curso de postgrado en herramientas estadísticas … · medidas de similaridad estandarización de...
TRANSCRIPT

Curso de Postgrado en Herramientas Estadísticas Avanzadas:
ANÁLISIS MULTIVARIANTE PARA INVESTIGACIÓN EN SISTEMASANÁLISIS MULTIVARIANTE PARA INVESTIGACIÓN EN SISTEMAS AGROPECUARIOS
ANÁLISIS CLUSTERANÁLISIS CLUSTER
Prof. Dr. José PereaDpto. Producción Animal

ÁANÁLISIS DE CONGLOMERADOS
1. Introducción
2 Medidas de similaridad2. Medidas de similaridad
3. Análisis jerárquico
4. Análisis no jerárquico
5. Elección entre los distintos tipos de análisisp
6. Caso práctico

Análisis de interdependenciasclasificación
Relaciónentre
variables
Relaciónentrecasos
Relaciónentre
objetosj
Métricas No métricas
componentesprincipales
análisisfactorial
análisiscorrespondencias
análisiscluster
escalamientomultidimensional

Técnica para clasificar observaciones en grupos:
introducción
Técnica para clasificar observaciones en grupos:
- Cada grupo sea homogéneo respecto a las variablesutilizadas para su formaciónutilizadas para su formación
- Que los grupos sean lo más distintos posible unos deotros respectos a las variables consideradasotros respectos a las variables consideradas
- La composición de los grupos es desconocida a priori (enel análisis discriminante o en la regresión logística se conocenel análisis discriminante o en la regresión logística se conocenlos grupos)

Por ejemplo:
introducción
- Por ejemplo:
- Clasificar los animales de un rebaño según suscaracterísticas productivas y aptitudes para la explotacióncaracterísticas productivas y aptitudes para la explotaciónecológica (producción de leche, producción de carne,edad, enfermedades, rusticidad, prolificidad, fertilidad,aplomos, raza, etc.)
- Clasificar explotaciones ganaderas según su implicaciónen funciones no productivas

P d l áli i l t
introducción
Pasos del análisis cluster:
- Se tiene información de n casos y k variables
- Se establece un indicador que nos diga en qué medida cadapar de observaciones se parece entre sí (distancia osimilaridad)similaridad)
- Se crean los grupos de acuerdo a la medida de similaridad odistancia anterior Hay dos tipos de creación de grupos ydistancia anterior. Hay dos tipos de creación de grupos yvarios métodos de agrupación
Se describen los grupos obtenidos y se comparan unos con- Se describen los grupos obtenidos y se comparan unos conotros
Validación del análisis- Validación del análisis

Medidas de similaridad
medidas de similaridad
Medidas de similaridad
Ejemplo
Se tiene información de la producción de leche y del rendimiento d 8 bquesero de 8 cabras
Cabra Producción leche Rendimiento quesero1 225 102 225 153 210 303 0 304 200 355 325 206 375 256 375 257 450 408 500 35

medidas de similaridad
45
35
40
20
25
30
10
15
20
0
5
100 250 400 550

medidas de similaridad
45
35
40
20
25
30
10
15
20
0
5
100 250 400 550

M did d i il id d i bl ét i
medidas de similaridad
Medidas de similaridad para variables métricas
- Distancia euclídea (D) entre dos casos: D = √Σ (Xip – Xjp)2
- En el ejemplo:
- D12 = √ (225 – 225)2 + (15 – 10)2 = 512 ( ) ( )
- D13 = √ (210 – 225)2 + (30 – 10)2 = 196
Cabra Producción leche Rendimiento quesero1 225 101 225 102 225 153 210 304 200 354 200 355 325 206 375 257 450 408 500 35

Di t i líd l d d (D2) t d
medidas de similaridad
- Distancia euclídea al cuadrado (D2) entre dos casos:
- Menos exigente que el anterior
- D = Σ (Xip – Xjp)2
- En el ejemplo:j p
- D12 = (225 – 225)2 + (15 – 10)2 = 25
D = (210 225)2 + (30 10)2 = 38425- D13 = (210 – 225)2 + (30 – 10)2 = 38425
Cabra Producción leche Rendimiento queseroq1 225 102 225 153 210 303 210 304 200 355 325 206 375 256 375 257 450 408 500 35

Di t i d Mi k ki
medidas de similaridad
- Distancia de Minkowski:
- M = [Σ (Xip – Xjp)2]1/n
- Los dos casos anteriores son un caso particular (n=2)de la distancia de Minkowski
- Distancia city block o “Manhatan”:
M = Σ (X X )- M = Σ (Xip – Xjp)

medidas de similaridad
45
35
40c
20
25
30 b
10
15
20a
0
5
10
0100 250 400 550

medidas de similaridad
Estandarización de los datos:Estandarización de los datos:
- Las distancias de similaridad son muy sensibles a lasunidades en que estén medidas las variables.q
- En el ejemplo (distancia D2):
D = (225 225)2 + (15 10)2 = 25- D12 = (225 – 225)2 + (15 – 10)2 = 25
- D13 = (210 – 225)2 + (30 – 10)2 = 38.425
- Si la producción de leche la medimos en centilitros:
- D12 = (22500 – 22500)2 + (15 – 10)2 = 25
- D = (21000 – 22500)2 + (30 – 10)2 = 2 250 400- D13 = (21000 – 22500) + (30 – 10) = 2.250.400
- Lo más común en restar la media a cada observación y dividir- Lo más común en restar la media a cada observación y dividirpor la desviación típica (variables de media cero y d.t. 1)

M did d i il id d d t bi i
medidas de similaridad
Medidas de similaridad para datos binarios
- Se utilizan con variables ficticias o con variables dicotómicas( “ ” 0 “ i” 1)(p.e. “no”=0; “si”=1)
- Se utiliza una tabla de doble entrada:
G d E ló i ATP S lt E t diGanadero Ecológico ATP Soltero Estudios1 1 1 0 02 0 1 1 13 1 1 0 14 0 0 0 15 1 1 1 0

medidas de similaridad
G d E ló i ATP S lt E t diGanadero Ecológico ATP Soltero Estudios1 1 1 0 02 0 1 1 13 1 1 0 14 0 0 0 15 1 1 1 0
1 01
1 1 20 1 0
2

medidas de similaridad
G d E ló i ATP S lt E t diGanadero Ecológico ATP Soltero Estudios1 1 1 0 02 0 1 1 13 1 1 0 14 0 0 0 15 1 1 1 0
1 01
1 1 20 1 0
2 a bc d

M did
medidas de similaridad
Medidas:
- D2 = b + c
- D = √ b + c
Diferencia de tamaño = (b c)2/(a+b+c+d)2- Diferencia de tamaño = (b–c)2/(a+b+c+d)2
Diferencia de configuración = (b*c)/(a+b+c+d)2- Diferencia de configuración = (b c)/(a+b+c+d)2
Diferencia de forma = [(a+b+c+d)*(b+c) (b c)2]/(a+b+c+d)2- Diferencia de forma = [(a+b+c+d) (b+c)-(b–c)2]/(a+b+c+d)2

F ió d
análisis jerárquico
Formación de grupos:
- Análisis jerárquico: Inicialmente cada caso es un grupo ení i i t f i dsí mismo y sucesivamente se van fusionando grupos
cercanos hasta que todos los individuos confluyen en un sologrupo.g p
Análisis no jerárquico: Inicialmente se establece el número- Análisis no jerárquico: Inicialmente se establece el númerode grupos y cada caso se asigna a uno de ellos.
Nótese que si elegimos p.e. 3 grupos, en el método jerárquico los grupos proceden de fusionar dos grupos de la anteriorgrupos proceden de fusionar dos grupos de la anterior
combinación de 4 y en el método no jerárquico los 3 grupos se habrán confeccionado para maximizar la heterogeneidad
entre grupos y la homogeneidad dentro de grupos.

análisis jerárquico
Ej lEjemplo:
- 12 casos (explotaciones ecológicas de vacuno lechero)
- Agrupar según las siguientes variables:
- NHT (superficie ´dedicada a la actividad en ha)( p )
- NHT_NHP (superficie en propiedad %)
NVAC (número de vacas)- NVAC (número de vacas)
- TREP (tasa de reposición)
- TMORT (tasa de mortalidad)
- CARGA (carga ganadera UGM/ha)
- ITC (índice terneros comerciales)
- ILC (índice de litros comerciales)- ILC (índice de litros comerciales)

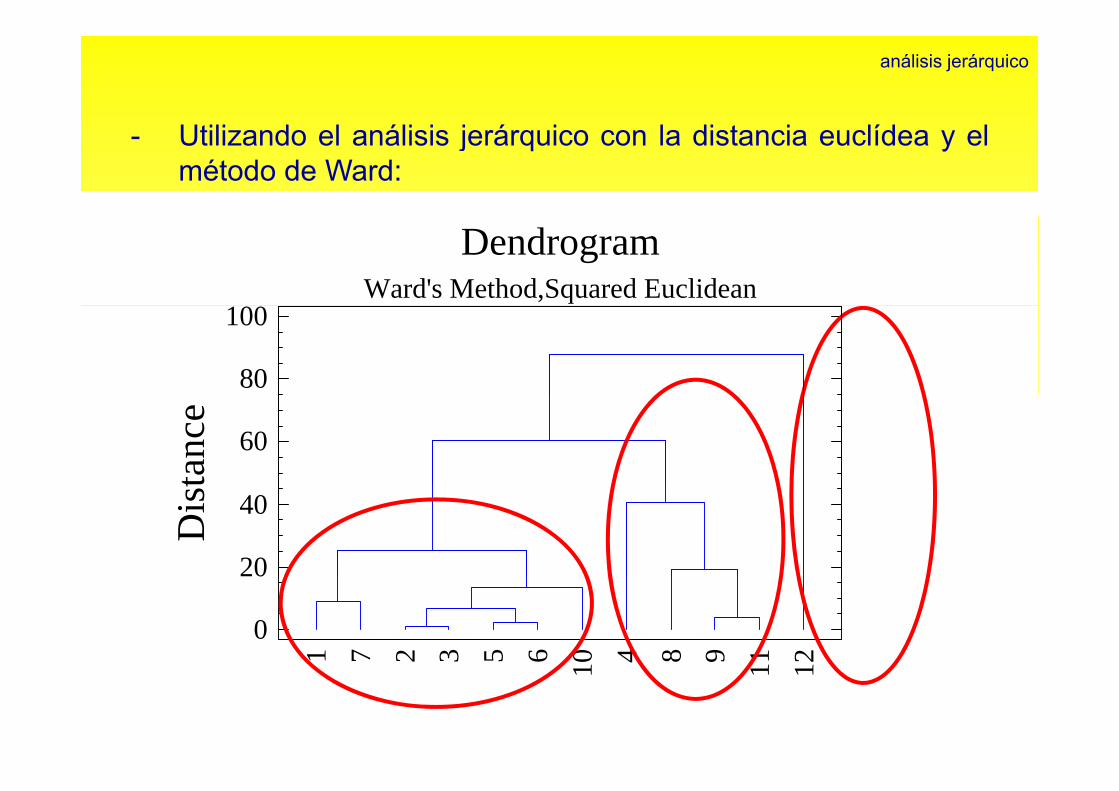
análisis jerárquico
Utili d l áli i j á i l di t i líd l- Utilizando el análisis jerárquico con la distancia euclídea y elmétodo de Ward:
DendrogramWard's Method,Squared Euclidean
80
100
tanc
e
60
Dis
t
20
40
0
20
1 2 3 45 67 8 90 1 21 1 1
análisis jerárquico
Utili d l áli i j á i l di t i líd l- Utilizando el análisis jerárquico con la distancia euclídea y elmétodo de Ward:
DendrogramWard's Method,Squared Euclidean
80
100
tanc
e
60
Dis
t
20
40
0
20
1 2 3 45 67 8 90 1 21 1 1

análisis jerárquico
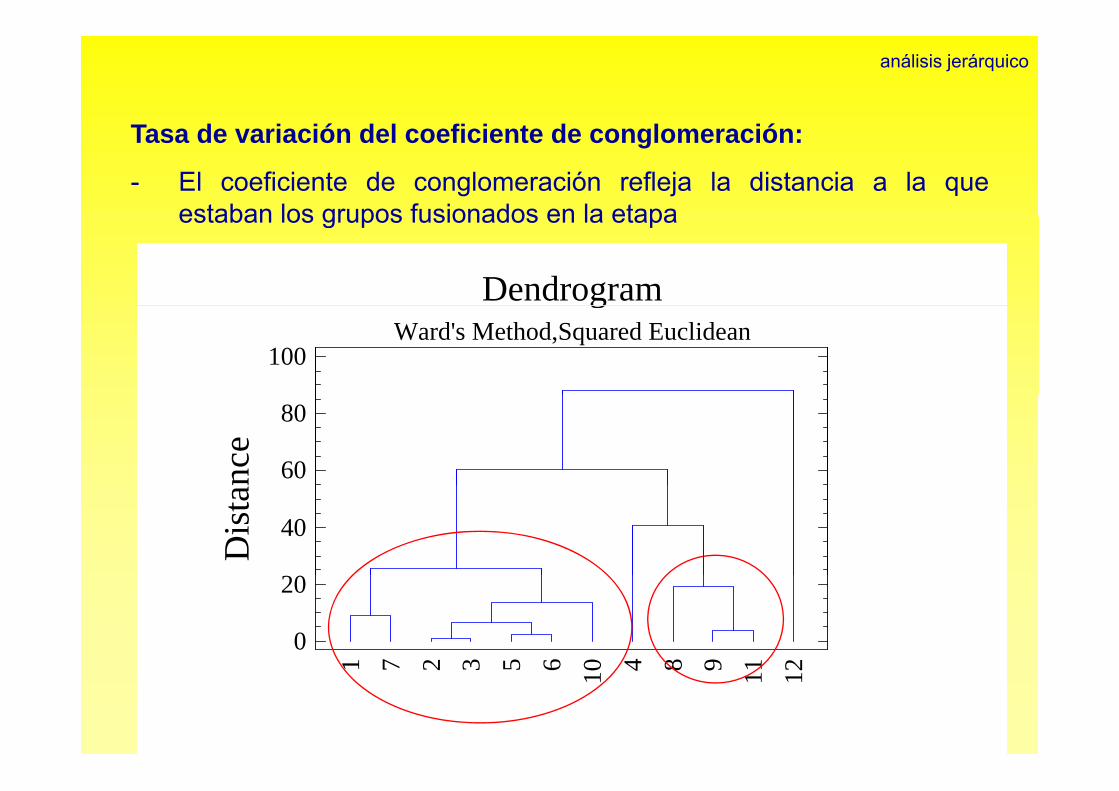
Utili d l áli i j á i l di t i líd l- Utilizando el análisis jerárquico con la distancia euclídea y elmétodo de Ward:
G I 1 3 5 6 7 10- Grupo I: 1, 3, 5, 6, 7, 10
- Grupo II: 4, 8, 9, 11
- Grupo III: 12
- Utilizando el análisis no jerárquico con la distancia euclídea:
Grupo I: 1 7 12- Grupo I: 1, 7, 12
- Grupo II: 4, 8, 9, 10
- Grupo III: 2, 3, 5, 6, 11

Mét d d ió j á i
análisis jerárquico
Métodos de agrupación jerárquica:
- Método del centroide
- Método del vecino más cercano
- Método del vecino más lejanoj
- Método de la vinculación promedio
Método de Ward- Método de Ward

Mét d d l t id
análisis jerárquico
Métodos del centroide:
- Comienza uniendo las dos observaciones máscercanas.
- A continuación, el grupo se sustituye por una observaciónque lo representa (centroide) y en el que todas lasque lo representa (centroide) y en el que todas lasvariables toman un valor medio.
Se vuelven a calcular la matriz de distancias (D D2- Se vuelven a calcular la matriz de distancias (D, D2,etc.), se unen otro par de observaciones y se recalcula lamatriz.
- Así hasta que todas las observaciones quedan en un sologrupo.

Métodos del vecino más cercano:análisis jerárquico
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )grupo (en vez del valor medio).
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Métodos del vecino más cercano:
- Igual que el método del centroide pero varía el cálculo dela distancia.
- Las distancias entre los grupos a fusionar se calculantomando las observaciones más cercanas de cada
( d l l di )
45
grupo (en vez del valor medio).
30
35
40
15
20
25
5
10
15
0100 250 400 550
Mét d d l i á l j
análisis jerárquico
Métodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i á l jMétodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i á l jMétodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i á l jMétodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i á l jMétodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i á l jMétodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i á l jMétodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i á l jMétodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i á l jMétodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

Mét d d l i á l j
análisis jerárquico
Métodos del vecino más lejano:
- Igual que el método anterior pero utiliza las observacionesá l j d d l l l di t imás lejanas de cada grupo para calcular las distancias.
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

Mét d d l i l ió di
análisis jerárquico
Métodos de la vinculación promedio:
- La distancia entre los grupos se obtiene calculando ladi t i di t t d l ddistancia promedio entre todos los pares deobservaciones que pueden formarse entre los dosgrupos fusionar.g p
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

análisis jerárquico
Mét d d l i l ió diMétodos de la vinculación promedio:
- La distancia entre los grupos se obtiene calculando ladi t i di t t d l ddistancia promedio entre todos los pares deobservaciones que pueden formarse entre los dosgrupos fusionar.
45
g p
30
35
40
15
20
25
5
10
15
0100 250 400 550

Mét d d l i l ió di
análisis jerárquico
Métodos de la vinculación promedio:
45
30
35
40
15
20
25
5
10
15
0100 250 400 550

Mét d d W d
análisis jerárquico
Métodos de Ward:
- El método de Ward es el más utilizado (maximiza lah id d d t d l )homogeneidad dentro de los grupos).
- Para ello, plantea todas las posibles fusiones en cadaetapa concreta y elige la que maximiza la homogeneidad:etapa concreta y elige la que maximiza la homogeneidad:
- Calcula los centroides de los grupos resultantes delas posibles fusioneslas posibles fusiones
- A continuación calcula la distancia al centroide detodas las observaciones del grupo (suma detodas las observaciones del grupo (suma decuadrados total)
La solución con menor suma de cuadrados total es la- La solución con menor suma de cuadrados total es laelegida

Ejemplo método de Ward (distancia D2):análisis jerárquico
Cabra Producción leche Rendimiento queseroCabra Producción leche Rendimiento quesero1 225 102 225 153 210 304 200 354 200 355 325 206 375 257 450 40
45
7 450 408 500 35
8
30
35
40 8
4 7
3
15
20
253
5 6
1
5
10
15 1
2
0100 250 400 550

Ejemplo método de Ward (distancia D2):análisis jerárquico
Cabra Producción leche Rendimiento quesero
Posibles fusiones:
(1,2,3,4) y (5,6)
Cabra Producción leche Rendimiento quesero1 225 102 225 153 210 304 200 35
( , , , ) y ( , )4 200 355 325 206 375 257 450 40
45
7 450 408 500 35
8
30
35
40 8
4 7
3
15
20
253
5 6
1
5
10
15 1
2
0100 250 400 550

Ejemplo método de Ward (distancia D2):análisis jerárquico
Cabra Producción leche Rendimiento quesero
Posibles fusiones:Cabra Producción leche Rendimiento quesero
1 225 102 225 153 210 304 200 35
(5,6) y (7,8)4 200 355 325 206 375 257 450 40
45
7 450 408 500 35
8
30
35
40 8
4 7
3
15
20
253
5 6
1
5
10
15 1
2
0100 250 400 550

Ejemplo método de Ward (distancia D2):análisis jerárquico
Cabra Producción leche Rendimiento quesero
Posibles fusiones:Cabra Producción leche Rendimiento quesero
1 225 102 225 153 210 304 200 35
(1 2 3 4) y (7 8)
4 200 355 325 206 375 257 450 40(1,2,3,4) y (7,8)
45
7 450 408 500 35
8
30
35
40 8
4 7
3
15
20
253
5 6
1
5
10
15 1
2
0100 250 400 550

Ejemplo método de Ward (distancia D2):análisis jerárquico
Cabra Producción leche Rendimiento quesero
Posibles fusiones:
(1,2,3,4) y (5,6)
Cabra Producción leche Rendimiento quesero1 225 102 225 153 210 304 200 35
( , , , ) y ( , )
(5,6) y (7,8)
(1 2 3 4) y (7 8)
4 200 355 325 206 375 257 450 40(1,2,3,4) y (7,8)
45
7 450 408 500 35
8
30
35
40 8
4 7
3
15
20
253
5 6
1
5
10
15 1
2
0100 250 400 550

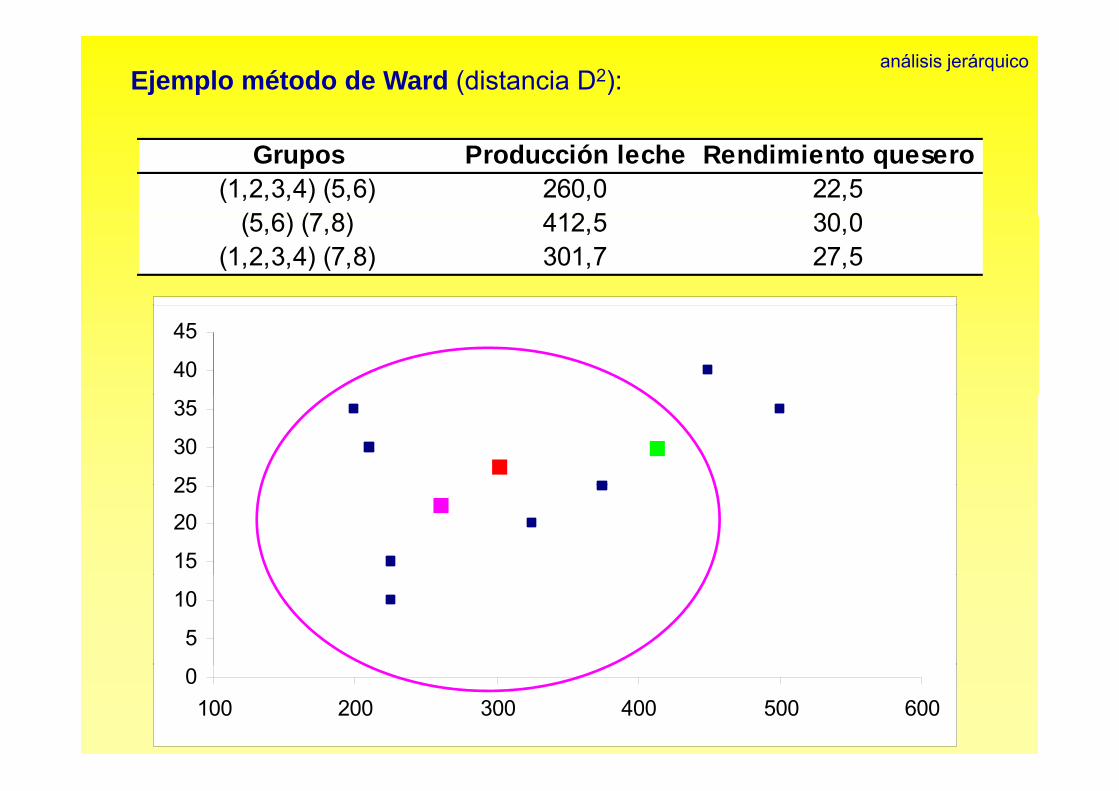
Ejemplo método de Ward (distancia D2):análisis jerárquico
Grupos Producción leche Rendimiento quesero(1,2,3,4) (5,6) 260,0 22,5
(5 6) (7 8) 412 5 30 0(5,6) (7,8) 412,5 30,0(1,2,3,4) (7,8) 301,7 27,5
40
45
25
30
35
15
20
25
5
10
0100 200 300 400 500 600
Ejemplo método de Ward (distancia D2):análisis jerárquico
Grupos Producción leche Rendimiento quesero(1,2,3,4) (5,6) 260,0 22,5
(5 6) (7 8) 412 5 30 0(5,6) (7,8) 412,5 30,0(1,2,3,4) (7,8) 301,7 27,5
40
45
25
30
35
15
20
25
5
10
0100 200 300 400 500 600

Ejemplo método de Ward (distancia D2):análisis jerárquico
Grupos Producción leche Rendimiento quesero(1,2,3,4) (5,6) 260,0 22,5
(5 6) (7 8) 412 5 30 0(5,6) (7,8) 412,5 30,0(1,2,3,4) (7,8) 301,7 27,5
40
45
25
30
35
15
20
25
5
10
0100 200 300 400 500 600

Ejemplo método de Ward (distancia D2):análisis jerárquico
Grupos Producción leche Rendimiento quesero(1,2,3,4) (5,6) 260,0 22,5
(5 6) (7 8) 412 5 30 0(5,6) (7,8) 412,5 30,0(1,2,3,4) (7,8) 301,7 27,5
40
45
25
30
35
15
20
25
5
10
0100 200 300 400 500 600

Ejemplo método de Ward (distancia D2):análisis jerárquico
Grupos Producción leche Rendimiento quesero(1,2,3,4) (5,6) 260,0 22,5
(5 6) (7 8) 412 5 30 0(5,6) (7,8) 412,5 30,0(1,2,3,4) (7,8) 301,7 27,5
40
45
25
30
35
15
20
25
5
10
0100 200 300 400 500 600

Ejemplo método de Ward (distancia D2):análisis jerárquico
Grupos Producción leche Rendimiento quesero(1,2,3,4) (5,6) 260,0 22,5
(5 6) (7 8) 412 5 30 0(5,6) (7,8) 412,5 30,0(1,2,3,4) (7,8) 301,7 27,5
40
45
25
30
35
15
20
25
5
10
0100 200 300 400 500 600

Ejemplo método de Ward (distancia D2):análisis jerárquico
G P d ió l h R di i tGrupos Producción leche Rendimiento quesero(1,2,3,4) (5,6) 260,0 22,5
(5,6) (7,8) 412,5 30,0(1,2,3,4) (7,8) 301,7 27,5
Cabra Producción leche Rendimiento quesero1 225 101 225 102 225 153 210 304 200 355 325 206 375 257 450 408 500 35
- D1 2 3 4 5 6 = 26437
8 500 35
1,2,3,4,5,6
- D1,2,3,4,7,8 = 111625
D = 103137- D5,6,7,8 = 103137

Ejemplo método de Ward (distancia D2):análisis jerárquico
G P d ió l h R di i tGrupos Producción leche Rendimiento quesero(1,2,3,4) (5,6) 260,0 22,5
(5,6) (7,8) 412,5 30,0(1,2,3,4) (7,8) 301,7 27,5
Cabra Producción leche Rendimiento quesero1 225 101 225 102 225 153 210 304 200 355 325 206 375 257 450 408 500 35
- D1,2,3,4,5,6 = 26437
8 500 35
, , , , ,
- D1,2,3,4,7,8 = 111625
- D5 6 7 8 = 1031375,6,7,8

El ió d l ét d d ió j á i
análisis jerárquico
Elección del método de agrupación jerárquica:
- Sigue planteando interrogantes a resolver
- Probar varios métodos y comparar los resultados
- Método del vecino más cercano: Tiende a crear pocospgrupos, aunque es muy sensible a outliers
- Método del vecino más lejano: Grupos muyj p yhomogéneos
- Método de Ward: Tiende a grupos muy compactos detamaño similar

S l ió d l ú d l d
análisis jerárquico
Selección del número de conglomerados:
- Problema que aún plantea dudas.
- Dos criterios:
- Debe detenerse la fusión cuando los grupos a unirg pestán a una distancia significativamente mayor de losque previamente se han fusionado.
- El investigador debe interpretar adecuadamente cadagrupo de la solución final.

S l ió d l ú d l d
análisis jerárquico
Selección del número de conglomerados:
- Distancia de los conglomerados (DC)
- Tasa de variación del coeficiente de conglomeración
- Raíz cuadrada de la media de las D.T. del nuevo cluster (RC)( )
- R2 semiparcial (R2S)
R cuadrado (R2)- R cuadrado (R2)

Di t i d l l d (DC)
análisis jerárquico
Distancia de los conglomerados (DC):
- Indica la homogeneidad dentro del nuevo conglomerado.
- Responde a la distancia utilizada.
- El valor debe ser pequeño.p q
Num Cluster DCNum. Cluster DC7 3,66 5,385 5 655 5,654 7,073 11,882 13,51 35,03

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
Agglomeration Distance PlotWard's Method,Squared Euclidean
100
60
80
ance
20
40
Dis
ta
0 2 4 6 8 10 120
20
0 2 4 6 8 10 12
Stage

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
Agglomeration Distance PlotWard's Method,Squared Euclidean
100
60
80
ance
20
40
Dis
ta
0 2 4 6 8 10 120
20
0 2 4 6 8 10 12
Stage

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
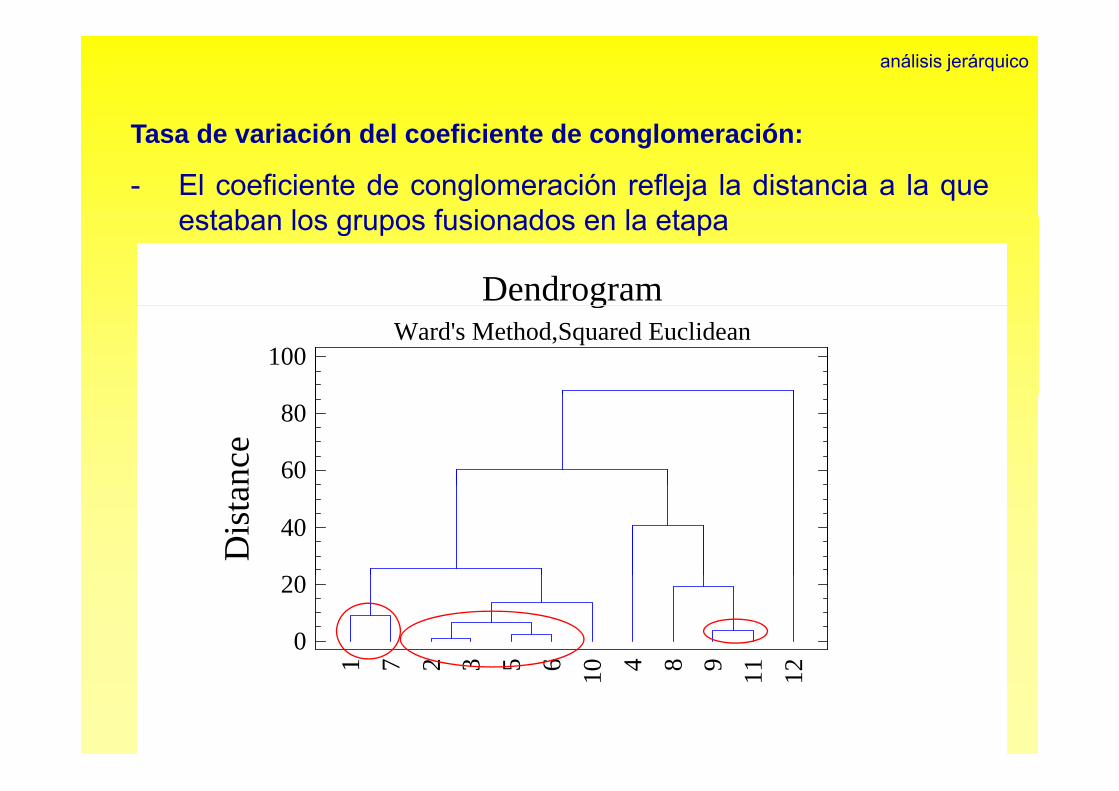
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12
T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12
T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
DendrogramgWard's Method,Squared Euclidean
100
nce
60
80
Dis
tan
40
0
20
1 2 3 45 67 8 90 1 21 2 3 45 67 8 910 11 12

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
Agglomeration Schedule----------------------Clustering Method: Ward'sDistance Metric: Squared Euclidean
Clusters Combined Stage First Appears Nextg ppStage Cluster 1 Cluster 2 Coefficient Cluster 1 Cluster 2 Stage-------------------------------------------------------------------------- 1 2 3 0,91948 0 0 4 2 5 6 2,27928 0 0 4
3 9 11 3 92254 0 0 7 3 9 11 3,92254 0 0 7 4 2 5 6,44183 1 2 6 5 1 7 9,0135 0 0 8 6 2 10 13,4301 4 0 8
7 8 9 19,2448 0 3 9 7 8 9 19,2448 0 3 9 8 1 2 25,2716 5 6 10 9 4 8 40,384 0 7 10 10 1 4 60,5273 8 9 11 11 1 12 88,0 10 0 0--------------------------------------------------------------------------

T d i ió d l fi i t d l ió
análisis jerárquico
Tasa de variación del coeficiente de conglomeración:
- El coeficiente de conglomeración refleja la distancia a la queestaban los grupos fusionados en la etapaestaban los grupos fusionados en la etapa
Agglomeration Schedule----------------------Clustering Method: Ward'sDistance Metric: Squared Euclidean
Clusters Combined Stage First Appears Nextg ppStage Cluster 1 Cluster 2 Coefficient Cluster 1 Cluster 2 Stage-------------------------------------------------------------------------- 1 2 3 0,91948 0 0 4 2 5 6 2,27928 0 0 4
3 9 11 3 92254 0 0 7 3 9 11 3,92254 0 0 7 4 2 5 6,44183 1 2 6 5 1 7 9,0135 0 0 8 6 2 10 13,4301 4 0 8
7 8 9 19,2448 0 3 9 7 8 9 19,2448 0 3 9 8 1 2 25,2716 5 6 10 9 4 8 40,384 0 7 10 10 1 4 60,5273 8 9 11 11 1 12 88,0 10 0 0--------------------------------------------------------------------------

R í d d d l di d l D T d l l t (RC)
análisis jerárquico
Raíz cuadrada de la media de las D.T. del nuevo cluster (RC):
- Indica la homogeneidad del nuevo conglomerado.
- La suma de todas las desviaciones típicas de todas lasobservaciones del nuevo conglomerado respecto al centroide.
- El valor debe ser pequeño.
Num Cluster DC RCNum. Cluster DC RC7 3,6 1,86 5,38 2,695 5 65 2 825 5,65 2,824 7,07 3,533 11,88 5,222 13,5 6,071 35,03 14,24

R2 i i l (R2S)
análisis jerárquico
R2 semiparcial (R2S):
- Indica la pérdida de homogeneidad que se produce en laf iófusión.
- Su cálculo se basa en el ratio entre la pérdida dehomogeneidad en cada fusión (suma de cuadrados tras lahomogeneidad en cada fusión (suma de cuadrados tras lafusión menos la suma de cuadrados de los grupos que seunen) y la homogeneidad máxima (cada observación es un) y g (grupo).
- El valor debe ser pequeño.Num. Cluster DC RC R2S
7 3,6 1,8 06 5,38 2,69 06 5,38 2,69 05 5,65 2,82 04 7,07 3,53 03 11,88 5,22 0,042 13,5 6,07 0,061 35,03 14,24 0,86

R2
análisis jerárquico
R2:
- Indica la heterogeneidad entre conglomerados en cadaf iófusión.
- Ratio entre la heterogeneidad entre conglomerados y la total.
- El valor debe ser alto.
Num. Cluster DC RC R2S R27 3,6 1,8 0 0,996 5,38 2,69 0 0,995 5,65 2,82 0 0,984 7,07 3,53 0 0,973 11,88 5,22 0,04 0,922 13,5 6,07 0,06 0,861 35,03 14,24 0,86 0

DC h id d l t f i d P ñ
análisis jerárquico
DC: homogeneidad clusters fusionados Pequeño
T. Var. CC: pérdida homogeneidad en la fusión Pequeño
RC: homogeneidad del nuevo cluster Pequeño
R2S: pérdida homogeneidad en la fusión Pequeño
R2: heterogeneidad entre clusters Grande
Num. Cluster DC RC R2S R27 3,6 1,8 0 0,996 5,38 2,69 0 0,996 5,38 2,69 0 0,995 5,65 2,82 0 0,984 7,07 3,53 0 0,973 11,88 5,22 0,04 0,923 11,88 5,22 0,04 0,922 13,5 6,07 0,06 0,861 35,03 14,24 0,86 0

DC h id d l t f i d P ñ
análisis jerárquico
DC: homogeneidad clusters fusionados Pequeño
T. Var. CC: pérdida homogeneidad en la fusión Pequeño
RC: homogeneidad del nuevo cluster Pequeño
R2S: pérdida homogeneidad en la fusión Pequeño
R2: heterogeneidad entre clusters Grande
Num. Cluster DC RC R2S R27 3,6 1,8 0 0,996 5,38 2,69 0 0,995 5,65 2,82 0 0,98, , ,4 7,07 3,53 0 0,973 11,88 5,22 0,04 0,922 13,5 6,07 0,06 0,86, , , ,1 35,03 14,24 0,86 0

análisis jerárquico
35
40
DC RC
20
25
30DC RC
5
10
15
00 1 2 3 4 5 6 7 8
0,80,9
1
0,40,50,60,7
R2S R2
00,10,20,3,
00 1 2 3 4 5 6 7 8

A li i t t l lt d
análisis jerárquico
Analizar e interpretar los resultados:
- ANOVA entre clusters con las variables utilizadas en eláli ianálisis.
- ANOVA con las demás variables.
- Tabla de contingencia entre clusters para variablescategóricas.
- Interpretar los resultados con las agrupaciones sucesivas.

A áli i j á i
análisis no jerárquico
Análisis no jerárquico:
- Se conoce a priori el número de k grupos
- Cada observación es asignada a un grupo
- Maximiza la homogeneidad dentro de los gruposg g p
- Maximiza la heterogeneidad entre grupos
- Etapas:
1. Determinar los centroides iniciales de los k grupos
2. Formación de los grupos
3. Recalcular los centroides y formar grupos hasta laestabilidad

1 D t i l t id i i i l d l k
análisis no jerárquico
1. Determinar los centroides iniciales de los k grupos:
- Se utilizan las k primeras observaciones del fichero comot id d tidcentroides de partida.
- Se calculan las distancias entre las k observaciones y seretiene la correspondiente a las 2 observaciones másretiene la correspondiente a las 2 observaciones máscercanas (O1-O2).

1 D t i l t id i i i l d l k
análisis no jerárquico
1. Determinar los centroides iniciales de los k grupos:
- A continuación se determina si alguna de las 2 observacionesd tit id l t id l b ió Ok+1puede ser sustituida en el centroide por la observación Ok+1.
- Si la distancia de Ok+1 a la observación más cercanaperteneciente a las k observaciones centroides es mayorperteneciente a las k observaciones centroides es mayorque la distancia entre las dos observaciones máscercanas, Ok+1 sustituye a O1 o a O2 (la más cercana).y ( )
- Si la distancia de Ok+1 a cualquiera de las kobservaciones centroides (exceptuando la más cercana)es más grande que la menor distancia de la más cercanaa todas las que integran el centroide, Ok+1 sustituye a Ok

A ti ió d t i i l d l 2 b i d
análisis no jerárquico
- A continuación se determina si alguna de las 2 observaciones puedeser sustituida en el centroide por la observación Ok+1.
- Si la distancia de Ok+1 a la observación más cercana- Si la distancia de Ok+1 a la observación más cercanaperteneciente a las k observaciones centroides es mayor que ladistancia entre las dos observaciones más cercanas, Ok+1sustituye a O1 o a O2 (la más cercana)sustituye a O1 o a O2 (la más cercana).
O1 O2 OkO1 O2 Ok
Ok+1

A ti ió d t i i l d l 2 b i d
análisis no jerárquico
- A continuación se determina si alguna de las 2 observaciones puedeser sustituida en el centroide por la observación Ok+1.
- Si la distancia de Ok+1 a la observación más cercana- Si la distancia de Ok+1 a la observación más cercanaperteneciente a las k observaciones centroides es mayor que ladistancia entre las dos observaciones más cercanas, Ok+1sustituye a O1 o a O2 (la más cercana)sustituye a O1 o a O2 (la más cercana).
O1 OkO1 Ok
Ok+1

A ti ió d t i i l d l 2 b i d
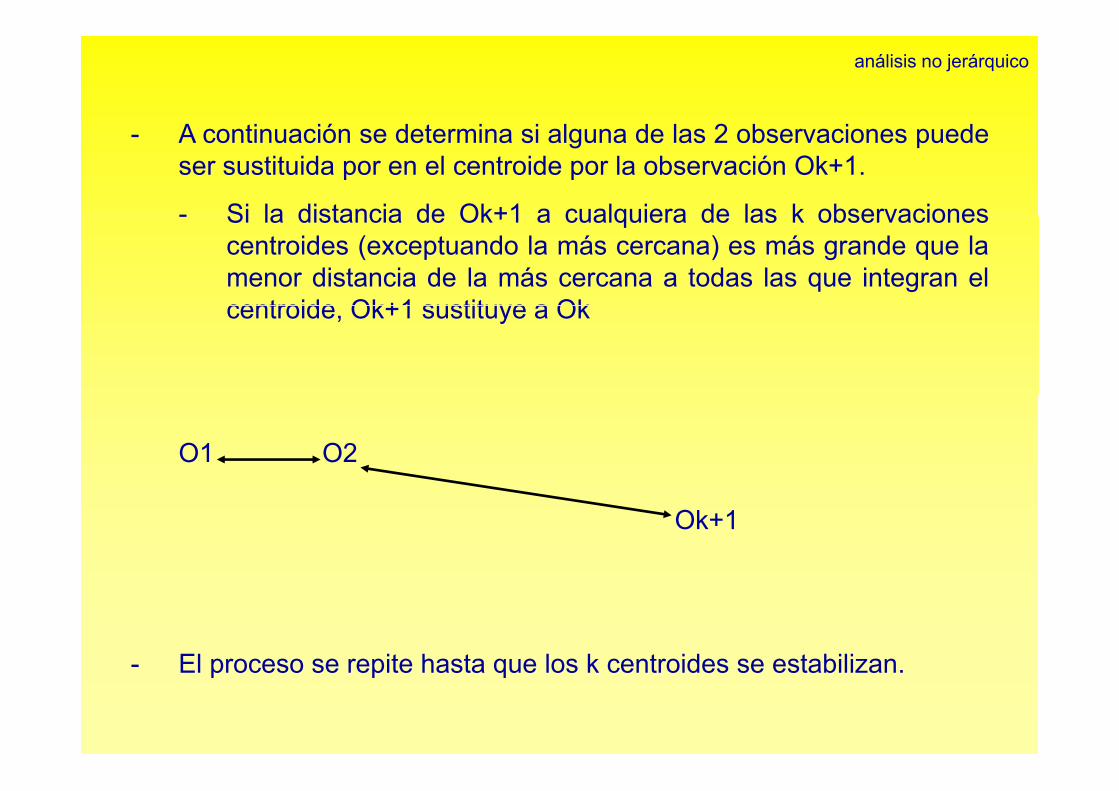
análisis no jerárquico
- A continuación se determina si alguna de las 2 observaciones puedeser sustituida por en el centroide por la observación Ok+1.
- Si la distancia de Ok+1 a cualquiera de las k observaciones- Si la distancia de Ok+1 a cualquiera de las k observacionescentroides (exceptuando la más cercana) es más grande que lamenor distancia de la más cercana a todas las que integran elcentroide Ok+1 sustituye a Okcentroide, Ok+1 sustituye a Ok
O1 O2 Ok
Ok+1
A ti ió d t i i l d l 2 b i d
análisis no jerárquico
- A continuación se determina si alguna de las 2 observaciones puedeser sustituida por en el centroide por la observación Ok+1.
- Si la distancia de Ok+1 a cualquiera de las k observaciones- Si la distancia de Ok+1 a cualquiera de las k observacionescentroides (exceptuando la más cercana) es más grande que lamenor distancia de la más cercana a todas las que integran elcentroide Ok+1 sustituye a Okcentroide, Ok+1 sustituye a Ok
O1 O2
Ok+1
- El proceso se repite hasta que los k centroides se estabilizan- El proceso se repite hasta que los k centroides se estabilizan.

2 F ió d l
análisis no jerárquico
2. Formación de los nuevos grupos:
- Se calcula distancia de cada observación a los k centroides yi l áse asigna al más cercano.
- Se recalculan los centroides (etapa 1) y se vuelven a asignarlas observacioneslas observaciones.
- El proceso finaliza cuando las observaciones no cambiande grupo o cuando se alcanza un determinado número dede grupo o cuando se alcanza un determinado número deiteraciones (marcadas por el investigador)

El ió t l d j á i j á i
elección
Elección entre conglomerado jerárquico o no jerárquico:
- Sigue planteando dudas.
- Depende de los objetivos del estudio y de las propiedades delos distintos métodos.
- Lo ideal sería un enfoque jerárquico inicial y complementarioq j q y pa un enfoque no jerárquico final:
- El análisis jerárquico inicial determinaría cuál es elnúmero de grupos y los centroides iniciales delposterior análisis no jerárquico.
- El posterior análisis no jerárquico maximiza lahomogeneidad dentro de grupos y la heterogeneidadentre gruposentre grupos.