distributed components week 6 – lecture 1. network pcs 3 tier client/server c proc c operating...
Post on 19-Dec-2015
214 views
TRANSCRIPT

Distributed components
Week 6 – Lecture 1

Network
PCs
3 TierClient/Server
c
Proc C
Operating system
File system
Operating systemPresentatio
n
DatabaseProc C
Operating system
Application

Why do we have distributed systems?
• Scalability
• Heterogeneity
• Fault tolerance

Scalability
• Able to handle growth as it arises
• Without a reduction in service i.e. response time
• Without changing the code
• Implies– Changing the host of processes– Adding hosts

Heterogeneity
• We know that components may be heterogeneous in several dimensions– The hardware platform
– The operating system
– The programming language in which it is written

Fault tolerant
• If a host fails we need to transfer the work to another host
• Seamlessly

A service request consists of three parts
• The name of the component
• The service to be performed
• The list of parameters
Requests and results are passed in messages.

So what do we need to do?
• We need– To identify the host and process that can provide
the service – To transfer messages to/from the requesting
process in one host from/to the serving process in another host reliably and quickly
– The messages need to be understood – both syntax and semantics.

Applications will be built on HTTP – e.g. WEB services
• More applications will be written using HTTP as the transport protocol and XML to pass parameters between – processes within an application
– applications within an organisation
– and applications between organisations.
• This allows thin client architectures to be more feasible and make the differences between operating systems and platforms less important

Today we want to look at a more generalised form of distributed
components –
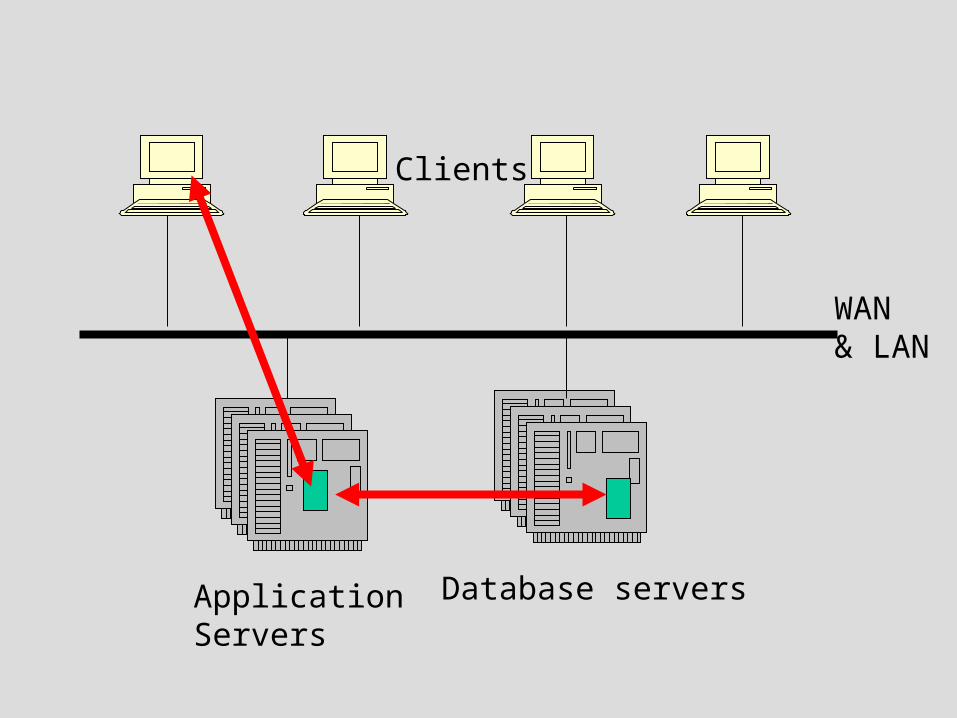
Clients
ApplicationServers
Database servers
WAN& LAN

We know that TCP will transport messages between processes on different hosts reliably, but we will need more than that.
TCP needs the IP address and then the port number
We need –- A protocol to find the host supporting the process - A protocol to ensure we are passing parameters understandably

To implement scalability and heterogeneity and fault tolerance, and to allow developers to proceed without knowing theimplementation we need transparency
There are eight layers of transparency!!
(see Emmerich – Engineering Distributed Objects – page 19-27)
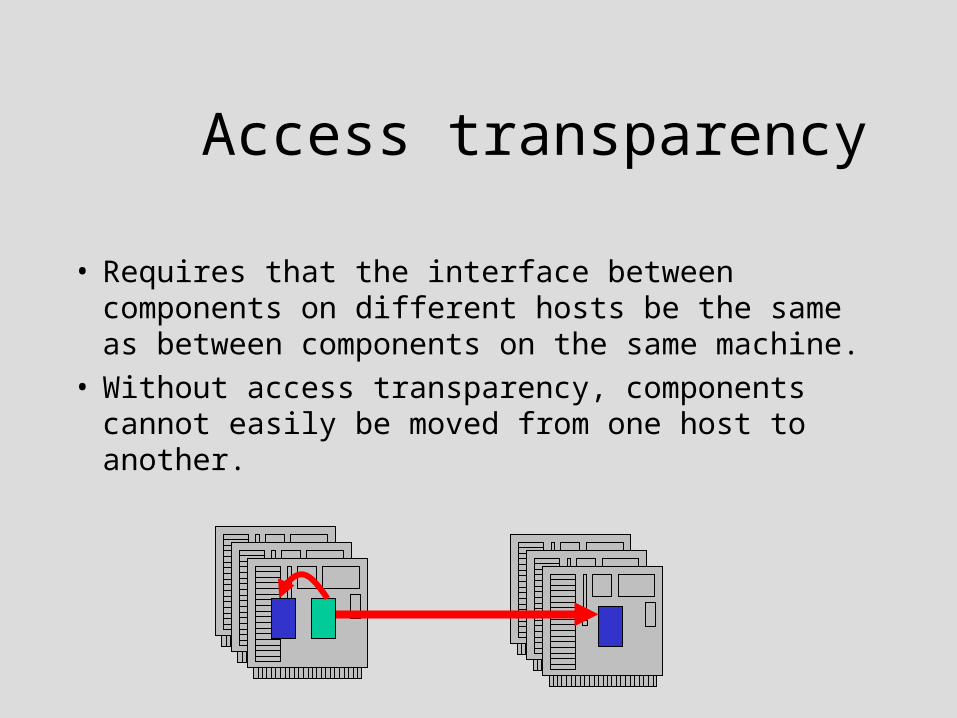
Access transparency
• Requires that the interface between components on different hosts be the same as between components on the same machine.
• Without access transparency, components cannot easily be moved from one host to another.

Location transparency
• Requires that a component can be addressed without knowledge of the host on which the component is located.
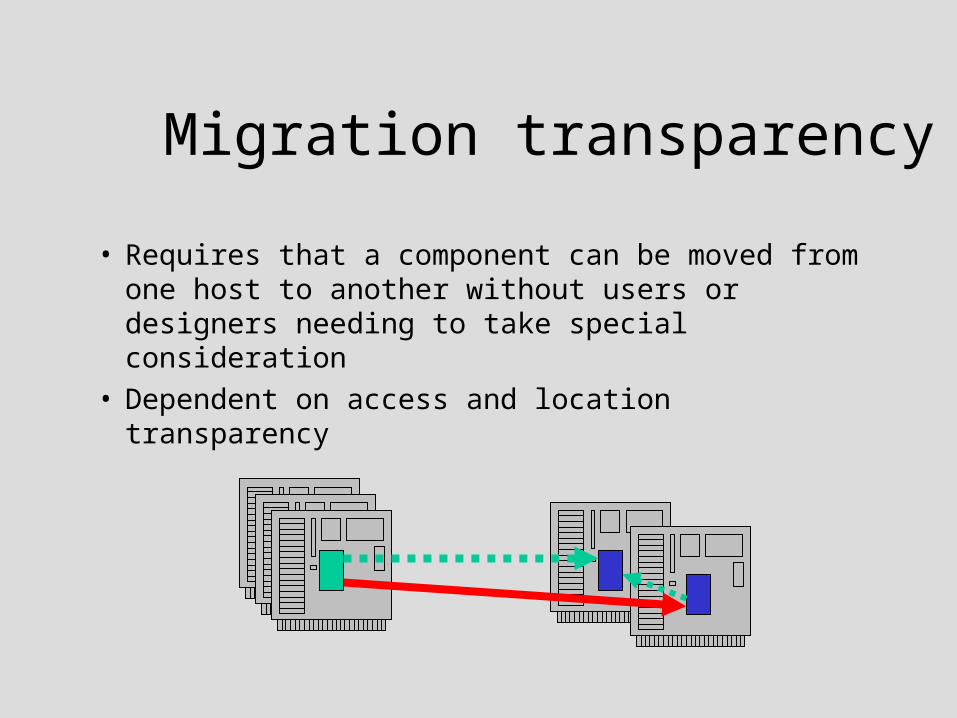
Migration transparency
• Requires that a component can be moved from one host to another without users or designers needing to take special consideration
• Dependent on access and location transparency

Replication Transparency
• Requires that multiple copies of the same component can be kept on the same or different hosts
• And that the user is not aware that the service is being provided by the copy not the original
• And that when a component changes all copies are changed simultaneously
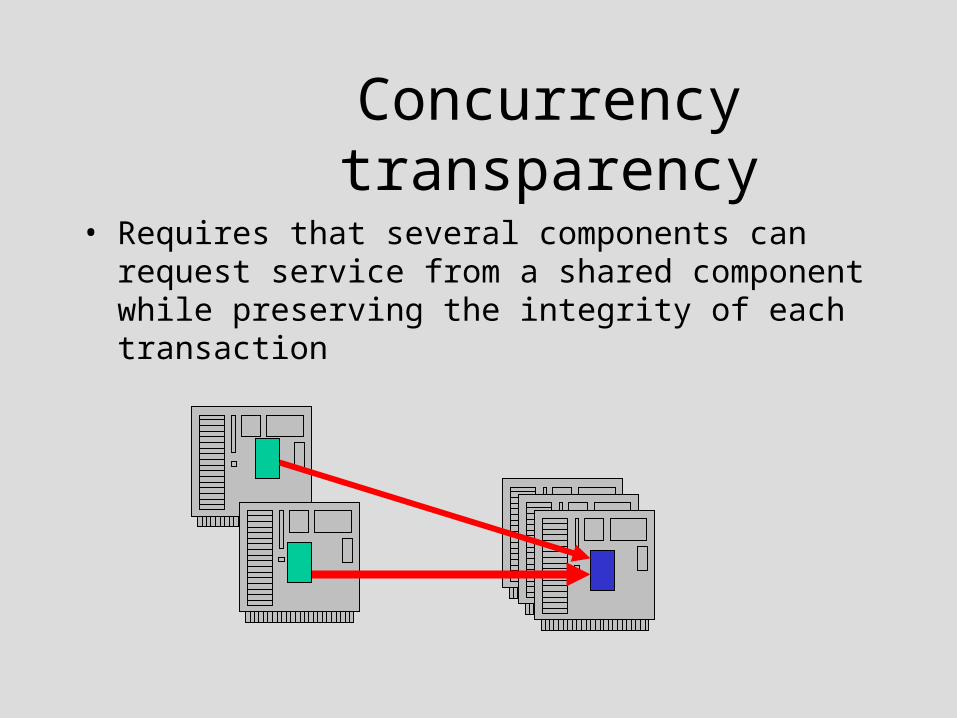
Concurrency transparency
• Requires that several components can request service from a shared component while preserving the integrity of each transaction

Scalability transparency
• Requires that it should be transparent to the designers and users of a component how scalability is to be achieved
• It is achieved by replication and migration transparency
Performance transparency
• Requires that load is balanced across multiple copies of a component such that the user does not see any reduction in performance as the number of transactions processed increases

Failure transparency
• We know that failures are more likely to occur in a distributed environment
• This facility requires that users are unaware that a failure has occurred, that recovery occurs automatically and that transactions are rerouted to other servers and processes
• If a failure occur, a transaction must not be left part processed

Why use the term “component” and not “object”?
• They may not have been written using an object oriented language
• They may not have all of the attributes of objects• They tend to be larger in scope and carry out a
significant unit of work• They are often “containers” consisting of a
number of objects• Encapsulate business functions

Reasons for using components
• Code re-use
• Assembly of new applications from pre-built components
• Support for heterogeneity
• Ability to scale

Distributed component requests have a lot of work to do
• Find the host for the process (resource discovery)
• Resolve data heterogeneity
• Synchronise client and server (parallelism)
• Transfer messages across the network
• Start the process if it is not active (and deactivate it afterwards)
• Handle errors
Perhaps 2000 times more work than to invoke a process in the same language on the same host.

So how do we do this and maintain transparency?
Data link & Physical layers
TCP/IP TCP/IPNetwork & TransportLayers
Middleware MiddlewarePresentation & Session Layers
ProcessOn Host A
Process onHost B
Application layer

Seven different approaches
• Load balancing• Transaction oriented middleware• Message oriented middleware (MOM)• Remote Procedure Calls (RPCs)• Distributed Objects• XML, UDDI, WSDL and SOAP on the WEB• GRID computing

More mnemonics to learn
• Uses XML rather than HTML to give semantic meaning to the data being exchanged
• UDDI (Universal Description Discovery Integration) to describe services
• WSDL (WEB Service Description Language)
• SOAP (Simple Object Access Protocol)