deep dive into spark streaming
TRANSCRIPT

NRT: Deep Dive into Spark Streaming

Agenda
Spark Streaming Introduction Computing Model in Spark Streaming
System Model & Architecture
Fault-tolerance, Check pointing
Comb on Spark Streaming

What is Spark Streaming?
• Extends Spark for doing large scale stream processing
• Efficient and fault-tolerant stateful stream processing
• Provides a simple batch-like API for implementing complex algorithms
Spark
Spark SQL
Spark Streaming
GraphX MLLib …

Why Spark Streaming
• Scales to hundreds of nodes
• Achieves low latency
• Efficiently recover from failures
• Integrates with batch and interactive processing

Spark Streaming
Run a streaming computation as a series of very small, deterministic batch jobs
Spark
SparkStreaming
batches of X seconds
live data stream
processed results
Chop up the live stream into batches of X seconds (Batch Size as low as 0.5 Second, Latency is about 1 second)
Spark treats each batch of data as RDDs and processes them using RDD operations
Finally, the processed results of the RDD operations are returned in batches

Agenda
Spark Streaming Introduction
Computing Model in Spark Streaming System Model & Architecture
Fault-tolerance, Check pointing
Comb on Spark Streaming

Spark Computing Model
• Discretized Stream (DStream)Represents a stream of data
Implemented as a sequence of RDDs
• DStreams can be either …Created from Streaming input sources
Created by applying transformations on existing DStreams

Spark Streaming - Key Concepts
DStream – sequence of RDDs representing a stream of data
- Twitter, HDFS, Kafka, Flume, ZeroMQ, Akka Actor, TCP sockets
Transformations – modify data from one DStream to another
- Standard RDD operations – map, countByValue, reduceByKey, join, …
- Stateful operations – window, countByValueAndWindow, …
Output Operations – send data to external entity
- saveAsHadoopFiles – saves to HDFS
- foreach – do anything with each batch of results

Example 1 – Get hashtags from Twitter
val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)
DStream: a sequence of distributed datasets (RDDs) representing a distributed stream of data
batch @ t+1batch @ t batch @ t+2
tweets DStream
stored in memory as an RDD (immutable, distributed dataset)
Twitter Streaming API

Example 1 – Get hashtags from Twitter
val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)
val hashTags = tweets.flatMap (status => getTags(status))
flatMap flatMap flatMap
…
transformation: modify data in one DStream to create another DStream
new DStream
new RDDs created for every batch
batch @ t+1batch @ t batch @ t+2
tweets DStream
hashTags Dstream[#cat, #dog, … ]

Example 1 – Get hashtags from Twitter
val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)
val hashTags = tweets.flatMap (status => getTags(status))
hashTags.saveAsHadoopFiles("hdfs://...")
output operation: to push data to external storage
flatMap flatMap flatMap
save save save
batch @ t+1batch @ t batch @ t+2
tweets DStream
hashTags DStream
every batch saved to HDFS

DStream of data
Example 2 – Count the hashtags over last 1 min
val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)
val hashTags = tweets.flatMap (status => getTags(status))
val tagCounts = hashTags.window(Minutes(1), Seconds(1)).countByValue()
sliding window operation
window length sliding interval
window length
sliding interval

tagCounts
Example 2 – Count the hashtags over last 1 min
val tagCounts = hashTags.window(Minutes(1), Seconds(1)).countByValue()
hashTags
t-1 t t+1 t+2 t+3
sliding window
countByValue
count over all the data in the
window

Example 3 - Arbitrary Stateful Computations
Maintain arbitrary state, track sessions
- Maintain per-user mood as state, and update it with his/her tweets
moods = tweets.updateStateByKey(tweet => updateMood(tweet))
updateMood(newTweets, lastMood) => newMood
tweets
t-1 t t+1 t+2 t+3
moods

Example 4 - Combine Batch and Stream Processing
Do arbitrary Spark RDD computation within DStream
- Join incoming tweets with a spam file to filter out bad tweets
tweets.transform(tweetsRDD => {
tweetsRDD.join(spamHDFSFile).filter(...)
})
•Combine Live data Streams with Historical data
•Combine Streaming with MLLib, GraphX algos
•Query Streaming data using SQL

Agenda
Spark Streaming Introduction
Computing Model in Spark Streaming
System Model & Architecture Fault-tolerance, Check pointing
Comb on Spark Streaming

System - Components
• Network Input Tracker – Keeps track of the data received by each network receiver and maps them to the corresponding input DStreams
• Job Scheduler – Periodically queries the DStream graph to generate Spark jobs from received data, and hands them to Job Manager for execution
• Job Manager – Maintains a job queue and executes the jobs in Spark
ssc = new StreamingContext
t = ssc.twitterStream(“…”)
t.filter(…).foreach(…)
Your program
DStream graph
Spark Context
Network Input Tracker
Job Manager
Job Scheduler
Spark Client
RDD graph Scheduler
Block manager Shuffle tracker
Spark Worker
Block manager
Task threads
Cluster Manager
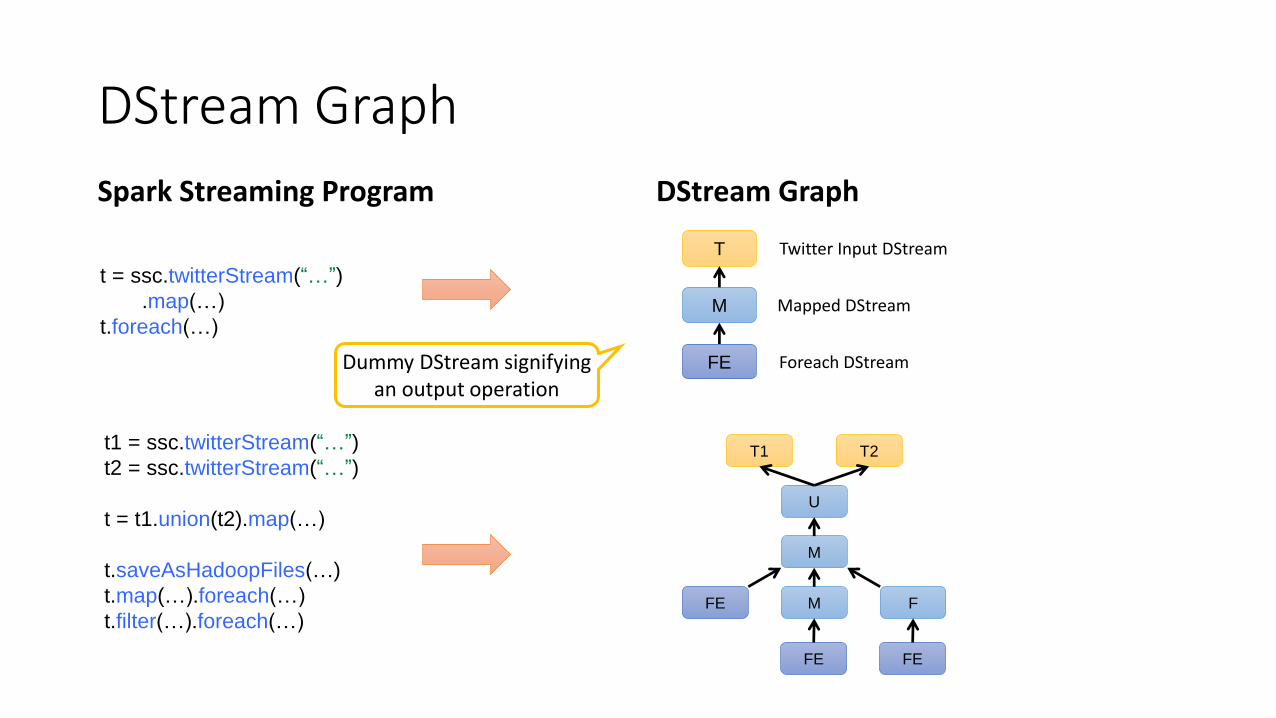
DStream Graph
Spark Streaming Program DStream Graph
t = ssc.twitterStream(“…”)
.map(…)
t.foreach(…)
t1 = ssc.twitterStream(“…”)
t2 = ssc.twitterStream(“…”)
t = t1.union(t2).map(…)
t.saveAsHadoopFiles(…)
t.map(…).foreach(…)
t.filter(…).foreach(…)
T
M
FE
Twitter Input DStream
Mapped DStream
Foreach DStream
T1
U
M
T2
M FFE
FE FE
Dummy DStream signifying an output operation

DStream Graph -> RDD Graphs -> Spark Jobs• Every interval, RDD graph is computed from DStream graph
• For each output operation, a Spark action is created
• For each action, a Spark job is created to compute it
T
U
M
T
M FFE
FE FE
DStream Graph
B
U
M
B
M FA
A A
RDD Graph
Spark actions
Block RDDs with data received in last batch interval
3 Spark jobs

Execution Model – Receiving Data
Spark Streaming + Driver Spark Workers
StreamingContext.start()
Network
Input
Tracker
Receiver
Data Received
Block Manager
Blocks replicated
Block Manager
Master
Block
Manager
Blocks pushed
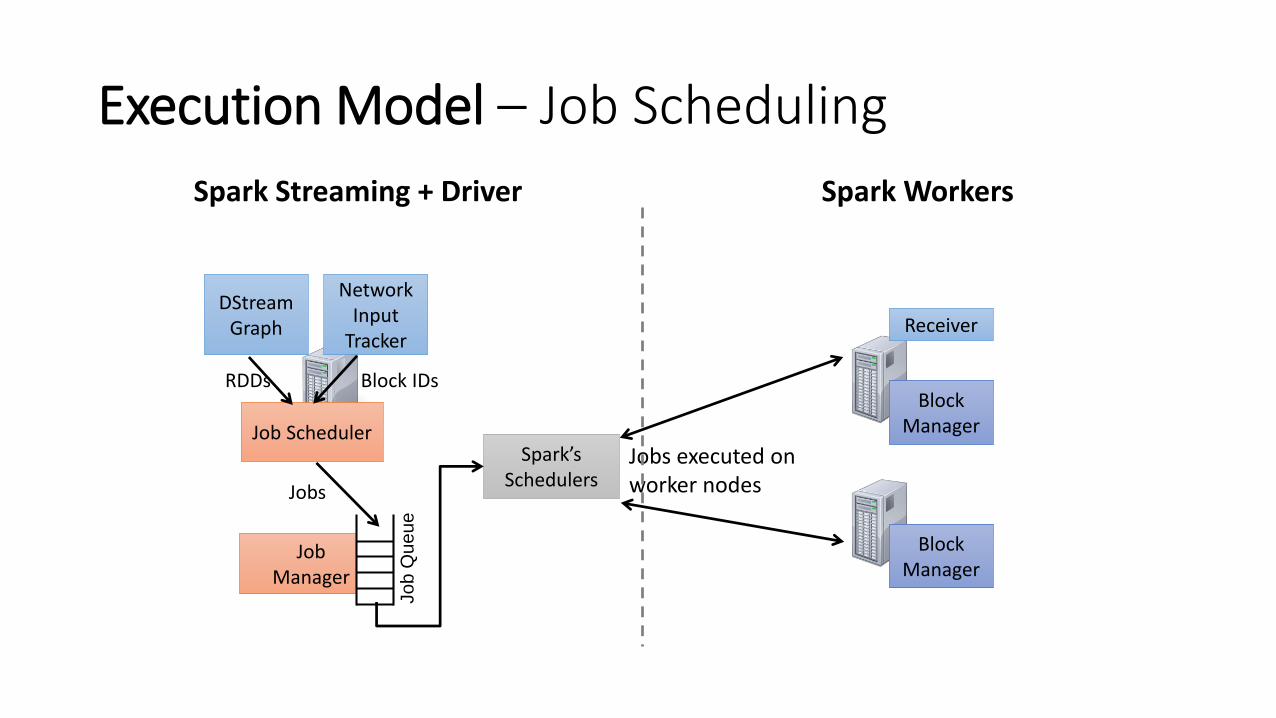
Execution Model – Job Scheduling
Spark Streaming + Driver Spark Workers
Network Input
Tracker
Job SchedulerSpark’s
Schedulers
Receiver
Block Manager
Block Manager
Jobs executed on worker nodes
DStream Graph
Job Manager
Jo
b Q
ueue
Jobs
Block IDsRDDs

Agenda
Spark Streaming Introduction
Computing Model in Spark Streaming
System Model & Architecture
Fault-tolerance, Check pointing Comb on Spark Streaming

Fault-tolerance: Worker
• RDDs remember the operations that created them
• Batches of input data are replicated in memory for fault-tolerance
• Data lost due to worker failure, can be recomputed from replicated input data
• All transformed data is fault-tolerant, and exactly-once transformations
input data
replicated
in memory
flatMap
lost partitions
recomputed
on other
workers
tweetsRDD
hashTagsRDD

Fault-tolerance: Driver
• Master saves the state of the DStreams to a checkpoint file• Checkpoint file saved to HDFS periodically
• If master fails, it can be restarted using the checkpoint file
• Automated master fault recovery

Check Pointing - RDDSaving RDD to HDFS to prevent RDD graph from growing too large
Done internally in Spark transparent to the user program
Done lazily, saved to HDFS the first time it is computed
red_rdd.checkpoint()
HDFS file
Contents of red_rdd saved to a HDFS file
transparent to all child RDDs

Why is RDD checkpointing necessary?
Stateful DStream operators can have infinite lineages
Large lineages lead to …
Large closure of the RDD object large task sizes high task launch times
High recovery times under failure
data
t-1 t t+1 t+2 t+3
states

Check Pointing - MetadataSaving of the information defining the streaming computation to fault-tolerant storage like HDFS. Metadata includes:
Configuration - The configuration that were used to create the streaming application.
DStream operations - The set of DStream operations that define the streaming application.
Incomplete batches - Batches whose jobs are queued but have not completed yet.
This is used to recover from failure of the node running the driver of the streaming application

Agenda
Spark Streaming Introduction
Computing Model in Spark Streaming
System Model & Architecture
Fault-tolerance, Check pointing
Comb on Spark Streaming

Data Processing – Window Operation
• Window based Computing• countByWindow
• reduceByKeyAndWindow
• Scenarios• App Metrics in time Window
• Cache/Persist events in time Window
• Notes:• Checkpoint
• Performance tuning
val eventCount = inputs.countByWindow(Seconds(30), Seconds(10))eventCount.print()
val idCount=lines.map(x=>(parser(x),1)).reduceByKey(_+_)val idWindowCount=idCount.reduceByKeyAndWindow(
(a:Int,b:Int)=>(a+b),Seconds(30),Seconds(10))idWindowCount.print()

Data Processing – Session Operation
• Sessionization: updateStateByKeyval events =inputs.map[(String, (Long, String))](event => {
val eventObj = event.getBondValue()val id = eventObj.getAppInfo().getId()val eventName = eventObj.getEventInfo.getName()
val time = System.currentTimeMillis()
(eventName, (time, id))})val latestSessions = events.map[(String, (Long, Long, Long))](imp => {
(imp._1, (imp._2._1, imp._2._1, 1))})
.reduceByKey((imp1, imp2) => {(Math.min(imp1._1, imp2._1), Math.max(imp1._2, imp2._2), imp1._3 + imp2._3)
}).updateStateByKey(SessionObject.updateStatbyOfSessions)
1
1
2
How to Update Session Status?

def updateStatbyOfSessions(newBatch: Seq[(Long, Long, Long)], session: Option[(Long, Long, Long)]): Option[(Long, Long, Long)] = {
var result: Option[(Long, Long, Long)] = null
if (newBatch.isEmpty) {if (System.currentTimeMillis() - session.get._2 > SESSION_TIMEOUT) {result = None
} else {result =session
}}
newBatch.foreach(c => {if (session.isEmpty || c._1 - session.get._2 > SESSION_TIMEOUT) {
result = Some(c)} else {result = Some((
Math.min(c._1, session.get._1), //newStartTimeMath.max(c._2, session.get._2), //newFinishTimesession.get._3 + c._3 //newSumOfPageView))
}})
result}
Create New Session• Previous Session is empty
OR• Previous Session Timeout,
With new batches
Extend Going on Sessions• Previous Session not emptyAND• New Batch is not timed out to
previous Session
Retire Timed out Session• Previous session is timed out

QA