ddbms paper with solution
TRANSCRIPT

Faculty of Degree Engineering
Department of CE/IT (07/
Enrollment no: _____________________
B.E. – SEMESTER – Subject Code: 2170714 Subject Name: Distributed DBMS
Duration: 2:30 hr. Instruction:
1. Attempt all questions. 2. Make suitable assumption where necessary.3. Figure to the right indicate full Marks.
Q. 1 (A) Explain the potential problems with DDBMSA:1 (A) 1.6.1 Distributed Database D
The question that is being addressed is how the database and the applications that runagainst it should be placed across the sites. There are two basic alternatives to placingdata: partitioned (or non-database is divided into a number of disjoint partitions each of which is placed ata different site. Replicated designs can be either duplicated) where the entire database is stored at each site, or partially duplicated) where each partition of the database is stored at more than onesite, but not at all the sites. The two fundamental design issues are the separation of the database into partitions called Optimum distribution of fragments.The research in this area mostly involves mathematical programming in orderto minimize the combined cost of storing the database, processing transactionsAgainst it, and message communication among siteTherefore, the proposed solutions are based on heuristics.
1.6.2 Distributed Directory ManagementA directory contains information (such as descriptions and locations) about dataitems in the database. Problems related tto the database placement problem discussed in the preceding section. A directorymay be global to the entire DDBS or local to each site; it can be centralized at onesite or distributed over several sites; ther
1.6.3 Distributed Query ProcessingQuery processing deals with designing algorithms that analyze queries and convertthem into a series of data manipulation operations. The problem is how to decideon a strategy for executing each query over the network in the most costway, however cost is defined. The factors to be considered are the distribution ofdata, communication costs, and lack of sufficient locallyobjective is to optimize where the inherent parallelism is used to improve the performanceof executing the transaction, subject to the aboveproblem is NP-hard in nature, and the approaches are usually heuristic.
1.6.4 Distributed Concurrency ConConcurrency control involves the synchronization of accesses to the distributed database,such that the integrity of the database is maintained. It is, without any doubt,one of the most extensively studied problems in the DDBS field. The concurrencycontrol problem in a distributed context is somewhat different than in a centralizedframework. One not only has to worry about the integrity of a single database, but
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Enrollment no: _____________________ Seat No: _____________________
VII PRE-FINAL EXAMINATION –Date: 17
Time: Total Marks:
Make suitable assumption where necessary. Figure to the right indicate full Marks.
Explain the potential problems with DDBMS. 1.6.1 Distributed Database Design The question that is being addressed is how the database and the applications that runagainst it should be placed across the sites. There are two basic alternatives to placing
-replicated) and replicated. In the partitioned scheme thedatabase is divided into a number of disjoint partitions each of which is placed ata different site. Replicated designs can be either fully replicated (also called
) where the entire database is stored at each site, or partially replicated ) where each partition of the database is stored at more than one
site, but not at all the sites. The two fundamental design issues are fragmentationthe separation of the database into partitions called fragments, and distributionOptimum distribution of fragments. The research in this area mostly involves mathematical programming in orderto minimize the combined cost of storing the database, processing transactionsAgainst it, and message communication among sites. The general problem is NPTherefore, the proposed solutions are based on heuristics.
1.6.2 Distributed Directory Management A directory contains information (such as descriptions and locations) about dataitems in the database. Problems related to directory management are similar in natureto the database placement problem discussed in the preceding section. A directorymay be global to the entire DDBS or local to each site; it can be centralized at onesite or distributed over several sites; there can be a single copy or multiple copies.
1.6.3 Distributed Query Processing Query processing deals with designing algorithms that analyze queries and convertthem into a series of data manipulation operations. The problem is how to decide
for executing each query over the network in the most cost-way, however cost is defined. The factors to be considered are the distribution ofdata, communication costs, and lack of sufficient locally-available information. The
imize where the inherent parallelism is used to improve the performanceof executing the transaction, subject to the above-mentioned constraints. The
hard in nature, and the approaches are usually heuristic.
1.6.4 Distributed Concurrency Control Concurrency control involves the synchronization of accesses to the distributed database,such that the integrity of the database is maintained. It is, without any doubt,one of the most extensively studied problems in the DDBS field. The concurrencycontrol problem in a distributed context is somewhat different than in a centralizedframework. One not only has to worry about the integrity of a single database, but
083
Seat No: _____________________
– 2016 (ODD) 17-10-2016 10:00 AM To 12:30 PM
Total Marks: 70
07
The question that is being addressed is how the database and the applications that run against it should be placed across the sites. There are two basic alternatives to placing
scheme the database is divided into a number of disjoint partitions each of which is placed at
(also called fully replicated (or
) where each partition of the database is stored at more than one fragmentation, distribution, the
The research in this area mostly involves mathematical programming in order to minimize the combined cost of storing the database, processing transactions
s. The general problem is NP-hard.
A directory contains information (such as descriptions and locations) about data o directory management are similar in nature
to the database placement problem discussed in the preceding section. A directory may be global to the entire DDBS or local to each site; it can be centralized at one
e can be a single copy or multiple copies.
Query processing deals with designing algorithms that analyze queries and convert them into a series of data manipulation operations. The problem is how to decide
-effective way, however cost is defined. The factors to be considered are the distribution of
available information. The imize where the inherent parallelism is used to improve the performance
mentioned constraints. The
Concurrency control involves the synchronization of accesses to the distributed database, such that the integrity of the database is maintained. It is, without any doubt, one of the most extensively studied problems in the DDBS field. The concurrency control problem in a distributed context is somewhat different than in a centralized framework. One not only has to worry about the integrity of a single database, but

Faculty of Degree Engineering
Department of CE/IT (07/
also about the consistency of multiple copies of the database. The condition thatrequires all the values of multiple copies of every data item to converge to the samevalue is called mutual consistency
1.6.5 Distributed Deadlock ManagementThe deadlock problem in DDBSs is similar in nature to that encountered in operatingsystems. The competition among users for access to a set of resources (data, in thiscase) can result in a deadlock if the synchronization mechanism is based on locking.The well-known alternatives of prevention, avoidance, and detection/recovery alsoapply to DDBSs.
1.6.6 Reliability of Distributed DBMSWe mentioned earlier that one of the potential advantages of distributed systemsis improved reliability and availability. This, however, is not a feature that comesautomatically. It is important that mechanisms be providof the database as well as to detect failures and recover from them. The implicationfor DDBSs is that when a failure occurs and various sites become either inoperableor inaccessible, the databases at the operational sites remFurthermore, when the computer system or network recovers from the failure, theDDBSs should be able to recover and bring the databases at the failed sites upThis may be especially difficult in the case of network pare divided into two or more groups with no communication among them.
1.6.7 Replication If the distributed database is (partially or fully) replicated, it is necessary to implementprotocols that ensure the consistency of the have the same value. These protocols can be to be applied to all the replicas before the transaction completes, or they may belazy so that the transaction updates one copy (care propagated to the others after the transaction completes.
1.6.8 Relationship among ProblemThe design of distributed databases affects many areas. It affects directory management, because thedefinition of fragments and their placement determine the contents of the directory(or directories) as well as the strategies that may be employed to manage them.The same information (i.e., fragment structure and placement) is used by the queryprocessor to determine the querand usage patterns that are determined by the query processor are used as inputs tothe data distribution and fragmentation algorithms. Similarly, directory placementand contents influence the processin There is a strong relationship among the concurrency control problem, the deadlockmanagement problem, and reliability issues. This is to be expected, since togetherthey are usually called the control algorithm that is employed will determine whether or not a separate deadlockmanagement facility is required. If a lockingoccur, whereas they will not if time stamping is the chosen alternative.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
also about the consistency of multiple copies of the database. The condition thates all the values of multiple copies of every data item to converge to the same
mutual consistency.
1.6.5 Distributed Deadlock Management The deadlock problem in DDBSs is similar in nature to that encountered in operating
etition among users for access to a set of resources (data, in thiscase) can result in a deadlock if the synchronization mechanism is based on locking.
known alternatives of prevention, avoidance, and detection/recovery also
6 Reliability of Distributed DBMS We mentioned earlier that one of the potential advantages of distributed systemsis improved reliability and availability. This, however, is not a feature that comesautomatically. It is important that mechanisms be provided to ensure the consistencyof the database as well as to detect failures and recover from them. The implicationfor DDBSs is that when a failure occurs and various sites become either inoperableor inaccessible, the databases at the operational sites remain consistent and up to date.Furthermore, when the computer system or network recovers from the failure, theDDBSs should be able to recover and bring the databases at the failed sites upThis may be especially difficult in the case of network partitioning, where the sitesare divided into two or more groups with no communication among them.
If the distributed database is (partially or fully) replicated, it is necessary to implementprotocols that ensure the consistency of the replicas,i.e., copies of the same data itemhave the same value. These protocols can be eager in that they force the updatesto be applied to all the replicas before the transaction completes, or they may be
so that the transaction updates one copy (called the master) from which updatesare propagated to the others after the transaction completes.
1.6.8 Relationship among Problem
distributed databases affects many areas. It affects directory management, because thes and their placement determine the contents of the directory
(or directories) as well as the strategies that may be employed to manage them.The same information (i.e., fragment structure and placement) is used by the queryprocessor to determine the query evaluation strategy. On the other hand, the accessand usage patterns that are determined by the query processor are used as inputs tothe data distribution and fragmentation algorithms. Similarly, directory placementand contents influence the processing of queries.
There is a strong relationship among the concurrency control problem, the deadlockmanagement problem, and reliability issues. This is to be expected, since togetherthey are usually called the transaction management problem. The concurrencycontrol algorithm that is employed will determine whether or not a separate deadlockmanagement facility is required. If a locking-based algorithm is used, deadlocks willoccur, whereas they will not if time stamping is the chosen alternative.
083
also about the consistency of multiple copies of the database. The condition that es all the values of multiple copies of every data item to converge to the same
The deadlock problem in DDBSs is similar in nature to that encountered in operating etition among users for access to a set of resources (data, in this
case) can result in a deadlock if the synchronization mechanism is based on locking. known alternatives of prevention, avoidance, and detection/recovery also
We mentioned earlier that one of the potential advantages of distributed systems is improved reliability and availability. This, however, is not a feature that comes
ed to ensure the consistency of the database as well as to detect failures and recover from them. The implication for DDBSs is that when a failure occurs and various sites become either inoperable
ain consistent and up to date. Furthermore, when the computer system or network recovers from the failure, the DDBSs should be able to recover and bring the databases at the failed sites up-to-date.
artitioning, where the sites are divided into two or more groups with no communication among them.
If the distributed database is (partially or fully) replicated, it is necessary to implement replicas,i.e., copies of the same data item
in that they force the updates to be applied to all the replicas before the transaction completes, or they may be
) from which updates
distributed databases affects many areas. It affects directory management, because the s and their placement determine the contents of the directory
(or directories) as well as the strategies that may be employed to manage them. The same information (i.e., fragment structure and placement) is used by the query
y evaluation strategy. On the other hand, the access and usage patterns that are determined by the query processor are used as inputs to the data distribution and fragmentation algorithms. Similarly, directory placement
There is a strong relationship among the concurrency control problem, the deadlock management problem, and reliability issues. This is to be expected, since together
problem. The concurrency control algorithm that is employed will determine whether or not a separate deadlock
based algorithm is used, deadlocks will
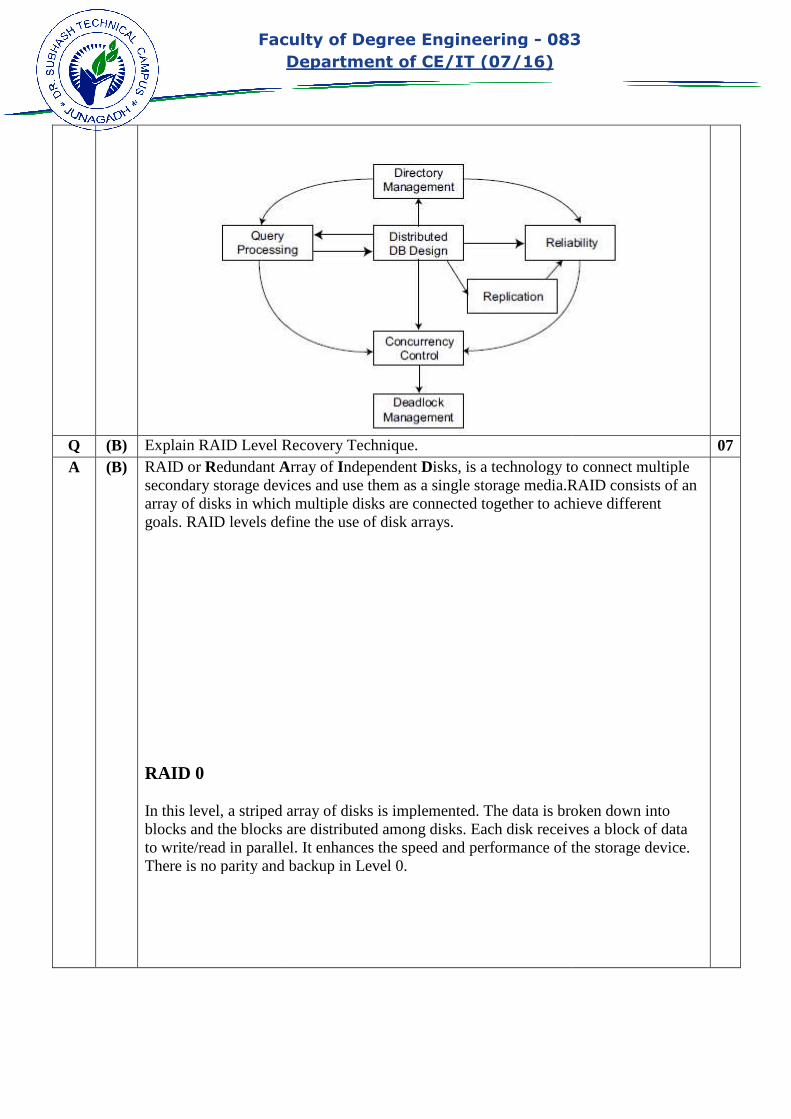
Faculty of Degree Engineering
Department of CE/IT (07/
Q (B) Explain RAID Level Recovery Technique.A (B) RAID or Redundant A
secondary storage devices and use them as a single storage media.RAID consists of an array of disks in which multiple disks goals. RAID levels define the use of disk arrays.
RAID 0
In this level, a striped array of disks is implemented. The data is broken down into blocks and the blocks are distributed among disks. Each disk receiveto write/read in parallel. It enhances the speed and performance of the storage device. There is no parity and backup in Level 0.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Explain RAID Level Recovery Technique. Array of Independent Disks, is a technology to connect multiple
secondary storage devices and use them as a single storage media.RAID consists of an array of disks in which multiple disks are connected together to achieve different goals. RAID levels define the use of disk arrays.
In this level, a striped array of disks is implemented. The data is broken down into blocks and the blocks are distributed among disks. Each disk receiveto write/read in parallel. It enhances the speed and performance of the storage device. There is no parity and backup in Level 0.
083
07 isks, is a technology to connect multiple
secondary storage devices and use them as a single storage media.RAID consists of an are connected together to achieve different
In this level, a striped array of disks is implemented. The data is broken down into blocks and the blocks are distributed among disks. Each disk receives a block of data to write/read in parallel. It enhances the speed and performance of the storage device.

Faculty of Degree Engineering
Department of CE/IT (07/
RAID 1
RAID 1 uses mirroring techniques. When data is sent to a RAID controller, it sends a copy of data to all the disks in the array. RAID level 1 is also called provides 100% redundancy in case of a failure.
RAID 2
• RAID Level 2 uses concept of parallel access technique. It works on the word(byte) level. So each strip stores one bit. It takextreme, writing only 1 bit per strip, instead of in arbitrary size block. For this reason, it require a minimum, of 8 surface to write data to the hard disk.
• In RAID level 2, strip are very small, so when a block is read, all diskaccessed in parallel.
• Hamming code generation is time consuming, therefore RAID level 2 is too slow for most commercial application.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
RAID 1 uses mirroring techniques. When data is sent to a RAID controller, it sends a to all the disks in the array. RAID level 1 is also called
provides 100% redundancy in case of a failure.
RAID Level 2 uses concept of parallel access technique. It works on the word(byte) level. So each strip stores one bit. It takes data striping to the extreme, writing only 1 bit per strip, instead of in arbitrary size block. For this reason, it require a minimum, of 8 surface to write data to the hard disk. In RAID level 2, strip are very small, so when a block is read, all diskaccessed in parallel. Hamming code generation is time consuming, therefore RAID level 2 is too slow for most commercial application.
083
RAID 1 uses mirroring techniques. When data is sent to a RAID controller, it sends a to all the disks in the array. RAID level 1 is also called mirroring and
RAID Level 2 uses concept of parallel access technique. It works on the es data striping to the
extreme, writing only 1 bit per strip, instead of in arbitrary size block. For this reason, it require a minimum, of 8 surface to write data to the hard disk. In RAID level 2, strip are very small, so when a block is read, all disks are
Hamming code generation is time consuming, therefore RAID level 2 is too

Faculty of Degree Engineering
Department of CE/IT (07/
RAID 3
RAID 3 stripes the data onto multiple disks. The parity bit generated for data word is stored on a different disk. This technique makes it to overcome single disk failures.
RAID 4
In this level, an entire block of data is written onto data disks and then the parity is generated and stored on a different disk. Note that level 3 uses bytewhereas level 4 uses blockdisks to implement RAID.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
RAID 3 stripes the data onto multiple disks. The parity bit generated for data word is t disk. This technique makes it to overcome single disk failures.
In this level, an entire block of data is written onto data disks and then the parity is generated and stored on a different disk. Note that level 3 uses byte
s level 4 uses block-level striping. Both level 3 and level 4 require at least three disks to implement RAID.
083
RAID 3 stripes the data onto multiple disks. The parity bit generated for data word is t disk. This technique makes it to overcome single disk failures.
In this level, an entire block of data is written onto data disks and then the parity is generated and stored on a different disk. Note that level 3 uses byte-level striping,
level striping. Both level 3 and level 4 require at least three

Faculty of Degree Engineering
Department of CE/IT (07/
RAID 5
RAID 5 writes whole data blocks onto different disks, but the parity bits generated for data block stripe are distributed among all the different dedicated disk.
RAID 6
RAID 6 is an extension of level 5. In this level, two independent parities are generated and stored in distributed fashion among multiple disks. Two parities provide additional fault tolerance. This level requires at least four disk drives to implement RAID.
Q. 2 (A) What is Concurrency? List out method of Concurrency control and Explain any one of them.
A. 2 (A) Concurrency: In computer science, instruction sequences at the same time.
• In distributed database system, database is typically used by many users. These system usually allow multiple transaction to run concurrently at the same time.
• It must support parallel execution of tran• Communication delay is less.• It must be recovery from site and communication failure.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
RAID 5 writes whole data blocks onto different disks, but the parity bits generated for data block stripe are distributed among all the data disks rather than storing them on a different dedicated disk.
RAID 6 is an extension of level 5. In this level, two independent parities are generated and stored in distributed fashion among multiple disks. Two parities provide additional
lt tolerance. This level requires at least four disk drives to implement RAID.
What is Concurrency? List out method of Concurrency control and Explain any one of
In computer science, concurrency is the execution of several instruction sequences at the same time.
In distributed database system, database is typically used by many users. These system usually allow multiple transaction to run concurrently at the same time. It must support parallel execution of transaction. Communication delay is less. It must be recovery from site and communication failure.
083
RAID 5 writes whole data blocks onto different disks, but the parity bits generated for data disks rather than storing them on a
RAID 6 is an extension of level 5. In this level, two independent parities are generated and stored in distributed fashion among multiple disks. Two parities provide additional
lt tolerance. This level requires at least four disk drives to implement RAID.
What is Concurrency? List out method of Concurrency control and Explain any one of 07
n of several
In distributed database system, database is typically used by many users. These system usually allow multiple transaction to run concurrently at the same time.

Faculty of Degree Engineering
Department of CE/IT (07/
Locking-Based Concurrency Control
• The main idea of lockingitem that is shared by conflicting operations is accessed by one operation at a time.
• This lock is set by a transaction before it is accessed and is reset at the end of its use.
• There are two types of locks read lock (rl) and write lock (wl) Locking-Based Concurrency Control Algorithms
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Methods of concurrency control
Based Concurrency Control
The main idea of locking-based concurrency control is to ensure that a datitem that is shared by conflicting operations is accessed by one operation at a
This lock is set by a transaction before it is accessed and is reset at the end of
There are two types of locks read lock (rl) and write lock (wl)
ed Concurrency Control Algorithms
083
based concurrency control is to ensure that a data item that is shared by conflicting operations is accessed by one operation at a
This lock is set by a transaction before it is accessed and is reset at the end of
There are two types of locks read lock (rl) and write lock (wl)

Faculty of Degree Engineering
Department of CE/IT (07/
2PL Lock Graph
Q (B) Explain layers of query processing.A (B) Query Decomposition
• The first layer decomposes the calculus query into an algebraic query on global relations. The information needed for thisconceptual schema describing the global relations.
• Query decomposition can be viewed as four successive steps.• First , the calculus query is rewritten in a normalized form that is suitable for
subsequent manipulation. manipulation of the query quantifiers and of the query qualification by applying logical operator priority.
• Second, the normalized query is analyzed semantically so that incorrect queries are detected and rejqueries exist only for a subset of relational calculus. Typically, they use some sort of graph that captures the semantics of the query.
• Third , the correct query (still expressed in relational calOne way to simplify a query is to eliminate redundant predicates. Note that redundant queries are likely to arise when a query is the result of system transformations applied to the user query. such transformations are used for performing semantic data control (views, protection, and semantic integrity control).
• Fourth , the calculus query is restructured as an algebraic query. The traditional way to do this transformation toward a “better” algebraic specification is to start with an initial algebraic query and transform it in order to find a “go
• The algebraic query generated by this layer is good in the sense that the worse executions are typically avoided.
Data Localization • The input to the second layer is an algebraic query on globa
main role of the second layer is to localize the query’s data using data distribution information in the fragment schema.
• This layer determines which fragments are involved in the query and transforms the distributed query into a query on
• A global relation can be reconstructed by applying the fragmentation rules, and
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Explain layers of query processing. Query Decomposition
The first layer decomposes the calculus query into an algebraic query on global relations. The information needed for this transformation is found in the global conceptual schema describing the global relations. Query decomposition can be viewed as four successive steps.
, the calculus query is rewritten in a normalized form that is suitable for subsequent manipulation. Normalization of a query generally involves the manipulation of the query quantifiers and of the query qualification by applying logical operator priority.
, the normalized query is analyzed semantically so that incorrect queries are detected and rejected as early as possible. Techniques to detect incorrect queries exist only for a subset of relational calculus. Typically, they use some sort of graph that captures the semantics of the query.
, the correct query (still expressed in relational calculus) is simplified. One way to simplify a query is to eliminate redundant predicates. Note that redundant queries are likely to arise when a query is the result of system transformations applied to the user query. such transformations are used for
rming semantic data control (views, protection, and semantic integrity
, the calculus query is restructured as an algebraic query. The traditional way to do this transformation toward a “better” algebraic specification is to
nitial algebraic query and transform it in order to find a “goThe algebraic query generated by this layer is good in the sense that the worse executions are typically avoided.
The input to the second layer is an algebraic query on globamain role of the second layer is to localize the query’s data using data distribution information in the fragment schema. This layer determines which fragments are involved in the query and transforms the distributed query into a query on fragments. A global relation can be reconstructed by applying the fragmentation rules, and
083
07
The first layer decomposes the calculus query into an algebraic query on global transformation is found in the global
Query decomposition can be viewed as four successive steps. , the calculus query is rewritten in a normalized form that is suitable for
Normalization of a query generally involves the manipulation of the query quantifiers and of the query qualification by applying
, the normalized query is analyzed semantically so that incorrect queries ected as early as possible. Techniques to detect incorrect
queries exist only for a subset of relational calculus. Typically, they use some
culus) is simplified. One way to simplify a query is to eliminate redundant predicates. Note that redundant queries are likely to arise when a query is the result of system transformations applied to the user query. such transformations are used for
rming semantic data control (views, protection, and semantic integrity
, the calculus query is restructured as an algebraic query. The traditional way to do this transformation toward a “better” algebraic specification is to
nitial algebraic query and transform it in order to find a “go The algebraic query generated by this layer is good in the sense that the worse
The input to the second layer is an algebraic query on global relations. The main role of the second layer is to localize the query’s data using data
This layer determines which fragments are involved in the query and
A global relation can be reconstructed by applying the fragmentation rules, and

Faculty of Degree Engineering
Department of CE/IT (07/
then deriving a program, called a localization program, of relational algebra operators, which then act on fragments.
• Generating a query on fragments is done in two • First , the query is mapped into a fragment query by substituting each
relation by its reconstruction program (also called materialization program).
• Secondanother “good” query.
Global Query Optimization
• The input to the third layer is an algebraic query on fragments. The goal of query optimization is to find an execution strategy for the query which is close to optimal.
• The previous layers have already optimized the quereliminating redundant expressions. However, this optimization is independent of fragment characteristics such as fragment allocation and cardinalities.
• Query optimization consists of finding the “best” ordering of operators in the query, including communication operators that minimize a cost function.
• The output of the query optimization layer is a optimized algebraic query with communication operators included on fragments. It is typically represented and saved (for future executions) as
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
then deriving a program, called a localization program, of relational algebra operators, which then act on fragments. Generating a query on fragments is done in two steps
, the query is mapped into a fragment query by substituting each relation by its reconstruction program (also called materialization program). Second, the fragment query is simplified and restructured to produce another “good” query.
Global Query Optimization The input to the third layer is an algebraic query on fragments. The goal of query optimization is to find an execution strategy for the query which is close
The previous layers have already optimized the query, for example, by eliminating redundant expressions. However, this optimization is independent of fragment characteristics such as fragment allocation and cardinalities.Query optimization consists of finding the “best” ordering of operators in
including communication operators that minimize a cost
The output of the query optimization layer is a optimized algebraic query with communication operators included on fragments. It is typically represented and saved (for future executions) as a distributed query execution
083
then deriving a program, called a localization program, of relational algebra
, the query is mapped into a fragment query by substituting each relation by its reconstruction program (also called materialization
, the fragment query is simplified and restructured to produce
The input to the third layer is an algebraic query on fragments. The goal of query optimization is to find an execution strategy for the query which is close
y, for example, by eliminating redundant expressions. However, this optimization is independent of fragment characteristics such as fragment allocation and cardinalities. Query optimization consists of finding the “best” ordering of operators in
including communication operators that minimize a cost
The output of the query optimization layer is a optimized algebraic query with communication operators included on fragments. It is typically represented and
a distributed query execution plan.

Faculty of Degree Engineering
Department of CE/IT (07/
Distributed Query Execution• The last layer is performed by all the sites having fragments involved in the
query. • Each sub query executing at one site, called a local query, is then optimized
using the local schema o
Q. 2 (B) Explain, Min term predict, COM_MIN algorithm in context of horizontal fragmentation.
A. 2 (B) Example PROJECT table:• PROJ:
Minterms Let set of minterm predicates beM = { m1, m2, …, mz }where M = {mj | mj =
• Some property equivalences:• For equality: !(attr = val) = (attr <> val)• For inequality: !(attr > val) = (attr val)• It is not necessary to duplicate predicates• In minterms, one is sufficient
Minterm Examples
• p1: LOC = 'Montreal'• p2: LOC = 'New Y• p3: LOC = 'Paris'• p4: BUDGET > 200000• p5: BUDGET <= 200000• m1: LOC = 'New York' ^ BUDGET > 200000• m2: LOC = 'New York' ^ BUDGET <= 200000• m3: LOC = 'Paris' ^ BUDGET > 200000• m4: LOC = 'Paris' ^ BUDGET <= 200000• m5: LOC = 'Montreal' ^ BUDGET > 200000• m6: LOC = 'Montreal ' ^ BUDGET <= 200000
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Distributed Query Execution The last layer is performed by all the sites having fragments involved in the
Each sub query executing at one site, called a local query, is then optimized using the local schema of the site and executed.
OR Explain, Min term predict, COM_MIN algorithm in context of horizontal
Example PROJECT table:
Let set of minterm predicates be M = { m1, m2, …, mz } where M = {mj | mj = ̂ (pn ԑ Pr) pn}
Some property equivalences: For equality: !(attr = val) = (attr <> val) For inequality: !(attr > val) = (attr val) It is not necessary to duplicate predicates In minterms, one is sufficient
p1: LOC = 'Montreal' p2: LOC = 'New York' p3: LOC = 'Paris' p4: BUDGET > 200000 p5: BUDGET <= 200000 m1: LOC = 'New York' ^ BUDGET > 200000 m2: LOC = 'New York' ^ BUDGET <= 200000 m3: LOC = 'Paris' ^ BUDGET > 200000 m4: LOC = 'Paris' ^ BUDGET <= 200000 m5: LOC = 'Montreal' ^ BUDGET > 200000
6: LOC = 'Montreal ' ^ BUDGET <= 200000
083
The last layer is performed by all the sites having fragments involved in the
Each sub query executing at one site, called a local query, is then optimized
Explain, Min term predict, COM_MIN algorithm in context of horizontal 07

Faculty of Degree Engineering
Department of CE/IT (07/
Minterm Properties
• Minterm selectivity• Number of records that satisfy minterm• sel(m1) = 1; sel(m2) = 1; sel(m4) = 0
• Access frequency by applications and users• Q = {q1, q2, …, qq} is set of queries• acc(q1) is freque
Algorithm for Determining Minterms Rule 1: fragment is partitioned into at least two parts thatby at least one application Definitions
R - relation
Pr - set of simple predicates
Pr' - another set of simple predicates
F - set of minterm fragments
COM_MIN (R, Pr) { // Compute minterms Rule 1 Pr' = pi
Pr = Pr - pi F = fi // fi is minterm fragment according to pwhile (Pr' is incomplete) { find pj Pr that partitions some f Pr' = Pr' U pj Pr = Pr - pj F = F U fj // fj is minterm fragment according to p if pk Pr' which is Pr' = Pr' - pk
F = F - fk
} } return Pr' }
Q.3 (A) Explain following in context of Relational algebra :1. Selection 2. Natural Join 3.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Minterm selectivity Number of records that satisfy minterm sel(m1) = 1; sel(m2) = 1; sel(m4) = 0
Access frequency by applications and users Q = {q1, q2, …, qq} is set of queries acc(q1) is frequency of access of query 1
Algorithm for Determining Minterms
Rule 1: fragment is partitioned into at least two parts that are accessed differently by at least one application
set of simple predicates
simple predicates
set of minterm fragments
COM_MIN (R, Pr) { // Compute minterms // find a pi such that pi partitions R according to
is minterm fragment according to pi
while (Pr' is incomplete)
Pr that partitions some fk of Pr'
is minterm fragment according to pj
Pr' which is non-relevant { // this is complex
following in context of Relational algebra : 1. Selection 2. Natural Join 3. Projection
083
are accessed differently
partitions R according to
07

Faculty of Degree Engineering
Department of CE/IT (07/
A.3 (A) 1. Selection • Produces a horizontal subset of the operand relation• General form
σF(R)={ where
• R is a relation, • F is a formula consisting of
• •
•
Selection Example
2. Natural Join
• Equi-join of two reboth R and S and projecting out one copy of those attributes
• R ⋈ S = ΠR∪Sσ
Natural Join Example
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Produces a horizontal subset of the operand relation
)={ t |t∈R and F(t) is true}
is a relation, t is a tuple variable is a formula consisting of
operands that are constants or attributes arithmetic comparison operators
<, >, =, ≠, ≤, ≥ logical operators
∧, ∨, ¬
join of two relations R and S over an attribute (or attributes) common to and projecting out one copy of those attributes
σF(R × S)
Natural Join Example
083
over an attribute (or attributes) common to and projecting out one copy of those attributes

Faculty of Degree Engineering
Department of CE/IT (07/
3. Projection
• Produces a vertical slice of a relation• General form
where
• R is a relation, • { A1,…,
will be performed• Note: projection can generate duplicate tuples. Commercial systems (and SQL)
allow this and provide• Projection with duplicate elimination• Projection without duplicate elimination
Projection Example
Q (B) Explain Client Server architecture for Distributed DBMS.A (B) • This provides two-
complexity of modern DBMSs and the complexity of distribution.• The server does most of the data management work (query processing an
optimization, transaction management, storage management).• The client is the application and the user interface (management the data that is
cached to the client, management the transaction locks).
• Multiple client - single server From a data management perspective, this is not much different from centralized databases since the database is stor
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Produces a vertical slice of a relation
ΠA1,…,An(R)={ t[A1,…, An] | t∈R}
is a relation, t is a tuple variable ,…, An} is a subset of the attributes of R over which the
will be performed Note: projection can generate duplicate tuples. Commercial systems (and SQL) allow this and provide
Projection with duplicate elimination Projection without duplicate elimination
erver architecture for Distributed DBMS. -level architecture which make it easier to manage the
complexity of modern DBMSs and the complexity of distribution.does most of the data management work (query processing an
optimization, transaction management, storage management). is the application and the user interface (management the data that is
cached to the client, management the transaction locks).
• This architecture is quite common in relational systems where the communication between the clients and the server(s) is at the level of SQL statements.
single server From a data management perspective, this is not much different from
centralized databases since the database is stored on only one machine (the server)
083
over which the projection
Note: projection can generate duplicate tuples. Commercial systems (and SQL)
07
which make it easier to manage the complexity of modern DBMSs and the complexity of distribution.
does most of the data management work (query processing and
is the application and the user interface (management the data that is
This architecture is quite common in ems where the communication
between the clients and the server(s) is at the level of SQL statements.
From a data management perspective, this is not much different from ed on only one machine (the server)
Faculty of Degree Engineering
Department of CE/IT (07/
which also hosts the software to manage it. However, there are some differences from centralized systems in the way transactions are executed and caches are managed. • Multiple client - multiple server In this case, two client manages its own connection to the appropriate server or each client knows of only its “home server” which then communicates with other servers as required.
Q. 3 (A) Explain ACID property in concept of DDBMS.A. 3 (A) • The consistency and reliability aspects of transactions are due to four properties
1. Atomicity 2. Consistency 3. Isolation 4. Durability
• Together, these are commonly referred to as the ACID properties of transactions. 1. Atomicity
• Atomicity refers to the fact that a transaction is treated as a unit of operation. Therefore, either all the transaction’s actions are completed, or none of them are. This is also known as the “all
2. Consistency • The consistency of a t• In other words, a transaction is a correct program that maps one consistent
database state to another.3. Isolation
• Isolation is the property of transactions that requires each transaction to see a consistent database at
• In other words, an executing transaction cannot reveal its results to other concurrent transactions before its commitment.
4. Durability • Durability refers to that property of transactions which ensures that once a
transaction commits, its resultdatabase.
Q (B) Explain AA matrix, CA matrix and BEA algorithm in context of vertical fragmentation.
A (B) Determining Affinity• The attribute use matrix does not help us yet• We cannot determine the affin
• because we don't know the access frequency of the• attribute groups• We need this to calculate attribute affinity • Defines how often Ai and Aj are accessed together
• Depends on the frequency of query requests for
simultaneously.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
which also hosts the software to manage it. However, there are some differences from centralized systems in the way transactions are executed and caches are managed.
multiple server In this case, two alternative management strategies are possible: either each
client manages its own connection to the appropriate server or each client knows of only its “home server” which then communicates with other servers as required.
OR rty in concept of DDBMS.
The consistency and reliability aspects of transactions are due to four properties
Together, these are commonly referred to as the ACID properties of transactions.
Atomicity refers to the fact that a transaction is treated as a unit of operation. Therefore, either all the transaction’s actions are completed, or none of them are. This is also known as the “all-or-nothing property.”
The consistency of a transaction is simply its correctness. In other words, a transaction is a correct program that maps one consistent database state to another.
Isolation is the property of transactions that requires each transaction to see a consistent database at all times. In other words, an executing transaction cannot reveal its results to other concurrent transactions before its commitment.
Durability refers to that property of transactions which ensures that once a transaction commits, its results are permanent and cannot be erased from the
Explain AA matrix, CA matrix and BEA algorithm in context of vertical
Determining Affinity The attribute use matrix does not help us yet We cannot determine the affinity of the attributes
because we don't know the access frequency of the attribute groups
ed this to calculate attribute affinity - aff(Ai, Aj) Defines how often Ai and Aj are accessed together
Depends on the frequency of query requests for attributes Ai and Aj simultaneously.
083
which also hosts the software to manage it. However, there are some differences from centralized systems in the way transactions are executed and caches are managed.
alternative management strategies are possible: either each client manages its own connection to the appropriate server or each client knows of only its “home server” which then communicates with other servers as required.
07 The consistency and reliability aspects of transactions are due to four properties
Together, these are commonly referred to as the ACID properties of transactions.
Atomicity refers to the fact that a transaction is treated as a unit of operation. Therefore, either all the transaction’s actions are completed, or none of them
In other words, a transaction is a correct program that maps one consistent
Isolation is the property of transactions that requires each transaction to see a
In other words, an executing transaction cannot reveal its results to other
Durability refers to that property of transactions which ensures that once a s are permanent and cannot be erased from the
Explain AA matrix, CA matrix and BEA algorithm in context of vertical 07
Ai and Aj

Faculty of Degree Engineering
Department of CE/IT (07/
Affinity Measure • The attribute affinity between two attributes Ai and Aj of a relation
• where refm(qk) is the number of access to attributes Ai and Aj for each application qk at site Sm
• where accl(qk) is the access frequency of Attribute Affinity Matrix
Clustering Algorithm
• Want to find which attributes belong together in a vertically fragmented table• Examining it for this small case is sufficient
Bond Energy Algorithm (BEA)
• Initialize - pick • Iterate
Select the next column and try to place it in the matrix Choose the place that maximizes the global affinity Repeat
• Repeat the process for rows. However, since AA is symmetric, jus We will reorder the columns later to create a symmetric matrix
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
The attribute affinity between two attributes Ai and Aj of a relation
where refm(qk) is the number of access to attributes Ai and Aj for each application qk at site Sm where accl(qk) is the access frequency of qk for each site
Attribute Affinity Matrix – Example
Clustering Algorithm
Want to find which attributes belong together in a vertically fragmented tableExamining it for this small case is sufficient
Bond Energy Algorithm (BEA) pick any column
Select the next column and try to place it in the matrix Choose the place that maximizes the global affinity
Repeat the process for rows. However, since AA is symmetric, just reorder the rows! We will reorder the columns later to create a symmetric matrix
083
The attribute affinity between two attributes Ai and Aj of a relation
where refm(qk) is the number of access to attributes Ai and Aj for each
Want to find which attributes belong together in a vertically fragmented table
We will reorder the columns later to create a symmetric matrix

Faculty of Degree Engineering
Department of CE/IT (07/
BEA Pseudocode Bond Energy Algorithm (BEA) {input: AA // attribute affinity matrixoutput: CA // clustered attribute matrix// put the first two columns inCA(*, 1) <- AA(*, 1) CA(*, 2) <- AA(*, 2) // for each of the rest of the columns of AA,// choose the best placement.while (index <= n ) { // calculate continuity of each possible place for new columnfor (i=1; i< index; i++) // iterate over the columnscalculate cont(Ai-1, Aindex, Ai);calculate cont(Aindex-loc <- placement given by maximum cont()for (j=index; j>loc; j--CA(*,j) <- CA (*, j- 1);CA(*, loc) = AA(*, index);index <- index + 1; } // reorder the rows according to the placement of columns}
Q.4 (A) Explain Two phase commit protocol.A:4 (A) Two-phase commit (2PC) is a very simple and elegant protocol that ensures the atomic
commitment of distributed transactions. It extends tdistributed transactions by insisting that all sites involved in the execution of a distributed transaction agree to commit the transaction before its effects are made permanent. There are a number of reasons whthe type of concurrency control algorithm that is used, some schedulers may not be ready to terminate a transaction. For example, if a transaction has read a value of a data item that is updated by another transaction that has not yet committed, the associated scheduler may not want to commit the former. Of course, strict concurrency control algorithms that avoid cascading aborts would not permit the updated value of a data item to be readtransaction until the updating transaction terminates. This is sometimes called the recoverability condition. A brief description of the 2PC protocol that does not consider failures is as follows. Initially, the coordinator writes a begin comsites, and enters the WAIT state. When a participant receives a “prepare” message, it checks if it could commit the transaction. If so, the participant writes a “vote-commit” message to the coordinator, and enters READY state; otherwise, the participant writes an abort record and sends a “votethe site is to abort, it can forget about that transaction, si(i.e., unilateral abort). After the coordinator has received a reply from every participant, itdecides whether to commit or to abort the transaction. If even one participant has registered a negative vote, the coordisends a “global-abort” message to all participant sites, and enters the ABORT state; otherwise, it writes a commit record, sends a “globalCOMMIT state. The participants either commit or abort the transaction according to the coordinator’s instructions and send back an acknowledgment, at which point the coordinator terminates the transaction by writing an
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Bond Energy Algorithm (BEA) { input: AA // attribute affinity matrix output: CA // clustered attribute matrix // put the first two columns in
// for each of the rest of the columns of AA, // choose the best placement.
// calculate continuity of each possible place for new column for (i=1; i< index; i++) // iterate over the columns
1, Aindex, Ai); -1, Aindex, Aindex+1); // boundary
placement given by maximum cont() --) // iterate over the columns 1);
CA(*, loc) = AA(*, index);
// reorder the rows according to the placement of columns
Explain Two phase commit protocol. phase commit (2PC) is a very simple and elegant protocol that ensures the atomic
commitment of distributed transactions. It extends the effects of local atomic commit actions to distributed transactions by insisting that all sites involved in the execution of a distributed transaction agree to commit the transaction before its effects are made permanent. There are a number of reasons why such synchronization among sites is necessary. First, depending on the type of concurrency control algorithm that is used, some schedulers may not be ready to terminate a transaction. For example, if a transaction has read a value of a data item that is updated by another transaction that has not yet committed, the associated scheduler may not want to commit the former. Of course, strict concurrency control algorithms that avoid cascading aborts would not permit the updated value of a data item to be readtransaction until the updating transaction terminates. This is sometimes called the
A brief description of the 2PC protocol that does not consider failures is as follows. Initially, the
begin commit record in its log, sends a “prepare” message to all participant sites, and enters the WAIT state. When a participant receives a “prepare” message, it checks if it could commit the transaction. If so, the participant writes a ready record in the log, se
commit” message to the coordinator, and enters READY state; otherwise, the participant record and sends a “vote-abort” message to the coordinator. If the decision of
the site is to abort, it can forget about that transaction, since an abort decision serves as a veto (i.e., unilateral abort). After the coordinator has received a reply from every participant, itdecides whether to commit or to abort the transaction. If even one participant has registered a negative vote, the coordinator has to abort the transaction globally. So it writes an
abort” message to all participant sites, and enters the ABORT state; otherwise, record, sends a “global-commit” message to all participants, and e
COMMIT state. The participants either commit or abort the transaction according to the coordinator’s instructions and send back an acknowledgment, at which point the coordinator terminates the transaction by writing an end of transaction record in the log.
083
07 phase commit (2PC) is a very simple and elegant protocol that ensures the atomic
he effects of local atomic commit actions to distributed transactions by insisting that all sites involved in the execution of a distributed transaction agree to commit the transaction before its effects are made permanent. There are
y such synchronization among sites is necessary. First, depending on the type of concurrency control algorithm that is used, some schedulers may not be ready to terminate a transaction. For example, if a transaction has read a value of a data item that is updated by another transaction that has not yet committed, the associated scheduler may not want to commit the former. Of course, strict concurrency control algorithms that avoid cascading aborts would not permit the updated value of a data item to be read by any other transaction until the updating transaction terminates. This is sometimes called the
A brief description of the 2PC protocol that does not consider failures is as follows. Initially, the record in its log, sends a “prepare” message to all participant
sites, and enters the WAIT state. When a participant receives a “prepare” message, it checks if record in the log, sends a
commit” message to the coordinator, and enters READY state; otherwise, the participant abort” message to the coordinator. If the decision of
nce an abort decision serves as a veto (i.e., unilateral abort). After the coordinator has received a reply from every participant, it decides whether to commit or to abort the transaction. If even one participant has registered a
nator has to abort the transaction globally. So it writes an abort record, abort” message to all participant sites, and enters the ABORT state; otherwise,
commit” message to all participants, and enters the COMMIT state. The participants either commit or abort the transaction according to the coordinator’s instructions and send back an acknowledgment, at which point the coordinator

Faculty of Degree Engineering
Department of CE/IT (07/
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
State Transitions in 2PC Protocol
083

Faculty of Degree Engineering
Department of CE/IT (07/
Q (B) Explain Top-down and Bottom
A (B) Top-Down Design Process Conceptual design of the data is the ER model of the whole enterprise Federated by the views Must anticipate new views/usages Must describe semantics of the data as used in the domain/enterpriseThis is almost identical to typical DB design However, we are concerned with Distribution Design We need to place tables "geographic We also need to fragment tables
Bottom Up
• Top-down design is the choice when you have the liberty of starting from scratch Unfortunately, this is not usually the case Some element of bottom
• Bottom-up design is integrating independent/semiGlobal Conceptual Must deal with schema mapping issues May deal with heterogeneous integration issues
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
down and Bottom-up design strategies.
Down Design Process
Conceptual design of the data is the ER model of the whole enterprise Federated by the views Must anticipate new views/usages Must describe semantics of the data as used in the domain/enterprise
This is almost identical to typical DB design However, we are concerned with Distribution Design We need to place tables "geographically" on the network We also need to fragment tables
down design is the choice when you have the liberty of starting from scratchUnfortunately, this is not usually the case Some element of bottom-up design is more common
up design is integrating independent/semi-independent schemas into a Global Conceptual Schema (GCS)
Must deal with schema mapping issues May deal with heterogeneous integration issues
OR
083
07
Conceptual design of the data is the ER model of the whole enterprise
Must describe semantics of the data as used in the domain/enterprise
down design is the choice when you have the liberty of starting from scratch
independent schemas into a

Faculty of Degree Engineering
Department of CE/IT (07/
Q.4 (A) Write short note on different tecA.4 (A) • The additional components and abnormal algorithm can be added to a system these
components and algorithms attempt to ensure that occurrences of erroneous states do not result in later system failure ideally, they remothem to “correct” states from which normal processing can continue. These additional component and abnormal algorithm, called recovery technique.
• Backward and Forward Error Recovery• Log Based Recovery• Write- Ahead Logging Proto
Backward and Forward Error Recovery Approaches to failure recovery:
– Forward•
• – Backward
•
Comparison: Forward vs. Backward error recovery– Backward
(+) Simple to implement(+) Can be used as general recovery mechanism(-) Performance penalty(-) No guarantee that fa(-) Some components cannot be recovered
– Forward(+) Less overhead (-) Limited use, i.e. only when impact of faults understood(-) Cannot be used as general mechanism for error recovery
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
ifferent techniques of recoverability. The additional components and abnormal algorithm can be added to a system these components and algorithms attempt to ensure that occurrences of erroneous states do not result in later system failure ideally, they removes these errors and restore them to “correct” states from which normal processing can continue. These additional component and abnormal algorithm, called recovery technique. Backward and Forward Error Recovery Log Based Recovery
Ahead Logging Protocol
Backward and Forward Error Recovery
Approaches to failure recovery: Forward-error recovery:
Remove errors in process/system state (if errors can be completely assessed) Continue process/system forward execution
Backward-error recovery: Restore process/system to previous error-free state and restart from there
Forward vs. Backward error recovery Backward-error recovery
Simple to implement Can be used as general recovery mechanism
Performance penalty No guarantee that fault does not occur again Some components cannot be recovered Forward-error Recovery
Limited use, i.e. only when impact of faults understoodCannot be used as general mechanism for error recovery
083
07 The additional components and abnormal algorithm can be added to a system these components and algorithms attempt to ensure that occurrences of erroneous states
ves these errors and restore them to “correct” states from which normal processing can continue. These additional component and abnormal algorithm, called recovery technique.
Remove errors in process/system state (if errors can be
free state and restart
Limited use, i.e. only when impact of faults understood Cannot be used as general mechanism for error recovery

Faculty of Degree Engineering
Department of CE/IT (07/
(1) The Operation-based Appr• Principle:
– Record all changes made to state of process (‘audit trail’ or ‘log’) such that process can be returned to a previous state
– Example: A transaction based environment where transactions update a database
•
•
(2) State-based Approach• Principle: establish frequent ‘recovery points’ or ‘checkpoints’ saving the entire
state of process• Actions:
– ‘Checkpointing’ or ‘taking a checkpoint’: saving process state– ‘Rolling back’ a process: restoring a process to a prior state
Log Based Recovery
• When failures occur the following operation that use the log are executed.• UNDO: restore database to stat• REDO: perform the changes to the database over again.
UNDO
REDO
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
based Approach
Record all changes made to state of process (‘audit trail’ or ‘log’) such that process can be returned to a previous state Example: A transaction based environment where transactions update a database
It is possible to commit or undo updates on a perbasis A commit indicates that the transaction on the object was successful and changes are permanent
based Approach establish frequent ‘recovery points’ or ‘checkpoints’ saving the entire
state of process
‘Checkpointing’ or ‘taking a checkpoint’: saving process state‘Rolling back’ a process: restoring a process to a prior state
When failures occur the following operation that use the log are executed.UNDO: restore database to state prior to execution. REDO: perform the changes to the database over again.
083
Record all changes made to state of process (‘audit trail’ or ‘log’) such
Example: A transaction based environment where transactions update a
es on a per-transaction
A commit indicates that the transaction on the object was
establish frequent ‘recovery points’ or ‘checkpoints’ saving the entire
‘Checkpointing’ or ‘taking a checkpoint’: saving process state ‘Rolling back’ a process: restoring a process to a prior state
When failures occur the following operation that use the log are executed.
REDO: perform the changes to the database over again.

Faculty of Degree Engineering
Department of CE/IT (07/
Write- Ahead Logging Protocol • write-ahead logging
durability in database systems.• In a system using W
applied. Usually both redo and undo information is stored in the log.• The purpose of this can be illustrated by an example. Imagine a program that is in
the middle of performing some operation whenpower. Upon restart, that program might well need to know whether the operation it was performing succeeded, halfused, the program can check this log and compare what it wasdoing when it unexpectedly lost power to what was actually done. On the basis of this comparison, the program could decide to undo what it had started, complete what it had started, or keep things as they are.
Q (B) What is Semantic Integrity control? Explain in concept of Centralized and Distributed environment.
A (B) Semantic Integrity Control • Semantic integrity control ensures database consistency by rejecting update transactions that lead to inconsistent database states, or bthe database state, which compensate for the effects of the update transactions. • Two main types of integrity constraints can be distinguished: structural constraints and
behavioral constraints.• Structural constraints expre
of such constraints are unique key constraints in the relational model, or oneassociations between objects in the object
• Behavioral constraints are essential in the databasassociations between objects, such as inclusion dependency in the relational model, or describe object properties and structures.
Centralized Semantic Integrity Control • Specification of Integrity Constraints• triggers (event-condition
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Ahead Logging Protocol
ahead logging (WAL ) is a family of techniques for providing atomicity and durability in database systems. In a system using WAL, all modifications are written to a log before they are applied. Usually both redo and undo information is stored in the log.The purpose of this can be illustrated by an example. Imagine a program that is in the middle of performing some operation when the machine it is running on loses power. Upon restart, that program might well need to know whether the operation it was performing succeeded, half-succeeded, or failed. If a writeused, the program can check this log and compare what it was doing when it unexpectedly lost power to what was actually done. On the basis of this comparison, the program could decide to undo what it had started, complete what it had started, or keep things as they are.
ntegrity control? Explain in concept of Centralized and Distributed
Semantic Integrity Control
Semantic integrity control ensures database consistency by rejecting update transactions that lead to inconsistent database states, or by activating specific actions on the database state, which compensate for the effects of the update transactions.
Two main types of integrity constraints can be distinguished: structural constraints and behavioral constraints. Structural constraints express basic semantic properties inherent to a model. Examples of such constraints are unique key constraints in the relational model, or oneassociations between objects in the object-oriented model. Behavioral constraints are essential in the database design process. They can express associations between objects, such as inclusion dependency in the relational model, or describe object properties and structures.
Centralized Semantic Integrity Control
Specification of Integrity Constraints condition-action rules) can be used to automatically propagate updates,
083
) is a family of techniques for providing atomicity and
AL, all modifications are written to a log before they are applied. Usually both redo and undo information is stored in the log. The purpose of this can be illustrated by an example. Imagine a program that is in
the machine it is running on loses power. Upon restart, that program might well need to know whether the operation
succeeded, or failed. If a write-ahead log is supposed to be
doing when it unexpectedly lost power to what was actually done. On the basis of this comparison, the program could decide to undo what it had started, complete
ntegrity control? Explain in concept of Centralized and Distributed 07
Semantic integrity control ensures database consistency by rejecting update y activating specific actions on
the database state, which compensate for the effects of the update transactions.
Two main types of integrity constraints can be distinguished: structural constraints and
ss basic semantic properties inherent to a model. Examples of such constraints are unique key constraints in the relational model, or one-to-many
e design process. They can express associations between objects, such as inclusion dependency in the relational model, or
action rules) can be used to automatically propagate updates,

Faculty of Degree Engineering
Department of CE/IT (07/
and thus to maintain semantic integrity.• We can distinguish between three types of integrity constraints:
precondition, or general constraints• EMP(ENO, ENAME, TITLE)• PROJ(PNO, PNAME, BUDGET)• ASG(ENO, PNO, RESP, DUR) • Predefined constraints
express concisely the more common constraints of the relational model, such as nonnull attribute, unique key, foreign
• Employee number in relation EMP cannot be null.ENO NOT NULL IN EMP• The project number PNO in relation ASG is a foreign key matching the primary key
PNO of relation PROJ.PNO IN ASG REFERENCES PNO IN PROJ • Precondition const
relation for a given update type. The update type, which might be INSERT, DELETE, or MODIFY, permits restricting the integrity control.
• Precondition constraints can be expressed with the with the ability to specify the update type.
CHECK ON <relation name > WHEN <update type>
• The budget of a project is between 500K and 1000K.CHECK ON PROJ (BUDGET+ >= 500000 AND BUDGET <= 10• Only the tuples whose budget is 0 may be deleted.CHECK ON PROJ WHEN DELETE (BUDGET = 0) • General constraints
quantified. The database system must ensure that those formulas are alwayCHECK ON list of <variable name>:<relation name>,(<qualification>)
• The total duration for all employees in the CAD project is less than 100.• CHECK ON g:ASG, j:PROJ (SUM(g.DUR WHERE g.PNO=j.PNO)<100 IF
j.PNAME="CAD/CAM") Distributed Semantic Integr • Definition of Distributed Integrity Constraints• Assertions can involve data stored at different sites, the storage of the constraints must
be decided so as to minimize the cost of integrity checking. There is a strategy based on a taxonomy of integrity constraints that distinguishes three classes:
• Individual constraintstuples to be updated independently of the rest of the database.
• Set-oriented constraints
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
and thus to maintain semantic integrity. We can distinguish between three types of integrity constraints: predefined
general constraints. EMP(ENO, ENAME, TITLE) PROJ(PNO, PNAME, BUDGET) ASG(ENO, PNO, RESP, DUR)
Predefined constraints are based on simple keywords. Through them, it is possible to express concisely the more common constraints of the relational model, such as nonnull attribute, unique key, foreign key, or functional dependency. Employee number in relation EMP cannot be null.
ENO NOT NULL IN EMP The project number PNO in relation ASG is a foreign key matching the primary key PNO of relation PROJ.
PNO IN ASG REFERENCES PNO IN PROJ
Precondition constraints express conditions that must be satisfied by all tuples in a relation for a given update type. The update type, which might be INSERT, DELETE, or MODIFY, permits restricting the integrity control. Precondition constraints can be expressed with the SQL CHECK statement enriched with the ability to specify the update type.
CHECK ON <relation name > WHEN <update type>(<qualification over relation name>)
The budget of a project is between 500K and 1000K. CHECK ON PROJ (BUDGET+ >= 500000 AND BUDGET <= 1000000)
Only the tuples whose budget is 0 may be deleted. CHECK ON PROJ WHEN DELETE (BUDGET = 0)
General constraints are formulas of tuple relational calculus where all variables are quantified. The database system must ensure that those formulas are alway
CHECK ON list of <variable name>:<relation name>,(<qualification>)The total duration for all employees in the CAD project is less than 100.CHECK ON g:ASG, j:PROJ (SUM(g.DUR WHERE g.PNO=j.PNO)<100 IF j.PNAME="CAD/CAM")
Distributed Semantic Integrity Control
Definition of Distributed Integrity Constraints Assertions can involve data stored at different sites, the storage of the constraints must be decided so as to minimize the cost of integrity checking. There is a strategy based
integrity constraints that distinguishes three classes:Individual constraints: single-relation single-variable constraints. They refer only to tuples to be updated independently of the rest of the database.
oriented constraints: include single-relation multivariable constraints such as
083
predefined,
are based on simple keywords. Through them, it is possible to express concisely the more common constraints of the relational model, such as non-
The project number PNO in relation ASG is a foreign key matching the primary key
express conditions that must be satisfied by all tuples in a relation for a given update type. The update type, which might be INSERT, DELETE,
SQL CHECK statement enriched
CHECK ON <relation name > WHEN <update type>
00000)
are formulas of tuple relational calculus where all variables are quantified. The database system must ensure that those formulas are always true.
CHECK ON list of <variable name>:<relation name>,(<qualification>) The total duration for all employees in the CAD project is less than 100. CHECK ON g:ASG, j:PROJ (SUM(g.DUR WHERE g.PNO=j.PNO)<100 IF
Assertions can involve data stored at different sites, the storage of the constraints must be decided so as to minimize the cost of integrity checking. There is a strategy based
integrity constraints that distinguishes three classes: variable constraints. They refer only to
n multivariable constraints such as

Faculty of Degree Engineering
Department of CE/IT (07/
functional dependency and multirelation multivariable constraints such as foreign key constraints
• Constraints involving aggregatesevaluating the aggregates.
Individual constraints• Consider relation EMP, horizontally fragmented across three sites using the predicates
and the domain constraint C: ENO < “E4”.� p1 : 0 ENO < “E3”� p2 : ”E3” ENO “E6”� p3 : ENO > “E6” • Constraint C is compatible with p1 (if C i
not necessarily false), but not with p3 (if C is true, then p3 is false). Therefore, constraint C should be globally rejected because the tuples at site 3 cannot satisfy C, and thus relation EMP does not sati
Set-oriented constraints• Set-oriented constraint are multivariable; that is, they involve join predicates.• Three cases, given in increasing cost of checking, can occur:1. The fragmentation of R is derived from that of S based on a semi join on t
used in the assertion join predicate.2. S is fragmented on join attribute.3. S is not fragmented on join attribute. • In the first case, compatibility checking is cheap since the tuple of S matching a tuple
of R is at the same site.• In the second case, each tuple of R must be compared with at most one fragment of S,
because the join attribute value of the tuple of R can be used to find the site of the corresponding fragment of S.
• In the third case, each tuple of R must be compared with all fcompatibility is found for all tuples of R, the constraint can be stored at each site.
Constraints involving aggregates• These constraints are among the most costly to test because they require the calculation
of the aggregate functions• The aggregate functions generally manipulated are MIN, MAX, SUM, and COUNT.• Each aggregate function contains a projection part and a selection part.
Q.5 (A) Explain Query Processing in Distributed Systems.
A.5 (A) Query Processing in Distributed Systems • In a distributed DBMS the catalog has to store additional i
location of relations and their replicas. The catalog must also include system wise information such as the number of site in the system along with their identifiers'.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
functional dependency and multirelation multivariable constraints such as foreign key
Constraints involving aggregates: require special processing because of the cost of evaluating the aggregates.
Individual constraints Consider relation EMP, horizontally fragmented across three sites using the predicatesand the domain constraint C: ENO < “E4”. p1 : 0 ENO < “E3” p2 : ”E3” ENO “E6”
Constraint C is compatible with p1 (if C is true, p1 is true) and p2 (if C is true, p2 is not necessarily false), but not with p3 (if C is true, then p3 is false). Therefore, constraint C should be globally rejected because the tuples at site 3 cannot satisfy C, and thus relation EMP does not satisfy C.
oriented constraints oriented constraint are multivariable; that is, they involve join predicates.
Three cases, given in increasing cost of checking, can occur: The fragmentation of R is derived from that of S based on a semi join on tused in the assertion join predicate. S is fragmented on join attribute. S is not fragmented on join attribute. In the first case, compatibility checking is cheap since the tuple of S matching a tuple of R is at the same site.
cond case, each tuple of R must be compared with at most one fragment of S, because the join attribute value of the tuple of R can be used to find the site of the corresponding fragment of S. In the third case, each tuple of R must be compared with all fragments of S. If compatibility is found for all tuples of R, the constraint can be stored at each site.
Constraints involving aggregates These constraints are among the most costly to test because they require the calculation of the aggregate functions. The aggregate functions generally manipulated are MIN, MAX, SUM, and COUNT.Each aggregate function contains a projection part and a selection part.
Query Processing in Distributed Systems. Query Processing in Distributed Systems
In a distributed DBMS the catalog has to store additional information including the location of relations and their replicas. The catalog must also include system wise information such as the number of site in the system along with their identifiers'.
083
functional dependency and multirelation multivariable constraints such as foreign key
: require special processing because of the cost of
Consider relation EMP, horizontally fragmented across three sites using the predicates
s true, p1 is true) and p2 (if C is true, p2 is not necessarily false), but not with p3 (if C is true, then p3 is false). Therefore, constraint C should be globally rejected because the tuples at site 3 cannot satisfy C,
oriented constraint are multivariable; that is, they involve join predicates.
The fragmentation of R is derived from that of S based on a semi join on the attribute
In the first case, compatibility checking is cheap since the tuple of S matching a tuple
cond case, each tuple of R must be compared with at most one fragment of S, because the join attribute value of the tuple of R can be used to find the site of the
ragments of S. If compatibility is found for all tuples of R, the constraint can be stored at each site.
These constraints are among the most costly to test because they require the calculation
The aggregate functions generally manipulated are MIN, MAX, SUM, and COUNT. Each aggregate function contains a projection part and a selection part.
07
nformation including the location of relations and their replicas. The catalog must also include system wise information such as the number of site in the system along with their identifiers'.

Faculty of Degree Engineering
Department of CE/IT (07/
Mapping Global Query to Local• The tables required in a glob
sites. The local databases have information only about local data. The controlling site uses the global data dictionary to gather information about the distribution and reconstructs the global view from t
• If there is no replication, the global optimizer runs local queries at the sites where the fragments are stored. If there is replication, the global optimizer selects the site based upon communication cost, workload, and server speed.
• The global optimizer generates a distributed execution plan so that least amount of data transfer occurs across the sites. The plan states the location of the fragments, order in which query steps needs to be executed and the processes involved in transferring intermediate results.
• The local queries are optimized by the local database servers. Finally, the local query results are merged together through union operation in case of horizontal fragments and join operation for vertical fragments.
Example • For example, let us consider that the following Project schema is horizontally
fragmented according to City, the cities being New Delhi, Kolkata and Hyderabad.• PROJECT
• Suppose there is a query to retrieve details of all projects whose status is
“Ongoing”. • The global query will be
• Query in New Delhi’s server will be
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Mapping Global Query to Local
The tables required in a global query have fragments distributed across multiple sites. The local databases have information only about local data. The controlling site uses the global data dictionary to gather information about the distribution and reconstructs the global view from the fragments. If there is no replication, the global optimizer runs local queries at the sites where the fragments are stored. If there is replication, the global optimizer selects the site based upon communication cost, workload, and server speed.
lobal optimizer generates a distributed execution plan so that least amount of data transfer occurs across the sites. The plan states the location of the fragments, order in which query steps needs to be executed and the processes involved in
intermediate results. The local queries are optimized by the local database servers. Finally, the local query results are merged together through union operation in case of horizontal fragments and join operation for vertical fragments.
mple, let us consider that the following Project schema is horizontally fragmented according to City, the cities being New Delhi, Kolkata and Hyderabad.
Suppose there is a query to retrieve details of all projects whose status is
global query will be σstatus=" ongoing"( PROJECT)
Query in New Delhi’s server will be σstatus=" ongoing"( NewD−PROJECT)
083
al query have fragments distributed across multiple sites. The local databases have information only about local data. The controlling site uses the global data dictionary to gather information about the distribution and
If there is no replication, the global optimizer runs local queries at the sites where the fragments are stored. If there is replication, the global optimizer selects the site
lobal optimizer generates a distributed execution plan so that least amount of data transfer occurs across the sites. The plan states the location of the fragments, order in which query steps needs to be executed and the processes involved in
The local queries are optimized by the local database servers. Finally, the local query results are merged together through union operation in case of horizontal
mple, let us consider that the following Project schema is horizontally fragmented according to City, the cities being New Delhi, Kolkata and Hyderabad.
Suppose there is a query to retrieve details of all projects whose status is

Faculty of Degree Engineering
Department of CE/IT (07/
• Query in Kolkata’s server will be
• Query in Hyderabad’s server will be
• In order to get the overall result, we need to union the results of the three queries as follows
σstatus=" ongoing"( NewD
Q (B) Explain Deadlock in Distributed SystemsA (B) Deadlock
• A deadlock can occur because transactions wait for one another. Informally, a
deadlock situation is a set of requests that can never be granted by the concurrency control mechanism.
• A deadlock can be indicated by a cycle in the • In computer science,
processes are each waiting for another to release a resource, or more than two processes are waiting for resources in a circular chain.
Deadlock Detection • Deadlock detection
identifying the processes and resources involved in the • Detection of a cycle in WFG proceeds concurrently with normal operation in main
of deadlock detectionDeadlock Prevention• The deadlock prevention approach does not allow any transaction to acquire locks
that will lead to deadlocks. The convention is that when more than one transactions request for locking the same data item, only one of them is grante
• One of the most popular deadlock prevention methods is prelocks.
Deadlock Avoidance • The deadlock avoidance approach handles deadlocks before they occur. It analyzes
the transactions and the locks to determine whetherdeadlock.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Query in Kolkata’s server will be σstatus=" ongoing"( Kol−PROJECT)
Query in Hyderabad’s server will be σstatus=" ongoing"( Hyd−PROJECT)
In order to get the overall result, we need to union the results of the three queries as
NewD−PROJECT)∪σstatus=" ongoing"( kol−us=" ongoing"( Hyd−PROJECT)
Deadlock in Distributed Systems.
A deadlock can occur because transactions wait for one another. Informally, a deadlock situation is a set of requests that can never be granted by the concurrency control mechanism. A deadlock can be indicated by a cycle in the wait-for-graph (WFG)In computer science, deadlock refers to a specific condition when two or more processes are each waiting for another to release a resource, or more than two processes are waiting for resources in a circular chain.
Deadlock detection is the process of actually determining that a identifying the processes and resources involved in the deadlock.Detection of a cycle in WFG proceeds concurrently with normal operation in main of deadlock detection.
Deadlock Prevention The deadlock prevention approach does not allow any transaction to acquire locks that will lead to deadlocks. The convention is that when more than one transactions request for locking the same data item, only one of them is granteOne of the most popular deadlock prevention methods is pre-acquisition of all the
The deadlock avoidance approach handles deadlocks before they occur. It analyzes the transactions and the locks to determine whether or not waiting leads to a
083
In order to get the overall result, we need to union the results of the three queries as
kol−PROJECT)∪σstat
07
A deadlock can occur because transactions wait for one another. Informally, a deadlock situation is a set of requests that can never be granted by the concurrency
graph (WFG). refers to a specific condition when two or more
processes are each waiting for another to release a resource, or more than two
is the process of actually determining that a deadlock exists and deadlock.
Detection of a cycle in WFG proceeds concurrently with normal operation in main
The deadlock prevention approach does not allow any transaction to acquire locks that will lead to deadlocks. The convention is that when more than one transactions request for locking the same data item, only one of them is granted the lock.
acquisition of all the
The deadlock avoidance approach handles deadlocks before they occur. It analyzes or not waiting leads to a

Faculty of Degree Engineering
Department of CE/IT (07/
• There are two algorithms for this purpose, namely • Let us assume that there are two transactions, T1 and T2, where T1 tries to lock a
data item which is already locked by T2. The algorithms are as follows • Wait-Die − If T1 is older than T2, T1 is allowed to wait. Otherwise, if T1 is
younger than T2, T1 is aborted and later restarted.• Wound-Wait − If T1 is older than T2, T2 is aborted and later restar
if T1 is younger than T2, T1 is allowed to wait.
Q.5 (A) What is authorization control? How do imply authorization control in a distributed environment?
A.5 (A) Authorization control • Authorization control consists of checking whether a given triple (subject, operation,
object) can be allowed to proceed.• The introduction of a subject in the system
password). • The objects to protect are subsets of the database. Relational systems provide finer and
more general protection granularity than do earlier systems.• A right expresses a relationship between a subject and an object for a particular set of
operations. GRANT <operation type(s)> ON <object> TO <subject(s)>
REVOKE <operation type(s)> FROM <object> TO <subject(s)>
Multilevel Access Control• Discretionary access control has some limitations. One problem is that a malicious user
can access unauthorized data through an authorized user.• For instance, consider user A who has authorized access to relations R and S and user
B who has authorized accapplication program used by A so it writes R data into S, then B can read unauthorized data without violating authorization rules.
• Multilevel access control answers this problem and further improvedefining different security levels for both subjects and data objects.• process has a security level also called clearance derived from that of the user.• In its simplest form, the security levels are Top Secret (TS), Secret (S),
Confidential (C) and Unclassified (U), and ordered as TS > S >C >U, where “>” means “more secure”.
• Access in read and write modes by subjects is restricted by two simple rules:Rule 1 (called “no read up”)
• protects data from unauthorized disclosure, i.e., a subjectcan only read objects at the same or lower security levels.
Rule 2 (called “no write down”)• protects data from unauthorized change, i.e., a subject at a given security level can
only write objects at the same or higher security
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
There are two algorithms for this purpose, namely wait-die and Let us assume that there are two transactions, T1 and T2, where T1 tries to lock a
is already locked by T2. The algorithms are as follows − If T1 is older than T2, T1 is allowed to wait. Otherwise, if T1 is
younger than T2, T1 is aborted and later restarted. − If T1 is older than T2, T2 is aborted and later restar
if T1 is younger than T2, T1 is allowed to wait. OR
What is authorization control? How do imply authorization control in a distributed
Authorization control
Authorization control consists of checking whether a given triple (subject, operation, object) can be allowed to proceed. The introduction of a subject in the system is typically done by a pair (user name,
The objects to protect are subsets of the database. Relational systems provide finer and more general protection granularity than do earlier systems. A right expresses a relationship between a subject and an object for a particular set of
GRANT <operation type(s)> ON <object> TO <subject(s)>REVOKE <operation type(s)> FROM <object> TO <subject(s)>
Multilevel Access Control
Discretionary access control has some limitations. One problem is that a malicious user can access unauthorized data through an authorized user. For instance, consider user A who has authorized access to relations R and S and user B who has authorized access to relation S only. If B somehow manages to modify an application program used by A so it writes R data into S, then B can read unauthorized data without violating authorization rules. Multilevel access control answers this problem and further improvedefining different security levels for both subjects and data objects.
process has a security level also called clearance derived from that of the user.In its simplest form, the security levels are Top Secret (TS), Secret (S),
l (C) and Unclassified (U), and ordered as TS > S >C >U, where “>” means “more secure”. Access in read and write modes by subjects is restricted by two simple rules:
Rule 1 (called “no read up”) protects data from unauthorized disclosure, i.e., a subject at a given security level can only read objects at the same or lower security levels.
Rule 2 (called “no write down”) protects data from unauthorized change, i.e., a subject at a given security level can only write objects at the same or higher security levels.
083
and wound-wait. Let us assume that there are two transactions, T1 and T2, where T1 tries to lock a
is already locked by T2. The algorithms are as follows − − If T1 is older than T2, T1 is allowed to wait. Otherwise, if T1 is
− If T1 is older than T2, T2 is aborted and later restarted. Otherwise,
What is authorization control? How do imply authorization control in a distributed 07
Authorization control consists of checking whether a given triple (subject, operation,
is typically done by a pair (user name,
The objects to protect are subsets of the database. Relational systems provide finer and
A right expresses a relationship between a subject and an object for a particular set of
GRANT <operation type(s)> ON <object> TO <subject(s)> REVOKE <operation type(s)> FROM <object> TO <subject(s)>
Discretionary access control has some limitations. One problem is that a malicious user
For instance, consider user A who has authorized access to relations R and S and user ess to relation S only. If B somehow manages to modify an
application program used by A so it writes R data into S, then B can read unauthorized
Multilevel access control answers this problem and further improves security by defining different security levels for both subjects and data objects.
process has a security level also called clearance derived from that of the user. In its simplest form, the security levels are Top Secret (TS), Secret (S),
l (C) and Unclassified (U), and ordered as TS > S >C >U, where
Access in read and write modes by subjects is restricted by two simple rules:
at a given security level
protects data from unauthorized change, i.e., a subject at a given security level can

Faculty of Degree Engineering
Department of CE/IT (07/
Distributed Access Control• The additional problems of access control in a distributed environment stem from the
fact that objects and subjects are distributed and that messages with sensitive data can be read by unauthorized users.
• These problems are: remote user authentication, management of discretionary access rules, handling of views and of user groups, and enforcing multilevel access control.
• Remote user authentication is necessary since any site of a distributed DBMS may accept programs initiated, and authorized, at remote sites.
• Three solutions are possible for managing authentication1. Authentication information is maintained at a central site for global users which can
then be authenticated only once and then 2. The information for authenticating users (user name and password) is replicated at all
sites in the catalog. 3. Intersite communication is thus protected by the use of the site password. Once the
initiating site has been authusers.
Q (B) Write a short note on Query OptiA (B) Query optimization refers to the process of producing a query execution plan
represents an execution strategy for the query. This QEP minimizesA query optimizer, the software module that performsconsisting of three components: a search space,search space is the set ofplans are equivalent, in the sense that they yield the same result, but they differ in the execution order of operations and the way these operations are implemented, and therefore in their performance. The cost model predicts must have good knowledge about the distributed execution environment. The explores the search space and selects the best plan, using the cost model. It defines whichplans are examined and indistributed) are captured by the search space and the cost model.
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Distributed Access Control The additional problems of access control in a distributed environment stem from the fact that objects and subjects are distributed and that messages with sensitive data can be read by unauthorized users.
ms are: remote user authentication, management of discretionary access rules, handling of views and of user groups, and enforcing multilevel access control.Remote user authentication is necessary since any site of a distributed DBMS may
nitiated, and authorized, at remote sites. Three solutions are possible for managing authentication Authentication information is maintained at a central site for global users which can then be authenticated only once and then accessed from multiple sites.The information for authenticating users (user name and password) is replicated at all
Intersite communication is thus protected by the use of the site password. Once the initiating site has been authenticated, there is no need for authenticating their remote
Query Optimization. Query optimization refers to the process of producing a query execution planrepresents an execution strategy for the query. This QEP minimizes an objective cost function.
ery optimizer, the software module that performs query optimization, is usually seen as consisting of three components: a search space, a cost model, and a search
is the set of alternative execution plans that represent the input qin the sense that they yield the same result, but they differ in the
of operations and the way these operations are implemented, and therefore in
the cost of a given execution plan. To be accurate, the cost model knowledge about the distributed execution environment. The
the search space and selects the best plan, using the cost model. It defines whichplans are examined and in which order. The details of the environment (centralizeddistributed) are captured by the search space and the cost model.
083
The additional problems of access control in a distributed environment stem from the fact that objects and subjects are distributed and that messages with sensitive data can
ms are: remote user authentication, management of discretionary access rules, handling of views and of user groups, and enforcing multilevel access control. Remote user authentication is necessary since any site of a distributed DBMS may
Authentication information is maintained at a central site for global users which can accessed from multiple sites.
The information for authenticating users (user name and password) is replicated at all
Intersite communication is thus protected by the use of the site password. Once the enticated, there is no need for authenticating their remote
07 Query optimization refers to the process of producing a query execution plan (QEP) which
an objective cost function. query optimization, is usually seen as
a cost model, and a search strategy. The alternative execution plans that represent the input query. These
in the sense that they yield the same result, but they differ in the of operations and the way these operations are implemented, and therefore in
n execution plan. To be accurate, the cost model knowledge about the distributed execution environment. The search strategy
the search space and selects the best plan, using the cost model. It defines which which order. The details of the environment (centralized versus

Faculty of Degree Engineering
Department of CE/IT (07/
1 Search Space Query execution plans are typically abstracted by means of operator treesorder in which the operations are executed. They are enrichedsuch as the best algorithm chosen for each operation.thus be defined as the set of equivalenttransformation rules. To characterize querywhich are operator trees whosepermutations of the join orderqueries. 2 Search Strategy
The most popular search strategy used by query optimizers is deterministic. Deterministic strategies proceed by joining one more relation at each step until complete plans areprogramming builds all possible plans, reduce the optimization cost, partial planspruned (i.e., discarded) as soon asgreedy algorithm, builds
3 Distributed Cost Model An optimizer’s cost model includes cost functions to predict the cost of operators,base data, and formulas to evaluate the sizes of intermediate resultexecution time, so a cost function represents the execution
Faculty of Degree Engineering - 083
Department of CE/IT (07/16)
Query execution plans are typically abstracted by means of operator treesorder in which the operations are executed. They are enriched with additional information, such as the best algorithm chosen for each operation. For a given query, the search space can thus be defined as the set of equivalent operator trees that can be produced using transformation rules. To characterize query optimizers, it is useful to concentrate on which are operator trees whose operators are join or Cartesian product. Thipermutations of the join order have the most important effect on performance of relational
The most popular search strategy used by query optimizers is dynamic programmingDeterministic strategies proceed by building plans, starting
joining one more relation at each step until complete plans are obtained, as in Figureprogramming builds all possible plans, breadth first, before it chooses the “best” plan. To reduce the optimization cost, partial plans that are not likely to lead to the optimal plan are
(i.e., discarded) as soon as possible. By contrast, another deterministic strategy, the only one plan, depth-first.
3 Distributed Cost Model
An optimizer’s cost model includes cost functions to predict the cost of operators,base data, and formulas to evaluate the sizes of intermediate results. The cost is in terms of execution time, so a cost function represents the execution time of a query.
*****Best of Luck*****
083
Query execution plans are typically abstracted by means of operator trees , which define the with additional information,
For a given query, the search space can operator trees that can be produced using
optimizers, it is useful to concentrate on join trees, operators are join or Cartesian product. This is because
have the most important effect on performance of relational
dynamic programming, which is from base relations,
obtained, as in Figure. Dynamic before it chooses the “best” plan. To
that are not likely to lead to the optimal plan are possible. By contrast, another deterministic strategy, the
An optimizer’s cost model includes cost functions to predict the cost of operators, statistics and The cost is in terms of
time of a query.