cvim saisentan 半精度浮動小数点数 half
TRANSCRIPT

半精度浮動小数点数half
@tomoaki_teshima関東 CV 勉強会

Float の演算に必要なメモリ量• 必要なメモリ(ディスク)量はどれぐらい?

サイズをもっと減らしたい!• RGB 3 bytes / pixel• float 4 bytes / pixel• どうやって減らしますか?

本日の発表• Deep Learning をはじめとする機械学習• 一切出てきません
• Python• 一切出てきません• C/C++ とアセンブラが半々
• Chainer などの便利ライブラリ• 一切出てきません

本日の発表• 半精度浮動小数点数 half の説明• ARM の対応• ARM(SIMD) の対応• Intel, AMD(x86) の対応• CUDA の対応

浮動小数点数のフォーマットIEEE754
64bit = double 倍精度
32bit = float 単精度
16bit = half 半精度
符号 bit
指数部仮数部
1
1
1
11bit 52bit
23bit
10bit5bit
8bit

ARM には fp16 がある
https://ja.wikipedia.org/wiki/半精度浮動小数点数

用意するもの• Linux が走る ARM• Raspberry Pi zero/1/2/3• ODROID XU4/C2• Jetson TK1/TX1• PINE64• 赤字は 64bit 対応
• 実機買った方が開発には最適!

試して見ようint main(int argc, char**argv)
{
printf("Hello World !!\n");
__fp16 halfPrecision = 1.5f;
printf("half precision:%f\n“, halfPrecision);
printf("half precision:sizeof %d\n“, sizeof(halfPrecision));
printf("half precision:0x%04x\n", *(short*)(void*)&halfPrecision);
float original[] = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f,
9.0f,10.0f,11.0f,12.0f,13.0f,14.0f,15.0f,16.0f,};
for (unsigned int i = 0;i < 16;i++)
{
__fp16 stub = original[i];
printf(“%2d 0x%04x\n", (int)original[i], *(short*)&stub);
}
return 0;
}
https://github.com/tomoaki0705/sampleFp16

ビルドしてみよう
• オプションを付ける必要あり• ARM 上の gcc でないと、 unknown option
エラー
$ gcc -std=c99 -mfp16-format=ieee main.c

実行結果 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 0
1/2
1/1024
1/41/81/16
1/321/64
1/1281/256
1/512
2(17− 15)×(1+ 12+ 14 )=22× 74=7
符号ビット (+)
指数部 (17)
仮数部
指数部が全部 0 だと subnormal 、指数部が全部 1 だと Inf もしくは NaN と定義されている

おしまい• 浮動小数点の符号 / 復号化は意外に面倒• 2byte で浮動小数点を表した• めでたしめでたし

アセンブラで見てみよう•まさかのソフト実装!
•がっかり・・・・•一日一回感謝のアセンブラ
$ gcc –S -std=c99 -mfp16-format=ieee –O main.c.s main.c
movw r3, #15872 ←0x3e00strh r3, [r7, #8] @ __fp16 ←stack に保存ldrh r3, [r7, #8] @ __fp16 ←stack から読込mov r0, r3 @ __fp16 ← レジスタに移動bl __gnu_h2f_ieee ← 関数コール (half2float)

ARM の half 変換命令•half ←→float の変換命令• VCVTB.F16.F32 ( float→half )• VCVTB.F32.F16 ( half→float )• VCVTT.F16.F32 ( float→half )• VCVTT.F32.F16 ( half→float )
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0204ij/CJAGIFIJ.html

Half 変換命令は拡張機能•実行時のプロセッサに FPU 命令が無い場合が普通にある• FPU もオプションで追加する$ gcc –mfp16-format=ieee main.c ↓$ gcc –mfp16-format=ieee –mfpu=vfpv4 main.c

アセンブラで見てみよう 2
movw r3, #15872strh r3, [r7, #8] @ __fp16add r2, r7, #8vld1.16 {d7[2]}, [r2]vcvtb.f32.f16 s15, s15
movw r3, #15872strh r3, [r7, #8] @ __fp16ldrh r3, [r7, #8] @ __fp16mov r0, r3 @ __fp16bl __gnu_h2f_ieee
FPU オプション無し FPU=vfpv4

ARM で half のままの演算• half ←→float の変換のみ• VCVTB.F16.F32• VCVTB.F32.F16• VCVTT.F16.F32• VCVTT.F32.F16
• 直接 half で演算すると floatに自動的に cast される

まとめ• ARM• FPU を指定すると HW の変換命令を使用する• あるのは変換命令だけ、演算時に float に cast される• めでたしめでたし
• ARM(SIMD)• Intel, AMD (x86)• CUDA

ARM での fp16 命令 (SIMD)
• vcvt はベクトルの V
• SIMD で演算してみよう!• 浮動小数点間の変換• float16x4_t vcvt_f16_f32(float32x4_t a);• VCVT.F16.F32 d0, q0
• float32x4_t vcvt_f32_f16(float16x4_t a);• VCVT.F32.F16 q0, d0
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0348bj/BABGABJH.html

ベクトル演算してみようconst unsigned int cParallel = 8;for (unsigned int x = 0;x <= cSize - cParallel;x += cParallel){ uint8x8_t srcInteger = vld1_u8(src+x); // load 64bits float16x4_t gainHalfLow = *(float16x4_t*)(gain + x ); // load 32bits float16x4_t gainHalfHigh = *(float16x4_t*)(gain + x + 4 ); // load 32bits uint16x8_t srcIntegerShort = vmovl_u8(srcInteger); // uchar -> ushort uint32x4_t srcIntegerLow = vmovl_u16(vget_low_s16 (srcIntegerShort)); // ushort -> uint uint32x4_t srcIntegerHigh = vmovl_u16(vget_high_s16(srcIntegerShort)); // ushort -> uint float32x4_t srcFloatLow = vcvtq_f32_u32(srcIntegerLow ); // uint -> float float32x4_t srcFloatHigh = vcvtq_f32_u32(srcIntegerHigh); // uint -> float float32x4_t gainFloatLow = vcvt_f32_f16(gainHalfLow ); // half -> float float32x4_t gainFloatHigh = vcvt_f32_f16(gainHalfHigh); // half -> float float32x4_t dstFloatLow = vmulq_f32(srcFloatLow, gainFloatLow ); // float * float float32x4_t dstFloatHigh = vmulq_f32(srcFloatHigh, gainFloatHigh); // float * float uint32x4_t dstIntegerLow = vcvtq_u32_f32(dstFloatLow ); // float -> uint uint32x4_t dstIntegerHigh = vcvtq_u32_f32(dstFloatHigh); // float -> uint uint16x8_t dstIntegerShort = vcombine_u16(vmovn_u16(dstIntegerLow), vmovn_u16(dstIntegerHigh)); // uint -> ushort uint8x8_t dstInteger = vmovn_u16(dstIntegerShort); // ushort -> uchar vst1_u8(dst+x, dstInteger); // store}
https://github.com/tomoaki0705/sampleFp16Vector

さすがに読みにくいのでconst unsigned int cParallel = 8;for (unsigned int x = 0;x <= cSize - cParallel;x += cParallel){ uchar8 srcInteger = load_uchar8(src+x); // load 64bits half4 gainHalfLow = load_half4(gain + x ); // load 32bits half4 gainHalfHigh = load_half4(gain + x + 4 ); // load 32bits ushort8 srcIntegerShort = convert_uchar8_ushort8(srcInteger); // uchar -> ushort uint4 srcIntegerLow = convert_ushort8_lo_uint4(srcIntegerShort); // ushort -> uint uint4 srcIntegerHigh = convert_ushort8_hi_uint4(srcIntegerShort); // ushort -> uint float4 srcFloatLow = convert_uint4_float4(srcIntegerLow ); // uint -> float float4 srcFloatHigh = convert_uint4_float4(srcIntegerHigh); // uint -> float float4 gainFloatLow = convert_half4_float4(gainHalfLow ); // half -> float float4 gainFloatHigh = convert_half4_float4(gainHalfHigh); // half -> float float4 dstFloatLow = multiply_float4(srcFloatLow , gainFloatLow ); // float * float float4 dstFloatHigh = multiply_float4(srcFloatHigh, gainFloatHigh); // float * float uint4 dstIntegerLow = convert_float4_uint4(dstFloatLow ); // float -> uint uint4 dstIntegerHigh = convert_float4_uint4(dstFloatHigh); // float -> uint ushort8 dstIntegerShort = convert_uint4_ushort8(dstIntegerLow, dstIntegerHigh); // uint -> ushort uchar8 dstInteger = convert_ushort8_uchar8(dstIntegerShort); // ushort -> uchar store_uchar8(dst + x, dstInteger); // store}

ビルドしてみよう• -mfpu オプションで half の指定だけではダメ• half かつ NEON(SIMD) に対応してる FPU を指定する• 詳細は参考リンク
vfpvfpv3vfpv3-fp16vfpv3-d16vfpv3-d16-fp16vfpv3xdvfpv3xd-fp16neonneon-fp16vfpv4vfpv4-d16fpv4-sp-d16neon-vfpv4fp-armv8crypto-neon-fp-armv8
参考 :mfpu のオプション一覧
http://dench.flatlib.jp/opengl/fpu_vfphttp://tessy.org/wiki/index.php?ARM%A4%CEFPU

アセンブラで見てみよう
ちゃんと変換命令が使用されている

まとめ• ARM• めでたしめでたし
• ARM(SIMD)• オプションで fp16 命令かつ neon 命令に対応した
FPU を指定する• めでたしめでたし
• Intel,AMD (x86)• CUDA

x86 の half 対応• F16C 拡張命令セット
https://en.wikipedia.org/wiki/F16C

ベクトル演算してみようconst unsigned int cParallel = 8;for (unsigned int x = 0;x <= cSize - cParallel;x += cParallel){ __m128i srcInteger = _mm_loadl_epi64((__m128i const *)(src + x)); // load 64bits __m128i gainHalfLow = _mm_loadl_epi64((__m128i const *)(gain + x )); // load 32bits __m128i gainHalfHigh = _mm_loadl_epi64((__m128i const *)(gain + x + 4)); // load 32bits __m128i srcIntegerShort = _mm_unpacklo_epi8(srcInteger, v_zero); // uchar -> ushort __m128i srcIntegerLow = _mm_unpacklo_epi16(srcIntegerShort, v_zero); // ushort -> uint __m128i srcIntegerHigh = _mm_unpackhi_epi16(srcIntegerShort, v_zero); // ushort -> uint __m128i srcFloatLow = _mm_cvtepi32_ps(srcIntegerLow ); // uint -> float __m128i srcFloatHigh = _mm_cvtepi32_ps(srcIntegerHigh); // uint -> float __m128 gainFloatLow = _mm_cvtph_ps(gainHalfLow ); // half -> float __m128 gainFloatHigh = _mm_cvtph_ps(gainHalfHigh); // half -> float __m128 dstFloatLow = _mm_mul_ps(srcFloatLow , gainFloatLow ); // float * float __m128 dstFloatHigh = _mm_mul_ps(srcFloatHigh, gainFloatHigh); // float * float __m128i dstIntegerLow = _mm_cvtps_epi32(dstFloatLow ); // float -> uint __m128i dstIntegerHigh = _mm_cvtps_epi32(dstFloatHigh); // float -> uint __m128i dstIntegerShort = _mm_packs_epi32(dstIntegerLow, dstIntegerHigh); // uint -> ushort __m128i dstInteger = _mm_packus_epi16(dstIntegerShort, v_zero); // ushort -> uchar _mm_storel_epi64((__m128i *)(dst + x), dstInteger); // store}
https://github.com/tomoaki0705/sampleFp16Vector

さすがに読みにくいのでconst unsigned int cParallel = 8;for (unsigned int x = 0;x <= cSize - cParallel;x += cParallel){ uchar8 srcInteger = load_uchar8(src+x); // load 64bits half4 gainHalfLow = load_half4(gain + x ); // load 32bits half4 gainHalfHigh = load_half4(gain + x + 4 ); // load 32bits ushort8 srcIntegerShort = convert_uchar8_ushort8(srcInteger); // uchar -> ushort uint4 srcIntegerLow = convert_ushort8_lo_uint4(srcIntegerShort); // ushort -> uint uint4 srcIntegerHigh = convert_ushort8_hi_uint4(srcIntegerShort); // ushort -> uint float4 srcFloatLow = convert_uint4_float4(srcIntegerLow ); // uint -> float float4 srcFloatHigh = convert_uint4_float4(srcIntegerHigh); // uint -> float float4 gainFloatLow = convert_half4_float4(gainHalfLow ); // half -> float float4 gainFloatHigh = convert_half4_float4(gainHalfHigh); // half -> float float4 dstFloatLow = multiply_float4(srcFloatLow , gainFloatLow ); // float * float float4 dstFloatHigh = multiply_float4(srcFloatHigh, gainFloatHigh); // float * float uint4 dstIntegerLow = convert_float4_uint4(dstFloatLow ); // float -> uint uint4 dstIntegerHigh = convert_float4_uint4(dstFloatHigh); // float -> uint ushort8 dstIntegerShort = convert_uint4_ushort8(dstIntegerLow, dstIntegerHigh);// uint -> ushort uchar8 dstInteger = convert_ushort8_uchar8(dstIntegerShort); // ushort -> uchar store_uchar8(dst + x, dstInteger); // store}
$ gcc -mf16c main.cpp

アセンブラで見てみよう• Debug モードでビルド• Inline 関数が展開されていない
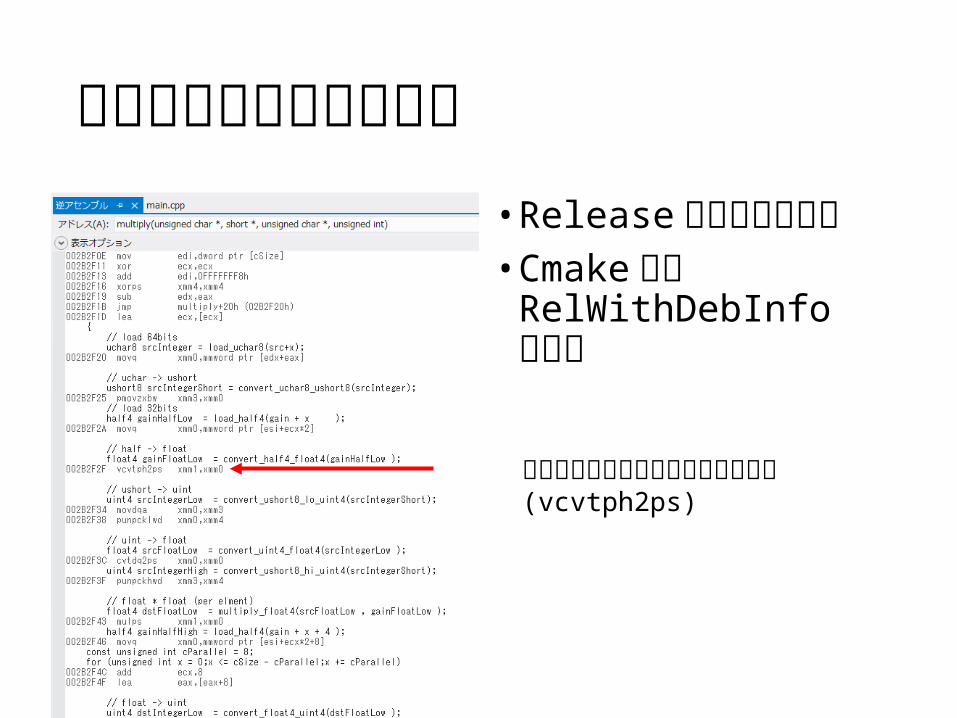
アセンブラで見てみよう• Release モードでビルド• Cmake なら
RelWithDebInfo モードちゃんと変換命令が使用されている(vcvtph2ps)

アセンブラで見てみよう (gcc)• VS 同様 Debug モード• inline 関数は展開されていない

アセンブラで見てみよう (gcc)• Release モードでビルド• 逆アセンブリ
ちゃんと変換命令が使用されている(vcvtph2ps)

まとめ• ARM• めでたしめでたし
• ARM(SIMD)• めでたしめでたし
• Intel,AMD (x86)• x86 でも SSE の中に変換命令がある• Ivy Bridge 以降の Intel と Piledriver 以降の AMD で利用可 • めでたしめでたし
• CUDAhttps://blogs.msdn.microsoft.com/chuckw/2012/09/11/directxmath-f16c-and-fma/

CUDAunsigned short a = g_indata[y*imgw+x];float gain;gain = __half2float(a);
float b = imageData[(y*imgw+x)*3 ];float g = imageData[(y*imgw+x)*3+1];float r = imageData[(y*imgw+x)*3+2];
g_odata[(y*imgw+x)*3 ] = clamp(b * gain, 0.0f, 255.0f);g_odata[(y*imgw+x)*3+1] = clamp(g * gain, 0.0f, 255.0f);g_odata[(y*imgw+x)*3+2] = clamp(r * gain, 0.0f, 255.0f);

half を使う最大のメリット• GPU へ転送するバイト数が半分で済む
メモリ (GPU 上 )

まとめ• ARM
• めでたしめでたし• ARM(SIMD)
• めでたしめでたし• Intel,AMD (x86)
• めでたしめでたし• CUDA
• CUDA 7.5 から正式サポート• Half での演算命令は Pascal から搭載予定→搭載発表← New!!• 一部の演算命令は既に Jetson TX1 で利用可能• 変換命令自体は割と古い GPU でも HW 的に存在するhttp://www.slideshare.net/NVIDIAJapan/1071-gpu-cuda-75maxwellhttp://pc.watch.impress.co.jp/docs/news/event/20160406_751833.html

各プラットフォームの half 対応プラットフォーム 単一の変数 SIMDでの変換 Fp16のままの演算ARM ◯ ◯ ×X86 × ◯ ×
CUDA(Maxwell 以前 ) ◯ ◯ ×
CUDA(Pascal 以降 ) ◯ ◯ ←New!◯←New!

半精度浮動小数点数の限界 – オーバーフロー• float の最大• 指数部 8bit 、仮数部 23bit→ 10E38 まで扱える• signed int の最大 + 2,147,483,647 より大きい
• half の最大• 指数部 5bit 、仮数部 10bit→65504 まで扱える• unsigned short の最大 +65536 より小さい!

半精度浮動小数点数の限界 – 丸め誤差• float の丸め誤差
• 16777216(=2^24) までは整数を正確に表記できる• half の丸め誤差
• 2048 (=2^11) までは整数を正確に表記できる• 1024-2048 のレンジだと小数点以下の情報は失われる• 512-1024 のレンジだと 0.5 刻みでしか表現できない
• Ex. 180.5 + 178.2 + 185.2 + 150.3 + 160.3 = 854.5• 正しい平均値 170.9• Half で計算 171.0 ← 丸め誤差 0.1

そもそものきっかけ• CodeIQ で出題された「マヨイドーロ問題」に挑戦• フィボナッチ数を求める計算
• 再帰関数で計算• メモ化再帰で計算• 指数関数で計算
𝑝𝑛=1√5 {( 1+√5
2 )𝑛
−( 1−√52 )
𝑛}pow 関数 で計算
マヨイドーロ問題 - https://codeiq.jp/q/2549 解説 - https://codeiq.jp/magazine/2015/12/35521/

指数で計算する場合n Fn pnの結果 桁数 (10
進 )桁数 (2進 )
73 806515533049393 806515533049393 15 5074 1304969544928657 1304969544928657 16 5175 2111485077978050 2111485077978050 16 5176 3416454622906707 3416454622906706 16 5277 5527939700884757 5527939700884756 16 5378 8944394323791464 8944394323791464 16 5379 14472334024676221 14472334024676218 17 54

参考文献1. 半精度浮動小数点数 - Wikipediahttps://ja.wikipedia.org/wiki/半精度浮動小数点数
2. tomoaki0705/sampleFp16: sample code to treat FP16 on ARMhttps://github.com/tomoaki0705/sampleFp16
3. ARM Information Centerhttp://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0204ij/CJAGIFIJ.html
4. ARM Information Centerhttp://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0348bj/BABGABJH.html
5. tomoaki0705/sampleFp16Vector: float16bit sample code on x86 and ARMhttps://github.com/tomoaki0705/sampleFp16Vector
6. opengl:fpu_vfp [HYPER でんち ]http://dench.flatlib.jp/opengl/fpu_vfp
7. ARM の FPU - AkiWiki http://tessy.org/wiki/index.php?ARM%A4%CEFPU
8. F16C - Wikipedia, the free encyclopedia https://en.wikipedia.org/wiki/F16C
9. DirectXMath: F16C and FMA | Games for Windows and the DirectX SDK https://blogs.msdn.microsoft.com/chuckw/2012/09/11/directxmath-f16c-and-fma/
10. 1071: GPU コンピューティング最新情報 ~ CUDA 7.5 と Maxwell アーキテクチャ ~http://www.slideshare.net/NVIDIAJapan/1071-gpu-cuda-75maxwell
11. 【イベントレポート】次世代 GPU アーキテクチャ「 Pascal 」が明らかに ~ HBM2 による 720GB/sec の超広帯域など - PC Watch http://pc.watch.impress.co.jp/docs/news/event/20160406_751833.html
12. 結城浩の「マヨイドーロ問題」 | CodeIQ https://codeiq.jp/q/2549
13. 結城浩の「マヨイドーロ問題」解説| CodeIQ MAGAZINEhttps://codeiq.jp/magazine/2015/12/35521/