data warehousing concepts - krishna training data warehousing concepts what is enterprise? what is...
TRANSCRIPT
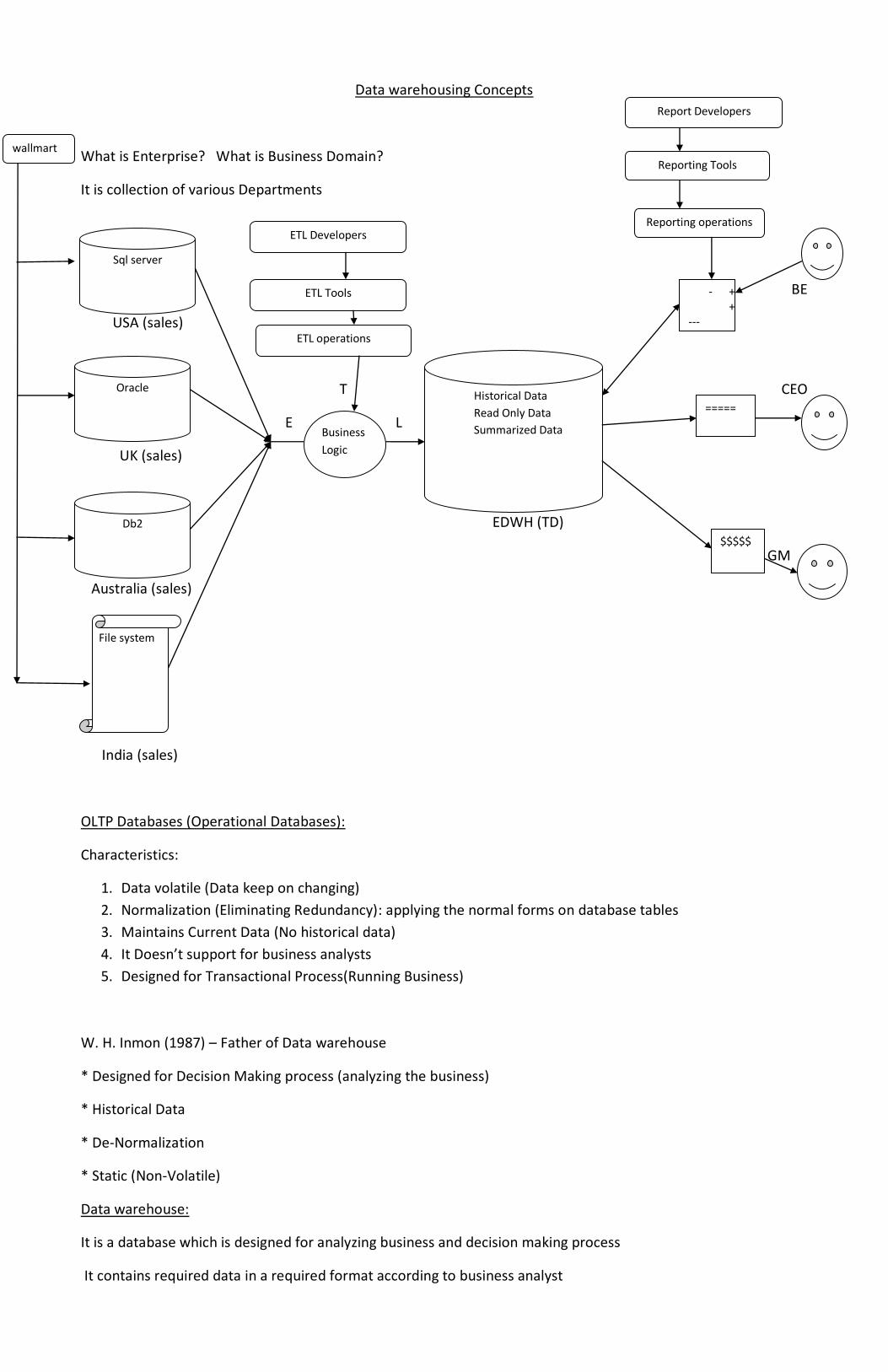
Data warehousing Concepts
What is Enterprise? What is Business Domain?
It is collection of various Departments
BE
USA (sales)
T CEO
E L
UK (sales)
EDWH (TD)
GM
Australia (sales)
India (sales)
OLTP Databases (Operational Databases):
Characteristics:
1. Data volatile (Data keep on changing)
2. Normalization (Eliminating Redundancy): applying the normal forms on database tables
3. Maintains Current Data (No historical data)
4. It Doesn’t support for business analysts
5. Designed for Transactional Process(Running Business)
W. H. Inmon (1987) – Father of Data warehouse
* Designed for Decision Making process (analyzing the business)
* Historical Data
* De-Normalization
* Static (Non-Volatile)
Data warehouse:
It is a database which is designed for analyzing business and decision making process
It contains required data in a required format according to business analyst
Sql server
Oracle
Db2
File system
Historical Data
Read Only Data
Summarized Data Business
Logic
- ++
---
=====
$$$$$
wallmart
Reporting operations
Reporting Tools
Report Developers
ETL operations
ETL Tools
ETL Developers

Data warehouse: Ralph Kimball
DW is a database which is specifically designed for analyzing the business but not for business transactional
processing
DWH is a design to support decision making Process
Characteristic Features of Data warehouse (OLAP):
Time Variant:
DW is a time variant db which supports the users in analyzing the business with different time
periods
r variance
e
v
e
n
u
e Q1 Q1
EDWH
Non-Volatile: DW is a non-volatile db Once data entered into DW, It doesn’t reflect to the changes which take place in operational sources
Integrated DB: DW is an integrated db which can store the data in an integrated and homogeneous format T E
Subject Oriented DB: DW is a subject – Oriented DB which supports the business needs of individual depts. In the Enterprise Ex: Sales, HR, Accounts, Loans.. etc Decision Supporting System (DSS): Since a DW is a Design to support decision Making Process hence it is called as Decision Supporting System (DSS) Historical Database Read Only Database
2
0
0
9
2
0
1
0 Time
Year, quarter, month,
Week, day, hour, min,
sec
S1
S2
S3
EDWH
hr
sales
mrkt

Differences between OLTP and DWH (OLAP) databases OLTP Databases: 1. It is designed to support operational monitoring 2. Data is volatile 3. Current data 4. Detailed data 5. Normalized data 6. Designed to support ER Modeling 7. Designed for running the business 8. Designed for clerical access 9. More number of joins 10. Few indexes
Data warehouse database (OLAP):
1. It is designed to support decision making process 2. Data is non-volatile 3. Historical data 4. Summarized data 5. De-normalization 6. Designed to support Dimensional modeling 7. Designed for analyzing the business 8. Designed for managerial access 9. Few joins 10. More Indexes
Data Acquisition: It‘s process of extracting the relevant business information, transforming the data into a required business format and loading into a DWH It’s is designed with following process:
Data extraction
Data Transformation
Data loading
Staging area (Buffer)
Extraction Loading
DB
Types of ETL:
There are 2 types of ETL tools used in implementing data Acquisition
Code Based ETL:
o The data acquisition apply can be built using some Programming Languages like SQL, PL/SQL
Relational
Sources
ERP Sources
Mainframes
DWH Transformation
Data Acquisition

Eq: SAS BASE, SAS ACCESS, Tera data ETL Utilities ( bteq, fast load, fast export, multi load, tpump )
Drawbacks:
Development cost
Testing Increases
Maintenance
GUI Based ETL Tools:
Designed ETL application with a simple graphical user interface, point and click techniques
Ex: Informatica (7500) , datastage (700), ab-initio, data services, BODI
Data Extraction:
It is a process of reading the data from various types of sources such as relational sources, ERP sources,
mainframes sources, other sources etc
1. Relational Sources:
a. Oracle
b. Sql server
c. Teradata
d. DB2
e. Informix
f. Sybase
g. Red bricks
h. Neteeza
i. Mysql
j. Ingress
2. ERP Sources:
a. SAP R3
b. J.D.Edwards
c. Baan
d. Ramco Marshall
e. People soft
f. Sieble CRM
g. Oracle Applications
3. Mainframe sources:
a. COBOL files
b. IMS files
c. DB2
4. File sources:
a. Flat – files (text files,.csv,.txt,.xls,)
b. Xml files
5. Other sources:
a. Web log files
b. TIBCO MQ series
c. PDF
Data Transformation:
It is a process of cleaning the data and transforming the data into a required business format.

The following data transformation activities take place in staging area
Data merging
Data cleansing
Data scrubbing
Data aggregation
Data Merging:
It is process of combining the data from multiple inputs into a single output. There are 2 types of data merging
activities
1. Vertical Merging: One table data beside another table data is available.
2. Horizontal Merging: One table data below another table data is available.
empno staging
ename
OLTP(Oracle) job
deptno
deptno
dname
OLTP(sql server) loc
Oracle(ny) Staging Area
Sql server(ca)
Data cleansing:
It is a process of removing unwanted data from staging It is a process of changing inconsistencies and inaccuracies
Staging
Target(DB)
Source (DB)
Staging
Employee
Dept
Employee(s1)
Dept(s2)
Join
Sales(s1)100 rec
Sales(s2)150 rec
Union
India italy Autralia austria
Country Initcap(country) India Italy Australia Austria
Sales Amount $7.0 $9.950 $10.01
Round(salamnt,2)
$7.00 $9.11 $10.01
Empno,ename,job,dno,dname,loc
Oid,pid,pname,price,qty,totprice
100 records (s1)
150 records (s2)
WM

Data Scrubbing:
It is process of deriving new data definitions
Staging
Data Aggregation:
It is a process of calculation the summaries for a group of records using aggregate functions (avg, max, min….etc)
Staging:
It is a temporary memory where the above data processing activities takes place
Data loading:
It is a process of inserting the data into a target system. There are 2 types of data loads
1. Initial load (or) full load
2. Incremental load (or) Delta load
Initial (or) Full Load:
It’s process of loading all the required data at very first load
Incremental (or) Delta Load:
It’s a process of loading only new records after initial load
Customer + Cid + Cfname + Clname
Sales + Sid + Product + Qty + Price
Cname=Concat (cfname,
clname)
Qty*price=saleamnt
Customer + Cid + Cname
Sales + Sid +product + Qt + Saleamnt

ETL Plan:
CLIENT GUI (designer)
ODBC
S.Def T/R rule T.Def
+ Cid +cid +cfname +cname +clname +gender Source DB +gender
Source DB Target DB
ETL Plan
ETL PLAN: An ETL plan defines the graphical representation of data flow from source to target
It is designed with following inputs
Source Definition which defines extraction
Target Definition which defines loading
Transformation rule which defines Transformation(business logic)
ETL Plan tool
Mapping Informatica
Job Data stage
Graph Ab-Initio
Top-Down DWH Approach (W.H. Inmon):
According to W.H.Inmon, first we need to design an Enterprise Data warehouse, from EDW design a
small form of subject Oriented Department Design specific DB known as Data Mart.
Data Marts
Customer Customer +cid +cfname +clname +Gender(0,1)
T_Customer Concat (fn,ln),
decode (G,0,female,male)
T_CUSTOMER + CID +CNAME(fn,ln) +GENDER(0-f,1-m)
Extract Transformation Loading
ODBC(CS)
EDWH
Sales
Marketing
Financial
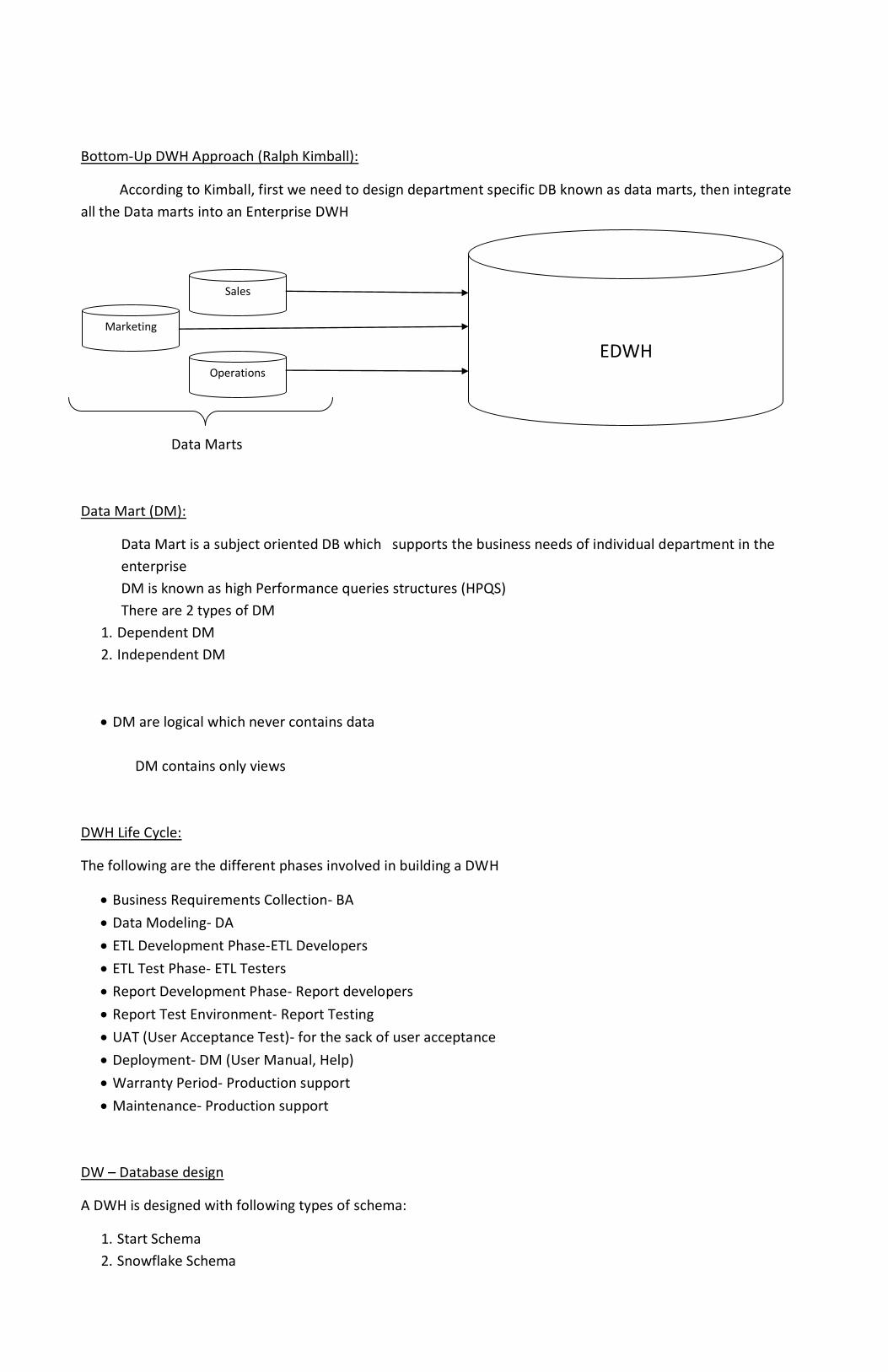
Bottom-Up DWH Approach (Ralph Kimball):
According to Kimball, first we need to design department specific DB known as data marts, then integrate
all the Data marts into an Enterprise DWH
Data Marts
Data Mart (DM):
Data Mart is a subject oriented DB which supports the business needs of individual department in the
enterprise
DM is known as high Performance queries structures (HPQS)
There are 2 types of DM
1. Dependent DM
2. Independent DM
DM are logical which never contains data
DM contains only views
DWH Life Cycle:
The following are the different phases involved in building a DWH
Business Requirements Collection- BA
Data Modeling- DA
ETL Development Phase-ETL Developers
ETL Test Phase- ETL Testers
Report Development Phase- Report developers
Report Test Environment- Report Testing
UAT (User Acceptance Test)- for the sack of user acceptance
Deployment- DM (User Manual, Help)
Warranty Period- Production support
Maintenance- Production support
DW – Database design
A DWH is designed with following types of schema:
1. Start Schema
2. Snowflake Schema
Sales
Marketing
Operations
EDWH

3. Integrated (or) Galaxy Schema (constellation schema)
Schema is a collection of objects (Tables)
Start schema:
A star schema is a logical database design which contains centrally located fact table which is surrounded by
dimension tables
Since the DB design looks like a star hence it is called star schema DB design
A fact table contains a composite key where each candidate key is a foreign key to the dimension tables
A fact table contains facts. Fact are numeric
Not every numeric is a fact but numeric which are of type key performance indicators are known as facts
A dimension is a descriptive data about the major aspects of business.
The Dimensions are used to describe key performance indicators known as facts.
A dimension table contains dimensions which are de-normalized
A star schema represents a simple subjects.
Customer Time
Sales
Product Store
Snowflake schema (DM)
In a snowflake schema a de-normalized dimensional table is spitted into one (or) more tables which results in
Normalization of dimensions
Disadvantages:
Query performance hampers coz of more number of joints
Advantages:
Table space can be minimized
Customer_id(pk) Name Address Phone Fax
Date_id(pk) Year Quarter Month Week Day
Product_id(pk) Category Sub-Category Product quantity
Store_id(pk) Country Region State city
Sale_id(pk)
Customer_id(fk)
Store_id(fk)
Product_id(fk)
Date_id(fk)
Quantity
Revenue
Profit
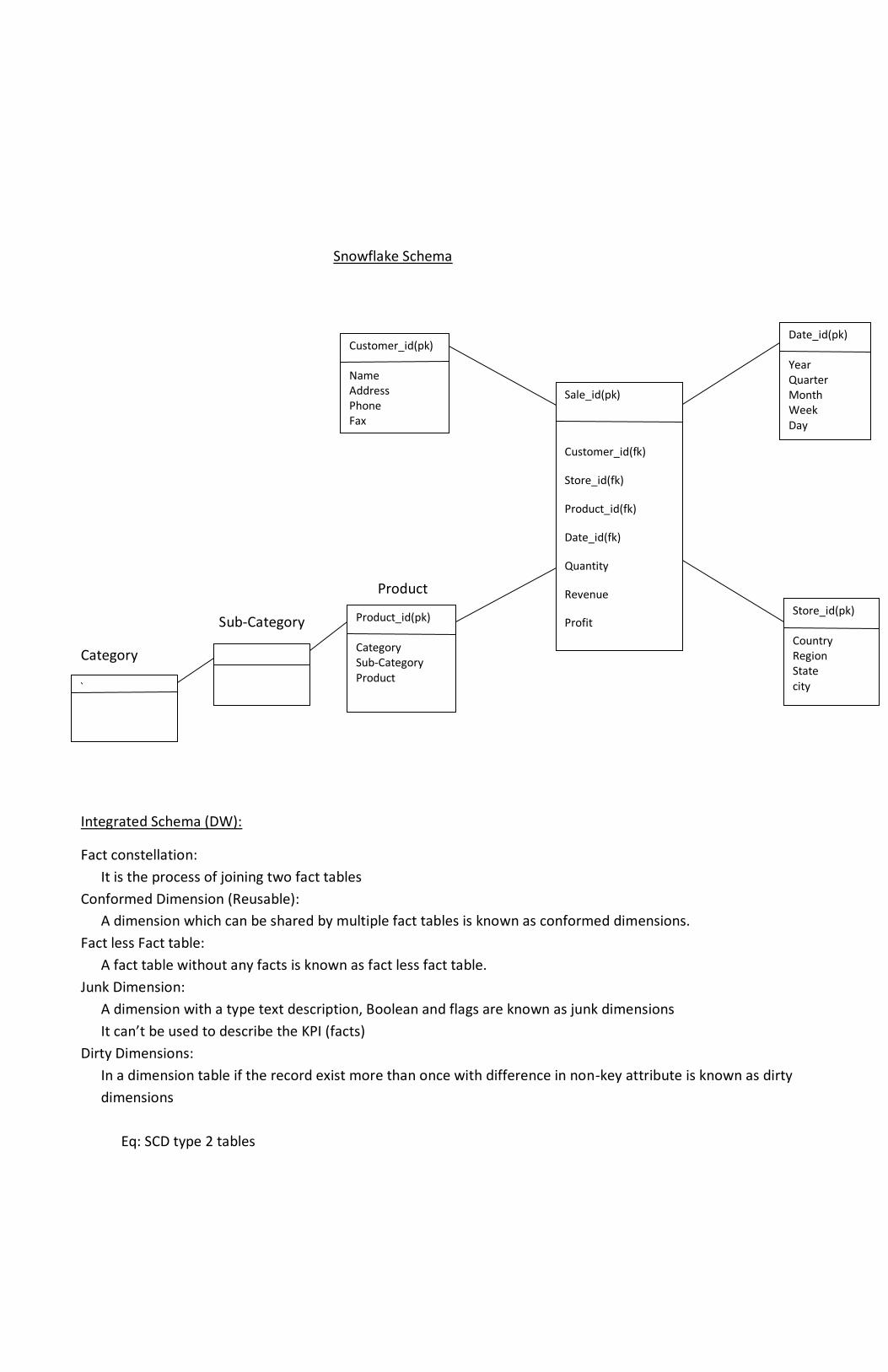
Snowflake Schema
Product
Sub-Category
Category
Integrated Schema (DW):
Fact constellation:
It is the process of joining two fact tables
Conformed Dimension (Reusable):
A dimension which can be shared by multiple fact tables is known as conformed dimensions.
Fact less Fact table:
A fact table without any facts is known as fact less fact table.
Junk Dimension:
A dimension with a type text description, Boolean and flags are known as junk dimensions
It can’t be used to describe the KPI (facts)
Dirty Dimensions:
In a dimension table if the record exist more than once with difference in non-key attribute is known as dirty
dimensions
Eq: SCD type 2 tables
Sale_id(pk)
Customer_id(fk)
Store_id(fk)
Product_id(fk)
Date_id(fk)
Quantity
Revenue
Profit
Customer_id(pk) Name Address Phone Fax
Date_id(pk) Year Quarter Month Week Day
Store_id(pk) Country Region State city
Product_id(pk) Category Sub-Category Product
`

Integrated schema:
Slowly changing Dimensions (SCD)
SCD captures the changes which takes place over the period of time there are 3 types of SCD:
Type1 SCD:
A type1 dimension keeps only the current values doesn’t maintain history
Type2SCD:
A type2 dimension maintains the full history in the target for each update it inserts a new record in the
target
Type3SCD:
A type3 dimension maintains current and previous information (Partial History)
OLAP:
An OLAP is a set of specifications which allows the client applications (Reports) in retrieving the data from
DWH
Fact 1 Fact2
Fact3(combination
of fact 1 and fact2)

Types of OLAP:
ROLAP (Relational OLAP) sql server, oracle , teradata
MOLAP (Multi – Dimensional OLAP) Essbase
DOLAP ( Desktop OLAP) ms-access, excel , foxpro
HOLAP ( Hybrid OLAP) cognos , bo
Business 80%
Query
Reports
DW
ROLAP: An OLAP which can query the data from RDBMS are known as ROLAP
Ex: Cognos 8.4, BO XI R3, Micro strategy, Hyperion
MOLAP: An OLAP which can query the data from Multi- Dimensional DB (Cube) known as MOLAP
Ex : Cognos 8.4, Bo XI R3, Hyperion Web Analysis, Micro strategy, Hyperion financial Reporting
HOLAP: An OLAP which can combine the properties of ROLAP and MOLAP is known as HOLAP
Ex: Cognos, BO , Micro strategy
DOLAP: An OLAP which can query the data from desktop db like Ms-Access, Excel, foxpro.. etc
Ex : Cognos, BO, Micro strategy
DB: Joints & types Views &types Materialized views Index & types Partition & types DCL commands
Sales Information
Locations Department Info
End User Interface (Gateway)

Informatica Power centre 8.6.0
An Informatica PowerCentre is a single, unified enterprise data integration platform which allows the companies and organizations to accept the data from multiple sources transforms the data into homogeneous format and delivers the data throughout the enterprise at any speed Informatica power centre is a clinet server technology and an integrated toolset used for designing, running, monitoring and administrating the plan of data acquisition known as Mappings Informatica power Centre is a GUI based ETL product from Informatica Corporation.
Incorporated in 1993
Java is the base programming language used to design Informatica engine
2 Flavors Power Centre Large-Scale Industry Power Centre Small & Medium-Scale Industry
Most efficient ETL tool in ROI(Return On Investment) Power Centre Components: When we install an Informatica Power Centre Enterprise the following components gets, Installed:
1. Power Centre Clients(designer, workflow manager, work flow monitor, repository manager) 2. Power Centre Repository(Info-> rep) 3. Power Centre Domain 4. Integration Services 5. Repository Services 6. Web Services Hub 7. SAP BW Services 8. Power Centre Admin console
ETL Plan A mapping is a logical representation of data flow from source to target. Mapping is designed with following definitions
1. Source Definition: It defines an extraction from source 2. Target Definition: It defines the loading into the target 3. Transformation Rule: It defines the business logic for processing the data
Source DB(scott) Mapping Target DB(target)
ODBC – Open Database connectivity It’s an Interface between back End applications to any application
Employee +Eid +Ename +Esal +Deptno
Employee Tax = sal * 0.20 T_employee
ODBC ODBC
GUI Tool (client)
Eid Ename Esal Deptno
Empno Ename Sal Tax Deptno
T_Employee +Empno +Ename +Sal +Tax +Deptno
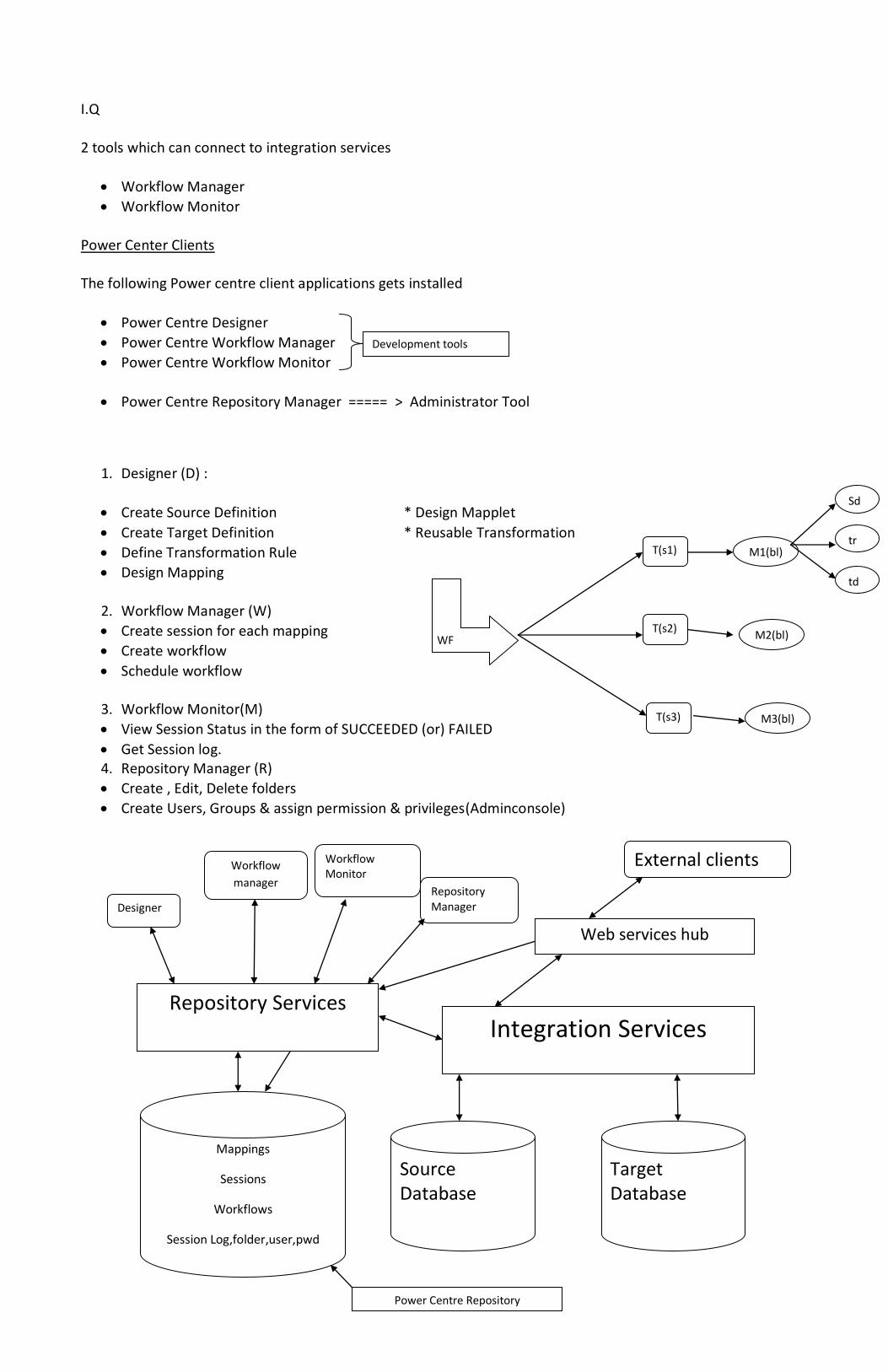
I.Q 2 tools which can connect to integration services
Workflow Manager
Workflow Monitor Power Center Clients The following Power centre client applications gets installed
Power Centre Designer
Power Centre Workflow Manager
Power Centre Workflow Monitor
Power Centre Repository Manager ===== > Administrator Tool
1. Designer (D) :
Create Source Definition * Design Mapplet
Create Target Definition * Reusable Transformation
Define Transformation Rule
Design Mapping
2. Workflow Manager (W)
Create session for each mapping
Create workflow
Schedule workflow
3. Workflow Monitor(M)
View Session Status in the form of SUCCEEDED (or) FAILED
Get Session log. 4. Repository Manager (R)
Create , Edit, Delete folders
Create Users, Groups & assign permission & privileges(Adminconsole)
Development tools
Mappings
Sessions
Workflows
Session Log,folder,user,pwd
Repository Services Integration Services
Source Database
Target Database
Web services hub
External clients
Designer
Workflow
manager
Workflow Monitor
Repository Manager
Power Centre Repository
M1(bl)
M2(bl)
M3(bl)
T(s1)
T(s2)
T(s3)
WF
Sd
tr
td

1. Node: 2. Service Manager:
1. Authentication 2. Authorization 3. Node Configuration
3. Application services 4. Power Centre Admin Console
Node1 Node2 Node3 Node4
No of Nodes = No of partitions
Power Centre Repository:
It is a system database which contains proprietary tables to store the meta data
It resides on a RDBMS
The repository tables contains metadata require to perform extraction, transformation and loading
The power centre client application can access repository db through repository services
Source definition
Target definition
Transformation rule
Mappings
Workflows , sessions
Schedules
Previlages
Integration service uses repository objects to extract, transform and load the data
The repository also stores the administrative info such as users, permission & privileges
Repository stores the session status and workflow status created by integration services
Repository also stores the session log which is created by integration services
Integration service can access the repository through repository service
Master Gate
Way Node
(host takes
request from
clients)
334 333 332

Repository Service:
It manages connection to power centre repository from client application
It is a multi-threaded process that inserts, retrieves and update meta data in the repository db tables
It ensures the consistency of metadata stored in the repository
It accepts the connection request from following power centre applications
1. Power centre clients
2. Integration services
3. Web services hub
Integration Services:
It reads mapping and session info from repository
It extracts the data from mapping sources and stores in memory where it applies the transformation rules
that configure in mapping
It loads the transformation data into the mapping targets
Web series Hub:
When web services hub is started it connects to the repository through repository services to fetch the web-
enabled workflows
It’s a web service gateway for external hubs/clients
Web services clients access the integration services and repository services through web services hub
Run & monitor web-enabled workflows
Application services
It’s a group of services which provides power centre server based functionality it includes
Repository services
Integration services
Web services Hub
SAP BW services
Power centre Domain:
Informatica power centre has a service-oriented architecture that provides the ability to scale services and share
resources across multiple machines
Power centre domain supports the administration of power centre services.
The domain is a primary unit for management and administration of services in the power centre
The domain has the following components

1. Node
It ‘s a logical representation of a machine. Domain may contain more than one nodes. The nodes can be
configured as a master gateway nodes and worker nodes
Configure the nodes (worker node) to run integration services and repository services. All the services
request in the domain passes through gateway node
2. Service manager:
It runs on each node in the domain and performs the following functions
Authentication
Authorization
Node configuration
It supports application services which run on each node
3. Application services:
Group of services that provides power centre server based functionality
Power centre admin Console:
It’s a complete web-based administration utility that is used to manage power centre domain
If you have a user login to the domain, we can access the administration console to perform administrative
tasks such as managing user accounts and domain objects
Domain objects includes services, nodes and licenses
Roles & Responsibilities
Administration:
An administrator is assigned with following tasks
1. Installations and configurations in a distributed network environment.
2. Creation of system database known as repository
3. Repository backup and recovery
4. Managing the domain using admin console
5. Creation of users, assigning permissions and privileges
ETL Developer:
1. Design mappings according to ETL specification documents
2. Performing following ETL tests in the order
o ETL unit testing
o System testing
o Performance testing
o UAT

1. Creation of database user for source(scott,tiger)
2. Creation of database user for target(target,target)
3. Odbc driver connection (ora_scott_conn(scott),ora_target_conn(target))
4. Create the folder for ETL developer(folder name: jas)
Steps involved in defining ETL Process:
Create source definition
Create target definition
Design mapping with (or) without T/R rule
Create a session for each mapping
Create workflow
Execute workflow
1. Creation of Source Definition:
A source definition is created using source analyzer tool in the designer client component
UN: scott/tiger SystemDB(Repository)
Start->Programs->Informatica Power Centre 8.6.0->client->Power Centre Designer
2. Create target definition
3. Design mapping
4. Creation of session
5. Creation of workflow
6. Execution of workflow
Transformation:
It ‘s an object which allows to define the business logic for processing the data Transformations are categorized
into 2 types
Source analyzer Repository
services
s.definition(emp)
emp

1. Active Transformations:
A transformation which can affect the number of rows (or) change the number of rows when the data is
moving from source to target is known as active transformation
Note: change in number of rows entry in transformation and exit from transformation
The following are the list of active transformations used for processing the data
Filter T/R
Joiner T/R
Aggregator T/R
Sorter T/R
Rank T/R
Router T/R
Transaction control T/R
Update Strategy T/R
Xml source Qualifier T/R
Normalizer T/R
2. Passive Transformations
A transformation which doesn’t affect the number of rows while data moving from source to target is
known as passive transformation
The following are the list of passive T/R used for processing the data
Expression T/R
Sequence Generator T/R
Look up T/R
Stored Procedure T/R
Eq: Active Transformation
Filter T/R
14(I) 14(I) 6(o) 6(o)
Extraction Transformation Loading
Example: Passive Transformation
14(I) 14(i) 14(o) 14(o)
Extraction Transformation Loading
Emp(sd) Sq_emp Sal > 3000 T_emp
emp Sq_emp Tax=sal*0.10 T_emp

Connected & Unconnected Transformations
Connected Transformation:
A Transformation which is participated in a mapping dataflow direction (connected to source and/or connected
to target) is known as connected T/R
It can receive multiple inputs and can provide multiple outputs
All active & passive t/R’s can be used as connected transformations
Unconnected Transformation:
A transformation which doesn’t participate in data flow direction (neither connected to source nor connected to
target) is known as unconnected Transformation.
It can receive multiple inputs but provide single output.
Following T/R’s can be used as unconnected
Lookup T/R
Stored Procedure T/R
Terminology:
Port = column
Ports and types of ports:
Input Port (I)
Output port (O)
A port defines column of a table (or) file
Input port:
A port which can receive the data is known as input port, which is symbolically represented as I
emp Emp_t Sq_emp
T/R

Output Port:
A port which can provide the data is known as output port, which is symbolically represented as O
Examples:
1. Filter Transformation:
This is a type of an active T/R which allows to filter the data based on given condition
A condition is built with the following components
1. Port
2. Operator
3. Operand
Filter T/R supports single target to send the data. It is used to perform data cleansing activities.
It evaluates each input record again as condition and returns True or False
True indicates that data is given for further processing (or) loading the data into the target
False indicates that the records are dropped from filter T/r
True Input records satisfied with condition
False Records which doesn’t meet condition
It doesn’t support IN operator instead of it we can use OR, AND
Data loaded into only single target
Real time terminology for mapping: Data flow diagram (DFD) and high level process Diagram