database summarization: application to a commercial ... · database summarization: application to a...
TRANSCRIPT

Database summarization:Application to a Commercial BankingData Set
Régis Saint-Paul— Guillaume Raschia— Noureddine Mouaddib
Institut de Recherche en Informatique de Nantes2, rue de la Houssinière BP 92208 - 44322 Nantes Cedex 3, FRANCE
Saint-Paul,Raschia,[email protected]
ABSTRACT.In this paper, an original approach to database summarization is applied to a massivedata set provided by a bank marketing department. The summarization process is based on anincremental and hierarchical conceptual clustering algorithm, building a summary hierarchyfrom database records. Levels of the hierarchy provides some views with different granulari-ties over the entire database. Each summary describes part of the data set. Furthermore, thefuzzy set-based representation of summaries allows the system to ensure a strong robustness andaccuracy regarding the well-known threshold effect of the crisp clustering methods. The sum-marization process is also supported by some background knowledge, providing a user-friendlyvocabulary to describe summaries with a high-level semantics. Even though our method is notimmediately concerned with computational performance, its low time and memory requirementsmakes it appropriate for large real-life databases. The scalability of the process is demonstratedthrough the application on a banking data set.
RÉSUMÉ.Dans cet article, une approche originale du résumé de données est appliquée à unebase réelle du service marketing d’un groupe banquaire. Le processus de résumé se fonde sur unalgorithme de formation de concepts hiérarchique et incrémental. Les niveaux de la hiérarchieproposent des vues avec différentes granularité de l’intégralité de la base. Chaque résumé décritune partie des données de l’ensemble de départ. La représentation des résumés basée sur lathéorie des ensembles flous donne au système une forte robustesse et bonne précision, évitantle fameux effet de seuil des méthodes non-floues de clustering. Le processus de résumé reposeégalement sur une base de connaissances préalable qui permet une description des donnéesdans le vocabulaire de l’utilisateur avec un haut niveau sémantique. Quoique notre méthodene soit pas immédiatement concernée par les problèmes de performance, sa complexité linéaireet ses faibles besoins en ressource mémoire lui permette d’envisager le traitement de grandsensemble de données réelles, ainsi que le montre l’application présentée.
KEYWORDS:Database summarization, Knowledge Discovery, Fuzzy logic
MOTS-CLÉS :Résumé de bases de données, Extraction de connaissances, Logique floue

1. Introduction
Generally, the huge amount of informations stored each day into databases is use-less, since standard tools for visualizing, querying and analyzing data are inefficientdue to the scalability problem. Therefore, new research domains, such as data min-ing, data warehousing and knowledge discovery have recently raised up interest ofdatabase community. In the same time, the data summarization paradigm has beenconsidered as a main topic of the extended database research area.
In that context, a lot of work has been done, especially on classification, clustering,association rules and decision trees, as a way to discover correlations between classesof database observations. For instance, the natural language-translated rule“longpapers are generally the most interesting one” could be inferredfrom a case study on scientific journals. Also these techniques have been used to iden-tify, characterize and/or discriminate parts of the database with conjunction of predi-cates, such as [SALARY>50000 AND AGE>50 AND (CAR=MERCEDES OR CAR=BMW) AND SEX=M] roughly defines the group of company chairmen.
However, most of the KDD (Knowledge Discovery in Databases) systems aredesigned to extract knowledge nuggets into the data, i.e. a very precise and hiddenknowledge, rather than to provide a global view on database. Moreover, knowledgerepresentation is often unintelligible for the user.
Besides, multidimensional databases are arising great interest from the summa-rization task point of view, since they allow an end-user to query and visualize part ofthe data using some special algebraic operators such as roll-up or drill-down. Oftenimplemented through materialized views, multidimensional databases are however notable to provide to the user some intentional descriptions of parts of the data set, butrather to give, at different levels of granularity, the real distribution of attribute valuescalled measures, according to others called dimensions, through basic elements calledcells.
Therefore, in complement to these well-known KDD and OLAP approaches, wepropose a fuzzy set-based summarization method, the SAINT ETIQ system, providingsummaries which cover parts of the primary database at different levels of abstrac-tion. Since interpretation and exploration of summaries is a main goal of summa-rization, the symbolic/numerical interface provided by tools of the Zadeh’s fuzzy settheory (ZAD 65), and more especially linguistic variables (ZAD 75) and fuzzy par-titions (RUS 69), are the fundamental background of all the approaches to linguis-tic summarization. Significant works have been done in this area, for instance byYager (YAG 82), Rasmussen and Yager (RAS 97), Kacprzyk (KAC 99), Bosc et al.(BOS 99b; BOS 98), Cubero et al. (CUB 99), Dubois and Prade (DUB 00).
Our approach considers a primary relationR(A1, . . . , An) in the relational databasemodel, and constructs a new relationR∗(A1, . . . , An), in which tuplesz are sum-maries and attribute values are fuzzy linguistic labels describing a sub-table ofR.Thus, the SAINT ETIQ system identifies statements of the form“ Q objects of
2

R are a1 and . . . and am” . Furthermore, summaries are organized into a hi-erarchy, such that the user can refine an approximative search into the database, fromthe most generic summary verifying the query to the most specific one. The over-lapped summariesz of R∗ are defined from database records and prior knowledge,providing synthetic views of a part of the database at different level of abstraction.One singular feature of the SAINT ETIQ system is the intensive use of BackgroundKnowledge (BK) in the summarization process. BK is built a priori on each attribute.It supports a translation step of descriptions of database tuples into a user-definedvocabulary.
The rest of this paper is organized as follows. First, the overall architecture of theSAINT ETIQ system is presented. Second, we focus on the use of background knowl-edge through the rewriting process of database records. Then, the construction and therepresentation of summaries are detailed. Finally, features of our prototype of SAIN -TETIQ are presented, as well as some interesting results offered by the application ofSAINT ETIQ over a real-life data-set..
2. Summarization Model Architecture
Our model of data summarization takes database records as input and gives somekind of knowledgeas output. Figure 1 shows the overall architecture of the system.The summarization task is then designed as a knowledge data discovery process, in asense that it is divided into three major parts such as follows:
1) apre-processingstep: it allows the system to rewrite database records in orderto be processed by the mining algorithm. This translation step gives birth to candidatetuples, which are different representations of a single database record, according tosome background knowledge. Background knowledge are fuzzy partitions definedover attribute domains. Each class of a partition is also labelled with a linguisticdescriptor provided by the user or a domain expert. For instance, the fuzzy labelyoungcould belongs to a partition built over the domain of the attributeAGE.
2) a “data mining” step: it considers the candidate tuples one at a time, and per-forms a scalable machine learning algorithm to extract knowledge. Obviously, theintensive use of background knowledge, which supports the translation step, avoidsfinding surprising knowledge nuggets. The model is rather designed to producesummaries–the extracted knowledge in the KDD process analogy—over the entiredatabase, even if some of them are considered as trivial from the user point of view.Furthermore, summaries are human-friendly since they are described with the uservocabulary taken from background knowledge. Hence, their direct interpretation iseasily performed by the user. It is an important feature of our model, and the maindifference with the usual KDD processes.
3) apost-processingstep: our model tries to define summaries at different level ofgranularity. the post-processing step consists in organizing the extracted summariesinto a hierarchy, such that the most general summary is placed at the root of the tree,
3

and the most specific summaries are the leaves. The root summary describes the entiredata set, whereas the leaves are summaries of only a few records of the database. Thus,browsing the hierarchy with a top-down approach allows the user to progressivelyrefine a rough query on the database until considering database records themselves.
3. Translation Step
3.1. The classical relational database framework
A database is a collection of data logically organized into files or tables of fixed-length objects (records), described by a set of features (attributes). Each attribute isdefined on a domain corresponding to the set of possible values for an attribute vari-able. Each record is an ordered list of attribute-value pairs. A tuple is an elementof the cartesian product of attribute domains. For convenience, we limit ourselves inconsidering a single table, the universal tableR in the relational database paradigm(COD 90). Table 1 presents a toy example of database records described by two at-
NAME (id) OCCUPATION INCOME (US$)
Burns NPP boss 87 000Cletus unemployed 5 000Homer safety inspector 44 000Kent anchorman 99 000Krusty clown 68 000Lisa sax player 15 000Maggie baby star 72 000Marge private housekeeper 0P. Kashmir exotic dancer 19 000Smithers assistant manager 60 000Snake PHU artist 67 000. . . . . . . . .
Table 1. part of the SIMPSONS_CHARACTERS table
tributes : the Simpsons characters are listed with their jobs and annual incomes. Forinstance,Cletus the Slaw-Jawed Yokelis said to beunemployedwith a US$5 000an-nual income earned from the Social Security Disability Insurance. The abbreviationsNPP, PHU andP. Kashmirare respectively used forNuclear Power Plant, Profes-sional Hold-UpandPrincess Kashmir.
Formally, letA = A1, A2, . . . , An be the set of attributes ofR. For instance, at-tributes areAGE, INCOME, OCCUPATIONor COUNTRY. Denote byDA the primarydomain of the attributeA, such as the interval[0, 150] for the numerical attributeAGE,or the term setFrance, Marocco, Poland for the nominal attributeCOUNTRY. An
4

elementt ∈ R is represented by the vector〈t.A1, . . . , t.An〉, where attribute valuest.Ai, Ai ∈ A, are basically crisp. For instance,Apu.JOB=grocer.
3.2. Notations related to the fuzzy set theory
Some useful notations related to the Zadeh’s fuzzy set theory (ZAD 65) are intro-duced here. They are all used in the following of this communication.
Consider the crisp setΩ as the universe of discourse.F(Ω) is the power fuzzy setof Ω, i.e. the set of fuzzy sets ofΩ. An elementF ∈ F(Ω) is defined onΩ by themembership functionµF which takes values in[0, 1].
In the following, we indistinctly denote byF (x) or µF (x) the membership gradeof x in F . The crisp set0+F is the strong zero cut ofF . It corresponds to thesupport of the fuzzy setF defined asx ∈ Ω | F (x) > 0. Moreover, in the caseΩ = x1, . . . , xn, n ∈ N, we denote byµF = α1/x1 + . . . + αn/xn, withαi = F (xi), i ∈ [1, n].
Finally, F is a fuzzy subset ofF ′, denoted byF ⊆F F ′, if and only if for allelementx in Ω, the inequalityF (x) ≤ F ′(x) is satisfied.
3.3. Generation of Candidate Tuples
The first use of the domain knowledge consists in finding the best representationof a database tuple according to linguistic labels provided by BK. Indeed, for a giventuplet the SAINT ETIQ system identifies on each attribute the most similar fuzzy setsd’s of the BK language, and it quantifies the satisfaction of the representation oft bythed’s.
The translation step is based on labeled type-1 fuzzy sets for the nominal attributes,and linguistic variables (ZAD 75) for the numerical attributes. Fuzzy sets of BK sat-isfy on each attribute the cover property in the sense that for all the attribute valuesvin F(DA), there exists at least one elementd of BK with v ∈ 0+d.
Figure 2 presents an example of a fuzzy linguistic partition on the attributeIN-COME. Someone who earns US$ 37 000 a year has both a modest and reasonableincome with different satisfaction degrees.
Table 3 shows the definition of labeled type-1 fuzzy sets asartist, on the nominalattributeOCCUPATION.
The translation step generates, from a given primary database record, all thecan-didate tuplesfor the generalization.For instance, consider the database record〈Burns,NPP boss, US$ 87 000〉 from Table 1. The translation step turnsBurns.OCCUPATION=NPP Bossinto predefined linguistic descriptors taken from BK provided in Table 3.Thus, the candidates are defined in Table 2.
5

In the same way,Burns.INCOME=US$ 87 000 is translated into the linguistic de-scriptorenormouswith a maximum satisfaction degree, since US$ 87 000 belongs tothe core of the fuzzy setenormousaccording to Figure 2.
Thus, the translation step converts the primary tupleBurns= 〈NPP boss, US$ 87 000〉into 2 user-defined vocabulary tuples:
Burns[1] = 〈businessman, enormous〉Burns[2] = 〈 firm manager, enormous〉
with the appropriate satisfaction degrees:
ϕ(Burns[1].OCC) = businessman(NPP boss)= 0.9
ϕ(Burns[2].OCC) = firm manager(NPP boss)= 1.0
ϕ(Burns[k].INC) = enormous(US$ 87 000)= 1.0
The abbreviationOCCstands forOCCUPATIONandINC is used forINCOME.
More formally, consider the primary database recordt and a candidate tuplectbuilt from t. The satisfaction degree of a descriptord of ct on the attributeA isdefined as the membership grade oft in d: ϕ(ct.A) = ct.A(t.A).
The SAINT ETIQ system associates a weightw to each candidate tuplet, corre-sponding to the proportion of a database record it represents. Considert gives birth tok candidate tuples through the translation step. Then the weight associated to eachctbuilt from t is simply given byw(ct) = 1/k. For instance,w(Burns[1]) = 0.5 sincethere exist two candidate tuples,Burns[1] andBurns[2], built from the database recordBurns. The weightsw allow one to exactly know the representativity of a cluster ofcandidate tuples from the primary database point of view.
The translation step applied either on numerical or nominal attributes allows oneto achieve a unified framework for the generalization process of the candidate tuples.The result of the translation is considered as the first level of summarization.Burns[k]is in fact the intentional description of a summary of database records close toBurns.
Furthermore, the translation step provides some informations about the match-ing degree between the user-defined vocabulary in BK and the real distribution ofdatabase records over the different attributes. The more database records generatesome candidate tuples, the less BK fits the database distribution. The study of weightsw associated to the candidate tuples seems to be an interesting starting point to eval-uate the accuracy of BK according toR. But this discussion as well as an extensionto a hypothetical interactive mechanism of refinement of BK is out of order in thiscommunication.
In the following, we denote byD+A the upper attribute domain ofA defined as the
finite set of linguistic termsd of BK. Both primary numerical and nominal attributes
6

translated term membership grade candidate
artist 0.0 nobusinessman 0.9 yeshigher ed. empl. 0.0 noschool qualif. empl. 0.0 noshopkeeper 0.0 nofirm manager 1.0 yesno occupation 0.0 no
Table 2. Translation step of Burns.OCCUPATION
are now associated with discrete domains since the translation step provides candi-date tuples described on each attribute by elements ofD+
A . For instance,D+INCOME
= none, miserable, modest, reasonable, comfortable, enormous, outrageous, andD+
OCCUPATION= artist, businessman, shopkeeper,. . . . The next section will focus ona particular subset ofF(D+
A).
4. Summary Representation
4.1. What are summaries ?
The main goal of SAINT ETIQ is to extract summaries from a huge amount ofdatabase records. Each summaryz provides a synthetic view of a part of the database,i.e. a sub-tableσz(R) of R.
The subset of database recordsσz(R) involved into the summarization is usuallycalled theextent, whereas the summarized descriptionz of these database records isthe intent.
The intentional descriptionz = 〈z.A1, . . . , z.An〉 of a summary describes similarfeatures of tuples inσz(R). It allows to generalize the descriptions of database tuples,attribute by attribute. Eachz.Ai is a fuzzy set represented by some linguistic labelsdtaken from prior knowledge (see Section 3). A descriptord generalizes the attributevalues of database records in the extent ofz.
For instance, consider the selection Kent, Krusty, Lisa, Maggie, Princess Kash-mir, Snake of records from Table 1 described on the attributesOCCUPATIONandINCOME. These six tuples are then summarized by a single fuzzy tuplez defined as:
z = 〈z.INCOME, z.OCCUPATION〉z.INCOME = αfp/fatly paid+
αpp/poorly paidz.OCCUPATION = αa/artist
7

whereαd is the membership grade ofd in z.A. It represents asatisfaction degreeofthe intentional description of the summaryz by d on the attributeA. Section 4.2 givesdetails about computation ofαd.
A fuzzy attribute value-oriented extension of the relational database paradigm isadopted to consider uncertainty and imprecision into the description of summaries.The approach adopted here (ZEM 84) is based on the possibilistic model (PRA 84)for relational databases. To handle ill-known values, it considers attribute descriptionsz.A of summariesz as weighted disjunctive statements. Further discussions on fuzzydatabases are developed in (PET 96; BOS 99a).
Obviously, we observe that the annual income of the artists of Table 1 is duallydefined. The disjunction of descriptors ofz on the attributeINCOMEderives from thescattering of attribute values of database records. Indeed, Lisa Simpsons and PrincessKashmir look like they use to earn a low income, in contrast to the other artists likethe Springfield’s esteemed anchorman Kent Brockman. But, it should be interestingto roughly decide in a more general way whether the Springfield’s artists are well paidor not.
Therefore, each linguistic labeld describing a database summary on an attributeis associated to arepresentativity degree. Coupled with the membership grade, itprovides basic informations to evaluate the description ability ofd. In our example,the linguistic labelfatly paid supports 66% of the extension ofz, whereaspoorlypaid represents only 33% of it. Besides, consider the two descriptors have the samesatisfaction degrees (αfp = αpp). Thus, we interpret the description ofz as:
most of the Springfield’s artists seems to be fatly paid, but a few ofthem are poorly paid.
4.2. Formal Definition of Summaries
Through the above introductory example, the user point of view is put forward.It allows one to intuitively keep in mind what we call summary and what kind ofinterpretation we can expect from it. Further formal details about the representationof summaries are now introduced.
A summary is defined in an extensional manner with a collection of candidate tu-plesRz = ct1, ct2, . . . , ctN. Eachcti is associated to a primary database record,i.e. an element ofR. Denote bycard(Rz) =
∑ct∈Rz
w(ct), and by|Rz| the num-ber of candidate tuples inRz. card(Rz) corresponds to the representativity of thesummaryz according to the primary databaseR, whereas|Rz| is the standard scalarcardinality of the crisp set of candidate tuples defined by the relationRz.
Moreover, the intent of a summary is defined as:
z = 〈z.A1, z.A2, . . . , z.An〉with z.Ai ∈ F(D+Ai
) , 1 ≤ i ≤ n .
8

Figure 1. The overall process of database summarization
Figure 2. Linguistic variable defined onINCOME
ConsiderRz=Apu[1], Burns[1], Moe[1]. The intentional description of the sum-maryz is then defined as:
z = 〈.9/businessman, 1.0/enormous+ 1.0/miserable〉
where membership gradeαd of a descriptord is computed as an optimistic aggregationvalue—with the usual triangular conormmax1—of satisfaction degrees of candidatetuples:
αd = maxct∈Rz | ct.A=d
(ϕ(ct.A))
1. Since the maximum satisfies the property of monotonicity w.r.t. the inclusion of extensionaldescriptions of summariesRz.
9
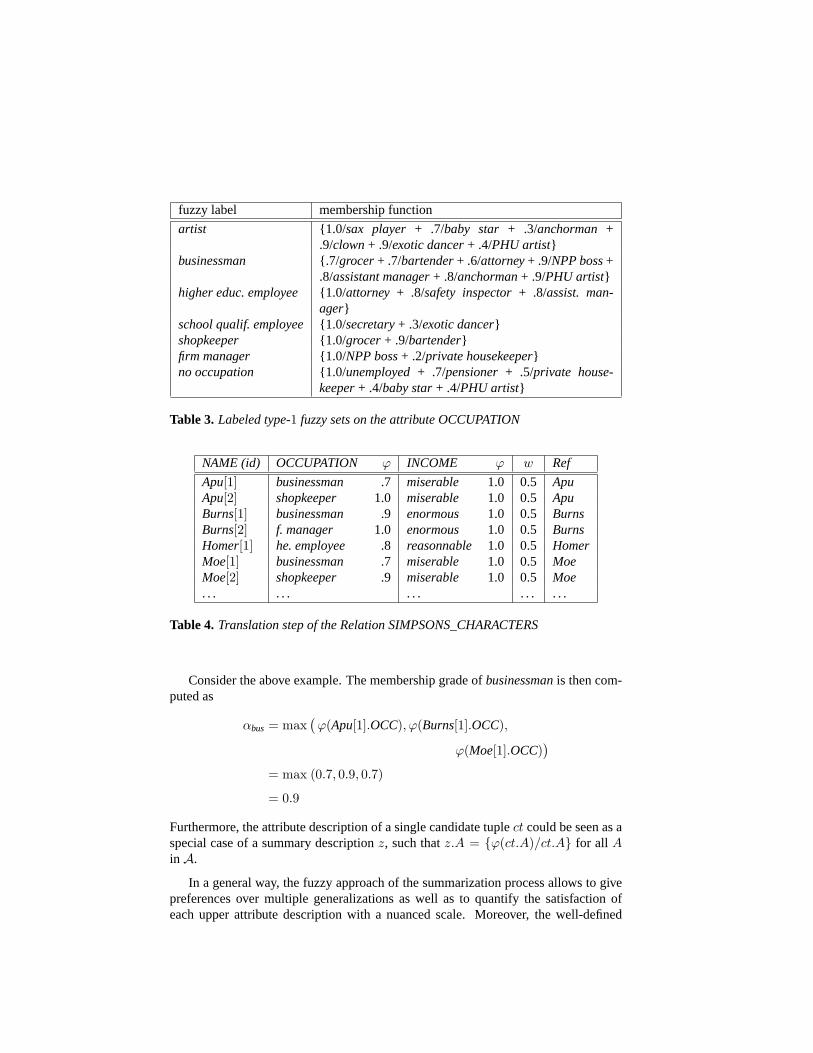
fuzzy label membership function
artist 1.0/sax player + .7/baby star + .3/anchorman +.9/clown+ .9/exotic dancer+ .4/PHU artist
businessman .7/grocer+ .7/bartender+ .6/attorney+ .9/NPP boss+.8/assistant manager+ .8/anchorman+ .9/PHU artist
higher educ. employee 1.0/attorney + .8/safety inspector+ .8/assist. man-ager
school qualif. employee 1.0/secretary+ .3/exotic dancershopkeeper 1.0/grocer+ .9/bartenderfirm manager 1.0/NPP boss+ .2/private housekeeperno occupation 1.0/unemployed+ .7/pensioner+ .5/private house-
keeper+ .4/baby star+ .4/PHU artist
Table 3. Labeled type-1 fuzzy sets on the attribute OCCUPATION
NAME (id) OCCUPATION ϕ INCOME ϕ w Ref
Apu[1] businessman .7 miserable 1.0 0.5 ApuApu[2] shopkeeper 1.0 miserable 1.0 0.5 ApuBurns[1] businessman .9 enormous 1.0 0.5 BurnsBurns[2] f. manager 1.0 enormous 1.0 0.5 BurnsHomer[1] he. employee .8 reasonnable 1.0 0.5 HomerMoe[1] businessman .7 miserable 1.0 0.5 MoeMoe[2] shopkeeper .9 miserable 1.0 0.5 Moe. . . . . . . . . . . . . . .
Table 4. Translation step of the Relation SIMPSONS_CHARACTERS
Consider the above example. The membership grade ofbusinessmanis then com-puted as
αbus = max(ϕ(Apu[1].OCC), ϕ(Burns[1].OCC),
ϕ(Moe[1].OCC))
= max (0.7, 0.9, 0.7)
= 0.9
Furthermore, the attribute description of a single candidate tuplect could be seen as aspecial case of a summary descriptionz, such thatz.A = ϕ(ct.A)/ct.A for all Ain A.
In a general way, the fuzzy approach of the summarization process allows to givepreferences over multiple generalizations as well as to quantify the satisfaction ofeach upper attribute description with a nuanced scale. Moreover, the well-defined
10

numerical/symbolic interface of the fuzzy set theory provides a powerful support forlinguistic descriptions of summaries, especially for the translation step.
To provide some representativity measure of each linguistic labeld into a summarydescriptionz.A, we use a primary database relative cardinality measure defined as:
cardz.A(d) =∑
ct∈Rz | ct.A=d
w(ct)
wherew(ct) is the weight associated to the candidate tuplect according to the primarydatabaseR (see Section 3.3).
The descriptor cardinalitycardz.A(d) relative to the extent ofz determines theproportion of primary database records involved into the generalized description ofRz with the linguistic labeld of BK.
Denote bycardz.A(d) = cardz.A(d)/ card(Rz), the normalized descriptor car-dinality. It measures the importance of each labeld into the summary descriptionz.A.
Consider the above example in which|Rz| = 3 andcard(Rz) = 1.5. Cardinali-ties of linguistic labels are given as follows:
cardz.OCCUPATION(businessman) = 1.5cardz.INCOME(enormous) = 0.5cardz.INCOME(miserable) = 1.0
Moreover,cardz.INCOME(enormous) ≈ 0.33 andcardz.INCOME(miserable) ≈ 0.66.Hence, all the Springfield’s inhabitants partially or totally incorporated intoRz arebusinessmen, and one third of them has an enormous annual income whereas the otherpart uses to earn a miserable salary.
5. Learning Summaries From Data
The SAINT ETIQ system performs the database summarization process by the wayof a concept formation algorithm (FIS 87). The process integrates learning and clas-sification tasks, sorting each tuple through a summary hierarchy, and in the sametime, updating summary descriptions and related measures. Note that in our approach,learned concepts are the summaries and objects are the database records.
5.1. Concept Formation
Most of human learning can be regarded as a gradual process of concept formation:observation of a succession of objects allows to induce a conceptual hierarchy thatsummarizes and organizes human experience. In other words, concept formation isthe fundamental activity which structures objects into a concise form of knowledge
11

that can be efficiently used in the future (REI 91). It includes the classification ofnew objects based on a subset of their properties (the prediction ability), as well asthe qualitative understanding of those objects based on the generated knowledge (theobservation ability).
Hence this task is very similar to theconceptual clusteringissue as defined byMichalski and Stepp (MIC 83), with the added constraint that learning is incremental.
More formally, given a sequential presentation of tuples and their associated de-scriptions, the main goals of concept formation are:
1) identifying clusters that group the tuples in categories;
2) defining an intentional description (i.e. a concept) that summarizes instances ofeach category;
3) organizing these concepts into a hierarchy.
5.2. Hierarchical Organization of Summaries
Summariesz are stored as fuzzy tuples into a relationR∗, and are organized intoa hierarchy which defines a partial ordering on tuples ofR∗.
Considering a nodez into the hierarchy, its parent node summarizes more databaserecords thanz, and its children nodes less than itself. Consequently, there respectiveintents are more or less specific in a sense that, on each attribute, the summary descrip-tion of the parent node is more scattered thanz. In the same way,z is more scatteredthan all of its children nodes. The specialization happens over one or more attributes,according to decisions made during the hierarchy building
Besides, applying the algorithm on candidate tuplesct rather than directly on prim-itive database recordst allows one to incorporatet into several summaries in differentbranches of the hierarchy, by the way of the corresponding candidate tuplesct of t.Thus, SAINT ETIQ generates a non-disjoint hierarchy, so called apyramid, from thepoint of view of elements inR.
5.3. Incremental Learner
Incremental learning methods are basicaly dynamic: their input is a stream of ob-jects that are assimilated one at a time. Thus, incremental processes build at any timean estimated knowledge structure of an unknown real one. Therefore, a primary mo-tivation for using incremental systems is that knowledge may be rapidly updated witheach new object. Indeed, incremental learners are driven by new objects, such thateach step through the hypothesis space occurs in response to some new experiences.
Obviously, the major drawback of this approach is that the estimated structure (thesummary hierarchy) is only built from past observations, and thus corresponds to alocal optimization of a heuristic measure used to evaluate the quality of the summary
12

partition at each level of the hierarchy. However, D. Fisher (FIS 87) showed thatexperiences with such systems provide good results if some bidirectional learningoperators are used.
5.4. Hill-Climbing Search
One can consider the concept formation as a search through a space of concepthierarchies, and hill-climbing is a basic Artificial Intelligence search method provid-ing a possible way of controlling that search. Indeed, the system adopts a top-downclassification method, incorporating a new tuplet into the root of the hierarchy anddescending the tree according to the hill-climbing search.
At a nodez, the algorithm considersincorporating the current tuplet into eachchild node ofz as well ascreatinga new child node accommodatingt. Furthermore,the system evaluates the preference ofmergingthe two best children nodes ofz andsplitting the best child node. Then SAINT ETIQ uses a heuristic objective functionbased on contrast and typicality of summary descriptions to determine the best opera-tor to apply at each level of the hierarchy.
Furthermore, bidirectional operators, such as splitting and merging, make localmodifications to the summary hierarchy. They are used to weaken sensitivity of theobject ordering, simulating the effect of backtracking in the space of summary hierar-chies, without storing previous hypotheses on the resulting structure. Thus, the systemdoes not adopt a purely agglomerative or divisive approach, but rather uses both kindof operators for the construction of the tree. To reduce effects of this well-known draw-back of concept formation algorithms, one can consider an optimization and simpli-fication step, for instance with an iterative hierarchical redistribution (FIS 96) whichconsiders the movement of a set of observations, represented by an existing cluster(summary), through the overall summary hierarchy.
Finally, the main advantage of hill-climbing search is its low memory requirement,since there are never more than a few states in memory, by contrast to search-intensivemethods as depth-first or breadth-first ones.
5.5. Discussion about Complexity
The temporal complexityc(n) = O(n) of SAINT ETIQ is linear w.r.t. the numbern of database tuples. Indeed, considering learning operators as primitive elements,c(n) is defined as:
c(n) = [(B + 3) ·N · logB p] · (n · pN ) ,
whereN = |A| is the number of attributes,B the average number of children nodesof a summary, andp represents the average cardinality of translated attribute domainsD+
A . In the above formulae,N · logB p gives the depth of the tree, whereas(B + 3)
13

stands for the exact number of learning operators applied at each node of the tree.Moreover,(n · pN ) is the maximum number of candidate tuples generated from theprimary database.
Observe that the primary database has to be parsed only once. Computation ofthe SAINT ETIQ algorithm is then performed with a low temporal cost, since the in-cremental learning, the hill climbing search method and the predefined vocabulary ofsummary descriptions.
6. A Real-Life Application
6.1. Model’s Implementation
A prototype implementing our model has been developed with the pascal languageusing Borland(TM) Delphi c© 6. The source code is about 56000 lines long, amongwhich 40% is used for the summarization model implementation itself. The rest isdedicated to both the graphical user interface and some libraries devoted to the XMLrepresentation of background knowledge and summaries.
As stated in 5.4, a quality measure is used to evaluate candidate summaries dur-ing the learning task and determine the appropriate learning operator. This qualitymeasure combines:
– a contrast measure, which is expected to be monotonously decreasing as thespecificity of the summary partition increase,
– and atypicality measure, which reciprocally is expected to be monotonouslyincreasing as the specificity increases.
Those measures are normalized over the[0, 1] range. Therefore, at the root of thehierarchy, contrast will be maximum and typicality minimum, while the opposite willbe observed if we consider a leaf summary. This property is inherited from the con-cept representation model of the concept formation paradigm, as defined by E. Rosch(ROS 78).
Typicality of a partition reflects the way intensional descriptions of summaries arenot scattered over the attribute domains, i.e. there exist only a few linguistic descriptorson each attribute for the summaries of a given partition (see 4.1). It is based on aspecificity measure defined as:
Sp(z.A) =|D+
A | − | 0+z.A||D+
A | − 1,
where|X| is the cardinality of the crisp setX.
Although typicality measure is not uniquely implemented, its instantiation doesnot yield to great difference in the resulting summary. Indeed, its behavior is wellbounded by the fuzzy linguistic partitions of attribute domains and the implementationexactly reflects the model’s representation of background knowledge.
14

At the opposite, the contrast measure greatly affects the resulting hierarchy. Forexample, using optimistic or pessimistic aggregation operators, respectively max andmin operators, to compute contrast, will lead to very different situations: a wide hi-erarchy with barely no depth for the optimistic computation, and a binary tree forthe pessimistic one. Of course, such a choice would not be very interesting becausethe singularity of produced hierarchy does not contribute to have a human-friendlyrepresentation of the data set at different levels of granularity. Therefore, averagingoperators are preferred to compute contrast and typicality.
The effective computation of the contrast measure is based on a dissimilarity de-gree. Dissimilarity between two summaries is intended to reflect the distance betweentheir respective intensional descriptions. This measure can itself be tuned to allowdomain specific treatments. For instance, if the user wants a particular attribute to betaken a special care, the dissimilarity measure will be adjusted with the goal. Thedissimilarity measure however does not directly affect properties of the hierarchy. Itrather affects the way tuples are grouped together and consequently, how summariesare described. However, defining domain specific dissimilarity measure requires ahigher expertise level on the domain. The prototype implements a general dissimilar-ity measureδ which is expected to meet most of the real cases. Its expression is basedon a resemblance measureRe such asδ(zi.A, zj .A) = 1−Re(zi.A, zj .A):
Re(zi.A, zj .A) =|zi.A ∩min zj .A|
min(|zi.A|, |zj .A|),
where|X| is the cardinality (sigma count) of the fuzzy setX, and∩min is the standardfuzzy intersection connective operator.
Contrast of a partition is then evaluated by computing a mean on the pairwise dis-similarities observed between the summaries of the partition. The hierarchy widenessis controlled by applying a correction on the contrast measure, proportionally to thegiven partition cardinality. The decision function of this correction can be adjustedto meet the specific mining task requirement and will affect the average wideness andmaximum depth of the resulting hierarchy.
Besides, the graphical user interface of our prototype allows the user to intuitivelydefine the background knowledge in terms of fuzzy sets, as well as to choose an ap-propriate strategy and to browse through the generated summary hierarchy.
6.2. The Commercial Banking Data Set
Over an agreement, the CIC Banking Group provided us with an extract of statisti-cal data used for behavioral studies over customers. The database consists in a singletable in which each record represents a customer, and fields (attributes) describe thecustomer in terms of age, income, or occupation, as well as banking products this cus-tomer is used to hold (accounts, credit cards, loan, . . . ). And finally, several attributesreflect statistics over the operations the customer do on a monthly period (number of
15

operations, total cash withdrawal, . . . ). The database represents a set of 33700 cus-tomers and 70 attributes. It is to be noted that some of the database values are absentand some are incoherent.
6.3. Construction of BK
Marketing experts provided us with the vocabulary they use to describe the valueson each attribute. For instance, they gave the range of income they would qualify withHigh,Averageor Low. The fuzzy approach of our system allows to take into accountthe inherent imprecision of such a vocabulary.
In addition, we used some basic mining tools, natively built in the prototype, toallow a refinement of linguistic partitions over each attribute domain; the system sim-ply provides an image of the distribution of tuple values on each attribute domain,such that the user can tune the linguistic partition to better fit the data. It is to benoted that an extensive use of such tools, allowing to define great partitions that meetsome mathematical properties, is out of our purpose. Indeed, summaries are first in-tended to reflect the content of the database with the user’s vocabulary. Therefore,background knowledge are built by a domain expert, and those tools are only used tocheck inconsistency and coverage properties.
For the results presented in this paper, we used a subset of 10 of the most relevantattributes. On each attribute, we defined between 3 and 8 modalities leading to a totalof 1036800 possible descriptor combinations.
6.3.1. Behavior of the Summarization Task
Figure 3 shows the evolution of the number of learning operations. Each of thisfigure bar expresses the total learning operators requiered for the treatement of setsof 1000 tuples. The learning operatorsAdd a levelandMergeare more frequent thanSplitandNewdue to the choosen strategy. Their ratio however remains the same alongthe all process, which is a good indicator of the well balanced use of those operators.
Figure 4 shows the evolution of the number of leaf nodes. Leaf nodes are themost specific summaries and are defined with a single descriptor on each attribute.Therefor, the number of leaf nodes is equal to the number of attribute/ rewritten valuecombination found in the database. The curve appears to have two discontinuities,the first being arround the 6000th processed tuple and the second arround the 18000thprocessed tuple showing that new value combinations appears at a higher rate at thosestages than during the rest of the process. Those two discontinuities are in correlationwith the two brusk increases of the learning operators used for handling those newtuples (Figure 3). After a sequence of learning activity to take into account the newmodalities found in the data set, the hierarchy becomes stable again and less operationsare required for the incorporation of incoming tuples.
16

Figure 3. Usage of Learning Operators
Figure 4. Evolution of the Number of Leaves
Figure 5. Evolution of the Hierarchy Depth
17

Figure 6. Performance of the Summarization Task
The evolution of the average depth of the hierarchy, shown on figure 5, is rapidlyconverging to 14, with the maximum being stable at 25. This is due to the naturallybounded nature of the hierarchy from BK definition (see section 5.5).
The SAINT ETIQ prototype has not been built with all the possible optimizations.However, it’s performance appears to conforme to the expected behaviour. Figure 6shows the performance evolution during the summary process. All the 55724 can-didate were processed within 21 minutes, but with at least 50% of the computationtime being taken by logging and statistic tasks. Two factors mainly affect the processperformance :
– The hierarchy size and balance,
– The hierarchy stability.
Those factors are closely linked since, for any particular learning strategy, theyonly depend on the sequential order of the data values. Figure 6 shows two localminima arround tuple 6000 and tuple 18000 that can be explained by the increase ofthe number of operations necessary to handle those parts of the database, as discussedabove. It is expected that, as the number of processed tuples increase, new candidatetuple values become rare. In this context, performance of the process will tend tobe constant and only depends on the final stable hierarchy size and balance. At thisstage, there is no more learning, and the process only performs a classification taskwith performance similare to tree based indexing methods.
6.4. Interpretation
The rewriting step of the summarization process can possibly produce many can-didate tuples for each database record. The exact number of candidate tuples dependson the fuzzyness introduced in BK. BK defined for this test produced 55724 rewritencandidate from the 33700 original tuples. The summarization process is applied to allthose candidate tuples and leads to a resulting hierarchy with 14766 leaf nodes (see
18

Figure 7. Widness of the Final Summary Hierarchy
figure 4). This number of leaf nodes is rather small regarding the cardinality of thecartesian product (1036800) and is a first interesting result of the summary process.
Figure 7 shows the widness of the final hierarchy for each level. The averagewidness is about half the maximum widness which expresses a well balanced tree.
The graphical interface provides the user a efficient tool to browse through thefinal hierarchy and visualize the intensive and extensive content of each node. Whenclicking on a node, the graphical interface also shows the intentional content of eachchild nodes and highlight the differences existing between the intentional descriptorof those child nodes. This way, the user have an immediate understanding of thedistinctive features between each sub-level hierarchy and can easily browse throughthe all hierarchy.
Considering a particular level, user can interprete the relative cardinality of childnodes and the task to infere knowledge from this is left to him. For example, summarywith a small cardinality will express particular modalities that are unlikely to occure(e.g. custommer with many credit cards and only one account).
6.5. Supervised knowledge discovery
Browsing through the hierarchy may allow the user to grab some general knowl-edge but it is unlikely he would be able to answer specific questions he may be lookingafter. Thus, the SAINT ETIQ prototype comes with a set of tools to help the user in hissearch.
The system first builds an index of all the summariy leaves. To build this index,all the summaries are uniquely identified by their position within the hierarchy, forinstanceR.1.1.2with R meaningRootand each number beeing the child number inthe list of the summary childrens. Therefor, each database tuple processed may leadto one or more canditate tuple, each of which will be found in the extensive content of
19

a particular leaf summary of the hierarchy. The system then builds an index of tupleIDs that allow to quickly find all the leaf summaries containing one of the candidatetuple generated from this tuple.
Then, a classical SQL query tool allows the user to perform queries over the orig-inal database. Those queries are aimed to extract subsets of data instances whichmeets the user questions. For instance, in the banking application considered here,we wanted to figure out if custommer fidellity corresponds to some nd out wether theconsidered attributes were revelant to give some indication about the custommer fidel-lity. The fidellity of custommer was not an attribute used during the summarizationprocess, but some external information allowed to
The extracted tuple subset correspond to a subset of leaf summaries gathered fromthe builded index. The summary list is displayed with their corresponding effectivecontent and a Query to Summary Matching (QtFM) degree. QtFM degree is calculatedas the ratio between the summary content of selected tuples and the total content. Itexpresses the degree by whitch a summary more or less exactly reflects the querycontent.
Leaves however are the most specific summaries to express tuple and they wouldonly reflect each of the rewritten modalities of the tuple subset and their relativeweight. But if the knowledge to gather is not absolutely trivial, ie. if there are manyleaf nodes needed to express all the modalities of the tuple subset, the user will needto look at the data from a more general point of view. To help him with it, we proposetwo mechanism :
– The result can be displayed as a list of summaries and their associated measures(QtFM degree and total cardinality) at any level of the hierarchy
– A graph shows the number of concepts needed to represent all the tuple subsetaccording to the considered level. It indicates a compression ratio whitch expressesthe ratio between the number of leaves and the number of summaries at the consideredlevel. A second ratio indicates the number of summaries needed in regard of the totalnumber of summaries present at this same level.
Those tools help the user to easily locate summaries that efficiently describe thequeried tuples at a generalization level that permit to gather some knowledge. Forexample, if all queried tuples are located into very few summaries, it can be concludedthat there exists some dependency between the query and the intensional descriptorsof those summaries.
7. Conclusion and Future Work
In this communication, we introduced an original fuzzy set-based approach todatabase summarization, with some common and distinctive features with the usualKDD processes. The dual representation of summaries have been introduced, as wellas the intensive use of background knowledge for the translation step. The main fea-
20

tures of the concept formation algorithm used to build the summary hierarchy havealso been considered. The scalability of our SAINT ETIQ system have been demon-strated through the good results of a real-life application.
We are now working on a query tool over the summary hierarchy. This module isintented to provide an easier way to infere knowledge from the summary by providingthe user a way to highlight hierarchy nodes that contain part of the query result.
Acknowledgements
We wish to thank the CIC group for providing their banking data and their expertiseon the banking domain without which this study couldn’t have been possible.
References
[BOS 98] BOSC P., LIÉTARD L., PIVERT O., “Extended Functional Dependenciesas a Basis for Linguistic Summaries”,ZYTKOW J. M., QUAFAFOU M., Eds.,Proc. of the 2nd European Symposium on Principles of Data Mining and Knowl-edge Discovery (PKDD’98), vol. 1510 ofLNAI, Berlin, sep 23-26 1998, Springer,p. 255–263.
[BOS 99a] BOSC P., BUCKLES B., PETRY F. E., PIVERT O., “Fuzzy databases”,BEZDEK J., DUBOIS D., PRADE H., Eds.,Fuzzy sets in approximate reasoningand information systems, vol. 5 of The Handbooks of fuzzy sets series, p. 403–468, Kluwer Academic Publishers, July 1999.
[BOS 99b] BOSC P., PIVERT O., UGHETTO L., “On data summaries based on grad-ual rules”, Proc. of the Int. Conf. on Computational Intelligence, 6th DortmundFuzzy Days (DFD’99), vol. 1625 ofLNCS, Dortmund, Germany, may 25-28 1999,Springer, p. 512–521.
[COD 90] CODD E. F.,The Relational Model for Database Management - Version 2,Addison-Wesley, 1990.
[CUB 99] CUBERO J. C., MEDINA J. M., PONS O., VILA M.-A., “Data Summa-rization in Relational Databases through Fuzzy Dependencies”,Information Sci-ences, vol. 121, num. 3-4, 1999, p. 233–270.
[DUB 00] DUBOIS D., PRADE H., “Fuzzy sets in data summaries - Outline of a newapproach”,Proc. of the 8th Int. Conf. on Information Processing and Managementof Uncertainty in Knowledge-Based Systems (IPMU’2000), vol. 2, Madrid, July3-7 2000, p. 1035–1040.
[FIS 87] FISHER D. H., “Knowledge Acquisition via Incremental Conceptual Clus-tering”, Machine Learning, vol. 2, 1987, p. 139–172, Kluwer Academic Publish-ers, Boston.
21

[FIS 96] FISHER D. H., “Iterative Optimization and Simplification of HierarchicalClusterings”,Artificial Intelligence Research, vol. 4, 1996, p. 147–179.
[KAC 99] K ACPRZYK J., “Fuzzy Logic for Linguistic Summarization of Databases”,Proc. of the 8th Int. Conf. on Fuzzy Systems (FUZZ-IEEE’99), vol. 1, Seoul, Korea,August 22-25 1999, p. 813–818.
[MIC 83] M ICHALSKI R. S., STEPPR. E., “Learning from Observation: ConceptualClustering”, MICHALSKI R. S., CARBONELL J. G., TOM M. M ITCHELL E.,Eds.,Machine Learning, an Artificial Intelligence Approach, p. 331–363, TiogaPublishing Co., Palo Alto, CA, 1983.
[PET 96] PETRY F. E.,Fuzzy databases - Principles and applications, Kluwer Aca-demic Publishers, 1996.
[PRA 84] PRADE H., TESTEMALE C., “Generalizing database relational algebra forthe treatment of incomplete or uncertain information and vague queries”,Informa-tion Sciences, vol. 34, 1984, p. 115–143.
[RAS 97] RASMUSSEN D., YAGER R. R., “Fuzzy query language for hypothesisevaluation”, ANDREASEN T., CHRISTIANSEN H., LARSEN H. L., Eds.,FlexibleQuery Answering Systems, Kluwer Academic Publishers, 1997, p. 23–43.
[REI 91] REICH Y., “Constructive Induction by Incremental Concept Formation”,FELDMAN Y. A., BRUCKSTEIN A., Eds., Artificial Intelligence and ComputerVision, Amsterdam, 1991, Elsevier Science Publishers, p. 191–204.
[ROS 78] ROSCH E., “Principles of Categorization”, ROSCH E., B.B. LLOYD E.,Eds.,Cognition and Categorization, p. 27–48, Erlbaum, Hillsdale, NJ, 1978.
[RUS 69] RUSPINI E. H., “A new approach to clustering”,Information and Control,vol. 15, num. 1, 1969, p. 22–32.
[YAG 82] YAGER R. R., “A new approach to the summarization of data”,Informa-tion Sciences, vol. 28, num. 1, 1982, p. 69–86.
[ZAD 65] ZADEH L. A., “Fuzzy Sets”, Information and Control, vol. 8, 1965,p. 338–353.
[ZAD 75] ZADEH L., “Concept of a linguistic variable and its application to approx-imate reasoning-I”,Information Systems, vol. 8, 1975, p. 199-249.
[ZEM 84] ZEMANKOVA M., KANDEL A., Fuzzy Relational Databases — A Key toExpert Systems, Verlag TUV Rheinland, Cologne, Germany, 1984.
22