distributed deep q-learning - arxiv · distributed deep q-learning hao yi ong 1, kevin chavez 1,...
TRANSCRIPT

Distributed Deep Q-Learning
Hao Yi Ong1, Kevin Chavez1, and Augustus Hong1
Abstract— We propose a distributed deep learning model tolearn control policies directly from high-dimensional sensoryinput via reinforcement learning. The model is based on thedeep Q-network, a convolutional neural network trained withQ-learning. Its input is raw pixels and its output is a valuefunction estimating future rewards from taking an action ata given state. To distribute the deep Q-network training, weadapt the DistBelief software framework to train the reinforce-ment learning agents. As a result, the method is completelyasynchronous and scales well with the number of machines.We demonstrate that the deep Q-network agent, receiving onlythe pixels and the game score as inputs, was able to achievereasonable success on a simple game with minimal parametertuning.
I. INTRODUCTION
Reinforcement learning (RL) agents face a tremendouschallenge in optimizing their control of a system approachingreal-world complexity: they must derive efficient represen-tations of the environment from high-dimensional sensoryinputs and use these to generalize past experience to newsituations. While past work in RL has shown that with goodhand-crafted features agents are able to learn good controlpolicies, their applicability has been limited to domainswhere such features have been discovered, or to domainswith fully observed, low-dimensional state spaces [1]–[3].
We consider the problem of efficiently scaling a deeplearning algorithm to control a complicated system withhigh-dimensional sensory inputs. The basis of our algorithmis a RL agent called a deep Q-network (DQN) [4], [5] thatcombines RL with a class of artificial neural networks knownas deep neural networks [6]. DQN uses an architecture calledthe deep convolutional network, which utilizes hierarchicallayers of tiled convolutional filters to exploit the local spatialcorrelations present in images. As a result, this architectureis robust to natural transformations such as changes ofviewpoint and scale [7].
In practice, increasing the scale of deep learning withrespect to the number of training examples or the number ofmodel parameters can drastically improve the performance ofdeep neural networks [8], [9]. To train a deep network withmany parameters on multiple machines efficiently, we adapta software framework called DistBelief to the context of thetraining of RL agents [10]. Our new framework supportsdata parallelism, thereby allowing us to potentially utilizecomputing clusters with thousands of machines for large-scale distributed training, as shown in [10] in the context of
1H. Y. Ong, K. Chavez, and A. Hong are with the Departments ofMechanical Engineering, Electrical Engineering, and Computer Science,respectively, at Stanford University, Stanford, CA 94305, USA {haoyi,kjchavez, auhong}@stanford.edu
unsupervised image classification. To achieve model paral-lelism, we use Caffe, a deep learning framework developedfor image recognition that distributes training across multipleprocessor cores [11].
The contributions of this paper are twofold. First, wedevelop and implement a software framework adapted thatsupports model and data parallelism for DQN. Second, wedemonstrate and analyze the performance of our distributedRL agent. The rest of this paper is organized as follows.Section II introduces the background on the class of machinelearning problem our algorithm solves. This is followed bySection III and Section IV, which detail the serial DQNand our approach to distributing the training. Section Vdiscusses our experiments on a classic video game, and someconcluding remarks are drawn and future works mentionedin Section VI.
II. BACKGROUND
We begin with a brief review on MDPs and reinforcementlearning (RL).
A. Markov decision process
In an MDP, an agent chooses action at at time t afterobserving state st . The agent then receives reward rt , andthe state evolves probabilistically based on the current state-action pair. The explicit assumption that the next state onlydepends on the current state-action pair is referred to as theMarkov assumption. An MDP can be defined by the tuple(S ,A ,T,R), where S and A are the sets of all possiblestates and actions, respectively, T is a probabilistic transitionfunction, and R is a reward function. T gives the probabilityof transitioning into state s′ from taking action a at thecurrent state s, and is often denoted T (s,a,s′). R gives ascalar value indicating the immediate reward received fortaking action a at the current state s and is denoted R(s,a).
To solve an MDP, we compute a policy π? that, iffollowed, maximizes the expected sum of immediate rewardsfrom any given state. The optimal policy is related to theoptimal state-action value function Q? (s,a), which is theexpected value when starting in state s, taking action a,and then following actions dictated by π?. Mathematically,it obeys the Bellman recursion
Q? (s,a) = R(s,a)+ ∑s′∈S
T(s,a,s′
)maxa′∈A
Q?(s′,a′
).
The state-action value function can be computed using adynamic programming algorithm called value iteration. To
arX
iv:1
508.
0418
6v2
[cs
.LG
] 1
5 O
ct 2
015

obtain the optimal policy for state s, we compute
π? (s) = argmaxa∈A
Q? (s,a) .
B. Reinforcement learning
The problem reinforcement learning seeks to solve differsfrom the standard MDP in that the state space and transitionand reward functions are unknown to the agent. The goal ofthe agent is thus to both build an internal representation ofthe world and select actions that maximizes cumulative futurereward. To do this, the agent interacts with an environmentthrough a sequence of observations, actions, and rewards andlearns from past experience.
In our algorithm, the deep Q-network builds its internalrepresentation of its environment by explicitly approximatingthe state-action value function Q? via a deep neural network.Here, the basic idea is to estimate
Q? (s,a) = maxπ
E [Rt | st = s,at = a,π] ,
where π maps states to actions (or distributions over actions),with the additional knowledge that the optimal value functionobeys Bellman equation
Q? (s,a) = Es′∼E
[r+ γ max
a′Q?(s′,a′
)| s,a
],
where E is the MDP environment.
III. APPROACH
This section presents the general approach adapted fromthe serial deep Q-learning in [4], [5] to our purpose. Inparticular, we discuss the neural network architecture, theiterative training algorithm, and a mechanism that improvestraining convergence stability.
A. Preprocessing and network architecture
Working directly with raw video game frames can becomputationally demanding. Our algorithm applies a basicpreprocessing step aimed at reducing the input dimension-ality. Here, the raw frames are gray-scaled from their RGBrepresentation and down-sampled to a fixed size for inputto the neural network. For this paper, the function appliesthis preprocessing to the last four frames of a sequence andstacks them to produce the input to the state-action valuefunction Q.
We use an architecture in which there is a separate outputunit for each possible action, and only the state representationis an input to the neural network; i.e., the preprocessed fourframes sequence. The outputs correspond to the predictedQ-values of the individual action for the input size. Themain advantage of this type of architecture is the ability tocompute Q-values for all possible actions in a given statewith only a single forward pass through the network. Theexact architecture is presented in Appendix A, but a briefoutline is as follows. The neural network takes as input asequence of four frames preprocessed as described above.The first few layers are convolutional layers that applies a
rectifier nonlinearity
f (x) = max(0,x) ,
which was empirically observed to model real/integer valuedinputs well [12], [13], as is required in our case. Theremaining layers are fully-connected linear layers with asingle output for each valid action. The number of validactions varies with the game application. The neural networkis implemented on Caffe [11], which is a versatile deeplearning framework that allows us to define the networkarchitecture and training parameters freely. And becauseCaffe is designed to take advantage of all available com-puting resources on a machine, we can easily achieve modelparallelism using the software.
B. Q-learning
We parameterize the approximate value functionQ(s,a | θ) using the deep convolutional network asdescribed above, in which θ are the parameters of theQ-network. These parameters are iteratively updated by theminimizers of the loss function
Li (θi) = Es,a∼ρ(·)
[(yi−Q(s,a;θi))
2], (1)
with iteration number i, target yi =Es′∼E [r+ γ maxa′Q(s′,a′;θi−1) | s,a], and “behaviordistribution” (exploration policy ρ (s,a). The optimizers ofthe Q-network loss function can be computed by gradientdescent
Q(s,a;θ) := Q(s,a;θ)+α∇θ Q(s,a;θ) ,
with learning rate α .For computational expedience, the parameters are updated
after every time step; i.e., with every new experience. Ouralgorithm also avoids computing full expectations, and wetrain on single samples from ρ and E . This results in theQ-learning update
Q(s,a) := Q(s,a)+α(
r+ γ maxa′
Q(s′,a′
)−Q(s,a)
).
The procedure is an off-policy training method [14] thatlearns the policy a = argmaxa Q(s,a;θ) while using anexploration policy or behavior distribution selected by anε-greedy strategy.
The target network parameters used to compute y in Eq. (1)are only updated with the Q-network parameters every Csteps and are held fixed between individual updates. Thesestaggered updates stabilizes the learning process comparedto the standard Q-learning process, where an update that in-creases Q(st ,at) often also increases Q(st+1,a) for all a andhence also increases the target y. These immediate updatescould potentially lead to oscillations or even divergence ofthe policy. Deliberately introducing a delay between the timean update to Q is made and the time the update affects thetargets makes divergence or oscillations more unlikely [4],[5].
2

C. Experience replay
Reinforcement learning can be unstable or even divergewhen a nonlinear function approximator such as a neuralnetwork is used to represent the value function [15]. Thisinstability has several causes. A source of instability is thecorrelations present in the sequence of observations. Addi-tionally, the fact that small updates to Q may significantlychange the policy and therefore change the data distribution.Finally, the correlations between Q and its target valuescan cause the learning to diverge. [4], [5] address theseinstabilities uses a mechanism called experience replay thatrandomizes over the data, thereby removing correlations inthe observation sequence and smoothing over changes in thedata distribution.
In experience replay, the agent’s experiences at each timestep is stored as a tuple et = (st ,at ,rt ,st+1) in a datasetDt = (e1, . . . ,et) pooled over many game instances (definedby the start and termination of a game) into a replay memory.During the inner loop of the algorithm, we apply Q-learningupdates, or minibatch updates, to samples of experiencedrawn at random from the replay dataset.
This approach demonstrates several improvements overstandard Q-learning. First, each step of experience is poten-tially used in many weight updates, thus allowing for greaterdata efficiency. Second, learning directly from consecutivesamples is inefficient due to the strong correlations betweenthe samples. Randomizing the samples breaks these correla-tions and reduces the update variance. Last, when learningon-policy the current parameters determine the next datasample that the parameters are trained on. For instance, if themaximizing action is to move left then the training sampleswill be dominated by samples from the left-hand side; if themaximizing action then changes to the right then the trainingdistribution will also change. Unwanted feedback loops maytherefore arise and the method could get stuck in a poor localminimum or even diverge.
With experience replay, the behavior distribution is aver-aged over many of its states, smoothing out learning andavoiding oscillations or divergence in the parameters. Notethat when learning by experience replay, it is necessary tolearn off-policy because our current parameters are differentto those used to generate the sample, which motivates thechoice of Q-learning.
In practice, our algorithm only stores the last N experiencetuples in the replay memory. It then samples uniformly atrandom from D when performing updates. This approachis limited because the memory buffer does not differenti-ate important transitions and always overwrites with recenttransitions owing to the finite memory size N. Similarly, theuniform sampling gives equal importance to all transitions inthe replay memory. A more sophisticated sampling strategymight emphasize transitions from which we can learn themost, similar to prioritized sweeping [16].
IV. DISTRIBUTED DEEP Q-LEARNING
Algorithm 1 and Algorithm 2 define the distributed deepQ-learning algorithm. In this section we discuss some im-
portant points about parallelism and performance.
Algorithm 1 Worker k: ComputeGradientstate: Replay dataset Dk, game state st , target model θ̂ , targetmodel generation `
Fetch model θ and iteration number n from server.if n≥ ` C then
θ̂ ← θ`← bn/Cc+1
q←max{(Nmax−n)/Nmax,0}ε ← (1−q)εmin +qεmax
Select action at =
{maxa Q(φ (st) ,a;θ) w.p. 1− εrandom action otherwise
Execute action at and observe reward rt and frame xt+1
Append st+1 = (st ,at ,xt+1) and preprocess φt+1 = φ (st+1)
Store experience (φt ,at ,rt ,φt+1) in Dk
Uniformly sample minibatch of experiences X from Dk,where X j =
(φ j,a j,r j,φ j+1
)
Set y j =
{r j if φ j+1 terminalr j + γ maxa′ Q̂
(φ j+1,a′; θ̂
)otherwise
∆θ ← ∇θ f (θ ;X) =1b
b
∑i=1
∇θ
(12(Q(φi,ai;θ)− yi)
2)
Send ∆θ to parameter server.
A. Data parallelism
The serial Deep Q-learning algorithm uses stochastic gra-dient descent to train the Q network. SGD is an inherentlysequential algorithm, but various attempts have been madeto parallelize it effectively. We implement a variant ofDownpour SGD that takes advantage of data parallelism[10]. Unlike the “vanilla” version of Downpour SGD, ourRL agents actively add experiences to the memory replaydataset (see Fig. 1).
parameter server
RL agent 1 RL agent 2 RL agentm
….
replay dataset m
replay dataset 2
replay dataset 1
….
env env env
learner server
gradient/sync
store experience
Fig. 1: A variant of Downpour SGD adapted to deep Q-learning.
A parameter server stores a global copy of the model. Eachworker node is responsible for
1) fetching the latest model, θ , from the server
3

Algorithm 2 Distributed deep Q-learning
function RMSPROPUPDATE(∆θ )ri← 0.9ri +0.1(∆θ)2
i for all iAcquire write-lockθi← θi−α (∆θ)i /
√ri
Release write-lockInitialize server θi ∼N (0,ξ ), r← 0, n← 0for all workers k do
AsyncStartPopulate Dk by playing with random actionsrepeat
COMPUTEGRADIENT
until server timeoutAsyncEnd
while n < MaxIters doif latest model requested by worker k then
Acquire write-lockSend (θ ,n) to worker kRelease write-lock
if gradient ∆θ received from worker k thenRMSPROPUPDATE(∆θ )n← n+1
Shutdown server
2) generating new data for its local shard3) computing a gradient using this model and mini-batch
from its local replay memory dataset4) sending the gradient ∆θ back to the server.These operations constitute a single worker iteration.
All workers perform these iterations independently, asyn-chronously fetching from and pushing to the parameterserver. Upon receiving a gradient, the parameter serverimmediately applies an update to the global model. The onlysynchronization is a write-lock on the model as it is beingwritten to the network buffer.
For typical sizes of Q-networks, it takes much longer tocompute a mini-batch gradient than it does to perform aparameter update. Therefore we can train on more data inthe same amount of time by simply adding worker nodes(eventually this breaks, as we discuss later). Since eachmini-batch is supposed to be drawn uniformly at randomfrom some history of experiences, we can keep completelyindependent histories on each of the worker nodes andsample only from the local dataset. This allows our algorithmto scale extremely well with the size of the training data.
B. Model parallelism
Google’s implementation of Downpour SGD distributeseach model replica across multiple machines. This allowsthem to scale to very large models. Our implementation,on the other hand, assumes that the model fits on a single
machine. This places a strict upper bound on the size ofthe model. However, it allows us to easily take advantageof hardware acceleration for a single node’s computation.We use the Caffe deep learning framework to perform thegradient computation on each of the worker machines. Caffeallows us to take advantage of fast BLAS implementations,using the worker’s CPU or GPU resources.
In this sense, the work done by a single node is alsoparallelized—either across multiple CPU cores or many GPUcores. Pushing the computation down to the GPU yields asubstantial speed up, but it further constrains the size of themodel. The GPU memory must not only hold the modeland batch of data, but also all the intermediate outputs ofthe feedforward computation. This memory limit is oftenapproached in practice, especially for lower end GPUs. TheCPU’s memory is much more accommodating and should beable to hold any reasonably large model. In the case wherethe worker computation must be done on the CPU due tomemory constraints, the advantages of distributed deep Qare even more drastic.
C. Communication pattern
The server must communicate with all workers since eachrequires the latest model at every iteration. Each worker, inturn, communicates with the server to send a gradient, butdoes not need to communicate with any other worker node.This is similar to a one-to-all and all-to-one communicationpattern, which could benefit from the allreduce primitive.However, all of the communication happens asynchronously,breaking the allreduce communication pattern. Further,to minimize the “staleness” of the model used by a worker forits gradient computation, it should fetch the latest version ofthe model directly from the server, not in bit-torrent fashionfrom its peers.
D. Scalability issues
As we scale up the number of worker nodes, certainissues become increasingly important in thinking about theperformance of the distributed deep Q-learning algorithm.
1) Server bottleneck: With few machines, the speed oftraining is bound by the gradient computation time. In thisregime, the frequency of parameter updates grows linearlywith the number of workers. However, the server takes somefinite amount of time, τ , to receive a gradient message andapply a parameter update. Thus, even with an infinite poolof workers, we cannot perform more than 1/τ updates persecond.
This latency, τ , is generally small compared to the gradientcomputation time, but it becomes more significant as thenumber of workers increases. Suppose a mini-batch gradientcan be computed in time T . A pool of P workers will—on average—serve up a new gradient every T/P. Thus,once we have P = T/τ workers, we will no longer see anyimprovement by adding nodes.
This is potentially alarming, especially since both T andτ grow linearly with the model size (i.e. the ratio T/τ isconstant). However, one way to improve performance beyond
4

this limit is to increase the batch size. Note that this increasesthe single worker computation time T , but does not affectthe server latency τ . Another option is to use a powerfulmachine for the server and further optimize our server-sidecode to reduce τ .
2) Gradient staleness: As the frequency of parameterupdates grows, it becomes increasingly likely that a gradientreceived by the server was computed using a significantlyoutdated model. This increases the noise in the parameterupdates and could potentially slow down the optimizationprocess and lead to problems with convergence. In practice,using adaptive learning rate methods like RMSprop or Ada-Grad, we do not see such issues. However, as the number ofworkers increases, this could become a significant problemand should be examined carefully.
E. Implementation details
We rely on a slighted out-of-date version of Caffe (whichis included as a submodule) as well as Spark for runningthe multi-worker version of distributed deep Q-learning. Ourimplementation does not make heavy use of Spark. How-ever, Spark does facilitate scheduling of gradient updates,coordinating the addresses of all machines involved in thecomputation, and shipping the necessary files and serializedcode to all of the worker nodes. We also made some progresstowards a more generic interface between Caffe and Sparkusing MemoryDataLayers and shared memory. For this,please see the shmem branch of the GitHub repository.
F. Complexity analysis
1) Convolutional neural network: To analyze our modelcomplexity, we break our neural network into three com-ponents. The first part consists of the convolutional layersof the convolutional neural network (CNN). The complexityfor this part is O
(d2Fk2N2LC
), where we have frame width
d, frame count F , filter width k, filter count N, convolutionlayer count LC. The second part consists of the fully con-nected layers and its complexity is O
(H2LB
), where H is
the node count and LB is the hidden layer count. Finally,the “bridge” between the convolutional layers and fullyconnected layers contributes a complexity of O
(Hd2N
).
The total number of parameters in the model p is thusO(d2Fk2N2LC +H2LB +Hd2N
). We use the variable p to
simplify our notation.2) Runtime: Consider a single worker and its interaction
with the parameter server. The run-time for a single param-eter update is the time to compute a gradient, T , plus thetime to perform the update, τ . Both T and τ are O(p), butthe constant factor differs substantially. Further, the servertakes at least time τ to perform an update, regardless of thenumber of workers.
Thus the run-time for N parameter updates using k workermachines is O(N p/k) if k < T/τ or O(Nτ) otherwise.
3) Communication cost: Each iteration requires both amodel and a gradient to be sent over the network. Thisis O(p) data. We do this for N iterations. Thus the totalcommunication cost is O(N p).
V. NUMERICAL EXPERIMENTS
To validate our approach, we apply it on the classic gameof Snake and empirically demonstrate the performance ofour algorithm.
A. Snake
We implemented the Snake game in Python. To generateexperiences, our program preprocesses the frames of thegame and feeds them into our neural network (see Fig. 2).In our implementation, the Spark driver sends a script toeach worker that spawns a local game instance and a neuralnetwork. Using the neural network, the worker generatesexperience tuples by interacting with the game. The gameis made up of an n× n array. The snake starts with bodylength of two and gains an additional body length when iteats an “apple.” Ingesting an apple awards the agent onepoint. At game termination, conditioned on the snake hittingitself, the agent loses one point. The goal of the game is tomaximize the score by having the snake eat more apples andnot dying. Each worker sends their model to the server afterevery gradient computation, and receives the latest modelfrom the server periodically as detailed in Section IV.
raw screen downsample + grayscale
final input
Fig. 2: Preprocessing consists of downsampling and gray-scaling the image, and then cropping the image to the inputsize of our neural network.
B. Computation and communication
Figure 3 shows the experiment runtimes with differentmodel sizes, which correspond to different game frame sizes.The legend is as follows. “comms” refers to the amountof time required for sending the model parameters between(either way) the parameter server and one worker. “gradient”refers to the compute time required to calculate a gradientupdate by a worker. “latency” refers to the amount of timerequired by the parameter server to update its weights withone set of gradients. The training rate was compute-boundby gradient calculations by each worker in our experiments.
Note that the gradient calculation line is two orders ofmagnitude larger than the other two lines in the figure. Notealso that the upper bound on number of updates per second isinversely proportional to number of parameters in the model,since the single parameter server cannot update its weights
5
faster than a linear rate with respect to the number of updatesin a serial fashion. Thus we observe that as the number ofworkers and model size increase, the update latency couldbecome the bottleneck of the learning process. To preventsuch bottlenecks, we can increase the minibatch size for eachgradient update. This modification would therefore increasethe compute time required by each worker machine andtherefore reduce the rate at which gradient updates are sentto the parameter server. Additionally, the gradient estimateswould be better due to the larger minibatch size.
0 2 4 6 8
·106
0
50
100
150
number of parameters
expe
rim
enta
ltim
es
comms (x1 ms)gradient (x100 ms)latency (x1 ms)
Fig. 3: Compute and communication times for various pro-cesses.
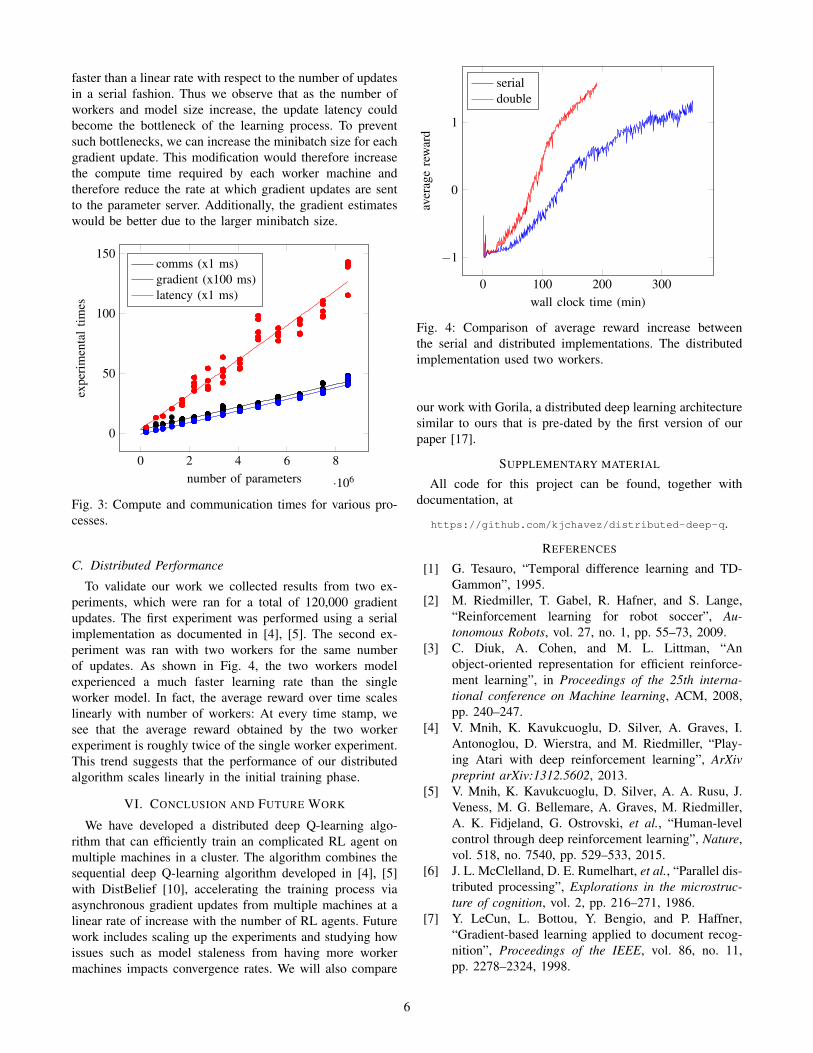
C. Distributed Performance
To validate our work we collected results from two ex-periments, which were ran for a total of 120,000 gradientupdates. The first experiment was performed using a serialimplementation as documented in [4], [5]. The second ex-periment was ran with two workers for the same numberof updates. As shown in Fig. 4, the two workers modelexperienced a much faster learning rate than the singleworker model. In fact, the average reward over time scaleslinearly with number of workers: At every time stamp, wesee that the average reward obtained by the two workerexperiment is roughly twice of the single worker experiment.This trend suggests that the performance of our distributedalgorithm scales linearly in the initial training phase.
VI. CONCLUSION AND FUTURE WORK
We have developed a distributed deep Q-learning algo-rithm that can efficiently train an complicated RL agent onmultiple machines in a cluster. The algorithm combines thesequential deep Q-learning algorithm developed in [4], [5]with DistBelief [10], accelerating the training process viaasynchronous gradient updates from multiple machines at alinear rate of increase with the number of RL agents. Futurework includes scaling up the experiments and studying howissues such as model staleness from having more workermachines impacts convergence rates. We will also compare
0 100 200 300
−1
0
1
wall clock time (min)
aver
age
rew
ard
serialdouble
Fig. 4: Comparison of average reward increase betweenthe serial and distributed implementations. The distributedimplementation used two workers.
our work with Gorila, a distributed deep learning architecturesimilar to ours that is pre-dated by the first version of ourpaper [17].
SUPPLEMENTARY MATERIAL
All code for this project can be found, together withdocumentation, at
https://github.com/kjchavez/distributed-deep-q.
REFERENCES
[1] G. Tesauro, “Temporal difference learning and TD-Gammon”, 1995.
[2] M. Riedmiller, T. Gabel, R. Hafner, and S. Lange,“Reinforcement learning for robot soccer”, Au-tonomous Robots, vol. 27, no. 1, pp. 55–73, 2009.
[3] C. Diuk, A. Cohen, and M. L. Littman, “Anobject-oriented representation for efficient reinforce-ment learning”, in Proceedings of the 25th interna-tional conference on Machine learning, ACM, 2008,pp. 240–247.
[4] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I.Antonoglou, D. Wierstra, and M. Riedmiller, “Play-ing Atari with deep reinforcement learning”, ArXivpreprint arXiv:1312.5602, 2013.
[5] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J.Veness, M. G. Bellemare, A. Graves, M. Riedmiller,A. K. Fidjeland, G. Ostrovski, et al., “Human-levelcontrol through deep reinforcement learning”, Nature,vol. 518, no. 7540, pp. 529–533, 2015.
[6] J. L. McClelland, D. E. Rumelhart, et al., “Parallel dis-tributed processing”, Explorations in the microstruc-ture of cognition, vol. 2, pp. 216–271, 1986.
[7] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner,“Gradient-based learning applied to document recog-nition”, Proceedings of the IEEE, vol. 86, no. 11,pp. 2278–2324, 1998.
6

[8] A. Coates, A. Y. Ng, and H. Lee, “An analysis ofsingle-layer networks in unsupervised feature learn-ing”, in International Conference on Artificial Intelli-gence and Statistics, 2011, pp. 215–223.
[9] J. Ngiam, A. Coates, A. Lahiri, B. Prochnow, Q. V. Le,and A. Y. Ng, “On optimization methods for deeplearning”, in Proceedings of the 28th InternationalConference on Machine Learning (ICML-11), 2011,pp. 265–272.
[10] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin,M. Mao, A. Senior, P. Tucker, K. Yang, Q. V. Le,et al., “Large scale distributed deep networks”, inAdvances in Neural Information Processing Systems,2012, pp. 1223–1231.
[11] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J.Long, R. Girshick, S. Guadarrama, and T. Darrell,“Caffe: Convolutional architecture for fast feature em-bedding”, ArXiv preprint arXiv:1408.5093, 2014.
[12] M. Hausknecht, J. Lehman, R. Miikkulainen, and P.Stone, “A neuroevolution approach to general atarigame playing”, 2013.
[13] K. Jarrett, K. Kavukcuoglu, M Ranzato, and Y. LeCun,“What is the best multi-stage architecture for objectrecognition?”, in Computer Vision, 2009 IEEE 12thInternational Conference on, IEEE, 2009, pp. 2146–2153.
[14] D. Precup, R. S. Sutton, and S. Dasgupta, “Off-policytemporal-difference learning with function approxima-tion”, in ICML, Citeseer, 2001, pp. 417–424.
[15] J. N. Tsitsiklis and B. Van Roy, “An analysis oftemporal-difference learning with function approxima-tion”, Automatic Control, IEEE Transactions on, vol.42, no. 5, pp. 674–690, 1997.
[16] A. W. Moore and C. G. Atkeson, “Prioritized sweep-ing: Reinforcement learning with less data and lesstime”, Machine Learning, vol. 13, no. 1, pp. 103–130,1993.
[17] A. Nair, P. Srinivasan, S. Blackwell, C. Alcicek, R.Fearon, A. De Maria, V. Panneershelvam, M. Su-leyman, C. Beattie, S. Petersen, et al., “Massivelyparallel methods for deep reinforcement learning”,ArXiv preprint arXiv:1507.04296, 2015.
APPENDIX
A. Network architecture
Figure 5 visualizes the exact architecture of our deepneural network, as implemented in Caffe. Note that unlikein the “vanilla” DQN agent developed in [4], [5], our variantwas designed as a single RL agent with both the target andactively training neural networks. This feature was enabledby special layers provided in the Caffe framework.
7

Fig. 5: Deep neural network architecture for numerical experiments.
8