describing ultrasound video content using deep...
TRANSCRIPT

DESCRIBING ULTRASOUND VIDEO CONTENT USING DEEP CONVOLUTIONAL NEURALNETWORKS
Y. Gao, M. A. Maraci and J. A. Noble
Institute of Biomedical Engineering, Department of Engineering Science, University of Oxford, UK
ABSTRACT
We address the task of object recognition in obstetric ul-trasound videos using deep Convolutional Neural Networks(CNNs). A transfer learning based design is presented tostudy the transferability of features learnt from natural im-ages to ultrasound image object recognition which on thesurface is a very different problem. Our results demonstratethat CNNs initialised with large-scale pre-trained networksoutperform those directly learnt from small-scale ultrasounddata (91.5% versus 87.9%), in terms of object identification.
Index Terms— Obstetric ultrasound, Convolutional neu-ral networks, Classification, Transfer learning
1. INTRODUCTION
Feature encoding has been demonstrated to provide a power-ful approach to object detection from Ultrasound (US) videos.For instance, [1] proposed a framework where images are ini-tially pre-processed to create intensity invariant structures us-ing local phase based feature symmetry maps, followed bylearning a Bag of Visual Words (BoVW) encoding of denselycomputed SIFT features and an SVM classification. Insteadof using SIFT features, [2] use Fisher Vector (FV) encod-ing. That work also demonstrated that using structured ran-dom forest edge detection instead of feature symmetry signif-icantly outperforms previously published methods.
However, convolutional neural networks (CNNs) aretransforming object detection in natural images so a natu-ral thing is to consider how this class of method can be usedto advantage for ultrasound image analysis. CNNs are highlycomplex and non-linear model which has powerful featurerepresentation capacity. The capacity can be controlled byvarying their depth and breadth, and they also use strong priorknowledge of images, for example, locality of pixel depen-dencies. Deep CNNs have achieved a great success on largescale natural image classification [3, 4, 5]. One of the key rea-sons is that it is now possible to collect labelled datasets withmillions of images. For example, ImageNET [6] consists ofover 15 million labelled images in about 22,000 categories.Medical Imaging, however, is, at least currently, not able toprovide this amount of “Big Imaging” information. This islikely to change with time, but current data ethics and data
protection rules limit the ability to build large scale publiclyavailable healthcare imaging resources at the current time.
However, a number of recent studies [7, 8, 9] have demon-strated that transfer learning provide a powerful way to reduceoverfitting by using the knowledge of a pre-trained networkto solve a target task which has limited number of data. Thequestion we therefore address in this paper is “Do featureslearnt from natural images generalise to be useful for US im-age machine learning tasks”? The answer is not necessarilyobvious, as the appearance of ultrasound images and videosare is quite different from natural images - acoustic ridges, ul-trasonic texture patterns as well as shadows are characteristicin this case. Specifically, in this paper, CNNs are first trainedon a small-scale database of labelled US images directly toidentify four type of frames, which are skull, abdomen, heartand other structures. A transfer learning approach is thenproposed to experimentally quantify the transferability of fea-tures learnt from ImageNET to ultrasound video frame recog-nition. A number of transfer learning models are comparedwith direct learning models in terms of their classification per-formance.
2. MATERIALS AND METHODS
2.1. Data
The clinical data used in the research [1] consisted of 323 fe-tal ultrasound videos acquired to a freehand sweep protocol.The clinical data was acquired using a mid-range US machine(Philips HD9 with a V7-3 transducer) by an experienced ob-stetrician moving the ultrasound probe from bottom to top ofthe abdomen in approximately 6-8 seconds. Four classes ofvideo frames were created from these video sweeps of thefetal abdomen, heart, skull and other structures. “Other struc-tures” included any video frame that do not fall into the otherthree classes. All the subjects included in this study werehealthy volunteers of 28 weeks of gestation and over. 70% ofthe US videos were used to generate training samples (10,820frames), and the remaining 30% (3,648 frames) were used fortesting. The original frames had size 240× 320 pixels. Aug-mentation was applied to the raw frames by extracting five227 × 227 patches (the four corner patches and the centerpatch) as well as their horizontal reflections.
978-1-4799-2349-6/16/$31.00 ©2016 IEEE 787

Fig. 1. A schematic of the CNN used in this paper. 96-256-384-384-256-256 are the number of feature maps generatedin each layer. 55-27-13-13-13-6 are the sizes of the featuremaps. There are 4096 neurons in each of the fully connectedlayers. There are 4 neurons in the output layer.
2.2. Convolutional Neural Network
Fig.1 illustrates the overall architecture of the CNN (denotedDCNN) used in the paper. The design [3] adopts relativelylarge kernels and stride in the first two convolutional lay-ers which gives an aggressive reduction of spatial resolution.This effectively improves the computational efficiency andaccelerates the training process. However, drawbacks of thedesign are that the accuracy of classification may compro-mise with the large stride, and the lower level features areless detailed due to the usage of large kernels [4]. The third,fourth and fifth convolutional layers have 3×3 kernels stackedtogether with Rectified Linear Units (ReLUs) between eachother. This can be seen as imposing a regularisation on the7 × 7 conv. filters, forcing them to have a decompositionthrough the 3 × 3 filters (with non-linearity injected in be-tween). The design significantly increases the non-linearityof the network and makes the decision function more discrim-inative, hence makes their features more expressive [5].
In order to train the CNNs, parameters including the con-volution kernels W and the bias b are updated by minimisinga loss function L(Ii, yi; θ) via, in practice, Stochastic Gradi-ent Descent (SGD) with momentum [5], where θ representsthe set of trainable parameters. The loss function used in thepaper is the Softmax cost function defined as:
L(Ii, yi; θ) = −N∑i=1
K∑k=1
(1 {yi = k} logP(yi = k|Ii; θ))
(1)
P(yi = k|Ii; θ) =exp(θTk xi)∑Kj=1 exp(θ
Tj xi)
, k = 1, .....,K (2)
where, 1 {·} is the indicator function and yi is the predicted la-bel; θTk xi is the output of kth neuron in the last layer; P (yi =k|Ii; θ) is the posterior probability of predicting the trainingsample Ii as the kth class among total K classes;
Fig. 2. Overview of transfer learning framework. Top row:The TCNN-A is pre-trained on the ImageNet database forclassification. The labelled purple rectangles (e.g. Wc1) rep-resent the weights learned by that layer. Bottom row: In theTCNN-B, the first n weight layers (in this example, n = 3)are copied from the base network A. The remaining layers arerandomly initialised, and then the entire network is trainedon ultrasound datasets with the transferred parameters locked(frozen) or unlocked (fine-tuned).
2.3. Transfer Learning
The Transfer learning model used in this paper is illustratedschematically in Fig.2. The base CNN (denoted TCNN-A),having the same architecture as described in Sect.2.2, waspre-trained on ImageNet. The parameters of the first n layers(n= 1,2,..,7) of the TCNN-A were transferred to another CNN,denoted as TCNN-B, and the remaining layers of TCNN-Bwere randomly initialised from a Gaussian with zero meanand standard deviation 0.01. The parameters of TCNN-Bwere either frozen or fine-tuned by feeding US datasets.
2.4. Learning details
Models were trained using SGD (see Sect 2.2) with a batchsize of 256 samples, momentum rate of 0.9, and weight decayof 0.0005. The weights and bias in each layer were initialisedfrom a zero-mean Gaussian distribution with standard devia-tion 0.01. The number of epochs was set to 60. Training andvalidation were implemented separately for each epoch. Clas-sification error was accumulated batch by batch for each classto compare classification performance between the classes.Learning rate ξ was constant for all layers, and adjusted foreach training epoch. The initial learning rate was set to 0.01and continuously reduced to 10−4 until training termination.
3. EXPERIMENTS AND RESULTS
Experiments were designed to evaluate the performance ofdirect learning models and compare with the performance oftransfer learning models. There were three direct learningexperiments conducted. Firstly, the standard model (depictedin Fig.1) was directly trained on the 10,820 227×227 US
788
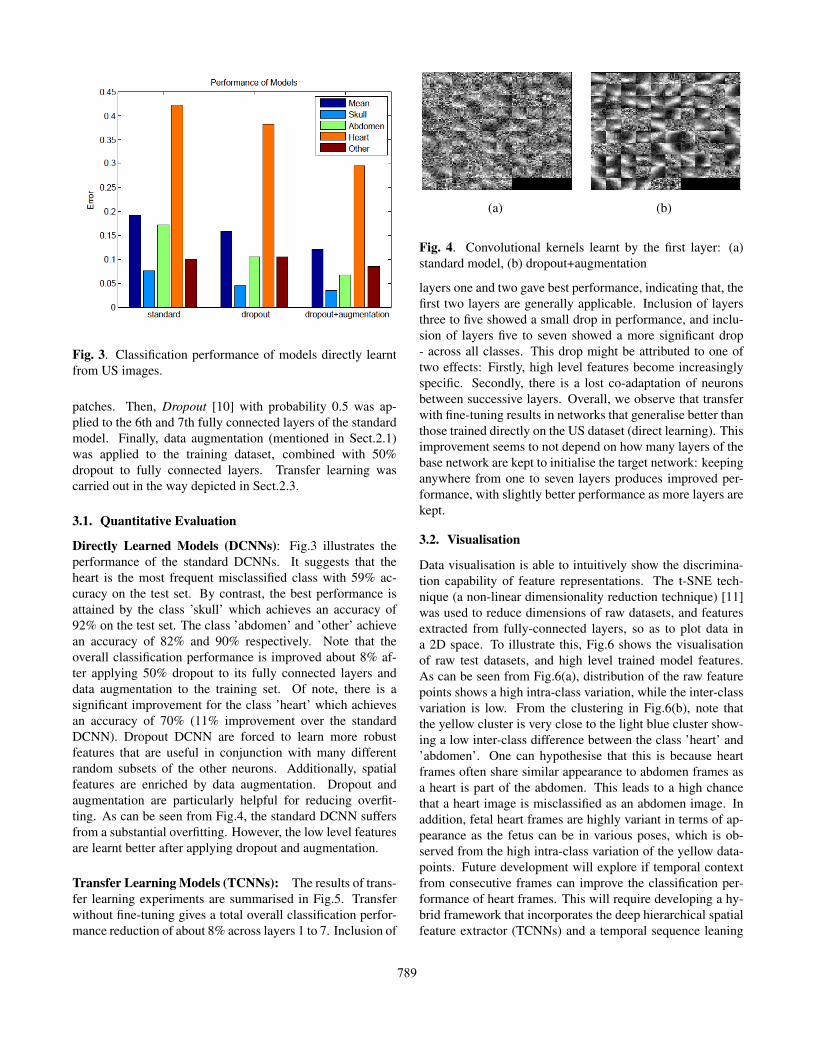
Fig. 3. Classification performance of models directly learntfrom US images.
patches. Then, Dropout [10] with probability 0.5 was ap-plied to the 6th and 7th fully connected layers of the standardmodel. Finally, data augmentation (mentioned in Sect.2.1)was applied to the training dataset, combined with 50%dropout to fully connected layers. Transfer learning wascarried out in the way depicted in Sect.2.3.
3.1. Quantitative Evaluation
Directly Learned Models (DCNNs): Fig.3 illustrates theperformance of the standard DCNNs. It suggests that theheart is the most frequent misclassified class with 59% ac-curacy on the test set. By contrast, the best performance isattained by the class ’skull’ which achieves an accuracy of92% on the test set. The class ’abdomen’ and ’other’ achievean accuracy of 82% and 90% respectively. Note that theoverall classification performance is improved about 8% af-ter applying 50% dropout to its fully connected layers anddata augmentation to the training set. Of note, there is asignificant improvement for the class ’heart’ which achievesan accuracy of 70% (11% improvement over the standardDCNN). Dropout DCNN are forced to learn more robustfeatures that are useful in conjunction with many differentrandom subsets of the other neurons. Additionally, spatialfeatures are enriched by data augmentation. Dropout andaugmentation are particularly helpful for reducing overfit-ting. As can be seen from Fig.4, the standard DCNN suffersfrom a substantial overfitting. However, the low level featuresare learnt better after applying dropout and augmentation.
Transfer Learning Models (TCNNs): The results of trans-fer learning experiments are summarised in Fig.5. Transferwithout fine-tuning gives a total overall classification perfor-mance reduction of about 8% across layers 1 to 7. Inclusion of
(a) (b)
Fig. 4. Convolutional kernels learnt by the first layer: (a)standard model, (b) dropout+augmentation
layers one and two gave best performance, indicating that, thefirst two layers are generally applicable. Inclusion of layersthree to five showed a small drop in performance, and inclu-sion of layers five to seven showed a more significant drop- across all classes. This drop might be attributed to one oftwo effects: Firstly, high level features become increasinglyspecific. Secondly, there is a lost co-adaptation of neuronsbetween successive layers. Overall, we observe that transferwith fine-tuning results in networks that generalise better thanthose trained directly on the US dataset (direct learning). Thisimprovement seems to not depend on how many layers of thebase network are kept to initialise the target network: keepinganywhere from one to seven layers produces improved per-formance, with slightly better performance as more layers arekept.
3.2. Visualisation
Data visualisation is able to intuitively show the discrimina-tion capability of feature representations. The t-SNE tech-nique (a non-linear dimensionality reduction technique) [11]was used to reduce dimensions of raw datasets, and featuresextracted from fully-connected layers, so as to plot data ina 2D space. To illustrate this, Fig.6 shows the visualisationof raw test datasets, and high level trained model features.As can be seen from Fig.6(a), distribution of the raw featurepoints shows a high intra-class variation, while the inter-classvariation is low. From the clustering in Fig.6(b), note thatthe yellow cluster is very close to the light blue cluster show-ing a low inter-class difference between the class ’heart’ and’abdomen’. One can hypothesise that this is because heartframes often share similar appearance to abdomen frames asa heart is part of the abdomen. This leads to a high chancethat a heart image is misclassified as an abdomen image. Inaddition, fetal heart frames are highly variant in terms of ap-pearance as the fetus can be in various poses, which is ob-served from the high intra-class variation of the yellow data-points. Future development will explore if temporal contextfrom consecutive frames can improve the classification per-formance of heart frames. This will require developing a hy-brid framework that incorporates the deep hierarchical spatialfeature extractor (TCNNs) and a temporal sequence leaning
789
Fig. 5. Classification performance of transfer learning mod-els. Layer 0 shows the best performance of direct learning.
model.
4. CONCLUSIONS
The results presented in this paper demonstrate a state-of-the-art multi-label classification in obstetric ultrasound video us-ing CNNs. Note that our accuracy results are data dependent.In particularly they are very encouraging given our data isfrom a linear sweep scanning protocol which is a simple scan-ning protocol designed for use by a non-expert [1, 2]. Ourwork shows that given small scale data, performance of themodels can be enhanced via initialising networks with fea-tures learnt from natural images which is also helpful to re-duce overfitting of the models.
5. ACKNOWLEDGEMENT
The authors acknowledge the China Scholarship Council forDoctoral Training Award (grant No. 201408060107).
6. REFERENCES
[1] MA Maraci, R Napolitano, A Papageorghiou, andJA Noble, “Searching for structures of interest in an
(a) (b)
(c)
Fig. 6. t-SNE visualisation. Blue, light blue, yellow and redpoints represent the classes ’skull’, ’abdomen’, ’heart’ and’other’, respectively. (a) Raw test data. (b) Extracted fea-tures of the 7th fully connected layer from test data. (c) heartframes (marked by red rectangle) misclassified as abdomen.
ultrasound video sequence,” MLMI, pp. 133–140, 2014.[2] MA Maraci, R Napolitano, A Papageorghiou, JA Noble,
“Fisher vector encoding for detecting objects of interestin ultrasound videos,” in ISBI. 2015, pp. 651–654.
[3] A Krizhevsky, I Sutskever, and GE Hinton, “Imagenetclassification with deep convolutional neural networks,”in NIPS, pp. 1097–1105, 2012.
[4] P Sermanet, D Eigen, M Mathieu, R Fergus, Y LeCun,“Overfeat: Integrated recognition, localization and de-tection using convolutional networks,” in ICLR, 2013.
[5] K Simonyan, A Zisserman, “Very deep convolutionalnetworks for large-scale image recognition,” in ICLR,2015.
[6] O Russakovsky et al., “ImageNet Large Scale VisualRecognition Challenge,” in IJCV, pp. 1–42, April 2015.
[7] M Long, J Wang, “Learning transferable features withdeep adaptation networks,” Proc. 32nd ICML, 2015.
[8] A Razavian, H Azizpour, J Sullivan, S Carlsson, “Cnnfeatures off-the-shelf: an astounding baseline for recog-nition,” in CVPR, pp. 512–519, 2014.
[9] J Donahue et al., “Decaf: A deep convolutional activa-tion feature for generic visual recognition,” in CVPR,2014.
[10] GE Hinton et al., “Improving neural networks by pre-venting co-adaptation of feature detectors,” in CoRR,vol. abs/1207.0580, 2012.
[11] L Van der Maaten, GE Hinton, “Visualizing data usingt-sne,” in JMLR, vol. 9, no. 2579-2605, pp. 85, 2008.
790