detecting spam blogs: an adaptive online approach pranam kolari
DESCRIPTION
Detecting Spam Blogs: An Adaptive Online Approach Pranam Kolari. Ph.D. Defense, Sept 25, 2007. THESIS STATEMENT. It is possible to develop an effective, efficient and adaptive system to detect spam blogs. CONTRIBUTIONS. a principled study of the characteristics of the problem, - PowerPoint PPT PresentationTRANSCRIPT

Detecting Spam Blogs:
An Adaptive Online Approach
Pranam KolariPh.D. Defense, Sept 25, 2007

THESIS STATEMENT
It is possible to develop an effective, efficient and adaptive system to detect spam blogs.

CONTRIBUTIONS
(i) a principled study of the characteristics of the problem,
(ii) a well motivated feature discovery effort,
(iii) a cost-sensitive, real-time filtering implementation, and
(iv) an ensemble driven classifier co-evolution.

• Introduction
• Characterization
• Feature Discovery
• Cost-aware pipeline
• Adaptive Classifiers
• Evaluation
• Conclusions
• Future Directions
OUTLINE

WHAT IS SPAM?
• “Unsolicited usually commercial e-mail sent to a large number of addresses” – Merriam Webster Online
• As the Internet has supported new applications, many other forms are common, requiring a much broader definition
Capturing user attention unjustifiably in Internet enabled applications (e-mail,
Web, Social Media etc..)

DIRECT INDIRECT
E-Mail Spam
General Web Spam
Spam Blogs (Splogs)
SPAM TAXONOMY
IM Spam (SPIM)
Spamdexing
INTERNET SPAM
[Forms]
[Mechanisms]
Social Network Spam
Comment Spam
Bookmark Spam
Social Media Spam

SPAMDEXING
Spam pages,Spam Blogs,Spam Comments,Guestbook SpamWiki Spam
SERP
Search Engines
Affiliate ProgramsContext Ads
ads/affiliate linksarbitrage
in-links
spamdex
JavaScript Redirect
Affiliate Program Buyers
Spam pages,Spam Blogs[DOORWAY]
Spammer owneddomains
(i)
(ii)
(iii)

SPAM BLOG
Auto-generated and/or Plagiarized Content
Advertisements inProfitable Contexts
Link Farms to promoteother spam pages

• Introduction
• Characterization
• Feature Discovery
• Cost-aware pipeline
• Adaptive Classifiers
• Evaluation
• Conclusions
• Future Directions
OUTLINE

CONTRIBUTIONS
(i) a principled study of the characteristics of the problem,
(ii) a well motivated feature discovery effort,
(iii) a cost-sensitive, real-time filtering implementation, and
(iv) an ensemble driven classifier co-evolution.

• WorldNet defines characterize as “to describe or portray the characters or the qualities or peculiarities”
• Our efforts– Define and Scope the Problem– Field Study– Principled Empirical Analysis– Publicize and solicit feedback
CHARACTERIZATION

Update Pings
Update Pings
Ping Stream
1
2
Fetch Content 3
Splog Filtering between steps 2 and 3 (Pre-indexing) , used by blog harvester
SCOPE

• Bias of Search engines to blogs– through quick indexing (ping servers)– and higher relevance (temporal)
• Availability of third party blogging platforms – providing service for free– supporting programmatic content injection– enjoying high authority and trust (e.g. blogspot)– enabling obfuscation (doorways) to search
engines and DMCA notices
BLOGS & SPAMDEXING

56% of all active blogs are splogs! (2007)
SPLOGS BY NUMBERS
• 75% of update pings (eBiquity 2006)• 20% of indexed Blogosphere (Umbria 2006)• 56% of update pings (eBiquity 2007)

• Given a blog, is it authentic or spam?
• Explore evidence space– Contents of the Blogs (Local Attributes)
– Evidence from Neighbors (Global Attributes)
SPLOG DETECTION PROBLEM
P(splog(x)/ O(x))
P(splog(x)/ L(x))

EXISTING CONTEXTSE-MAIL WEB BLOGS
time time/posts
• Image Spam, • Character Salad
• Scripts, Doorways • Scripts, Doorways• Temporal Deception
• Users• E-mail Service Provider
• Search Engines• Page Hosting Services (e.g. Tripod)
• Web Search Engines• Blog Search Engines• Blog Hosting Services• (Ping Servers)
• Fast Detection• Low Overhead• Online
• Batch Detection• Mostly Offline
• Fast Detection• Low Overhead
NATURE
WHO USES IT?
CONSTRAINTS
ATTACKS

• Local Content (Drost et al, 2005)– using TFIDF word-features, specialized
features etc. • Statistical Properties (Fetterly et al, 2004)
– using page updates, identical pages through page-stitching
• Trust-Rank (Gyongi et al, 2004)– As an extension to Page-Rank
• Splog Detection (Salvetti et al, Lin et al)
RELATED WORK – WEB SPAM

• Introduction
• Characterization
• Feature Discovery
• Cost-aware pipeline
• Adaptive Classifiers
• Evaluation
• Conclusions
• Future Directions
OUTLINE

CONTRIBUTIONS
(i) a principled study of the characteristics of the problem,
(ii) a well motivated feature discovery effort,
(iii) a cost-sensitive, real-time filtering implementation, and
(iv) an ensemble driven classifier co-evolution.

• Document as vectors in a feature space
• Feature Space– Discovery– Representation– Selection
• Classification Techniques– Support Vector Machines (Discriminative)– Naïve Bayes Classifier (Generative)
• Tools (libsvm, weka)
MACHINE LEARNING CLASSIFICATION
f1, f2, f3 .. fm

• Precision (P)– a measure of correctness of classified
documents
• Recall (R)– a measure of completeness of classified
documents
• F-1 = 2*P*R/(P+R) • ROC AUC* – Area Under the Curve
– a measure of discriminatory power
MACHINE LEARNING EVALUATION
* Presented in Thesis Document

• SPLOG-2005– Sampled Summer 2005 at Technorati– Labeled samples of 700 blogs and 700 splogs– Only Blog-homepages
• SPLOG-2006– Sampled Oct 2006 at Weblogs.com– Labeled samples of 750 blogs and 750 splogs– Blog-homepages + feeds
DATASETS

EXPERIMENTAL SETUP
• Binary feature encoding
• Top 50K selected using frequency count
• SVMs– Default parameters– Linear Kernel
• No stemming or stop word elimination
• Naïve Bayes
• Ten fold cross-validation

URL
2005 2006

URL• 3,4,5 charactergrams from URL• Captures profitable contexts • Highly effective at ping streams• Supports an extremely low cost classifier
2005 2006

WORDS
2005 2006

WORDS
2005 2006
• Words (Text) on a Blog• Previously effective in topic classification• Captures profitable advertising contexts• Interesting Authentic Genre Observed
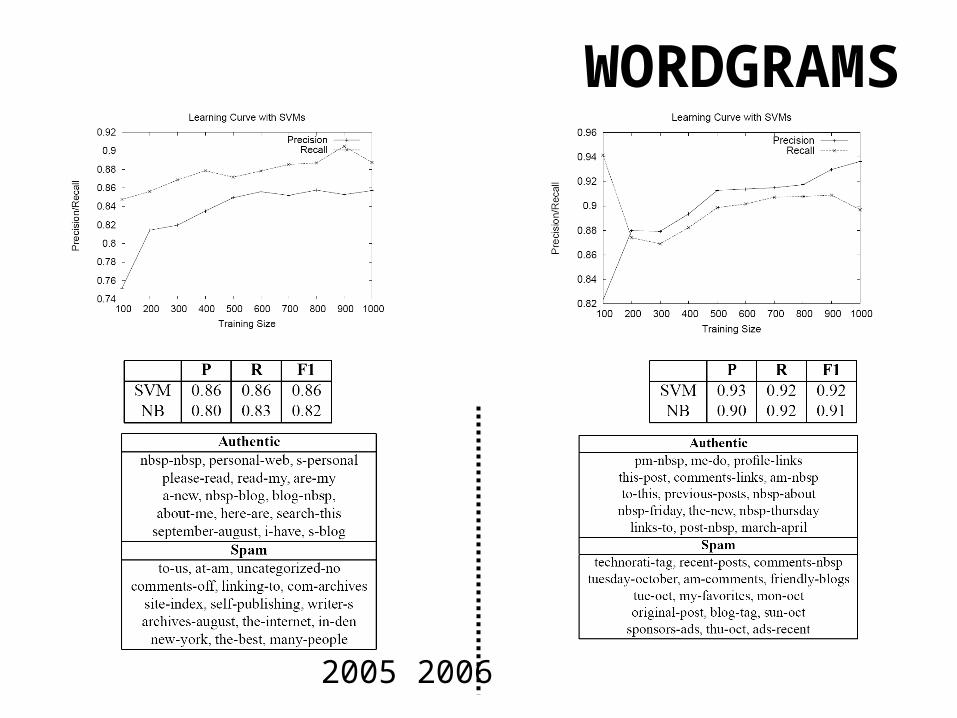
WORDGRAMS
2005 2006

WORDGRAMS
2005 2006
• Word-2-grams, 2 adjacent words• Shallow NLP technique to tackle word salad• Word salad less common in web spam (TFIDF)• Word-x-gram features, exponential with x
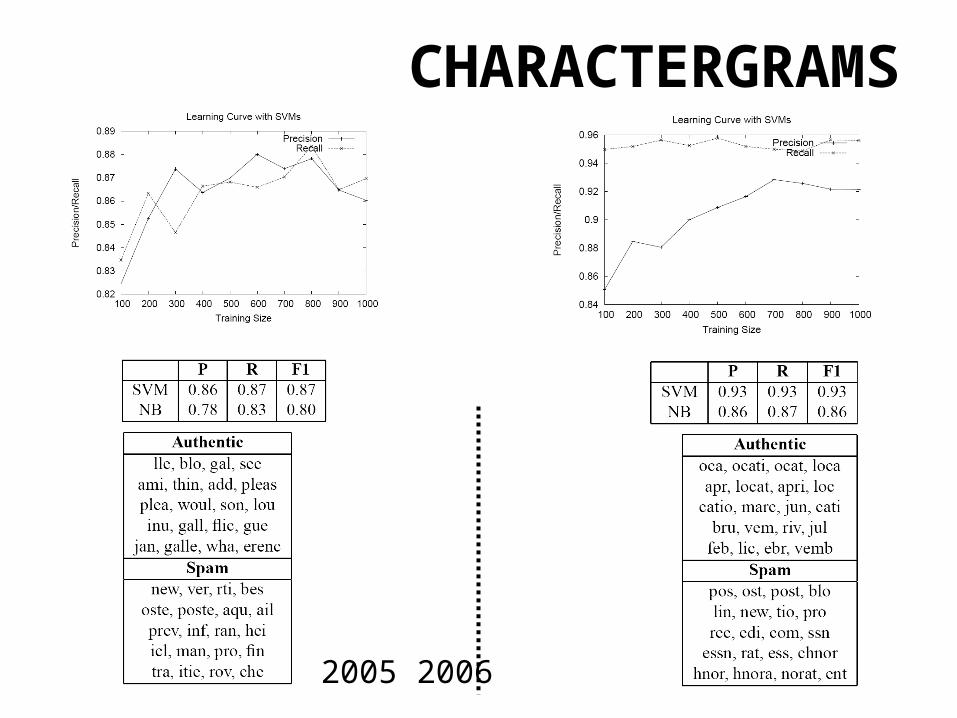
CHARACTERGRAMS
2005 2006

CHARACTERGRAMS
2005 2006
• 3,4,5 charactergrams from blog content• Can capture character salad (e.g. p1lls)• Feature selection important

OUTLINKS
2005 2006

OUTLINKS
2005 2006
• Out-links tokenized by non-alphabets• Similar to URL n-grams, likely more robust
• Novel feature space

ANCHORS
2005 2006

ANCHORS
2005 2006
• Anchor text tokenized into words• Subsumed by words, but obfuscation difficult• Capture personalization of publishing template• Novel feature space

“Honestly, Do you think people who make $10k/month from adsense make blogs manually? Come on, they need to make them as fast as possible. Save Time = More Money! It's Common SENSE! How much money do you think you will save if you can increase your work pace by a hundred times? Think about it…”
“Discover The Amazing Stealth Traffic Secrets Insiders Use To Drive Thousands Of Targeted Visitors To Any Site They Desire!”
“Holy Grail Of Advertising... “
“Easily Dominate Any Market, AnySearch Engine, Any Keyword.”
Splog software ?!
$ 197

Capture HTML Stylistic Patterns in Authentic Blogs

HTMLTAGS
2005 2006

HTMLTAGS
2005 2006
• Use HTML Tags – stylistic information• Capture signatures of splog software• Fully language independent• Novel feature space

FEED BASED DETECTION
• Limitations using only home-pages– No knowledge of blog lifetime– Classifiers less effective in early lifecycle
• Benefits of using feeds– Most recent posts, lifetime, metadata– Capture correlations across posts
• Limitations of using only feeds– Loose out signatures in publishing template

FEED ITEM DISTRIBUTON
• Plot number of items in feeds (SPLOG-2006)• Authentic Blogs feature normal distribution• Splogs – many with just one post• Knowledge of classifier effectiveness vs. lifetime

FEED BASED DETECTION
• Disjoint feature spaces – Words, Tags• Trained and Tested with n (x-axis) posts• Publishing template signatures important• Tags much more effective – early lifecycle

RELATED CLASSIFIERS
• Blog Identification– Competency requirement for blog harvesters– F-1 measure of 98%
• Relational Features– Less Effective (High P, Low R)– Short-lived blogs, lifetime dependent– Knowledge of Web-graph
• Derived Features– Less Effective

FEATURE SPACE OBSERVATIONS
• Cost based classifier bucketing
• Known Feature Spaces– Words continue to be effective– Word-grams against obfuscation
• Novel Feature Spaces– Out-links, Anchors capture useful signals– HTML Tags very effective, even early lifecycle
• Feature Space Exploration– Tags, JavaScript, Feed Classification

• Introduction
• Characterization
• Feature Discovery
• Cost-aware pipeline
• Adaptive Classifiers
• Evaluation
• Conclusions
• Future Directions
OUTLINE

CONTRIBUTIONS
(i) a principled study of the characteristics of the problem,
(ii) a well motivated feature discovery effort,
(iii) a cost-sensitive, real-time filtering implementation, and
(iv) an ensemble driven classifier co-evolution.

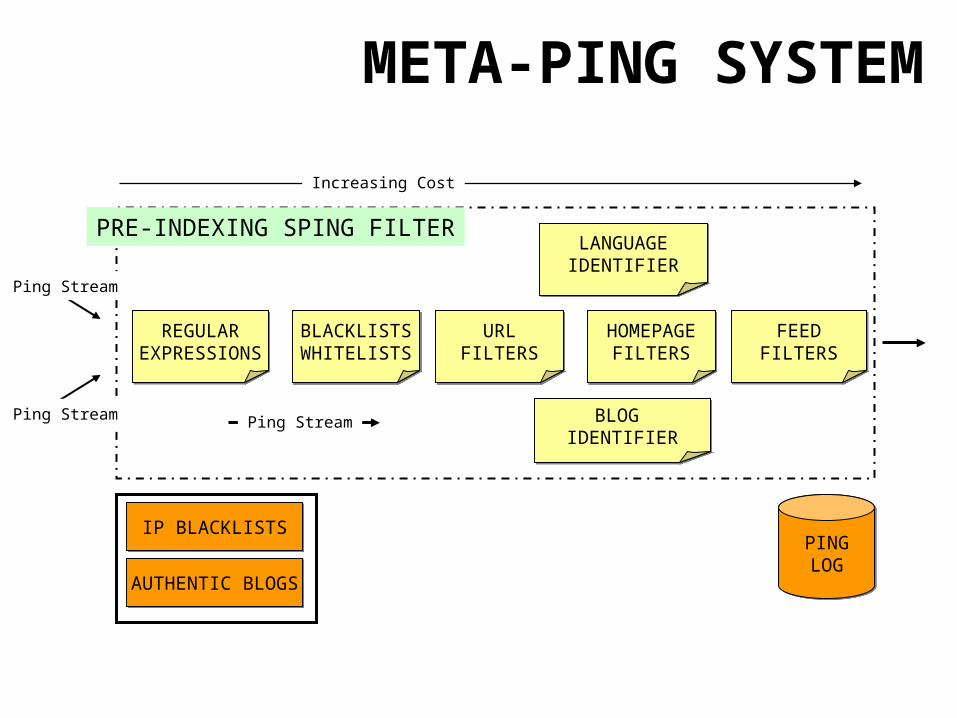
META-PING SYSTEM
• Regular Expression Filtering (March 2005)
• List of Authentic Blogs (August 2005)
• Blog Home-page Classifier (December 2005)
• URL Classifier (October 2006)
• Feed Classifier (May 2007)
• Cost-Aware Pipeline Implementation (Jan 2007)

BLOG IDENTIFIER
BLOG IDENTIFIER
LANGUAGEIDENTIFIERLANGUAGEIDENTIFIER
PINGLOGPINGLOG
PRE-INDEXING SPING FILTER
REGULAREXPRESSIONS
REGULAREXPRESSIONS
BLACKLISTSWHITELISTSBLACKLISTSWHITELISTS
URLFILTERS
URLFILTERS
HOMEPAGEFILTERS
HOMEPAGEFILTERS
FEEDFILTERS
FEEDFILTERS
AUTHENTIC BLOGSAUTHENTIC BLOGS
IP BLACKLISTSIP BLACKLISTS
Ping Stream
Ping Stream
Ping Stream
META-PING SYSTEM
Increasing Cost

META-PING SYSTEM
• Static Design– Project specific thresholds– Classifiers in pipeline– Based on accrued domain knowledge
• Dynamic Possibilities– Classifier Thresholds– Classifier use– Queuing analysis and Precision/Recall
requirements

• Introduction
• Characterization
• Feature Discovery
• Cost-aware pipeline
• Adaptive Classifiers
• Evaluation
• Conclusions
• Future Directions
OUTLINE

CONTRIBUTIONS
(i) a principled study of the characteristics of the problem,
(ii) a well motivated feature discovery effort,
(iii) a cost-sensitive, real-time filtering implementation, and
(iv) an ensemble driven classifier co-evolution.

• Change in distribution in feature space
• Concept Drift – Seasonal, seen in both splogs and blogs
• Adversarial Scenario – seen in splogs
• Concept Description needs to be updated
ADAPTIVE CONTEXT
f1, f2, f3 .. fm
P(O(x)/splog(x))
P(splog(x)/O(x))

ENSEMBLE INTUITION
• Stream of unlabeled instances (drifting)
• Base classifiers with potentially independent feature spaces
• Is an ensemble (probabilistic committee) of the catalogue more robust to drift?
• Are instances classified by the ensemble effective to retrain base classifiers (semi-supervised learning)?
• Motivated by co-training
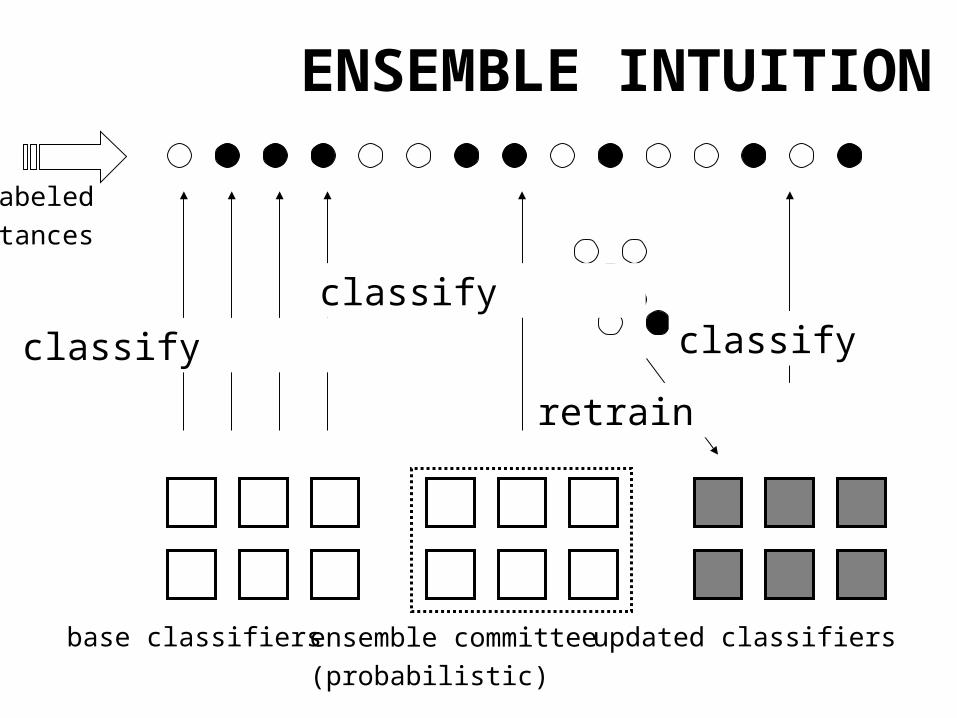
ENSEMBLE INTUITION
base classifiers updated classifiersensemble committee
(probabilistic)
classify
classifyclassify
retrain
unlabeled
instances

ENSEMBLE APPROACH
ensemble
committee
probabilistic base
classifiers

POTENTIAL TO ADAPT
URL
Anchor
Chargram
Outlink
Tag
Wordgrams
Words

EXPERIMENTAL SETUP
• A catalog of seven classifiers
• SPLOG-2005 as base labeled dataset
• SPLOG-2006 as evaluation stream
• 10K Top Features
• SVM based learning
• SPLOG-2006 separated out into unlabeled stream and test set (3-fold)
• F-1 performance metric evaluation

RESULTS – WORD DRIFT

RESULTS – ALL CLASSIFIERS

ENSEMBLE PROPERTIES
• Effectiveness tied to properties of ensemble
• Precision 92%, Recall 93%– 5 points over best base classifier
• Ensemble Diversity– a measure of disagreement between base
classifier– maintain error of base classifiers

ENSEMBLE PROPERTIES
• Different metrics for diversity
• Q-statistic compares pairs of classifiers in an ensemble, [-1, +1]
• -1 most diverse, +1 least diverse
N11N00 - N01N10
N11N00 + N01N10Q =
N11 – Both classify correctly
N00 – Both misclassify
N10 – Misclassification by 2nd
N01 – Misclassification by 1st

ENSEMBLE PROPERTIES
cgram wgram word tag outlink anchor url
cgram 1.0 0.67 0.86 -0.23 0.35 0.58 0.08
wgram 0.67 1.0 0.77 -0.08 0.62 0.56 0.11
word 0.86 0.77 1.0 -0.19 0.53 0.76 0.04
tag -0.23 -0.08 -0.19 1.0 0.15 -0.12 0.24
outlink 0.35 0.62 0.53 0.15 1.0 0.45 0.10
anchor 0.58 0.56 0.76 -0.12 0.45 1.0 0.03
url 0.08 0.11 0.04 0.24 0.10 0.03 1.0

ADAPTIVE - OBSERVATIONS
• Interplay between co-training and adversarial classification
• Maintaining and exploiting (ensemble) a catalogue of features effective
• Unlike existing work in concept drift– Real-world data– Stream of unlabeled instances
• Novel “feature spaces” key to adaptive, adversary resilient classifiers

• Introduction
• Characterization
• Feature Discovery
• Adaptive Classifiers
• Cost-aware pipeline
• Evaluation
• Conclusions
• Future Directions
OUTLINE

THESIS STATEMENT
It is possible to develop an effective, efficient and adaptive system to detect spam blogs.
BLOG IDENTIFIER
BLOG IDENTIFIER
LANGUAGEIDENTIFIERLANGUAGEIDENTIFIER
PINGLOGPINGLOG
PRE-INDEXING SPING FILTER
REGULAREXPRESSIONS
REGULAREXPRESSIONS
BLACKLISTSWHITELISTSBLACKLISTSWHITELISTS
URLFILTERS
URLFILTERS
HOMEPAGEFILTERS
HOMEPAGEFILTERS
FEEDFILTERS
FEEDFILTERS
AUTHENTIC BLOGSAUTHENTIC BLOGS
IP BLACKLISTSIP BLACKLISTS
Ping Stream
Ping Stream
Ping Stream
META-PING SYSTEM
Increasing Cost

META-PING IMPLEMENTATION
• Multithreaded, distributed Java implementation
• Regular Expressions, accrued over two years, tested using white-lists
• Blacklists - IP Address from known domain, learnt using higher cost classifiers
• libsvm toolkit for probabilistic classifiers
• Project specific classifier choices and thresholds

META-PING EVALUATON
• Effective sub-modules– Evaluation of effective features– Harvard (Blog Identification, Word-based classifier),
UMich (shared results)– ********, *******, LMCO
• Efficient solution– Pipeline deployment at UMBC (January 2007)– Ping filtering for two months (3 machines – 40 threads)
• Adaptive ready (offline)– Evaluation using year apart real-world datasets

• Introduction
• Characterization
• Feature Discovery
• Adaptive Classifiers
• Cost-aware pipeline
• Evaluation
• Conclusions
• Future Directions
OUTLINE

THESIS STATEMENT
It is possible to develop an effective, efficient and adaptive system to detect spam blogs.

CONCLUSIONS
• Characterizing the Problem of Spam Blogs– Helps Drive Solutions– Readies tackling new emerging problems
(e.g. Social Media spam)
• Feature Spaces effective for text classification are also useful here
• New feature spaces are quite effective, and could potentially be useful in other domains

CONCLUSIONS
• Using classifier costs to drive a pipeline based implementation can lead to an efficient filtering solution
• Semi-supervised ensemble approach can enable adaptive classifiers– Could be useful in domains (adversarial)
that use a catalogue of classifiers– Proactive techniques are feasible for web
spam detection

• Introduction
• Characterization
• Feature Discovery
• Adaptive Classifiers
• Cost-aware pipeline
• Evaluation
• Conclusions
• Future Directions
OUTLINE
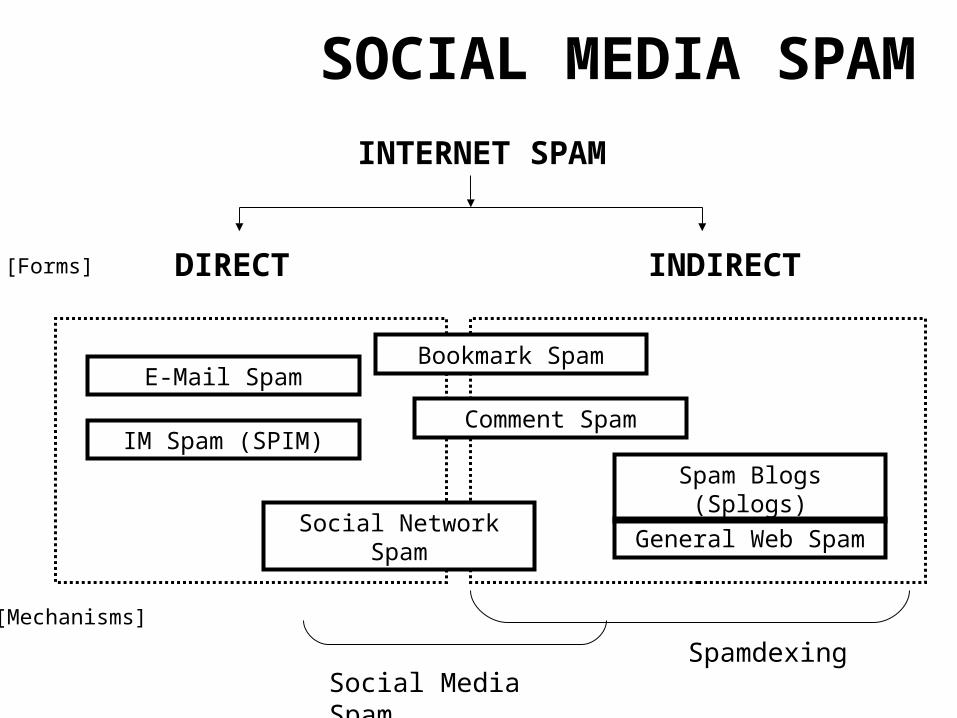
DIRECT INDIRECT
E-Mail Spam
General Web Spam
Spam Blogs (Splogs)
SOCIAL MEDIA SPAM
IM Spam (SPIM)
Spamdexing
INTERNET SPAM
[Forms]
[Mechanisms]
Social Network Spam
Comment Spam
Bookmark Spam
Social Media Spam

SOCIAL MEDIA SPAM
• Spam in social “microcosms” on the Web
• Spam on the Web– Spamdexing– Social Media Spam
• Social Media Spam serves two purposes– Local effects initially– Global effects subsequently (spamdexing)
• Detection efforts should address deployment contexts (microcosm, search)

OPEN PROBLEMS
• Feature Sophistication in new feature spaces, HTML Tags, JavaScript, Feeds
• Cost-aware pipeline (dynamic)
• Adversarial Classification, interplay with concept drift, catalog of features
• Active Learning and Adversarial Classification in the “catalogue” context
• Social Media Spam

THANK YOU!