directed graphical model memm as sequence classifier niket tandon tutor: martin theobald, date: 09...
TRANSCRIPT

DIRECTED GRAPHICAL MODEL MEMM AS SEQUENCE
CLASSIFIER
NIKET TANDON
Tutor: Martin Theobald , Date: 09 June, 2011

Why talk about them..
HMMs is a sequence classifier Hidden Markov models (HMMs) successfully applied to:
Part-of-speech tagging:
<PRP>He</PRP> <VB>attends</VB> <NNS>seminars</NNS> Named entity recognition:
<ORG>MPI</ORG> director <PRS>Gerhard Weikum</PRS>
2

Agenda
HMM Recap MaxEnt Model HMM + MaxEnt ~= MEMM Training & Decoding Experimental results and discussion
3

Agenda
HMM Recap MaxEnt Model HMM + MaxEnt ~= MEMM Training & Decoding Experimental results and discussion
4
5
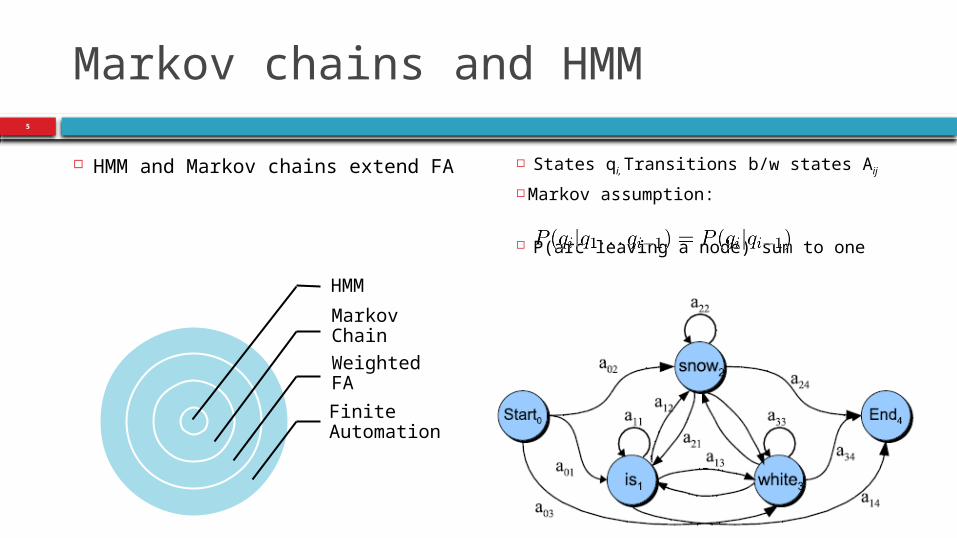
Markov chains and HMM
HMM and Markov chains extend FA States qi, Transitions b/w states Aij
Markov assumption:
P(arc leaving a node) sum to oneHMM
Markov Chain
Weighted FA
Finite Automation

6
HMM (One additional layer of uncertainty. States are hidden!)
Think of causal factors in prob.model
States qi
Transitions between states Aij
Observation likelihood or emission probability B = bi(ot) observation ot being generated from state qi
Markov Assumption
Output independence assumption
Task: Given observation #ice creams, predice weather states

HMM characterized by…7
three fundamental problems: Computing likelihood (Given an HMM l = (A,B) and O, find P(O|l) Decoding Given HMM l = (A,B) and O, find best hidden seq Q Learning Given Q and O, learn HMM parameters A, B

Computing P(O|l) observation likelihood8
N hidden states , T observations N x N x .. N = NT sequences. Exponentially large! HHC, HCH, CHH.. Efficient algo is Forward Algorithm (uses a table for intermediate values)

9
Forward Algorithm
Previous forward prob *
P(previous state to current state) *
P(observation ot given current state j)
at(j) is P( tth state is state j after seeing first t observations )
For many HMM application many aij are zero, thus reducing the space.
Finally, summing over the prob of every path

10

11
Decoding: Viterbi Algorithm
Given HMM l = (A,B) and O, find most probable hidden seq Q
Choose the hidden state sequence with max observation likelihood on running fwd algo. Exponential!
An efficient alternative is: Viterbi
Previous viterbi path prob *
P(previous state to current state) *
P(observation ot given current state j)
Compare fwd algo (sum Vs max) Keep a pointer to best path that
brought us here (backtrace)

12

13

14
Learning: Forward Backward Algorithm
Train transition prob A, emmission B Consider Markov chain, then B = 1.0 ( so compute A)
Max likelihood of aij = transitionsij / all transitions from i But, HMM has hidden states! Additional work , computed using EM style Forward Backward Algorithm.
sum over all successive values bt+1 weighted by aij and observation prob

Agenda
HMM Recap MaxEnt Model HMM + MaxEnt ~= MEMM Training & Decoding Experimental results and discussion
15

16
Background - Maximum Entropy models
A second probabilistic machine learning framework
Maximum Entropy as a non-sequential, sequence classifier
Most common MaxEnt sequence classifier is Max Entropy Markov Model MEMM
First, we discuss non-seq MaxEnt
Max Entropy works by extracting set of features (on input), combining linearly, and then sum as exponent
You must know: linear regression,
This value is not bounded. So, need normalize it.
Instead of prob, compute odds (recall that if P(A) = 0.9, P(A’) = 0.1
then, odds of A = 0.9 /0.3 = 3

17
Logistic Regression
Linear model to predict odds of y=true
Now lies between 0 and ∞ , but need lie between –∞ and +∞, so take log. Left func is called logit
Model of regression used to estimate not prob but logit of Prob is called logistic regresssion.
So, if linear func estimates logit: what is P(y=true)?
This function called logistic function, gives gives Logistic regression its name

18
Learning Weights (w)
Unlike Linear Regression that minimizes squared loss on train set, Logistic Regression uses Conditional Max Likelihood estimation.
w that makes P(observed y values in training data) to be highest, given x.
For entire train set
Taking log
An unwieldy expression
Condensed form (why)and substitution

19
How to solve the convex optim. Problem?
Several methods to solve convex optimization problem Later we explain an algorithm: Generalized Iterative Scaling Method called GIS

20
MaxEnt
Until now two classes, when more, Logistic regression is called Multinomial Logistic Regression (or MaxEnt)
In MaxEnt Prob that y=c is:
Normalize to make prob
fi(c,x) means feature i of observation x for class c.
fi are not real valued but binary (more common in text processing)
Learning w is similar to logistic regression, with one change. MaxEnt learns very high weights, so
Let us see a classification problem..

21
Niket/NNP is/BEZ expected/VBN to/TO talk/?? today/
f1 f2 f3 f4 f5 f6
VB(f) 0 1 0 1 1 0
VB(w)
.8 .01 .1
NN(f)
1 0 0 0 0 1
NN(w)
.8 -1.3
VB/NN?

22
More complex features..
Word starting with capital letter (Day) is more likely to be NNP than a common noun (e.g. Independence Day)
But a capitalized word occurring at beginning is not more likely NNP (e.g. Day after day) But, MaxEnt would be by hand as below
Key to successful use of MaxEnt is design of appropriate features and feature combinations

23
Why the name Maximum Entropy?
Suppose we tag a new word Prabhu with a model that makes fewest assumptions, imposing no constraints.
We get an equiprobable distribution
Suppose we had some training data from which we learnt set of possible tags for Prabhu are NN,JJ,NNS,VB
Since of the tags is correct so, P(NN)+ P(JJ)+ P(NNS)+ P(VB) = 1
NN JJ NNS
VB NNP
VBG IN CD
1/8 1/8 1/8 1/8 1/8 1/8 1/8 1/8
NN JJ NNS
VB NNP
VBG
IN CD
¼ ¼ ¼ ¼ 0 0 0 0

24
Maximum Entropy
… of all possible distributions, the equiprobable distribution has the maximum entropy
p* = argmax H(p)
Solution to this is entropy of a MaxEnt model whose weights W maximize the likelihood of the training data!

Agenda
HMM Recap MaxEnt Model HMM + MaxEnt ~= MEMM Training & Decoding Experimental results and discussion
25
HMM MEMM

26
Why HMM is not sufficient
HMM based on probabilities P(tag|tag) and P(word|tag). For tagging unknown words, useful features include capitalization, the presence of
hyphens, word endings HMM is unable to use information from later words to inform its decision early on. MEMM (Maximum Entropy Markov Model) mates Viterbi algorithm with
MaxEnt to overcome this problem!

27
HMM (Generative) Vs MEMM (Discriminative)
HMM: two probabilities for the observation likelihood and prior.
MEMM: single probability, conditioned on the previous state, observation.

28
MEMM
MEMM can condition on many features of input (capitalization, morphology (ending in -s or -ed), as well as earlier words or tags).
HMM can’t as its likelihood based, and needs to compute likelihood of each feature.
HMM
MEMM

Agenda
HMM Recap MaxEnt Model HMM + MaxEnt ~= MEMM Training & Decoding Experimental results and discussion
29

30
Decoding(inference) and Learning in MEMM
Viterbi in HMM
Viterbi in MEMM
Learning in MEMM : train the weights so as maximize the log-likelihood of the training corpus. GIS!

31
Learning: GIS basics
estimate a probability distribution p(a,b) where a defines classes (y1,y2) and b is feature indicator (0,1)
p(y1,0)+p(y2 ,0) = 0.6
Constraint on model’s expectation
Ep f = 0.6 (Expectation of feature)
p(y1,0)+p(y1 ,1)+ p(y2,0)+p(y2 ,1) = 1
Find prob distribution p with maxEnt
0 1
y1 ? ?
y2 ? ?
0 1
y1 .3 .2
y2 .3 .2

32
GIS algorithm sketch
Finds weight parameter of the unique distribution p* belonging to P and Q
Each iteration of GIS requires model expectation and trainset expectation of features.
Train set expectation is a count of features. But, model expectation requires approximation.

Agenda
HMM Recap MaxEnt Model HMM + MaxEnt ~= MEMM Training & Decoding Experimental results and discussion
33

34
Application: segmentation of FAQs
38 files belonging to 7 Usenet multi-part FAQs (set of files) Basic file structure:
header
text in Usenet header format
[preamble or table of content]
series of one of more question/answer pairs
tail
[copyright]
[acknowledgements]
[origin of document]
Formatting regularities: indentation, numbered questions, types of paragraph breaks Consistent formatting within a single FAQ

35
Train data
Lines in each file are hand-labeled into 4 categories: head, questions, answers, tail<head>Archive-name: acorn/faq/part2
<head>Frequency: monthly
<head>
<question> 2.6) What configuration of serial cable should I use
<answer>
<answer> Here follows a diagram of the necessary connections
<answer> programs to work properly. They are as far as I know t
<answer>
<answer> Pins 1, 4, and 8 must be connected together inside
<answer> is to avoid the well known serial port chip bugs. The
Prediction: Given a sequence of lines, a learner must return a sequence of labels.

36
Boolean features of lines
The 24 line-based features used in the experiments are:
begins-with-number contains-question-mark
begins-with-ordinal contains-question-word
begins-with-punctuation ends-with-question-mark
begins-with-question-word first-alpha-is-capitalized
begins-with-subject indented
blank indented-1-to-4
contains-alphanum indented-5-to-10
contains-bracketed-number more-than-one-third-space
contains-http only-punctuation
contains-non-space prev-is-blank
contains-number prev-begins-with-ordinal
contains-pipe shorter-than-30

37
Experiment setup
“Leave one out” testing: For each file in a group (FAQ), train a learner and test it on the remaining files in the group.
Scores are averaged over n(n-1) results.

38
Evaluation metrics
Segment: consecutive lines belonging to the same category Co-occurrence agreement probability (COAP)
Empirical probability that the actual and the predicted segmentation agree on the placement of two lines according to some distance distribution D between lines.
Measures whether segment boundaries are properly aligned by the learner
Segmentation precision (SP):
Segmentation recall (SR):

39
Comparison of learners
ME-Stateless: Maximum entropy classifier document is an unordered set of lines lines are classified in isolation using the binary features, not using label of previous line
TokenHMM: Fully connected HMM with hidden states for each of the four labels no binary features transitions between states only on line boundaries
FeatureHMM: same as TokenHMM lines are converted to sequences of features
MEMM

40
Results
Learner COAP SegPrec SegRecall
ME-Stateless 0.52 0.038 0.362
TokenHMM 0.865 0.276 0.14
FeatureHMM 0.941 0.413 0.529
MEMM 0.965 0.867 0.681

41
Problems with MEMM
Label bias problem Lead to CRF and further models (more on this in a while)

Thank you!