data analysis with galaxy on the cloud
DESCRIPTION
Workshop slides demonstrating how to setup a CloudMan cluster and use Galaxy to perform the Galaxy 101 exercise.TRANSCRIPT

Data analysis with Galaxy on the Cloud
Enis Afgan

100sGB
100+

How to use the cloud?
1. Get an account on the supported cloud
2. Start a master instance via a launcher app
3. Use CloudMan’s web interface on the master instance to manage the platform

Agenda details
•Launch an instance
•Demonstrate the following CloudMan features and prepare for the data analysis part:
•Manual & Auto-scaling
•Using an S3 bucket as a data source
•Accessing an instance over ssh
•Customizing an instance
•Controlling Galaxy
•Sharing-an-instance
•Perform data analysis in Galaxy
• Find exons with most SNPs
Inte
ra
cti
on
flo
w

YOUR TURNhttp://bit.ly/goc-ws

Launch an instance1. Slides @ bit.ly/goc-ws
2. Load biocloudcentral.org
3. Enter the access key and secret key
provided at http://bit.ly/ws-creds
4. Provide your email address
5. Use your initials as the cluster name
6. Set any password (and remember it)
7. Keep Large instance type
8. Start your instance
Wait for the instance to start (~2-3 minutes)For more details, seehttp://cloudman.irb.hr

Scaling computation

Agenda details
• Launch an instance ✓
•Demonstrate the following CloudMan features and prepare for the data analysis part:
•Manual & Auto-scaling
•Using an S3 bucket as a data source
•Accessing an instance over ssh
•Customizing an instance
•Controlling Galaxy
•Sharing-an-instance
•Perform data analysis in Galaxy
• Find exons with most SNPs
Inte
ra
cti
on
flo
w

Manual scaling•Explicitly add 1 worker node to your
cluster
• Node type corresponds to node processing capacity
• Research use of Spot instances
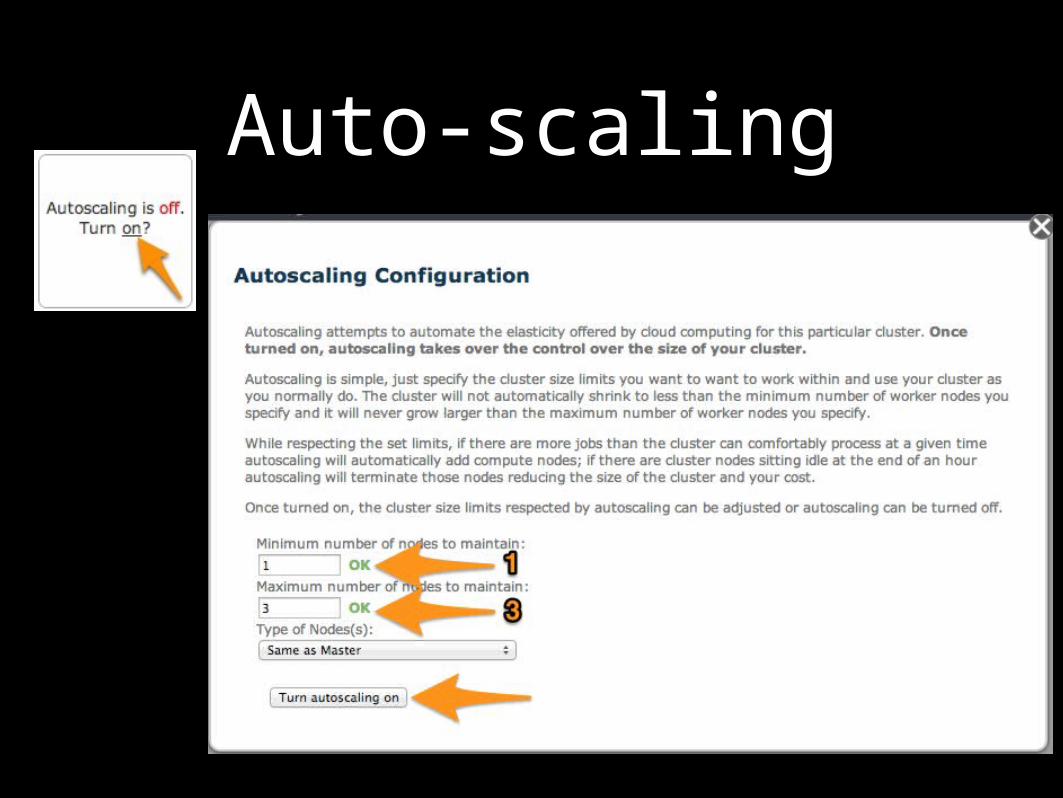
Auto-scaling

Agenda details
• Launch an instance ✓
•Demonstrate the following CloudMan features and prepare for the data analysis part:
•Manual & Auto-scaling ✓
•Using an S3 bucket as a data source
•Accessing an instance over ssh
•Customizing an instance
•Controlling Galaxy
•Sharing-an-instance
•Perform data analysis in Galaxy
•Find exons with most SNPs
Inte
ra
cti
on
flo
w

On human chromosome 22, which coding exons have the most SNPs in them?

A Rough Plan
•Get some data
•Coding exons on chromosome 22
•SNPs on chromosome 22
•Mess with it
• Identify which exons have SNPs
•Count SNPs per exon
•Visualize our results
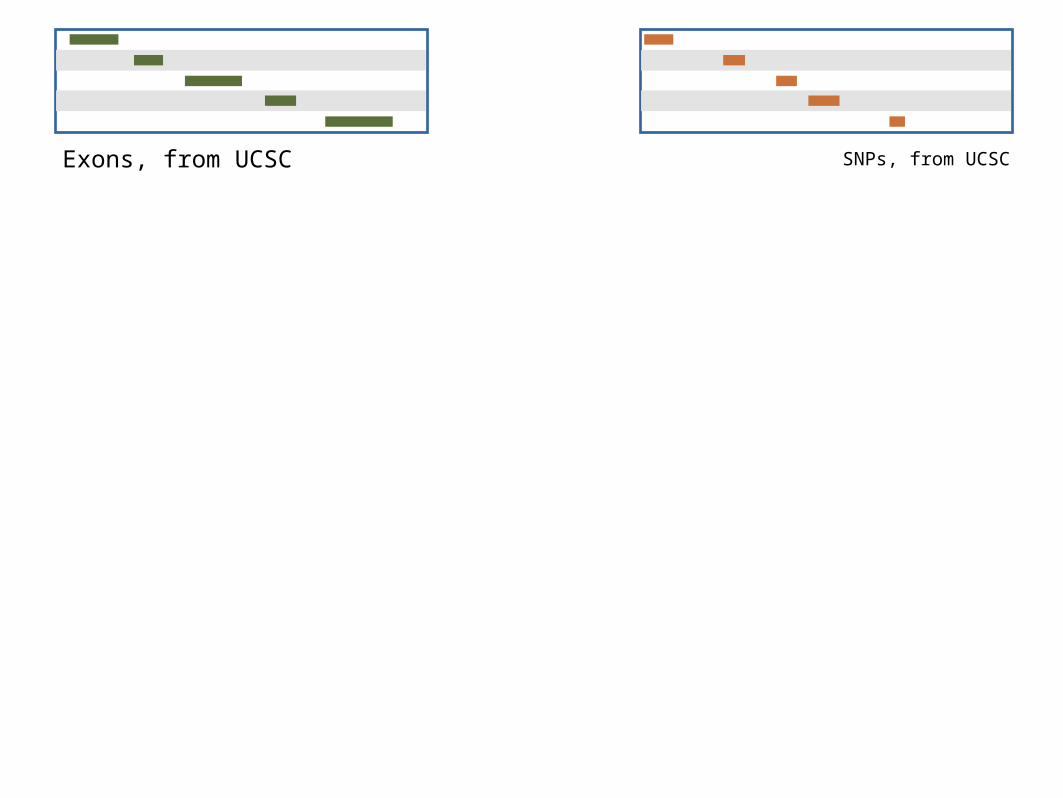
Exons, from UCSC SNPs, from UCSC
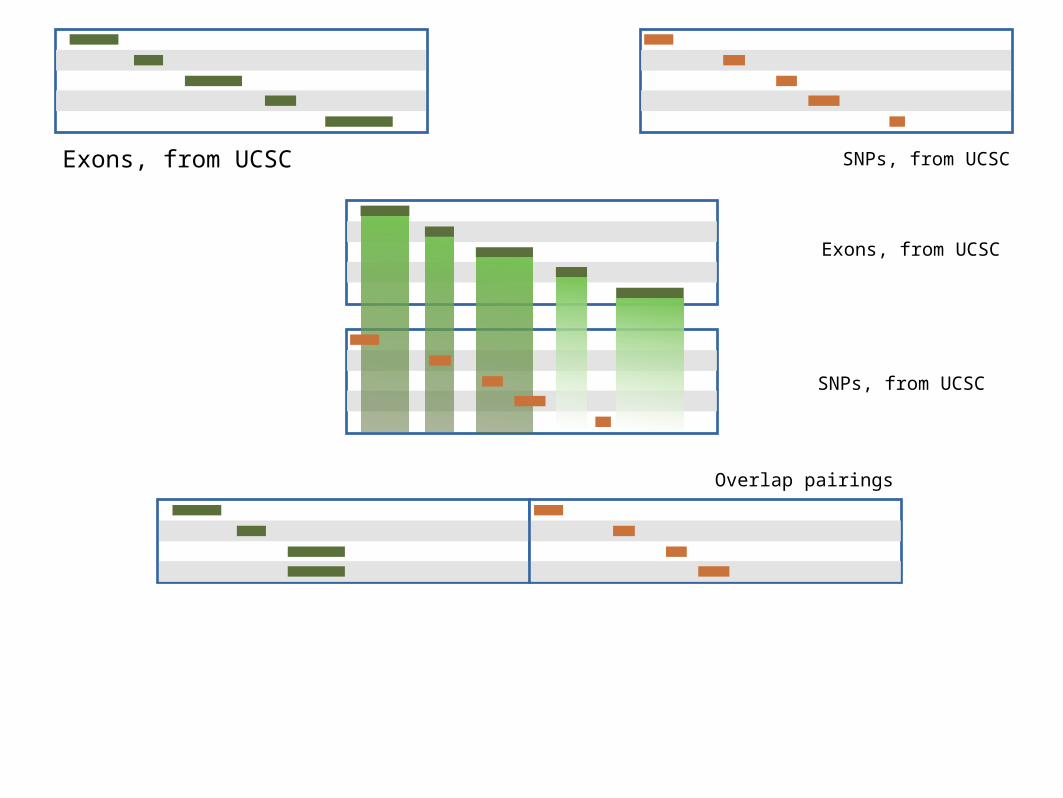
Exons, from UCSC SNPs, from UCSC
Exons, from UCSC
SNPs, from UCSC
Overlap pairings
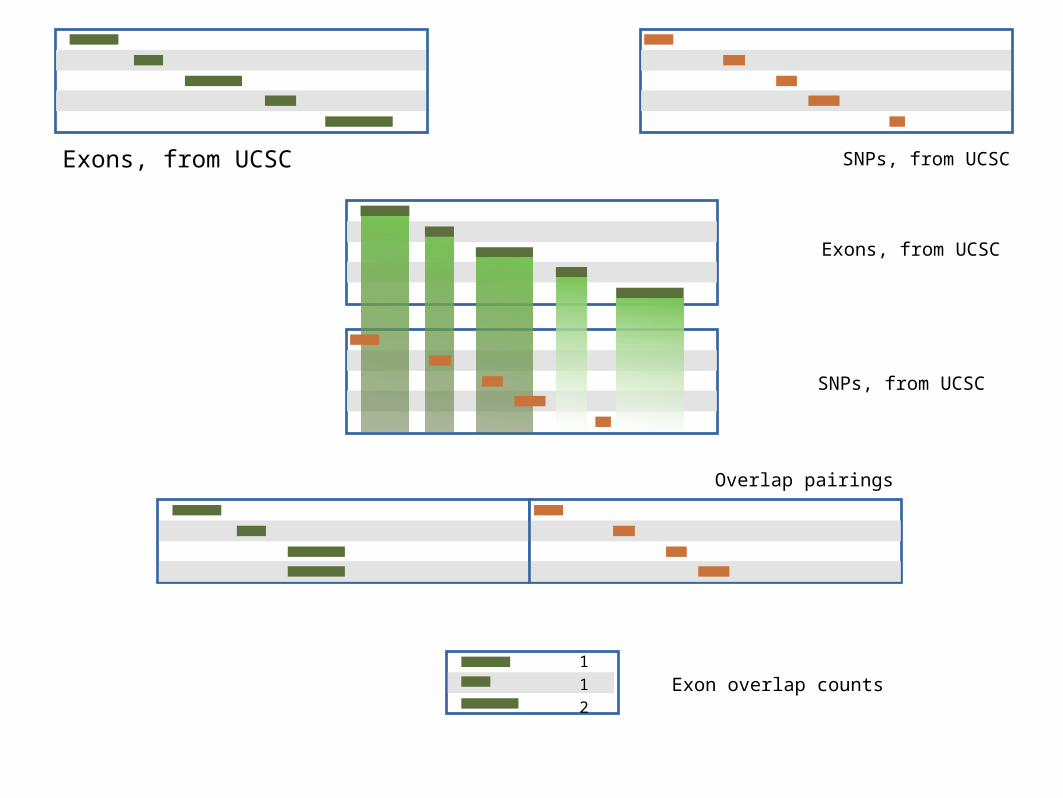
Exons, from UCSC SNPs, from UCSC
112
Exons, from UCSC
SNPs, from UCSC
Overlap pairings
Exon overlap counts

Exons, from UCSC
112
Exon overlap counts

Exons, from UCSC
112
Exon overlap counts
112
Join on exon name000
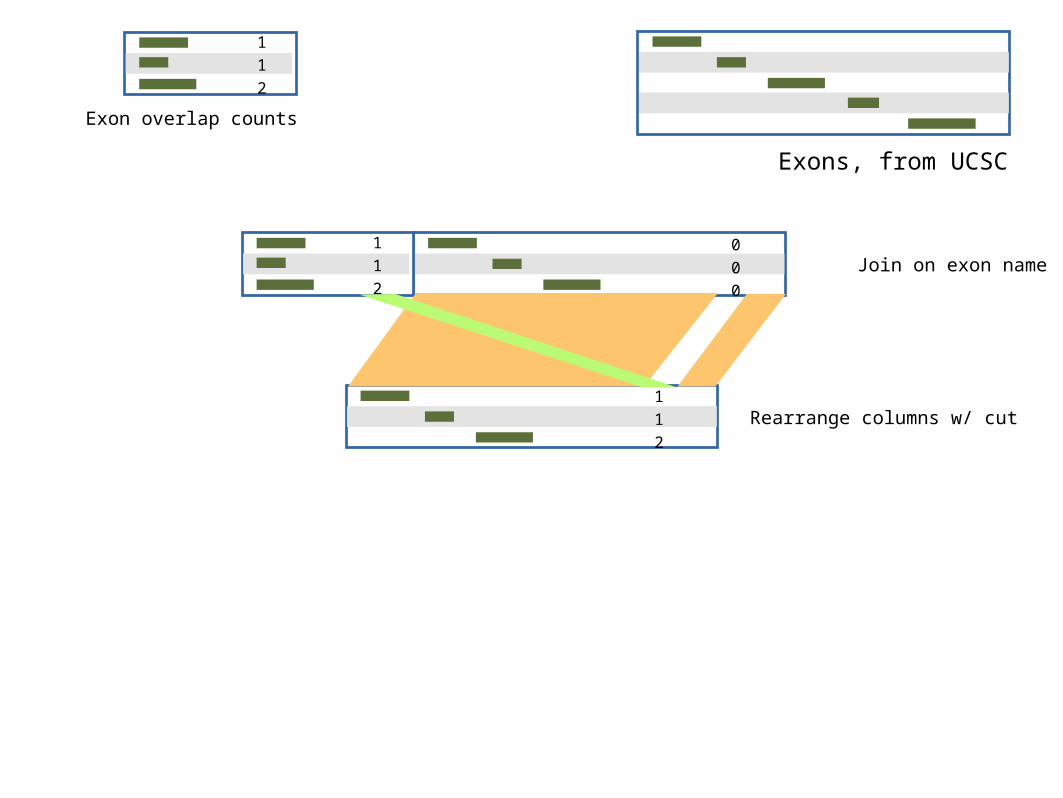
Exons, from UCSC
112
Exon overlap counts
112
Join on exon name000
112
Rearrange columns w/ cut

Your turnhttp://usegalaxy.org/galaxy101
Slides @ http://bit.ly/gxy-ws

Agenda details
• Launch an instance ✓
•Demonstrate the following CloudMan features and prepare for the data analysis part:
•Manual & Auto-scaling ✓
•Using an S3 bucket as a data source
•Accessing an instance over ssh
•Customizing an instance
•Controlling Galaxy
•Sharing-an-instance
•Perform data analysis in Galaxy
• Find exons with most SNPs ✓
Inte
ra
cti
on
flo
w
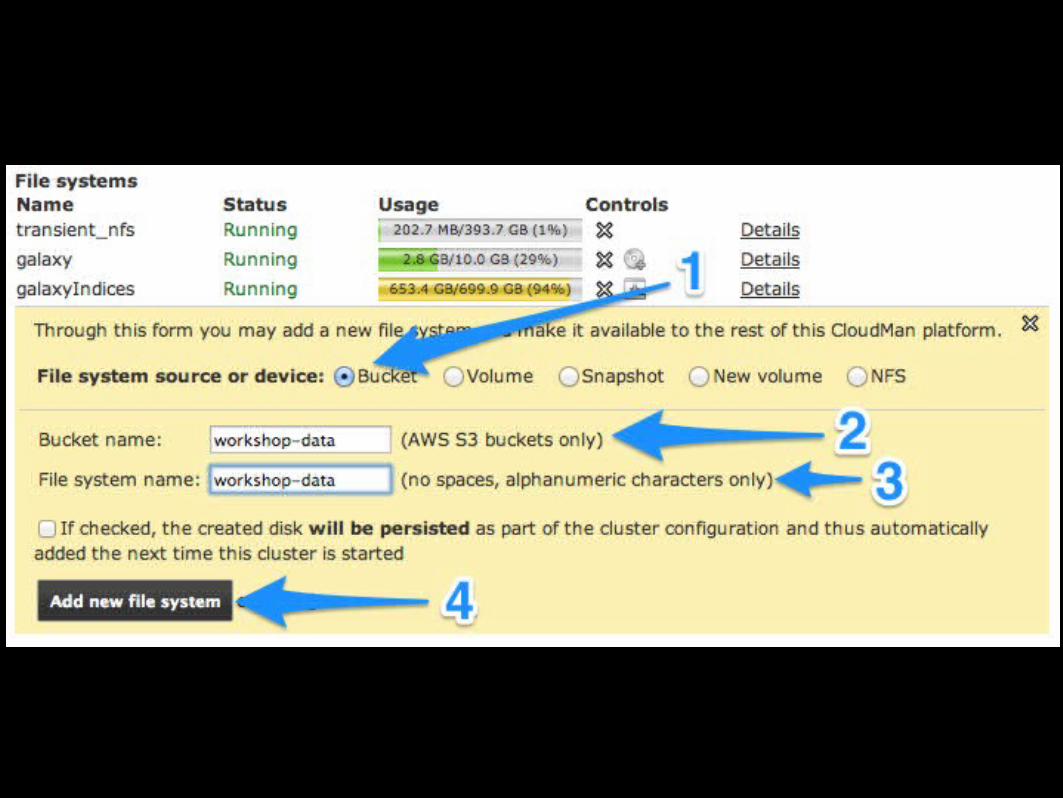
Using an S3 bucket as a data source
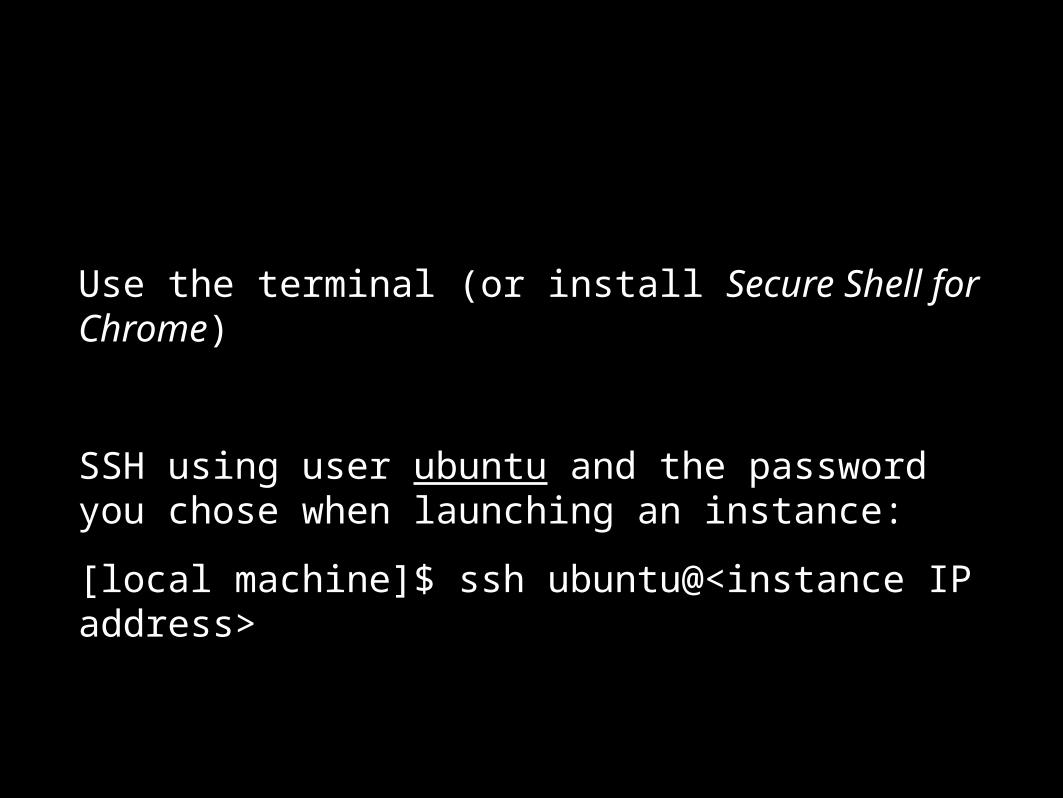
Accessing an instance over ssh
Use the terminal (or install Secure Shell for Chrome)
SSH using user ubuntu and the password you chose when launching an instance:
[local machine]$ ssh ubuntu@<instance IP address>

Once logged in
• You have full system access to your instance, including sudo; use it as any other system
• galaxy user exists on the system and should be used when manipulating Galaxy (sudo su galaxy)
•Can submit any jobs via the standard qsub command

Customizing an instance• Edit Galaxy’s configuration
$ sudo su galaxy
$ cd /mnt/galaxy/galaxy-app
$ vi universe_wsgi.ini
allow_library_path_paste = True
Controlling Galaxy
• Start/stop Galaxy application
• Add an admin user
• Use the email you registered with

S3 bucket as a data library
• Within Galaxy, create a Data Library, using S3 bucket path as the data source (/mnt/workshop-data)
• This will import all the datasets into the Data Library
• Import that dataset into a history

Sharing-an-Instance• Share the entire CloudMan platform
• Includes all of user data and even the customizations
• Publish a self-contained analysis
• Make a note of the share-string and sendit to your neighbor

/mnt/galaxy[Indices]
/mnt/cm/paster.log cm-<hash>
/usr/bin/ec2autorun.log/tmp/cm/cm_boot.log
Troubleshooting
1°
2°
3°

CLUSTER ON THE COMMAND LINE

Distributed Job Manager (DRM)
•Controls job execution on a (set of) resource(s)
•A job: an invocation of a program
•Manages job load
•Provides ability to monitor system and job status
•Popular DRMs: Sun Grid Engine (SGE), Portable Batch Scheduler (PBS), TORQUE, Condor, Load Sharing Facility (LSF)

Customize your instance -
install a new tool$ cd /mnt/galaxy/export$ wget http://heanet.dl.sourceforge.net/project/dnaclust/parallel_release_3/dnaclust_linux_release3.zip$ unzip dnaclust_linux_release3.zip$ cd dnaclust_linux_release3$ chmod +x *
$ cp /mnt/workshop-data/mtDNA.fasta .
Get a copy of a sample dataset Don’t forget

Use the new tool in the cluster mode
1. Create a new sample shell file to run the tool; call it job_script.sh with the following content:#$ -cwd./dnaclust -l -s 0.9 /mnt/workshop-data/mtDNA.fasta
2. Submit single job to SGE queueqsub job_script.sh
3. Check the queue: qstat -f4. Job output will be in the local directory in file job_script.sh.o#5. Start a number of instances of the script:qsub job_script.sh (*10)watch qstat –f
1. See all jobs lined up6. See auto-scaling in (using /cloud) [1.5-2 mins]7. Go back to command prmopt, see jobs being distributed