deployment of simulation (trends and issues impacting it)...•a combination of serial-io...
TRANSCRIPT

© 2011 ANSYS, Inc. September 7, 20111
Deployment of Simulation (Trends and Issues Impacting IT)
– Discussion
Mapping HPC to Performance (Scaling, Technology Advances)
– Discussion
Optimizing IT for Remote Access (Private / Public Cloud Computing)
– Discussion
Break
Let’s Talk about Hardware (Specifying HW for ANSYS)
– Discussion
ANSYS Roadmap (Toward aligned IT Planning)
Tomorrow
1:1 Meeting Time
HPC and IT Issues
Session Agenda

© 2011 ANSYS, Inc. September 7, 20112
Mapping HPC to ANSYS PerformanceTechnology for Simulation Excellence
Barbara [email protected]

© 2011 ANSYS, Inc. September 7, 20113
2001 - 2003►Parallel dynamic moving/deforming mesh►Distributed memory particle tracking
ANSYS HPC Leadership
A History of HPC Performance
1980
1990
2010
1990► Shared Memory Multiprocessing for structural simulations
1994►Iterative PCG Solver Introduced for large structural analysis
1999 - 2000►64bit large memory addressing►Shared memory multiprocessing (HFSS 7)
► 15 % spent on R&D
► 570 software developers
► Partner relationships
2004►1st company to solve 100M structural DOF
2007 - 2008► Optimized performance on multicore
processors►1st One Billion cell fluids simulation
2009►Ideal scaling to 2048 cores (fluids)►Teraflop performance at 512 core (structures)►Parallel I/O (fluids)►Domain Decomposition introduced (HFSS 12)
1998-1999►Integration with load management systems►Support for Linux clusters, low latency interconnects►10M cell fluids simulations, 128 processors
2005 - 2006►Parallel meshing (fluids)►Support for clusters using Windows HPC
© 2008 ANSYS, Inc. All rights reserved. ANSYS, Inc. Proprietary
1980’s► Vector Processing on Mainframes
1993►1st general-purpose parallel CFD with
interactive client-server user environment
1994 - 1995►Parallel dynamic mesh refinement and coarsening►Dynamic load balancing
2005 -2007►Distributed sparse solver►Distributed PCG solver►Variational Technology►DANSYS released►Distributed Solve (DSO) HFSS 10
2000
Today’s multi-core / many-core hardware evolution makes HPC a software development imperative. ANSYS is committed to maintaining performance
leadership.
2010► Hybrid parallel for sustained multi-
core performance (fluids)►GPU acceleration (structures)

© 2011 ANSYS, Inc. September 7, 20114
HPC – A Software Development Imperative
• Clock Speed – Leveling off
• Core Counts – Growing• Exploding (GPUs)
• Future performance depends on highly scalable parallel software
Source: http://www.lanl.gov/news/index.php/fuseaction/1663.article/d/20085/id/13277

© 2011 ANSYS, Inc. September 7, 20115
0
200
400
600
800
1000
1200
1400
0 256 512 768 1024 1280 1536
RA
TIN
GNumber of Cores
2010 Hardware(Intel Westmere, QDR IB)
12.1.0
13.0.0
IDEAL
0
50
100
150
200
250
300
350
400
450
0 200 400 600 800 1000 1200
RA
TIN
G
Number of Cores
2008 Hardware (Intel Harpertown, DDR IB)
6.3.35
12.0.5
IDEAL
Systems keep improving: faster processors, more cores• Ideal rating (speed) doubled in two years!
Memory bandwidth per core and network latency/BW stress scalability• 2008 release (12.0) re-architected MPI – huge scaling improvement, for a while…
• 2010 release (13.0) introduces hybrid parallelism – and scaling continues!
ANSYS FLUENT Scaling Achievement

© 2011 ANSYS, Inc. September 7, 20116
Extreme CFD Scaling - 1000’s of cores
Enabled by ongoing software innovation
Hybrid parallel: fast shared memory communication (OpenMP) within a machine to speed up overall solver performance; distributed memory (MPI) between machines
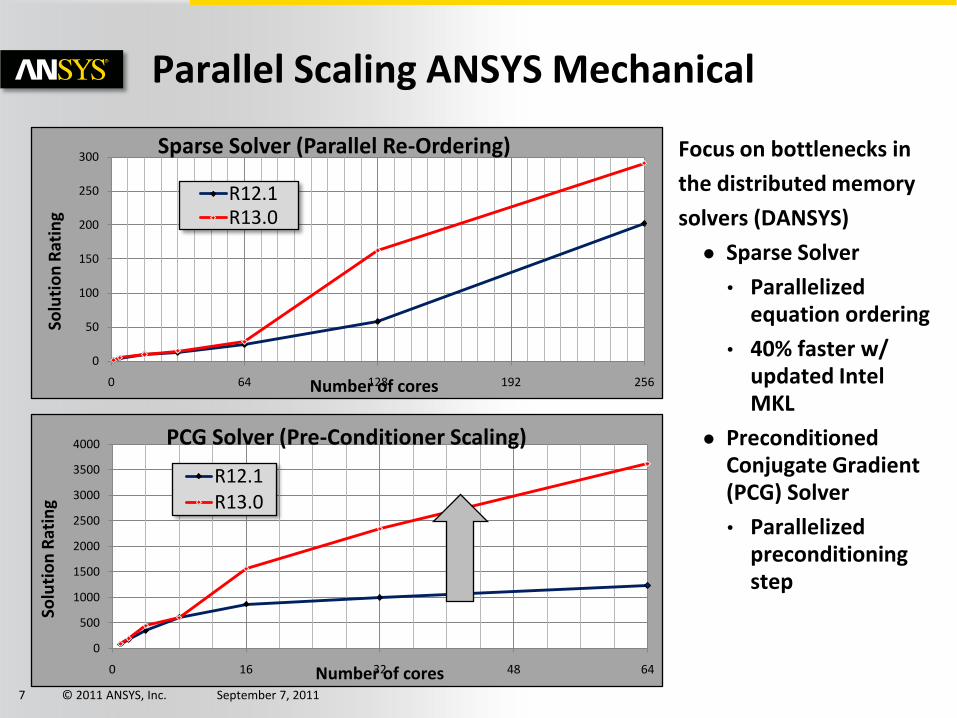
© 2011 ANSYS, Inc. September 7, 20117
Parallel Scaling ANSYS Mechanical
0
50
100
150
200
250
300
0 64 128 192 256
Solu
tio
n R
atin
g
Number of cores
Sparse Solver (Parallel Re-Ordering)
R12.1R13.0
0
500
1000
1500
2000
2500
3000
3500
4000
0 16 32 48 64
Solu
tio
n R
atin
g
Number of cores
PCG Solver (Pre-Conditioner Scaling)
R12.1R13.0
Focus on bottlenecks in
the distributed memory
solvers (DANSYS)
● Sparse Solver
• Parallelized equation ordering
• 40% faster w/ updated Intel MKL
● Preconditioned Conjugate Gradient (PCG) Solver
• Parallelized preconditioning step

© 2011 ANSYS, Inc. September 7, 20118
Architecture-Aware Partitioning
Original partitions are remapped to the cluster considering the network topology and latencies
Minimizes inter-machine traffic reducing load on network switches
Improves performance, particularly on slow interconnects and/or large clusters
Partition Graph3 machines, 8 cores eachColors indicate machines
Original mapping New mapping

© 2011 ANSYS, Inc. September 7, 20119
File I/O Performance
Case file IO
• Both read and write significantly faster in R13
• A combination of serial-IO optimizations as well as parallel-IO techniques, where available
Parallel-IO (.pdat)
• Significant speedup of parallel IO, particularly for cases with large number of zones
• Support for Lustre, EMC/MPFS, AIX/GPFS file systems added
Data file IO (.dat)
• Performance in R12 was highly optimized. Further incremental improvements done in R13
Parallel Data write
R12 vs. R13
BMW -68%
FL5L2 4M -63%
Circuit -97%
Truck 14M -64%
91.279.5 90.4 94.4
37.3 35.2 39.6 45.3
48 96 192 384
truck_14m, case read
12.1.0 13.0.0

© 2011 ANSYS, Inc. September 7, 201110
What about GPU Computing?
CPUs and GPUs work in a collaborative fashion
Multi-core processors
•Typically 4-6 cores
•Powerful, general purpose
Many-core processors
•Typically hundreds of cores
•Great for highly parallel code, within memory constraints
CPU GPU
PCI Express channel

© 2011 ANSYS, Inc. September 7, 201111
SolverKernel
Speedups
OverallSpeedups
From NAFEMS World Congress
May 2011 Boston, MA, USA
“Accelerate FEA Simulations with a
GPU”-by Jeff Beisheim,
ANSYS
ANSYS Mechanical SMP – GPU Speedup
Tesla C2050 and Intel Xeon 5560

© 2011 ANSYS, Inc. September 7, 201112
•Windows workstation : Two Intel Xeon 5560 processors (2.8 GHz, 8 cores total), 32 GB RAM, NVIDIA Tesla C2070, Windows 7, TCC driver mode
R14: GPU Acceleration for DANSYS
1.52
1.16
1.70
1.20
2.24
1.44
0
1
2
3
V13cg-1 (JCG,
1100k)
V13sp-1 (sparse, 430k)
V13sp-2 (sparse, 500k)
V13sp-3 (sparse, 2400k)
V13sp-4 (sparse, 1000k)
V13sp-5 (sparse, 2100k)
R14 Distributed ANSYS Total Simulation Speedups for R13 Benchmark set
4 CPU cores
4 CPU cores + 1 GPU

© 2011 ANSYS, Inc. September 7, 201113
1.9x
3.2x
1.7x
3.4x
4.4x
0.0
1.0
2.0
3.0
4.0
5.0
16 cores 32 cores 64 cores
Tota
l Sp
eed
up
R14 Distributed ANSYS w/wo GPU
Without GPU
With GPU
ANSYS Mechanical – Multi-Node GPU
Mold
PCB
Solder balls
Results Courtesy of MicroConsult Engineering, GmbH
• Solder Joint Benchmark (4 MDOF, Creep Strain Analysis)
Linux cluster : Each node contains 12 Intel Xeon 5600-series cores, 96 GB RAM, NVIDIA Tesla M2070, InfiniBand

© 2011 ANSYS, Inc. September 7, 201114
First capability for “specialty physics”
– view factors, ray tracing, reaction rates, etc.
R&D focus on linear solvers, smoothers – but potential limited by Amdahl’s Law
GPU Acceleration for CFD
Radiation viewfactorcalculation (ANSYS FLUENT 14 - beta)

© 2011 ANSYS, Inc. September 7, 201115
Case Study
HPC for High Fidelity CFD
http://www.ansys.com/About+ANSYS/ANSYS+Advantage+Magazine/Current+Issue
• 8M to 12M element turbocharger models (ANSYS CFX)
• Previous practice (8 nodes HPC)
● Full stage compressor runs 36-48 hours
● Turbine simulations up to 72 hours
• Current practice (160 nodes)
● 32 nodes per simulation
● Full stage compressor 4 hours
● Turbine simulations 5-6 hours
● Simultaneous consideration of 5 ideas
● Ability to address design uncertainty – clearance tolerance
“ANSYS HPC technology is enabling Cummins to use larger models with greater geometric details and more-realistic treatment of physical phenomena.”

© 2011 ANSYS, Inc. September 7, 201116
Microconsult GmbH
Solder joint failure analysis
• Thermal stress 7.8 MDOF
• Creep strain 5.5 MDOF
Simulation time reduced from 2 weeks to 1 day
• From 8 – 26 cores (past) to 128 cores (present)
“HPC is an important competitive advantage for companies looking to optimize the performance of their products and reduce time to market.”
Case Study
HPC for High Fidelity Mechanical

© 2011 ANSYS, Inc. September 7, 201117
3 Millions of Cells(6 Days)
25 Millions(4 Days)
10 Millions(5 Days)
50 Millions(2 Days)
Increase of :
Spatial-temporal Accuracy
Complexity of Physical Phenomenon
SupersonicMultiphaseRadiation
CompressibilityConduction/Convection
TransientOptimisation / DOEDynamic Mesh
LES CombustionAeroacousticFluid Structure Interaction
Case Study
HPC for High Fidelity CFD
EuroCFD• Model sizes up to 100M cells (ANSYS FLUENT)
• 2011 cluster of 700 cores
– 64-256 cores per simulation

© 2011 ANSYS, Inc. September 7, 201118
Case Study
HPC for Desktop Productivity
• Cognity Limited – steerable conductors for oil recovery
• ANSYS Mechanical simulations to determine load carrying capacity
• 750K elements, many contacts• 12 core workstations / 24 GB RAM• 6X speedup / results in 1 hour or less• 5-10 design iterations per day
“Parallel processing makes it possible to evaluate five to 10 design iterations per day, enabling Cognity to rapidly improve their design.
http://www.ansys.com/About+ANSYS/ANSYS+Advantage+Magazine/Current+Issue

© 2011 ANSYS, Inc. September 7, 201119
NVIDIA - Case study on the value of HW refresh and SW best-practice
Deflection and bending of 3D glasses
• ANSYS Mechanical – 1M DOF models
Optimization of:
• Solver selection (direct vs iterative)
• Machine memory (in core execution)
• Multicore (8-way) parallel with GPU acceleration
Before/After:
77x speedup – from 60 hours per simulation to 47 minutes.
Most importantly: HPC tuning added scope for design exploration and optimization.
Case Study
Desktop Productivity Cautionary Tale

© 2011 ANSYS, Inc. September 7, 201120
“Take Home” Points / Discussion
ANSYS HPC performance enables scaling for high-fidelity● What could you learn from a 10M (or 100M) cell / DOF model?
● What could you learn if you had time to consider 10 x more design ideas?
● Scaling applies to “all physics”, “all hardware” (desktop and cluster)
ANSYS continually invests in software development for HPC• Maximized value from your HPC investment
• This creates differentiated competitive advantage for ANSYS users
Comments / Questions / Discussion