data analysis using r: 2. descriptive statistics tuan v. nguyen garvan institute of medical...
TRANSCRIPT

Data Analysis Using R:2. Descriptive Statistics
Tuan V. Nguyen
Garvan Institute of Medical Research,
Sydney, Australia

Overview
• Measurements• Population vs sample• Summary of data: mean, variance, standard deviation,
standard error• Graphical analyses• Transformation

Scales of Measurement
• In general, most observable behaviors can be measured on a ratio-scale
• In general, many unobservable psychological qualities (e.g., extraversion), are measured on interval scales
• We will mostly concern ourselves with the simple categorical (nominal) versus continuous distinction (ordinal, interval, ratio)
categorical continuous
ordinal
interval
ratio
variables

Ordinal Measurement
• Ordinal: Designates an ordering; quasi-ranking– Does not assume that the intervals between numbers are equal.– finishing place in a race (first place, second place)
1 hour 2 hours 3 hours 4 hours 5 hours 6 hours 7 hours 8 hours
1st place 2nd place 3rd place 4th place

Interval and Ratio Measurement
• Interval: designates an equal-interval ordering– The distance between, for example, a 1 and a 2 is the
same as the distance between a 4 and a 5– Example: Common IQ tests are assumed to use an
interval metric
• Ratio: designates an equal-interval ordering with a true zero point (i.e., the zero implies an absence of the thing being measured)– Example: number of intimate relationships a person has
had• 0 quite literally means none• a person who has had 4 relationships has had twice as many
as someone who has had 2

Statististics: Enquiry to the unknown
Population Sample
Parameter Estimate

Estimate the population mean
Population height mean = 160 cm
Standard deviation = 5.0 cm
ht <- rnorm(10, mean=160, sd=5)mean(ht)
ht <- rnorm(10, mean=160, sd=5)mean(ht)
ht <- rnorm(100, mean=160, sd=5)mean(ht)
ht <- rnorm(1000, mean=160, sd=5)mean(ht)
ht <- rnorm(10000, mean=160, sd=5)mean(ht)hist(ht)
The larger the sample, the more accurate the estimate is!

Estimate the population proportion
Population proportion of males = 0.50 Take n samples, record the number of k males
rbinom(n, k, prob)
males <- rbinom(10, 10, 0.5)malesmean(males)
males <- rbinom(20, 100, 0.5)malesmean(males)
males <- rbinom(1000, 100, 0.5)malesmean(males)
The larger the sample, the more accurate the estimate is!

Summary of Continuous Data
• Measures of central tendency:– Mean, median, mode
• Measures of dispersion or variability:– Variance, standard deviation, standard error– Interquartile range
R commandslength(x), mean(x), median(x), var(x), sd(x)
summary(x)

R example
height <- rnorm(1000, mean=55, sd=8.2)mean(height)[1] 55.30948
median(height)[1] 55.018
var(height)[1] 68.02786
sd(height)[1] 8.2479
summary(height) Min. 1st Qu. Median Mean 3rd Qu. Max. 28.34 49.97 55.02 55.31 60.78 85.05

Graphical Summary: Box plot3
04
05
06
07
08
0boxplot(height)
95% percentile
75% percentile
25% percentile
5% percentile
Median, 50% perc.
Strip chart
30 40 50 60 70 80
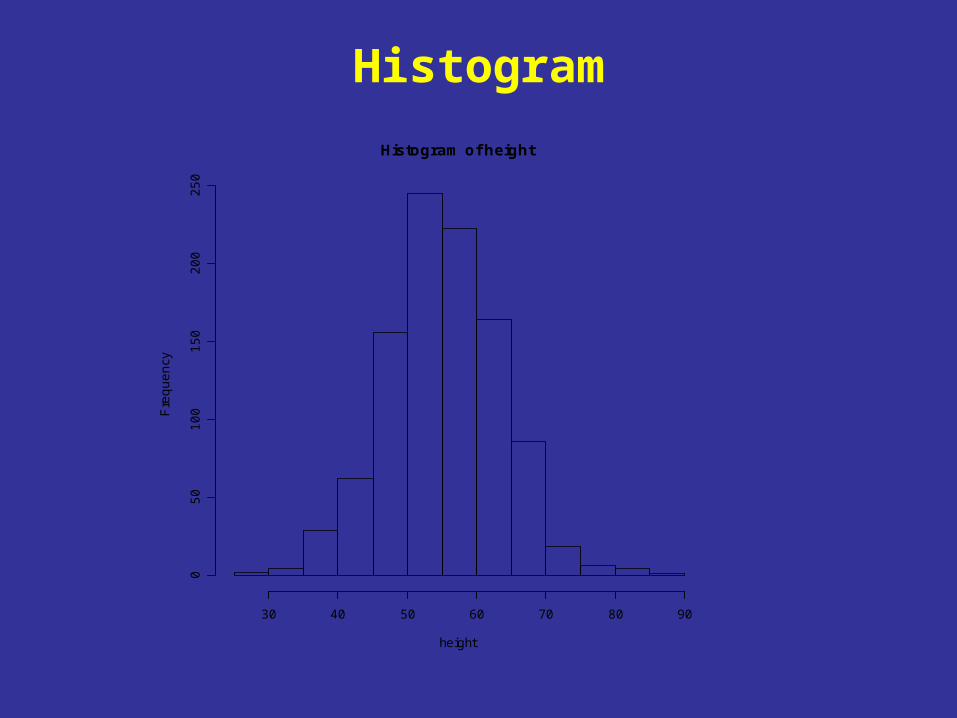
Histogram
Histogram of height
height
Fre
qu
en
cy
30 40 50 60 70 80 90
05
01
00
15
02
00
25
0

Implications of the mean and SD
• “In the Vietnamese population aged 30+ years, the average of weight was 55.0 kg, with the SD being 8.2 kg.”
• What does this mean?
• 68% individuals will have height between 55 +/- 8.2*1 = 46.8 to 63.2 kg
• 95% individuals will have height between 55 +/- 8.2*1.96 = 38.9 to 71.1 kg

Implications of the mean and SD
• The distribution of weight of the entire population can be shown to be:
0
1
2
3
4
5
6
22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 92
Weight (kg)
Per
cen
t (%
)
1SD
1.96SD

Summary of Categorical Data
• Categorical data: – Gender: male, female
– Race: Asian, Caucasian, African
• Semi-quantitative data: – Severity of disease: mild, moderate, severe
– Stages of cancer: I, II, III, IV
– Preference: dislike very much, dislike, equivocal, like, like very much

Mean and variance of a proportion
• For an individual i consumer, the probability he/she prefers A is pi. Assuming that all consumers are independent, then pi = p.
• Variance of pi is var(pi) = p(1-p)
• For a sample of n consumers, the estimated probability of preference for A is:
n
ppppp n
...321
and the variance of p_bar is:
n
ppp
1var

Normal approximation of a binomial distribution
• For an individual i consumer, the probability he/she prefers A is pi. Assuming that all consumers are independent, then pi = p.
• Variance of pi is var(pi) = p(1-p)
• For a sample of n consumers, the estimated probability of preference for A is:
n
ppppp n
...321
and the variance of p_bar is:
n
ppp
1var
and standard deviation: n
pps
1

Normal approximation of a binomial distribution - example
• 10 consumbers, 8 preferred product A.
• Proportion of preference for A: p = 0.8
• Variance: var(p) = 0.8(0.2)/10 = 0.016
• Standard deviation of p: s = 0.126
• 95% CI of p: 0.8 + 1.96(0.126) = 0.55 to 1.00

Descriptive AnalysesContinuous data

Paired t-test
• Continuous data• Normally distributed• Two samples are NOT independent
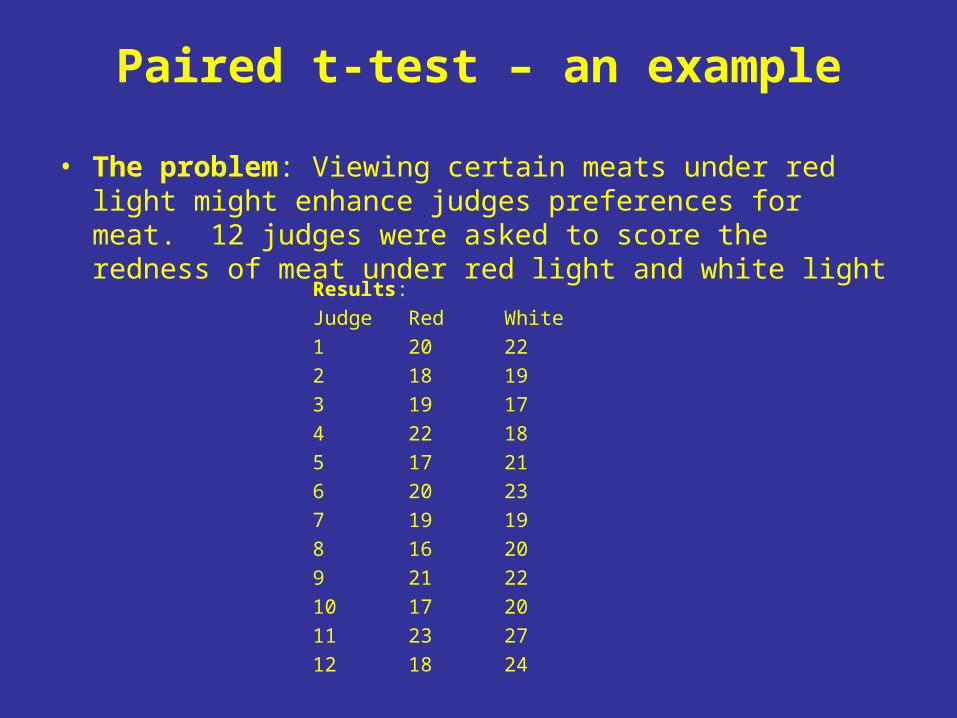
Paired t-test – an example
• The problem: Viewing certain meats under red light might enhance judges preferences for meat. 12 judges were asked to score the redness of meat under red light and white light
Results:
Judge Red White
1 20 22
2 18 19
3 19 17
4 22 18
5 17 21
6 20 23
7 19 19
8 16 20
9 21 22
10 17 20
11 23 27
12 18 24
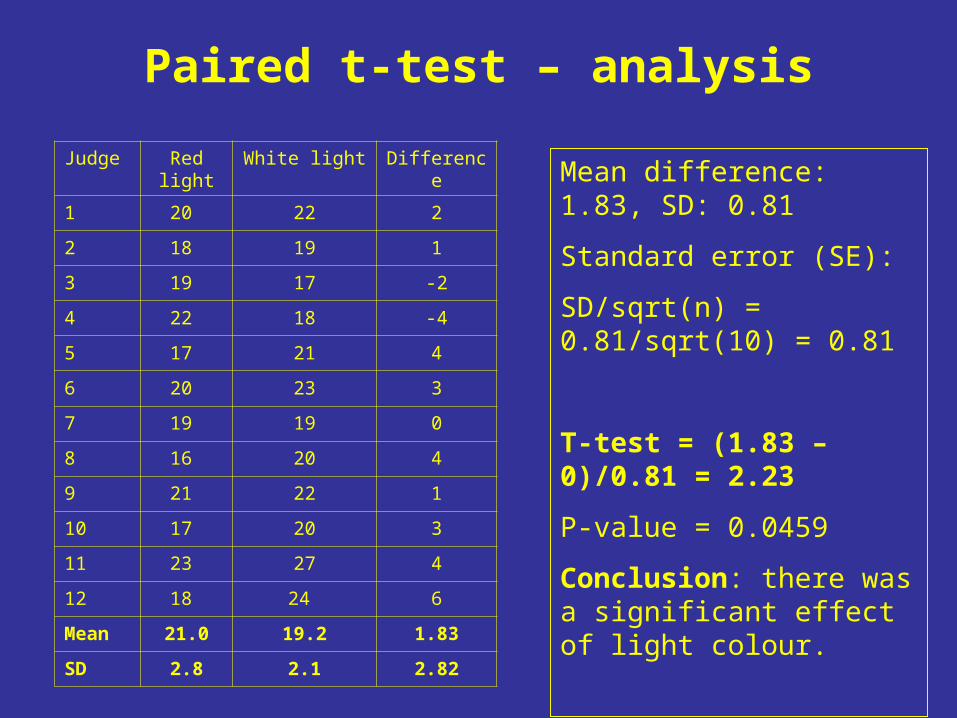
Paired t-test – analysis
Judge Red light White light Difference
1 20 22 2
2 18 19 1
3 19 17 -2
4 22 18 -4
5 17 21 4
6 20 23 3
7 19 19 0
8 16 20 4
9 21 22 1
10 17 20 3
11 23 27 4
12 18 24 6
Mean 21.0 19.2 1.83
SD 2.8 2.1 2.82
Mean difference: 1.83, SD: 0.81
Standard error (SE):
SD/sqrt(n) = 0.81/sqrt(10) = 0.81
T-test = (1.83 – 0)/0.81 = 2.23
P-value = 0.0459
Conclusion: there was a significant effect of light colour.
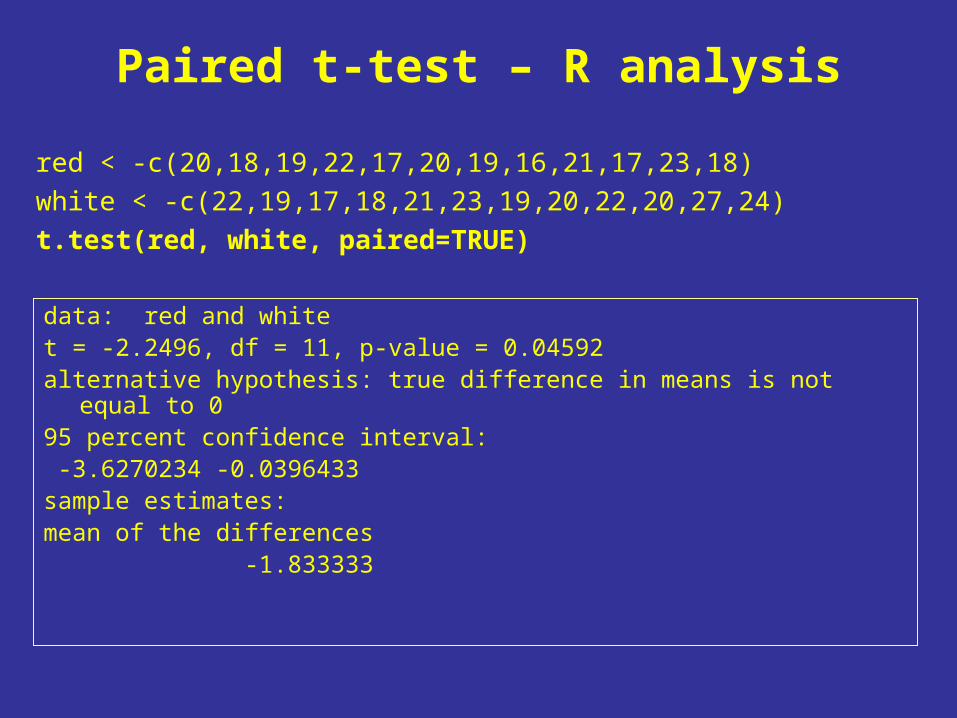
Paired t-test – R analysis
red < -c(20,18,19,22,17,20,19,16,21,17,23,18)
white < -c(22,19,17,18,21,23,19,20,22,20,27,24)
t.test(red, white, paired=TRUE)
data: red and white t = -2.2496, df = 11, p-value = 0.04592alternative hypothesis: true difference in means is not
equal to 0 95 percent confidence interval: -3.6270234 -0.0396433 sample estimates:mean of the differences -1.833333

Two-sample t-test
Sample Group 1 Group21 x1 y1
2 x2 y2 3 x3 y3 4 x4 y4 5 x5 y5 … …n xn yn
Sample size n1 n2
Mean x y
SD sx sy
Mean difference:
D = x – y
Variance of D:
T-statistic:
95% Confidence interval:
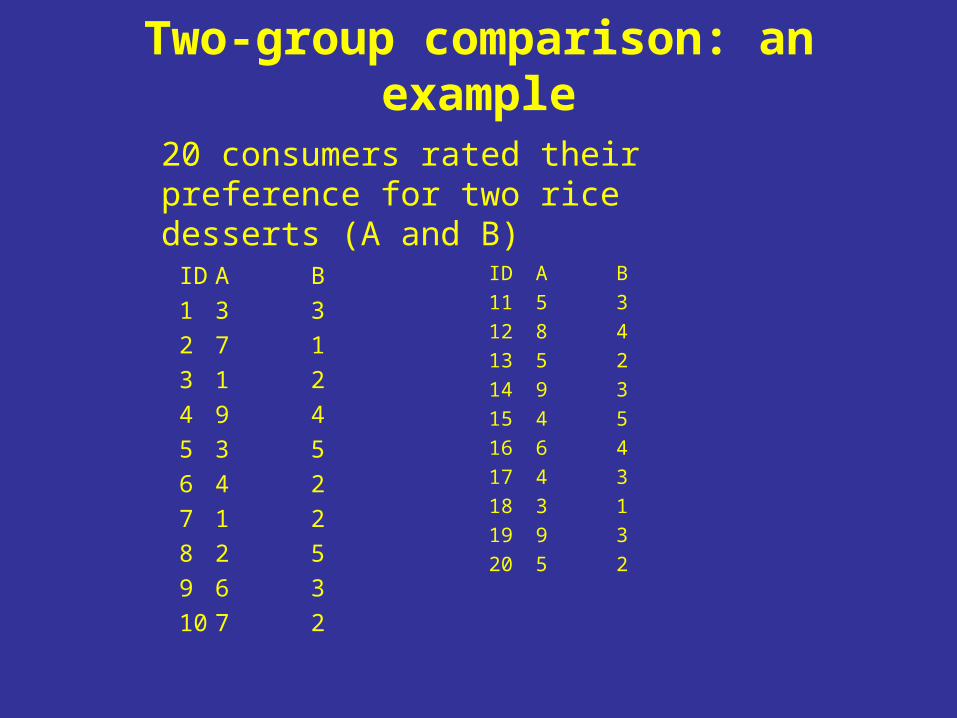
Two-group comparison: an example
ID A B
1 3 3
2 7 1
3 1 2
4 9 4
5 3 5
6 4 2
7 1 2
8 2 5
9 6 3
10 7 2
ID AB
11 5 3
12 8 4
13 5 2
14 9 3
15 4 5
16 6 4
17 4 3
18 3 1
19 9 3
20 5 2
20 consumers rated their preference for two rice desserts (A and B)
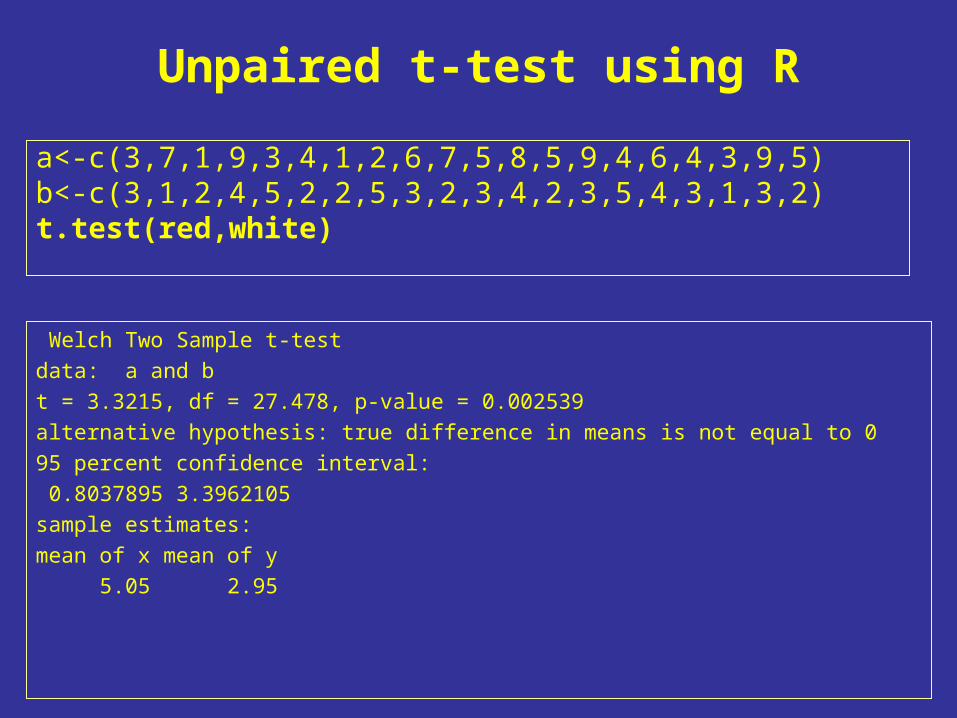
Unpaired t-test using R
a<-c(3,7,1,9,3,4,1,2,6,7,5,8,5,9,4,6,4,3,9,5)b<-c(3,1,2,4,5,2,2,5,3,2,3,4,2,3,5,4,3,1,3,2)t.test(red,white)
Welch Two Sample t-test
data: a and b
t = 3.3215, df = 27.478, p-value = 0.002539
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.8037895 3.3962105
sample estimates:
mean of x mean of y
5.05 2.95
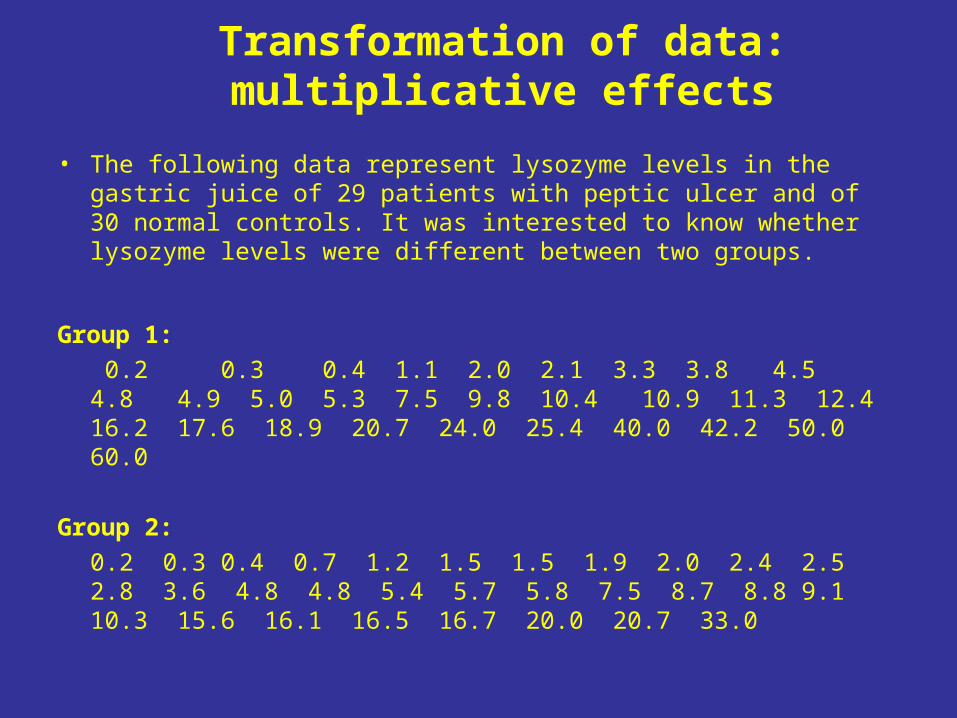
Transformation of data: multiplicative effects
• The following data represent lysozyme levels in the gastric juice of 29 patients with peptic ulcer and of 30 normal controls. It was interested to know whether lysozyme levels were different between two groups.
Group 1:
0.2 0.3 0.4 1.1 2.0 2.1 3.3 3.8 4.5 4.8 4.9 5.0 5.3 7.5 9.8 10.4 10.9 11.3 12.4 16.2 17.6 18.9 20.7 24.0 25.4 40.0 42.2 50.0 60.0
Group 2:
0.2 0.3 0.4 0.7 1.2 1.5 1.5 1.9 2.0 2.4 2.5 2.8 3.6 4.8 4.8 5.4 5.7 5.8 7.5 8.7 8.8 9.1 10.3 15.6 16.1 16.5 16.7 20.0 20.7 33.0
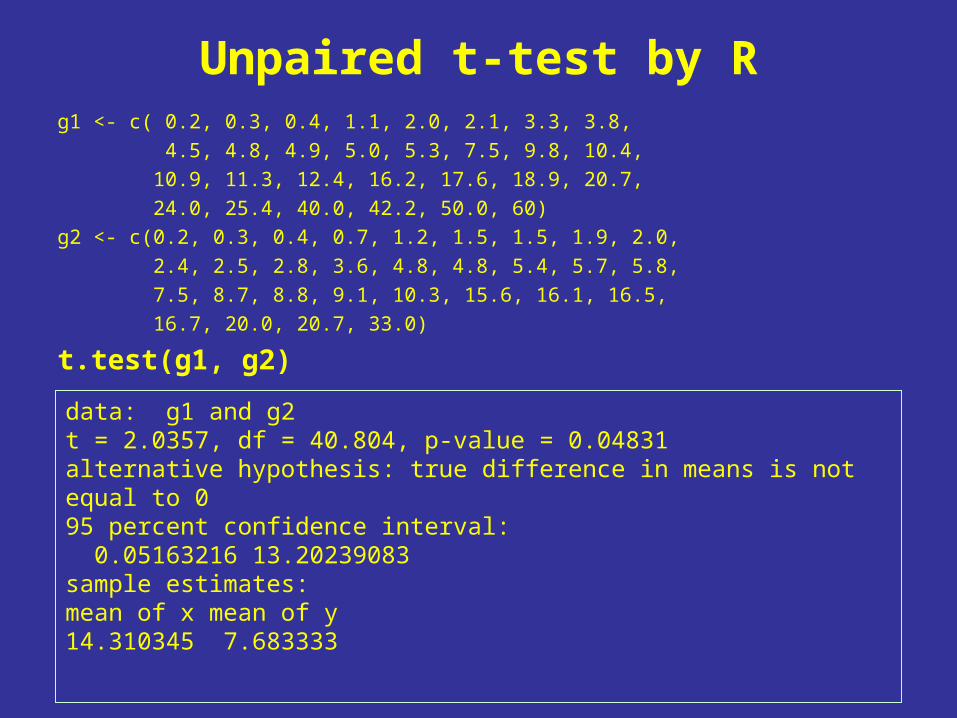
Unpaired t-test by Rg1 <- c( 0.2, 0.3, 0.4, 1.1, 2.0, 2.1, 3.3, 3.8,
4.5, 4.8, 4.9, 5.0, 5.3, 7.5, 9.8, 10.4,
10.9, 11.3, 12.4, 16.2, 17.6, 18.9, 20.7,
24.0, 25.4, 40.0, 42.2, 50.0, 60)
g2 <- c(0.2, 0.3, 0.4, 0.7, 1.2, 1.5, 1.5, 1.9, 2.0,
2.4, 2.5, 2.8, 3.6, 4.8, 4.8, 5.4, 5.7, 5.8,
7.5, 8.7, 8.8, 9.1, 10.3, 15.6, 16.1, 16.5,
16.7, 20.0, 20.7, 33.0)
t.test(g1, g2)
data: g1 and g2 t = 2.0357, df = 40.804, p-value = 0.04831alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 0.05163216 13.20239083 sample estimates:mean of x mean of y 14.310345 7.683333

Exploration of data
par(mfrow=c(1,2))
hist(g1)
hist(g2)
Histogram of g1
g1
Fre
qu
en
cy
0 10 20 30 40 50 60
05
10
15
Histogram of g2
g2
Fre
qu
en
cy
0 5 10 20 30
05
10
15
Group 1:
mean(g1) = 14.3
sd(g1) = 15.7
Group 2:
mean(g2) = 7.7
sd(g2) = 7.8

Re-analysis of lysozyme data
log.g1 <- log(g1)
log.g2 <- log(g2)
t.test(log.g1, log.g2)
data: log.g1 and log.g2 t = 1.406, df = 55.714, p-value = 0.1653alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.2182472 1.2453165 sample estimates:mean of x mean of y 1.921094 1.407559
exp(1.921-1.407) = 1.67
Group 1’s mean is 67% higher than group 2’s

Descriptive analysisCategorical data

Comparison of two proportions - theory
Group1 2
____________________________________________
Sample size n1 n2
Number of events e1 e2
Proportion of events p1 p2
Difference: D = p1 – p2 SE difference: SE = [p1(1–p1)/n1 + p2(1–p2)/n2]1/2
Z = D / SE95% CI: D + 1.96(SE)
With (n1 + n2) > 20, and if Z > 2, it is possible to reject the null hypothesis.
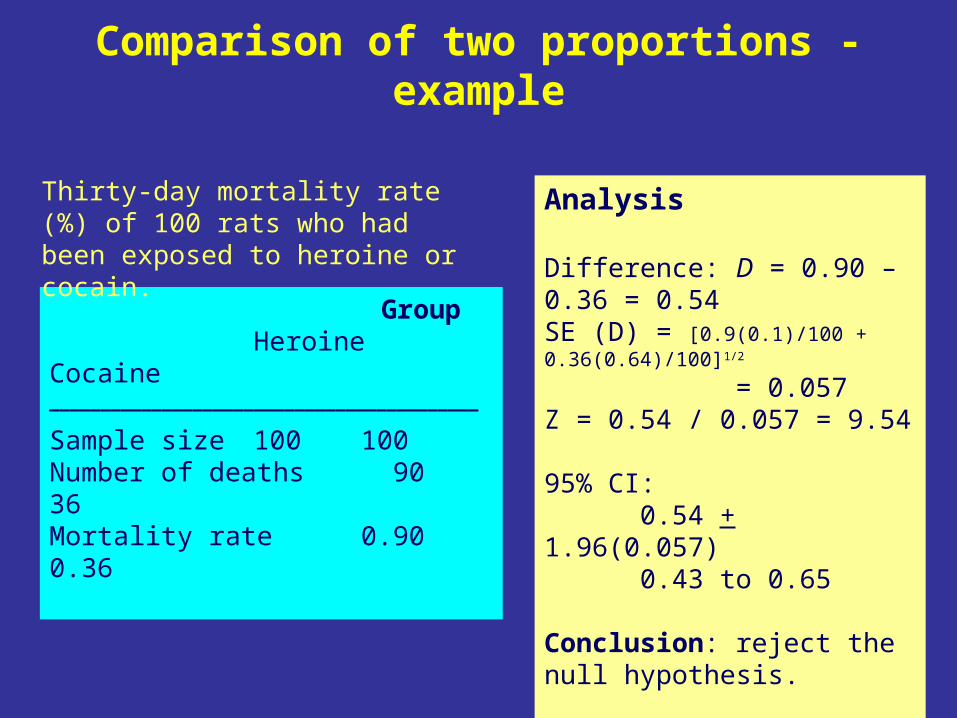
Comparison of two proportions - example
GroupHeroine Cocaine
__________________________________________
Sample size 100 100Number of deaths 90 36Mortality rate 0.90 0.36
Thirty-day mortality rate (%) of 100 rats who had been exposed to heroine or cocain.
Analysis
Difference: D = 0.90 – 0.36 = 0.54SE (D) = [0.9(0.1)/100 + 0.36(0.64)/100]1/2
= 0.057Z = 0.54 / 0.057 = 9.54
95% CI:0.54 + 1.96(0.057)0.43 to 0.65
Conclusion: reject the null hypothesis.

Comparison of two proportions - R
events <- c(90, 36)
total <- c(100, 100)
prop.test(events, total)
2-sample test for equality of proportions with continuity correction
data: deaths out of total X-squared = 60.2531, df = 1, p-value = 8.341e-15alternative hypothesis: two.sided 95 percent confidence interval: 0.4190584 0.6609416 sample estimates:prop 1 prop 2 0.90 0.36

Comparison of >2 proportions – Chi square analysis
table(sex, ethnicity)
ethnicity
sex African Asian Caucasian Others
Female 4 43 22 0
Male 4 17 8 2
females <- c(4, 43, 22, 0)
total <- c(8, 60, 30, 2)
prop.test(females, total)

Comparison of >2 proportions – Chi square analysis
4-sample test for equality of proportions without continuity
correction
data: females out of total X-squared = 6.2646, df = 3, p-value = 0.09942alternative hypothesis: two.sided sample estimates: prop 1 prop 2 prop 3 prop 4 0.5000000 0.7166667 0.7333333 0.0000000
Warning message:Chi-squared approximation may be incorrect in:
prop.test(females, total)

Summary
• Examine the distribution of data– Mean and variance: systematic difference?
– Normally distributed ?
• Transformation?
• Present confidence intervals (and p-values)