R) Core(TM) i7-5557U CPU @ 3.10GHz
machdep.cpu.features: FPU VME DE PSE TSC MSR PAE MCE CX8 APIC SEP MTRR PGE MCA CMOV PAT PSE36 CLFSH DS ACPI MMX FXSR SSE SSE2 SS HTT TM PBE SSE3 PCLMULQDQ DTES64 MON DSCPL VMX EST TM2 SSSE3 FMA CX16 TPR PDCM SSE4.1 SSE4.2 x2APIC MOVBE POPCNT AES PCID XSAVE OSXSAVE SEGLIM64 TSCTMR AVX1.0RDRAND F16C
machdep.cpu.leaf7_features: SMEP ERMS RDWRFSGS TSC_THREAD_OFFSET BMI1 AVX2 BMI2 INVPCID SMAP RDSEED ADX IPT FPU_CSDS
CS61c Lecture18:ParallelProcessing- SIMD 27

SIMDRegisters
CS61c Lecture18:ParallelProcessing- SIMD 28

SIMDDataTypes
CS61c Lecture18:ParallelProcessing- SIMD 29
(NowalsoAVX-512available)

SIMDVectorMode
CS61c Lecture18:ParallelProcessing- SIMD 30

Agenda• 61C– thebigpicture• Parallelprocessing• Singleinstruction,multipledata• SIMDmatrixmultiplication• Amdahl’slaw• Loopunrolling• Memoryaccessstrategy- blocking• AndinConclusion,…CS61c Lecture18:ParallelProcessing- SIMD 31

Problem• Today’scompilers(largely)donotgenerateSIMDcode• Backtoassembly…• x86(notusingRISC-Vasnovectorhardwareyet)
−Over1000instructionstolearn…−GreenBook
• Canweusethecompilertogenerateallnon-SIMDinstructions?
CS61c Lecture18:ParallelProcessing- SIMD 32

x86IntrinsicsAVXDataTypes
CS61c Lecture18:ParallelProcessing- SIMD 33
Intrinsics: Directaccesstoregisters&assemblyfromCRegister
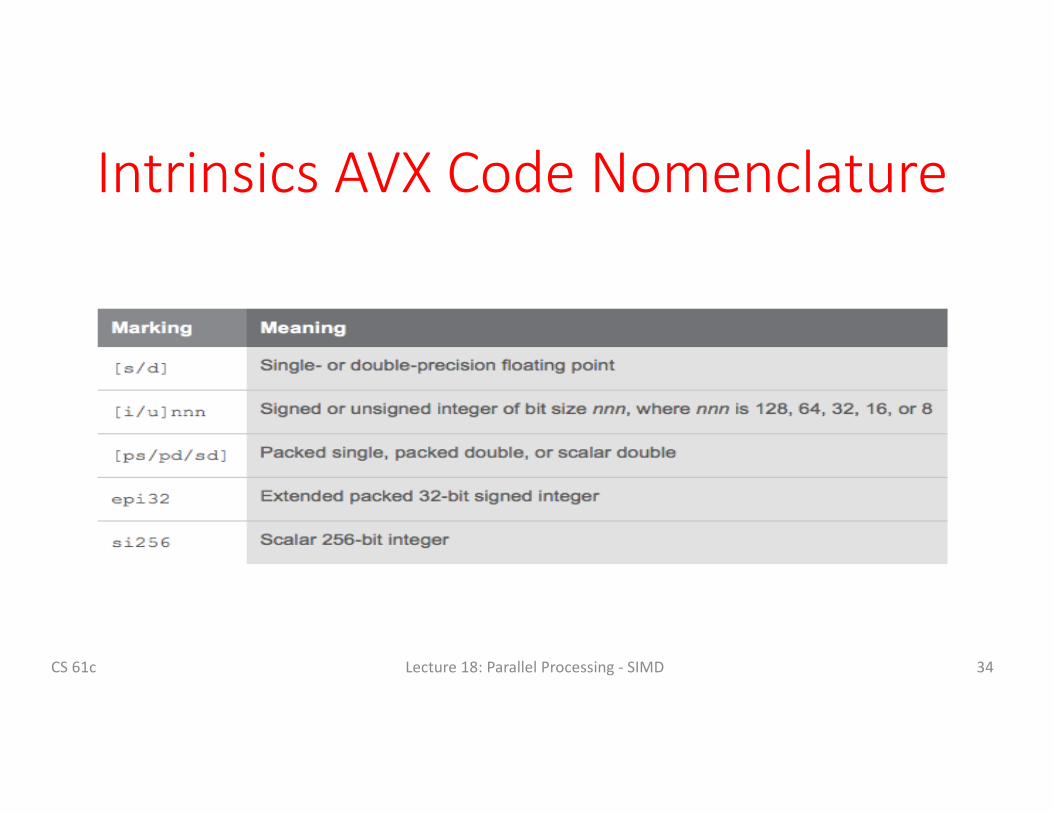
IntrinsicsAVXCodeNomenclature
CS61c Lecture18:ParallelProcessing- SIMD 34

https://software.intel.com/sites/landingpage/IntrinsicsGuide/CS61c Lecture18:ParallelProcessing- SIMD 35
4parallelmultiplies
2instructionsperclockcycle(CPI=0.5)
assemblyinstruction
x86SIMD“Intrinsics”
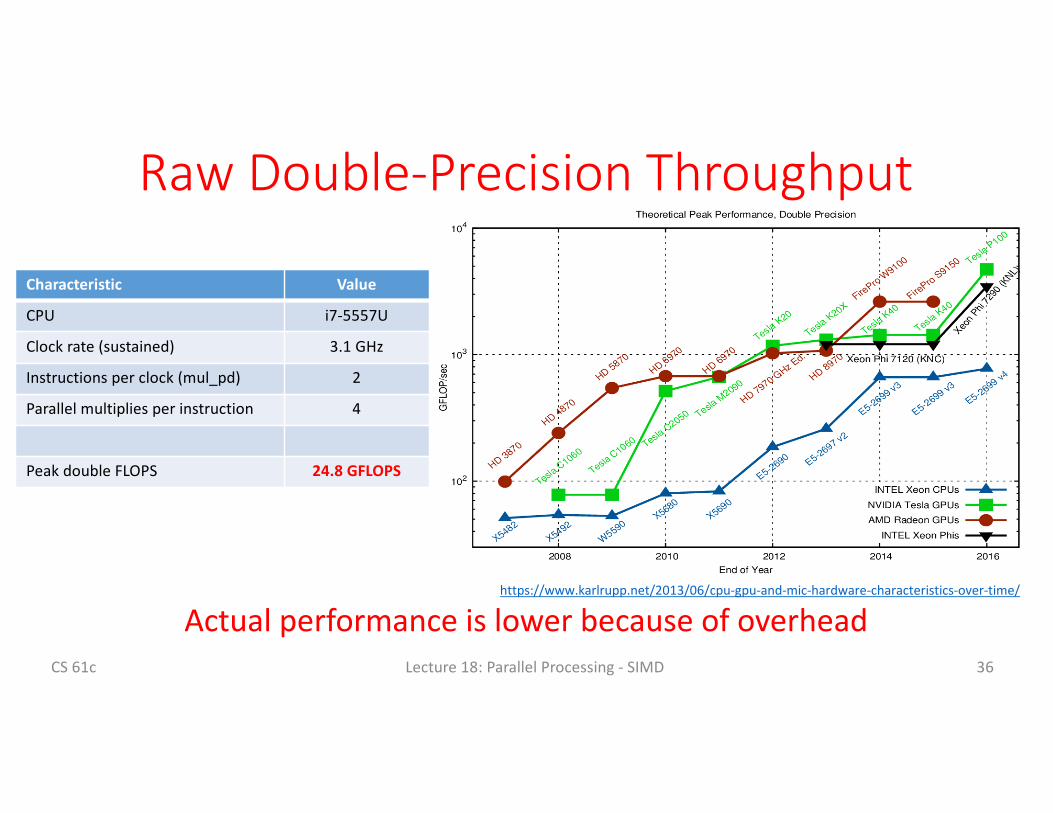
RawDouble-PrecisionThroughput
Characteristic Value
CPU i7-5557U
Clockrate(sustained) 3.1GHz
Instructions perclock(mul_pd) 2
Parallel multipliesperinstruction 4
PeakdoubleFLOPS 24.8GFLOPS
CS61c Lecture18:ParallelProcessing- SIMD 36
Actualperformanceislowerbecauseofoverheadhttps://www.karlrupp.net/2013/06/cpu-gpu-and-mic-hardware-characteristics-over-time/

VectorizedMatrixMultiplication
CS61c 37
𝑖
𝑗
𝑘
𝑘InnerLoop:
fori …;i+=4forj...
i+=4

“Vectorized”dgemm
CS61c Lecture18:ParallelProcessing- SIMD 38

Performance
NGflops
scalar avx32 1.30 4.56160 1.30 5.47480 1.32 5.27960 0.91 3.64
CS61c Lecture18:ParallelProcessing- SIMD 39
• 4xfaster• Butstill<<theoretical25GFLOPS!

Agenda• 61C– thebigpicture• Parallelprocessing• Singleinstruction,multipledata• SIMDmatrixmultiplication• Amdahl’slaw• Loopunrolling• Memoryaccessstrategy- blocking• AndinConclusion,…CS61c Lecture18:ParallelProcessing- SIMD 40

AtriptoLA
Get toSFO&check-in SFOà LAX Getto destination3hours 1hour 3 hours
CS61c Lecture18:ParallelProcessing- SIMD 41
Commercialairline:
Supersonicaircraft:
Get toSFO&check-in SFOà LAX Getto destination3hours 6min 3 hours
Totaltime:7hours
Totaltime:6.1hoursSpeedup:
Flyingtime Sflight =60/6=10xTriptime Strip =7/6.1=1.15x

Amdahl’sLaw• GetenhancementE foryournewPC− E.g.floating-pointrocketbooster• E− Speedsupsometask(e.g.arithmetic)byfactorSE− F isfractionofprogramthatusesthis”task”
CS61c Lecture18:ParallelProcessing- SIMD 42
1-F F
1-F F/ SE
ExecutionTime:
Speedup:
T0 (noE)TE (withE)
nospeedup speedupsection
Speedup=TO /TE =1/((1-F)+F/SE)

BigIdea:Amdahl’sLaw
43
Partnotspedup Partspedup
Example: Theexecutiontimeofhalf ofaprogramcanbeacceleratedbyafactorof2.Whatistheprogramspeed-upoverall?
CS61c Lecture18:ParallelProcessing- SIMD
Speedup=TO /TE =1/((1-F)+F/SE)
TO /TE =1/((1-F)+F/SE)=1/((1- 0.5)+0.5/2)=1.33<<2

Maximum“Achievable”Speed-Up
44
Question: Whatisareasonable#ofparallelprocessorstospeedupanalgorithmwithF=95%?(i.e.19/20th canbespedup)
a)Maximumspeedup: Smax =1/(1-0.95)=20butneedsSE=∞!
b) Reasonable“engineering”compromise:Equaltimeinsequentialandparallelcode:(1-F)=F/SE
SE =F/(1-F)=0.95/0.05=20S=1/(0.05+0.05)=10
CS61c
Speedup=1/((1-F)+F/SE)(SE->∞)=1/(1-F)

45
Iftheportionoftheprogramthatcanbeparallelizedissmall,thenthespeedupislimited
Inthisregion,thesequentialportionlimitstheperformance
500processorsfor19x
20processorsfor10x
CS61c

StrongandWeakScaling• Togetgoodspeeduponaparallelprocessorwhilekeepingtheproblemsizefixedisharderthangettinggoodspeedupbyincreasingthesizeoftheproblem.− Strongscaling:whenspeedupcanbeachievedonaparallelprocessorwithoutincreasingthesizeoftheproblem
− Weakscaling:whenspeedupisachievedonaparallelprocessorbyincreasingthesizeoftheproblemproportionallytotheincreaseinthenumberofprocessors
• Loadbalancingisanotherimportantfactor:everyprocessordoingsameamountofwork− Justoneunitwithtwicetheloadofotherscutsspeedupalmostinhalf
46CS61c Lecture18:ParallelProcessing- SIMD

PeerInstruction
47
Supposeaprogramspends80%ofitstimeinasquare-rootroutine.Howmuchmustyouspeedupsquareroottomaketheprogramrun5timesfaster?
CS61c Lecture18:ParallelProcessing- SIMD
Speedup=1/((1-F)+F/SE)RED: 5
GREEN: 20ORANGE: 500
Noneofabove

Administrivia• Midterm2isTuesdayduringclasstime!
− ReviewSession:Saturday10-12pm@HearstAnnexA1−Onedouble-sidedcribsheet;we’llprovidetheRISCVcard− BringyourID!We’llcheckit− RoomassignmentspostedonPiazza
• Project2pre-labdueFriday• HW4due11/3,butadvisabletofinishbythemidterm• Project2-2due11/6,butalsogoodtofinishbeforeMT2
48CS61c Lecture19:ThreadLevalParallelProcessing

Agenda• 61C– thebigpicture• Parallelprocessing• Singleinstruction,multipledata• SIMDmatrixmultiplication• Amdahl’slaw• Loopunrolling• Memoryaccessstrategy- blocking• AndinConclusion,…CS61c Lecture18:ParallelProcessing- SIMD 49

Amdahl’sLawappliedtodgemm• Measureddgemm performance
− Peak 5.5GFLOPS− Largematrices 3.6GFLOPS− Processor 24.8GFLOPS
• Whyarewenotgetting(closeto)25GFLOPS?− Somethingelse(notfloating-pointALU)islimitingperformance!− Butwhat?Possibleculprits:
§ Cache§ Hazards§ Let’slookatboth!
CS61c Lecture18:ParallelProcessing- SIMD 50

PipelineHazards– dgemm
CS61c Lecture18:ParallelProcessing- SIMD 51

LoopUnrolling
CS61c Lecture18:ParallelProcessing- SIMD 52
Compilerdoestheunrolling
Howdoyouverifythatthegeneratedcodeisactuallyunrolled?
4registers

Performance
NGflops
scalar avx unroll32 1.30 4.56 12.95160 1.30 5.47 19.70480 1.32 5.27 14.50960 0.91 3.64 6.91
CS61c Lecture18:ParallelProcessing- SIMD 53

Agenda• 61C– thebigpicture• Parallelprocessing• Singleinstruction,multipledata• SIMDmatrixmultiplication• Amdahl’slaw• Loopunrolling• Memoryaccessstrategy- blocking• AndinConclusion,…CS61c Lecture18:ParallelProcessing- SIMD 54

FPUversusMemoryAccess• Howmanyfloating-pointoperationsdoesmatrixmultiplytake?− F=2xN3 (N3 multiplies,N3 adds)
• Howmanymemoryload/stores?− M=3xN2 (forA,B,C)
• Manymorefloating-pointoperationsthanmemoryaccesses− q=F/M=2/3*N− Good,sincearithmeticisfasterthanmemoryaccess− Let’scheckthecode…
CS61c Lecture18:ParallelProcessing- SIMD 55

Butmemoryisaccessedrepeatedly
• q=F/M=1!(2loadsand2floating-pointoperations)
CS61c Lecture18:ParallelProcessing- SIMD 56
Innerloop:

CS61c Lecture18:ParallelProcessing- SIMD 57
Second-LevelCache(SRAM)
TypicalMemoryHierarchyControl
Datapath
SecondaryMemory(Disk
OrFlash)
On-ChipComponents
RegFile
MainMemory(DRAM)Data
CacheInstrCache
Speed(cycles):½’s 1’s 10’s 100’s-10001,000,000’sSize(bytes): 100’s 10K’sM’sG’sT’s
• Wherearetheoperands(A,B,C)stored?• WhathappensasNincreases?• Idea:arrangethatmostaccessesaretofastcache!
Cost/bit:highest lowest
Third-LevelCache(SRAM)

Sub-MatrixMultiplicationor:BeatingAmdahl’sLaw
CS61c 58

Blocking• Idea:
− Rearrangecodetousevaluesloadedincachemanytimes−Only“few”accessestoslowmainmemory(DRAM)perfloatingpointoperation
−à throughputlimitedbyFPhardwareandcache,notslowDRAM
− P&H,RISC-Veditionp.465
CS61c Lecture18:ParallelProcessing- SIMD 59

MemoryAccessBlocking
CS61c Lecture18:ParallelProcessing- SIMD 60

Performance
NGflops
scalar avx unroll blocking32 1.30 4.56 12.95 13.80160 1.30 5.47 19.70 21.79480 1.32 5.27 14.50 20.17960 0.91 3.64 6.91 15.82
CS61c Lecture18:ParallelProcessing- SIMD 61

Agenda• 61C– thebigpicture• Parallelprocessing• Singleinstruction,multipledata• SIMDmatrixmultiplication• Amdahl’slaw• Loopunrolling• Memoryaccessstrategy- blocking• AndinConclusion,…CS61c Lecture18:ParallelProcessing- SIMD 62

AndinConclusion,…• ApproachestoParallelism
− SISD,SIMD,MIMD(nextlecture)• SIMD
− Oneinstructionoperatesonmultipleoperandssimultaneously• Example:matrixmultiplication
− Floatingpointheavyà exploitMoore’slawtomakefast• Amdahl’sLaw:
− Serialsectionslimitspeedup− Cache
§ Blocking− Hazards
§ Loopunrolling
63CS61c Lecture18:ParallelProcessing- SIMD