dbms performance: a multidimensional challenge vadiraja bhatt database performance engineering group
Post on 18-Dec-2015
215 views
TRANSCRIPT

DBMS Performance:A multidimensional Challenge
Vadiraja BhattDatabase Performance engineering group.

DBMS Performance
DBMS servers are defacto backbend for most applications
Simple Client server
Muli-tier
ERP ( SAP, PeopleSoft..)
Financial
Healthcare
Web applications
Each application has unique performance requirement
Throughput v/s Response time

Performance challenges
Keeping up with various application characteristics
Financial
Mostly OLTP
Batch jobs
Report Generations
Security
Internet Portal
Mostly readonly
Loosely structured data
Transactions are not important
Short-lived sessions

Performance challengesTHE DATA EXPLOSION
• Web 174 TB on the surface• Email 400,000 TB/ year• Instant Messaging 274 TB/ year
• Transactions Growing 125%/ year
Data Volume
Time
Source: http://www.sims.berkeley.edu/research/projects/how-much-info-2003/

Performance challenges
Demand for increased capacity
Large number of users
Varying class of services
Need to satisfy SLA
Several generations of applications.
Client servers to Web applications.
Legacy is always painful

Performance Challenges
Consolidation
Cheaper hardware
Increased maintenance cost
Increased CPU power
Reduction in TCO ( Total cost of Ownership)
Net effect
DBMS have to work lot harder to keep-up

System Performance 101
How do I get my hardware and software to do more work without buying more hardware ?System Performance mainly depends on 3 areas
Processor Memory I/O

De-mystifying Processors
Classes of processors CISC/RISC/EPIC
Penitum is the most popular one Itanium didn’t make a big impact ( inspite of superior
performance) Dual-Core/Quad core are making noices
One 1.5GHz CPU does not necessarily yield the same performance as two 750MHz CPU’s. Various parameters to account for are L1/L2/L3 cache sizes (Internal CPU caches) Memory Latencies Cycles per instruction

DBMS servers are memory centric Experiments have shown that < 50% utilization of CPU > 50% cycles wasted in memory related stalls Computational power of CPU is underutilized
Memory access is very expensive Large L2 cache Increased memory latency
Cacheline sharing Light-weight locking constructs causes lot of cache-to-cache
transfers
Context switch becomes expensive Maintaining locality is very important
DBMS and CPU utilization

Operating System
CPUsDisksEngine 0
RegistersFile Descriptors
Running
Shared Executable (Program Memory)
2
Run QueuesSleepQueue
locksleep
diskI/O
Lock Chains
Other Memory sendsleep
Pending I/OsDISK
NET
NET
34
7
8
6
Shared Memory
Proc CacheHash
Engine 1 ...RegistersFile Descriptors
Running
Engine NRegistersFile Descriptors
Running
15
ASE – Architecture overview

ASE Engines
•ASE Engines are OS processes that schedule tasks•ASE Engines are multi-threaded Native thread implementation
•ASE Performs automatic load balancing of tasks Load balancing is dynamic N/w endpoints are also balanced
•ASE has automatic task affinity management Tasks tend to run on the same engine that they last ran on to
improve locality

ASE Engines
2 configuration parameters control the number of engines
The sp_engine stored procedure can be used to “online” or “offline” engines dynamicallyTune the number of engines based on the “Engine Busy Utilization” values presented by sp_sysmon
[processors]max online engines = 4number of engines at startup = 2

Benefits of Multiple Engines
•Multiple Engines take advantage of CPU processing power Tasks operate in parallel Efficient asynchronous processing
•Network I/O is distributed across all engines•Adaptive Server performance is scalable according to the CPU processing power

ASE Engines
•Logical Process management Lets users do create execution classes Bind applications/login to specific execution classes Add engines to execution classes Priority can be assigned to execution classes
• Lets DBA create various service hierarchies Dynamically change the priorities Dynamically modify the engine assignments based on the
CPU workload

Let’s not forget “Memory”
Memory is a very critical parameter to obtain overall system performanceEvery disk I/O saved is performance gained. Tools to monitor and manage memory

ASE Memory Consumption
Over 90% of memory is reserved for buffer caches.
DBMS I/OsVarying sizes Random v/s SequentialAsynchronous v/s Synchronous
Object access patternMost often accessed objects

Traditional cache management
All the objects share the space
Different objects can keep throwing each other out
Long running low priority query can throw out a often accessed objects
Increased contention in accessing data in cache

ASE Distributing I/O across Named Caches
If there there are many widely used objects in the database, distributing them across named caches can reduce spinlock contention
Each named cache has its own hash table

Distributing I/O across cachelets
HashTable
HashTable
HashTable
HashTable

ASE Named Caches
What to bind Transaction Log Tempdb Hot objects Hot indexes
When to use Named caches For highly contented objects Hot lookup tables, frequently used indexes, tempdb activity,
high transaction throughput applications are all good scenarios for using named caches.
How to determine what is hot ?? ASE provides Cache Wizard

Cache Wizard : Examples
sp_sysmon ’00:05:00’, ‘cache wizard’, ‘2’, ‘default data cache’
default data cache
Buffer Pool Information
Object Statistics Cache Occupancy Information
IO Size Wash Run Size APF% LR/Sec PR/Sec Hit % APF Eff % Usage %
4 Kb 17202 Kb
16 Mb 10 800 100 87.50 75 80
2 Kb 3276 Kb 84 Mb 10 1700 1400 17.65 20 80
Run Size: 100 Mb Usage %: 80 LR/sec: 2500 PR/sec: 1500
Hit%: 40
Object LR/sec PR/sec Hit%
db.dbo.cost_cutting 1800 1150 36.11
db.dbo.emp_perks 500 200 60.00
Obj_Size Size in Cache
Obj_Cache% Cache_Occp%
102400 Kb 40960 Kb 40 40
2048 Kb 1024 Kb 50 1

Reading ’n’ Writing [Disk I/O]
I/O avoided is Performance GainedASE buffer cache has algorithms to avoid/delay/Optimize I/Os whenever possible LRU replacement MRU replacement Tempdb writes delayed Write ahead logging [Only Log is written immediately] Group commit to batch Log writes Coalescing I/O using Large buffer pools UFS supportRaw devices and File systems supportedAsynchronous I/O is supported

ASE Asynchronous Prefetch
Issue I/Os in advance on data that we are going to process later Non-clustered index scan
Leaf pages have (key, pageno) Table scan Recovery
Reduces waiting on I/o completion. Eliminates context switches.

ASE – Private Log cache
begin transql..Sql..Sql..
commit tran
PLC
L1
L2
L3
Log CacheL1 L2 L3
Log Disk
Plc flush
Log Write

Logging Resource Contention
PLC eliminates steady state logging contentionDuring Commit Acquire Lock on Last Log page
Flush the PLC Allocate new log pages while flushing PLC
Issue write on the dirty log pages On high transaction throughput systems ( 1million/min)
Asynchronous logging service ( ALS) acts as coordinator for flushing PLC’s and issuing log writes
Eliminates contention for Log cache and streamlines log writing.

Very Large Database Support
Very Large Device Support Support storage of 1 Million Terabytes in 1 Server instance Virtually unlimited devices per server (>2Billion) Individual devices up to 4TB (support large S-ATA drives)
Partitions Divide up and manage very large tables as individual components

More on PARTITION
Large Table
Large Delete
Data load
DSSQuery
OLTP apps
Updatestatistics
Unpartitioned Table
Partition
Large Delete
PartitionUpdatestatistics
Partition
OLTP appsPartition
Data load
Partition
DS
SPartitioned Table
Small chunk

PARTITIONS - Benefits
Why PartitionsVLDB Support
High Performance and Parallel processing
Increased Operational Scalability
Lower Total Cost of Ownership (TCO) through: Improved Data Availability Improved Index Availability Enhanced Data
Manageability
Benefits Partition-level management
operations require smaller maintenance windows, thereby increasing data availability for all applications
Partition-level management operations reduce DBA time required for data management
Improved VLDB and mixed work-load performance reduces the total cost of ownership by enabling server consolidation
Partitions that are unavailable perhaps due to disk problems do not impede queries that only need to access other partitions

Sustained Query performance
Upgrades are double edge sword Offers new features, fixes, enhancement May destabilized applications due to fixing double negative issues
Customer don’t want to compromise current performance levels Long testing process before any upgrade happens Time is money
Expensive to upgrade from customer perspective
Unless we have mechanism to ensure same performance level we are at loss

Query Optimization - The Reality
ASE query optimization usually chooses the best query plan, however, sub-optimal query plans will occasionally result.Furthermore, whenever changes are made to the optimization process on ASE: Most queries will execute faster Some queries will be unaffected Some queries may execute slower (possibly a lot slower) The bottom line is that optimizers are not perfect!As a Senior Sybase Optimizer Developer once told me,“If they were perfect, they would call them perfectizers.”

ASE Solution: Abstract Plans
The Abstract Plans feature provides a new mechanism for users to communicate with ASE regarding how queries are executed.This communication: Does not require changing application code Applies to virtually all query plan attributes Occurs at the individual query-level May be stored and bundled in with applications Will persist across ASE releases

What Are Abstract Plans?
An abstract plan (AP) is a persistent, readable description of a query plan. Abstract plans: Are associated with exactly one query Are not syntactically part of the query May describe all or part of the query plan Override or influence the optimizer
A relational algebra language, specific to ASE, is used to
define the grammar of the abstract plan language.
This AP language, which uses a Lisp-like syntax

What Do Abstract Plans Look Like?
Full plan examples: select * from t1 where c=0 (i_scan c_index t1)
select * from t1, t2 where (nl_g_join t1.c = t2.c and t1.c = 0 (i_scan i1 t1) (i_scan i2 t2)
)
Instructs the optimizer to perform an index scan on table t1 using the c_index index.
Instructs the optimizer to:• perform a nested loop join with table t1 outer to t2 • perform an index scan on table t1 using the i1 index• perform an index scan on table t2 using the i2 index

Compilation Flow - Capture Mode
•Abstract plans are generated and captured during compilation•Query plans are generated
SQL Text
Query Resolution Process
Query Tree Stored in sysprocedures
System Catalog on Disk(Persistent Storage)
ASE Memory(Non-Persistent Storage)
Query Compilation Process
Query Plan Abstract Plan sysqueryplansStored inStored inProcedure Cache
For Compiled Objects Only
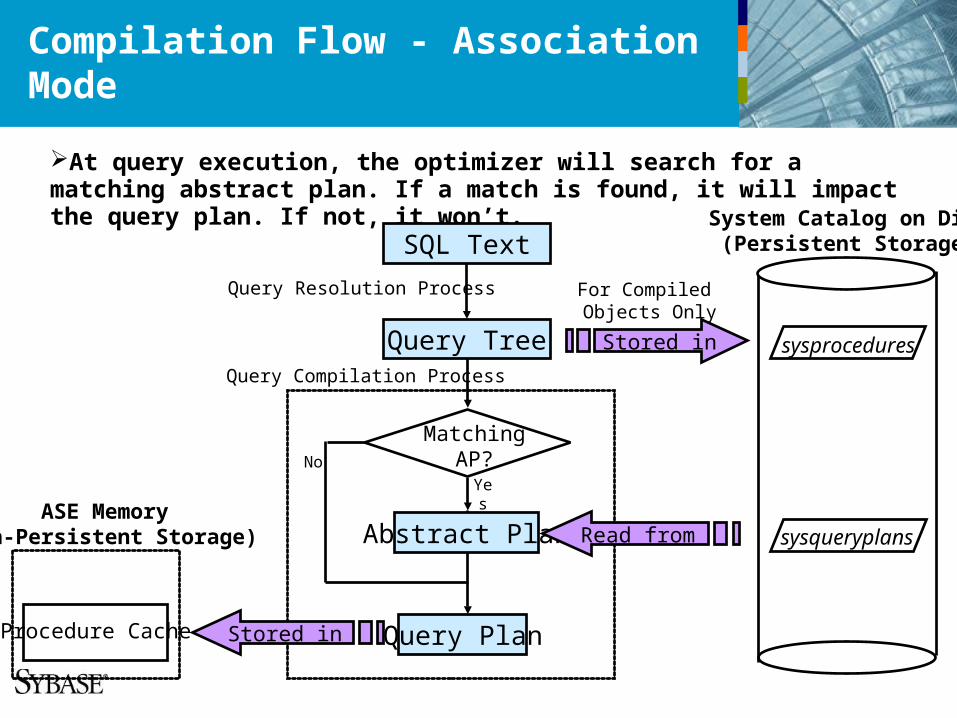
Compilation Flow - Association Mode
At query execution, the optimizer will search for a matching abstract plan. If a match is found, it will impact the query plan. If not, it won’t.
SQL Text
Query Resolution Process
Stored in sysprocedures
System Catalog on Disk(Persistent Storage)
ASE Memory(Non-Persistent Storage)
Query Compilation Process
Query Plan
sysqueryplans
Procedure Cache
MatchingAP?
Query Tree
No
Yes
Abstract Plan Read from
Stored in
For Compiled Objects Only

Q & A
Thank you