db tech showcase2015 how to replicate between clusters
TRANSCRIPT

MongoDB クラスター間レプリケーション
MongoDB JP代表窪田 博昭 @crumbjp

ブログ活動

仕事の話


Emotion Intelligence
日本有数のMongoDBユーザ企業
ECのCV率を上げるサービスZenclerkを運営
Web閲覧中のユーザの行動を逐次解析し感情を読み取る
月間10億PV程度を扱っている

Zenclerk
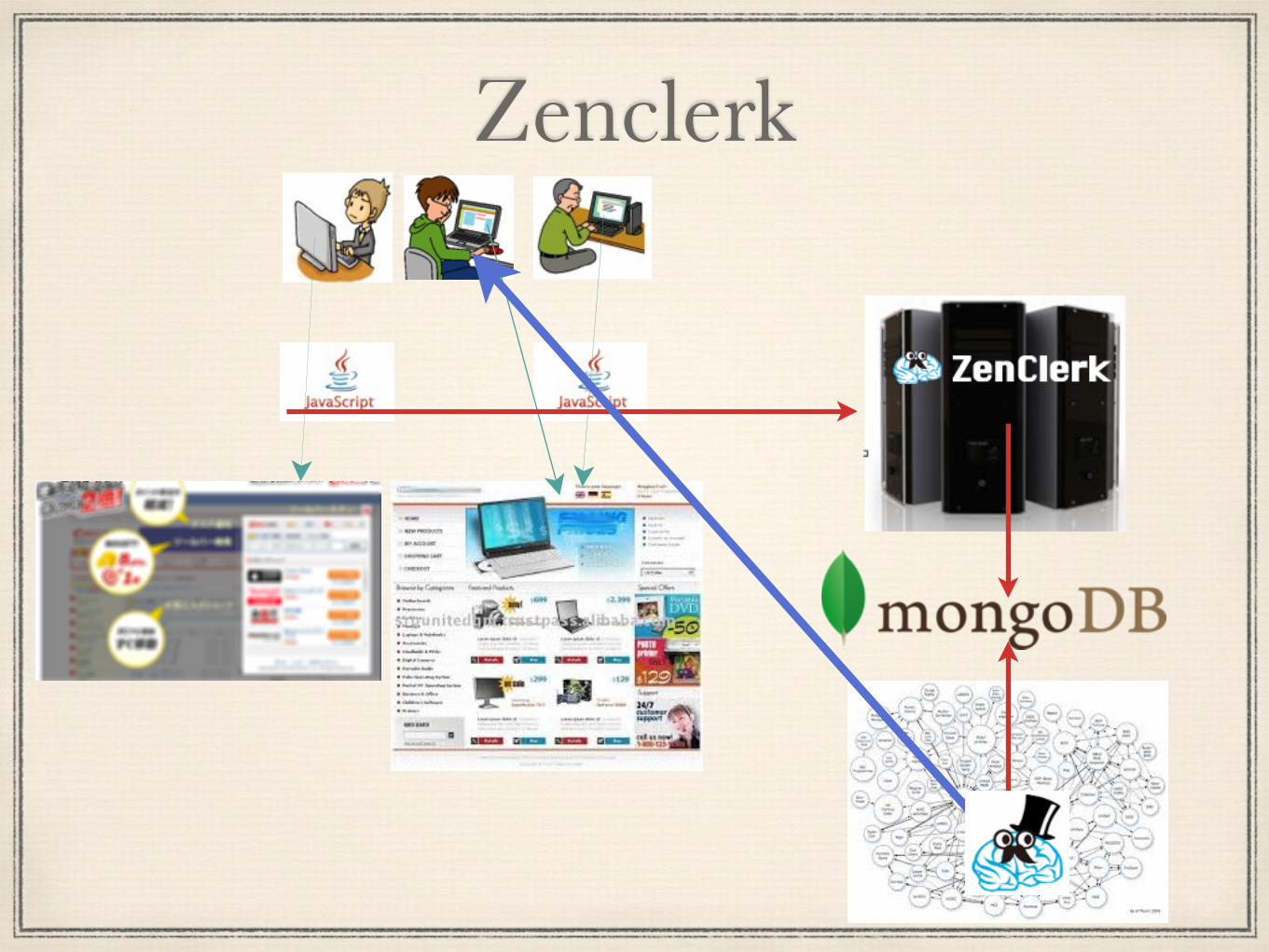
Zenclerk

Zenclerk
毎月
PB 単位のデータを扱う
10TB単位のデータをMongoDBに保存
MainDB は 5 shard 構成(そんなにお高くないサーバ)

困った

困ったそれなりに複雑なシステムはステージング環境が欲しいが、本番DBに向けてしまうと色々困る
機械学習で稼ぐビジネスなのに本番DBにカジュアルにクエリーするとシステムが高負荷でダウンして危険
何らかの調査でtypoしたフィールドのクエリー投げられて死ぬ
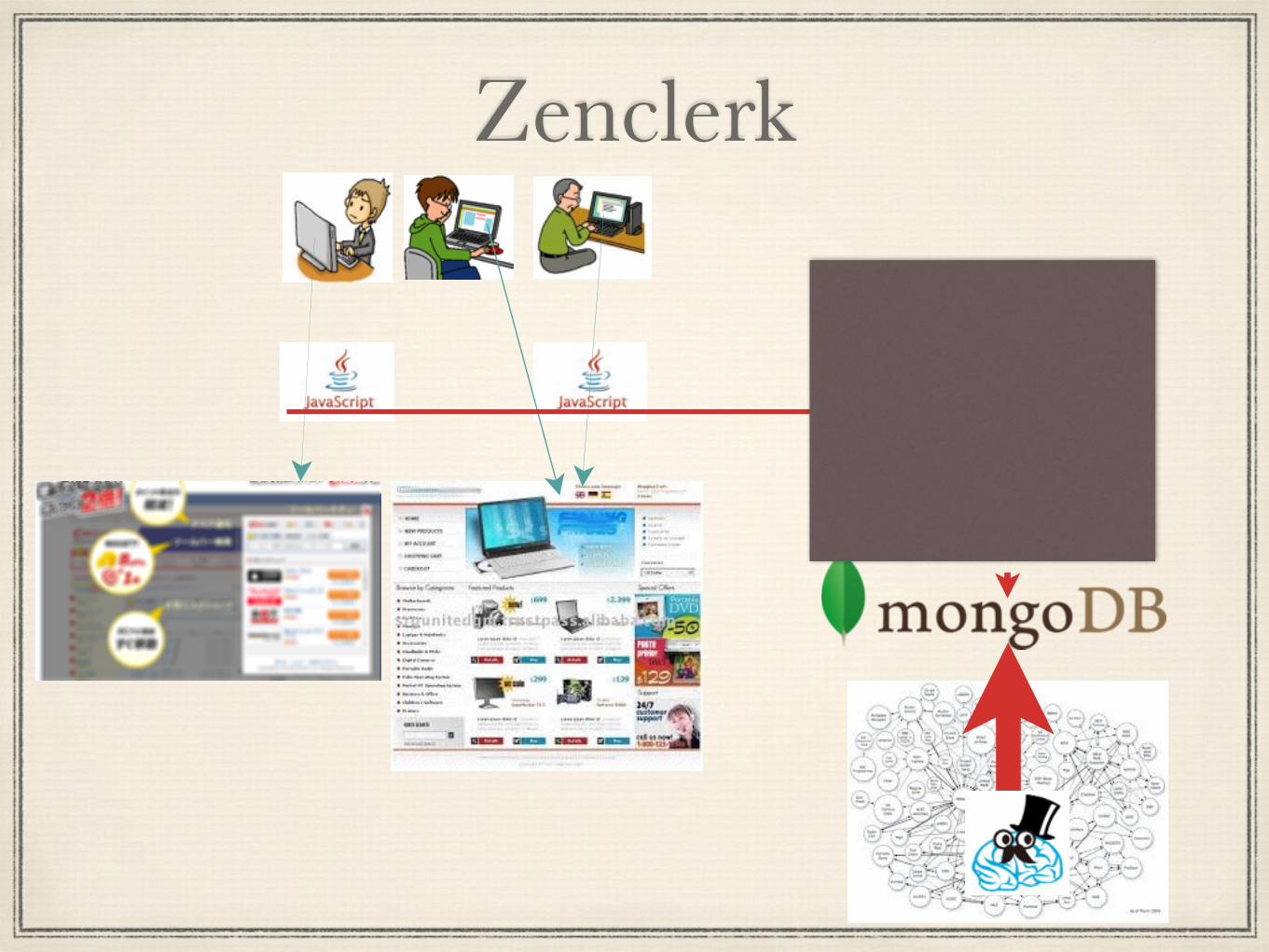
Zenclerk

それってStagingDB

DummyデータでStaging
!
大きなデータがあるから発生する問題が多い
本番と同じデータが無いと機械学習が巧く行く筈が無い
(作った本人含めて)誰も使わない
全然意味なかった・・・

でもMongoDBって・・・

MongoDBのレプリケーション!
ReplicaSet以外のデータ同期の仕組みは無い
ReadOnlyでは不便極まりない
1日一回Secondaryを切り離して使う?
フレッシュなデータが使いたいので却下された
Sharding環境でそんな面倒な運用無理!

でも困ってるんだよ・・・

つい出来心で・・・!
ある日ReplicaSetのoplogを生読みすればクエリーベースのレプリケーションが組める事に気付く
深い事考えずに『出来るわ!やろっか?』『お願い!』という会話をしてしまう。
スーパー後悔・・・

仕方が無い・・・面倒すぎて、1ヶ月放置した・・・
『まだ~?』『ゴメン!』を繰り返す。。
いい加減信用がヤバくなったので本腰入れた
即日nodeで書いたが速度がイマイチでmongo shellで書直し、色々問題直して賞味1週間くらいかかった

出来た!!

https://github.com/zenclerk/monmo_repl
書き込み側のレイテンシーをクリアすれば 3TB/month までは間違く動くそこから先は頑張り次第

技術的な説明
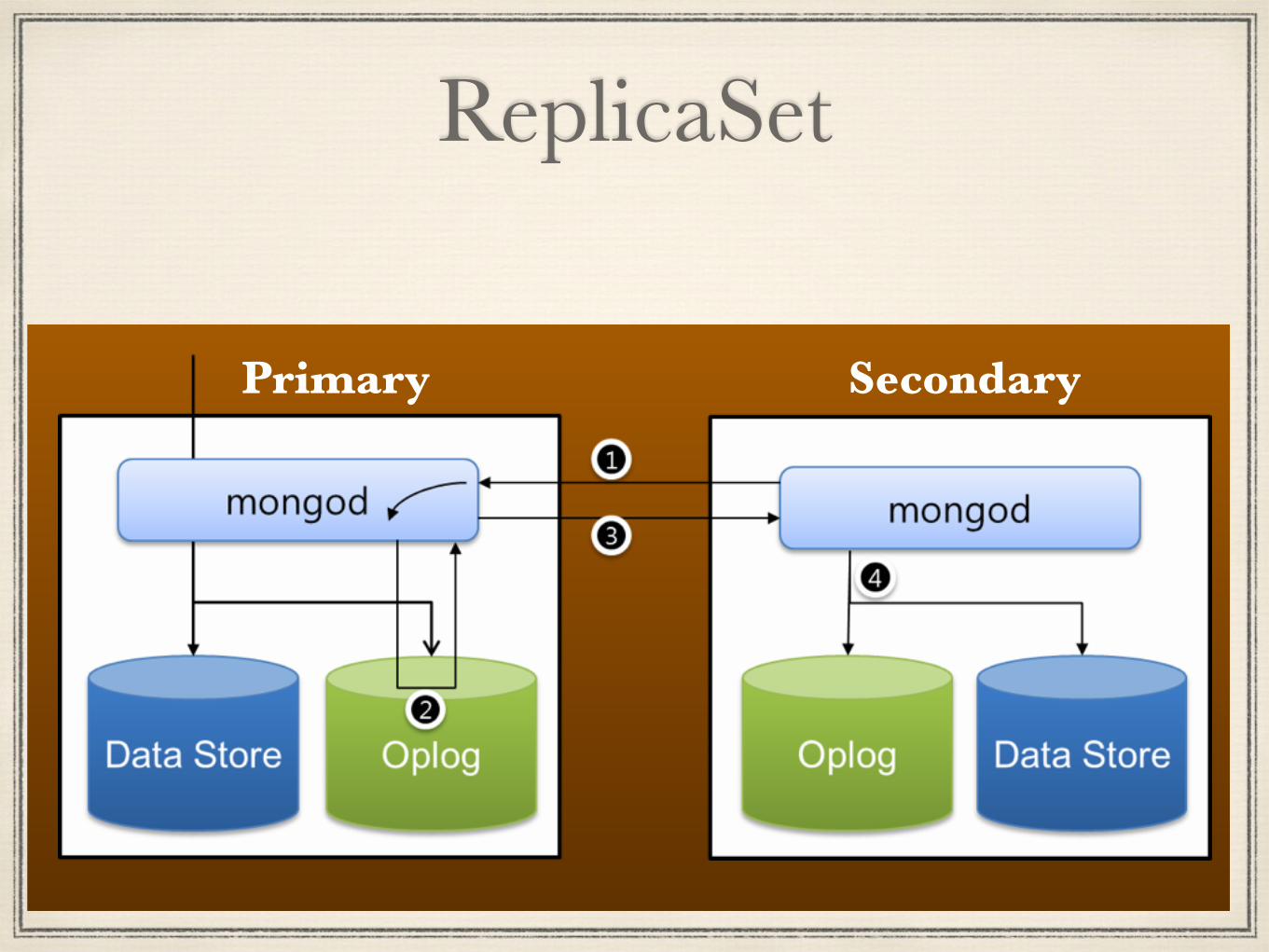
ReplicaSet
Primary Secondary

作戦
monmo_repl

性能1
MongoDBのレプリケーション周りはチューニングされており、とにかくoplogに追い着くのが大変
Bulkオペレーション必須
ns(collection)単位に分解して処理する

性能2
シビアなので選択肢が少ない
c++ driver → 流石にちょっと・・
node native driver → 少し遅かった
mongo shell → 低機能だが高速

性能3mongo shell
mongod, mongos の mongo client を直接使う
(本体だから)node native driver よりチューニングが進んでいるっぽい
Tailable cursorの不随意closeが検知できない・・・つらい・・・

oplogの注意点1Tailable cursorは終端まで移動させるのに分単位の時間が必要
レプリプログラムを再起動しても直ちに同期を再開できない
cursorは不随意に閉じる事がある
oplogに負けてcursorの先端まで追いつめられると上記のループに嵌って抜け出せない

oplogの注意点2oplogにはクエリーがそのまま保存されている訳ではない
更新、削除系のクエリーは_id指定に展開される
例えばdb.remove({}) はドキュメント数のoplogにバラされ処理が膨れあがる
レプリ先に独自に作ったドキュメントは範囲更新などの影響を受けない

oplogの注意点3レプリ元と先の用途の違いを考慮
別々に運用したい場合関連オペレーションを塞き止める
DB名、コレクション名を変えたい場合がある
データを選別して塞き止めたい(負荷が辛いが)

Shardingでもイケる
Mongos
Shard3Shard1 Shard2
monmo_repl
monmo_repl
monmo_repl
Staging replica

MMS backup agent

Shardingでの工夫
Shardingのmigrationに伴うinsert/deleteは識別して弾く

嬉しい誤算

Shardingでの嵌り所
Shardingのauto migrationはデータ量(chunk数)の均一化をしてくれる
書き込み量の均一化は考慮してくれない
書き込み量が均一化されていないと特定Shardのデータが膨れるのでmigrationを大量に誘発してしまう

printShardingStatus()
一見巧く分散しているように見えるが 、ほぼ全ての書き込みがshard1に集中している事がある
shardkey の境界を含むchunkに書き込みが集中するのでそれを保持しているshardに負荷が集中する
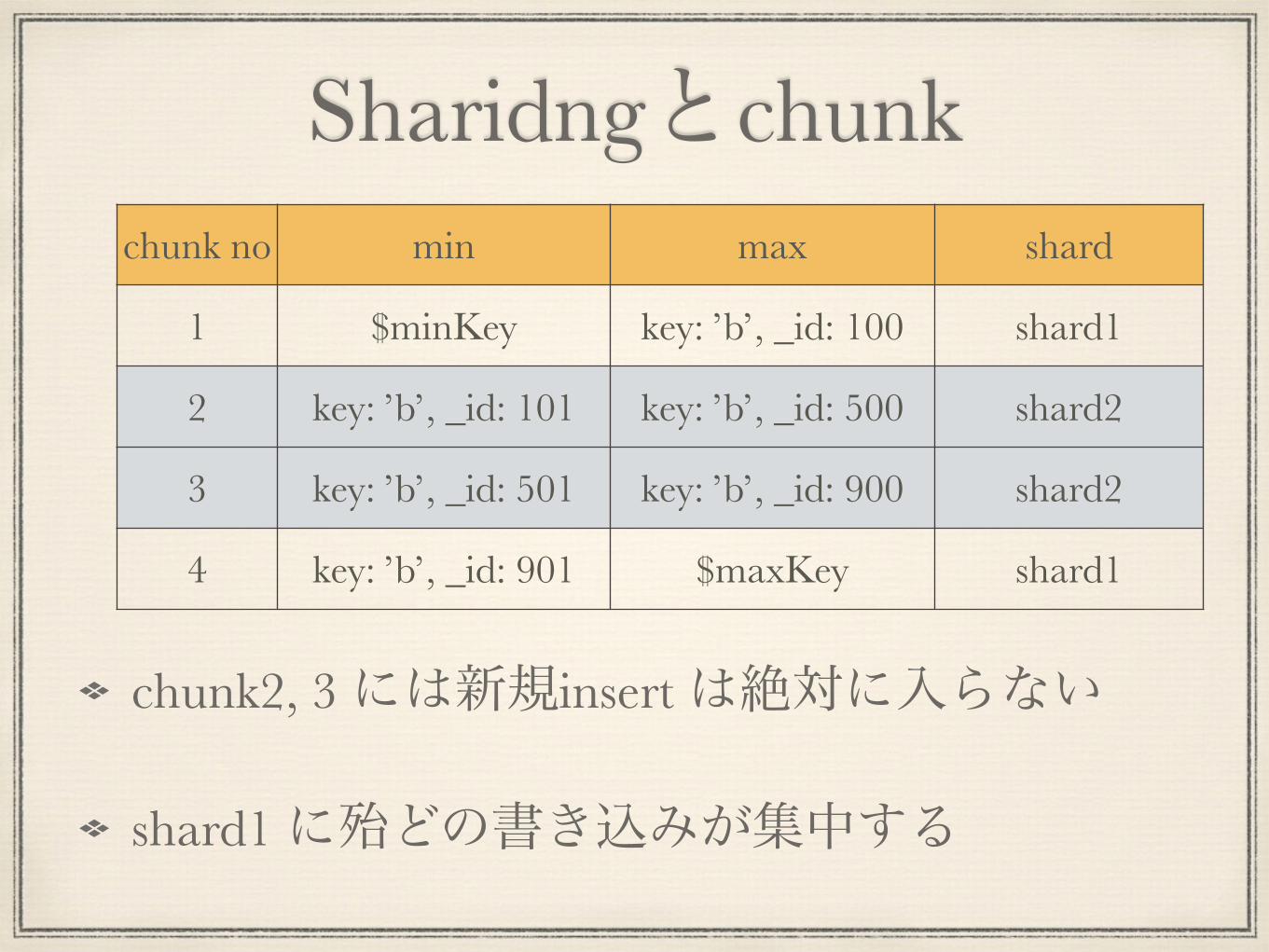
Sharidngとchunkchunk no min max shard
1 $minKey key: ’b’, _id: 100 shard1
2 key: ’b’, _id: 101 key: ’b’, _id: 500 shard2
3 key: ’b’, _id: 501 key: ’b’, _id: 900 shard2
4 key: ’b’, _id: 901 $maxKey shard1
chunk2, 3 には新規insert は絶対に入らない
shard1 に殆どの書き込みが集中する

各shardの負荷を可視化INFO, TS: Timestamp(1433592288, 132), DF: 1, C: 5000, {"loglv":100,"dry":false,"repllog":false} DUMP, BULK: xxxxxxxxx.yyyyyyyy01, {"i":0,"u":3124,"d":0,"m":0,"b":3124} DUMP, BULK: xxxxxxxxx.yyyyyyyy02, {"i":620,"u":1440,"d":0,"m":0,"b":2060} DUMP, BULK: xxxxxxxxx.yyyyyyyy03, {"i":11,"u":46,"d":0,"m":0,"b":57} DUMP, BULK: xxxxxxxxx.yyyyyyyy04, {"i":66,"u":0,"d":0,"m":0,"b":66} DUMP, BULK: xxxxxxxxx.yyyyyyyy05, {"i":6,"u":0,"d":0,"m":0,"b":6} DUMP, BULK: xxxxxxxxx.yyyyyyyy06, {"i":10,"u":0,"d":0,"m":0,"b":10} DUMP, BULK: xxxxxxxxx.yyyyyyyy07, {"i":6,"u":0,"d":0,"m":0,"b":6} DUMP, BULK: xxxxxxxxx.yyyyyyyy08, {"i":44,"u":0,"d":0,"m":0,"b":44} DUMP, BULK: xxxxxxxxx.yyyyyyyy09, {"i":0,"u":210,"d":0,"m":0,"b":210} DUMP, BULK: xxxxxxxxx.yyyyyyyy10, {"i":102,"u":0,"d":0,"m":0,"b":102} DUMP, BULK: xxxxxxxxx.yyyyyyyy11, {"i":200,"u":0,"d":0,"m":0,"b":200} DUMP, BULK: xxxxxxxxx.yyyyyyyy12, {"i":22,"u":0,"d":0,"m":0,"b":22}
INFO, TS: Timestamp(1433592309, 59), DF: 1, C: 4927, {"loglv":100,"dry":false,"repllog":false} DUMP, BULK: xxxxxxxxx.yyyyyyyy01, {"i":33,"u":877,"d":0,"m":0,"b":910} DUMP, BULK: xxxxxxxxx.yyyyyyyy02, {"i":705,"u":1631,"d":0,"m":0,"b":2336} DUMP, BULK: xxxxxxxxx.yyyyyyyy03, {"i":81,"u":1488,"d":0,"m":0,"b":1569} DUMP, BULK: xxxxxxxxx.yyyyyyyy07, {"i":384,"u":0,"d":0,"m":0,"b":384}
Shard1のレプリケーションログ
Shard2のレプリケーションログ

手で調整
問題のあるコレクションが解れば、shardkey
の境界を含んだchunkを移動すれば良い
monmo_replが仕掛けてあると調整の結果がリアルタイムで見える!
chunk移動もスクリプト化しておくと楽(まだ公開できない出来・・・)

もうMongoDB怖くないよね