data preprocessing - ui open...
TRANSCRIPT

Data PreprocessingLecture 3/DMBI/IKI83403T/MTI/UILecture 3/DMBI/IKI83403T/MTI/UI
Yudho Giri Sucahyo, Ph.D, CISA ([email protected])y , , (y )Faculty of Computer Science, University of Indonesia
Obj tiObjectivesMotivation: Why preprocess the Data?Motivation: Why preprocess the Data?Data Preprocessing TechniquesData CleaningData Integration and TransformationData Integration and TransformationData Reduction
University of Indonesia2
Wh P th D t ?Why Preprocess the Data?Quality decisions must be based on quality dataQuality decisions must be based on quality dataData could be incomplete, noisy, and inconsistentData warehouse needs consistent integration of quality dataq yIncomplete
L ki ib l i ib f iLacking attribute values or certain attributes of interestContaining only aggregate dataCauses:
Not considered important at the time of entryEquipment malfunctionsData not entered due to misunderstanding
University of Indonesia
Inconsistent with other recorded data and thus deleted3
Wh P th D t ? (2)Why Preprocess the Data? (2)Noisy (having incorrect attribute values)Noisy (having incorrect attribute values)
Containing errors, or outlier values that deviate from the expectedexpectedCauses:
Data collection instruments used may be faultyHuman or computer errors occuring at data entryErrors in data transmission
InconsistentContaining discrepancies in
the department codes the department codes used to categorize items
University of Indonesia4

Wh P th D t ? (3)Why Preprocess the Data? (3)“Clean” the data by filling in missing values smoothing Clean the data by filling in missing values, smoothing noisy data, identifying or removing outliers, and resolving inconsistenciesinconsistencies.Some examples of inconsistencies:
customer_id vs cust_idBill vs William vs B.
Some attributes may be inferred from others. Data cleaning including detection and removal of redundancies g gthat may have resulted.
University of Indonesia5
D t P i T h iData Preprocessing TechniquesData CleaningData Cleaning
To remove noise and correct inconsistencies in the data
Data IntegrationMerges data from multiple sources into a coherent data g pstore, such as a data warehouse or a data cube
Data TransformationData TransformationNormalization (to improve the accuracy and efficiency of mining algorithms involving distance measurements E g mining algorithms involving distance measurements E.g. Neural networks, nearest-neighbor)
D t Di ti tiData DiscretizationData Reduction
University of Indonesia6
D t P i T h i (2)Data Preprocessing Techniques (2)Data Reduction
Warehouse may store terabytes of data
Complex data analysis/mining may take a very long time to run on the p y g y y gcomplete data set
Obtains a reduced representation of the data set that is much smaller in pvolume, yet produces the same (or almost the same) analytical results.
Strategies for Data ReductionStrategies for Data ReductionData aggregation (e.g., building a data cube)Dimension reduction (e.g. removing irrelevant attributes through Dimension reduction (e.g. removing irrelevant attributes through correlation analysis)Data compression (e.g. using encoding schemes such as minimum length encoding or wavelets)Numerosity reduction
University of Indonesia
Generalization7
D t P i T h i (3)Data Preprocessing Techniques (3)
University of Indonesia8

D t Cl i Mi i V lData Cleaning – Missing Values1. Ignore the tuple1. Ignore the tuple
Usually done when class label is missing classification Not effective when the missing values in attributes spread in Not effective when the missing values in attributes spread in different tuples
F ll h l ll d f bl ?2. Fill in the missing value manually: tedious + infeasible?3. Use a global constant to fill in the missing valueg g
‘unknown’, a new class?Mining program may mistakenly think that they form an Mining program may mistakenly think that they form an interesting concept, since they all have a value in common not recommendednot recommended
4. Use the attribute mean to fill in the missing value i
University of Indonesia
avg income9
D t Cl i Mi i V l (2)Data Cleaning – Missing Values (2)5 Use the attribute mean for all samples belonging to the 5. Use the attribute mean for all samples belonging to the
same class as the given tuple same credit risk tcategory
6. Use the most probable value to fill in the missing valueDetermined with regression, inference-based tools such as Bayesian formalism, or decision tree inductiony
Methods 3 to 6 bias the data. The filled-in value may not be ycorrect. However, method 6 is a popular strategy, since:
It uses the most information from the present data to predict missing valuesIt uses the most information from the present data to predict missing values
There is a greater chance that the relationships between income and the other attributes are preserved
University of Indonesia
attributes are preserved.
10
Data Cleaning –N i d I t (I i t t) D tNoise and Incorrect (Inconsistent) DataNoise is a random error or variance in a measured variableNoise is a random error or variance in a measured variable.How can we smooth out the data to remove the noise?Binning Method
Smooth a sorted data value by consulting its “neighborhood”, that is, the values around it.The sorted values are distributed into a number of buckets, or bins.Because binning methods consult the neighborhood of values, they perform local smoothing.Binning is also uses as a discretizatin technique (will be discussed later)
University of Indonesia11
Data Cleaning – Noisy DataBi i M th dBinning Methods
* Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 26, 25, 28, 29, 34p ( ) , , , , , , , , , , ,
* Partition into (equidepth) bins of depth 3, each bin contains three values:
- Bin 1: 4, 8, 9, 15, , ,
- Bin 2: 21, 21, 24, 26- Bin 3: 25, 28, 29, 34, , ,
* Smoothing by bin means:
- Bin 1: 9, 9, 9, 9, , ,
- Bin 2: 23, 23, 23, 23
- Bin 3: 29, 29, 29, 29, , ,
* Smoothing by bin boundaries: the larger the width, the greater the effect- Bin 1: 4, 4, 4, 15, , ,
- Bin 2: 21, 21, 26, 26
- Bin 3: 25, 25, 25, 34
University of Indonesia
, , ,
12

Data Cleaning – Noisy DataCl t iClustering
Similar values are organized into groups or clustersSimilar values are organized into groups, or clusters.Values that fall outside of the set of clusters may be
id d tliconsidered outliers.
University of Indonesia13
Data Cleaning – Noisy DataR iRegression
Data can be smoothed by yData can be smoothed by fitting the data to a function such as with
y
Y1function, such as with regression.Li i i l
Y1
Linear regression involves finding the best line to fit
y = x + 1Y1’
two variables, so that one variable can be used to xX1predict the other.Multiple linear regression p g
> 2 variables, multidimensional surface
University of Indonesia
multidimensional surface14
D t S thi D t R d tiData Smoothing vs Data ReductionMany methods for data smoothing are also methods Many methods for data smoothing are also methods for data reduction involving discretization.Examples
Binning techniques reduce the number of distinct values g qper attribute. Useful for decision tree induction which repeatedly make value comparisons on sorted data.Concept hierarchies are also a form of data discretization that can also be used for data smoothng.g
Mapping real price into inexpensive, moderately_priced, expensivepReducing the number of data values to be handled by the mining process.
University of Indonesia
mining process.
15
D t Cl i I i t t D tData Cleaning - Inconsistent DataMay be corrected manuallyMay be corrected manually.Errors made at data entry may be corrected by
f i t l d ith ti d i d performing a paper trace, coupled with routines designed to help correct the inconsistent use of codes.Can also using tools to detect the violation of known data constraints.
University of Indonesia16

D t I t ti d T f tiData Integration and TransformationData Integration: combines data from multiple data storesData Integration: combines data from multiple data storesSchema integration
integrate metadata from different sources
Entity identification problem: identify real world entities from y p ymultiple data sources, e.g., A.cust-id ≡ B.cust-#
D t ti d l i d t l fli tDetecting and resolving data value conflicts
for the same real world entity, attribute values from different sources are different
possible reasons: different representations, different scales (feet possible reasons: different representations, different scales (feet vs metre)
University of Indonesia17
D t T f tiData TransformationData are transformed into forms appropriate for miningData are transformed into forms appropriate for miningMethods:
Smoothing: binning, clustering, and regressionAggregation: summarization, data cube constructiongg gGeneralization: low-level or raw data are replaced by higher-level concepts through the use of concept hierarchiesp g p
Street city or countryNumeric attributes of age young middle-aged seniorNumeric attributes of age young, middle-aged, senior
Normalization: attribute data are scaled so as to fall within a small specified range such as 0 0 to 1 0small specified range, such as 0.0 to 1.0
Useful for classification involving neural networks, or distance measurements such as nearest neighbor classification and clustering
University of Indonesia
measurements such as nearest neighbor classification and clustering
18
D t T f ti (2)Data Transformation (2)
N li i l d f ll i hi ll ifi d Normalization: scaled to fall within a small, specified range
min-max normalization
AAAA minnewminnewmaxnew
minmaxminvv _)__(' +−
−=
z-score normalization
AA minmax −
A
dt dmeanvv ' −
=
normalization by decimal scaling
Adevstand _y g
vv'= Where j is the smallest integer such that Max(| |)<1'vUniversity of Indonesia
19
j10Where j is the smallest integer such that Max(| |) 1v
D t R d ti D t C b A tiData Reduction – Data Cube AggregationData consist of sales per quarter for several years User Data consist of sales per quarter, for several years. User interested in the annual sales (total per year) data can b d h h l i d i h be aggregated so that the resulting data summarize the total sales per year instead of per quarter.
Resulting data set is smaller in volume, without loss of information necessary for the analysis taskinformation necessary for the analysis task.
See Figure 3.4 [JH]
University of Indonesia20

Di i lit R d tiDimensionality ReductionDatasets for analysis may contain hundreds of Datasets for analysis may contain hundreds of attributes, many of which may be irrelevant to the
i i t k d d tmining task, or redundant.Leaving out relevant attributes or keeping irrelevant attributes can cause confusion for the mining algorithm, poor quality of discovered patterns.algorithm, poor quality of discovered patterns.Added volume of irrelevant or redundant attributes
l d th i i can slow down the mining process.Dimensionality reduction reduces the data set size by removing such attributes from it.
University of Indonesia21
Di i lit R d ti (2)Dimensionality Reduction (2)The goal of attribute subset selection (also known as The goal of attribute subset selection (also known as feature selection) is to find a minimum set of attributes such that the resulting probability distribution of the data classes is that the resulting probability distribution of the data classes is as close as possible to the original distribution obtained using all attributes.For d attributes, there are 2d possible subsets.The best (and worst) attributes are typically determined using The best (and worst) attributes are typically determined using tests of statistical significance. Attribute evaluation measures such as information gain can be usedsuch as information gain can be used.Heuristic methods
St i f d l tiStepwise forward selectionStepwise backward selection (or combination of both)Decision tree induction
University of Indonesia
Decision tree induction22
Dimensionality Reduction (3)E l f D i i T I d tiExample of Decision Tree Induction
Initial attribute set:{A1, A2, A3, A4, A5, A6}
A4 ?
A1? A6?A1? A6?
Class 1 Class 2 Class 1 Class 2
> Reduced attribute set: {A1, A4, A6}
University of Indonesia23
D t C iData CompressionData encoding or transformations are applied so as to Data encoding or transformations are applied so as to obtain a reduced or compressed representation of the original dataoriginal data.Lossless data compression technique: If the original data
b d f h d d i h can be reconstructed from the compressed data without any loss of information.Lossy data compression technique: we can reconstruct only an approximation of the original data.y pp gTwo popular and effective methods of lossy data compression: wavelet transformts and principal components compression: wavelet transformts and principal components analysis.
University of Indonesia24

D t C i (2) Data Compression (2)
O i i l D t C dOriginal Data Compressed Data
l llossless
Original DataApproximated
University of Indonesia25
N it R d tiNumerosity ReductionParametric methods:Parametric methods:
Assume the data fits some model, estimate model parameters, store only the parameters and discard the data (except store only the parameters, and discard the data (except possible outliers).Log-linear models: obtain value at a point in m-D space as the Log-linear models: obtain value at a point in m-D space as the product on appropriate marginal subspaces. (see Slide 14)
Non parametric methods:Non-parametric methods:No assume modelsThree major families:
Clustering (see Slide 13)HistogramsSampling
University of Indonesia26
N it R d ti Hi tNumerosity Reduction - Histograms
A l d d i 40
A popular data reduction technique 35Divide data into buckets and store average (sum) for
h b k 25
30
each bucketPartitionng rules: 20
25
EquiwidthEquidepth 10
15EquidepthEtc.
5
10
010000 30000 50000 70000 90000
University of Indonesia27
N it R d ti S liNumerosity Reduction - SamplingAllows a large data set to be represented by a much Allows a large data set to be represented by a much smaller random sample (or subset) of the data.Ch t ti b t f th d tChoose a representative subset of the data
Simple random sampling may have very poor performance in th f kthe presence of skew
Develop adaptive sampling methodsStratified sampling:
Approximate the percentage of each class (or subpopulation of ) h ll d b interest) in the overall database
Used in conjunction with skewed data
Si l d l i h l (SRSWOR)Simple random sample without replacement (SRSWOR)Simple random sample with replacement (SRSWR)
University of Indonesia28
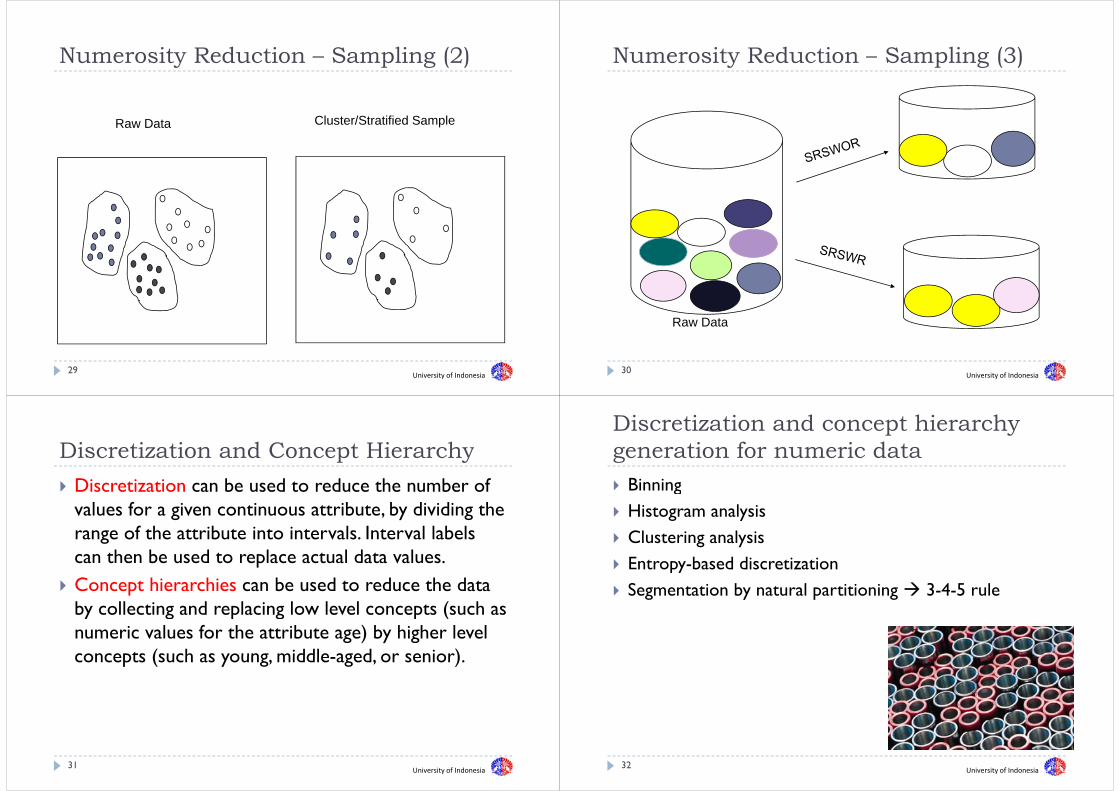
N it R d ti S li (2)Numerosity Reduction – Sampling (2)
Raw Data Cluster/Stratified Sample
University of Indonesia29
N it R d ti S li (3)Numerosity Reduction – Sampling (3)
Raw Data
University of Indonesia30
Di ti ti d C t Hi hDiscretization and Concept HierarchyDiscretization can be used to reduce the number of Discretization can be used to reduce the number of values for a given continuous attribute, by dividing the
f th tt ib t i t i t l I t l l b l range of the attribute into intervals. Interval labels can then be used to replace actual data values.Concept hierarchies can be used to reduce the data by collecting and replacing low level concepts (such as by collecting and replacing low level concepts (such as numeric values for the attribute age) by higher level concepts (such as young middle aged or senior)concepts (such as young, middle-aged, or senior).
University of Indonesia31
Discretization and concept hierarchy ti f i d tgeneration for numeric data
BinningBinningHistogram analysisClustering analysisEntropy-based discretizationpySegmentation by natural partitioning 3-4-5 rule
University of Indonesia32

E l f 3 4 5 lExample of 3-4-5 rulecount
msd=1,000 Low=-$1,000 High=$2,000Step 2:
Step 1:
-$351 -$159 profit $1,838 $4,700
Min Low (i.e, 5%-tile) High(i.e, 95%-0 tile) Max
(-$1,000 - $2,000)
(-$1,000 - 0) (0 -$ 1,000)
Step 3:
($1,000 - $2,000)
(-$4000 -$5,000)
( $400 0) (0 $1 000)($2,000 - $5, 000)($1 000 - $2 000)
Step 4:
(-$400 - 0)
(-$400 --$300)
(0 - $1,000)
(0 -
$200)($200 -$400)
($2,000 -$3,000)
($1,000 $2, 000)
($1,000 -$1,200)($1,200 -
(-$300 --$200)
(-$200 --$100)
$400)
($400 -$600)
($600 -
($3,000 -$4,000)
($4,000 -
($1,400)
($1,400 -$1,600)
($1 600 -
University of Indonesia33
(-$100 -0)
($600 $800) ($800 -
$1,000)$5,000)
($1,600 $1,800) ($1,800 -
$2,000)
Concept hierarchy generation for t i l d tcategorical data
Categorical data are discrete data Have a finite Categorical data are discrete data. Have a finite number of distinct values, with no ordering among the values Ex Location job categoryvalues. Ex. Location, job category.Specification of a set of attributes:
country 15 distinct valuesConcept hierarchy can be automatically generated
province_or_ state 65 distinct valuesbased on the number of distinct values per attribute
city 3567 distinct valuesin the given attribute set. The attribute with the most di ti t l i l d t
street 674,339 distinct valuesdistinct values is placed at the lowest level of the hierarchy
University of Indonesia34
hierarchy.
C l iConclusionData preparation is a big issue for both warehousing Data preparation is a big issue for both warehousing and miningData preparation includes
Data cleaning gData integration and Data transformationData reduction and feature selectionData reduction and feature selectionDiscretization
A l t th d h b d l d b t till A lot a methods have been developed but still an active area of research
University of Indonesia35
R fReferences[JH] Jiawei Han and Micheline Kamber Data Mining: [JH] Jiawei Han and Micheline Kamber, Data Mining: Concepts and Techniques, Morgan Kaufmann, 2001.
University of Indonesia36