disk aware discord discovery: finding unusual time series in terabyte sized datasets
DESCRIPTION
Disk Aware Discord Discovery: Finding Unusual Time Series in Terabyte Sized Datasets. Dragomir Yankov, Eamonn Keogh, Computer Science & Eng. Dept. University of California, Riverside. Umaa Rebbapragada Dept. of Computer Science Tufts University. Outline. What inspired the current work - PowerPoint PPT PresentationTRANSCRIPT

Time Series Data Mining GroupTime Series Data Mining Group
Disk Aware Discord Discovery: Finding Unusual Time Series in Terabyte Sized
Datasets
Dragomir Yankov, Eamonn Keogh,
Computer Science & Eng. Dept.
University of California, Riverside
Umaa Rebbapragada
Dept. of Computer Science
Tufts University

Time Series Data Mining GroupTime Series Data Mining Group
Outline
• What inspired the current work
• The time series discord detection problem
• An efficient algorithm for mining disk resident discords
– Detecting range-based discords
– Detecting the top k discords
• Experimental results
– Evaluating the effectiveness of the discord definition
– Scalability of the discord detection algorithm

Time Series Data Mining GroupTime Series Data Mining Group
A motivating example
• Myriads of telescopes around the world constantly record valuable astronomical data, e.g. star light-curves
Movie: By kind permissions of Prof. Richard W. Pogge, OSU
Image: Chandra X-ray observatory
• A light-curve is a real-valued time series of light magnitude measurements derived from telescopic images
Eclipsed binary:Sirius A&B

Time Series Data Mining GroupTime Series Data Mining Group
A motivating example (cont)
• The American Association of Variable Star Observers has a database of over 10.5 million variable star brightness measurements going back over ninety years
• Over 400,000 new variable star brightness measurements are added to the database every year
• Many of the observations are noisy or are preprocessed inaccurately prior to storing
• Efficient, unsupervised methods for cleaning the data are required

Time Series Data Mining GroupTime Series Data Mining Group
A motivating example (cont)• Data are inherently non-convex and hard to model
probabilistically.
•Anomalies should be
defined with respect to
the non-linear manifolds
defined by the light- curve time series
(true for many time series datasets)

Time Series Data Mining GroupTime Series Data Mining Group
Definitions and assumptions
• Notation– time series: – subseqence:
– time series database:
• Function (may not be a metric) defines an ordering for the elements in
),,( 1 mttT
11,
),,( 1
nmpmn
ttC nppi
}{ iCS
),( ji CCDistS
n
n
n
T
1iC
2iC
jiC
Nasdaq Composite (Oct06-Oct07)

Time Series Data Mining GroupTime Series Data Mining Group
Time series discords
• Most-significant discord – the subsequence with maximal distance to its nearest neighbor
SCi ),( ji CCDist
SC j iC
),( ji CCDist
jC

Time Series Data Mining GroupTime Series Data Mining Group
Generalized discord definitions
• Most-significant k-th NN discord – the subsequence with maximal distance to its k-th nearest neighbor
SCi ),( ji CCDist
SC j
iC
),( ji CCDist
jC 2k

Time Series Data Mining GroupTime Series Data Mining Group
Generalized discord definitions
• Most-significant k-NN discord – the subsequence with maximal distance to its k nearest neighbors in
SCi S
iC
jC
2k
The algorithm utilizes the first of these discord definitions for its computational efficiency and intuitive interpretation

Time Series Data Mining GroupTime Series Data Mining Group
Disk aware discord detection
• Detecting discords is harder than finding similar patterns– anytime algorithms can quickly detect similarities– anomalies require computation time
• Indexing is not a solution– time series are high dimensional– dimensionality reduction is often inadequate– linear scan is faster than 10% random disk accesses
)|(| 2SO
We are looking for an algorithm that performs two disk scans and “approximately linear” number of computations

Time Series Data Mining GroupTime Series Data Mining Group
Discord detection algorithm
• Phase 1 – candidates selection phaseS
1C
2C
3C
4C
C
r- discord range
5C
… …

Time Series Data Mining GroupTime Series Data Mining Group
Discord detection algorithm
• Phase 1 – candidates selection phaseS
1C
2C
3C
4C
C
r- discord range
5C
1C
rCCDist ),( 12… …

Time Series Data Mining GroupTime Series Data Mining Group
Discord detection algorithm
• Phase 1 – candidates selection phaseS
1C
2C
3C
4C
C
r- discord range
5C
1C
rCCDist ),( 13
2C… …

Time Series Data Mining GroupTime Series Data Mining Group
Discord detection algorithm
• Phase 1 – candidates selection phaseS
1C
2C
3C
4C
C
r- discord range
5C
rCCDist ),( 24
2C
… …

Time Series Data Mining GroupTime Series Data Mining Group
Discord detection algorithm
• Phase 1 – candidates selection phaseS
1C
2C
3C
4C
C
r- discord range
5C
rCCDist ),( 25
2C
… …
4C
rCCDist ),( 45

Time Series Data Mining GroupTime Series Data Mining Group
Discord detection algorithm
• Phase 2 – candidates refinement phaseS
1C
2C
3C
4C
C
r- discord range
5CrCCDist j ),( 1
2C
… …
4C
… …
5C
?

Time Series Data Mining GroupTime Series Data Mining Group
Discord detection algorithm
• Phase 2 – candidates refinement phaseS
1C
2C
3C
4C
C
r- discord range
5CrCCDist ),( 53
2C
… …
4C
… …
5C

Time Series Data Mining GroupTime Series Data Mining Group
Discord detection algorithm
• Phase 2 – candidates refinement phaseS
1C
2C
3C
4C
C
Upon completion sort the candidates list C
5C
2C
… …
4C
… …

Time Series Data Mining GroupTime Series Data Mining Group
Correctness of the algorithm
• The candidates set C contains all discords at distance at least r from their NN, plus some other elements
• The refinement phase removes from C all false positives, and no real discord is pruned
• Correctness: the range discord algorithm detects all discords and only the discords with respect to the specified range r

Time Series Data Mining GroupTime Series Data Mining Group
Finding a good range parameter• Selecting large r may result in an empty discord set, while
too small r can render the algorithm inefficient
• Computing the nearest neighbor distance distribution (NNDD) is
expensive
• NNDD depends on the number of examples in the data

Time Series Data Mining GroupTime Series Data Mining Group
Approximating NNDD
• Intuition – though the relative volume in the upper tail decreases, the absolute number of discords cut by r remains sufficient when adding more data
• Detecting the top k discords
1. Select a uniformly random sample
2. Compute the top k discords in
3. Order their NN distances as:
4. Set
5. Run the disk aware algorithm with range parameter
SS '
'S
kddd 21
kdr r

Time Series Data Mining GroupTime Series Data Mining Group
Experimental evaluation
We performed two sets of experiments
1. Experiments showing the utility of the time series discord definition
2. Experiments showing the scalability of the disk aware discord detection algorithm

Time Series Data Mining GroupTime Series Data Mining Group
Experimental evaluation - utility of the discord definition
• Star light-curve data from the Optical Gravitational Lensing Experiment (OGLE)
• Three classes of light-curves
- Eclipsed binaries
- Cepheids
- RR Lyrae variables
top two discordsin each class
typical examples
Time Series Data Mining GroupTime Series Data Mining Group
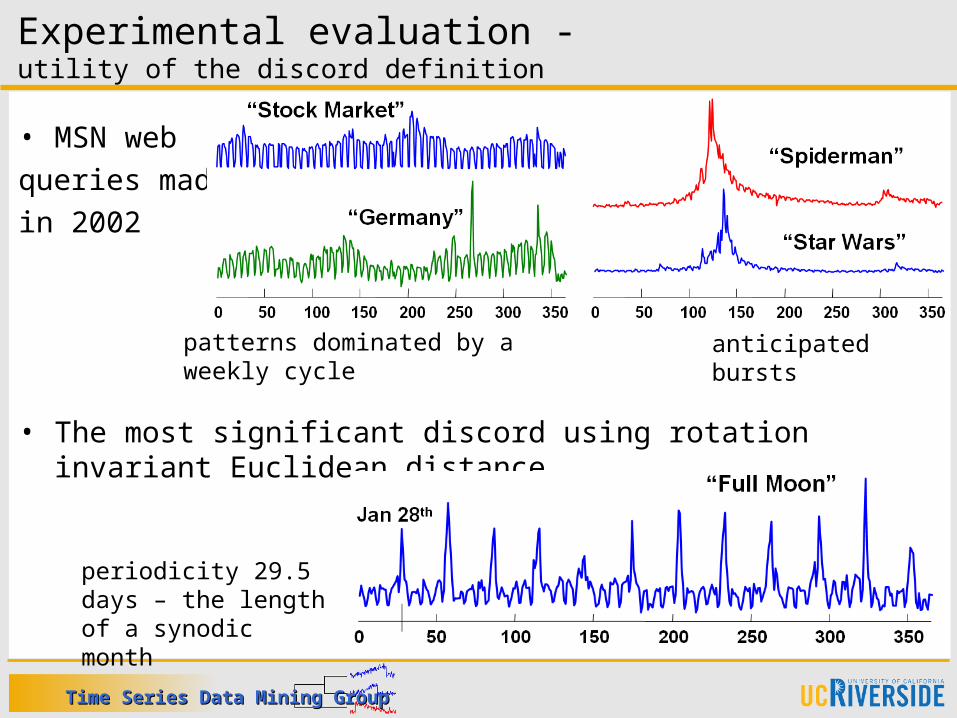
• MSN web queries made in 2002
• The most significant discord using rotation invariant Euclidean distance
Experimental evaluation -utility of the discord definition
patterns dominated by a weekly cycle
anticipated bursts
periodicity 29.5 days – the length of a synodic month
Time Series Data Mining GroupTime Series Data Mining Group
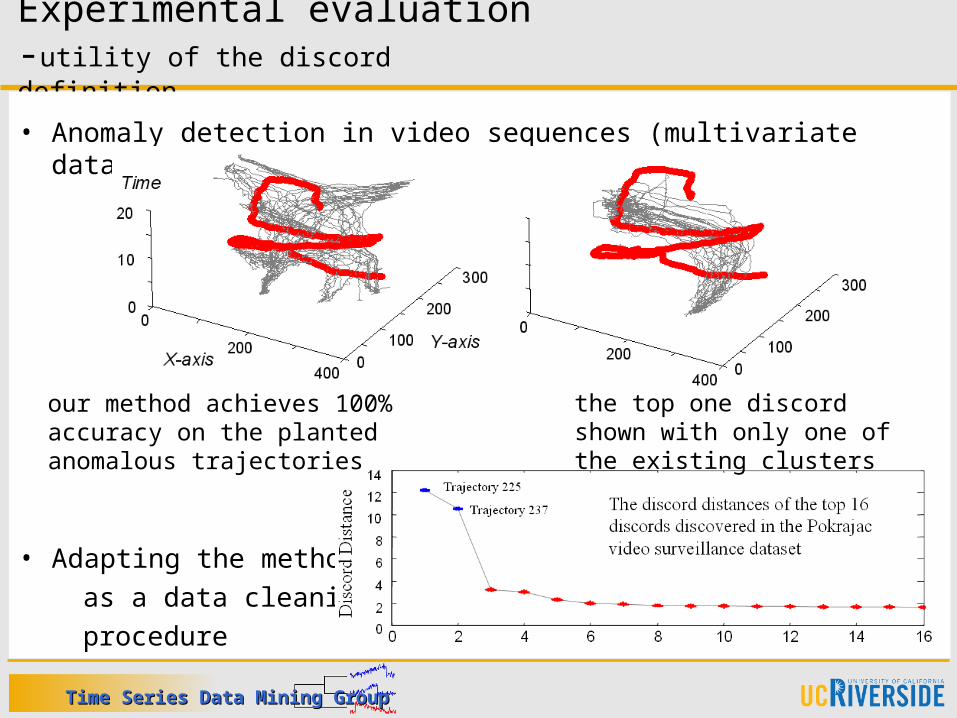
Experimental evaluation -utility of the discord definition
• Anomaly detection in video sequences (multivariate data)
• Adapting the method as a data cleaning procedure
our method achieves 100% accuracy on the planted anomalous trajectories
the top one discord shown with only one of the existing clusters
Time Series Data Mining GroupTime Series Data Mining Group
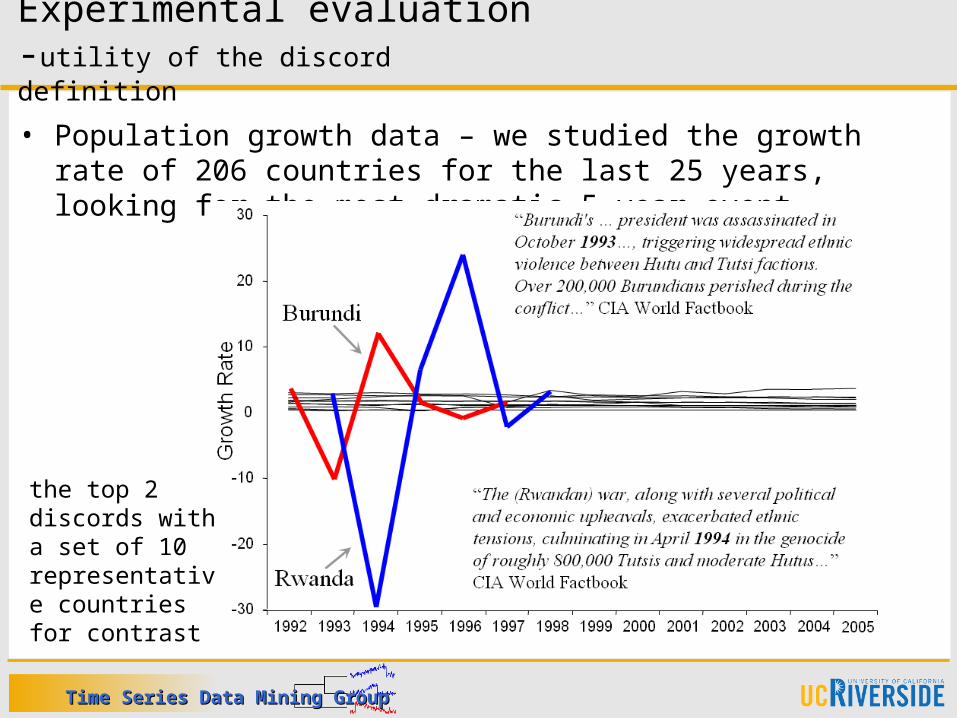
• Population growth data – we studied the growth rate of 206 countries for the last 25 years, looking for the most dramatic 5 year event
Experimental evaluation -utility of the discord definition
the top 2 discords with a set of 10 representative countries for contrast

Time Series Data Mining GroupTime Series Data Mining Group
• We generated 3 datasets of size up to 0.35Tb of random walk time series
• Six non-random walktime series were planted,we looked for the top 10 discords
• Time efficiency on the three random walk data sets:
Examples Disk size I/O Time Total time
1 million10 million
100 million
3.57 Gb35.7 Gb0.35 Tb
27min4h 30min
45h
41min7h 52min
90h 33min
Experimental evaluation –scalability of the disk aware algorithm
two of the planted series (top) were among the top 10 discords

Time Series Data Mining GroupTime Series Data Mining Group
• Time efficiency (Heterogeneous data):
• Main memory requirement for different thresholds
Examples Disk size I/O Time Total time
1.2 million
1.17 Gb 15min 16min
Experimental evaluation –scalability of the disk aware algorithm

Time Series Data Mining GroupTime Series Data Mining Group
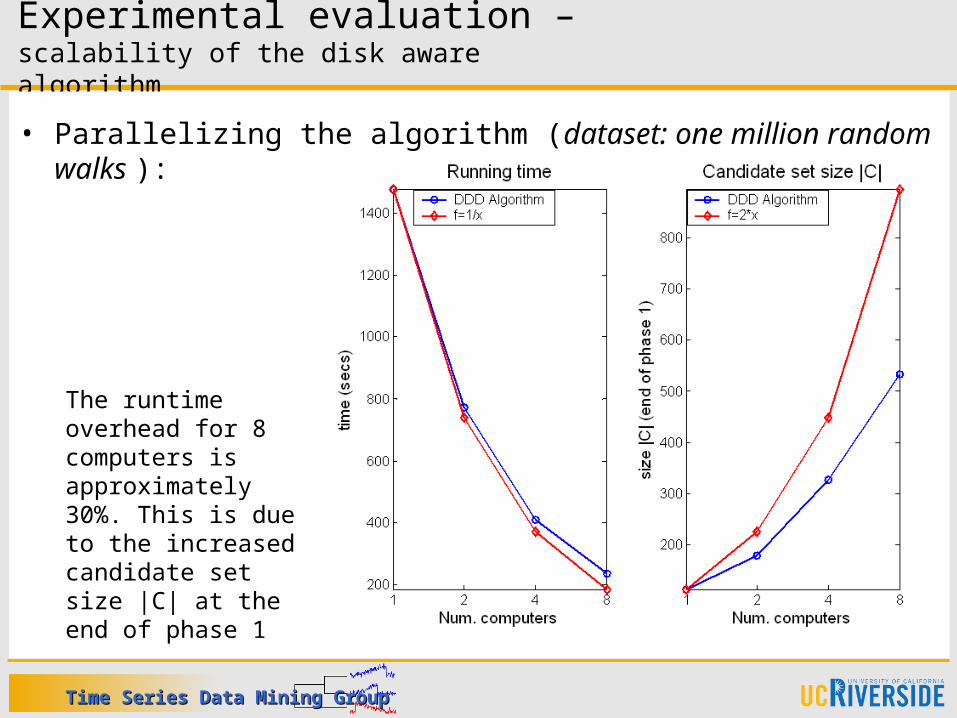
Experimental evaluation –scalability of the disk aware algorithm
• Parallelizing the algorithm (m computers):
…
mi
iCC,1
S
1C
2C
1S
2S
mSmC
CS ,1
CS ,2
CSm ,
…
mi
iCC,1
1C
2C
mC
Candidate selection phase Candidate refinement phase
Time Series Data Mining GroupTime Series Data Mining Group
Experimental evaluation –scalability of the disk aware algorithm
• Parallelizing the algorithm (dataset: one million random walks ):
The runtime overhead for 8 computers is approximately 30%. This is due to the increased candidate set size |C| at the end of phase 1

Time Series Data Mining GroupTime Series Data Mining Group
Conclusion
• Discords provide for an effective definition of rare time series patterns.
• The presented disk aware algorithm has all requirements of a good off-the-shelf data mining tool:
– The results are interpretable
– It is extremely efficient and largely scalable
– Very easy to implement (“8 lines in Matlab”)
• Allows for straight-forward parallel and online extensions

Time Series Data Mining GroupTime Series Data Mining Group
Acknowledgements
• We would like to thank to:– Dr. Pavlos Protopapas (Harvard University) – light-curve
dataset– Dr. Michail Vlachos (IBM Watson) – MSN web query data– Dr. Longin Jan Latecki (Temple University) – Trajectory
dataset1– Dr. Andrew Naftel (University of Manchester) - Trajectory
dataset2
also– Dr. Jessica Lin (George Mason University) and– Dr. Ada Fu (Chinese University of Hong Kong) – for useful
discussions
Time Series Data Mining GroupTime Series Data Mining Group
All datasets and the code can be downloaded from: http://www.cs.ucr.edu/~dyankov/projects/
THANK YOU!