desktop grid scheduling
TRANSCRIPT

1
A REPORT
ON
Primitive Scheduling Algorithms for Desktop Grid
Computing
By
PIYUSH KANDPAL 2005B4A8563P
Under Guidance Of
Mrs. Sunita Bansal
(Lecturer, CSIS Department)
AT
BITS Pilani
PILANI
BIRLA INSTITUTE OF TECHNOLOGY AND SCIENCE, PILANI
5 May, 2010

2
A REPORT
ON
Primitive Scheduling Algorithms for Desktop Grid
Computing
By
PIYUSH KANDPAL 2005B4A8563P
AT
BITS Pilani
PILANI
BIRLA INSTITUTE OF TECHNOLOGY AND SCIENCE, PILANI
5 May, 2010

3
BIRLA INSTITUTE OF TECHNOLOGY AND SCIENCE
PILANI (RAJASTHAN)
Research and Consultancy Division
Title of the Project: Primitive Scheduling algorithm for Distributed Computing ID No. : 2005B4A8563P
Name : Piyush Kandpal
Discipline: M.Sc. (Hons) Mathematics, B.E. (Hons) Electronics & Instrumentation
Engineering
Name(s) of the : Mrs. Sunita Bansal
Faculty
Key words : Desktop Grid Scheduling, Group-based Adaptive Scheduling, Resource
Grouping Method, Agent-based Group Scheduling Group Scheduling for Replication, Group
Scheduling for Result Certification, Fault Tolerant Algorithm, Agent-Based Autonomous
Scheduling Mechanism Using Availability, Volunteer Availability Based Fault Tolerant
Scheduling Mechanism.
Abstract: Desktop Grid Computing has emerged as a high throughput and high performance
computation technique but the existing scheduling mechanisms face some challenges like
heterogeneous capabilities (that is, CPU, memory, network bandwidth, and latency), and are
exposed to link and crash failures, volatility (that is, intermittent presence), and lack of trust, and
autonomy and heterogeneous volunteering times of resources which are big issues in
computation. Hence to cope up with these problems, the report discusses scheduling mechanisms
for desktop grid computing like resource grouping, reputation or incentive-based scheduling,
scheduling for result certification, dynamic, adaptive, or fault tolerant scheduling, distributed
scheduling, agent-based autonomous scheduling mechanism using availability, volunteer
availability based fault tolerant scheduling mechanism etc. These scheduling mechanisms not
only increase the reliability and performance of the computation but also decrease the overhead
of computation. Also the proposed scheduling mechanisms completes more tasks than existing
eager scheduling mechanism, while satisfying the desired credibility threshold and it decreases
the total and average execution times of tasks and guarantees the completion of execution of
tasks while guaranteeing guarantees fast turnaround time.
Signature of Student : Piyush Kandpal Signature of Faculty:
Date : 5 May 2010. Date 5 May 2010

4
Acknowledgement
I express my profound gratitude to Madam Sunita Bansal, Lecturer CSIS Department at
BITS Pilani, for having given me this wonderful opportunity for doing thesis on the topic
“Primitive Scheduling Algorithm for Distributed Grid Computing “ and work under her able
guidance and gain a good experience in the field of Desktop Grid computing .I would also like
to thank her for spending some of her invaluable time by sorting out my queries and for giving
me valuable information at times when I was facing difficulties to proceed and also for guiding
me at every step.
I would also like to express my gratitude to the member of the evaluation committee, Mr.
Dinesh Kumar Tyagi, for his valuable comments that have lead to significant improvements of
this thesis, and for smooth handling of the evaluation process.

5
Abstract
Grid Computing is the collection of tools, techniques, and theories required to solve on a
computer, mathematical models of problems from science and engineering, and its main goal is
to gain insight in such problems. Generally, it is difficult to understand or communicate
information from complex or large datasets generated by conventional Computing methods and
techniques (computational simulations, complex experiments, observational instruments etc.).
Usually, complex computational and visualization algorithms require large amounts of
computational power. The computing power of a single desktop computer is insufficient for
running such complex algorithms, and, traditionally, large parallel supercomputers or dedicated
clusters were used for this job. However, very high initial investments and maintenance costs
limit the availability of such systems. A more convenient solution, which is becoming more and
more popular, is based on the use of non dedicated desktop PCs in a Desktop Grid Computing
environment. Harnessing idle CPU cycles, storage space and other resources of networked
computers to work together on a particularly computational intensive application does this.
Increasing power and communication bandwidth of desktop computers provides for this solution.
In a desktop grid system, the execution of an application is orchestrated by a central
scheduler node, which distributes the tasks amongst the worker nodes and awaits workers’
results. An application only finishes when all tasks have been completed. The attractiveness of
exploiting desktop grids is further reinforced by the fact that costs are highly distributed: every
volunteer supports her resources (hardware, power costs and internet connections) while the
benefited entity provides management infrastructures, namely network bandwidth, servers and
management services, receiving in exchange a massive and otherwise unaffordable computing
power. The usefulness of desktop grid computing is not limited to major high throughput public
computing projects. Many institutions, ranging from academics to enterprises, hold vast number
of desktop machines and could benefit from exploiting the idle cycles of their local machines.
Desktop Grids have emerged as an important methodology to harness the idle cycles of
millions of participant desktop PCs over the Internet. However, to effectively utilize the
resources of a Desktop Grid, it is necessary to use scheduling policies suitable for such systems.
A scheduling policy must be applicable to large-scale systems involving large numbers of
machines. Also, the policy must be fault aware in the sense that it copes with resource volatility.
Further adding to the complexity of scheduling for Desktop Grids is the inherent heterogeneity of
such systems. Suboptimal performance would result if the scheduling policy does not take into
account information on heterogeneity.
The recent desktop grid systems can be characterized by decentralized control, large scale
and extreme dynamism of their computation environment. In the environment of high throughput
desktop grid systems, the volatility of volunteers, and the decentralized nature of desktop grid
systems pose significant challenges. Thus, an executing computation is not guarantee continuous
computation because of volatility of volunteers. In this thesis, these situations are called as
computational failure, which leaves in the middle of the computation. Current approaches to
utilizing desktop resources require either centralized servers, or extensive knowledge of the
underlying system, limiting scalability and performance .Hence Desktop Grid computing is

6
complicated by heterogeneous capabilities, failures, volatility, and lack of trust because it is
based on desktop computers at the edge of the Internet
To solve these problems ,the report discusses scheduling mechanisms for desktop grid
computing like resource grouping, reputation or incentive-based scheduling, scheduling for result
certification, dynamic, adaptive, or fault tolerant scheduling, distributed scheduling, agent-based
autonomous scheduling mechanism using availability, volunteer availability based fault tolerant
scheduling mechanism etc which adapts to a dynamic Desktop Grid computing environment.
The group-based adaptive scheduling mechanism classifies and constructs groups according to
volunteer's properties such as dedication, volatility, availability, and credibility. Then it applies
different scheduling, replication, result certification, and fault tolerance algorithms to each
group. These scheduling mechanisms not only increase the reliability and performance of the
computation but also decrease the overhead of computation. Also the proposed scheduling
mechanisms completes more tasks than existing eager scheduling mechanism, while satisfying
the desired credibility threshold and it decreases the total and average execution times of tasks
and guarantees the completion of execution of tasks while guaranteeing guarantees fast
turnaround time.

7
Table of Contents
Acknowledgements ………………………………………………………………………4
Abstract ………………………………………………………………………………….5
1. Introduction……………………………………………………………………...8
1.1 Grid computing………………………………………………………………8
1.2 Desktop Grid Computing…………………………………………………….9
1.3 Scheduling…………………………………………………………………..11
1.3.1 Scheduling for Desktop Grid………………………………………..12
2. Taxonomy of Desktop Grid……………………………………………………..13
3. Taxonomy of Desktop Grid……………………………………………………..13
4. Taxonomy of Desktop Grid Scheduling………………………………………...15
4.1 Application's Perspective Considerations…………………………………...15
4.2 Resource’s Perspective Considerations…………………………………......16
4.3 Scheduler's Perspective Considerations…………………………………......17
5. System Model…………………………………………………………………...22
5.1 Execution Model…………………………………………………………….22
5.2 Failure Model………………………………………………………………..23
6. Group-based Adaptive Scheduling Mechanism…………………………………25
6.1 Resource Grouping Method…………………………………………………25
6.2 Constructing and Characterizing Volunteer Groups………………………...27
6.3 Agent-based Group Scheduling.…………………………………………….30
6.4 Agent based Desktop Grid Computing Model………………………………31
6.5 Allocating Scheduling Agents to Scheduling Groups……………………….32
6.6 Distributing Task Agents to Group Members………………………………..33
7. Group Scheduling for Replication……………………………………………….34
8. Group Scheduling for Result Certification………………………………………36
9. Fault Tolerant Algorithm………………………………………………………...38
10. Related Works and Differences………………………………………………….40
10.1 Agent-based Autonomous Scheduling Mechanism Using Availability
in Desktop Grid System…………………………………………………40
10.2 Volunteer Availability based Fault Tolerant Scheduling Mechanism
in Desktop Grid Computing Environment…………………………….....42
11. Limitations of existing scheduling mechanisms and Recommendations………...46
12. Conclusion………………………………………………………………………..49
References……………………………………………………………………………………………50

8
1. Introduction
1.1 Grid computing
Grid computing is the combination of computer resources from multiple administrative
domains for a common goal. Grid computing (or the use of a computational grid) is applying the
resources of many computers in a network to a single problem at the same time - usually to a
scientific or technical problem that requires a great number of computer processing cycles or
access to large amounts of data.
The bringing together of many different groups in this collaborative effort is known as Virtual
Organizations (VOs). These VOs may be formed to solve a single task and may then disappear
just as quickly. Grids are usually used for solving scientific, technical or business problems that
require a great number of computer processing cycles for processing of large amounts of data.
One of the main strategies of Grid computing is to use middleware to divide and apportion pieces
of a program among several computers, sometimes up to many thousands. Grid computing
involves computation in a distributed fashion, which may also involve the aggregation of large-
scale cluster computing based systems. The size of a Grid may vary from being small and
confined to a network of computer workstations within a corporation, for example — to being
large, public collaboration across many companies and networks. "The notion of a confined grid
may also be known as intra-nodes cooperation whilst the notion of a larger, wider grid may thus
refer to inter-nodes cooperation.
Grids are a form of distributed computing whereby a “super virtual computer” is composed of
many networked loosely coupled computers acting in concert to perform very large tasks. This
technology has been applied to computationally intensive scientific, mathematical, and academic
problems through volunteer computing, and it is used in commercial enterprises for such diverse
applications as drug discovery, economic forecasting, seismic analysis, and back-office data
processing in support of e-commerce and Web services.
What distinguishes Grid computing from conventional high performance computing systems
such as cluster computing is that Grids tend to be more loosely coupled, heterogeneous, and
geographically dispersed. It is also true that while a Grid may be dedicated to a specialized
application, a single Grid may be used for many different purposes. They are often constructed
with the aid of general-purpose Grid software libraries called middleware.
Grid computing appears to be a promising trend for three reasons: (1) its ability to make more
cost-effective use of a given amount of computer resources, (2) as a way to solve problems that
can't be approached without an enormous amount of computing power, and (3) because it
suggests that the resources of many computers can be cooperatively and perhaps synergistically
harnessed and managed as a collaboration toward a common objective.

9
1.2 Desktop Grid Computing
Desktop grid computing is a computing paradigm that achieves a high throughput
computing by harvesting a number of idle computing resources on the Internet. Desktop grid
computing is usually applied to multi-parameter or embarrassingly parallel applications which
consist of a lot of instances of the same computation with its own input parameters. In recent
years, there has been a rapidly growing interest in desktop grid computing because of the success
of the most popular examples such as distributed.net and SETI@Home , the business interest of
P2P computing, and the advent and growth of Grid computing. Some studies have been made on
desktop grid computing systems which provide an underlying platform: Charlotte , Bayanihan,
Javelin, GUCHA, XtremWeb, WebCom, Nimrod, Entropia, AppLes and so on.
Desktop grids use the idle cycles of mostly desktop PC’s to support large-scale computation and
data storage. Today these types of computing platforms are the largest distributed computing
systems in the world. The most popular project, SETI@home, uses over 20 TeraFlop/sec
provided by hundreds of thousands of desktops. Numerous other projects, which span a wide
range of scientific domains, also use the cumulative computing power offered by desktop grids,
and there have also been commercial endeavors for harnessing the computing power within an
enterprise, i.e., an organization’s local area network. Despite the popularity and success of many
desktop grid projects, the volatility of the hosts within desktop grids has been poorly understood.
Yet, this characterization is essential for accurate simulation and modeling of such platforms.
Desktop grid computing environment mainly consists of clients, volunteers and volunteer
servers. A client is a job requester. A volunteer is a donator which is willing to contribute its
computing resources. A volunteer server is a manager which controls jobs and volunteers. A
client submits a job to a volunteer server. The job is divided into sub jobs which have each own
input parameter. The sub-job is called a task. A volunteer server distributes the tasks to
volunteers. Each volunteer executes its task and returns a result of execution of the task to the
volunteer server. The volunteer server returns a result of the job to the client.
Since desktop grid computing is based on Internet, volunteers are exposed to link and crash
failures. In addition, volunteers are voluntary participants, so they can freely join and leave in the
middle of the executions without any constraints. Thus, a public execution (i.e. the execution of a
task as a volunteer) is started or stopped (aborted) arbitrarily. Moreover, volunteers are not
totally dedicated to desktop grid computing, so public executions get temporarily suspended by a
private execution (i.e. the execution of a private job as a personal user). In this report, these
situations are termed as volunteer autonomy failures.
The volunteer autonomy failures occur more often than traditional parallel computing (i.e.
COWs, MPP etc.) which is not based on Internet. However, although previous scheduling
mechanisms (i.e. eager scheduling) tolerate crash and link failures, they do not deal with
volunteer autonomy failures. Therefore, when existing scheduling mechanisms are applied to
volunteer autonomy failures, they have an independent live lock problem, that is, volunteers do
not generate a result of a task even though they continuously execute the same task.
Consequently, the existing scheduling mechanisms lead to the delay and blocking of the entire
execution of a job. Therefore, one should consider the volunteer autonomy failures in scheduling

10
in order to guarantee reliable and continuous executions. In addition, some malicious volunteers
may tamper with the computation and return corrupt results. A variety of hardware and software
lead to deviation from the result of a task. These distinct features make it difficult for a server to
schedule tasks and manage allocated tasks and volunteers. Therefore, it is necessary to develop
scheduling mechanisms that adapt to such a dynamic computing environment.

11
1.3 Scheduling
An important component of a Desktop Grid system is its scheduler. The scheduler is
responsible for assigning resources to tasks. It uses a scheduling policy that is designed to
optimize certain performance requirements. These scheduling policies may use certain
information, such as task arrival rates and machine execution rates, to improve performance.
Based on the information that can be used, scheduling policies are classified as static, dynamic,
or adaptive.
In a static policy, the scheduling is carried out independent of the state of the system and is done
in a predetermined manner. A dynamic policy adapts its scheduling decisions based on the state
of the system. Adaptive policies are dynamic policies where the parameters of the scheduling
policy are changed based on the global state of the system. A scheduling policy must support
systems with a very large number of machines.
Besides the natural complexity of scheduling for such large systems, the complexity is further
complicated by several factors. First, Desktop Grids are characterized by very high resource
volatility. In such systems, machines can fail at any time without any advance notice. Since
Desktop Grids are typically based on the Internet, machines are also exposed to link failures.
Furthermore, Desktop Grids are volunteer computing systems where participants voluntarily join
in to execute the Grid applications. Thus, the machines of a Desktop Grid system are not
dedicated (i.e., machines’ local jobs should have higher priority than the Grid tasks).
To better cope with resource volatility, a scheduling policy must be fault aware in the sense that
it needs to exploit the knowledge of the effective computing power delivered by resources and
the distribution of their fault times (if such information is available).A second factor contributing
to the complexity of scheduling for Desktop Grids is related to the heterogeneous nature of such
systems. Heterogeneous machines have been considered which execute tasks that themselves
may be highly heterogeneous. The execution time of a task depends on the class of the task as
well as the executing machines. Performance would be significantly impacted if information on
task and machine heterogeneity is not taken into account by the scheduling policy.

12
1.3.1 Scheduling for Desktop Grid
Scheduling of Desktop Grid is different from that of Grid because Desktop Grid is different from
Grid in terms of the type of resource, dedication, trust, failure, application, and so on .
(i) Desktop Grid scheduling is mainly the process of assigning tasks to the most suitable
resources (that is, to decide where to execute tasks) .It is performed in a centralized
way or in a fully distributed way.
(ii) Most Desktop Grid systems do not need a local scheduler like Grid in the sense that a
scheduling target is a single desktop computer, not a site like Grid (that is, multiple
processors or computers in supercomputer or cluster).
(iii) Desktop Grid scheduling is complicated by heterogeneous, volatile, faulty, and
malicious resources. Desktop Grid scheduler focuses more on volatility (non-
dedication), lack of trust, and heterogeneous properties than Grid scheduler .
(iv) Desktop Grid scheduling is opportunistic. Desktop Grid respects the autonomy of
volunteers (that is, volunteers can freely participate in public execution). Thus,
Desktop Grid scheduling should use resources as quickly as possible when they are
available or idle.
Therefore, it is necessary to develop a new Desktop Grid scheduler. In order to consider these
distinct features, a Desktop Grid scheduler needs a resource grouping method, which ensures that
volunteers with similar properties (such as capability, performance, availability, workload,
reputation/trust, volatility, etc.) are grouped together. It needs to apply scheduling algorithms to
each group depending on group's characteristics. Coupling a resource grouping method with
scheduling helps schedule and manage tasks efficiently. It is very important how to group
volunteers depending on what properties, because scheduling and resource management are
performed on the basis of characteristics of the groups.
There are benefits by coupling a resource grouping method with scheduling as follows.
(i) The coupling method enables a scheduler to apply various replication, result
certification, and fault tolerant algorithms to each homogeneous group.
(ii) The coupling method easily enables reputation-based or incentive-based scheduling
(iii) The coupling method improves reliability and performance.
Although the coupling method has a lot of advantages, existing scheduling mechanisms,
however, did not consider volunteer's properties such as volatility, availability, and credibility
that strongly affect reliability, performance, and result correctness. Moreover, they did not
provide scheduling mechanisms on a per group basis. As a result, they deteriorate the reliability
of computation as well as performance .To solve these problems, the thesis proposes a new
group-based adaptive scheduling mechanism, which adapts to a dynamic Desktop Grid
computing environment. The group-based adaptive scheduling mechanism classifies and
constructs groups according to volunteer's properties such as dedication, volatility, availability,
and credibility. Then it applies different scheduling, replication, result certification, and fault
tolerance algorithms to each group. Consequently, it improves reliability and performance. The
simulation results show that how much it can outperform existing scheduling mechanisms.

13
2 Taxonomy of Desktop Grid
Desktop Grid is categorized according to organization, platform, scale, and resource properties
Fig 2
1. Organization Desktop Grid is categorized into centralized and distributed ones according to organization of
components.
Centralized Desktop Grid
Centralized Desktop Grid (DG) consists of client, volunteer, and server. The execution model of
centralized DG consists of seven phases: registration, job submission, task allocation, task
execution, task result return, result certification, and job result return phase.
Distributed Desktop Grid
Distributed Desktop Grid (DG) consists of client and volunteer. In contrast to centralized DG,
there is no server, so volunteers have the partial information of other volunteers. Volunteers are
responsible for constructing computational overlay network (CON) .The CON2 is a set of
volunteers for the execution of tasks. Scheduling is performed at each volunteer in a distributed
way, depending on CON. That is, volunteers distribute tasks to other volunteers differently
according to a characteristic or topology of CON (for example, tree, graph, or DHT (Distributed
Hash Table)). The execution model of distributed DG consists of seven phases: registration, job
submission, CON construction, task allocation, task execution, task result return, and job result
return phase
1. Platform Desktop Grid is categorized into web-based (Java applet-based) DG and middleware-based DG
according to platform running on volunteers. In the web-based DG, clients write their parallel
applications in Java and post them as Applet on the Web. Then, volunteers only join the web
page with their browsers. The Applet is downloaded automatically and runs on the volunteer's
machine. Typical examples are Charlotte, Bayanihan, Javelin and so on. In the middleware-based

14
DG, volunteers need to install and run a specific middleware (software that provides the services
and functionalities to execute parallel applications) on their machine. The middleware
automatically fetches tasks from a server and executes them, when CPU is idle. Typical
examples are BOINC, XtremWeb, Entropia , Bayanihan, Korea@Home , and so on.
2. Scale Desktop Grid is categorized into Internet-based DG and LAN-based DG according to scale.
Internet-based DG is based on anonymous volunteers (see Table 2.1). It should consider firewall,
NAT, dynamic address, poor bandwidth, and unreliable connection. On the other hand, LAN-
based DG is based on volunteers within a corporation, university, and institution. It has more
constant connectivity than Internet-based DG.
3. Resource Provider Desktop Grid is categorized into volunteer DG and enterprise DG according to properties of
resource provider (see Table 2.1). Volunteer DG is mainly based on voluntary participants.
Enterprise DG is mainly based on non voluntary participants usually within a corporation and
university. Mostly, volunteer DG can be Internet-based DG, and enterprise DG can be LAN-
based DG. Volunteer DG is more volatile, malicious, and faulty than enterprise DG. Enterprise
DG is more controllable than volunteer DG because volunteers are located in the same
administrative domain. Typical examples of volunteer DG are BOINC [7, 8, 9], XtremWeb
,Bayanihan ,Javelin ,Korea@Home, and so on. Enterprise DG can be Entropia and Condor .

15
3 Taxonomy of Desktop Grid Scheduling
3.1 Application's Perspective Considerations
Fig. 3.1
Dependency:
In the case of dependency between tasks, the relationship between tasks is mainly designed as a
graph (for example, Directed Acyclic Graph (DAG). The scheduler for DAG considers machine's
capability, communication cost, data and task dependency (synchronization requirement)
simultaneously in order to minimize the overall execution time of the graph. In the case of
independent tasks, a scheduler focuses on allocation of independent tasks to machines according
to resource's availability, capability, and properties
Type:
In the case of data-intensive application, a scheduler should consider location of data or replica,
the cost of transfer, or replication policy, and so on. In the case of computation-intensive, a
scheduler focuses on resource's capability and availability.
Divisibility:
Is a job divided into multiple sub-job (task) flexibly? In case of divisible or moldable job, a
scheduler focuses on how much a task is assigned to a resource. The size of task depends on
resource's capability, availability, deadline, etc.
Submission pattern to scheduler:
Does a client submit an application to scheduler before scheduling? Or does a client non
deterministically submit an application to scheduler during scheduling?

16
QoS: Some applications may request QoS to a scheduler. For example, a certain application needs to
be finished before the deadline. Assume that an application with highest priority wants to process
more immediately and quickly than other applications. In this case, a high-priority application
can preempt a low-priority application. A certain application does not want to be assigned to
specific nodes or domain. A certain application needs to guarantee result correctness.
3.2 Resource’s Perspective Considerations
A Desktop Grid scheduler should consider the following aspects on the Resource’s perspective
when designing and developing scheduling algorithm.
Dedication to public execution (or volatility):
Are resources allowed to freely join and leave in the middle of the public executions (that is, the
execution of a task as a volunteer) without any constraints? If resources are volatile and non-
dedicated, public execution can be suspended or stopped by a private execution (that is, the
execution of a private job as a personal user). In this case, it is appreciate that a scheduler is
opportunistic in the sense that a resource is not always available. A scheduler can be coupled
with reputation or incentive mechanism in order to select eager resources or exclude selfish
resources Scale:
Are resources located in the scope of LAN or Internet? The characteristics of environment (such
as connection, the degree of heterogeneity and trust, dedication pattern, failure, manageability,
etc.) are different between Internet based DG and LAN-based DG. If resources are connected to
Internet, it is proper that scheduling event is initiated by a resource's request in the sense that
some resources are behind network address translator (NAT) or firewall and they are not always
available. In other words, a resource pulls a task from its scheduler (that is, pull mode).
State change:
Is the properties of resources (such as availability, volatility, trust, failure, load, bandwidth, etc.)
changing during the public execution? In a Desktop Grid environment, resources are controlled
by individual owners. Resources are more heterogeneous, dynamic and unreliable, when
compared to Grid. A Desktop Grid scheduler should be dynamic and adaptive. In other words, a
scheduler should be able to change the scheduling policy, adapting to such a changing
environment.
Trust:
Are resources trustworthy or malicious? If they are malicious, a scheduler needs result
certification in order to ensure the correctness of results. A scheduler can be coupled with
reputation or incentive mechanism in order to select trustworthy resources or exclude malicious
resources

17
3.3 Scheduler's Perspective Considerations A Desktop Grid scheduler should consider the following aspects on the scheduler's perspective
when designing and developing scheduling algorithm
Fig 3.2

18
Fig 3.3
Organization:
A scheduler organization is classified into three categories: centralized, distributed, and
hierarchical according to where and how scheduling decision is made .In the centralized
approach, there is a central server that is responsible for scheduling decision. A central server
maintains all information of resources and task execution status. In the distributed approach,
scheduling decision is distributed to every node. Each node has the partial information about the
resources and task execution status. In the hierarchical approach, the scheduling decision is
performed in a hierarchical way (for example, Meta scheduler (high-level scheduler) and local
scheduler (low-level scheduler)). High-lever scheduler allocates tasks to low-level schedulers,
whereas low-lever scheduler directly allocates tasks to machines within its site.
Mode: Where is a scheduling event initiated? In the pull mode, a scheduling event is initiated
resource. In other words, when a resource is idle or highly-loaded, it requests (or pulls) tasks
from its server. In the push mode, a scheduler collects resource information, and then pushes
tasks to resources. Generally, the pull mode is useful if resources may be behind NAT (network-
address translators) or firewall, or if they are not dedicated or volatile

19
Policy:
Scheduling policy is used to match tasks with resources. It determines how to select appropriate
tasks or resources. It is classified into three categories: simple, model-based, and heuristics-
based. In the simple approach, tasks or resources are selected by using FCFS (First Come First
Served) or randomly. The model-based approach is categorized into deterministic, economy, and
probabilistic models. The deterministic model is based on structure or topology such as queue,
stack, tree, or ring. Tasks or resources are deterministically selected according to the properties
of structure or topology. In the heuristics-based approach, tasks or resources are selected by
ranking, matching, and exclusion methods on the basis of performance, capability, weight,
precedence, workload, availability, location, reputation/trust, etc.
The ranking method ranks the resources or tasks according to criteria and then chooses the most
or the worst one. The matching method chooses the most suitable tasks and resources in
accordance to evaluation functions (for example, min-min, max-min, suffrage, etc. The exclusion
method excludes resources according to criteria, and then chooses the most appropriate one
among the survivors.
Grouping:
Grouping is used to form resources or tasks into a group. In the application-oriented grouping
approach, a set of jobs are grouped logically. Particularly, dependent tasks are grouped together
on the basis of dependency or weight (communication or computation) in DAG in order to
reduce communication cost or improve performance. In addition, tasks are grouped together so
that a set of tasks that uses the same data is allocated to one node . The resource-oriented
grouping approach ensures that resources with similar properties are logically grouped together.
Resource-oriented grouping approach constructs CON (Computational Overlay Network).The
characteristics and topology of CON affect scheduling algorithm, resource management, and
information management.
Object:
Scheduling decision is made in an application-oriented or resource-oriented way according to
the target of scheduling. The application-oriented approach focuses on job selection, partition,
and grouping. On the other hand, resource-oriented approach emphasizes resource selection and
grouping.
Dynamism:
Scheduling is categorized into static and dynamic according to whether the information of jobs
and resources is known or available, and when scheduling decision is made. In the case of static
scheduling, the prior information is assumed to be available. Static scheduling considers the
entire tasks during decision making. In the case of dynamic scheduling, little a prior knowledge
is available.

20
Application type:
Compute-intensive scheduling focuses on how tasks are assigned to resources according to
resources' properties. Data-intensive scheduling focuses on data such as data size and location,
the cost of transfer, replication policy, or data dependency.
Dependency:
Dependent job scheduling (that is, workflow scheduling) focuses on task and data dependency
and synchronization between tasks in order to minimize the overall execution time of DAG.
Independent job scheduling focuses on distribution of independent tasks to each machine
according to machine's availability and capability, in order to complete as many tasks as
possible, concurrently.
Deadline:
Deadline scheduling distributes tasks to resources only if the resources are able to (that is, hard
deadline) or are likely to (that is, soft deadline) complete the task by its deadline.
Preemption: Preemptive scheduling considers task's priority. It allows a high-priority task to preempt a low-
priority task running on a machine. In non-preemptive scheduling, a machine is allowed to
execute another task only after finishing a task
Opportunistic scheduling:
Opportunistic scheduling is to use resources as quickly as possible, when they are idle or
available. It can be easily cooperated with the pull mode.
Reputation/incentive-based scheduling:
Reputation/incentive based scheduling evaluates resources in order to select more-qualified
resources. If resources are selfish (non-dedicated), distrusted, volatile, or faulty, a reputation-
based or an incentive based scheduling is needed to exclude these resources or to encourage
resource's owners to provide their resources reliably, eagerly, and trustworthily.
Adaptive scheduling:
Adaptive scheduling takes environmental stimuli into account to adapt to dynamically changing
environment .The environmental change leads to modifying the scheduling policy. Adaptive
scheduling is classified into migration, redundant reassignment, and change-policy or topology.
In the migration approach, a task is moved from one node to another node. In the redundant
reassignment approach, the task that a slow resource does not complete within timeout is
reassigned to other resources. This leads to replication. In the change-policy or topology
approach, scheduling policy or topology is switched in accordance with environmental change.
For example, in a tree topology, fast nodes move towards a root node. Or, in the SA (Switching
Algorithm), MCT (Minimum Completion time) heuristic is switched to MET (Minimum
Execution Time) depending on the load distribution threshold across the nodes.

21
Fault tolerant scheduling:
Fault tolerant scheduling tolerates failure as well as volatility. It is classified into checkpoint &
restart, reassignment, replication, and result certification. In the checkpoint & restart approach, if
a scheduler detects failure of resource, it restarts the failed task at another resource from the
checkpoint. In the reassignment approach, if a scheduler detects failure of resources, it reassigns
the failed task to another node. In the replication approach, a scheduler replicates the same task
to multiple nodes. Even though one of them fails, the others mask the failure. Result certification
approach tolerates malicious resources or a variety of hardware and software malfunctions. As a
result, it guarantees the correctness of results.
Load sharing or balancing:
Load sharing or balancing is categorized into work stealing and redistribution. In the work
stealing approach, a lightly-loaded node or idle node steals (or pulls) tasks from a heavily-loaded
node. On the contrary, in the redistribution approach, a heavily-loaded node transfers (or pushes)
tasks to a lightly-loaded node or idle node.
Scheduling goals:
A scheduler tries to achieve its own scheduling goals. It chooses appropriate scheduling policies
and algorithms according to its goals such as turnaround time, throughput, deadline, price, load
balance, and reliability.

22
4. System Model
A new execution model and a failure model here.
4.1 Execution Model
This report considers a centralized DG and volunteer DG computing environment. In such an
environment, a new execution model has been proposed. The execution model consists of eight
phases: registration, job submission, resource grouping, task allocation, task execution, task
result return, result certification, and job result return phase as shown in the given figure, a
resource grouping phase has been added to existing execution model.
The rest of the phases are the same as existing centralized DG. In the registration phase,
volunteers register basic properties such as CPU, memory, OS as well as additional properties
such as , volunteering time, availability, credibility, etc. The additional properties reflect dynamical Desktop Grid computing. In the resource grouping phase, a server constructs groups
according to capability, volatility, availability, reputation, and trust of volunteers. Scheduling is
performed, depending on the characteristics of groups. In the task allocation phase, a server
allocates tasks to volunteers on a group basis. In other words, it applies scheduling, replication,
and result certification algorithms to each group. In the presence of failures, a server reschedules
the failed tasks according to fault tolerant algorithm. In the result certification phase, a server
checks the correctness of the returned results on the basis of group.

23
4.2 Failure Model
In a Desktop Grid computing environment, volunteers are connected through the Internet, and
therefore are exposed to crash and link failures. In addition, since Desktop Grid computing is
based on voluntary participants, the autonomy of volunteers is respected. In other words,
volunteers can leave arbitrarily in the middle of public execution and are allowed to interrupt
public execution at any time. In a Desktop Grid computing environment, volunteer autonomy
failures occur much more frequently than crash and link failures. Therefore, volunteer autonomy
failures should specially be dealt with, while they are distinguished from traditional failures.
Moreover, volunteers have various occurrence rates and types of volunteer autonomy failures.
Since the heterogeneous occurrence rates and types of volunteer autonomy failures affect
computation directly, a scheduling mechanism must take them into account in order to obtain
better performance and guarantee reliable computation. To this end, volunteer autonomy failures
are first defined conceptually.
In order to clarify definition of volunteer autonomy failures, the notations given are used. First,
the join and leave patterns of a volunteer are categorized. The patterns are categorized into
expected join (EJ), expected leave (EL), unexpected join (UJ), and unexpected leave (UL).
UJ is categorized into before-unexpected-join UJb, middle-unexpected-join UJm, and after-
unexpected-join UJa. In addition, unexpected-leave UL is categorized into before-unexpected-
leave ULb, middle-unexpected-leave ULm, and after-unexpected-leave ULa.

24

25
5. Group-based Adaptive Scheduling
Mechanism
A new a resource grouping method is introduced, which classifies and constructs various groups
according to volunteer's properties such as dedication, volatility, availability, credibility, etc.
Then, it proposes group-based adaptive scheduling mechanisms, which apply scheduling,
replication, result certification, and fault tolerant algorithms to each group.
5.1 Resource Grouping Method
Resource grouping provides a method of forming volunteer groups which is a set of volunteers
that have similar properties such as dedication, volatility, failure, and trust. In order to apply
different scheduling mechanisms suitable for the properties of volunteers in a scheduling
procedure, volunteers are required to first be formed into homogeneous groups. First, volunteers
are classified according to their properties. Then, volunteer groups are constructed and
characterized.
When volunteers are classified, their CPU, memory, storage, and network capacities are
important factors. The most important factors, however, are location, volunteering time,
volunteer autonomy failures, volunteer availability, and volunteer credibility in the sense that the
completion and continuity of computation, the reliability and correctness of results, and
performance are tightly related with dedication, volatility, failure, and trust. In a Desktop Grid
computing environment, the capacities of desktop computers are very heterogeneous, and the
degree of volatility, dedication, and trust fluctuate considerably during execution.
Volatility means that volunteers can leave in the middle of public execution. Volunteers also are
exposed to crash and link failures because they are connected through Internet. Volatility and
failures lead to the delay and blocking of the execution of tasks and even partial or entire loss of
the executions. Thus, they are tightly related with reliability of computation. Volunteer
availability has been defined to express volatility and failures as follows:
Volunteer availability (αv) is the probability that a volunteer will be correctly operational
and be able
to perform public execution.
Here, the MTTVAF represents "mean time to volunteer autonomy failures" and the MTTR
represents "mean time to rejoin". The MTTVAF represents the average time before the volunteer
autonomy failures happen, and the MTTR means the mean duration of volunteer autonomy
failures. The αv reflects the degree of volunteer autonomy failures, whereas the traditional
availability in distributed systems is mainly related with the crash failure

26
MTTVAF and MTTR are recalculated dynamically when a volunteer detects φ and ψ. Here, MVT
represents "mean volunteering time".
Cases 1 and 2 describe how to calculate volunteer availability in the case of volunteer volatility
failure and unexpected-join. Case 3 describes how to calculate volunteer availability when
volunteer interference failure occurs. The parameter µ is used in order to reflect the rate and
frequency of volunteer autonomy failures into volunteer availability.
Dedication and Volunteer Service Time
Dedication means that how much volunteers participate in public execution. Dedication is related
with donation (or participation) time. A volunteer can be eager or selfish according to degree of
dedication. volunteering time and volunteer service time has been defined to express the degree
of dedication as follows:

27
Volunteering time (γ) is the period when a volunteer is supposed to donate its resources.
γ = γR + γS
the reserved volunteering time γR represents the reserved time when a volunteer provides
computing resources. The selfish volunteering time (γS) represents unexpected volunteering time.
Thus, a volunteer usually performs private execution during the γS and sometimes performs
public execution.
Volunteering service time (θ) is the expected service time when a volunteer participates in the
public execution during γ.
θ = γ × αv
Volunteer credibility Cv is the probability that the result produced by a volunteer is correct.
Here, ER represents the number of erroneous results, CR represents the number of correct results,
and IR represents the number of incomplete results. ER + CR + IR means the total number of
tasks that a volunteer executes.
5.2 Constructing and Characterizing Volunteer Groups
Classification I Volunteers are categorized into four classes according to αv and θ.
Volunteers are first categorized into region volunteers or home volunteers according to their
location. Home volunteers are defined as resource donators at home. Region volunteers are a set
of resource donators that are generally affiliated with organizations including universities,
institutions, and so on. Region volunteers are connected to LAN or Intranet, whereas home
volunteers are connected to the Internet. Volunteers are categorized into four classes according to
γ and αv.
The class A is a set of volunteers that have long γ and high αv. The class B is a set of
volunteers that have short γ and high αv. The class C is a set of volunteers that have long γ and low
αv. The class D is a set of volunteers that have short γ and low αv. A server selects volunteers as
volunteer group members according to the properties of volunteers such as location, volunteer
availability, and volunteering service time. When both αv and θ are considered in grouping the
volunteers, the volunteer groups are categorized into four classes. Here, is the expected
computation time of a task.

28
Volunteers are classified into four classes: A’, B’, C’, and D’ volunteer groups. If volunteers
have a high αv and θ ≥ they are included in the class A’. If volunteers have a high αv and θ <
, they are included in the class B. Volunteers have a low αv and θ ≥ , they are included in
the class C’. If volunteers have a low αv and θ < , they are included in the class D’
.
Volunteer groups are constructed using the algorithm of volunteer group construction.
1) The registered volunteers are classified into home or region volunteers, depending on
their location.
2) The home and region volunteers are classified into A, B, C, and D classes by
volunteering time and volunteer availability, respectively.
3) The volunteer groups are constructed according to volunteering service time and
volunteer availability.
Classification II according to αv, θ, and Cv.
Volunteers are categorized into four classes according to αv, θ, and Cv. First, the registered
volunteers are classified into A’, B’, C’, and D’ classes depending on volunteering service time
and volunteer availability as shown. Then, the classified volunteers are classified into each
29
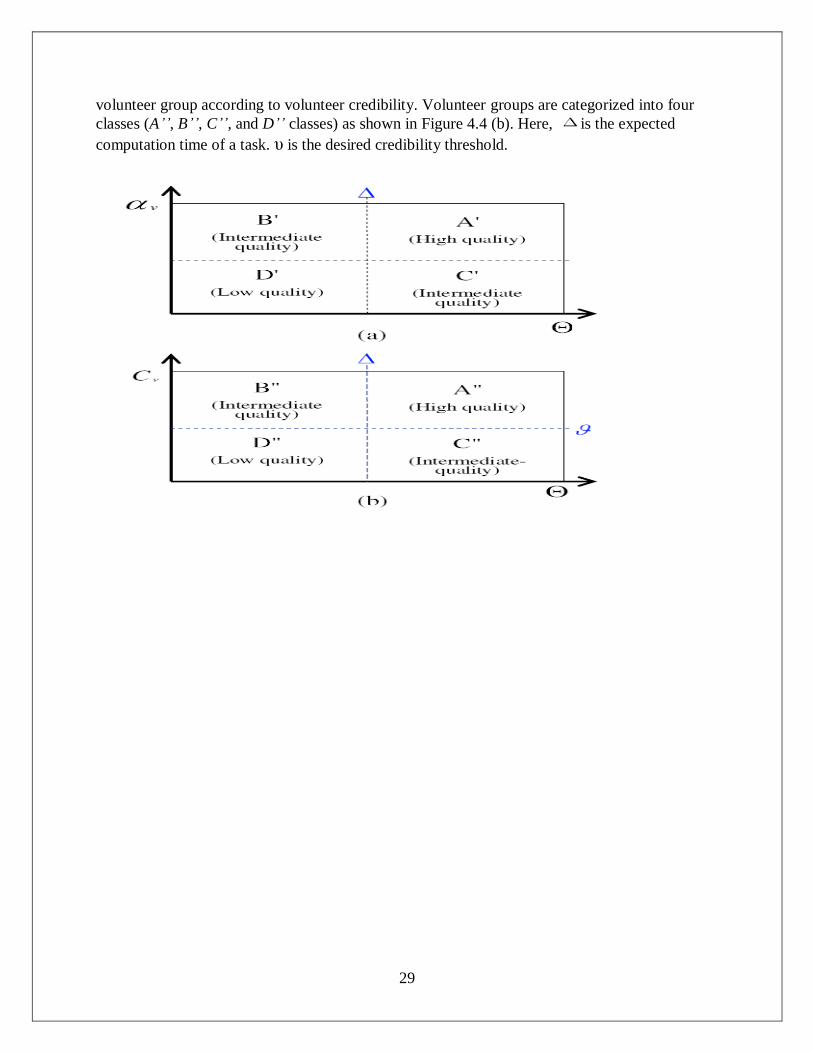
volunteer group according to volunteer credibility. Volunteer groups are categorized into four
classes (A’’, B’’, C’’, and D’’ classes) as shown in Figure 4.4 (b). Here, is the expected
computation time of a task. υ is the desired credibility threshold.

30
5.3 Agent-based Group Scheduling
In existing Desktop Grid computing system, a server suffers from high overhead. A
server maintains properties of volunteers such as CPU, memory, OS, location (address), and so
on. According to the properties, the server has responsibility for scheduling in a centralized way.
In addition, the server performs the fault tolerant mechanism if volunteers fail. Since a
scheduling mechanism is performed only by the server, various scheduling mechanisms are not
performed at a time according to volunteer properties. To solve these problems, mobile agent
technology has been used.
Mobile agent is a software program that migrates from one node to another while performing
some tasks on behalf of a user Mobile agent has some benefits as follows
1) A mobile agent can reduce network load and latency by dispatching the agents to a
remote node which has the required services or data and then executing it locally at the
host.
2) A mobile agent can solve frequent and intermittent disconnection since it executes some
tasks asynchronously and autonomously. Once a mobile agent is dispatched to a
destination node, it does not require direct connection with a user any more. Because a
mobile agent is performed asynchronously and autonomously on behalf of a user even
though a user (that is, mobile device) is disconnected from the network.
3) A mobile agent enables dynamic service customization and software deployment since a
mobile agent encapsulates some services or protocols in mobility entity.
4) A mobile agent can adapt to heterogeneous environment and dynamic changes because it
is computer-independent and transport-independent and also reacts autonomously
according to execution environment.
There are some advantages to make use of mobile agent in Desktop Grid computing
environment.
1) Several scheduling algorithms can be performed at a time according to the properties of
volunteers.
2) A mobile agent can decrease the overhead of server by performing scheduling and fault
tolerance procedures in a decentralized way.
3) A mobile agent can adapt to a dynamical Desktop Grid computing environment
31
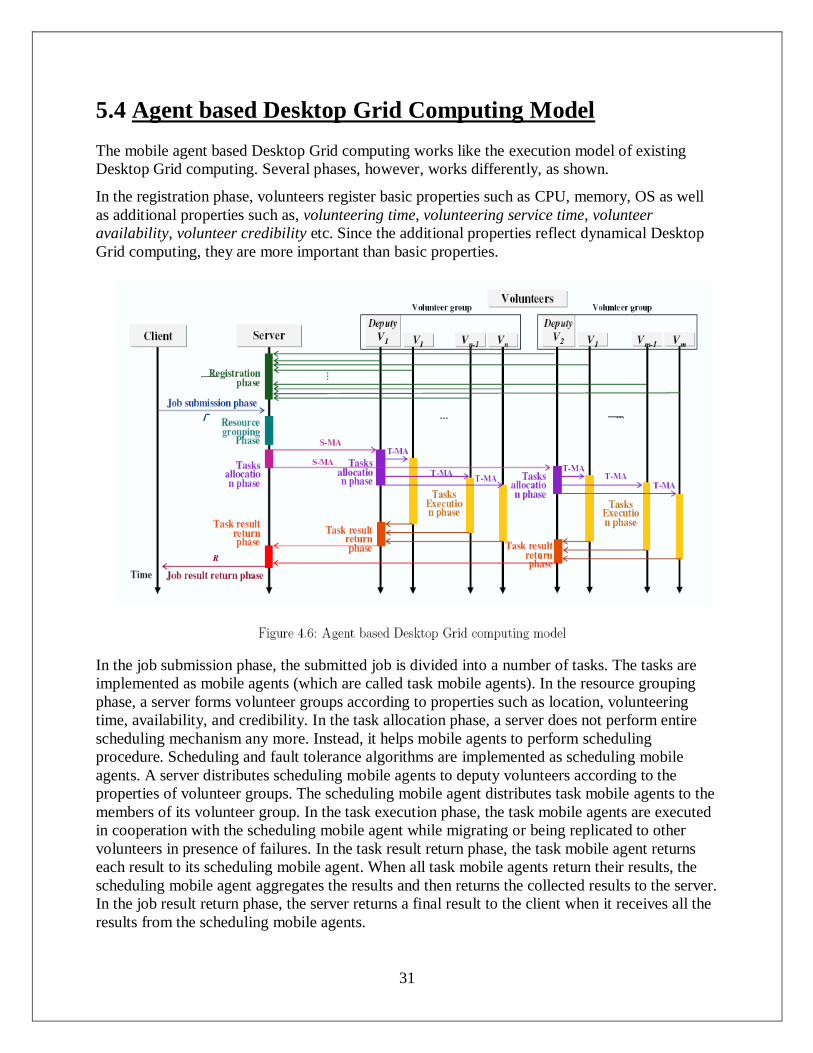
5.4 Agent based Desktop Grid Computing Model
The mobile agent based Desktop Grid computing works like the execution model of existing
Desktop Grid computing. Several phases, however, works differently, as shown.
In the registration phase, volunteers register basic properties such as CPU, memory, OS as well
as additional properties such as, volunteering time, volunteering service time, volunteer
availability, volunteer credibility etc. Since the additional properties reflect dynamical Desktop
Grid computing, they are more important than basic properties.
In the job submission phase, the submitted job is divided into a number of tasks. The tasks are
implemented as mobile agents (which are called task mobile agents). In the resource grouping
phase, a server forms volunteer groups according to properties such as location, volunteering
time, availability, and credibility. In the task allocation phase, a server does not perform entire
scheduling mechanism any more. Instead, it helps mobile agents to perform scheduling
procedure. Scheduling and fault tolerance algorithms are implemented as scheduling mobile
agents. A server distributes scheduling mobile agents to deputy volunteers according to the
properties of volunteer groups. The scheduling mobile agent distributes task mobile agents to the
members of its volunteer group. In the task execution phase, the task mobile agents are executed
in cooperation with the scheduling mobile agent while migrating or being replicated to other
volunteers in presence of failures. In the task result return phase, the task mobile agent returns
each result to its scheduling mobile agent. When all task mobile agents return their results, the
scheduling mobile agent aggregates the results and then returns the collected results to the server.
In the job result return phase, the server returns a final result to the client when it receives all the
results from the scheduling mobile agents.

32
5.5 Allocating Scheduling Agents to Scheduling Groups
After constructing volunteer groups (that is, A’, B’, C’ and D’), a server allocates the scheduling
mobile agents (S-MA) to volunteer groups. However, it is not practical to allocate S-MAs
directly to the volunteer groups in a scheduling procedure because some volunteer groups are not
perfect for finishing the tasks reliably. Therefore, it is necessary to build new scheduling groups
by combining the volunteer groups with each other.
The S-MA is executed at a deputy volunteer. The deputy volunteer is selected using the
algorithm given below in the table. The deputy volunteers are ordered by volunteer availability
and volunteering service time, and also by CPU, hard disk capacity (DC), and network
bandwidth (NB).Then, the deputy volunteers for scheduling groups are selected sequentially.
Next, each S-MA is transmitted to the selected deputy volunteer.

33
5.6 Distributing Task Agents to Group Members
After the S-MAs are allocated to the scheduling groups, each S-MA distributes the task mobile
agents (T-MA) that consist of parallel code and data to the members of the scheduling group.
The S-MAs perform different scheduling, fault tolerance, and replication algorithms according to
the type of volunteer groups, differently from existing Desktop Grid computing systems.
The S-MA of the A’D’ scheduling group performs the scheduling as follows.
1) Order the A’ volunteer group by αv and then by θ.
2) Distribute T-MAs to the arranged members of the A’ volunteer group.
3) If a T-MA fails, replicate the failed task to a new volunteer selected in the A’
volunteer group by using the replication algorithm, or move the task to the volunteer
selected in the A’ or B’ volunteer groups if task migration is allowed.
The S-MA of the C’B’ scheduling group performs the scheduling as follows.
1) Order the C’ and B’ volunteer groups by αv and then by θ.
2) Distribute T-MAs to the arranged members of the C’ volunteer group.
3) If a T-MA fails, replicate the failed task to a new volunteer selected in the ordered C’
volunteer groups, or move the task to a volunteer selected in the B’ or C’ volunteer
groups.

34
6.Group Scheduling for Replication
Replication is a well-known technique to improve reliability and performance in distributed
systems .In a Desktop Grid computing environment, replication is mainly used for reliability,
(that is, to tolerate failures), or for result certification, (that is, to detect and tolerate erroneous
results).
Calculate the Number of Redundancy
The parameter γ is the reliability threshold
In Equation 4.1, the expression represents the reliability of each volunteer group, which
means the probability to complete tasks within ¢. It reflects volunteer autonomy failures. The
means the probability that all replicas fail to complete the replicated tasks
Selection Of Replicas
After deciding the number of redundancy to each volunteer group, our group-based adaptive
replication algorithm selects replicas (that is, volunteers to execute the replicated task) according
to the number of redundancy. Therefore, each volunteer group has many replication groups,
which refer to a set of replicas for a task.

35
Selection in Classification I.
To make a replication group for a task, volunteers within each volunteer group are sorted by
volunteer availability αv and volunteering service time θ. Especially, A’ and C’ volunteer group
is sorted by αv and then by θ, B’ volunteer group is sorted by θ and then by αv. The θ is important
because of insufficient volunteering service time in B’ volunteer group. After each volunteer
group is sorted, the replication groups are constructed according to r.
Selection in Classification II.
To make a replication group for a task, volunteers within each volunteer group are sorted by
volunteer availability αv, volunteering service time θ, and volunteer credibility Cv. Especially,
A00 volunteer group is sorted by αv and then by θ. The Cv does not matter because the value is
beyond the desired credibility in A’’ volunteer group. B’’ volunteer group is sorted by θ and
then by αv. The £ is important because of insufficient volunteering service time in B’’ volunteer
group. C’’ volunteer group is sorted by Cv and the by αv because it has low credibility. After
each volunteer group is sorted, the replication groups are constructed according to r.
Distribution Of Tasks to Replicas The method to distribute a task to replication group is categorized into two approaches: parallel
distribution and sequential distribution as shown. In the Figure , the replication group consists of
volunteers, V0, V1, and V2 (that is, r = 3). With the parallel distribution, the task (Ti) is
distributed to all members at the same time as shown in Figure, and then executed
simultaneously. On the other hand, with the sequential distribution, the task (Ti) is distributed
and executed sequentially as shown in Figure.

36
7.Group Scheduling for Result Certification
Result certification approaches are categorized into majority voting and spot-checking
mechanisms. This group-based scheduling mechanism dynamically applies result certification to
volunteer groups.
Applying Result Certification to Volunteer Group
Result certification is dynamically applied to each volunteer group. The A’’ volunteer group has
high Cv, high θ, and high αv enough to execute tasks reliably. In the case of majority voting,
sequential distribution is more appropriate than parallel one. The A’’ volunteer group performs
spot-checking smaller than C’’ volunteer group. The B’’ volunteer group has high Cv and high
αv, but low θ In the case of majority voting, sequential voting group is more appropriate than
parallel voting group as with A volunteer group. If migration occurs, spot-checking is
additionally performed at a former volunteer as well as migrated volunteer to check their
correctness. The C’’ volunteer group has high θ, but low Cv and low αv .Thus, its results might
be incorrect. The C’’ volunteer group should do more spot-checking in order to strength the
credibility. Parallel voting group is more appropriate than sequential voting group.
Scheduling Algorithm for Result Certification The tasks are scheduled in the following order, that is, A’’, C’’ and B’’ volunteer groups
sequentially, because A’’ and C’’ volunteer groups have enough times to execute tasks In the A’’
volunteer group, scheduling algorithm for result certification is as follows:
1) Order A’’ volunteer group by αv and then by θ.
2) Evaluate the number of redundancy or spot-checking rate.
3) Construct a sequential voting group, or choose some volunteers for spot-checking on
the basis of θ.
4) Distribute tasks in a way of sequential voting group, or allocate special tasks for spot
checking.
5) Check the collected results.
In the B’’ volunteer group, scheduling algorithm for result certification is as follows:
1) Order A’’ volunteer group by θ and then by αv.
2) Same to A’’ volunteer group.
3) Construct a sequential voting group, or choose some volunteers for spot-checking on
the basis of θ.
4)»5) are same as A’’ volunteer group.
4) Especially, B’’ volunteer group must perform additional spot-checking during task
migration because of lack of volunteering service time.
In the C’’ volunteer group, scheduling algorithm for result certification is as follows:
1) Order C’’ volunteer group by Cv and then αv.
2) Evaluate the number of redundancy or spot-checking rate.
3) Construct a parallel voting group, or choose some volunteers for spot-checking on the
basis of Cv.

37
4)»5) are the same as A’’ volunteer group. C’’ volunteer group should handle the
volunteer autonomy failures.
we decide rA as the number of redundancy of A’’ volunteer group. The rB and rC are also
calculated in the same way.
The rate of spot-checking q is also calculated. The final error rate of spot-checking is evaluated
as follows
where, n is the saboteur's share in the total work. s is the sabotage rate of a saboteur.

38
8. Fault Tolerant Algorithm A Desktop Grid system is required to conduct various fault tolerance algorithms in
scheduling procedures according to the occurrence rate and form. To achieve this, we apply
different fault tolerance algorithms according to the property of each volunteer group, while also
distinguishing volunteer autonomy failures from the traditional failures.
A server detects the crash failure of S-MA using a timeout. Similarly, the S-MA detects the crash
failure of T-MA. To achieve this, the S-MA sends alive messages to its server. Similarly, the T-
MA sends alive messages to the S-MA. The T-MAs in the D’ volunteer group do not send alive
messages, in order to reduce the management overhead. A volunteer can detect volunteer
autonomy failures by oneself because its operating system does not shut down. If T-MA or S-
MA detects the volunteer autonomy failures, it notifies its S-MA or server, respectively.
Handling Failure of Scheduling Agent A S-MA rarely suffers from volunteer autonomy failures because it is executed at the deputy
volunteers that are selected among the A’ volunteer group. The S-MA stores information such as
scheduling group lists, scheduling table, and task results in a stable storage. If the S-MA fails, the
information is sent to a new deputy volunteer. If a server detects the crash failure of S-MA, the
new deputy volunteer is selected by the algorithm of deputy volunteer selection. Next, the S-MA
and the scheduling information are sent to the newly selected deputy volunteer. If an S-MA
suffers from the volunteer volatility failure, it sends a Volatility Failure message to the server. If
the S-MA joins again during the volunteering time, it sends Rejoin message to its server. If the
server does not receive a Rejoin message within the interval after receiving a Volatility Failure
message, it sends the S-MA to a new deputy volunteer. If a S-MA is at the edge of reserved
volunteering time, it sends an In Advance Volatility Failure message to its server. In this case,
the server responds with a candidate deputy volunteer. The S-MA migrates to the candidate
deputy volunteer. In the case of volunteer interference failure, a S-MA does not take any action
because it can perform scheduling procedures in the sense that the Desktop Grid system is alive.
Handling Failure of Task Agent A T-MA suffers from volunteer autonomy failures more frequently than a S-MA, because the
volunteer running a T-MA has relatively low availability. The T-MA checkpoints the execution
state at the rate of MTTV AF if check-pointing is used. If a S-MA detects the crash failure of T-
MA, it selects a new volunteer. If check-pointing is used, the S-MA sends the latest check-
pointed T-MA0 to it. Otherwise, the S-MA redistributes the T-MA to the new one. Each S-MA
redistributes the T-MA within the number of redundancy r.
If a T-MA is at the edge of reserved volunteering time, it sends an In Advance Volatility Failure
message to its S-MA. After receiving a candidate volunteer, it migrates to the candidate
volunteer or is replicated. If a T-MA suffers from volunteer volatility failure φ, it takes a check-
point of the execution of task and then notifies its S-MA of φ by means of a Volatility Failure
message. Next, if the S-MA does not receive any Rejoin message from the failed volunteers
within predefined time interval, it reschedules the T-MA. If check-pointing and migration are
used, the S-MA migrates the T-MA’ to a new volunteer. Otherwise, the S-MA replicates the T-
MA by the number of redundancy r.

39
If a T-MA suffers from volunteer interference failure, it takes a checkpoint of the execution.
Then, if the execution is not restarted within the interval, the volunteer sends an Interference
Failure message to its S-MA. After receiving a candidate volunteer, the T-MA migrates to the
candidate volunteer or is replicated.

40
9.Related Works and Differences
Some of the works related to this thesis topic and the differences in their approach are
discussed subsequently.
9.1 “Agent-based Autonomous Scheduling Mechanism Using Availability in
Desktop Grid System” HongSoo Kim, SeockIn Kim, EunJoung Byun, ChongSun Hwang.
This report discusses use of autonomous scheduling mechanisms on a computational
overlay network to meet these challenges of the volatility of volunteers, and the decentralized
nature of desktop grid systems In the environment of high throughput desktop grid systems.
However, current approaches to utilizing desktop resources require either centralized servers, or
extensive knowledge of the underlying system, limiting scalability and performance. In this
paper an Agent-Based Autonomous Scheduling (ABAS) mechanism on a computational overlay
network is proposed to further improve performance through adaptive behavior of agents which
have replication, migration, and check-pointing scheme. Performance evaluation demonstrates
that the proposed scheduling mechanism improves throughput using Korea@Home.
This paper considers some additional parameters besides as discussed in the report like
Volunteer durability Ξ. Volunteer durability is the fraction of the continuous time to volunteer
the resource since completed computation
Durable Time represents the continuance time of the computation since completing a
computation. Application Execution Time represents the execution time of a computation. n is
the number of tasks executed by the volunteer. It can be used as a migration technique using this
parameter. It also describes agent based computation on the Computational overlay network and
it uses autonomous scheduling in it which has almost similar steps to execution and failure
model as described in the report but it involves a load balancing step as well in which initially
submitted jobs are allocated to the coordinators as much as the total number of tasks divided by
the number of coordinators. In intermediate computation, the scheduler achieves load balancing
by periodically moving from minimum load to maximum load between coordinators.
Also concept of durability-based computation migration is discussed which decreases
turn-around time and guarantees continuous computation when volunteering resources for a
given period are volatile. In this case, important issues must be determined for when and where
to perform migration and predict available execution time. In this paper, a profile of the
volunteer is useful in predicting the duration of time that a resource will be available based on
previous availability history. The scheduler determines the migration time according to profile
information, and finds destination volunteers as messages to neighbors to determine the available
volunteer. The destination volunteer is determined, and the source volunteer migrates to the
destination volunteer after stored computing states with data in storage. This method decreases

41
the error rate for migration and considers the error range of the profile. In this case, calculating
the error range of ε is an important issue because it is under influence to reduce the gap between
computations. ε is determined as the mean time to execution history. The kth error range εk is
calculated as a fraction of the previous kth active range for total execution time at a volunteer i as
follows.
In Equation ARk refers to the kth active range of a volunteer, and TET refers to the total
execution time for a task on the profile of volunteer i.
Also this paper proposes a computation replication according to volunteer availability, using
executed time and volunteer availability, based on the history of the volunteer. This calculates
the number of replica n for the task, according to availability of the volunteer, and then n
replicas of the task are executed in n volunteers. Once computation is completed, the results are
returned. The coordinator of the computation group transmits termination messages to other
volunteers executing replicas. We determine the number of replica as follows.
In Equation Θi refers to the mean time for completion time Θk refers to the previous completion
time based on the profile of volunteer i. Θk means the kth task completion time, and k means the
number of completed tasks in volunteer i.
This equation determines to the number of replicas according to availability of volunteer i. In the
equation Θi means the mean time for task completion, and Ψi means executed completion time
without volatile characteristics, in volunteer i. Therefore, Equation (1) calculates the availability
Λi of a volunteer i, and is used to determine the number of computation replicas.

42
9.2 “Volunteer Availability based Fault Tolerant Scheduling Mechanism in
Desktop Grid Computing Environment”. SungJin Choi, MaengSoon Baik, ChongSun Hwang,
In this paper, in order to tolerate volunteer autonomy failures, a new fault tolerant scheduling
mechanism has been proposed. First, a volunteer autonomy failures and an independent live lock
problem is specified. Then, a volunteer availability has been proposed which reflects the degree
of volunteer autonomy failures. Finally, a fault tolerant scheduling mechanism based on
volunteer availability is proposed (which is called VAFTSM).
When existing scheduling mechanisms are applied to volunteer autonomy failures, they have an
independent live lock problem, that is, volunteers do not generate a result of a task even though
they continuously execute the same task. Therefore a volunteer availability based fault tolerant
scheduling mechanism (VAFTSM) has been proposed here. The VAFTSM solves the
independent live lock problem. In addition, the VAFTSM prevents the delay and blocking of the
entire execution of a job, so that it decreases a total execution time of a job. We describe the state
transition of execution of a task in order to define an independent live-lock. The states of
execution of a task are categorized into five states: started, executed, suspended, terminated,
aborted like Fig. 1 We define an independent live-lock problem of execution of a job in a
desktop grid computing environment.
Fig. State Transition Diagram
Cycle C: ξi of Γi is a cycle Cξi if state transition cannot reach a terminate state. Cycle means a
set of state transition which cannot be reachable to a terminate state.
Independent live-lock: ξ of Γ is independent live-lock if there exists Cξi for all volunteers which
execute the same Γi.
Architecture of VAFTSM
A volunteer server has a following components in order to supports fault tolerant scheduling: a
volunteer information manager (VIM), a task scheduling manager (TSM), a task allocation
manager (TAM) and a fault tolerance manager (FTM)

43
Fig. Architecture of VAFTSM
A VIM is responsible for maintaining information of volunteers. The VIM has a volunteers
information pool (VIP) which maintains computing resources information, volunteering time,
volunteer availability, etc. Volunteer availability is updated whenever a volunteer sends a
recalculated volunteer availability. A TSM is responsible for scheduling of tasks. The TSM has a
tasks information pool (TIP). The TIP maintains the scheduling information of the allocated
tasks. If a TSM finishes scheduling of tasks, a TAM distributes the tasks to the corresponding
volunteers. A FTM detects crash and link failures of volunteers by using heartbeat messages. In
addition, if a volunteer detects volunteer autonomy failures, it notifies a FTM of the volunteer
autonomy failures. If a FTM detects crash failure, or if a FTM is notified of volunteer autonomy
failures, it informs the failures of a TSM. The TSM selects an appropriate volunteer candidate
among volunteers in a VIP on the basis of volunteer availability and volunteering time, and then
performs a fault tolerant scheduling mechanism
Algorithm of VAFTSM
The VAFTSM uses adaptive replication for a fault tolerant scheduling in the presence of crash
failure and volunteer autonomy failures. Adaptive replication is to adaptively replicate original
execution to several volunteers and restart the replicated execution from the beginning.
An algorithm of VAFTSM consists of four phases: initial scheduling, adaptive scheduling, fault
tolerant scheduling and adaptive rescheduling phases.
Initial scheduling phase (ISP): A TSM schedules volunteers which have already logged in
according to Θ.
Adaptive scheduling phase (ASP): After an initial scheduling phase, if the number of volunteers
is greater than the number of tasks, then a TSM performs an adaptive replication according to Θ.
Fault tolerant scheduling phase (FSP): If a FTM detects crash failure or is notified of volunteer
autonomy failures, a TSM performs an adaptive replication for the failed volunteers according to
Θ.
Adaptive rescheduling phase (ARP): If a VIM informs a TSM that new volunteers have been
joined in or some volunteers have finished execution of each task, a TSM reschedules the
volunteers according to Θ by means of an adaptive replication.

44
Evaluation Volunteer availability time at a volunteer is modeled as exponential distribution is assumed.
And also that the number of volunteers which register to a volunteer server is Poisson distributed
.In order to evaluate previous scheduling mechanisms and the VAFTSM, the following
parameters are considered.
Total execution time TT : TT is the sum of each execution time at each volunteer.
Average execution time TA : TA is the average execution
time per a task.
Total execution time TT is calculated as follows. From now on, ES represents eager scheduling.
VA represents VAFTSM.
Here, c is a scheduling counter (c ≥ 0). When a job is submitted from a client, it is divided into
tasks. When the tasks are scheduled, if there are no enough volunteers, scheduling is performed
several times until all the tasks are allocated and the executions of the tasks are finished. The
scheduling counter c is increased every scheduling step. N is the total number of volunteers. tc is
the number of tasks at each scheduling step. pc is the number of volunteers to participate at each
scheduling step. sc is the number of volunteers to provides sufficient execution time at each
scheduling step. dc is the number of volunteers which have done execution of each task at a
previous scheduling step and participate at a current scheduling step. The pc, sc and dc are
calculated by functions ParticipatedV(), SufficientV() and DoneV(), respectively. α is a
participation parameter which affects the number of volunteers which participates at each
scheduling step. For example, as α gets to be larger, the number of volunteers participating at the
first scheduling steps becomes smaller. On the other hand, the number of volunteers participating
at the last scheduling steps becomes larger. λ is a volunteer availability time parameter which
means the volunteer autonomy failures rate of the systems. If a volunteer have a λ, the expected
life is 1 /λ. The larger λ becomes, the smaller volunteer availability time becomes. In case of an
eager scheduling, pc, sc and dc are calculated as follows.
In the VAFTSM, pc, sc and dc are calculated as follows.

45
Average execution time is calculated as follows. Here, t means the number of task.
The VAFTSM prevents the delay and blocking of entire execution of tasks in the presence of
volunteer autonomy failures, so it decreases the total and average execution times of tasks and
guarantees the completion of execution of tasks. The total execution time of VAFTSM is lower
than that of the eager scheduling is approved by experiments.

46
10. Limitations of existing scheduling
mechanisms and Recommendations
The following report discusses in detail the various scheduling mechanisms for desktop
grid scheduling. Firstly the Group-based Adaptive Scheduling Mechanism in Desktop Grid is
discussed where provide scheduling mechanisms on a per group basis which adapts to a dynamic
Desktop Grid computing environment. In other words, they apply different scheduling
algorithms to each group according to volunteer's properties such as dedication, volatility,
availability, and credibility. Then it applies different scheduling, replication, result certification,
and fault tolerance algorithms to each group. Consequently, it improves reliability and
performance.
However, the discussed scheduling mechanisms still face some major challenges which
are described here and some recommendations for the same are given along with the challenges:
Difficulty to manage heterogeneous volunteers and coping up with dynamic changes
in volunteer availability hence a scheduling algorithm must be implemented to
dynamically calculate the volunteer availability based on the history of volunteer.
Personal computers not effective as super computers in grid scheduling hence a
performance based merit list of volunteers must be constructed and the load must be
distributed according to the rating given.
Desktop Grid resources are highly-volatile, non-dedicated, and highly-heterogeneous, They also are more malicious, unreliable, and faulty than supercomputers and are also
difficult to make a group with the amount of heterogeneity and hence a replication
mechanism which considers the heterogeneity also besides all above parameters
which have been discussed in the report.
Desktop Grid resources are administrated by individual users, and hence they cannot
be expected to have trustworthy availability time and dedication .But a solution to this
problem is that the scheduling algorithm must also consider the domain of the
personal computer i.e. whether it belongs to which location and whether it is at a
public place like or a personal computer at home. According to the location the
desktop must be grouped according to the available time, since a public place like
office have a specific working hours after and before which the computers are idle
and will have 100% availability and there should be an information kept as a record
that at what times the desktops are 100% available and this in turn will increase the
performance significantly.
Desktop Grid tries to achieve high throughput (that is, the amount of work that
desktop computers can do within a given time period), but fails to achieve high
performance hence performance analysation must be considered seriously.
Considering a Centralized Desktop Grid system which consists of client server,
volunteer with a huge overhead on server to manage volunteer and distribute tasks. If
the server fails then the entire scheduling mechanism is of no use. Hence a scheduling
mechanism should be considered in which if a server fails during the execution of a
task , then an alternate server should be available for implementing the various
mechanisms .i.e. a free volunteer with a very high MTTVAF and a very high
volunteering time with high credibility should be assigned as an alternate server and it

47
should be selected by a dynamic merit list which chooses server satisfying a certain
threshold for credibility ,volunteer availability and list must be updated after
execution of tasks.
All the volunteers are autonomous and it’s a great difficulty in maintain records of
volunteers hence a dedicated desktop should be used to keep the track of all the
volunteers and their location, and group (whether they belong to public places or
home).
Considering the various phases in execution model and failure models, a significant
amount of time lost during registration phase which is called initial set up time and
then after job submission phase time lag in task allocation phase a, task result return
phase, result certification phase time lag. Hence time lag should be utilized between
these events by keeping a buffer volunteer for more job submission to achieve high
performance.
The proposed scheduling mechanisms have a big limitation in terms of the time factor
to execute a task ,like if a certain application requires the execution of a task in real
time in a very short duration (for example which is even less than time lag between
job submission phase and task allocation phase) .Hence there must be processing
time threshold set for the real time applications while assigning tasks to the scheduler
and a priority mechanism for real time applications in which a high priority
application preempts a low priority application to get quick results and correct job
must be assigned to correct nodes as per time threshold ,result correctness, volunteer
availability.
While assigning a task to the nodes ,higher priority must be given to nodes which are
located closely and have homogeneous properties so that the communication cost
between the nodes is minimized and for even making replicas the adjacent or nearby
nodes should be given priority over the nodes which are at a significant distance so
that the time lag is minimum and correct results are produced quickly and the node
gets free for another sub task execution which increases the performance of the
desktop grid.
While forming volunteer groups, resource heterogeneity (CPU, memory, bandwidth,
OS type, etc) must be also considered because resources having similar properties
will form a more trustworthy and credible group which will have a definite
processing time for the tasks and hence the threshold time for assigning tasks can be
easily calculated if the sources are in same domain (like same institution).
There must be a load sharing and balancing based on volunteer grouping such that the
faster and reliable group must be assigned the heavier task (the task which is data
intensive or computation intensive).
Distributed Desktop Grid has recently emerged as an alternative of centralized
Desktop Grid because it can solve the overhead and scalability of centralized Desktop
Grid. However, distributed Desktop Grid needs to construct computational overlay
network (CON) for efficient scheduling, and to equip with a distributed scheduling
because there is no central server. Existing decentralized Desktop Grid systems
provide how to construct a CON depending on time zone, performance, or work-
load, but they do not consider volatility, volunteering time, credibility, and
reputation/trust, which directly affect reliability, completion time, and result
correctness. They also do not consider these properties during scheduling.

48
Particularly, they do not provide replication or result certification mechanism. . Hence
there is a need to develop a new CON construction method and a new distributed
scheduling algorithm, which are coupled with replication and result certification.
There is a need to add job migration mechanism to the VAFTSM in order to resume
execution continuously from the an intermediate checkpoint at another node
in case of crash failure.

49
11. Conclusion
This thesis discusses the key concepts and characteristics about Desktop Grid. It also
provides a new comprehensive taxonomy and survey of Desktop Grid. The challenging issues for
Desktop Grid scheduling such as volatility, dynamic environment, lack of trust, failure,
heterogeneity, scalability, and voluntary participation have been discussed in detail in the report.
To overcome these challenges, following scheduling mechanisms such as resource grouping,
reputation or incentive-based scheduling, scheduling for result certification, dynamic, adaptive,
or fault tolerant scheduling, distributed scheduling, agent-based autonomous scheduling
mechanism using availability, volunteer availability based fault tolerant scheduling mechanism
have been discussed in detail. The experimental results have shown that the proposed scheduling
mechanism obtains better performance and reduces the overhead of computation and it improves
reliability and performance..
Reputation-based scheduling can choose more high qualified resources, so that it can
improve the reliability and performance. An incentive-based scheduling focuses on punishing
(for example, exclusion) volatile, selfish, or malicious resources. In the case of replication, the
proposed scheduling mechanism completes more task than earlier mechanisms like eager
scheduling. With simulated experiments it has been found that group-based scheduling
mechanism for result certification completes more tasks than existing eager scheduling
mechanism, while satisfying the desired credibility threshold.
The volunteer autonomy failures result in an independent live lock problem. Therefore, in
order to solve the independent live lock problem, a volunteer availability based fault tolerant
scheduling mechanism (VAFTSM) was proposed. The VAFTSM performs task scheduling
according to a volunteer availability which reflects the volunteer autonomy. In addition, it deals
with the volunteer autonomy failures by using an adaptive replication, so it prevents the
independent live lock problem. Consequently, the VAFTSM prevents the delay and blocking of
entire execution of tasks in the presence of volunteer autonomy failures, so it decreases the total
and average execution times of tasks and guarantees the completion of execution of tasks. The
total execution time of VAFTSM is lower than that of the eager scheduling.
Also an agent-based Autonomous scheduling mechanism through coordinator-initiated
computational overlay network in desktop grid systems is proposed. First, a classification and
organization strategy, according to volunteer availability, volunteer durability, and locality, is
pro- posed. Second, an agent-based autonomous scheduling mechanism is proposed, such as
autonomous scheduling with an durability-based migration and an availability-based
computational replication scheme .Agent scheduling policy can be classified as optimistic or
pessimistic. The former can be applied to volunteers for a long given period, as a profile of the
volunteer. In this case, if a volunteer leaves computation during a given period in a profile, local
checkpoint policy is applied; and, if the computation is uncompleted until it is a given
volunteering time, it is migrated to an another time slot of an available volunteer. Through
continuous execution as elimination of a gap between computations, the scheduler guarantees
fast turnaround time. The latter can be applied to volunteers frequently leaving and joining the
computation during a volunteering period. The volunteers can achieve high throughput as local
checkpoint or computation replication policy.

50
References
[1] SungJin Choi, “Group-based Adaptive Scheduling Mechanism in Desktop Grid”, PHD
Thesis Report, Department of Computer Science and Engineering, Graduate School, Korea
University, June 2007.
[2] HongSoo Kim, SeockIn Kim, EunJoung Byun,ChongSun Hwang, “Agent-based
Autonomous Scheduling Mechanism Using Availability in Desktop Grid Systems”, Proceedings
of the 15th International Conference on Computing (CIC),2006.
[3] SungJin Choi, MaengSoon Baik, ChongSun Hwang, “Volunteer Availability based Fault
Tolerant Scheduling Mechanism in Desktop Grid Computing Environment”, Proceedings of the
Third IEEE International Symposium on Network Computing and Applications (NCA),2004.
[4] Issam Al-Azzoni and Douglas G. Down, “Dynamic Scheduling for Heterogeneous Desktop
Grids”, 9th Grid Computing Conference , 2008.
[5] Nicolae-Zoran Constantinescu-Fülöp, “A Desktop Grid Computing Approach for Scientific
Computing and Visualization”, doctoral thesis report, Department of Computer and Information
Science, Faculty of Information Technology, Mathematics and Electrical Engineering,
Norwegian University of Science and Technology, May 2008
[6] Patricio Domingue, Artur Andrzejak, Luis Silva, “Scheduling for Fast Turnaround Time on
Institutional Desktop grid”, CoreGRID Technical Report Number TR-0027, 1School of
Technology and Management - Polytechnic Institute of Leiria, Portugal, January 30, 2006
[7] S. J. Mason, R. R. Hill, L. Mönch, O. Rose, T. Jefferson, J. W. Fowler eds, “High
Performance Spreadsheet Simulation On A Desktop Grid”, Proceedings of the 2008 Winter
Simulation Conference, Thailand, 2006.
Web:
www.wikipedia.org/wiki/Grid_computing
www.idi.ntnu.no/research/doctor_theses/zoran.pdf
www.serine.umiacs.umd.edu/research/grid.php
www.artima.com/articles/desktop_grid.html