cs626/449 : speech, nlp and the web/topics in ai programming (lecture 6: wiktionary; semantic...
TRANSCRIPT

CS626/449 : Speech, NLP and the Web/Topics in AI Programming
(Lecture 6: Wiktionary; semantic relatedness; how toread research papers)
Pushpak BhattacharyyaCSE Dept., IIT Bombay

Query Expansion
Definition• adding more terms (keyword spices) to a
user’s basic query Goal• to improve Precision and/or Recall
Example• User Query: car• Expanded Query: car, cars, automobile,
automobiles, auto, .. etc

Naïve Methods
• Finding synonyms of query terms and searching for synonyms as well
• Finding various morphological forms of words by stemming each word in the query
• Fixing spelling errors and automatically searching for the corrected form
• Re-weighting the terms in original query

Existing QE techniques
• Global methods (static; of all documents in collection)– Query expansion• Thesauri (or WordNet)• Automatic thesaurus generation
• Local methods (dynamic; analysis of documents in result set)– Relevance feedback– Pseudo relevance feedback

Relevance Feedback Example: Initial Query and Top 8 Results
• Query: New space satellite applications
• + 1. 0.539, 08/13/91, NASA Hasn't Scrapped Imaging Spectrometer• + 2. 0.533, 07/09/91, NASA Scratches Environment Gear From Satellite
Plan• 3. 0.528, 04/04/90, Science Panel Backs NASA Satellite Plan, But Urges
Launches of Smaller Probes• 4. 0.526, 09/09/91, A NASA Satellite Project Accomplishes Incredible
Feat: Staying Within Budget• 5. 0.525, 07/24/90, Scientist Who Exposed Global Warming Proposes
Satellites for Climate Research• 6. 0.524, 08/22/90, Report Provides Support for the Critics Of Using Big
Satellites to Study Climate• 7. 0.516, 04/13/87, Arianespace Receives Satellite Launch Pact From
Telesat Canada• + 8. 0.509, 12/02/87, Telecommunications Tale of Two Companies

Relevance Feedback Example: Expanded Query
• 2.074 new 15.106 space• 30.816 satellite 5.660 application• 5.991 nasa 5.196 eos• 4.196 launch 3.972 aster• 3.516 instrument 3.446 arianespace• 3.004 bundespost 2.806 ss• 2.790 rocket 2.053 scientist• 2.003 broadcast 1.172 earth• 0.836 oil 0.646 measure

Top 8 Results After Relevance Feedback
• + 1. 0.513, 07/09/91, NASA Scratches Environment Gear From Satellite Plan
• + 2. 0.500, 08/13/91, NASA Hasn't Scrapped Imaging Spectrometer• 3. 0.493, 08/07/89, When the Pentagon Launches a Secret Satellite,
Space Sleuths Do Some Spy Work of Their Own• 4. 0.493, 07/31/89, NASA Uses 'Warm‘ Superconductors For Fast Circuit• + 5. 0.492, 12/02/87, Telecommunications Tale of Two Companies• 6. 0.491, 07/09/91, Soviets May Adapt Parts of SS-20 Missile For
Commercial Use• 7. 0.490, 07/12/88, Gaping Gap: Pentagon Lags in Race To Match the
Soviets In Rocket Launchers• 8. 0.490, 06/14/90, Rescue of Satellite By Space Agency To Cost $90
Million

Pseudo Relevance Feedback
• Automatic local analysis• Pseudo relevance feedback attempts to
automate the manual part of relevance feedback.
• Retrieve an initial set of relevant documents.• Assume that top m ranked documents are
relevant.• Do relevance feedback

Computing Semantic Relatedness

Introduction• Computing Semantic Relatedness between
words has uses in various applications• Many measures exist, all using WordNet• Wiktionary models lexical semantic knowledge
similar to conventional WordNets• Wiktionary can be a substitute to WordNet• We see how Concept-Vector and PageRank is
used to measure Semantic Relatedness using Wiktionary as a corpus

Wiktionary• Freely available, multilingual, web based
dictionary in over 151 languages• Project by WikiMedia foundation• Written collaboratively by online volunteers• The English version has over 800,000 entries• Contains many relation types such as
synonyms, etymology, hypernymy, etc.

Comparison with WordNets
Expert-made WordNets Wiktionary
Constructors Linguists User Community on web
Construction Costs Significant Negligible
Schema Fixed Changing
Size Limited by construction costs
Quickly growing
Data Quality Editorial control Social control by community
Available Languages Major languages Many interconnected languages

Differences between WordNet & Wiktionary
• Wiktionary constructed by users on web rather than by expert linguists
• This reduces creation costs and increases size and speed of creation of entries
• Wiktionary is available in more languages• Wiktionary schema is fixed but not enforced• Older entries not updated hence inconsistent• Wiktionary entries not necessary complete and
may contain stubs. Not symmetrical also

Similarities Between Wiktionary & WordNet
• Wiktionary contains concepts connected to each other by lexical semantic relations
• Have glosses giving short descriptions• Size of all major languages are large• Wiktionary articles are monitored by the
community on the web just like WordNet

Structure of Wiktionary Entry• Is in XML format with tags for title, author,
creation date, comments, etc.• Meanings and various forms with examples• List of synonyms and related terms• Linked to other words represented by “[[ ]]”• Contains list of translations of word in other
languages and categories to which it belongs• Pronunciation and rhyming words as well

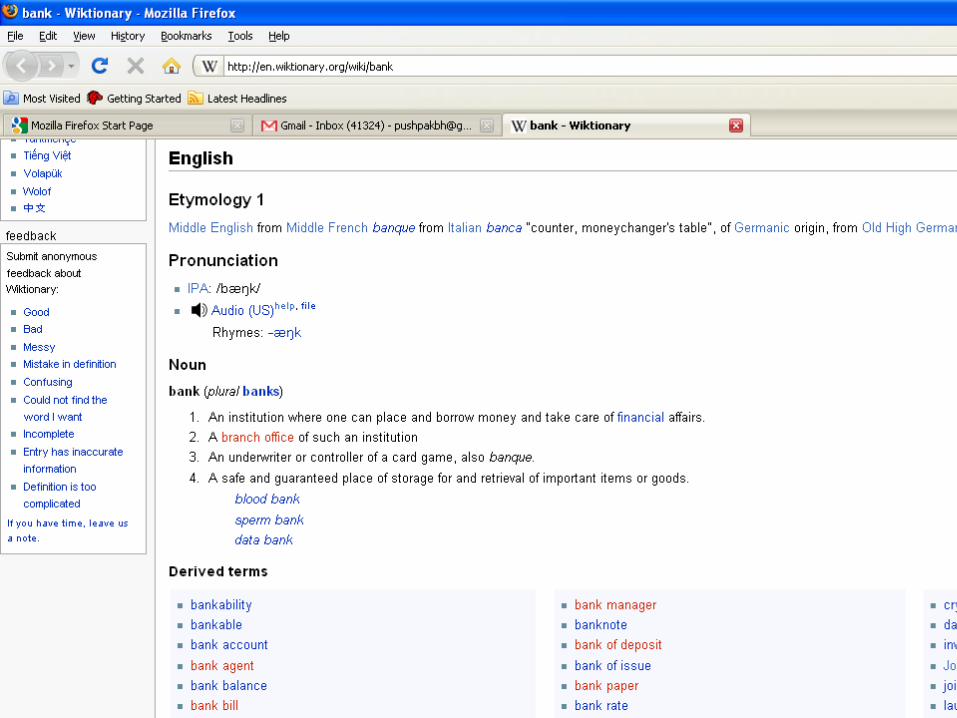
Example• http://en.wiktionary.org/wiki/bank• We can see the various meanings for the
different forms of the word “bank”• List of derived and related terms present• Contains translations into other languages


Semantic Relatedness• Defines resemblance between two words• More general concept than similarity• Similar and dissimilar entries can be related by
lexical relationships such as meronymy• Cars-petrol more related than cars-bicycle which
is more similar• Humans can judge easily unlike computers• Computers need vast amount of common sense
and world knowledge

Measures of Semantic Relatedness
• Concept – Vector Based Approach– Word represented as high dimensional concept vector,
v (w) = (v1,…, vn), n is no. of documents
– The tf.idf score is stored in vector element– Vector v represents word w in concept space– Semantic Relatedness can be calculated using:-
– This is also known as cosine similarity and the score varies from 0 to 1

Measures of Semantic Relatedness
• Path – Length Based Measure– Computes Semantic Relatedness in WordNet– Views it as a graph and sees path length between
concepts. “Shorter the path, the more related it is”– Good results when path consists of is-a links– Concepts are nodes and semantic relations between these
concepts can be treated as edges– SR calculated by relPL (c1, c2) = Lmax – L (c1, c2)
– Lmax is length of longest non-cyclic path and L (c1, c2) gives number of edges from concept c1 to c2

Measures of Semantic Relatedness
– Problem is that is considers all links to be uniform in distance which may not be the case always
– Many improvements using Information Content
• The Resnik Measure– Information content based relatedness measure– Higher information content specific to particular
topics, lower ones specific to more general topics– Carving fork – HIGH, entity – LOW– Idea is that two concepts are semantically related
proportional to the amount of information shared

Measures of Semantic Relatedness
– Considers position of nouns in is-a hierarchy– SR is determined by information content of lowest
common concept which subsumes both concept– For example: Nickel and Dime subsumed by Coin,
Nickel and Credit card by Medium of Exchange– P(c) is probability of encountering concept c.– If a is-a b, then p(a) is less than equal to p(b)– Information content calculated by formula:-
IC (concept) = – log (P (concept))

Measures of Semantic Relatedness
– Thus relatedness is given by:-Simres (c1, c2) = IC (LCS (c1, c2))
– Does not consider information content of the concepts themselves nor path length
– Problems faced is that many concepts might have the same subsumer thus having same score
– May get high measures on the basis of some inappropriate word senses. E.g tobacco and horse
– Newer methods such as Jiang-Conrath, Lin and Leacock-Chodorow measures

Page Rank• Developed by Larry Page and Sergei Brinn• Link analysis algorithm assigns numerical
weighting to hyperlinked set of documents• Measures relative importance of page in set• Link to a page is a vote of support which
increases the rank of that particular page• It is a probability distribution representing the
likelihood of a person randomly clicking ultimately ending up on a specific page

Pagerank based Algorithm• Assume universe has 4 pages A, B, C and D• Initial values of all the pages is 0.25• Now suppose B, C and D link only to A• Rank of A given by:-
• If B links to other pages also then rank of A:-
• L(B) is the number of outbound links from B

Pagerank based Algorithm (contd.)
• Page rank of U depends on rank of page V linking to U divided by number of links from V
• Page Rank can be given by general formula:-
• Formula applicable for pages which link to U• Thus we can see that the page ranks of all
pages in corpus will be equal to 1

Pagerank based Algorithm (contd.)
• Damping Factor : Imaginary surfer will stop clicking at links after some time.
• d is probability that user will continue clicking• Damping factor is estimated at 0.85 here• The new page rank formula using this is:-
• Now to get actual rank of a page we will have to iterate this formula many times
• Problem of Dangling Links

HOW TO READ RESEARCH PAPERS

Before that: How to read a book
• 1940 classic by Mortimer Adler• Revised and coauthored by Charles Van Doren
in 1972• Guidelines for critically reading good and
great books of any tradition

Three types of Knowledge
• Practical– though teachable, cannot be truly mastered without
experience• Informational– that only informational knowledge can be gained by
one whose understanding equals the author's• Comprehensive– comprehension (insight) is best learned from who first
achieved said understanding — an "original communication

Three Approaches to Reading (non-fiction)
• Structural– Understanding the structure and purpose of the book– Determining the basic topic and type of the book– Distinguish between practical and theoretical books, as well as determining
the field of study that the book addresses.– Divisions in the book, and that these are not restricted to the divisions laid out
in the table of contents. – Lastly, What problems the author is trying to solve.
• Interpretative– Constructing the author's arguments– Requires the reader to note and understand any special phrases and terms– Find and work to understand each proposition that the author advances, as
well as the author's support for those propositions.• Syntopical
– Judge the book's merit and accuracy• AKA, Structure-Proposition-Evaluation (SPE) method

VERY PRACTICALFrom Wikihow!

Steps
• Find a book• Buy/rent it and take it home• Settle into a comfortable chair or get comfortable
on the couch• Be calm and alert• Start the book by turning the pages• Read and enjoy it• Close book

Warnings
• Do not forget about your daily life. Check the time and take a break every once in a while.
• If the book is rented, then be very careful to not damage it, and return it on time.
• You will pay for lateness, and is not fun.• If you read the book in a bus/subway, then be
careful to not miss the station where you should go off.

Reading research papers
From Philip W. Fonghttp://www2.cs.uregina.ca/
~pwlfong/CS499/reading-paper.pdf

Comprehension: what does the paper say
• A common pitfall for a beginner is to focus solely on the technicalities
• Technical content is no way the only focus of a careful reading

Question-1: What is the research problem the paper attempts to address?
• What is the motivation of the research work? • Is there a crisis in the research field that the
paper attempts to resolve? • Is the research work attempting to overcome
the weaknesses of existing approaches? • Is an existing research paradigm challenged? • In short, what is the niche of the paper?

How do the authors substantiate their claims?
• What is the methodology adopted to substantiate the claims?
• What is the argument of the paper? • What are the major theorems? • What experiments are conducted? Data analyses?
Simulations? Benchmarks? User studies? Case studies? Examples?
• In short, what makes the claims scientific (as opposed to being mere opinions (science as opposed to science fiction)

What are the conclusions?• What have we learned from the paper? • Shall the standard practice of the field be
changed as a result of the new findings? • Is the result generalizable? • Can the result be applied to other areas of the
field? • What are the open problems? • In short, what are the lessons one can learn from
the paper?

VVIMP
• Look first to the abstract for answers to previous questions– The paper should be an elaboration of the
abstract.
• Every good paper tells a story– ask yourself, “What is the plot?” – The four questions listed above make up a plot
structure

Evaluation
• An integral component of scholarship: critical of scientific claims
• Fancy claims are usually easy to make but difficult to substantiate]
• Solid scholarship involves careful validation of scientific claims
• Reading research paper is therefore an exercise of critical thinking

Evaluation question-1: Is the research problem significant
• Is the work scratching minor itches? • Are the authors solving artificial problems • Does the work enable practical applications,
deepen understanding, or explore new design space?

Are the contributions significant?
• Is the paper worth reading? • Are the authors simply repeating the state of
the art? • Are there real surprises? • Are the authors aware of the relation of their
work to existing literature? • Is the paper addressing a well-known open
problem?

Are the claims valid?
• Have the authors been cutting corners (intentionally or unintentionally)?
• Has the right theorem been proven? Errors in proofs? Problematic experimental setup? Confounding factors? Unrealistic, artificial benchmarks? Comparing apples and oranges? Methodological misunderstanding?
• Do the numbers add up? • Are the generalizations valid? • Are the claims modest enough?

Synthesis: your own research agenda coming from the reading of the paper
• Creativity does not arise from the void. • Interacting with the scholarly community
through reading research papers is one of the most effective way for generating novel research agendas
• When you read a research paper, you should see it as an opportunity for you to come up with new research projects

Cautionary note
• Be very skeptical of work that is so “novel” that it – bears no relation to any existing work, – builds upon no existing paradigm, and yet – addresses a research problem so significant that it
promises to transform the world– Such are the signs that the author might not be
aware of existing literature on the topic– Repeat of work done decades ago?

Questions to help formulate research agenda
• What is the crux of the research problem?• What are some alternative approaches to address the
research problem?• What is a better way to substantiate the claim of the authors?• What is a good argument against the case made by the
authors?• How can the research results be improved?• Can the research results be applied to another context?• What are the open problems raised by this work?• Bottomline: Can we do better than the authors?