cs252/patterson lec 13.1 3/2/01 cs 213 lecture 6: multiprocessor 3: sgi altix programming and...
Post on 21-Dec-2015
223 views
TRANSCRIPT

CS252/PattersonLec 13.1
3/2/01
CS 213
Lecture 6:
Multiprocessor 3: SGI Altix Programming and Measurements

CS252/PattersonLec 13.2
3/2/01
SGI Altix Linux® Software
Development Tools
CS252/PattersonLec 13.3
3/2/01
Linux Software Development Experience
Programming LanguagesC,C++, Fortran, Java, Ada
Programming LanguagesC,C++, Fortran, Java, Ada
Libraries HPC, Math,
Parallel Programming
Libraries HPC, Math,
Parallel Programming+
Binary/Object CodeBinary/Object Code
Compile
OptimizationPerformance Analysis
• Leverage best of breed tools for Linux application development• Provides developers with a choice of tools

CS252/PattersonLec 13.4
3/2/01
Linux Software Development Environment
• Comprehensive Suite of Linux Software Development Tools– SGI sells complete suite of Intel compilers and tools which
cover» Programming Languages» Debuggers» Libraries» Parallel Programming» Performance analysis
– Other third-party tools are available from ISV partners– GNU and open source tools included with Linux distributions
• Performance Optimization– Compilers are optimized to achieve high performance
benchmark metrics– Performance Analysis tools to identify bottlenecks to improve
performance– Workload Management tools to optimize your application’s
performance with the rest of the system’s workload– SGI engineers assist with code optimization
• SGI’s Reconfigurable Compute RASC™ Software– Simplifies development and improves programmer efficiency
to the RASC hardware• Intel® Itanium® 2 and Xeon®-based Systems Support
– All compilers, tools, and libraries mentioned in this presentation support both except when noted otherwise

CS252/PattersonLec 13.5
3/2/01
Programming Languages: C & C++
• Intel C++ Compiler for Linux– Supports C & C++– Performance optimized for Intel Itanium 2 and
Intel Xeon processors– Compatible with GNU C & C++ compilers– OpenMP and Cluster OpenMP for shared
memory parallel programming– Auto-Parallelization support to improve
application performance by automatically threading of loops
– Available for purchase from SGI and Intel
•GNU C and C++ compilers – GCC which supports C and C++ is included
with Novell® SLESTM
– Free Software Foundation offers GCC in source form

CS252/PattersonLec 13.6
3/2/01
Programming Languages: Fortran
• Intel Fortran compilers for Linux – Supports Fortran 95– OpenMP and Cluster OpenMP for shared
memory parallel programming– Auto-Parallelization support to improve
application performance by automatically threading of loops
– Available for purchase from SGI and Intel
•GNU Fortran 77 – GCC supports Fortran 77 and is included
with Novell SLES – Free Software Foundation offers GCC in
source form– GNU Fortran 95 is still a project – see
http://g95.sourceforge.net/

CS252/PattersonLec 13.7
3/2/01
Programming Languages: Fortran
• Intel Fortran compilers for Linux – Supports Fortran 95– OpenMP and Cluster OpenMP for shared
memory parallel programming– Auto-Parallelization support to improve
application performance by automatically threading of loops
– Available for purchase from SGI and Intel
•GNU Fortran 77 – GCC supports Fortran 77 and is included
with Novell SLES – Free Software Foundation offers GCC in
source form– GNU Fortran 95 is still a project – see
http://g95.sourceforge.net/

CS252/PattersonLec 13.8
3/2/01
Parallel Programming• Message Passing Interface
– SGI Message Passing Interface (MPT)» MPI 1.2 with some customer requested MPI 2 APIs» Optimized for SGI® Altix® systems scaling to 100s of processes» For SGI Altix systems supporting Intel Itanium 2 processors only» Included with SGI ProPackTM for Linux
– Intel MPI Library» MPI-2 standard compliant Message Passing Interface library» On SGI Altix, scales to 90 processes (use SGI MPT for scaling to
>90 processes)» DAPLs available from Linux OS distributions
• DAPL for Altix available in SGI ProPack 5
» Available for purchase from SGI and Intel– Intel MPI Runtime Environment pre-installed on Altix XE Cluster
Solution» Any application using Intel MPI Library will run
– Voltaire MPI» Included with Voltaire IBHost and GridStack» DAPLs bundled with Voltaire IBHost and GridStack» Voltaire IBHost included with SGI’s systems containing
Infiniband» Pre-installed on Altix XE Cluster Solution
– Scali MPI Connect» MPI 1.2 compliant Message Passing Interface library» Available for purchase from Scali www.scali.com

CS252/PattersonLec 13.9
3/2/01
Parallel Programming (2)
•Parallel Programming Support in the Intel C++ and Fortran Compilers– OpenMP
» OpenMP directives convert serial applications into parallel application and enable potentially big performance gains from parallel execution on multi-core and SMP systems
– Auto-Parallelization» Improves application performance on
multiprocessor systems with automatic threading of loops
» Auto-Parallelization detects parallel loops capable of being executed safely in parallel and automatically generates multi-threaded code
CS252/PattersonLec 13.10
3/2/01
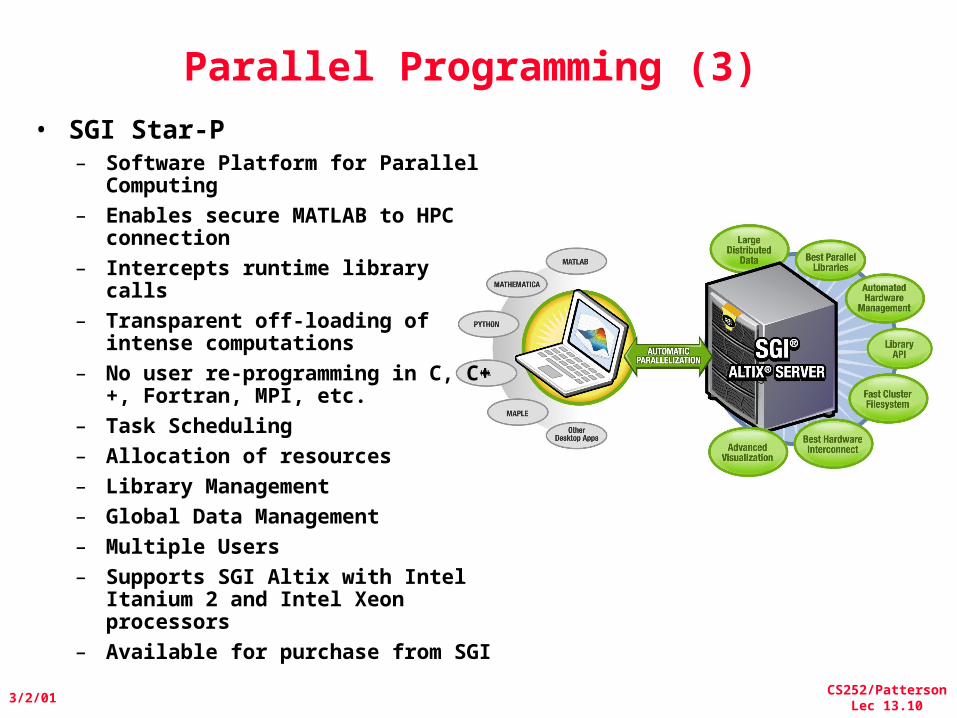
Parallel Programming (3)• SGI Star-P
– Software Platform for Parallel Computing
– Enables secure MATLAB to HPC connection
– Intercepts runtime library calls– Transparent off-loading of
intense computations– No user re-programming in C,
C++, Fortran, MPI, etc.– Task Scheduling– Allocation of resources– Library Management– Global Data Management– Multiple Users– Supports SGI Altix with Intel
Itanium 2 and Intel Xeon processors
– Available for purchase from SGI

CS252/PattersonLec 13.11
3/2/01
Parallel Programming (4)
• SGI Linux Trace– Kernel level trace data and Visualizer tool– Developed as a modified version of Linux Trace Toolkit– Requires a debug kernel containing the tracepoints– GUI interface to visualize and analyze trace data– For SGI Altix systems supporting Intel Itanium 2 processors
only– Included with SGI ProPack 5 for Linux
• Intel Trace Analyzer and Collector– For analyzing and optimizing parallel programs– GUI interface for visualizing parallel program behavior– Evaluates profiling statistics and load balancing– Analyzes performance of subroutines or code-blocks– Learns about communication patterns, parameters, and
performance data– Identifies communication hotspots– Decreases time to solution and increase application
efficiency– Available for purchase from SGI or Intel

CS252/PattersonLec 13.12
3/2/01
SGI’s Performance Analysis Tools
• SGI Linux Trace– Kernel level trace data and Visualizer tool– For SGI Altix systems supporting Intel Itanium 2
processors only– Included with SGI ProPack 5 for Linux
• Performance Co-PilotTM
– Monitor and manage system performance by collecting performance data and filtering to detect bottlenecks, cpu activity, and resource utilization metrics
– Well-suited for large servers, server clusters, multi-user DBMS environments, compute, web, file, video services
– For SGI Altix systems supporting Intel Itanium 2 and Intel Xeon processors
– Included in SGI ProPack for Linux

CS252/PattersonLec 13.13
3/2/01
Intel’s Performance Analysis Tools
• Intel VTune™ Performance Analyzer for Linux– Performance analysis tool for finding
bottlenecks in small and large applications– Uses sampling and call graph analysis – Integrated with the Eclipse development
environment– Latest version includes the Intel Memory
Checker Technology Preview for finding an application’s memory leaks and corruption
– Available for purchase from SGI or Intel
• Intel Trace Analyzer and Collector– For analyzing and optimizing parallel programs– Available for purchase from SGI or Intel

CS252/PattersonLec 13.14
3/2/01
Parallel/Concurrent Programming on the SGI Altix
Conley ReadJanuary 25, 2007
UC Riverside, Department of Computer Science

CS252/PattersonLec 13.15
3/2/01
Overview• The SGI Altix• Itanium 2 Features• Tools
– Schedutils• MPI Programming
• Star-P
• References• Try It

CS252/PattersonLec 13.16
3/2/01
About the SGIs– sgi-2.cs.ucr.edu
» 32 processor•Intel Itanium•1.5 GHz•128 GB (70 GB) RAM
– sgi-dev.cs.ucr.edu» 4 processor (2 sockets X 2 cores)
•Intel Xeon•3 GHz•8 GB RAM
» 2 Virtex 4 LX200 FPGAs•200,000 Logic Cells•80 MB SRAM

CS252/PattersonLec 13.17
3/2/01
SGI Altix 3000
• Runs one copy of Fedora or OpenSUSE Linux– Ported to SGI Hardware (Lessons from
IRIX)• Linux natively supports management of 32
processors
• 1 copy of Linux vs. 1 copy of Linux per node– Node sizes 32,64,128…?
• Programming for the 32 processor SGI is similar to programming for a 4 way SMP

CS252/PattersonLec 13.18
3/2/01
Global Shared Memory• Single Memory space
– All system resources– Processors– I/O
• SGI Altix 3000 uses NUMAflex (interconnect) to connect Itaniums with NUMAlink (ASIC)
• Creates SMP-like system
• Regardless of the node location of thread execution– Interprocess communication time is reduced

CS252/PattersonLec 13.19
3/2/01
The Itanium 2
• First Supercomputer using Itanium (1)– IBM Titan NOW Cluster at NCSA
• Unique Features– 16 Byte Atomic Operations– IA-64
» Fixed Length Instructions» Relies on Compile-time Optimizations» Branch Speculative Execution» Speculatively fetches data not in Cache
– Virtualization (Intel Vanderpool Technology or VT)– Explicitly Parallel Instruction Computing (EPIC)

CS252/PattersonLec 13.20
3/2/01
Tools
• GNU C Compiler – Installed• Intel C Compiler (icc) – Waiting for License
• Intel Debugger (idb)• GNU gdb – Debugger – Installed
– Some problems with code generated by icc
• Etnus TotalView – Better Debugger
• Intel Vtune – Available for purchase• sTrace – System Call Tracer• SGI Star-P – Currently being installed

CS252/PattersonLec 13.21
3/2/01
ICC
• Intel C Compiler (icc)– OpenMP – Simpler conversion from serial to
parallel execution– Auto-parallelization – Safe-loop parallelization– Fortran 95
• Optimizations for IA-64 Architecture– Itanium 2 uses IA-64

CS252/PattersonLec 13.22
3/2/01
Schedutils
• Change Process Scheduling Attributes– chrt [options] [pid | command]
» -p : Edit existing PID» --rr : Round Robin» --fifo : SCHED_FIFO» --other : SCHED_OTHER

CS252/PattersonLec 13.23
3/2/01
Schedutils
• Change Process CPU Affinity– taskset [options] [mask] [pid | command]
» -p : Edit existing PID» Mask
• 0x00000001 : Processor #0 …0001• 0x00000002 : Processor #2 …0010• 0x00000003 : Processor #0 and #1 …0011• …• 0xFFFFFFFFF : All Processors 11…11

CS252/PattersonLec 13.24
3/2/01
Parallel Programming Building Blocks
• SGI Altix supports common MPI libraries– Pthreads – not exactly threads– SGI Message Passing Interface– Intel MPI Library– Voltaire MPI – Installed– Scali MPI

CS252/PattersonLec 13.25
3/2/01
MPI Programming
• Create a new thread– fork() vs. pthreads_create()
» Hardware vs. POSIX
• Bind a thread to a processor– pthread_processor_bind_np()
• If you do not bind the pthread or modify the forked thread, the new thread will inherit the scheduling properties of the creating thread.

CS252/PattersonLec 13.26
3/2/01
Star-P
• The power of Supercomputers– MATLAB to SGI Altix over Network– Offloads computation tasks– Runtime call intercept– Perform day long computations in minutes
• Without the Hassle– No reprogramming in C MPI

CS252/PattersonLec 13.27
3/2/01
How to Login
• SGI Altix at UCR– sgi-2.cs.ucr.edu
» Use secure SSH protocol to connect• CS Username• CS Password
• SGI RASC Altix at UCR– sgi-dev.cs.ucr.edu
» Use secure SSH protocol to connect• CS Username• CS Password

CS252/PattersonLec 13.28
3/2/01
Try it
• ssh sgi-2.cs.ucr.edu
• cat /proc/cpuinfo• cat /proc/meminfo
• free• vmstat• uname -a

CS252/PattersonLec 13.29
3/2/01
References
• http://www.intel.com/products/processor/itanium2/
• http://en.wikipedia.org/wiki/Itanium2• http://
www.sgi.com/developers/technology/gsm.html• http://rlove.org/schedutils/• http://
www.llnl.gov/computing/tutorials/pthreads/

CS252/PattersonLec 13.30
3/2/01
NUMA Memory performance for Scientific Apps on SGI Origin
2000
• Show average cycles per memory reference in 4 categories:
• Cache Hit• Miss to local memory• Remote miss to home• 3-network hop miss to remote cache

CS252/PattersonLec 13.31
3/2/01
SGI Origin 2000
• a pure NUMA• 2 CPUs per node, • Scales up to 2048 processors• Design for scientific computation vs.
commercial processing• Scalable bandwidth is crucial to Origin

CS252/PattersonLec 13.32
3/2/01
Parallel App: Scientific/Technical
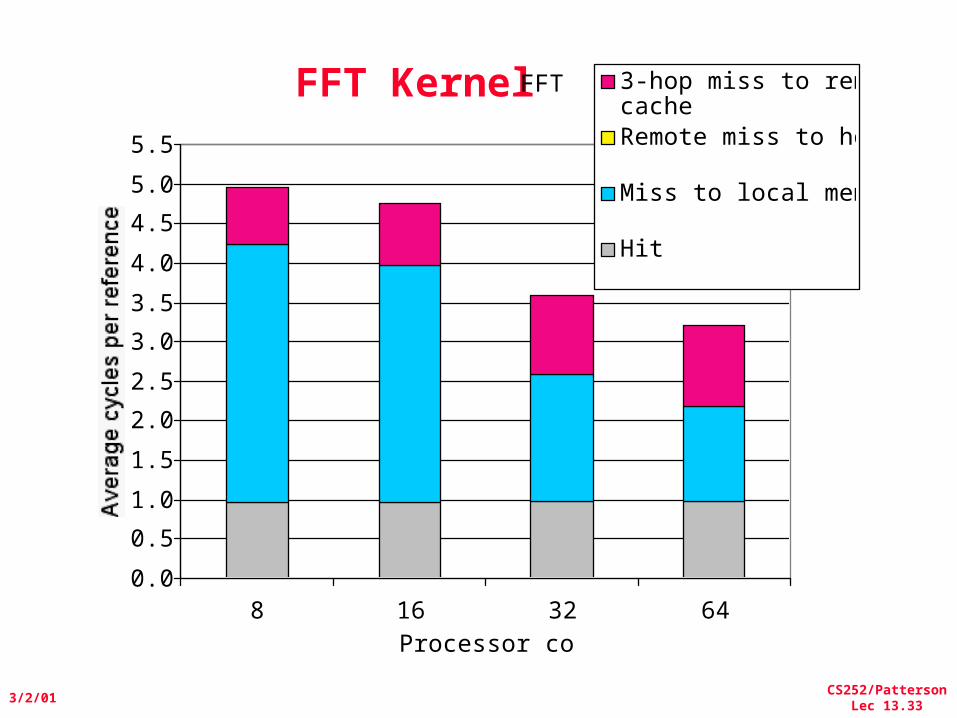
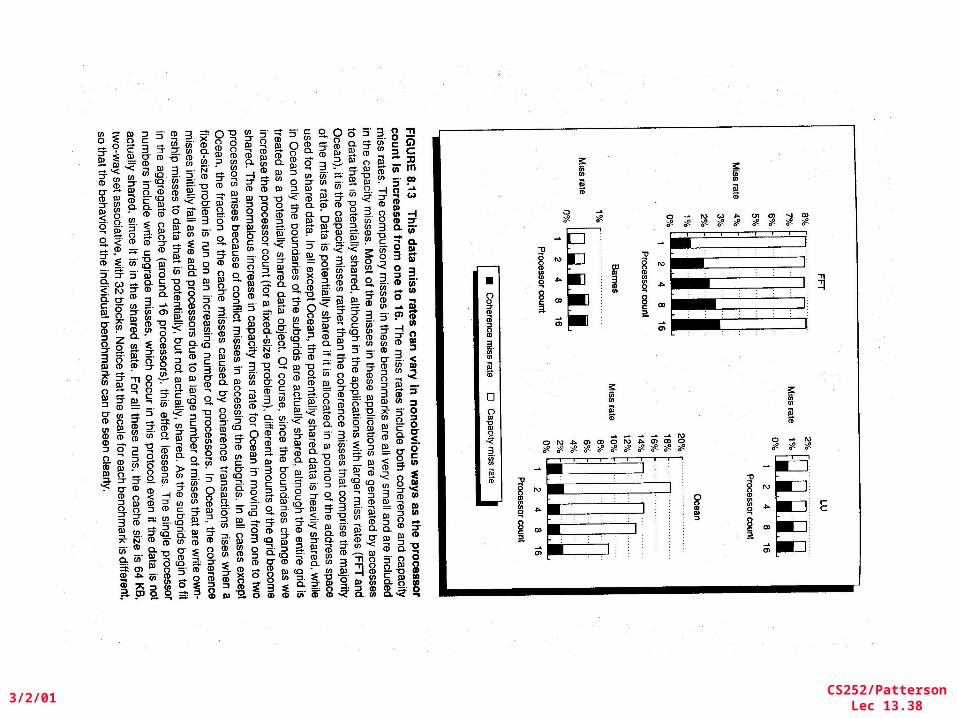
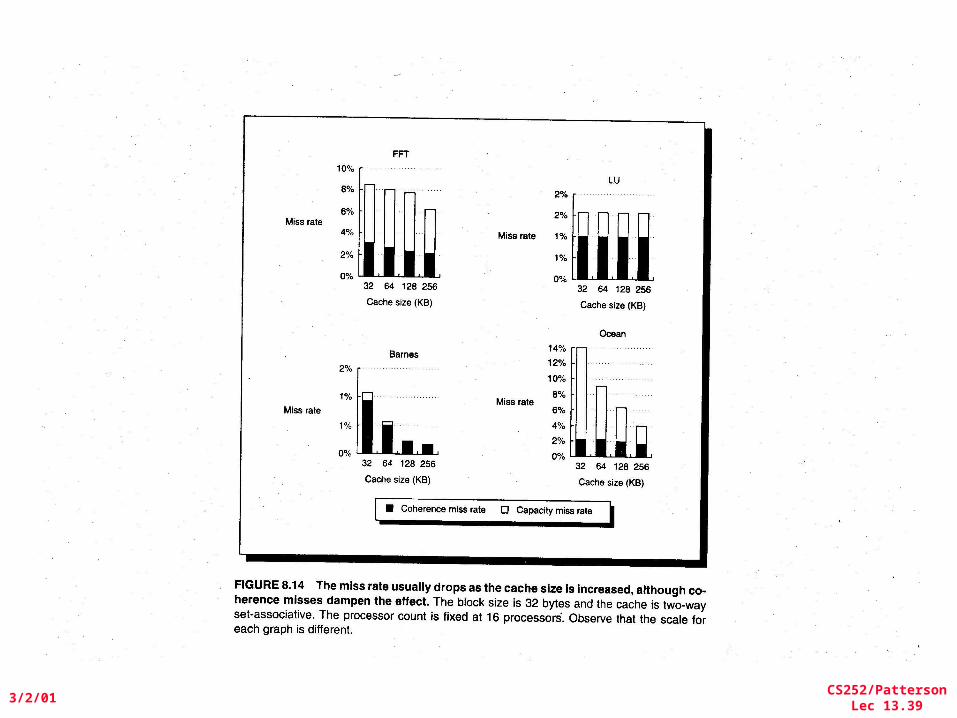
• FFT Kernel: 1D complex number FFT– 2 matrix transpose phases => all-to-all communication– Sequential time for n data points: O(n log n)– Example is 1 million point data set
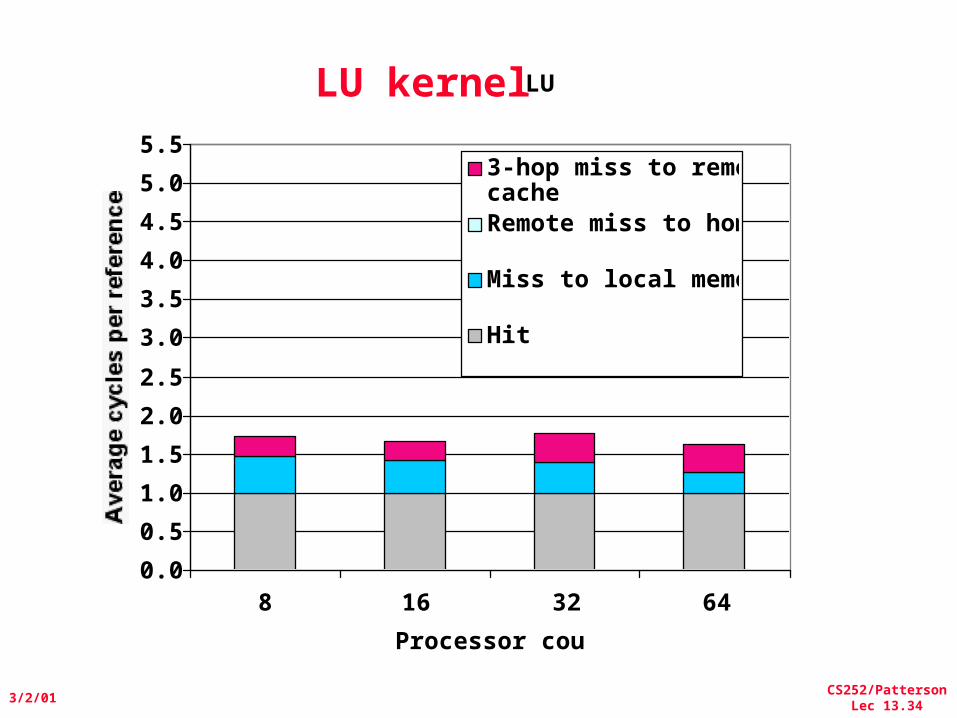
• LU Kernel: dense matrix factorization– Blocking helps cache miss rate, 16x16– Sequential time for nxn matrix: O(n3)– Example is 512 x 512 matrix
CS252/PattersonLec 13.33
3/2/01
FFT KernelFFT
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
8 16 32 64Processor count
Ave
rage
cyc
les
per
refe
renc
e3-hop miss to remotecacheRemote miss to home
Miss to local memory
Hit
CS252/PattersonLec 13.34
3/2/01
LU kernelLU
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
8 16 32 64
Processor count
Ave
rag
e cy
cles
per
ref
eren
ce
3-hop miss to remotecacheRemote miss to home
Miss to local memory
Hit

CS252/PattersonLec 13.35
3/2/01
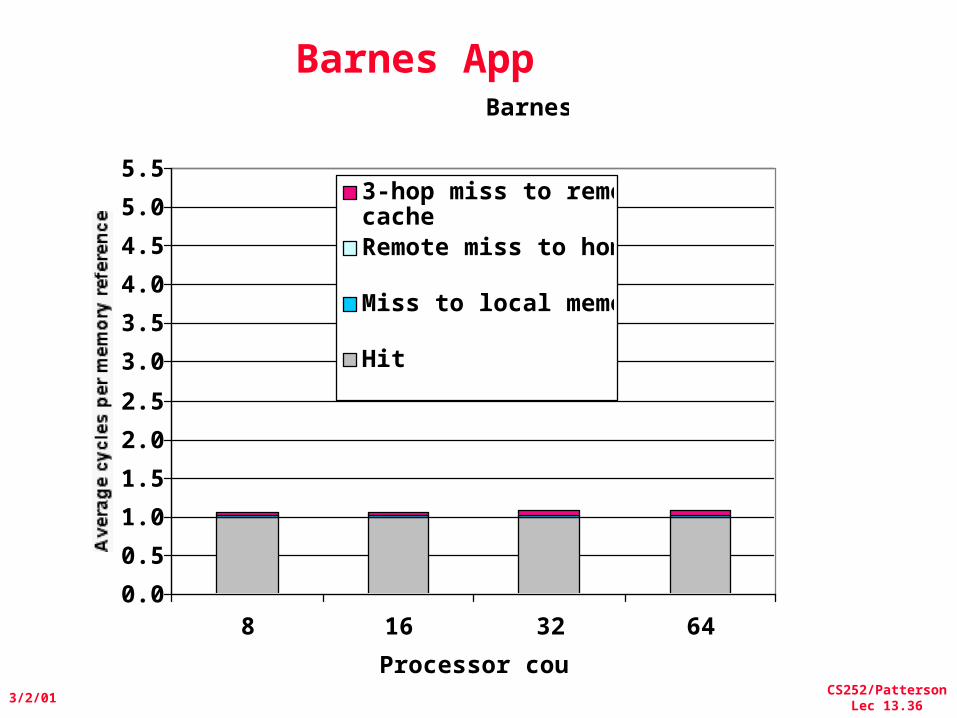
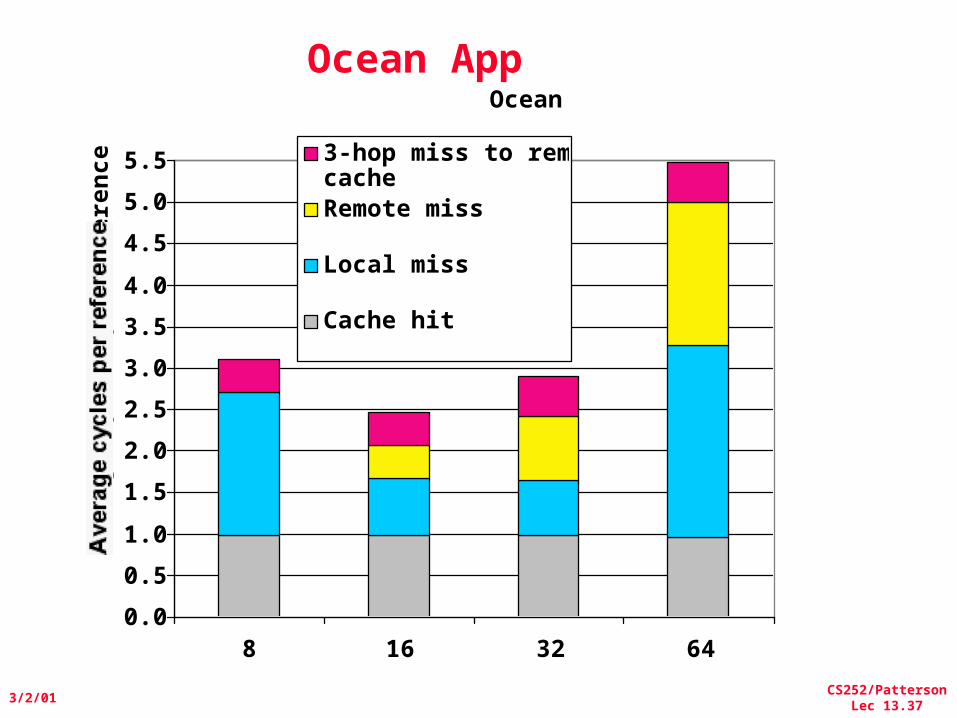
Parallel App: Scientific/Technical
• Barnes App: Barnes-Hut n-body algorithm solving a problem in galaxy evolution– n-body algs rely on forces drop off with distance;
if far enough away, can ignore (e.g., gravity is 1/d2)– Sequential time for n data points: O(n log n)– Example is 16,384 bodies
• Ocean App: Gauss-Seidel multigrid technique to solve a set of elliptical partial differential eq.s’– red-black Gauss-Seidel colors points in grid to consistently update points based on previous values of adjacent neighbors– Multigrid solve finite diff. eq. by iteration using hierarch. Grid– Communication when boundary accessed by adjacent subgrid– Sequential time for nxn grid: O(n2)– Input: 130 x 130 grid points, 5 iterations
CS252/PattersonLec 13.36
3/2/01
Barnes AppBarnes
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
8 16 32 64
Processor count
Av
era
ge
cy
cle
s p
er
me
mo
ry r
efe
ren
ce
3-hop miss to remotecacheRemote miss to home
Miss to local memory
Hit
CS252/PattersonLec 13.37
3/2/01
Ocean AppOcean
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
8 16 32 64
Ave
rag
e cy
cles
per
ref
eren
ce
3-hop miss to remotecacheRemote miss
Local miss
Cache hit
CS252/PattersonLec 13.38
3/2/01
CS252/PattersonLec 13.39
3/2/01
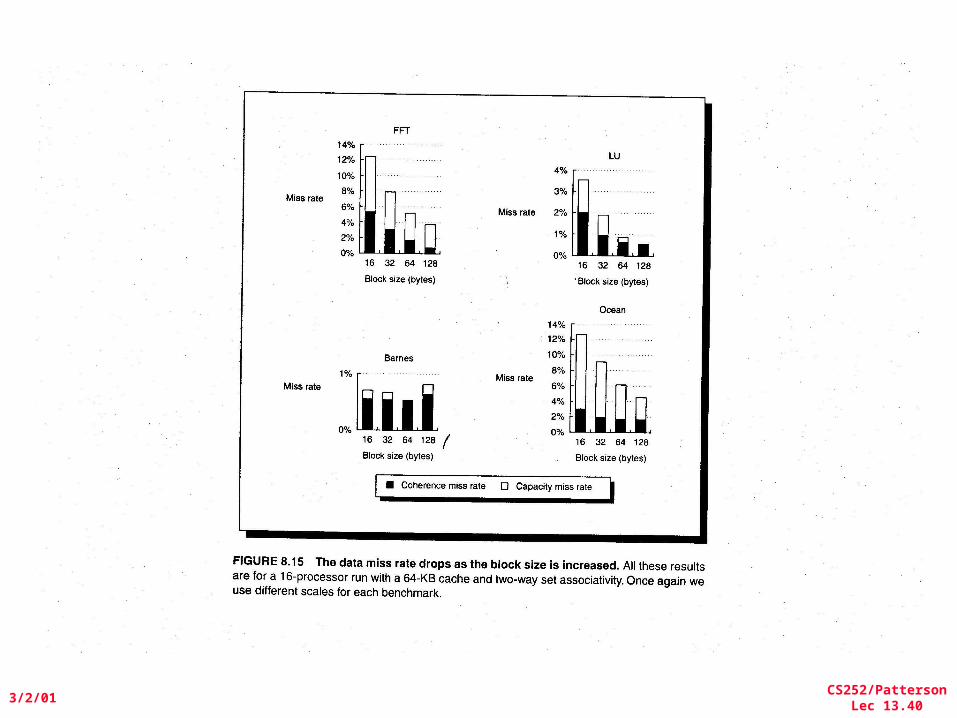
CS252/PattersonLec 13.40
3/2/01