distributed algorithms distributed transactionsdisi.unitn.it/~montreso/ds/handouts/13-acid.pdf ·...
TRANSCRIPT

Distributed AlgorithmsDistributed Transactions
Alberto Montresor
University of Trento, Italy
2016/05/11
This work is licensed under a Creative CommonsAttribution-ShareAlike 4.0 International License.
references
O. Babaoglu and S. Toueg.Understanding non-blocking atomic commitment.In S. Mullender, editor, Distributed Systems (2nd ed.).Addison-Wesley, 1993.http://www.disi.unitn.it/~montreso/ds/papers/
AtomicCommitment.pdf.

Contents
1 Introduction and motivation2 Transactional models
ACID PropertiesTypes of transactions
3 Implementing transactionsAtomicityIsolationDurability
4 From centralized to distributedIsolationDistributed commitment

Introduction and motivation
Introduction
Example (Transfer money between two accounts)
Withdraw 200e from account 1
Deposit 200e to account 2
What happens if one of the operations is not performed?
Definition (Transaction)
The execution of a sequence of actions on a server that must be eitherentirely completed or aborted, independently of other transactions
Our goals:
We want to allow the execution of concurrent transactions, yet tomaintain consistency
We want to deal with the failure of either the server or the client
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 1 / 42

Transactional models ACID Properties
ACID Properties
AtomicityI Either all operations are completed or none of them is executed
ConsistencyI Application invariants must hold before and after a transaction;I during the transaction, invariants may be violated but this is not
visible outside
Isolation (Serializability)I Execution of concurrent transactions should be equivalent (in effect)
to a serialized execution
DurabilityI Once a transaction commits, its effect are permanent
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 2 / 42

Transactional models ACID Properties
Transactional syntax
Applications are coded in a stylized way:I begin transactionI perform a series of read, write operationsI terminate by commit or abort
Example of transaction (sketch)
transaction Tvx ← read(”x”)vy ← read(”y”)vz ← vx + vywrite(”z”, z)commit
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 3 / 42

Transactional models Types of transactions
Flat transactions
Simplest, relatively easy to implement
Their greatest strength (atomicity) is also their weakness(lack of flexibility)
Technical issues:I How to maintain isolationI How to maintain atomicity + consistency
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 4 / 42

Transactional models Types of transactions
Nested transactions
Constructed from a number of sub-transactions
Sub-transactions may run in parallel or in sequence
The subdivision is logical
FlexibilityI When a transaction fails, all its sub-transactions must fail tooI When a sub-transaction fails:
F The parent transaction could failF Or, alternative actions could be taken
Example next slide
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 5 / 42

Transactional models Types of transactions
Nested transactions
Example of nested transaction (sketch)
transaction ”book travel”start transaction ”book flight”start transaction ”book hotel”start transaction ”book car”if ”book car” aborted then
start transaction ”book bus”
if ”book flight” and ”book hotel” and (”book car” or ”book bus”)committed then
commitelse
abort
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 6 / 42

Transactional models Types of transactions
Distributed transactions
Can be either flat or nested
Operates on distributed data (multiple servers)
Technical issuesI Separate distributed algorithms are needed to handle
F locking of data in multiple distributed systemsF committing data in an atomic way
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 7 / 42

Transactional models Types of transactions
Distributed transactions
Example of distributed transaction (sketch)
Site A, account x
transaction Tvx ← read(”x”)write(”x”, vx + C)commit
Site B, account y
transaction Tvy ← read(”y”)if vy ≥ C then
write(”y”, vy − C)commit
abort
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 8 / 42
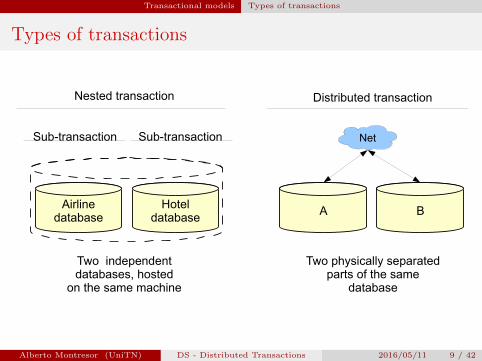
Transactional models Types of transactions
Types of transactions
Transactional model Types of transactions
Types of transactions
Airlinedatabase
Hoteldatabase
A B
Nested transaction Distributed transaction
Sub-transaction Sub-transaction
Two independent databases, hosted
on the same machine
Two physically separated parts of the same
database
Net
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 10 / 45Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 9 / 42
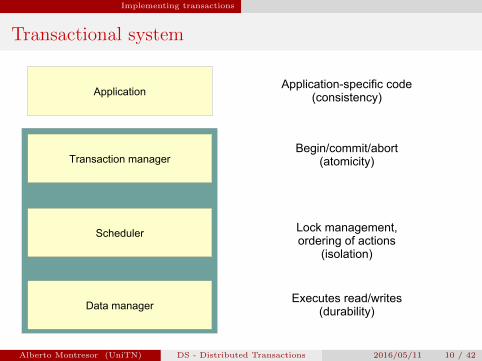
Implementing transactions
Transactional system
Implementing transactions
Transactional system
Data managerExecutes read/writes
(durability)
SchedulerLock management, ordering of actions
(isolation)
Transaction manager
Application
Begin/commit/abort(atomicity)
Application-specific code(consistency)
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 11 / 45Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 10 / 42

Implementing transactions
Atomicity
Private workspacesI At the beginning, give the transaction a private workspace and copy
all required objectsI Read/write/perform operations on the private workspaceI If all operations are successful, commit by writing the updates in
the permanent record; otherwise abort
How to extend this to a distributed system?I Each copy of the transaction on different server is given a private
workspaceI Perform a distributed atomic commitment protocol
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 11 / 42

Implementing transactions Atomicity
Atomicity
Write-ahead logI Write operation / initial state / final state on a logI Modify ”real” data
In case of commitI Mark operation as committed on the log
In case of abortI Mark operation as aborted on the logI Revert ”real” data to the initial state
How to extend this to a distributed system?I Distributed rollback recovery
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 12 / 42

Implementing transactions Atomicity
AtomicityImplementing transactions Atomicity
Atomicity
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 14 / 45Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 13 / 42

Implementing transactions Isolation
Isolation
IsolationI Means that effect of the interleaved execution is indistinguishable
from some possible serial execution of the committed transactions
Example:I T1 and T2 are interleaved but it ”looks like” T2 ran before T1
The idea:I Transactions can be coded to be correct if run in isolation, and yet
will run correctly when executed concurrently (hence gain aspeedup)
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 14 / 42

Implementing transactions Isolation
Isolation
Alice withdraws 250e from X
1) local ← read(”x”)2) local ← local − 2503) write(”x”, local)
Bob withdraws 250e from X
4) local ← read(”x”)5) local ← local − 2506) write(”x”, local)
What happens with the following sequences?
1-2-3-4-5-6 Correct
4-5-6-1-2-3 Correct
1-4-2-5-3-6 Lost update
1-2-4-5-6-3 Lost update
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 15 / 42

Implementing transactions Isolation
IsolationImplementing transactions Isolation
Isolation
DB: R1(X) R2(X) W2(X) R1(Y) W1(X) W2(Y) commit1 commit2
T1: R1(X) R1(Y) W1(X) commit1
T2: R2(X) W2(X) W2(Y) commit2
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 17 / 45
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 16 / 42

Implementing transactions Isolation
IsolationImplementing transactions Isolation
Isolation
Problem: transactions may “interfere”.
Here, T2 changes x, hence T1 should have either run first (read and write)
or after (reading the changed value).
Unsafe! Not serializable
DB: R1(X) R2(X) W2(X) R1(Y) W1(X) W2(Y) commit1 commit2
T1: R1(X) R1(Y) W1(X) commit1
T2: R2(X) W2(X) W2(Y) commit2
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 17 / 45
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 16 / 42

Implementing transactions Isolation
IsolationImplementing transactions Isolation
Isolation
T1: R1(X) R1(Y) W1(X) commit1
T2: R2(X) W2(X) W2(Y) commit2
DB: R2(X) W2(X) R1(X) W1(X) W2(Y) R1(Y) commit2 commit1
Data manager interleaves operations to improve concurrency but schedules them so that it looks as if one transaction ran at a time.
This schedule “looks” like T2 ran first.
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 17 / 45
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 16 / 42

Implementing transactions Isolation
Locking
Unlike other kinds of distributed systems, transactional systemstypically lock the data they access
Lock coverageI suppose that transaction T
will access object xI T must gets a lock that
”covers” x
We could have one lockI . . . per objectI . . . for the whole databaseI . . . for a category of objectsI . . . per tableI . . . per row
All transactions must obey thesame rules!
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 17 / 42

Implementing transactions Isolation
Strict 2-Phase locking (2-PL)
1st phase (”growing”)I Whenever the scheduler receives an operation operation(T, x)I If x is already owned by a conflicting lock:
F the operation (and the transaction) is delayed Otherwise:F the lock is granted
I Obtain all the locks it needs while it runs and hold onto them evenif no longer needed!
2nd phase (”shrinking”)I release locks only after making commit/abort decision and only
after updates are persistent
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 18 / 42

Implementing transactions Isolation
2-PL implies Serializability
Suppose that T ′ performs an operation that conflicts with anoperation that T has done
I e.g., T ′ will update data item x that T read or updatedI e.g., T updated item y and T ′ will read it
T must have had a lock on x/y that conflicts with the lock that T ′
wantsI T won’t release it until it commits or abortsI So T ′ will wait until T commits or aborts
Note: 2-PL may cause deadlocks; usual techniques apply
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 19 / 42

Implementing transactions Durability
Durability: Lampson’s stable storage
Maintain two copies of object A (A0 and A1) plus two timestampsand checksums (different disks)
Failure may happen at anytime between the six operations
Writing
update(A, x)
A0 ← xT0 ← now()S0 ← checksum(x, t0)A1 ← xT1 ← now()S1 ← checksum(x, t1)
Recovery
read(A)
if S0 = checksum(A0, T0) ∧ S1 = checksum(A1, T1) thenif T0 > T1 then return A0
else return A1
if S0 = checksum(A0, T0) ∧ S1 6= checksum(A1, T1) thenreturn A0
if S0 6= checksum(A0, T0) ∧ S1 = checksum(A1, T1) thenreturn A1
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 20 / 42

From centralized to distributed Isolation
Distributed locking
Centralized 2-PLI A single site is responsible for granting and releasing locksI Each scheduler communicates with this centralized schedulerI Issues: bottleneck, central point of failure
Primary 2-PLI Each data item is assigned to a ”primary” serverI Each scheduler communicates with the scheduler of the primaryI Issues: central points of failure
Distributed 2-PLI Locking is done in a decentralized way; messages are exchanged
through reliable multicast
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 21 / 42

From centralized to distributed Isolation
Failures on centralized system
If application crashes:I Treat as an abort
If transactional system crashes:I Abort non-committed transactions, but committed state is durable
Aborted transactions:I Leave no effect, either in database itself or in terms of indirect
side-effectsI Only need to consider committed operations in determining
serializability
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 22 / 42

From centralized to distributed Distributed commitment
Distributed commit problem
Atomic commitment
The distributed commit problem involves having an operationbeing performed by a distributed set of participants
Two protocolsI Two-phase commit (2PC)
F blocking, efficientF Jim Gray (1978)
I Three-phase commit (3PC)F non-blockingF Dale Skeen (1981)
Implementations based on a coordinator
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 23 / 42

From centralized to distributed Distributed commitment
System model
Fixed set of participants, known to all
No message losses
Synchronous communication: all messages arrive in δ time units
∆b-timeliness: it is possible to build a broadcast primitive suchthat all messages arrive in ∆b time units
Clocks existsI they are not required to be synchronizedI they may drift from real-time
Which systems:I local area networks
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 24 / 42

From centralized to distributed Distributed commitment
Generic Participant
Executed by the invoker
send 〈tstart, transaction, participants〉 to participants
Executed by all participants (including the invoker)
upon receipt of 〈tstart, transaction, participants〉 doCknow ← now(){ Perform operations requested by transaction }if willing and able to make updates permanent then
vote = yeselse
vote = no
AtomicCommitment(transaction, participants)
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 25 / 42

From centralized to distributed Distributed commitment
Coordinator selection
Coordinator axioms
AX1 At most one participant will assume the role of coordinator
AX2 If no failures occur, one participant will assume the role ofcoordinator
AX3 There exists a known constant ∆c such that no participantassumes the role of coordinator more than ∆c time units after thebeginning of the transaction
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 26 / 42

From centralized to distributed Distributed commitment
Specification
Atomic commitment
AC1 All participants that decide reach the same decision
AC2 If any participant decides commit, then all participants must havevoted yes
AC3 If all participants vote yes and no failures occur, then allparticipants decide commit
AC4 Each participant decides at most once
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 27 / 42

From centralized to distributed Distributed commitment
Atomic commitment
A generic algorithm – Atomic Commitment Protocol (ACP)
Based on a generic broadcast primitive
By ”plugging in” different versions of broadcast we obtain differentversions of ACP
Three phases:
Phase 1: The coordinator asks for votes yes/no from participantsand take a commit/abort decision
Phase 2: The coordinator disseminates the decision
Phase 3: Termination protocol; we’ll see
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 28 / 42

From centralized to distributed Distributed commitment
Atomic Commitment Protocol
From centralized to distributed Distributed commitment
Atomic Commitment Protocol (ACP)
6 A Simple Broadcast Primitive: SB
procedure atomic commitment(transaction, participants)cobegin% Task 1: Executed by the coordinator
1 send [VOTE REQUEST] to all participants % Including the coordinator2 set-timeout-to local clock + 23 wait-for (receipt of [VOTE: vote] messages from all participants)4 if (all votes are YES) then5 broadcast (COMMIT, participants)6 else broadcast (ABORT, participants)7 on-timeout8 broadcast (ABORT, participants)
//
9 % Task 2: Executed by all participants (including the coordinator)10 set-timeout-to11 wait-for (receipt of [VOTE REQUEST] from coordinator)12 send [VOTE: vote] to coordinator13 if (vote = NO) then14 decide ABORT
15 else16 set-timeout-to 217 wait-for (delivery of decision message)18 if (decision message is ABORT) then19 decide ABORT
20 else decide COMMIT
21 on-timeout22 decide according to termination protocol()23 on-timeout24 decide ABORT
coendend
Figure 2. ACP: A Generic Atomic Commitment Protocol
UBLCS-93-2 7
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 30 / 45Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 29 / 42

From centralized to distributed Distributed commitment
Atomic Commitment Protocol
From centralized to distributed Distributed commitment
Atomic Commitment Protocol (ACP)
6 A Simple Broadcast Primitive: SB
procedure atomic commitment(transaction, participants)cobegin% Task 1: Executed by the coordinator
1 send [VOTE REQUEST] to all participants % Including the coordinator2 set-timeout-to local clock + 23 wait-for (receipt of [VOTE: vote] messages from all participants)4 if (all votes are YES) then5 broadcast (COMMIT, participants)6 else broadcast (ABORT, participants)7 on-timeout8 broadcast (ABORT, participants)
//
9 % Task 2: Executed by all participants (including the coordinator)10 set-timeout-to11 wait-for (receipt of [VOTE REQUEST] from coordinator)12 send [VOTE: vote] to coordinator13 if (vote = NO) then14 decide ABORT
15 else16 set-timeout-to 217 wait-for (delivery of decision message)18 if (decision message is ABORT) then19 decide ABORT
20 else decide COMMIT
21 on-timeout22 decide according to termination protocol()23 on-timeout24 decide ABORT
coendend
Figure 2. ACP: A Generic Atomic Commitment Protocol
UBLCS-93-2 7
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 31 / 45Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 30 / 42

From centralized to distributed Distributed commitment
Terminating Best-Effort Broadcast
Definition (TBEB1 - Validity)
If p and q are correct, then every message B-broadcast by p iseventually delivered by q
Definition (TBEB2 - Uniform Integrity)
m is delivered by a process at most once, and only if it was previouslybroadcast
Definition (TBEB3 - ∆b-Timeliness)
All messages arrive in ∆b time units since the time they were sent
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 31 / 42

From centralized to distributed Distributed commitment
ACP - TBEB
The ACP algorithm with a best-effort broadcast implementationIt happens to be equivalent to 2PC
AC1: All participants thatdecide reach the same decision
See next page(too complex to fit in this box!)
AC2: If any participant decidescommit, then all participantsmust have voted yes
From the structure of the program(the coordinator must have receivedyes from all participants)
AC3: If all participants vote yesand no failures occur, then allparticipants decide commit
Given reliable communication, nofailure, synchrony, all messagesarrives before deadlines
AC4: Each participant decidesat most once
From the algorithm structure(decide op. are mutually exclusive)
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 32 / 42

From centralized to distributed Distributed commitment
Proof of AC1, by contradiction
1. Let p decide commit, let q decide abort. By AC4, p 6= q
2. p must have received a broadcast from a coordinator c
2.1 By AC2, c must have received votes yes from all, including q
3. A process decide abort in lines 14,19, 24
3.1 Line 14 is excluded by 2.13.2 Line 24 is excluded by 2.
4. So q must have delivered a message abort in line 19
5. But this message must have been sent by a coordinator differentfrom c; but this is a contradiction with AX1 (unique coordinator)
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 33 / 42

From centralized to distributed Distributed commitment
Blocking vs non-blocking
In some cases, a termination protocol is invoked
Informally, tries to contact other participants to learn a decisionI For example:
F if a process has already decided, copy the decisionF if a process has not voted, decide abort
But consider this scenario:I the coordinator crashes during the broadcast of a decisionI all faulty participants decide and then crashI all correct participants have previously voted yes, and they do not
deliver a decision
ACP-TBEB is blocking in this scenario
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 34 / 42

From centralized to distributed Distributed commitment
Blocking vs non-blocking
Non-blocking atomic commitment
{ AC1–AC4 }AC5 Every correct participant that executes the atomic commitment
protocol eventually decides
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 35 / 42

From centralized to distributed Distributed commitment
Uniform Terminating Reliable Broadcast
Definition (URB1 - Validity)
If p and q are correct, then every message B-broadcast by p iseventually delivered by q
Definition (URB2 - Uniform Agreement)
If a correct process delivers m, then all correct processes eventuallydeliver m
Definition (URB3 - Uniform Integrity)
m is delivered by a process at most once, and only if it was previouslybroadcast
Definition (URB4 - ∆b-Timeliness)
All messages arrive in ∆b time units since the time they were sent
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 36 / 42

From centralized to distributed Distributed commitment
ACP - UTRB
From centralized to distributed Distributed commitment
ACP - UTRB
9 The Non-Blocking Atomic Commitment Protocol: ACP-UTRB
procedure atomic commitment(transaction, participants)cobegin% Task 1: Executed by the coordinator
1 send [VOTE REQUEST] to all participants % Including the coordinator2 set-timeout-to local clock + 23 wait-for (receipt of [VOTE: vote] messages from all participants)4 if (all votes are YES) then5 broadcast (COMMIT, participants) % Using a UTRB6 else broadcast (ABORT, participants) % Using a UTRB7 on-timeout8 broadcast (ABORT, participants) % Using a UTRB
//
9 % Task 2: Executed by all participants (including the coordinator)10 set-timeout-to11 wait-for (receipt of [VOTE REQUEST] from coordinator)12 send [VOTE: vote] to coordinator13 if (vote = NO) then14 decide ABORT
15 else16 set-timeout-to 217 wait-for (delivery of decision message)18 if (decision message is ABORT) then19 decide ABORT
20 else decide COMMIT
21 on-timeout22 decide ABORT % Replaces termination protocol23 on-timeout24 decide ABORT
coendend
Figure 4. ACP-UTRB: A Non-Blocking Atomic Commitment Protocol Based on UTRB
UBLCS-93-2 11
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 39 / 45
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 37 / 42

From centralized to distributed Distributed commitment
ACP - UTRB
ACP - UTRB
If we use UTRB instead of TBEB, we obtain ACP-UTRB, which isequivalent to 3PC.
Correctness
The termination protocol is not needed any more.
Proof:
AC1-AC4: only AC1 is changed from before, we need to provethat q cannot decide abort in line 22
AC5: By the structure of the protocol, each line we have a decide
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 38 / 42

From centralized to distributed Distributed commitment
ACP - UTRB – Performance
ACP- BEBI 4n total messagesI n invoker-to-allI n coordinator-to-allI n all-to-coordinatorI n coordinator-to-all
ACP-UTRBI 3n+ n2 total messagesI n invoker-to-allI n coordinator-to-allI n all-to-coordinatorI n2 all-to-all
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 39 / 42

From centralized to distributed Distributed commitment
Recovery
To conclude, we need to consider the possibility of a participantthat was down becoming operational after being repaired
Recovery protocol
During normal execution, log all “transactional events” in adistributed transaction log (dt-log)
I t-start, vote yes, vote no, commit, abort
At recovery, try to conclude all transactions that were in progressat the participant at the time of crash
If recovery is not possible by simply looking at the log, try to gethelp from other participants
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 40 / 42

From centralized to distributed Distributed commitment
Recovery protocol
From centralized to distributed Distributed commitment
Recovery protocol11 Recovery from Failures
procedure recovery protocol(p)% Executed by recovering participant p
1 R := set of DT-log records regarding transaction2 case R of3 : skip4 start : decide ABORT
5 start,no : decide ABORT
6 start,vote,decision : skip7 start,yes :8 while (undecided) do9 send [HELP, transaction] to all participants10 set-timeout-to 211 wait-for receipt of [REPLY: transaction, reply] message12 if (reply ?) then13 decide reply14 else15 if (received ? replies from all participants) then16 decide ABORT
17 on-timeout18 skip
odesac
end
Figure 6. Recovery: The Recoverer’s Algorithm
11 Recovery from Failures
To complete our discussion of non-blocking atomic commitment, we need to considerthe possibility of a participant that was down becoming operational after being repaired.Such a participant returns to the operational state by executing a recovery protocol. Thisprotocol first restores the participant’s local state using a distributed transaction log (DT-log)that the participant maintains in stable storage. The protocol then tries to conclude all thetransactions that were in progress at the participant at the time of the crash. Our recoveryprotocol and DT-log management scheme are very similar to those of 2PC with cooperativetermination [3]. We include them here for completeness.
We consider the possibility of recovery by adding the following requirement to thespecification of the atomic commit problem:
AC6: If all participants that know about the transaction remain operational long enough,then they all decide.
To facilitate recovery, participants write records of certain key actions in the DT-log. Inparticular, when a participant receives a T START message, it writes a start record containingthe transaction identifier and the list of participants in the DT-log. Before a participant sendsa YES vote to the coordinator, it writes a yes record in the DT-log. If the vote is NO, a no recordis written as the vote and an abort is written as the decision. These records can be writtenbefore or after sending the NO vote. When a COMMIT (or ABORT) decision is received fromthe coordinator, the participant writes a commit (or abort) record in the DT-log. Writing of
UBLCS-93-2 14
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 43 / 45
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 41 / 42

From centralized to distributed Distributed commitment
Recovery protocolFrom centralized to distributed Distributed commitment
Recovery protocol
11 Recovery from Failures
1 upon (receipt of [HELP, transaction] message from p)2 R := set of DT-log records regarding transaction3 case R of4 : decide ABORT; send [REPLY: transaction, ABORT] to p5 start : decide ABORT; send [REPLY: transaction, ABORT] to p6 start,no : send [REPLY: transaction, ABORT] to p7 start,vote,decision : send [REPLY: transaction, decision] to p8 start,yes : send [REPLY: transaction, ?] to p
esac
Figure 7. Recovery: The Responder’s Algorithm
this decision record constitutes the act of “deciding.” In the protocol descriptions, we usevote and decision to represent arbitrary vote and decision records, respectively.
The recovery protocol consists of two components — the actions performed by therecovering participant (Figure 6) and the actions performed by other participants in responseto requests for help (Figure 7). For each transaction that was active at the time of the crash,the recovering participant first tries to decide unilaterally based on the DT-log. If it cannot,it send out requests for help from the other participants until it either receives a decisionfrom some participant, or it receives “don’t know” replies from all participants. When thisprotocol is used for recovery together with our non-blocking ACP-UTRB, we can prove thefollowing property (which is stronger than AC6):
Theorem 5 (AC6’) If a participant that knows about the transaction recovers, it will eventuallydecide provided that either (i) there was no total failure, or (ii) there was a total failure but allparticipants recover and stay operational long enough.
Proof: Let be the recovering participant. The only case where cannot decideunilaterally is if crashed after having voted YES but before having decided. We show that inboth scenarios of the theorem, eventually decides.
Suppose participant is recovering from a partial failure. In other words, there existsa participant that has never crashed. There are two cases to consider:
1. (Participant knows about the transaction) Since ACP-UTRB is non-blocking (i.e., sat-isfies AC5), eventually decides. The recovering participant succeed in contacting
for help and will decide accordingly.
2. (Participant does not knows about the transaction) By the protocol, when asked by, will unilaterally decide ABORT and send it to , forcing it to decide.
Now suppose is recovering from a total failure. Note that repeatedly sends helpmessages until either it receives a ? or it receives a reply from every participant: bothcases allow to decide. Since we assume that all participants eventually recover and remainoperational for long enough to respond to ’s request for help, one of these two conditionsmust eventually occur, and eventually decides.
Note that case in recovering from a total failure, waiting for all participants to recoveris conservative in the sense that it may be possible to recover earlier. In particular, itis sufficient to wait until the set of recovered participants contains the last one to have
UBLCS-93-2 15
Alberto Montresor (UniTN) DS - Atomic Commitment 2011/11/28 44 / 45
Alberto Montresor (UniTN) DS - Distributed Transactions 2016/05/11 42 / 42

Reading Material
O. Babaoglu and S. Toueg. Understanding non-blocking atomic commitment.
In S. Mullender, editor, Distributed Systems (2nd ed.). Addison-Wesley, 1993.
http://www.disi.unitn.it/~montreso/ds/papers/AtomicCommitment.pdf