developing optimized signal processing software on the … · jtag or 2-pin serial wire debug (swd)...
TRANSCRIPT

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 1 of 12
Developing optimized signal processing software on the Cortex‐M4 processor Shyam Sadasivan, ARM November, 2010
1. Introduction A microcontroller, according to the oft quoted Wikipedia, is a small computer on a single integrated
circuit consisting internally of a CPU, clock, timers, I/O ports, and memory. It also says that a digital
signal processor (DSP) is a specialized microprocessor with an optimized architecture for the fast
operational needs of digital signal processing, which is concerned with the representation of
signals by a sequence of numbers or symbols and the processing of these signals.
What it does not tell us is that these two words are coming closer every day.
32-bit microcontrollers have changed the embedded landscape in the recent past. End-users are
finding easy to use 32-bit technology within their grasp for their performance hungry signal
processing applications. With the ARM microcontroller partnership offering an incredible range of
products based upon Cortex-M processors, the choice of performance, peripherals and software is
now richer than ever before. Looking further into the future, processing demands will continue to
increase as designs incorporate both control and signal processing features into a single device.
Figure 1 : A typical embedded system with both control and signal processing requirements
2. Digital signal controller ( DSC ) The digital signal controller creates an efficient blend of digital control and signal processing. It
addresses the requirements of an increasingly converging but still demanding market.
Figure 2 : Digital Signal Controllers – efficient hybrid of MCU and DSP characteristics

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 2 of 12
The focus of this paper – the central processor in the Digital Signal Controller
One of the biggest challenges of most systems requiring digital signal processing is to manage the
data flow through the system. The input and output data can represent different real world signals
including motor position, audio signals, video signals, RF signals (GPS, etc.), sensors etc. Moreover,
there are many characteristics of a DSC including the CPU, the peripherals, memory, number of GPIO
pins, connectivity, etc., that contribute to its applicability for a particular design. For the purpose of
this paper, we will focus on the characteristics of the central processor, the architecture of which
significantly influences the software techniques employed for optimum signal processing
throughput.
3. The ARM Cortex-M4 processor – an excellent CPU for 32-bit DSCs A processor specifically designed for DSC devices is the ARM Cortex-M4 processor. This new
processor extends the ARM Cortex-M family of processors into signal processing markets through a
software compatible upgrade migration path for Cortex-M0 and Cortex-M3 users.
Cortex-M4 - microcontroller characteristics
The Cortex-M family of processors has a set of common technologies that make them an excellent
candidate for microcontroller applications. These features have already gained a lot of popularity
through the success of the Cortex-M0 and Cortex-M3 and form a key reason for the high rate of
adoption of the Cortex-M processors in the microcontroller marketplace today.
RISC processor core Thumb-2 technology
High performance 32-bit CPU Deterministic operation Low latency 3-stage pipeline
Optimal blend of 16/32-bit instructions Very high code density No compromise on performance
Low power modes Nested Vectored Interrupt Controller (NVIC)
Integrated sleep state support Multiple power domains Architected software control
Low latency, low jitter interrupt response No need for assembly programming Interrupt service routines in pure C
Tools and RTOS support
CoreSight debug and trace
Broad 3rd party tools support Cortex Microcontroller
Software Interface Standard (CMSIS) Maximizes software effort reuse
JTAG or 2-pin Serial Wire Debug (SWD) connection
Support for multiple processors Support for real-time trace
Table 1 : Microcontroller characteristics of the Cortex-M4 processor

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 3 of 12
Cortex-M4 - signal processing characteristics
The Cortex-M4 processor builds upon the microcontroller features of the Cortex-M family and
introduces signal processing performance typically only associated with DSPs until now. The
features that make this possible are detailed in Table 2 below.
Harvard architecture Single cycle 16,32-bit MAC
32-bit AHB-Lite interface for instruction fetches
32-bit AHB-Lite interface for data and debug accesses
Wide range of MAC instructions Choice of 32 or 64 bit
accumulatorInstructions execute in a single cycle
Single cycle SIMD arithmetic Single cycle dual 16-bit MAC
4 parallel 8-bit adds or subtracts 2 parallel 16-bit adds or subtracts Instructions execute in a single cycle
2 parallel 16 bit MAC operations Choice of 32 or 64 bit accumulator Instructions execute in a single cycle
Floating point unit Others
IEEE 754 standard compliant Single precision floating-point unit Fused MAC for higher precision
Saturating math Barrel shifter
Table 2 : Signal processing characteristics of the Cortex-M4 processor
4. Cortex-M4 processor signal processing features in detail
Harvard architecture
The Cortex-M4 processor is based on the Harvard architecture characterized by separate buses for
instructions and data. By being able to read both instruction and data from memory at the same
time, the Cortex-M4 processor can perform many operations in parallel, speeding application
execution. The 32-bit AHB-Lite ICode interface fetches instructions from the code space. The 32-bit
AHB-Lite DCode interface accesses data from the code memory space. The peripheral bus enables
access to components outside of the Cortex-M4 processor system.
8-bit & 16-bit packed data types
The data registers on the Cortex-M4 processor are 32-bits wide. Many signal processing
applications, like speech, audio, communications, and image processing manipulate 8-bit and 16-bit
data samples. As a further boost in performance, a 32-bit register can store two 16-bit data samples
or even four 8-bit samples and work with these multiple data items.

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 4 of 12
The Cortex-M4 provides a wide range of Single-Instruction-Multiple-Data (SIMD) functions to ensure
that such algorithms can execute in the minimum number of processor cycles. With SIMD, a
numeric operation will simultaneously apply to two 16-bit or four 8-bit values.
SIMD arithmetic
The Cortex-M4 has the ability to perform arithmetic operations on packed 8- and 16-bit data. The
various flavours of these instructions are show in Table 3 below.
INSTRUCTION
TYPE
S Signed
Q Signed
Saturating
SH Signed Halving
U Unsigned
UQ Unsigned Saturating
UH Unsigned Halving
ADD8 SADD8 QADD8 SHADD8 UADD8 UQADD8 UHADD8
SUB8 SSUB8 QSUB8 SHSUB8 USUB8 UQSUB8 UHSUB8
ADD16 SADD16 QADD16 SHADD16 UADD16 UQADD16 UHADD16
SUB16 SSUB16 QSUB16 SHSUB16 USUB16 UQSUB16 UHSUB16
Table 3 : Cortex-M4 SIMD arithmetic instructions
There are also other powerful instructions which allow you to exchange half words of the second
operand register and perform different operations on each half. There are also unsigned sum of
differences instructions that can work on pixel data from images and are quite useful in applications
like motion estimation.
Single cycle 16,32-bit MAC
One of the most important features of a processor for digital signal processing is an efficient single
cycle MAC responsible for speeding up a majority of DSP algorithms. The Cortex-M4 has a variety of
single –cycle MAC instructions for both 16 and 32-bit data as shown in Table 4 below.
OPERATION DESCRIPTION
16 x 16 = 32 16-bit signed multiply yielding 32-bit result
16 x 16 + 32 = 32 16-bit signed multiply with 32-bit accumulate
16 x 16 + 64 = 64 16-bit signed multiply with 64-bit accumulate
16 x 32 = 32 16-bit by 32-bit signed multiply returning 32-most-significant-bits
(16 x 32) + 32 = 32 16-bit by 32-bit signed multiply with 32-bit accumulate
32 x 32 = 32 32-bit multiply
32 ± (32 x 32) = 32 32-bit multiply accumulate/subtract
32 x 32 = 64 Signed/unsigned multiply to long
(32 x 32) + 64 = 64 Signed/unsigned multiply to long with accumulate
(32 x 32) + 32 + 32 = 64 32-bit unsigned multiply with double 32-bit accumulation yielding 64-bit result
32 ± (32 x 32) = 32 (upper) 32-bit multiply with 32-most-significant-bit accumulate/subtract
(32 x 32) = 32 (upper) 32-bit multiply returning 32-most-significant-bits
Table 4 : Single cycle 16 and 32-bit MAC operations of the Cortex-M4 processor

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 5 of 12
Single cycle dual 16-bit MAC
The Cortex-M4 processor can even perform two 16-bit MACs in parallel in a single cycle. This
effectively doubles the raw computational power of the core for 16-bit data and gives it a clear edge
compared to 16-bit devices.
OPERATION INSTRUCTION
(16 x 16) ± (16 x 16) = 32 Sum/difference of dual 16-bit signed multiply
(16 x 16) ± (16 x 16) + 32 = 32 Dual 16-bit signed multiply with single 32-bit accumulator
(16 x 16) ± (16 x 16) + 64 = 64 Dual 16-bit signed multiply with single 64-bit accumulator
Table 5 : Single cycle dual 16-bit MAC operations of the Cortex-M4 processor
Figure 3 shows the use of packed data for a dual 16-bit multiply operation with a single 64-bit
accumulator.
Figure 3 : Cortex-M4 packed data and dual 16-bit MAC
Single precision floating point unit ( FPU )
The FPU in the Cortex-M4 processor offers a wider dynamic range because it can represent a wide
range of numbers. It is also very easy to program, since designers need not worry about the
constraints imposed by fixed-point processing. So far, the availability of floating point hardware in
microcontrollers has been limited due to the higher silicon area costs. The low cost Cortex-M4
processor FPU now opens the path to a wide range of floating point enabled DSC devices.
The Cortex-M4 FPU provides functionality compliant with the IEEE 754 standard. The FPU supports single-precision data-processing instructions and data types. Some of the floating point operations supported are shown in Table 6 below.
FLOATING POINT OPERATION CYCLE COUNT
Add/Subtract 1
Divide 14
Multiply 1
Multiply Accumulate (MAC) 3
Fused MAC 3
Square Root 14
Add/Subtract 1
Table 6 : Selected Cortex-M4 FPU operations and execution times

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 6 of 12
Saturating math
Sample values in fixed-point signal processing algorithms have to live within a well-defined numeric
range. If numbers get too small, the effects of quantization noise degrade performance; if numbers
get too large there is the risk of overflow. Fixed-point algorithms require careful scaling and are
almost always designed to overflow under certain conditions. Standard integer arithmetic handles
overflow in the worst conceivable way. Sample values wrap around upon overflow leading to huge
discontinuities in signal.
Figure 4 : Processing with saturation
To mitigate these effects, the Cortex-M4 processor contains saturating math operations. When a
value overflows, it is saturated (ie: clipped) to the largest positive or negative value. The saturation
occurs in the same cycle as the arithmetic operation and incurs no overhead.
Barrel shifter
Shifting operations are also quite common in fixed-point DSP algorithms. Shifting is used, for
example, to provide additional guards bits to protect against saturation. Most devices can typically
shift values one bit left or right, but repeated shift operations are often required. The Cortex-M4
can shift data an arbitrary number of bits left or right in a single cycle, leading to more efficient code.
5. Ease of use - programming fully in C Adding hardware into a microcontroller that cannot be easily used is a futile exercise. Keeping
programming simple is absolutely crucial to ease adoption of high performance hardware.
Microcontrollers have attempted for many years to make leading technology available to the mass
market by making complex applications possible through very easy to use software tools. The
Cortex-M4 processor and its supporting software ecosystem also look to extend this ease-of-use
paradigm to traditionally hard-to-use signal processing features.

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 7 of 12
Software tools
The integrated signal processing features of the Cortex-M4 simplify the development of application software by offering a single tool-chain and processing device, when compared to architectures containing separate applications processors coupled with programmable DSPs or fixed-function accelerators. The single tool-chain environment speeds time-to-market as software plays an increasingly important role in product development.
Many of the high performance signal processing instructions of the Cortex-M4 processor can be
taken advantage of through the compiler. When further optimization is required, C compilers
support intrinsic functions for low-level assembly operations. Intrinsics allow you to leverage the
power of assembly programming in a C development environment while hiding much of the
complexity of pure assembly language.
Cortex Microcontroller Software Interface Standard ( CMSIS )
Typically, industries use standards to improve product quality and enable component sharing across
projects. The electronics industry is full of such standards, but the microcontroller market has many
proprietary CPU architectures which prevent the introduction of efficient software standards. This
situation is rapidly changing primarily due to wide adoption of ARM Cortex-M processors. For the
first time ever, the embedded microcontroller industry has the ability to standardize on a single
popular hardware platform.
Figure 5 : CMSIS – a hardware abstraction layer providing consistent access to CPU and peripherals
ARM has created the Cortex Microcontroller Software Interface Standard (CMSIS) that enables
silicon vendors and middleware providers to create software that can be easily integrated. CMSIS
has been developed in close partnership with several key silicon and software vendors. CMSIS is a
vendor-independent hardware abstraction layer that provides a common approach to interfacing
peripherals, real-time operating systems, and middleware components. The standard is scalable to

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 8 of 12
ensure that it is suitable for all Cortex-M series processor microcontrollers from the smallest 8KB
device up to devices with sophisticated communication peripherals such as Ethernet or USB-OTG.
CMSIS has been designed as an open software standard usable by everyone.
CMSIS has been extended specifically to support the Cortex-M4 processor. There will also very soon
be an extensive library of DSP software routines available along with the CMSIS standard. This library
will include filters, transforms, vector math, matrix math etc fully developed in C and heavily
optimized for the Cortex-M4 instruction set architecture.
6. Cortex-M4 programming examples and optimization strategies Some of the most often used functions in signal processing algorithms are -
Fast Fourier transforms (FFT) – used in audio compression, spread spectrum
communication, noise removal etc
Infinite impulse response (IIR) filters – used in audio equalization, motor control etc
Finite impulse response (FIR) filters – used in data communications, echo cancellation
(adaptive versions), smoothing data etc
The most important observation here is that all of these algorithms depend heavily on the MAC
operation. A high performance MAC is a key feature for optimizing these algorithms.
This section will focus on an FIR filter example and detail various software optimization strategies
that will result in highly optimized Cortex-M4 algorithms.
The FIR filter is one of the classic functions of signal processing and occurs frequently in
communications, audio, and video applications. A filter of length N requires N coefficients h[0], h[1],
…, h[N-1] , N state variables x[n], x[n-1], …, x[n-(N-1)] and N multiply accumulates.
Figure 6 : FIR filter
21
21
21
210
nyanya
nxbnxbnxbny
1z 1z 1z 1z
0h 1h 2h 3h 4h
nx
ny
jekXkXkY
kXkXkY
212
211
knxkhnyN
k
1
0
Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 9 of 12
Computing coefficients The coefficients h[0], h[1], …, h[N-1] can either be pre-computed using tools like MATLAB and stored
or be computed on the fly by the processor. A good example of the latter is a tone control knob on
an audio system where turning the knob results in a new set of coefficients. These could have been
pre-computed for certain settings and stored in device memory or could be computed by the device
for higher granularity.
Software optimization strategies Typical FIR code would use block based processing and the inner loop would consist of dual memory
fetches, MAC and pointer updates with circular addressing to make the most of the processor’s
capabilities. There are multiple strategies to optimize such code for the Cortex-M4 processor and
this section will apply each one and show the benefits at each stage. Let us start with the inner loop
code for an FIR filter as below that takes 12 cycles to complete on a Cortex-M4 processor.
Original inner loop code Total of 12 cycles for(k=0;k<filtLen;k++) {
sum += coeffs[k] * state[stateIndex];
stateIndex--;
if (stateIndex < 0) {
stateIndex = filtLen-1;
}
}
Fetch coeffs[k] 2 cycles
Fetch state[stateIndex] 1 cycle
MAC 1 cycle
stateIndex-- 1 cycle
Circular wrap 4 cycles
Loop overhead 3 cycles
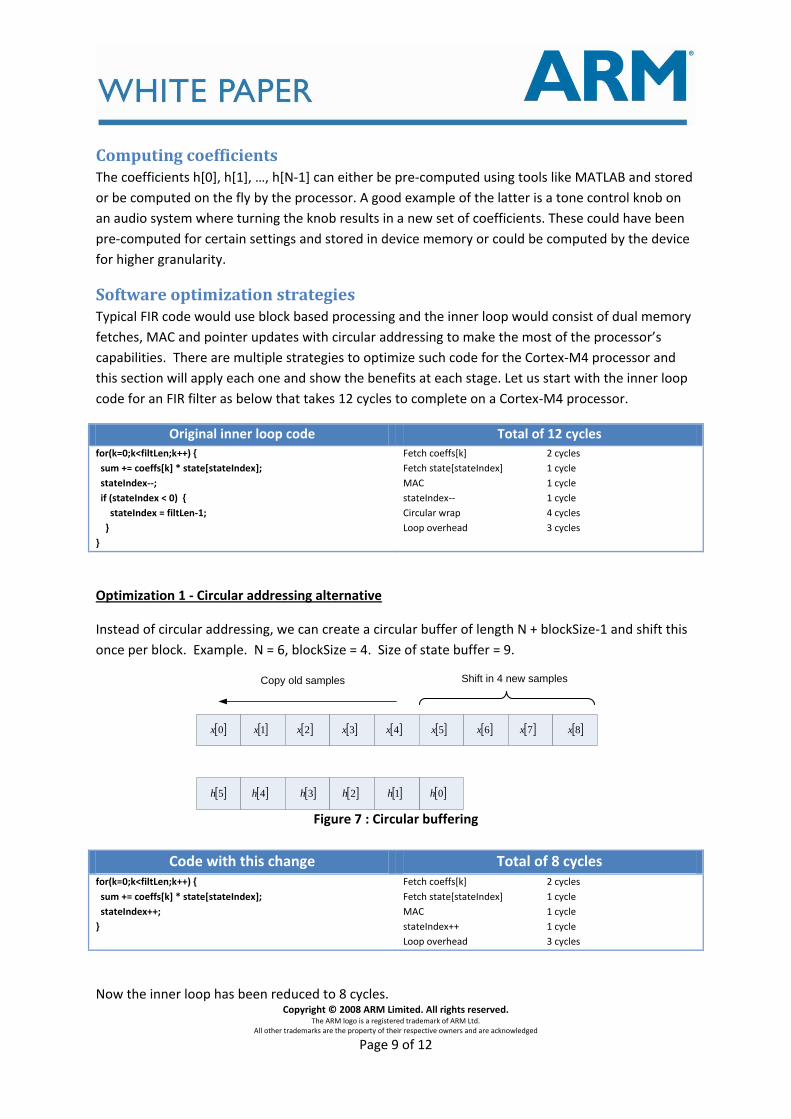
Optimization 1 - Circular addressing alternative
Instead of circular addressing, we can create a circular buffer of length N + blockSize-1 and shift this
once per block. Example. N = 6, blockSize = 4. Size of state buffer = 9.
Figure 7 : Circular buffering
Code with this change Total of 8 cycles for(k=0;k<filtLen;k++) {
sum += coeffs[k] * state[stateIndex];
stateIndex++;
}
Fetch coeffs[k] 2 cycles
Fetch state[stateIndex] 1 cycle
MAC 1 cycle
stateIndex++ 1 cycle
Loop overhead 3 cycles
Now the inner loop has been reduced to 8 cycles.
0h 1h
0x 1x 2x 3x 4x 5x
2h 3h 4h 5h
5x 6x 7x 8x
Shift in 4 new samplesCopy old samples

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 10 of 12
Optimization 2 - Loop unrolling
In order to overcome any overheads involved in frequently run loops, loop unrolling is a technique
used by compilers and can also be applied to code manually to improve performance. This is an
efficient language-independent optimization technique. There is overhead inherent in every loop for
checking the loop counter and incrementing it for every iteration (3 cycles on the Cortex-M4). Loop
unrolling processes ‘n’ loop indexes in one loop iteration, reducing the overhead by ‘n’ times.
Unroll loop by 4 Total of 5.75 cycles per tap for(k=0;k<filtLen;k++) {
sum += coeffs[k] * state[stateIndex];
stateIndex++;
sum += coeffs[k] * state[stateIndex];
stateIndex++;
sum += coeffs[k] * state[stateIndex];
stateIndex++;
sum += coeffs[k] * state[stateIndex];
stateIndex++;
}
Fetch coeffs[k] 2 x 4 = 8 cycles
Fetch state[stateIndex] 1 x 4 = 4 cycles
MAC 1 x 4 = 4 cycles
stateIndex++ 1 x 4 = 4 cycles
Loop overhead 3 x 1 = 3 cycles
TOTAL = 23 cycles for 4 taps
= 5.75 cycles per tap
The inner loop now runs at 5.75 cycles per filter tap
Optimization 3 - Extensive use of SIMD and intrinsics
Many image and video processing, and communications applications use 8- or 16-bit data types.
SIMD usage on 16-bit data yields a 2x speed improvement over 32-bit and on 8-bit data yields a 4x
speed improvement. Access to SIMD is via compiler intrinsic. Example : a dual 16-bit MAC can be
performed by this C code - SUM=__SMLALD(C, S, SUM).
Usage of SIMD intrinsic Total of 2.375 cycles per tap filtLen = filtLen << 2;
for(k = 0; k < filtLen; k++){
c = *coeffs++;
s = *state++;
sum = __SMLALD(c, s, sum);
c = *coeffs++;
s = *state++;
sum = __SMLALD(c, s, sum);
c = *coeffs++;
s = *state++;
sum = __SMLALD(c, s, sum);
c = *coeffs++;
s = *state++;
sum = __SMLALD(c, s, sum);
}
2 cycles
1 cycle
1 cycle
2 cycles
1 cycle
1 cycle
2 cycles
1 cycle
1 cycle
2 cycles
1 cycle
1 cycle
3 cycles
19 cycles TOTAL = 2.375 cycles per tap
We have now reduced the inner loop to 2.375 cycles per tap.

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 11 of 12
Optimization 4 - Caching of intermediate variables
An FIR filter is extremely memory intensive. 12 out of 19 cycles in the last code portion deal with
memory accesses. For example, 2 consecutive loads take 3 cycles on Cortex-M4 and a MAC takes
only 1 cycle on Cortex-M4. When operating on a block of data, memory bandwidth can be reduced
by simultaneously computing multiple outputs and caching several coefficients and state variables.
Figure 8 : Caching of intermediate variables
After applying this technique, we can reduce the cycles to just 1.6 cycles per filter tap. To recap, we
started with the Cortex-M4 standard C code taking 12 cycles and we improved performance by going
through a series of optimization techniques -
Using circular addressing alternative = 8 cycles
After loop unrolling < 6 cycles
After using SIMD instructions < 2.5 cycles
After caching intermediate values ~ 1.6 cycles
So in summary, basic C code written for the Cortex-M4 can, through simple optimizations, lead to
very high performance DSP algorithms. The FIR filter performance on the Cortex-M4 is now
comparable to high performance DSPs which can run this FIR filter at 1 cycle per filter tap. These
DSPs need optimized assembly to achieve this though, which requires a steep learning curve and
also removes portability. All of these optimizations on the Cortex-M4 can be done completely in a C
environment retaining all the benefits of writing and maintaining code in C.
A good example of digital signal control performance is audio playback(decode), which employs a
good mix of both control and DSP processor features. Figure 9 shows that the Cortex-M4 enables
users to reach close to optimized audio DSP performance in the area and power footprint of a
microcontroller CPU. Decode of a typical MP3 stream can be performed on the Cortex-M4
0h 1h
0x 4x 5x
2h 3h 4h 5h
5x 6x 7x 8x 1x 2x 3x
c0
Increment by 16-bits
statePtr++
Increment by 32-bits
coeffsPtr++
x0
x1
x2
x3
x0
x1
x2
x3
c0

Copyright © 2008 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd.
All other trademarks are the property of their respective owners and are acknowledged
Page 12 of 12
consuming less than 10MHz, which translates to less than 0.5mW processor dynamic power
consumption.
Figure 9 : High performance MP3 decode on the Cortex-M4
7. Conclusion
The MCU and DSP worlds are rapidly converging as users demand efficient and easy-to-use signal
processing technologies. The ARM Cortex-M4 processor presents an excellent option for digital
signal control devices aimed at markets like motor control, industrial automation, embedded audio,
digital power management and automotive.
The Cortex-M4 processor extends the Cortex-M processor family into signal processing markets by
introducing DSP specific features like a high performance single cycle MAC, SIMD arithmetic,
saturating math and single precision floating point hardware.
Developing applications on the Cortex-M4 is easy and can be done fully in C. Using simple
techniques, highly optimized programs can be developed with fast learning curves and minimal
effort.
The Cortex-M4 processor is an excellent option for next-generation microcontroller and digital signal
controller designs as they start to target applications requiring higher signal processing capabilities.