dataengconf sf16 - recommendations at instacart
TRANSCRIPT

Recommendations @ Instacart
Sharath RaoData Scientist
Catalog, Search and Discovery

v
The Instacart Value Proposition
Groceries from stores you love
deliveredto your
doorstep
in as little as an hour
+ + + =

v
Customer Experience
Select a Store
Shop for Groceries
Checkout Select Delivery Time
Delivered to Doorstep

v
Shopper Experience
Accept Order Find the Groceries
Out for Delivery
Delivered to DoorstepScan Barcode

v
Four Sided Marketplace
Customers Shoppers
Products(Advertisers)
Search
Advertising
Shopping
Delivery
Customer Service
Inventory
Picking
Loyalty
Stores(Retailers)

v
What this talk is about
A new collaborative filtering algorithm
• A case-study • live end to end recommendation system• one person month • hundreds of millions of transactions

v
Online grocery vs Traditional e-commerceWeek 3Week 2
Online Grocery
Week 1
Traditional e-commerce

v
Grocery Shopping in “Low Dimensional Space”
Search
Restock
Explore
+
+
=

v
Why recommendations at Instacart
Your storeEverybody’s store

v
Repeat purchases increase LTV of recommendations
$5.49
$549
Today A year later
1 +….+ 100
$549
$549

vDifferent recommendation systems address different needs

v
Personalized Top N recommendations
Promote broad-based discovery in a dynamic catalog
Including from stores customers may have never shopped

v
Replacement Product Recommendations
Mitigate adverse impact of last-minute out of stocks

v
“Frequently bought with” Recommendations
Not necessarily consumed together
Help customers shop for complementary products
and try alternatives
Probablyconsumed together

v
Post Checkout Recommendations
Accommodate last-minute requests for that
“just one more thing”

vPersonalized Top N Recommendations

v
Learning from feedback
Traditionally collaborative filtering used explicit feedback to predict ratings
There may still bias in whether the user chooses to rate
Explicit Feedback Implicit Feedback

v
Learning from Explicit Feedback
• Explicit feedback may be more reliable but there is much less of it
• Less reliable if users rate based on aspirations instead of true preferences
vs

v
Implicit Feedback - trade-off quality and quantity
Stre
ngth
of e
vide
nce
Number of Events
v
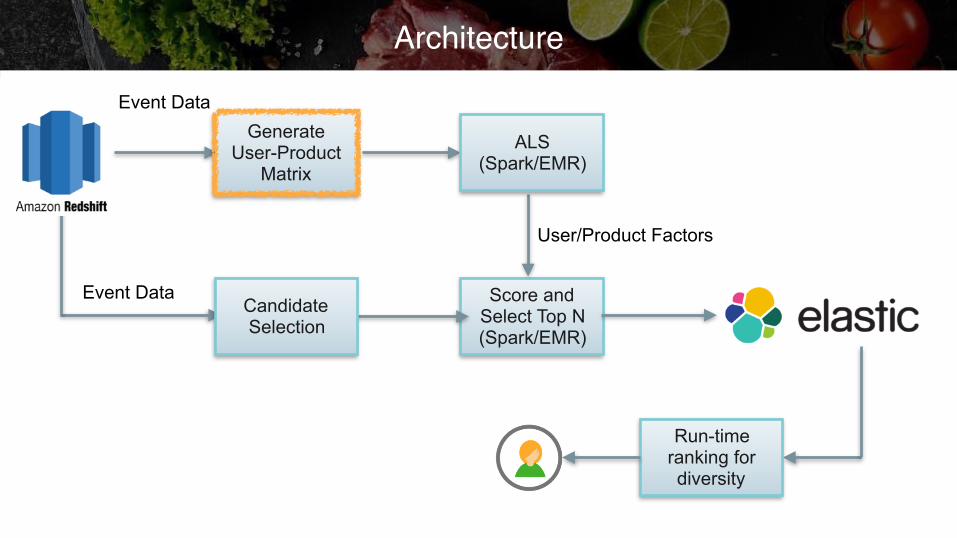
Architecture
Event Data Score and Select Top N (Spark/EMR)
User/Product Factors
Event Data
Run-time ranking for diversity
Candidate Selection
ALS (Spark/EMR)
Generate User-Product
Matrix

v
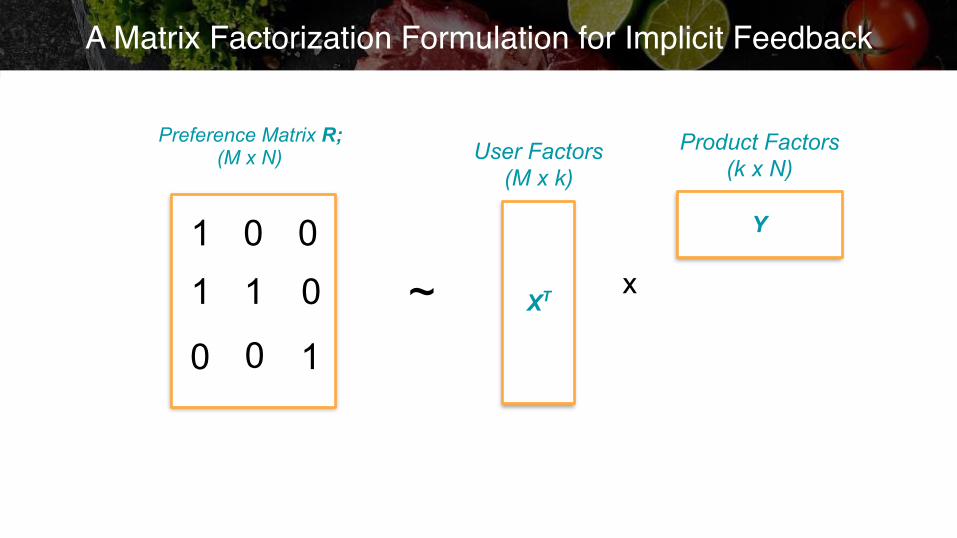
A Matrix Factorization Formulation for Implicit Feedback
N Products
M U
sers
1
-
- 9
-
- -
3
20
User Product Matrix R; (M x N)
1
0
0 1
0
0 0
1
1binary preferences
Preference Matrix R; (M x N)
“Collaborative Filtering for Implicit Feedback” - Hu et. al
v
A Matrix Factorization Formulation for Implicit Feedback
~Y
XT
Product Factors (k x N)
User Factors (M x k)
1
0
0 1
0
0 0
1
1x
Preference Matrix R; (M x N)

v
Matrix Factorization from Implicit Feedback - The Intuition
#Purchases Preference p Confidence c
0 0 Low
1 1 Low
>>1 1 High
• Confidence increases linearly with purchases r • c = 1 + alpha * r
• alpha controls the marginal rate of learning from user purchases
• Key questions• How should the unobserved events be treated• How should one trade-off observed and the unobserved

v
Regularized Weighted Squared Loss
Confidence
User Factors Matrix
Product Factors Matrix
Preference Matrix Regularization
Solve using Alternating Least Squares

v
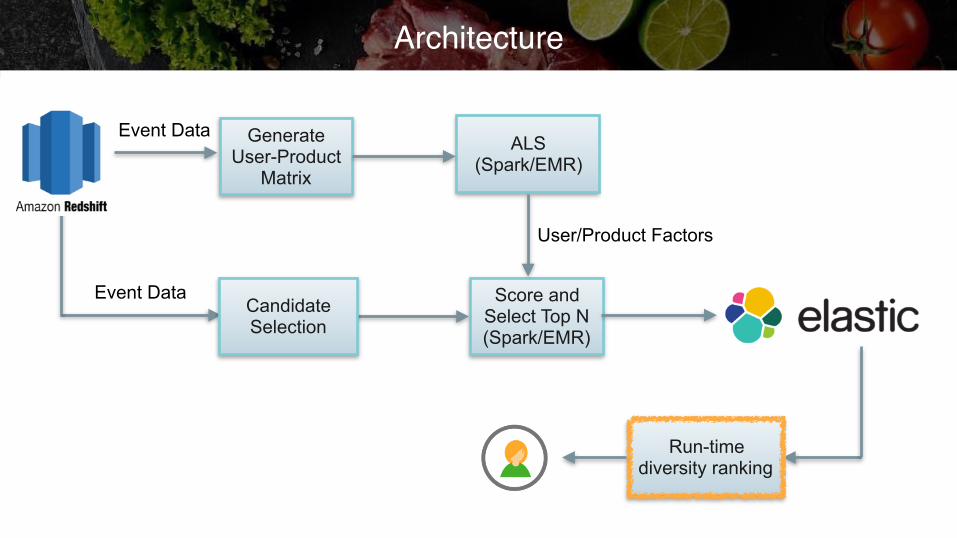
Architecture
Generate User-Product
Matrix
ALS (Spark/EMR)
Score and Select Top N (Spark/EMR)
User/Product Factors
Run-time ranking for diversity
Candidate Selection
Event Data
Event Data

v
Spark ALS Hyper-parameter Tuning
• rank k - diminishing returns after 150
• alpha - controls rate of learning from observed events
• iterations - ALS tends to converge within 5, seldom more than 10
• lambda - regularization parameter

v
Architecture
Generate User-Product
Matrix
ALS Matrix Factorization (Spark/EMR)
Candidate Selection
Score and Select Top N (Spark/EMR)
User/Product Factors
Run-time ranking for diversity
Event Data
Event Data

v
Scoring user and products
With millions of products and users, scoring every (user, product) pair is prohibitive
Two goals in selecting products to score• Products that have an a priori high purchase rate (popular)• Long tail which have not been discovered
Exclude previously purchased products
~

v
Candidate Product Selection
We start with simple stratified sampling
For each user, score N products
Sample h products from Head
Sample t products from tail
N ~ 10000 h ~ 3000 t ~7000
v
Architecture
Generate User-Product
Matrix
ALS (Spark/EMR)
Score and Select Top N (Spark/EMR)
User/Product Factors
Run-time diversity ranking
Candidate Selection
Event Data
Event Data

v
Offline evaluation
• Ideally we want to evaluate user response to recommendations• But we will only know this from an live A/B test
• Recall based metrics are an offline proxy (albeit not the best)• Recall: “Fraction of purchased products covered among Top N
recommendations”• We only use this for hyper parameter tuning

v
Tuning Spark For ALS
Understanding Spark execution model and its implementation of ALS helps
• Training is communication heavy1, set partitions <= #CPU cores
• Scoring is memory intensive
• Broad guidelines2 • Limit executor memory to 64GB • 5 cores per executor • Set executors based on data size
1 - http://apache-spark-user-list.1001560.n3.nabble.com/Error-No-space-left-on-device-tp9887p9896.html 2 - http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-1/

v
What better promotes broad-based discovery
vs

v
Online ranking for diversity
“Diversity within sessions, Novelty across sessions”
“Establish trust in a fresh and comprehensive catalog”
“Less is more”
Cached list of ~1000 products
per userFinal list of
<100 products
promote diversity

v
Diversity
Top K products - ranked by score
Rank product categories by their median product score
> > >

v
Weighted sampling for diversity
Sample category in proportion to score
Within category, sample in proportion to product score

v
A/B Test Setup
Generate User-Product
Matrix
ALS (Spark/EMR)
Score and Select Top N (Spark/EMR)
User/Product Factors
Run-time diversity ranking
Candidate Selection
Event Data
Event Data
Weekly for past N months data
Weekly for users with recent activity

v
A/B Test Results
• Statistically significant increases• Items per order• GMV per order
• Total product sales spread over more categories

vOk, we have a recommendation system
Where do we go from here?

v
What else do you do with user and product factors?
Score (user, product) pair on demand
Get Top N similar users
Get Top N similar product
As features in other models

v
Products similar to “Haigs Spicy Hummus"
More “Spicy Hummus”
Spicy Salsas
Generated using Approximate Nearest Neighbor (“annoy” from Spotify)

v
Ensembles
Use different types of evidence and/or product metadata to easily create ensembles
User x Products Purchased
User x Products Viewed
User x Brands Purchased
Model or Linear Combination
…

v
What next
• Improve candidate selection by leverage user and product factors
• Make recommendations more contextual
• Address cold-start problems, particularly for users
• Explain recommendations (“Because you did X”)

vReplacement Product Recommendation

v
Fulfillment in Traditional E-commerce
• Manage inventory in warehouses optimized for quick fulfillment
• Users only specify the “What” they want
• Disallow users from ordering out of stock products
• Set expectations• “3 day shipping” but will ship in 10 business days

v
Fulfillment for on-demand delivery from local retailers
• Shoppers navigate a complex environment where products • may have run out • may be misplaced• may be damaged
• User specifies “What”, “When” and “Where from”
• Improvise under uncertainty

v
Addressing new challenges in on-demand delivery
• Tight technology integrations help improve tracking of in-store availability
• Complemented by predictive models that estimate availability in real-time
• Last minute out of stocks can still happen

v

v
What makes a replacement acceptable?
Flavor PackingSizeBrand Price
• Several product attributes matter
• Context matters, might benefit from personalization
• Must scale to millions of products
• Not always symmetric
• May be ok to replace X with gluten free X but not the other way around
Diet Info

v• Shoppers are trained to pick replacements
• But shoppers can benefit from algorithmic suggestions
• Many unfamiliar products in a vast catalog
• Validation for common products
• Finding replacements fast improves operational efficiency
Replacement Recommendations for Shoppers

v
• Customers can specify replacements while placing the order
• Can choose to communicate with the shopper in store to verify
Replacement Recommendations for Customers

vHow do we algorithmically generate replacements?

COME BUILD IT :)
WE’RE HIRING!
@sharathrao