cs252 spring 2017 graduate computer architecture lecture...
TRANSCRIPT

WU UCB CS252 SP17
CS252 Spring 2017Graduate Computer Architecture
Lecture 4:Pipelining
Lisa Wu, Krste Asanovichttp://inst.eecs.berkeley.edu/~cs252/sp17

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
LastTimeinLecture3
§ Microcoding,aneffectivetechniquetomanagecontrolunitcomplexity,inventedinerawhenlogic(tubes),mainmemory(magneticcore),andROM(diodes)useddifferenttechnologies
§ DifferencebetweenROMandRAMspeedmotivatedadditionalcomplexinstructions
§ TechnologyadvancesleadingtofastSRAMmadetechnologyassumptionsinvalid
§ Complexinstructionssetsimpedeparallelandpipelinedimplementations
§ Load/store,register-richISAs(pioneeredbyCray,popularizedbyRISC)performbetterinnewVLSItechnology
2

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
§ Instructionsperprogramdependsonsourcecode,compilertechnology,andISA
§ Cyclesperinstructions(CPI)dependsonISAandµarchitecture
§ Timepercycledependsupontheµarchitectureandbasetechnology
3
Time =Instructions Cycles TimeProgramProgram*Instruction*Cycle
“IronLaw”ofProcessorPerformance
Microarchitecture CPI cycletimeMicrocoded >1 shortSingle-cycleunpipelined 1 longPipelined 1 short

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
MemoryEXecuteDecodeFetch
Classic5-StageRISCPipeline
4
Registers
ALU
BA
DataCache
PC
InstructionCache
Store
Imm
Inst.Register
Writeback
Thisversiondesignedforregfiles/memorieswithsynchronousreadsandwrites.

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
CPIExamples
5
Time
Inst3
7cycles
Inst1 Inst2
5cycles 10cyclesMicrocoded machine
3instructions,22cycles,CPI=7.33Unpipelined machine
3instructions,3cycles,CPI=1
Inst1 Inst2 Inst3
Pipelinedmachine
3instructions,3cycles,CPI=1Inst1
Inst2Inst3 5-stagepipelineCPI≠5!!!

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
Instructionsinteractwitheachotherinpipeline§ Aninstructioninthepipelinemayneedaresourcebeingusedbyanotherinstructioninthepipelineà structuralhazard
§ Aninstructionmaydependonsomethingproducedbyanearlierinstruction- Dependencemaybeforadatavalue
à datahazard- Dependencemaybeforthenextinstruction’saddress
à controlhazard(branches,exceptions)
§ HandlinghazardsgenerallyintroducesbubblesintopipelineandreducesidealCPI>1
6

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
PipelineCPIExamples
7
Time
3instructionsfinishin3cyclesCPI=3/3=1
Inst1Inst2
Inst3
3instructionsfinishin4cyclesCPI=4/3=1.33
Inst1Inst2
Inst3Bubble
Inst1
Inst2Inst3
Bubble1
Bubble2
Measurefromwhenfirstinstructionfinishestowhenlastinstructioninsequencefinishes.
3instructionsfinishin5cyclesCPI=5/3=1.67
Inst3

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
ResolvingStructuralHazards
§ Structuralhazardoccurswhentwoinstructionsneedsamehardwareresourceatsametime- Canresolveinhardwarebystallingnewerinstructiontillolderinstructionfinishedwithresource
§ Astructuralhazardcanalwaysbeavoidedbyaddingmorehardwaretodesign- E.g.,iftwoinstructionsbothneedaporttomemoryatsametime,couldavoidhazardbyaddingsecondporttomemory
§ ClassicRISC5-stageintegerpipelinehasnostructuralhazardsbydesign-ManyRISCimplementationshavestructuralhazardsonmulti-cycleunitssuchasmultipliers,dividers,floating-pointunits,etc.,andcanhaveonregisterwriteback ports
8

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
TypesofDataHazards
9
Considerexecutingasequenceofregister-registerinstructionsoftype:
rk ß ri oprjData-dependence
r3 ß r1 opr2 Read-after-Writer5 ß r3 opr4 (RAW)hazard
Anti-dependencer3 ß r1 opr2 Write-after-Readr1 ß r4 opr5 (WAR)hazard
Output-dependencer3 ß r1 opr2 Write-after-Writer3 ß r6 opr7 (WAW)hazard

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
ThreeStrategiesforDataHazards
§ Interlock-Waitforhazardtoclearbyholdingdependentinstructioninissuestage
§ Bypass- Resolvehazardearlierbybypassingvalueassoonasavailable
§ Speculate-Guessonvalue,correctifwrong
10
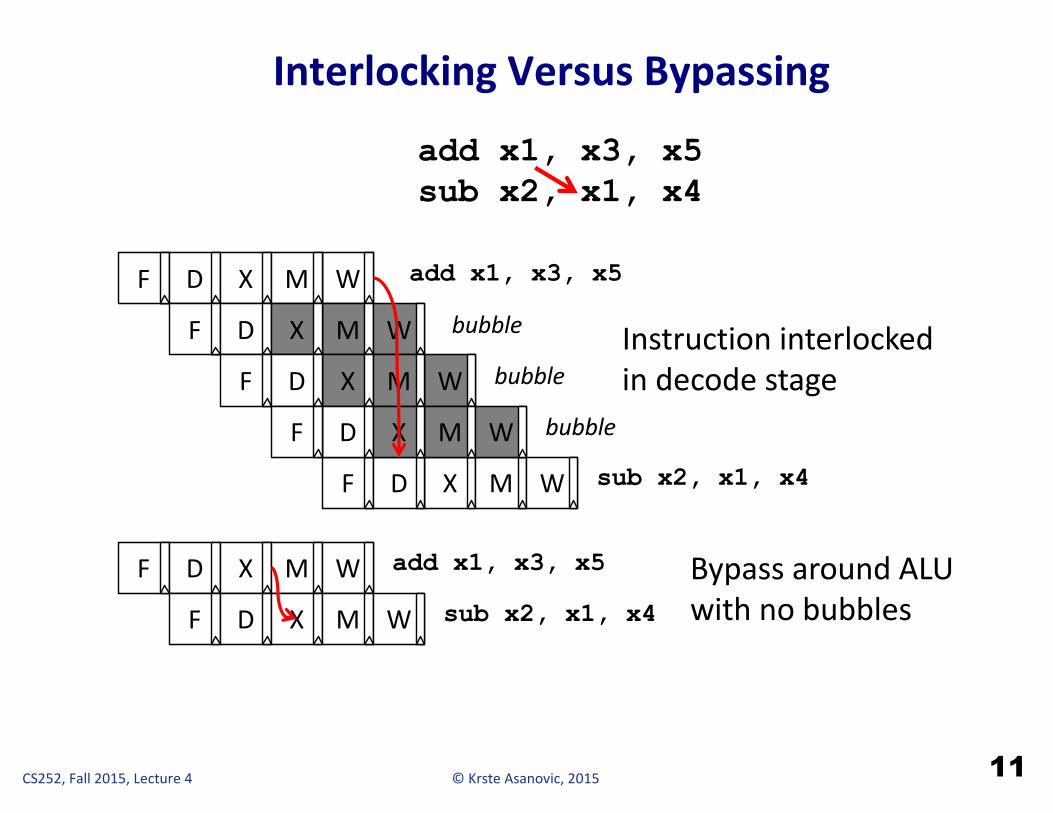
©KrsteAsanovic,2015CS252,Fall2015,Lecture4
InterlockingVersusBypassing
11
add x1, x3, x5sub x2, x1, x4
F add x1, x3, x5D
F
X
D
F
sub x2, x1, x4
W
M
X bubble
F
D
W
X M W
M W
W
M
D
X bubble
M
X bubble
D
F
Instructioninterlockedindecodestage
F D X M W add x1, x3, x5
F D X M W sub x2, x1, x4
BypassaroundALUwithnobubbles

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
MemoryEXecuteDecodeFetch
ExampleBypassPath
12
Registers
ALU
BA
DataCache
PC
InstructionCache
Store
Imm
Inst.Register
Writeback

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
MemoryEXecuteDecodeFetch
FullyBypassedDataPath
13
Registers
ALU
BA
DataCache
PC
InstructionCache
Store
Imm
Inst.Register
Writeback
F D X M W
F D X M W
F D X M W
F D X M W[AssumesdatawrittentoregistersinaWcycleisreadableinparallelDcycle(dottedline).Extrawritedataregisterandbypasspathsrequiredifthisisnotpossible.]

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
ValueSpeculationforRAWDataHazards
§ Ratherthanwaitforvalue,canguessvalue!
§ Sofar,onlyeffectiveincertainlimitedcases:- Branchprediction- Stackpointerupdates-Memoryaddressdisambiguation
14

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
ControlHazards
WhatdoweneedtocalculatenextPC?
§ ForUnconditionalJumps- Opcode,PC,andoffset
§ ForJumpRegister- Opcode,Registervalue,andoffset
§ ForConditionalBranches- Opcode,Register(forcondition),PCandoffset
§ Forallotherinstructions- Opcode andPC(andhavetoknowit’snotoneofabove)
15

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
MemoryEXecuteDecodeFetch
Controlflowinformationinpipeline
16
Registers B
A
DataCache
PC
InstructionCache
Store
Imm
Inst.Register
Writeback
PCknown Opcode,offsetknown
Branchcondition,Jumpregistervalueknown
ALU

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
EXecuteDecodeFetch
RISC-VUnconditionalPC-RelativeJumps
17
Registers B
A
InstructionCache
Imm
Inst.Register
ALU
PC_d
ecod
e
Add
Jump?PCJumpSelPC
_fetch
Kill
FKill
+4
[Killbitturnsinstructionintoabubble]

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
PipeliningforUnconditionalPC-RelativeJumps
18
M W
X M W
D X M W
j targetF D
F
target: add x1, x2, x3
X
D
F
bubble

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
BranchDelaySlots§ EarlyRISCsadoptedideafrompipelinedmicrocodeengines,andchangedISAsemanticssoinstructionafter branch/jumpisalwaysexecutedbeforecontrolflowchangeoccurs:0x100 j target0x104 add x1, x2, x3 // Executed before target…0x205 target: xori x1, x1, 7
§ Softwarehastofilldelayslotwithusefulwork,orfillwithexplicitNOPinstruction
19
M W
X M W
D X M W
j targetF D
F
target: xori x1, x1, 7
X
D
F
add x1, x2, x3

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
Post-1990RISCISAsdon’thavedelayslots
§ Encodesmicroarchitectural detailintoISA- c.f.IBM650drumlayout
§ Performanceissues- IncreasedI-cachemissesfromNOPsinunuseddelayslots- I-cachemissondelayslotcausesmachinetowait,evenifdelayslotisaNOP
§ Complicatesmoreadvancedmicroarchitectures- Consider30-stagepipelinewithfour-instruction-per-cycleissue
§ Betterbranchpredictionreducedneed- Branchpredictioninlaterlecture
20

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
EXecuteDecodeFetch
RISC-VConditionalBranches
21
Registers B
A
InstructionCache
Inst.
Inst.Register
ALU
PC_d
ecod
e
Add
Branch?PCSelPC
_fetch
Kill
FKill
+4
Cond?
PC_execute
Add
Kill
DKill

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
PipeliningforConditionalBranches
22
M W
X M W
D X M W
beq x1, x2, targetF D
F
target: add x1, x2, x3
X
D
F
bubble
bubble
F D X M W

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
PipeliningforJumpRegister
§ Registervalueobtainedinexecutestage
23
M W
X M W
D X M W
jr x1F D
F
target: add x5, x6, x7
X
D
F
bubble
bubble
F D X M W

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
Whyinstructionmaynotbedispatchedeverycycleinclassic5-stagepipeline(CPI>1)
§ Fullbypassingmaybetooexpensivetoimplement- typicallyallfrequentlyusedpathsareprovided- someinfrequentlyusedbypasspathsmayincreasecycletimeand
counteractthebenefitofreducingCPI§ Loadshavetwo-cyclelatency
- Instructionafterloadcannotuseloadresult- MIPS-IISAdefinedloaddelayslots,asoftware-visiblepipelinehazard
(compilerschedulesindependentinstructionorinserts NOPtoavoidhazard).RemovedinMIPS-II(pipelineinterlocksaddedinhardware)- MIPS:“Microprocessor withoutInterlockedPipelineStages”
§ Jumps/Conditionalbranchesmaycausebubbles- killfollowinginstruction(s)ifnodelayslots
24
Machineswithsoftware-visibledelayslotsmayexecutesignificantnumberofNOPinstructionsinsertedbythecompiler.NOPsreduceCPI,butincreaseinstructions/program!

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
TrapsandInterrupts
Inclass,we’llusefollowingterminology§ Exception:Anunusualinternaleventcausedbyprogramduringexecution- E.g.,pagefault,arithmeticunderflow
§ Trap:Forcedtransferofcontroltosupervisorcausedbyexception-Notallexceptionscausetraps(c.f.IEEE754floating-pointstandard)
§ Interrupt:Anexternaleventoutsideofrunningprogram,whichcausestransferofcontroltosupervisor
§ Trapsandinterruptsusuallyhandledbysamepipelinemechanism
25

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
HistoryofExceptionHandling
§ (AnalyticalEnginehadoverflowexceptions)§ FirstsystemwithtrapswasUnivac-I,1951
- Arithmeticoverflowwouldeither- 1.triggertheexecutionatwo-instructionfix-uproutineataddress0,or
- 2.attheprogrammer'soption,causethecomputertostop- LaterUnivac1103,1955,modifiedtoaddexternalinterrupts- Usedtogatherreal-timewindtunneldata
§ FirstsystemwithI/OinterruptswasDYSEAC,1954- Hadtwoprogramcounters,andI/OsignalcausedswitchbetweentwoPCs
- Also,firstsystemwithDMA(directmemoryaccessbyI/Odevice)- And,firstmobilecomputer(twotractortrailers,12tons+8tons)
26

WU UCB CS252 SP1727
DYSEAC:
front – control console and magnetic-wire input-output equipment
middle – the computer itself
middle rear – 512-word mercury delay-line memory
rear – air-conditioning

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
AsynchronousInterrupts
§ AnI/Odevicerequestsattentionbyassertingoneoftheprioritizedinterruptrequestlines
§ Whentheprocessordecidestoprocesstheinterrupt- ItstopsthecurrentprogramatinstructionIi,completingalltheinstructionsuptoIi-1 (preciseinterrupt)
- ItsavesthePCofinstructionIi inaspecialregister(EPC)- Itdisablesinterruptsandtransferscontroltoadesignatedinterrupthandlerrunninginthekernelmode
28

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
InterruptHandler
§ SavesEPCbeforeenablinginterruptstoallownestedinterruptsÞ- needaninstructiontomoveEPCintoGPRs- needawaytomaskfurtherinterruptsatleastuntilEPCcanbesaved
§ Needstoreada statusregister thatindicatesthecauseoftheinterrupt
§ Usesaspecial indirectjumpinstructionERET(return-from-environment)which- enablesinterrupts- restorestheprocessortotheusermode- restoreshardwarestatusandcontrolstate
29

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
SynchronousTrap
§ Asynchronoustrapiscausedbyanexceptiononaparticularinstruction
§ Ingeneral,theinstructioncannotbecompletedandneedstoberestarted aftertheexceptionhasbeenhandled- requiresundoingtheeffectofoneormorepartiallyexecutedinstructions
§ Inthecaseofasystemcalltrap,theinstructionisconsideredtohavebeencompleted- aspecialjumpinstructioninvolvingachangetoaprivilegedmode
30

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
ExceptionHandling5-StagePipeline
§ Howtohandlemultiplesimultaneousexceptionsindifferentpipelinestages?
§ Howandwheretohandleexternalasynchronousinterrupts?
31
PCInst.Mem D Decode E M
DataMem W+
IllegalOpcode Overflow Dataaddress
ExceptionsPCaddressException
AsynchronousInterrupts

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
ExceptionHandling5-StagePipeline
32
PCInst.Mem D Decode E M
DataMem W+
IllegalOpcode
Overflow DataaddressExceptions
PCaddressException
AsynchronousInterrupts
ExcD
PCD
ExcE
PCE
ExcM
PCM
Cause
EPC
KillDStage
KillFStage
KillEStage
SelectHandlerPC
KillWriteback
CommitPoint

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
ExceptionHandling5-StagePipeline
§ Holdexceptionflagsinpipelineuntilcommitpoint(Mstage)
§ Exceptionsinearlierpipestagesoverridelaterexceptionsforagiveninstruction
§ Injectexternalinterruptsatcommitpoint(overrideothers)
§ Ifexceptionatcommit:updateCauseandEPCregisters,killallstages,injecthandlerPCintofetchstage
33

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
SpeculatingonExceptions
§ Predictionmechanism- Exceptionsarerare,sosimplypredictingnoexceptionsisveryaccurate!
§ Checkpredictionmechanism- Exceptionsdetectedatendofinstructionexecutionpipeline,specialhardwareforvariousexceptiontypes
§ Recoverymechanism- Onlywritearchitecturalstateatcommitpoint,socanthrowawaypartiallyexecutedinstructionsafterexception
- Launchexceptionhandlerafterflushingpipeline
§ Bypassingallowsuseofuncommittedinstructionresultsbyfollowinginstructions
34

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
IssuesinComplexPipelineControl
35
IF ID WB
ALU Mem
Fadd
Fmul
Fdiv
Issue
GPRsFPRs
• Structuralconflictsattheexecutionstageifsome FPUormemoryunitisnotpipelinedandtakesmorethanonecycle• Structuralconflictsatthewrite-backstagedueto variablelatenciesofdifferentfunctionalunits• Out-of-orderwritehazardsduetovariablelatenciesofdifferentfunctionalunits• Howtohandleexceptions?

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
ComplexIn-OrderPipeline
§ Delaywriteback soalloperationshavesamelatencytoWstage- Writeportsneveroversubscribed
(oneinst.in&oneinst.outeverycycle)
- Stallpipelineonlonglatencyoperations,e.g.,divides,cachemisses
- Handleexceptionsin-orderatcommitpoint
36
CommitPoint
PCInst.Mem D Decode X1 X2
DataMem W+GPRs
X2 WFAdd X3
X3
FPRs X1
X2 FMul X3
X2FDiv X3
Unpipelineddivider
Howtopreventincreasedwriteback latencyfromslowingdownsinglecycleintegeroperations? Bypassing

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
In-OrderSuperscalarPipeline
§ Fetchtwoinstructionspercycle;issuebothsimultaneouslyifoneisinteger/memoryandotherisfloatingpoint
§ Inexpensivewayofincreasingthroughput,examplesincludeAlpha21064(1992)&MIPSR5000series(1996)
§ Sameideacanbeextendedtowiderissuebyduplicatingfunctionalunits(e.g.4-issueUltraSPARC &Alpha21164)butregfile portsandbypassingcostsgrowquickly
37
CommitPoint
2PC
Inst.Mem D
DualDecode X1 X2
DataMem W+GPRs
X2 WFAdd X3
X3
FPRs X1
X2 FMul X3
X2FDiv X3Unpipelineddivider

©KrsteAsanovic,2015CS252,Fall2015,Lecture4
Acknowledgements
§ ThiscourseispartlyinspiredbypreviousMIT6.823andBerkeleyCS252computerarchitecturecoursescreatedbymycollaboratorsandcolleagues:- Arvind (MIT)- JoelEmer (Intel/MIT)- JamesHoe(CMU)- JohnKubiatowicz (UCB)- DavidPatterson(UCB)
38