cuda 6.5 overview - gtc on-demand …on-demand.gputechconf.com/gtc/2014/webinar/gtc-express...cuda...
TRANSCRIPT

Ujval Kapasi
CUDA 6.5 OVERVIEW

2
1 Supported Platforms
2 64-bit ARM
3 cuFFT Callbacks
4 CUDA Fortran Tools
5 Static Libraries and nvprune
6 Occupancy calculation API
7 Performance improvements
8 nvidia-smi improvements
AGENDA

3
SUPPORTED PLATFORMS
Fedora 20
RHEL & CentOS 5, 6
OpenSUSE 13.1
SLES 11 SP3
Ubuntu 12.04 LTS, 14.04
SteamOS 1.0-beta
Intel ICC 14.0.1 compiler
Windows XP, 7, 8.1
Windows Server 2008 R2 & 2012 R2
Visual Studio 2010, 2012, 2013 [Express]
Mac OSX 10.8, 10.9, 10.10
64-bit and 32-bit x86
64-bit and 32-bit ARM
Refer to release notes for more details, including important deprecations and removals.

4
GPUS PROPEL 64-BIT ARM INTO HPC
ARM64
Power Efficiency
System Configurability
Large, Open Ecosystem
GPU
Ultra-Fast Compute Perf
Hundreds of CUDA Apps
Large HPC Ecosystem
GPUs make ARM64 Competitive
in HPC from Day One

5
DEVELOPER ARM64 + GPU PLATFORM
Available now on the CUDA Downloads page
8-Core 2.4GHz CPU
Tesla K20 GPU Accelerator
Strong Single Thread Performance
1+ TFLOPS Floating Point
CUDA 6.5
+
Applied Micro X-Gene ARM64 CPU
with Tesla K20 GPU Accelerator
6
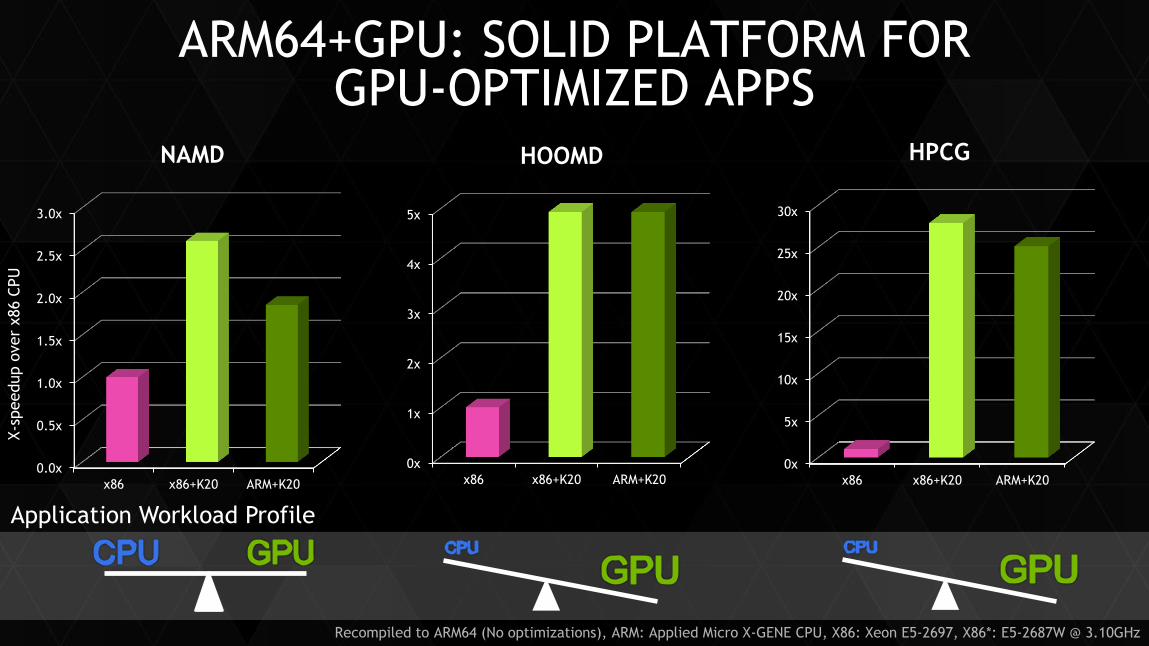
ARM64+GPU: SOLID PLATFORM FOR GPU-OPTIMIZED APPS
0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
3.0x
x86 x86+K20 ARM+K20
NAMD
0x
1x
2x
3x
4x
5x
x86 x86+K20 ARM+K20
HOOMD
0x
5x
10x
15x
20x
25x
30x
x86 x86+K20 ARM+K20
HPCG
Application Workload Profile
Recompiled to ARM64 (No optimizations), ARM: Applied Micro X-GENE CPU, X86: Xeon E5-2697, X86*: E5-2687W @ 3.10GHz
X-s
peedup o
ver
x86 C
PU
7
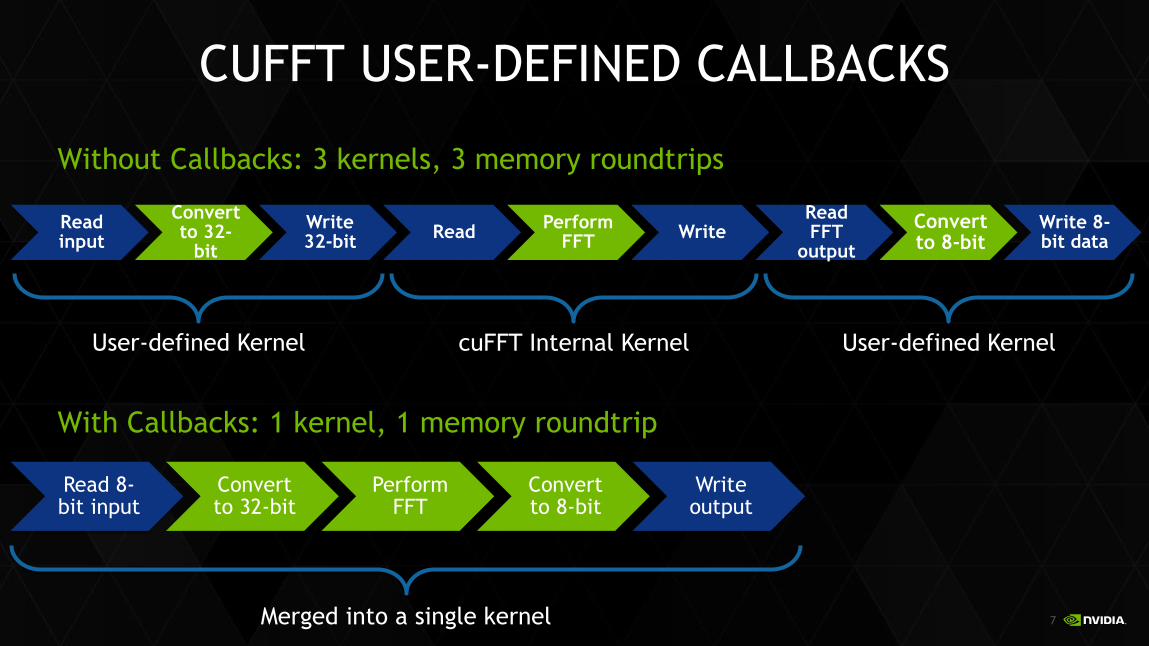
CUFFT USER-DEFINED CALLBACKS
Without Callbacks: 3 kernels, 3 memory roundtrips
With Callbacks: 1 kernel, 1 memory roundtrip
Read input
Convert to 32-
bit
Write 32-bit
Read Perform
FFT Write
Read FFT
output
Convert to 8-bit
Write 8-bit data
Read 8-bit input
Convert to 32-bit
Perform FFT
Convert to 8-bit
Write output
Merged into a single kernel
cuFFT Internal Kernel User-defined Kernel User-defined Kernel
8
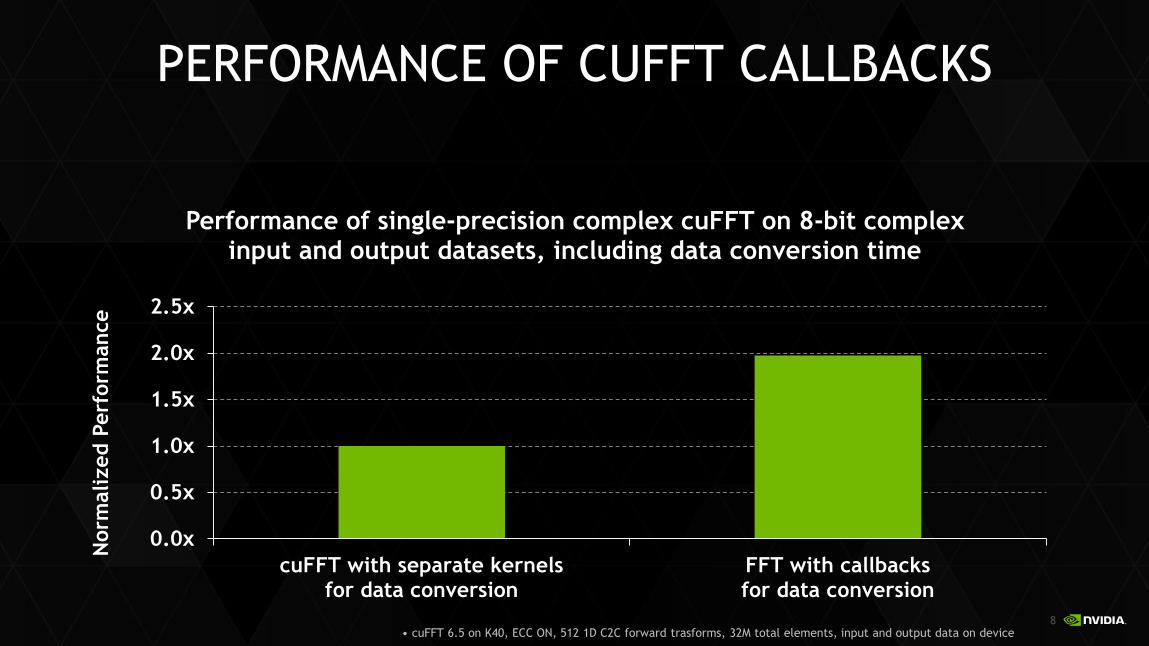
PERFORMANCE OF CUFFT CALLBACKS
0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
cuFFT with separate kernelsfor data conversion
FFT with callbacksfor data conversion
Norm
alized P
erf
orm
ance
Performance of single-precision complex cuFFT on 8-bit complex input and output datasets, including data conversion time
• cuFFT 6.5 on K40, ECC ON, 512 1D C2C forward trasforms, 32M total elements, input and output data on device
9
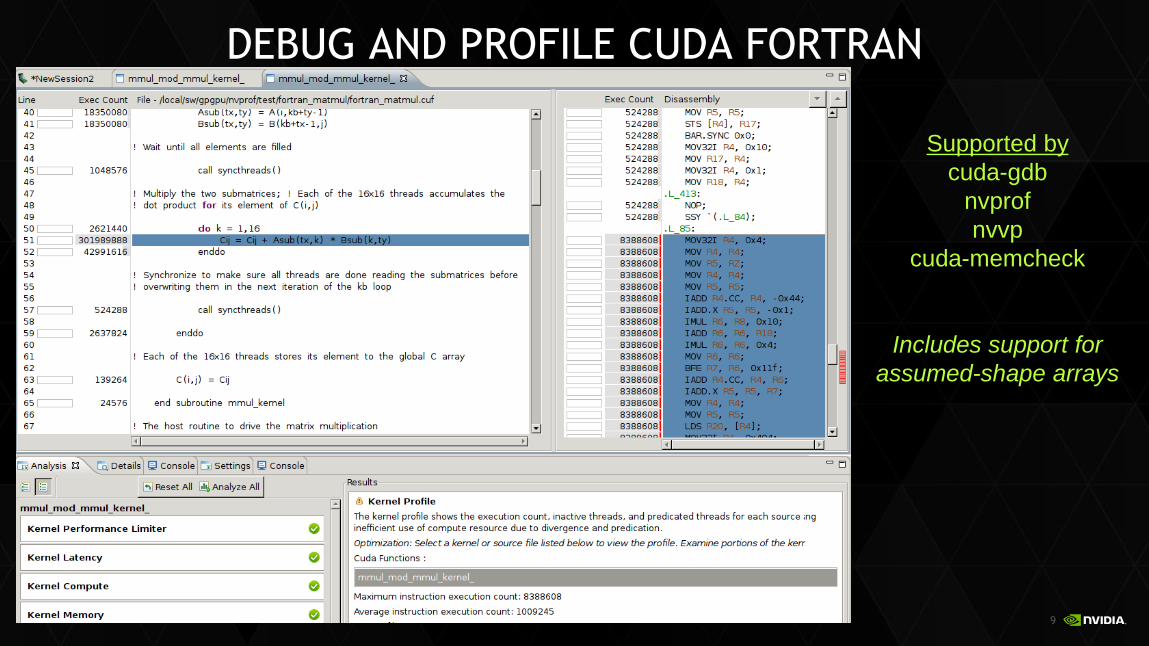
DEBUG AND PROFILE CUDA FORTRAN
Supported by
cuda-gdb
nvprof
nvvp
cuda-memcheck
Includes support for
assumed-shape arrays

10
STATIC LIBRARIES: CUFFT, CUBLAS, CUSPARSE, CURAND & NPP
A static version of these libraries is available on Linux and Mac
Linker selects only the required compilation units, reducing overall redistributable size
Example for an application that only uses cublasSgemm from cuBLAS
SHARED: nvcc test.c -lcublas -o test_shared
STATIC: nvcc test.c -lcublas_static -lculibos -o test_static
test_static 3.7MB
test_shared + libcublas.so.6.5.14 25MB
Simplifies application deployment

11
NVPRUNE BINARY UTILITY
Libraries (NVIDIA or 3rd Party) often include device code for many GPU generations
nvprune can minimize the device code shipped with your application
nvprune --arch sm_35 -o libcublas_static_pruned.a libcublas_static.a
nvcc test.c libcublas_static_pruned.a -lculibos -o test_static_pruned
test_static_pruned 2.8MB (~40% reduction vs. 3.7MB)
Works on static libraries and object files
Prune unnecessary device code from fatbinaries

12
CUDA OCCUPANCY CALCULATION API
cudaOccupancyMaxPotentialBlockSize()
Calculates block size that achieves maximum SM-level occupancy
Kernel block occupancy is closely correlated to performance:
(http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html#occupancy)
cudaOccupancyMaxPotentialBlockSize(&minGridSize, &blockSize, MyKernel, 0, N);
// Round up according to array size
gridSize = (N + blockSize - 1) / blockSize;
MyKernel<<< gridSize, blockSize >>>(array, N);
Simplifies selection of kernel launch block size

13
CUDA MULTI-PROCESS SERVER (MPS)
Concurrent execution of GPU tasks from >1 MPI Rank
FERMI 1 Queue for Tasks from all MPI Ranks
KEPLER 32 Parallel Queues for MPI Tasks

14
MPS KERNEL LAUNCHES 1.7X TO 2.0X FASTER
0
5
10
15
20
25
30
35
40
CUDA 6.0 CUDA 6.5 CUDA 6.0 CUDA 6.5
Back to Back Launches Launch and Synchronize
µse
c
1 Process 5 Processes 10 Processes
a<<<...>>>; a<<<...>>>;
a<<<...>>>; cudaDeviceSynchronize();

15
MATH PERFORMANCE IMPROVEMENTS
These double-precision functions are significantly improved:
[r]sqrt(), [r]hypot(), cbrt(), atan(), acosh()
These single-precision functions are significantly improved:
[r]hypot(), atanf(), expf(), exp10f(), expm1f()
698 GFLOPS
801 GFLOPS
0
200
400
600
800
1000
CUDA 6.0 CUDA 6.5
GFLO
PS
Performance of N-body application on Tesla K40
RSQRT Improvement Increases N-Body Performance by 15%
16
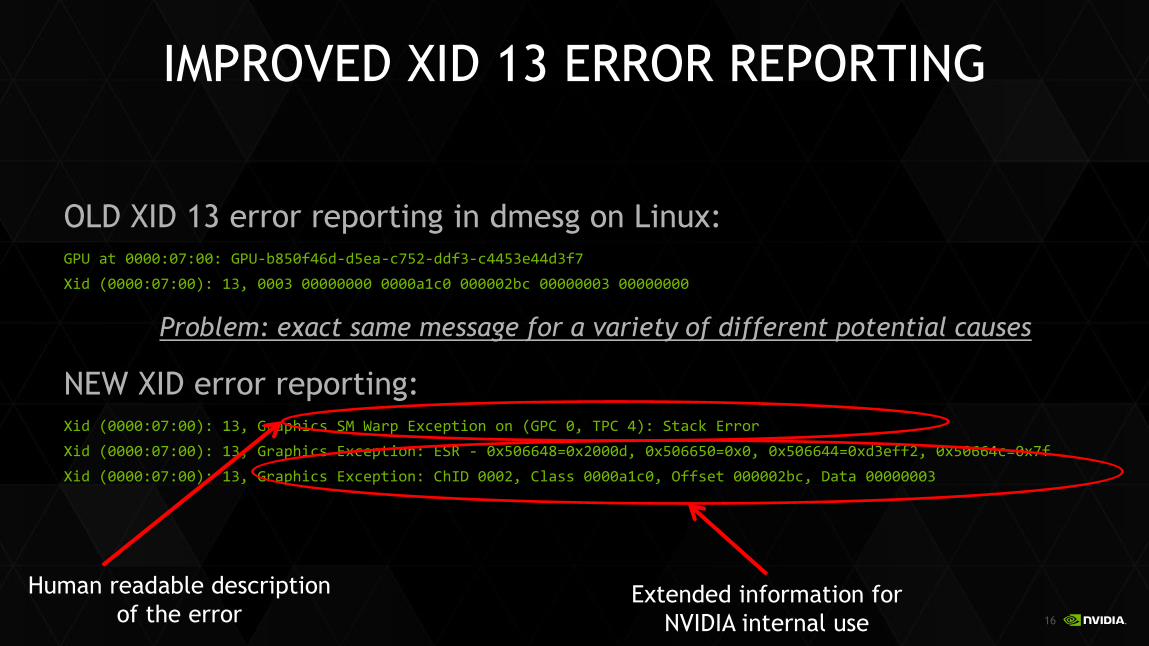
IMPROVED XID 13 ERROR REPORTING
OLD XID 13 error reporting in dmesg on Linux: GPU at 0000:07:00: GPU-b850f46d-d5ea-c752-ddf3-c4453e44d3f7
Xid (0000:07:00): 13, 0003 00000000 0000a1c0 000002bc 00000003 00000000
Problem: exact same message for a variety of different potential causes
NEW XID error reporting: Xid (0000:07:00): 13, Graphics SM Warp Exception on (GPC 0, TPC 4): Stack Error
Xid (0000:07:00): 13, Graphics Exception: ESR - 0x506648=0x2000d, 0x506650=0x0, 0x506644=0xd3eff2, 0x50664c=0x7f
Xid (0000:07:00): 13, Graphics Exception: ChID 0002, Class 0000a1c0, Offset 000002bc, Data 00000003
Human readable description
of the error Extended information for
NVIDIA internal use

17
GPUDIRECT P2P AND RDMA
GPUDirect Comm Matrix
GPU0 GPU1 GPU2 mlx5_0 mlx5_1 CPU Affinity
GPU0 X PIX SOC PHB SOC 0,1,2,3,4,5,6,7,8,9
GPU1 PIX X SOC PHB SOC 0,1,2,3,4,5,6,7,8,9
GPU2 SOC SOC X SOC PHB 10,11,12,13,14,15,16,17,18,19
mlx5_0 PHB PHB SOC X SOC
mlx5_1 SOC SOC PHB SOC X
Legend:
X = Self
SOC = Path traverses a socket-level link (e.g. QPI)
PHB = Path traverses a PCIe host bridge
PXB = Path traverses multiple PCIe internal switches
PIX = Path traverses a PCIe internal switch
CPU Affinity = The cores that are most ideal for NUMA
Healthmon measures bandwidth between GPU and 3rd-party RDMA device
Healthmon shows traversal expectations and potential bandwidth bottlenecks
Peer-to-peer path between 0 and mlx5_0 must cross a PCIe host bridge.
For NUMA binding
GPU0/1: Single
Tesla K10
GPU2: K40 on a
second PCI Host
Bridge
mlx5_0/1 are
Mellanox IB cards
NVSMI shows topology

18
NVSMI STATS INTERFACE
0
500
1000
21:38:53 21:39:10 21:39:27 21:39:45 21:40:02 21:40:19 21:40:36 21:40:54
0
50
0
200
Power
Draw
Power
Capping
Clock
Changes W
att
s
Se
cs
MH
z
procClk , 1395544840748857, 324
memClk , 1395544840748857, 324
pwrDraw , 1395544841083867, 20
pwrDraw , 1395544841251269, 20
gpuUtil , 1395544840912983, 0
violPwr , 1395544841708089, 0
procClk , 1395544841798380, 705
memClk , 1395544841798380, 2600
pwrDraw , 1395544841843620, 133
xid , 1395544841918978, 31
pwrDraw , 1395544841948860, 250
violPwr , 1395544842708054, 345
Clocks Idle
Clocks boost
Power cap
XID error
Tim
elin
e
New data buffers maintained by NVIDIA driver, time-stamped
Violation counters, power readings, clock changes, XID errors.
Allows logging of high fidelity data through NVSMI, with no perf impact

19
ADDITIONAL RESOURCES
Parallel Forall: devblogs.nvidia.com/parallelforall
CUDACasts at bit.ly/cudacasts
Self-paced labs: nvidia.qwiklab.com
90-minute labs, simply need a supported web browser
Documentation: docs.nvidia.com
Technical Questions:
NVIDIA Developer forums devtalk.nvidia.com
Search or ask on stackoverflow.com/tags/cuda
developer.nvidia.com/cudazone

20
CUDA REGISTERED DEVELOPER PROGRAM
Exclusive access to pre-release CUDA Installers
Submit bugs and features requests to NVIDIA
Keep informed about latest releases and training opportunities
Access to exclusive downloads
Exclusive activities and special offers
Sign up for free at: www.nvidia.com/paralleldeveloper