cse 803: image compression why? how much? how? related benefits and liabilities
Post on 19-Dec-2015
217 views
TRANSCRIPT

CSE 803: image compression
Why? How much? How?
Related benefits and liabilities.

topics
color table concept: .gif files brief notes on .jpg / wavelets, etc. motion-JPG concept metric for matching image regions motion compensation in MPG

Color table: cheaper graphics
image has 8-bit pixels
each 8-bit number is an index into a color look up table
can change colors without changing image
512 x 512 RGB image with 3x8-bit color values requires 750K Bytes.
512 x 512 8-bit codes = 256K Bytes
+ 256 x 3x8-bit color table =257K Bytes

GIF image format = image+table (plus other stuff) header information color table image pixels (up to 8 bits each) LZW
compressed RGB data is stored in the color table and NOT
in the image pixels themselves get good compression and ability to quickly
change the colors there are only 256 different colors for any single
image, but table RGB triples can be changed gif files are very good for line drawings

Types of compression
Lossless: no information is lost; every bit of the original image can be recovered.
if an image has no more than 256 different color triples in it, then color table can exactly recreate it.
Lossy: information is approximated; the original image cannot be recovered exactly.
Suppose there are 1000 color triples in the original image but we replace each by the closest one of a set of 256 triples in color table; e.g. (218, 58, 150) (220, 60, 150)

JPG primarily lossy
approximate 8 x 8 image blocks by sums of cosine waves
replace 64 intensities by coefficients suppose 1.3 cos ( f(x,y) ) + 2.5 cos
(g(x,y)) is a good approximation to the 8 x 8 intensity surface; then we only store 1.3 and 2.5.
2 coefficients replace 64 intensities

Interesting sidebar
can find 15 faces F1, F2, …, F15 such that your face looks like
a1F1+a2F2+ …+a15F15. therefore, your face is compressed to
15 numbers (weights) example below uses an average of only
4 faces how to find the “basis” F1, F2, …, F15
requires complex math and computing

“Eigenfaces” concept

Blackboard work on block matching
sum of squared pixel differences mean-squared difference sum of absolute values of pixel differences all of the above are 0 when blocks are the
same all of the above get large as more pixels are
different between the images

MPEG motion compression
Video frame N and N+1 shows slight movement: most pixels are same, just in different locations.

Can code frame N+d with displacments relative to frame N
for each 16 x 16 block in the 2nd image find a closely matching block in the 1st
image replace the 16x16 intensities by the
location in the 1st image (dX, dY) 256 bytes replaced by 2 bytes!

Frame approximation
Left is original video frame N+1. Right is set of best image blocks taken from frame N. (Work of Dina Eldin)

Best matching blocks between video frames N+1 to N (motion vectors)
The bulk of the vectors show the true motion of the airplane taking the pictures. The long vectors are incorrect motion vectors, but they do work well for image compression!
Best matches from 2nd to first image shown as vectors overlaid on the 2nd image. (Work by Dina Eldin.)

Motion vectors clustered to show 3 coherent regions
All motion vectors are clustered into 3 groups of similar vectors showing motion of 3 independent objects. (Dina Eldin)

Flow vectors resulting from camera motion
Zooming a camera gives results similar to those we see when we move forward or backward in a scene.
Panning effects are similar to what we see when we turn.

The Decathlete game
(Left) Man makes running movements with arms.
(Right) Display shows his avatar running. Camera controls speed and jumping according to his movements.
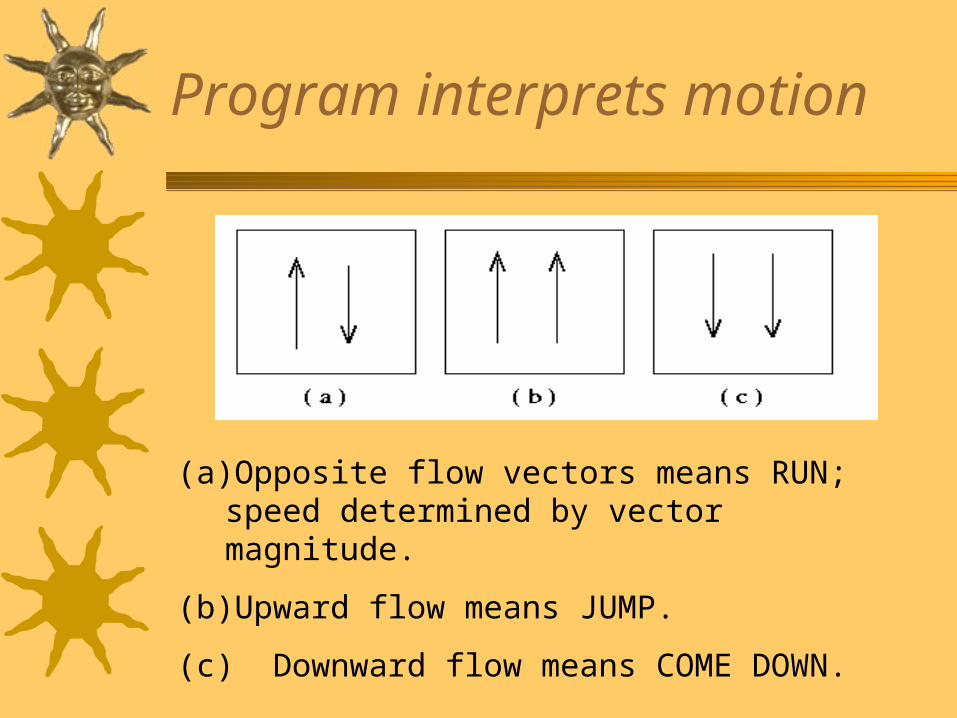
Program interprets motion
(a) Opposite flow vectors means RUN; speed determined by vector magnitude.
(b) Upward flow means JUMP.
(c) Downward flow means COME DOWN.

Program analysis display
(Top left) Video frame of the player.
(Middle left) Flow from several frames.
(Center) Jumping of the hurdles over time.

Requirements for interest points
Have unique multidirectional energyDetected and located with confidenceEdge detector not good (1D energy only)Corner detector is better (2D constraint)Autocorrelation can be used for matching
neighborhood from frame k to one from frame k+1
NHBD should have high energy

Matching interest point
Can use normalized cross correlation or image difference.
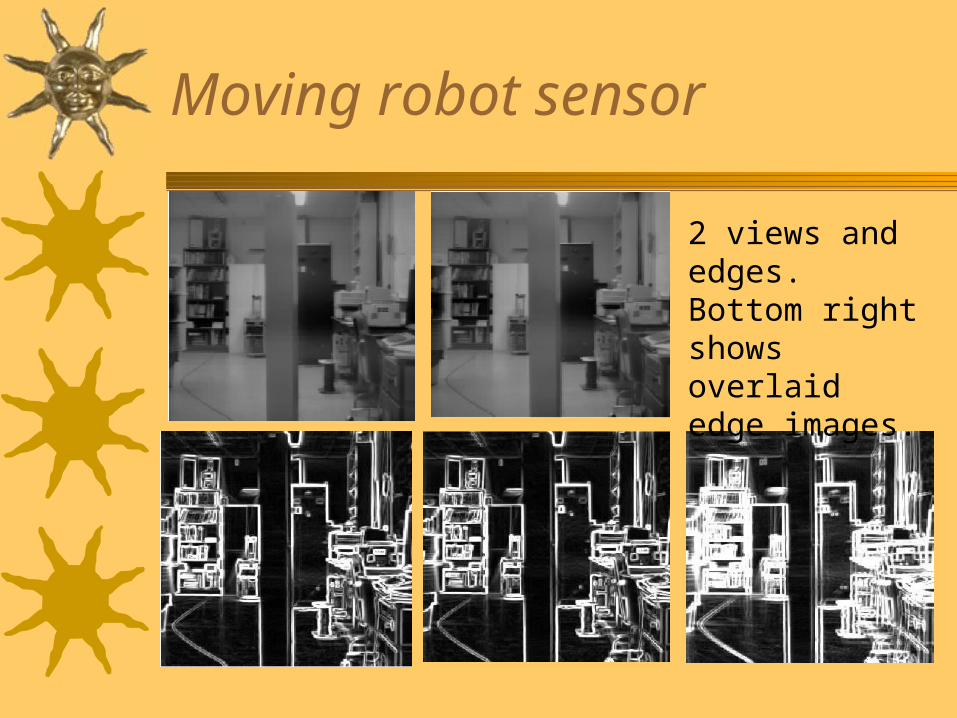
Moving robot sensor
2 views and edges. Bottom right shows overlaid edge images.

MPEG motion compression
Some frames are encoded in terms of others. Independent frame encoded as a still image using
JPEGPredicted frame encoded via flow vectors
relative to the independent frame and difference image.
Between frame encoded using flow vectors and independent and predicted frame.

MPEG compression method
I=F1 is an independent frame encoded via JPEG. P=F4 is a predicted frame. Each 16x16 block is matched to its closest match in P and represented by a motion vector and a difference image. Frames B1 and B2 between I and P are represented by two motion vectors per each 16 x 16 block.

Another idea
detect change in scene by histogram change – easier to do than match blocks
segment video automatically: Seinfeld restaurant vs Seinfeld apartment
can use motion vectors to dismiss changes due just to panning or zooming

Scene change: news TV

Detect via histogram change
(Top) gray level histogram of intensities from frame 1 in newsroom.
(Middle) histogram of intensities from frame 2 in newsroom.
(Bottom) histogram of intensities from street scene.
Histograms change less with pan and zoom of same scene.

Motion analysis on current frontier of computer vision
Surveillance and securityVideo segmentation and indexing (check
into Alex Jaimes IBM work, if time)Robotics and autonomous navigationBiometric diagnosticsTraining/teaching