distributed keyword search over rdf via mapreduce
TRANSCRIPT

Distributed Keyword Search over RDF via MapReduce
Roberto De Virgilio and Antonio Maccioni
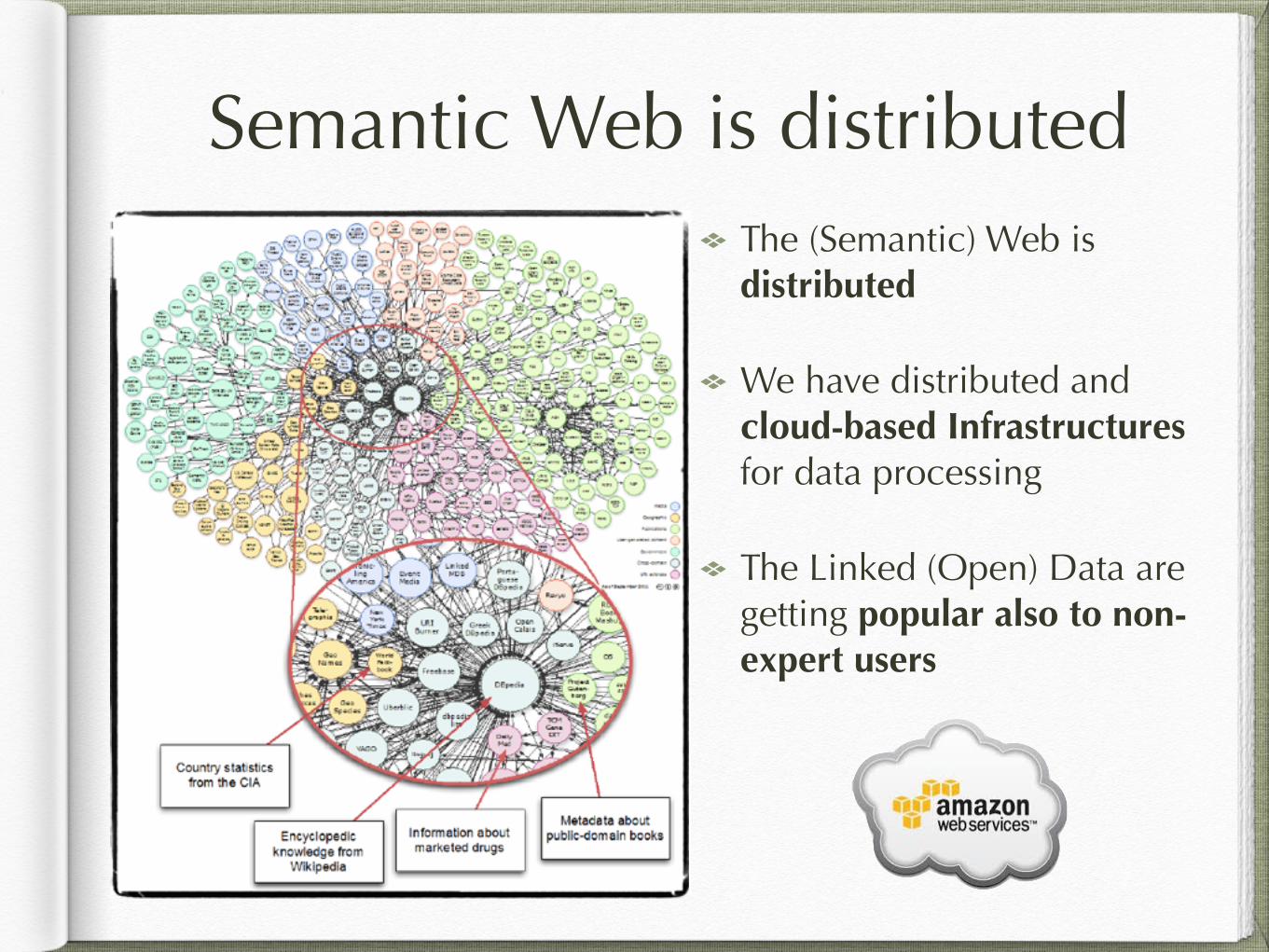
Semantic Web is distributedThe (Semantic) Web is distributed
We have distributed and cloud-based Infrastructures for data processing
The Linked (Open) Data are getting popular also to non-expert users
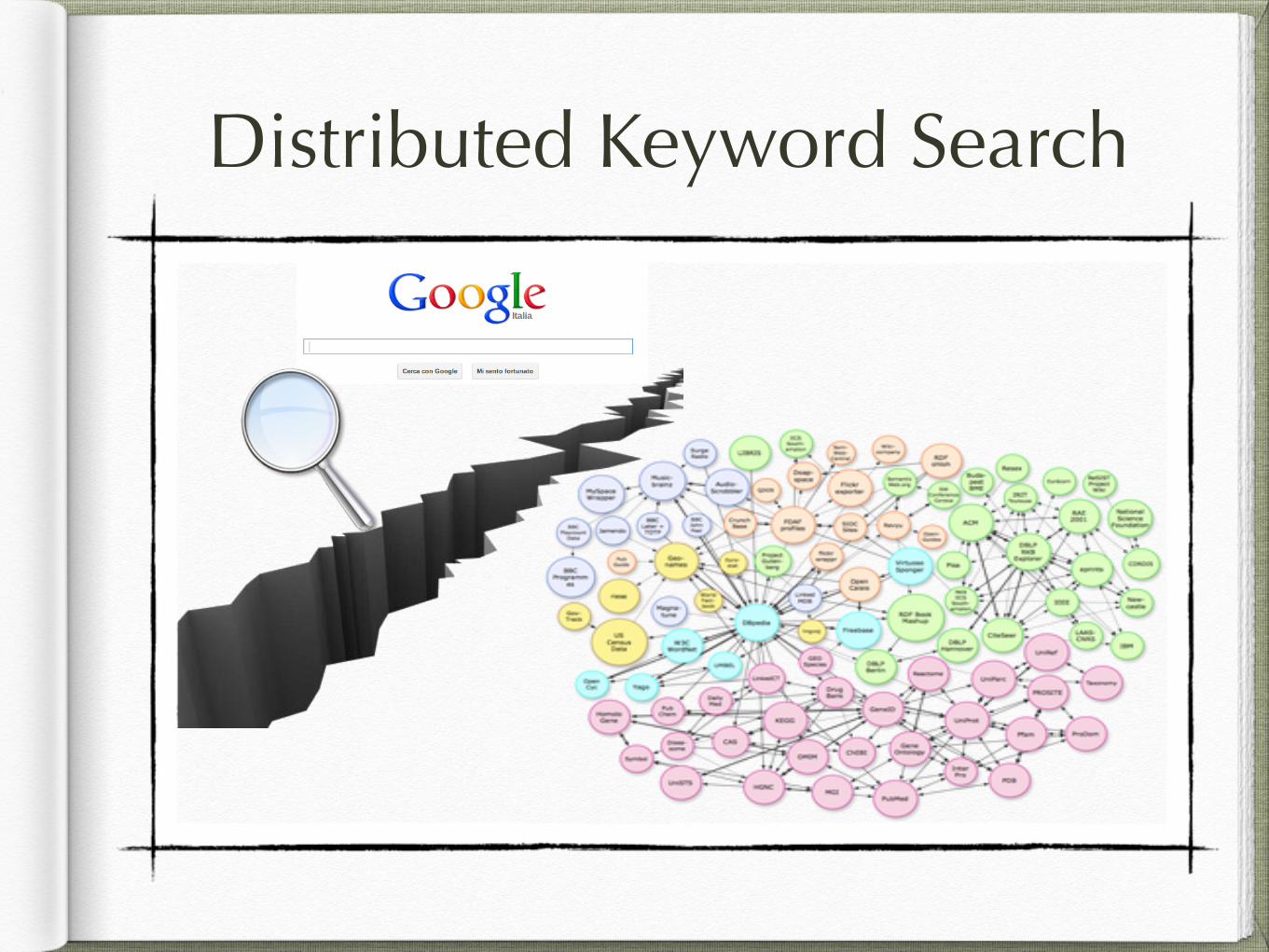
Distributed Keyword Search
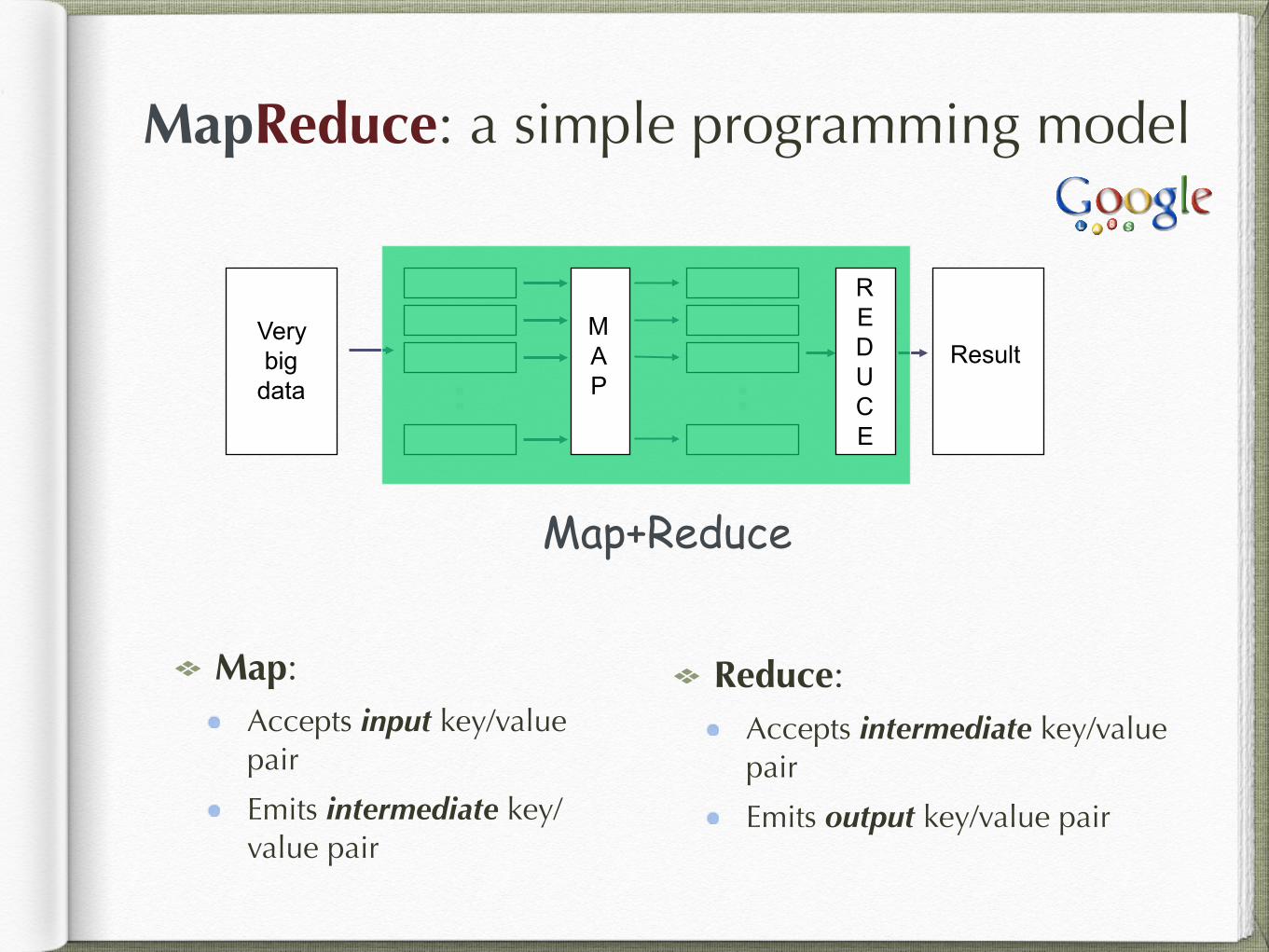
MapReduce: a simple programming model
Map+Reduce
Map: Accepts input key/value pair
Emits intermediate key/value pair
Reduce: Accepts intermediate key/value pair
Emits output key/value pair
Very big
data Result
M A P
R E D U C E
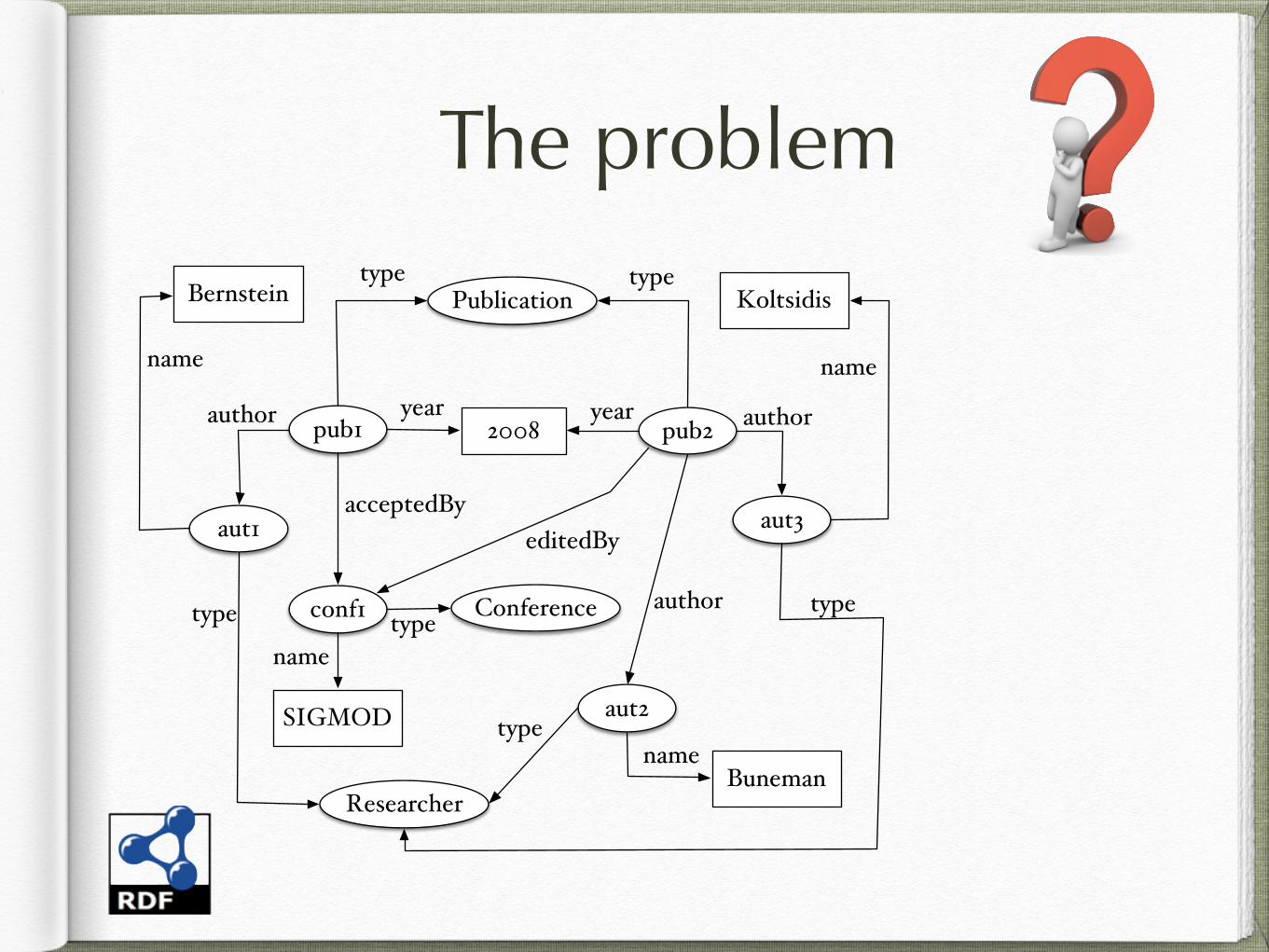
The problem
Bernstein
SIGMOD
Koltsidis
Buneman
2008pub1 pub2
Publication
Conferenceconf1
aut1
aut2
aut3
Researcher
type type
name name
name
author authoryear year
name
editedBy
acceptedBy
type
type
typetypeauthor
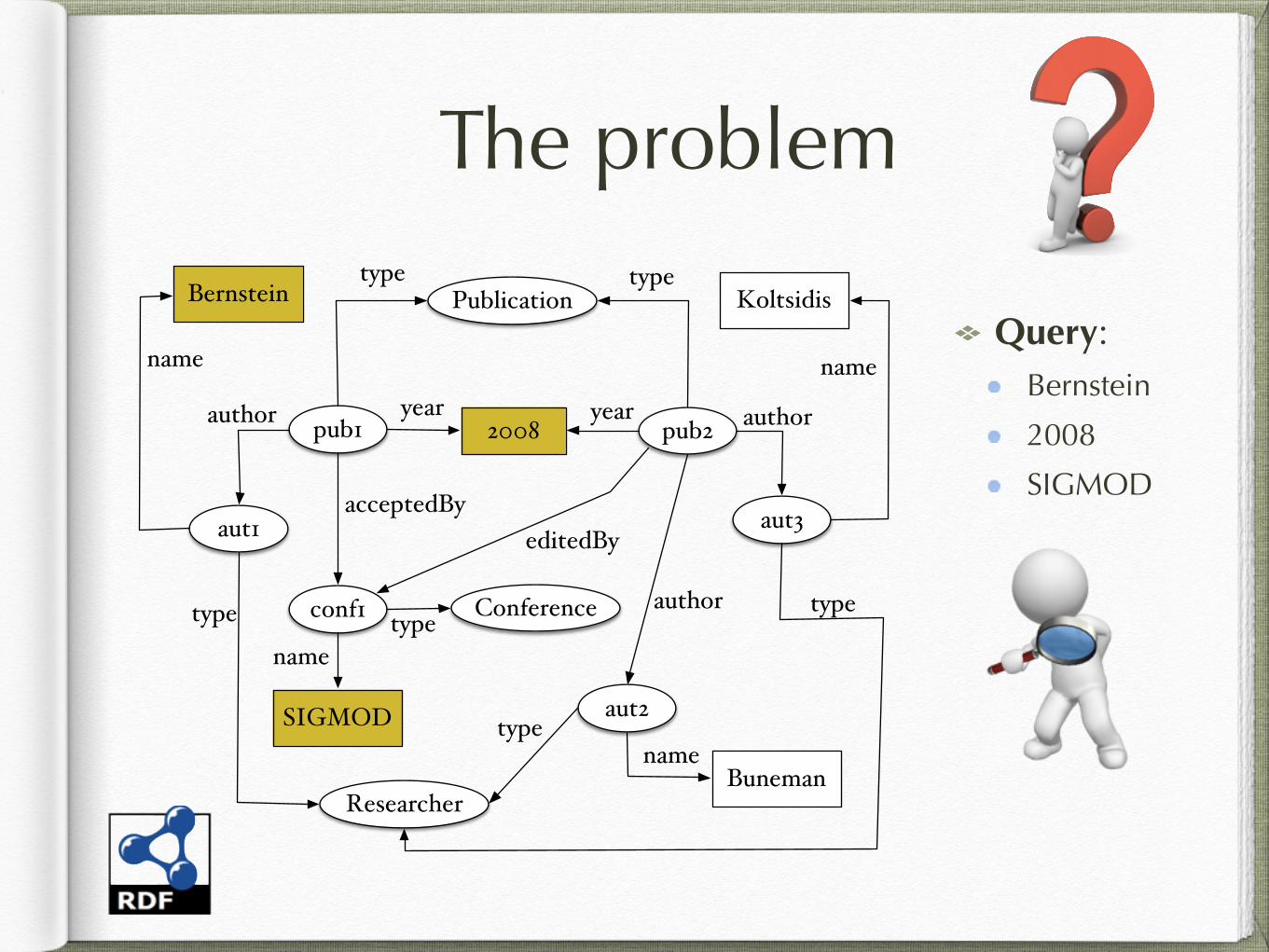
The problem
Query: Bernstein
2008
SIGMOD
Bernstein
SIGMOD
Koltsidis
Buneman
2008pub1 pub2
Publication
Conferenceconf1
aut1
aut2
aut3
Researcher
type type
name name
name
author authoryear year
name
editedBy
acceptedBy
type
type
typetypeauthor
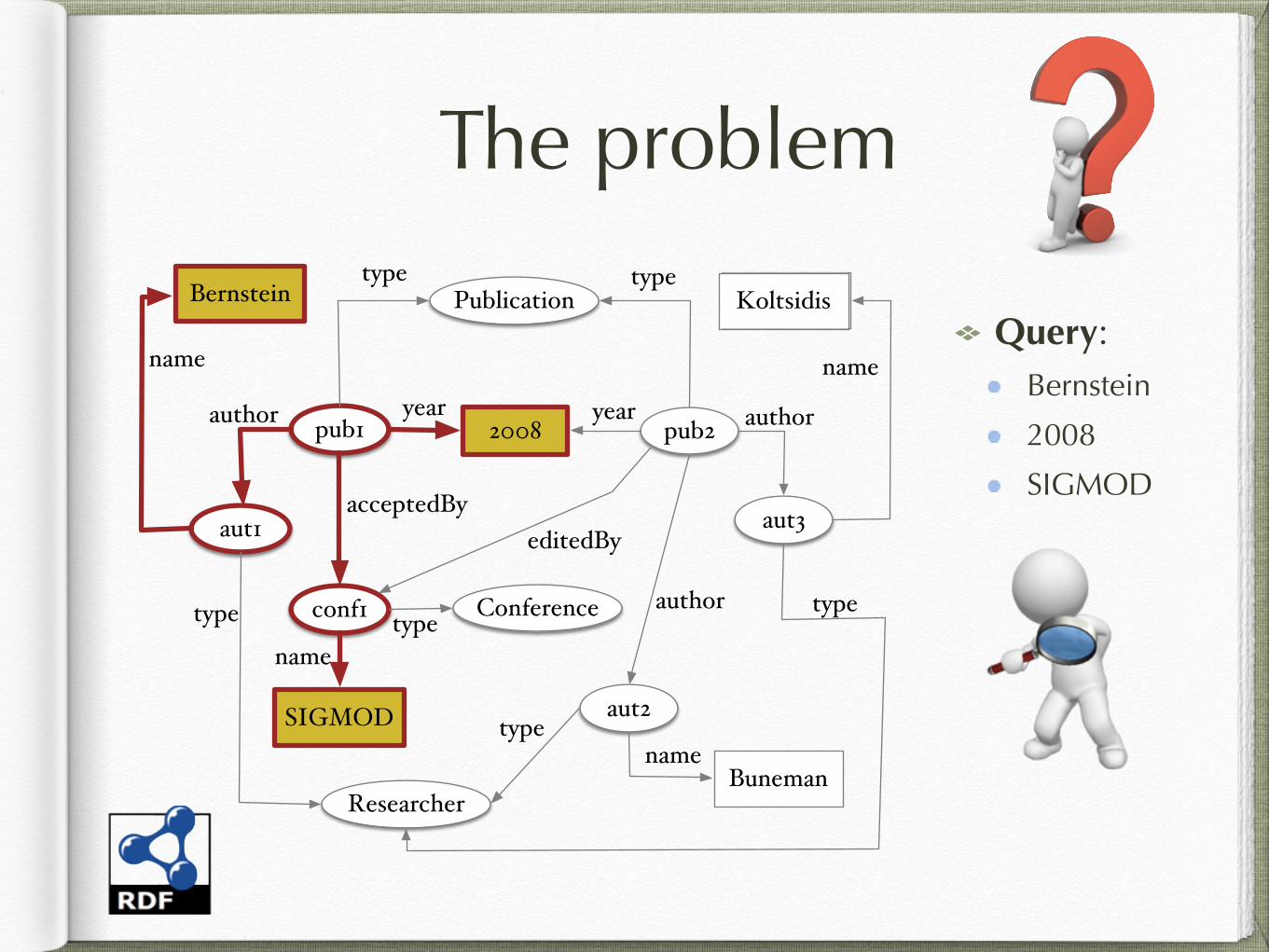
The problem
Bernstein
SIGMOD
Koltsides
Buneman
2008pub1 pub2
Publication
Conferenceconf1
aut1
aut2
aut3
Researcher
type type
name name
name
author authoryear year
name
editedBy
acceptedBy
type
type
typetypeauthor
Koltsidis
Query: Bernstein
2008
SIGMOD
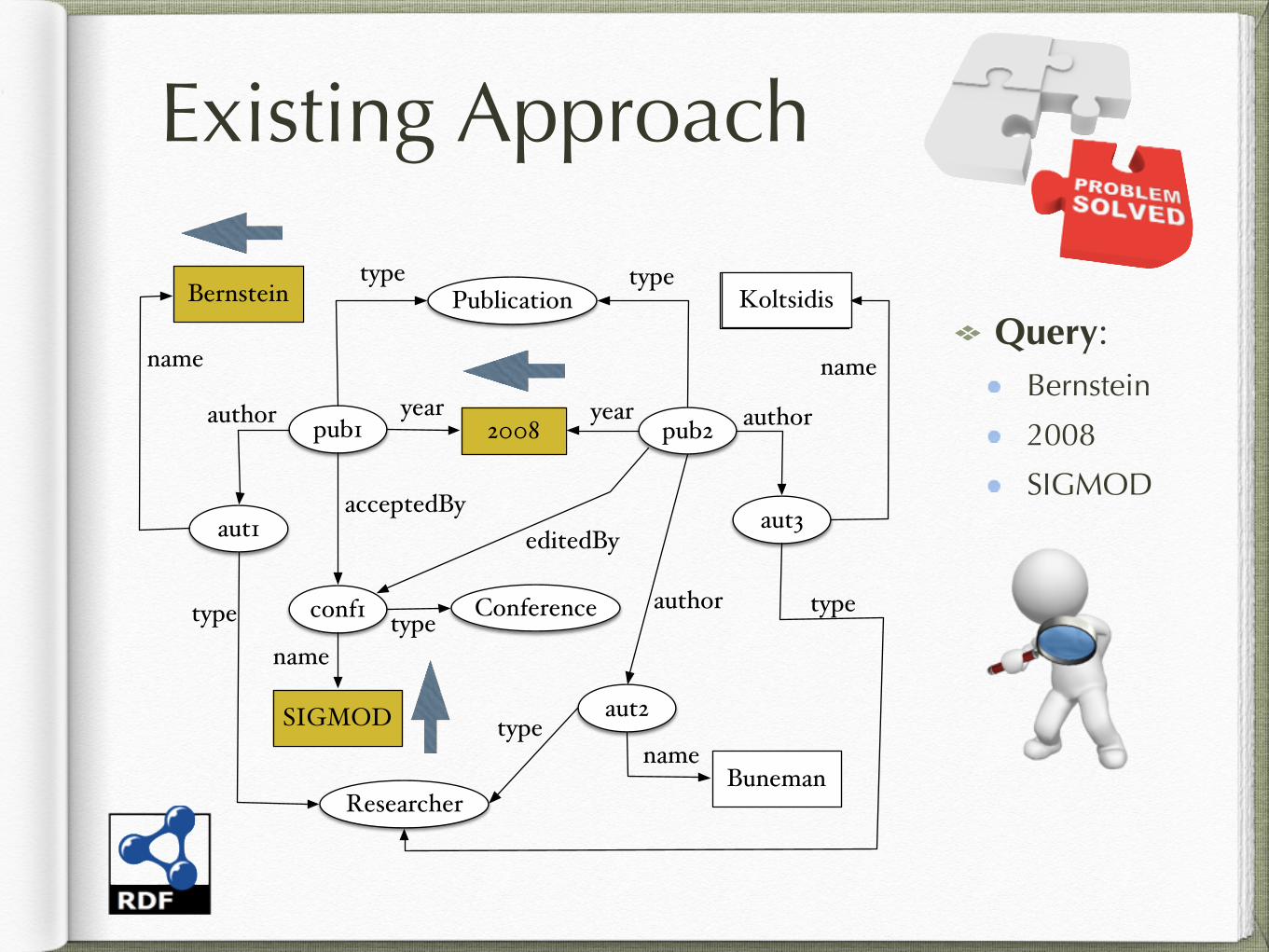
Existing Approach
Bernstein
SIGMOD
Koltsides
Buneman
2008pub1 pub2
Publication
Conferenceconf1
aut1
aut2
aut3
Researcher
type type
name name
name
author authoryear year
name
editedBy
acceptedBy
type
type
typetypeauthor
Koltsidis
Query: Bernstein
2008
SIGMOD

relevance
Existing Approach
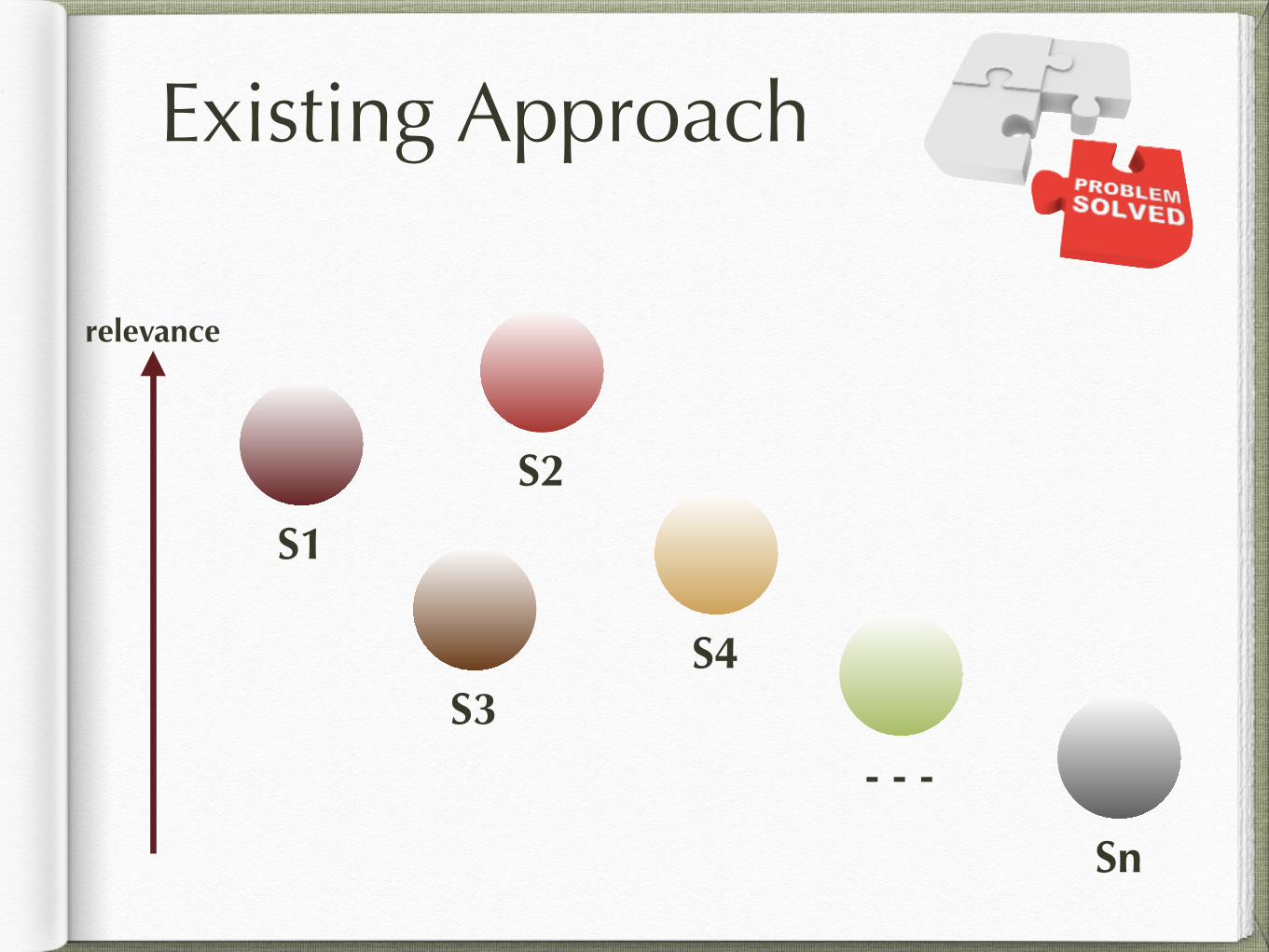
S1
S2
S3S4
- - -
Sn
relevance
Existing Approach
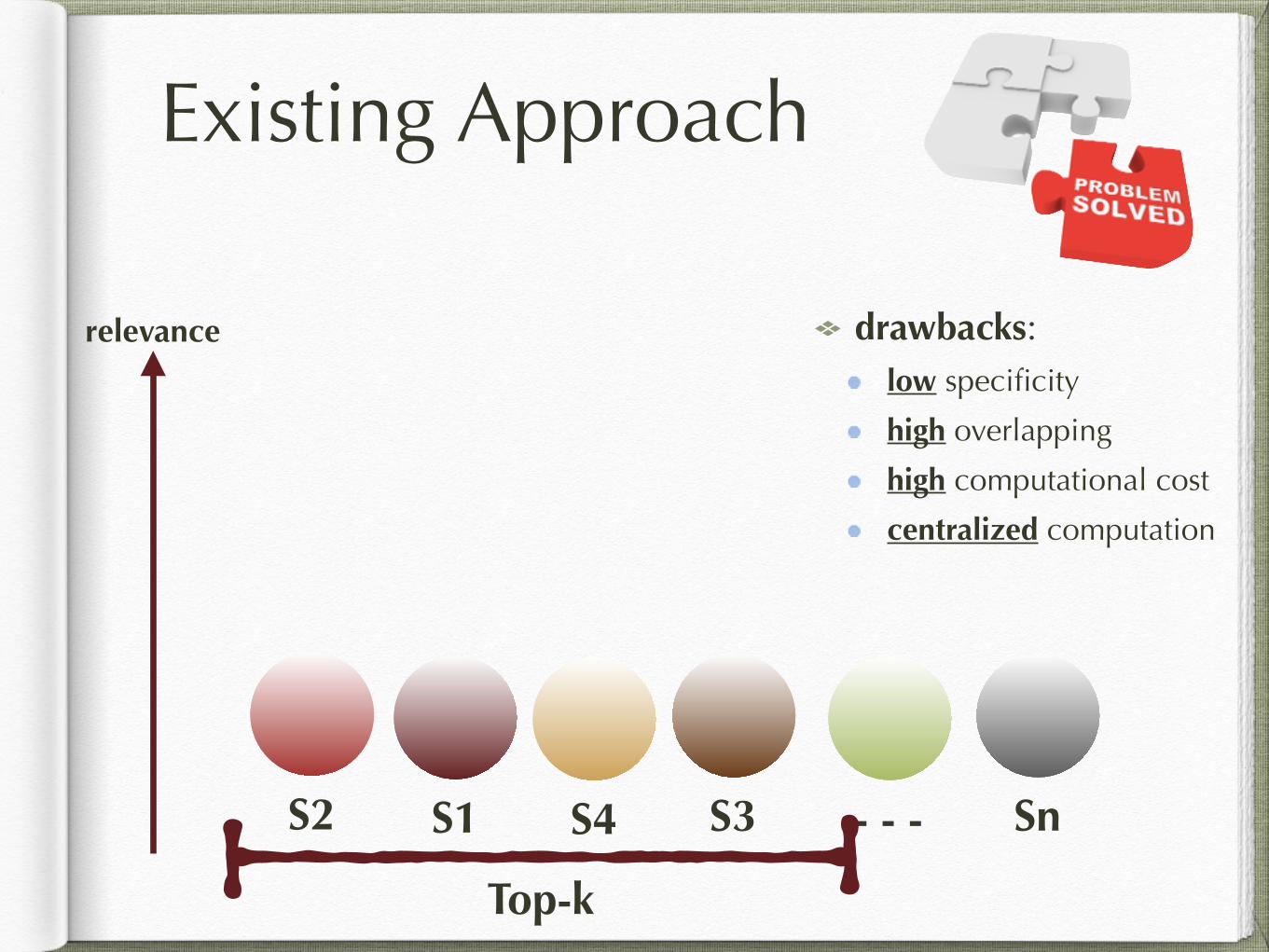
drawbacks: low specificity
high overlapping
high computational cost
centralized computation
S1S2 S3S4 - - - Sn
Top-k
relevance
Existing Approach

Desired direction
relevance

Desired direction
S1
S2
- - -Sk
relevance

strong points: linear computational cost
monotonic ranked result
low overlapping
distributed computation
Desired direction
S1 S2 - - - Sk
Top-k
relevance
From Graph parallel to Data parallel
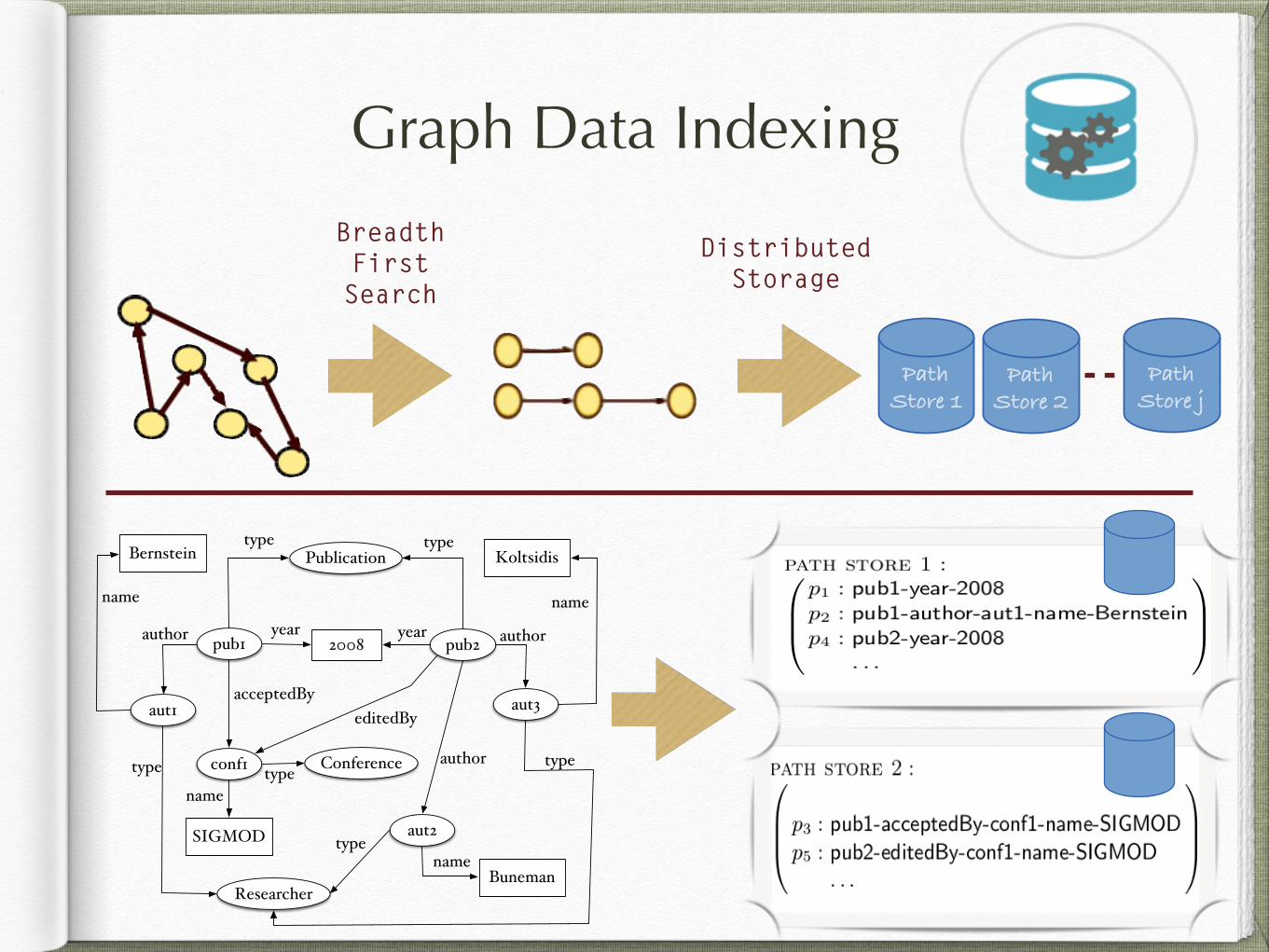
Graph Data Indexing
Breadth First Search
Distributed Storage
Path!Store 1!
Path!Store 2!
Path!Store j!
Bernstein
SIGMOD
Koltsidis
Buneman
2008pub1 pub2
Publication
Conferenceconf1
aut1
aut2
aut3
Researcher
type type
name name
name
author authoryear year
name
editedBy
acceptedBy
type
type
typetypeauthor
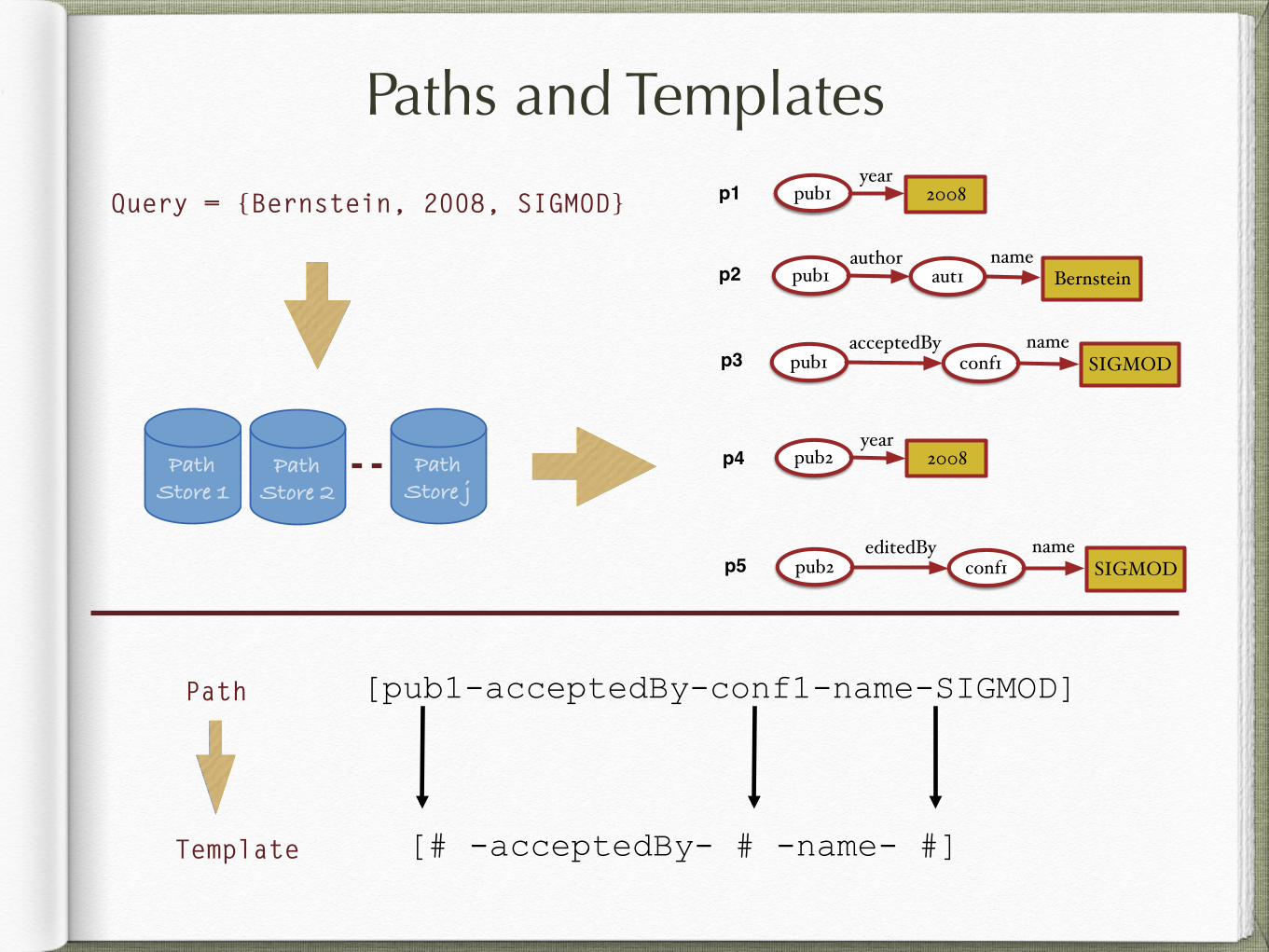
Paths and Templates
Path!Store 1 !
Path!Store 2!
Path!Store j!
[pub1-acceptedBy-conf1-name-SIGMOD]
[# -acceptedBy- # -name- #]
Query = {Bernstein, 2008, SIGMOD} 2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
Path
Template
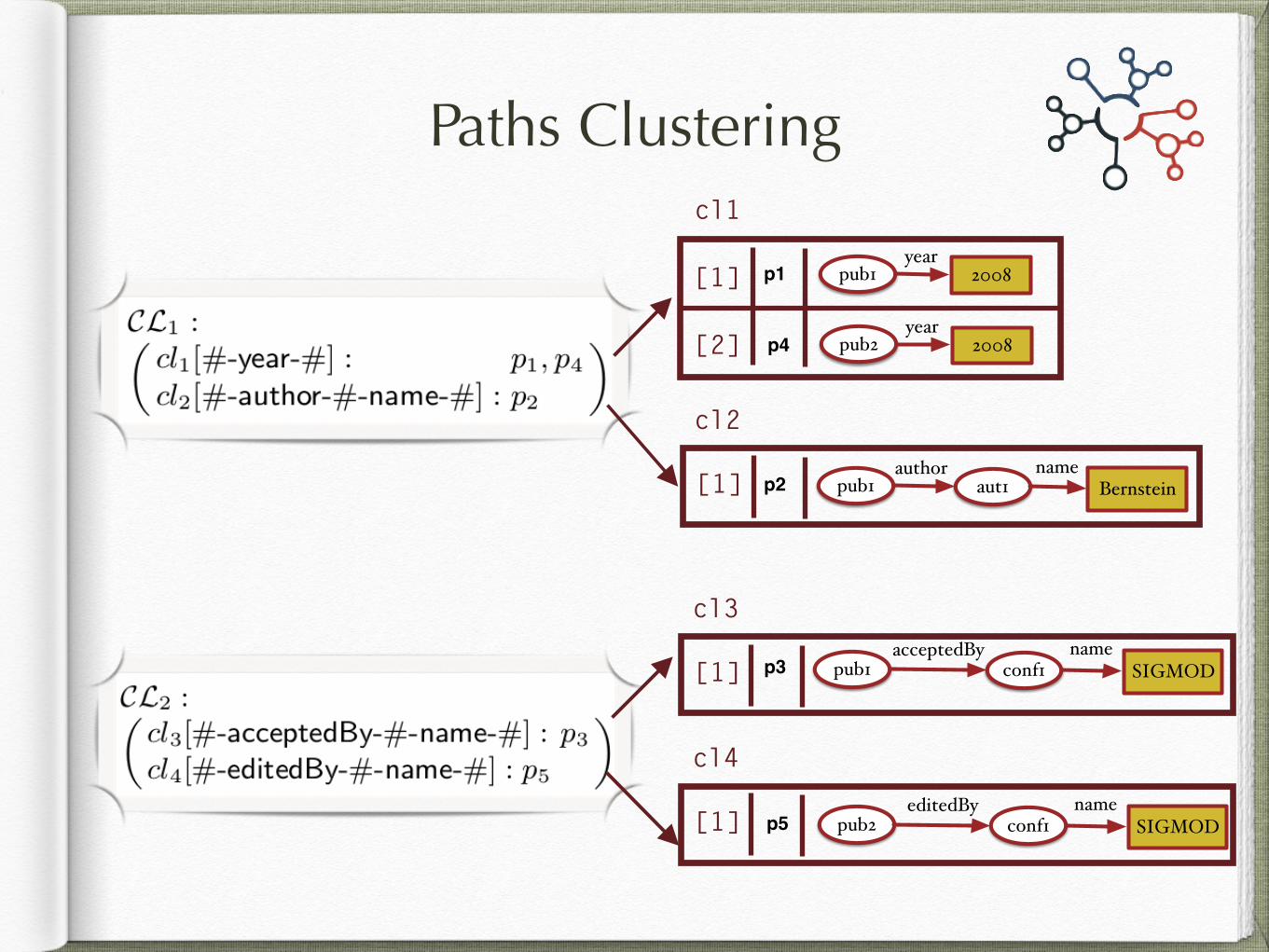
Paths Clustering
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
[1]
[2]
[1]
cl1
cl2
[1]
cl3
[1]
cl4

ScoringUnlike all current approaches, we are independent from the scoring function: we do not impose a monotonic, aggregative nor an “ad-hoc for the case” scoring function.
0
1
2
3
4
5
6
L M L M L M L M L M L M L M L M L M Mondial iMDb Wiki3 Mondial iMDb Wiki3 Mondial iMDb Wiki3
10-nodes 50-nodes 100-nodes
Job$Ru
n(me$(sec)$
ideal& overhead&
Figure 7: End-to-end job runtimes
[14] J. Huang, D. J. Abadi, and K. Ren. Scalable sparqlquerying of large rdf graphs. PVLDB,4(11):1123–1134, 2011.
[15] M. F. Husain, J. P. McGlothlin, M. M. Masud, L. R.Khan, and B. M. Thuraisingham. Heuristics-basedquery processing for large rdf graphs using cloudcomputing. IEEE Trans. Knowl. Data Eng.,23(9):1312–1327, 2011.
[16] V. Kacholia, S. Pandit, S. Chakrabarti, S. Sudarshan,R. Desai, and H. Karambelkar. Bidirectionalexpansion for keyword search on graph databases. InVLDB, 2005.
[17] Y. Luo, X. Lin, W. Wang, and X. Zhou. Spark: top-kkeyword query in relational databases. In SIGMOD,2007.
[18] N. Papailiou, I. Konstantinou, D. Tsoumakos, andN. Koziris. H2rdf: adaptive query processing on rdfdata in the cloud. In WWW (Companion Volume),pages 397–400, 2012.
[19] F. Prasser, A. Kemper, and K. A. Kuhn. E�cientdistributed query processing for autonomous rdfdatabases. In EDBT, pages 372–383, 2012.
[20] L. Qin, J. X. Yu, and L. Chang. Keyword search indatabases: the power of rdbms. In SIGMOD, 2009.
[21] P. Ravindra, S. Hong, H. Kim, and K. Anyanwu.E�cient processing of rdf graph pattern matching onmapreduce platforms. In DataCloud-SC ’11, pages13–20, 2011.
[22] A. Singhal, C. Buckley, and M. Mitra. Pivoteddocument length normalization. In SIGIR, pages21–29, 1996.
[23] T. Tran, H. Wang, S. Rudolph, and P. Cimiano. Top-kexploration of query candidates for e�cient keywordsearch on graph-shaped (rdf) data. In ICDE, pages405–416, 2009.
[24] G. Tsatsanifos, D. Sacharidis, and T. K. Sellis. Onenhancing scalability for distributed rdf/s stores. InEDBT, pages 141–152, 2011.
[25] K. Zeng, J. Yang, H. Wang, B. Shao, and Z. Wang. Adistributed graph engine for web scale rdf data.PVLDB, 6(4):265–276, 2013.
[26] G. Zenz, X. Zhou, E. Minack, W. Siberski, andW. Nejdl. From keywords to semantic queries -incremental query construction on the semantic web.Journal of Web Semantics, 7(3):166–176, 2009.
APPENDIXA. SCORING FUNCTION
Here we present the scoring function used to run our ex-periments. It has been inspired by the pivoted normalizationweighting method [22], one of the most used metric in IR.We assess a sub-graph (i.e. an answer or a path) with re-spect to a query Q on two key factors: its topology and therelevance of the information carried from its vertices andedges. The topology is evaluated in terms of the length ofits paths. The relevance of the information carried from itsvertices is evaluated through an implementation of TF/IDF.Given a query Q = {q1, . . . , qn
}, a graph G and a sub-graphsg in G, the score of sg with respect to Q is:
score(sg, Q) =↵(sg)
!str
(sg)·
X
q2Q
(⇢(q) · !ct
(sg, q))
where:
• ↵(sg) is the relative relevance of sg within G;
• ⇢(q) is the weight associated to each keyword q withrespect to the query Q;
• !ct
(sg, q) is the content weight of q considering sg;
• !str
(sg) is the structural weight of sg.
The relevance of sg is measured as follows:
↵(sg) = (Y
vi2sg
(deg�(v
i
) + 1deg+(v
i
) + 1))
1|V (sg)|
Inspired by the PageRank [3], we consider the relevance ofeach vertex v
i
2 V as the ratio between the in-degree (deg�)and the out-degree (deg+) of v
i
. The relevance of sg is thegeometric mean3 of the relevance of each vertex v
i
2 sg. In↵(sg) we indicate the number of vertices in sg as |V (sg)|.
3 The geometric mean of a data set {x1, x2, . . . , xn
} is givenby n
px1 · x2 · · ·x
n
Roberto De Virgilio, Antonio Maccioni, Paolo Cappellari: A Linear and Monotonic Strategy to Keyword Search over RDF Data. ICWE 2013:338-353

ScoringUnlike all current approaches, we are independent from the scoring function: we do not impose a monotonic, aggregative nor an “ad-hoc for the case” scoring function.
0
1
2
3
4
5
6
L M L M L M L M L M L M L M L M L M Mondial iMDb Wiki3 Mondial iMDb Wiki3 Mondial iMDb Wiki3
10-nodes 50-nodes 100-nodes
Job$Ru
n(me$(sec)$
ideal& overhead&
Figure 7: End-to-end job runtimes
[14] J. Huang, D. J. Abadi, and K. Ren. Scalable sparqlquerying of large rdf graphs. PVLDB,4(11):1123–1134, 2011.
[15] M. F. Husain, J. P. McGlothlin, M. M. Masud, L. R.Khan, and B. M. Thuraisingham. Heuristics-basedquery processing for large rdf graphs using cloudcomputing. IEEE Trans. Knowl. Data Eng.,23(9):1312–1327, 2011.
[16] V. Kacholia, S. Pandit, S. Chakrabarti, S. Sudarshan,R. Desai, and H. Karambelkar. Bidirectionalexpansion for keyword search on graph databases. InVLDB, 2005.
[17] Y. Luo, X. Lin, W. Wang, and X. Zhou. Spark: top-kkeyword query in relational databases. In SIGMOD,2007.
[18] N. Papailiou, I. Konstantinou, D. Tsoumakos, andN. Koziris. H2rdf: adaptive query processing on rdfdata in the cloud. In WWW (Companion Volume),pages 397–400, 2012.
[19] F. Prasser, A. Kemper, and K. A. Kuhn. E�cientdistributed query processing for autonomous rdfdatabases. In EDBT, pages 372–383, 2012.
[20] L. Qin, J. X. Yu, and L. Chang. Keyword search indatabases: the power of rdbms. In SIGMOD, 2009.
[21] P. Ravindra, S. Hong, H. Kim, and K. Anyanwu.E�cient processing of rdf graph pattern matching onmapreduce platforms. In DataCloud-SC ’11, pages13–20, 2011.
[22] A. Singhal, C. Buckley, and M. Mitra. Pivoteddocument length normalization. In SIGIR, pages21–29, 1996.
[23] T. Tran, H. Wang, S. Rudolph, and P. Cimiano. Top-kexploration of query candidates for e�cient keywordsearch on graph-shaped (rdf) data. In ICDE, pages405–416, 2009.
[24] G. Tsatsanifos, D. Sacharidis, and T. K. Sellis. Onenhancing scalability for distributed rdf/s stores. InEDBT, pages 141–152, 2011.
[25] K. Zeng, J. Yang, H. Wang, B. Shao, and Z. Wang. Adistributed graph engine for web scale rdf data.PVLDB, 6(4):265–276, 2013.
[26] G. Zenz, X. Zhou, E. Minack, W. Siberski, andW. Nejdl. From keywords to semantic queries -incremental query construction on the semantic web.Journal of Web Semantics, 7(3):166–176, 2009.
APPENDIXA. SCORING FUNCTION
Here we present the scoring function used to run our ex-periments. It has been inspired by the pivoted normalizationweighting method [22], one of the most used metric in IR.We assess a sub-graph (i.e. an answer or a path) with re-spect to a query Q on two key factors: its topology and therelevance of the information carried from its vertices andedges. The topology is evaluated in terms of the length ofits paths. The relevance of the information carried from itsvertices is evaluated through an implementation of TF/IDF.Given a query Q = {q1, . . . , qn
}, a graph G and a sub-graphsg in G, the score of sg with respect to Q is:
score(sg, Q) =↵(sg)
!str
(sg)·
X
q2Q
(⇢(q) · !ct
(sg, q))
where:
• ↵(sg) is the relative relevance of sg within G;
• ⇢(q) is the weight associated to each keyword q withrespect to the query Q;
• !ct
(sg, q) is the content weight of q considering sg;
• !str
(sg) is the structural weight of sg.
The relevance of sg is measured as follows:
↵(sg) = (Y
vi2sg
(deg�(v
i
) + 1deg+(v
i
) + 1))
1|V (sg)|
Inspired by the PageRank [3], we consider the relevance ofeach vertex v
i
2 V as the ratio between the in-degree (deg�)and the out-degree (deg+) of v
i
. The relevance of sg is thegeometric mean3 of the relevance of each vertex v
i
2 sg. In↵(sg) we indicate the number of vertices in sg as |V (sg)|.
3 The geometric mean of a data set {x1, x2, . . . , xn
} is givenby n
px1 · x2 · · ·x
n
topology: how keywords are strictly connected
length of the paths
Roberto De Virgilio, Antonio Maccioni, Paolo Cappellari: A Linear and Monotonic Strategy to Keyword Search over RDF Data. ICWE 2013:338-353

ScoringUnlike all current approaches, we are independent from the scoring function: we do not impose a monotonic, aggregative nor an “ad-hoc for the case” scoring function.
0
1
2
3
4
5
6
L M L M L M L M L M L M L M L M L M Mondial iMDb Wiki3 Mondial iMDb Wiki3 Mondial iMDb Wiki3
10-nodes 50-nodes 100-nodes
Job$Ru
n(me$(sec)$
ideal& overhead&
Figure 7: End-to-end job runtimes
[14] J. Huang, D. J. Abadi, and K. Ren. Scalable sparqlquerying of large rdf graphs. PVLDB,4(11):1123–1134, 2011.
[15] M. F. Husain, J. P. McGlothlin, M. M. Masud, L. R.Khan, and B. M. Thuraisingham. Heuristics-basedquery processing for large rdf graphs using cloudcomputing. IEEE Trans. Knowl. Data Eng.,23(9):1312–1327, 2011.
[16] V. Kacholia, S. Pandit, S. Chakrabarti, S. Sudarshan,R. Desai, and H. Karambelkar. Bidirectionalexpansion for keyword search on graph databases. InVLDB, 2005.
[17] Y. Luo, X. Lin, W. Wang, and X. Zhou. Spark: top-kkeyword query in relational databases. In SIGMOD,2007.
[18] N. Papailiou, I. Konstantinou, D. Tsoumakos, andN. Koziris. H2rdf: adaptive query processing on rdfdata in the cloud. In WWW (Companion Volume),pages 397–400, 2012.
[19] F. Prasser, A. Kemper, and K. A. Kuhn. E�cientdistributed query processing for autonomous rdfdatabases. In EDBT, pages 372–383, 2012.
[20] L. Qin, J. X. Yu, and L. Chang. Keyword search indatabases: the power of rdbms. In SIGMOD, 2009.
[21] P. Ravindra, S. Hong, H. Kim, and K. Anyanwu.E�cient processing of rdf graph pattern matching onmapreduce platforms. In DataCloud-SC ’11, pages13–20, 2011.
[22] A. Singhal, C. Buckley, and M. Mitra. Pivoteddocument length normalization. In SIGIR, pages21–29, 1996.
[23] T. Tran, H. Wang, S. Rudolph, and P. Cimiano. Top-kexploration of query candidates for e�cient keywordsearch on graph-shaped (rdf) data. In ICDE, pages405–416, 2009.
[24] G. Tsatsanifos, D. Sacharidis, and T. K. Sellis. Onenhancing scalability for distributed rdf/s stores. InEDBT, pages 141–152, 2011.
[25] K. Zeng, J. Yang, H. Wang, B. Shao, and Z. Wang. Adistributed graph engine for web scale rdf data.PVLDB, 6(4):265–276, 2013.
[26] G. Zenz, X. Zhou, E. Minack, W. Siberski, andW. Nejdl. From keywords to semantic queries -incremental query construction on the semantic web.Journal of Web Semantics, 7(3):166–176, 2009.
APPENDIXA. SCORING FUNCTION
Here we present the scoring function used to run our ex-periments. It has been inspired by the pivoted normalizationweighting method [22], one of the most used metric in IR.We assess a sub-graph (i.e. an answer or a path) with re-spect to a query Q on two key factors: its topology and therelevance of the information carried from its vertices andedges. The topology is evaluated in terms of the length ofits paths. The relevance of the information carried from itsvertices is evaluated through an implementation of TF/IDF.Given a query Q = {q1, . . . , qn
}, a graph G and a sub-graphsg in G, the score of sg with respect to Q is:
score(sg, Q) =↵(sg)
!str
(sg)·
X
q2Q
(⇢(q) · !ct
(sg, q))
where:
• ↵(sg) is the relative relevance of sg within G;
• ⇢(q) is the weight associated to each keyword q withrespect to the query Q;
• !ct
(sg, q) is the content weight of q considering sg;
• !str
(sg) is the structural weight of sg.
The relevance of sg is measured as follows:
↵(sg) = (Y
vi2sg
(deg�(v
i
) + 1deg+(v
i
) + 1))
1|V (sg)|
Inspired by the PageRank [3], we consider the relevance ofeach vertex v
i
2 V as the ratio between the in-degree (deg�)and the out-degree (deg+) of v
i
. The relevance of sg is thegeometric mean3 of the relevance of each vertex v
i
2 sg. In↵(sg) we indicate the number of vertices in sg as |V (sg)|.
3 The geometric mean of a data set {x1, x2, . . . , xn
} is givenby n
px1 · x2 · · ·x
n
topology: how keywords are strictly connected
length of the paths
relevance: information carried from nodes
implementation of TF/IDF
Roberto De Virgilio, Antonio Maccioni, Paolo Cappellari: A Linear and Monotonic Strategy to Keyword Search over RDF Data. ICWE 2013:338-353
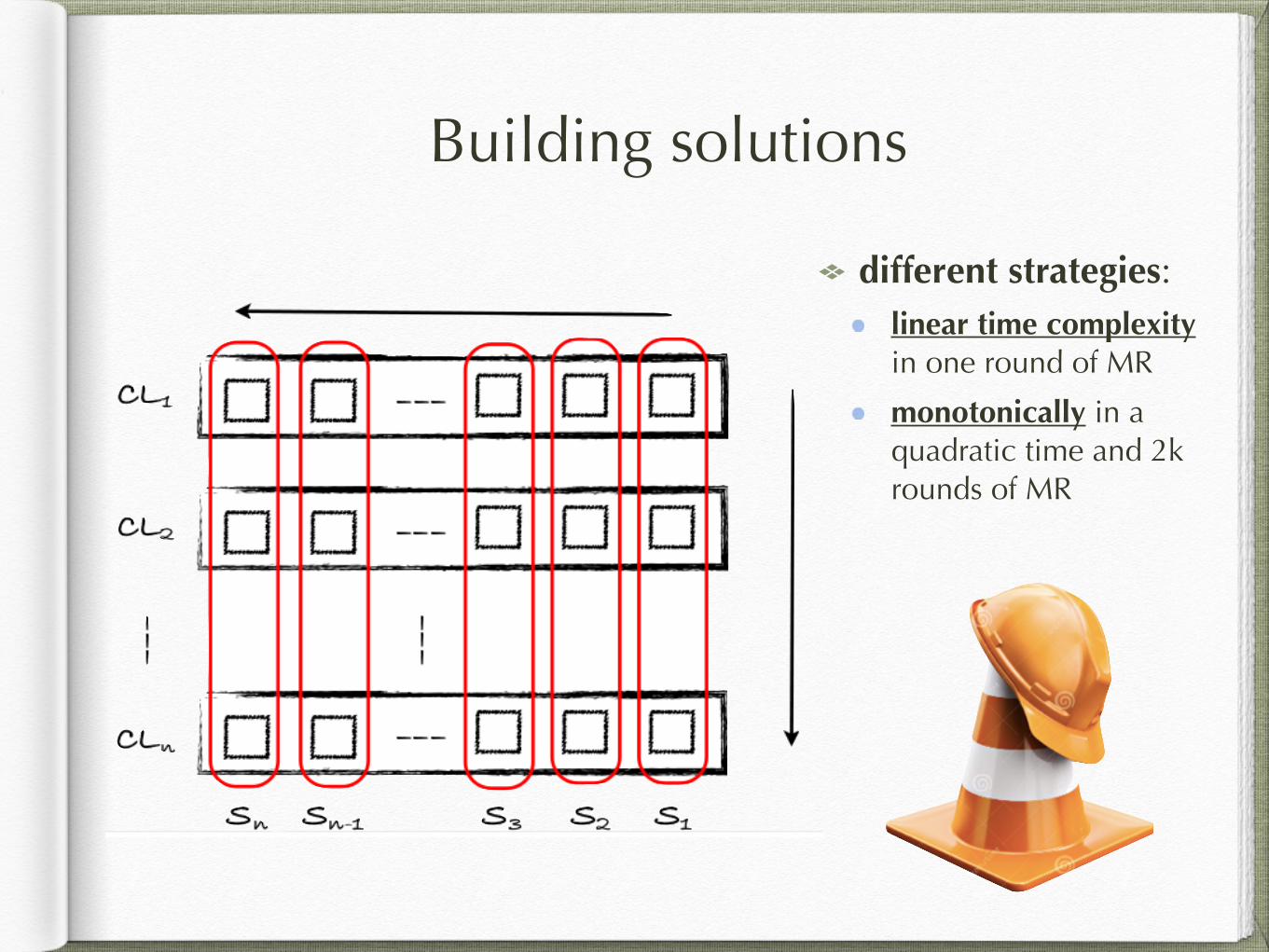
Building solutions
different strategies: linear time complexity in one round of MR
monotonically in a quadratic time and 2k rounds of MR
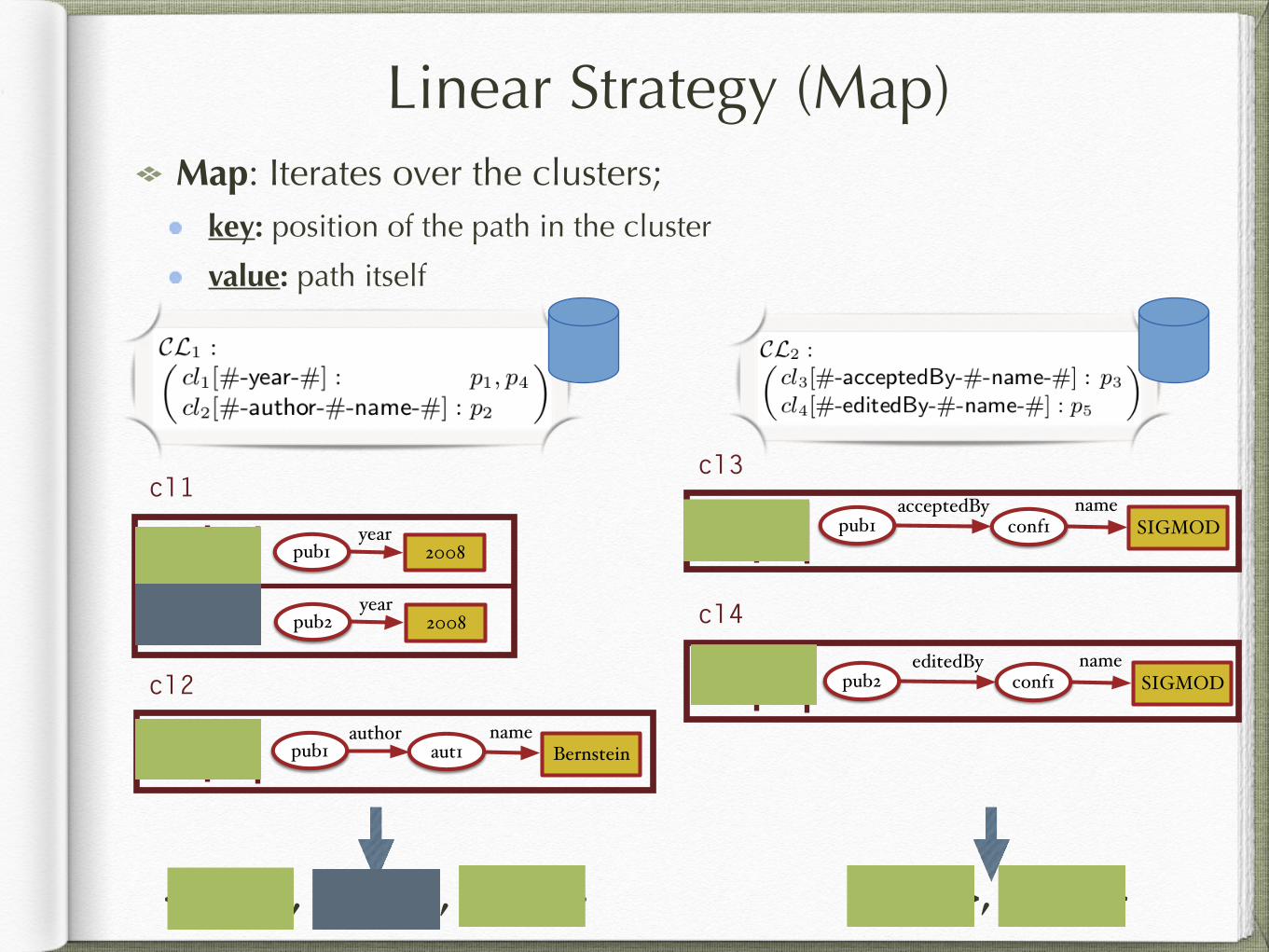
Linear Strategy (Map)Map: Iterates over the clusters;
key: position of the path in the cluster
value: path itself
<1, p1>, <2, p4>, <1, p2> <1, p3>, <1, p5>
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
[1]
[2]
[1]
cl1
cl2
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
[1]
cl3
[1]
cl4

Linear Strategy (Reduce)Reduce: Each machine receives a list of paths out of which it computes connected components;
key: position of the path in the cluster
value: path itself
<1, p1>, <2, p4>, <1, p2>
<1, p3>, <1, p5>
<1, {p1, p2, p3, p5}>
<2, {p4}>
Each connected component is a final solution to output S1: {p1, p2, p3, p5}
S2: {p4}
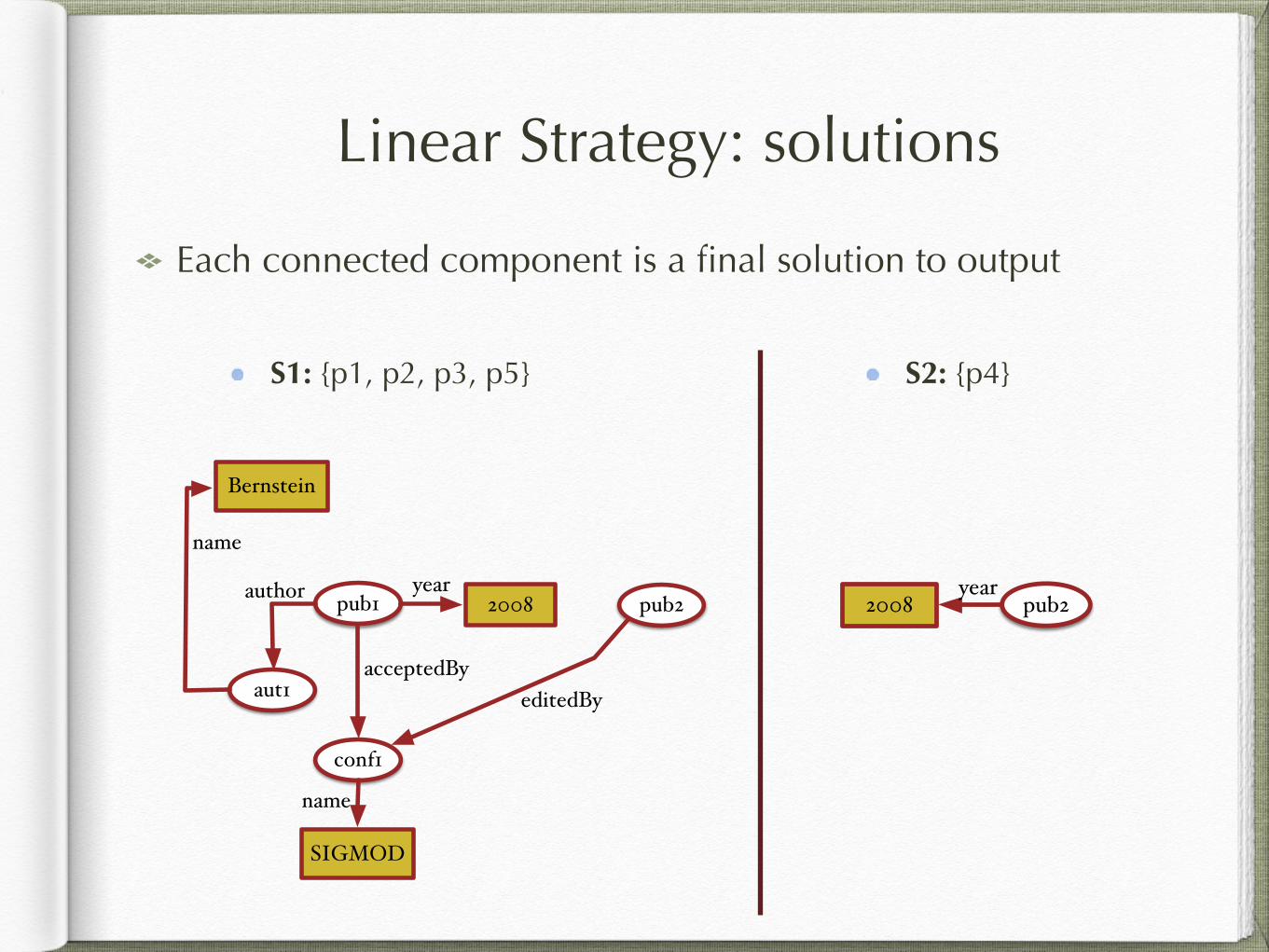
Linear Strategy: solutions
Each connected component is a final solution to output
Bernstein
SIGMOD
2008pub1 pub2
conf1
aut1
name
author year
name
editedBy
acceptedBy
2008 pub2year
S2: {p4}S1: {p1, p2, p3, p5}
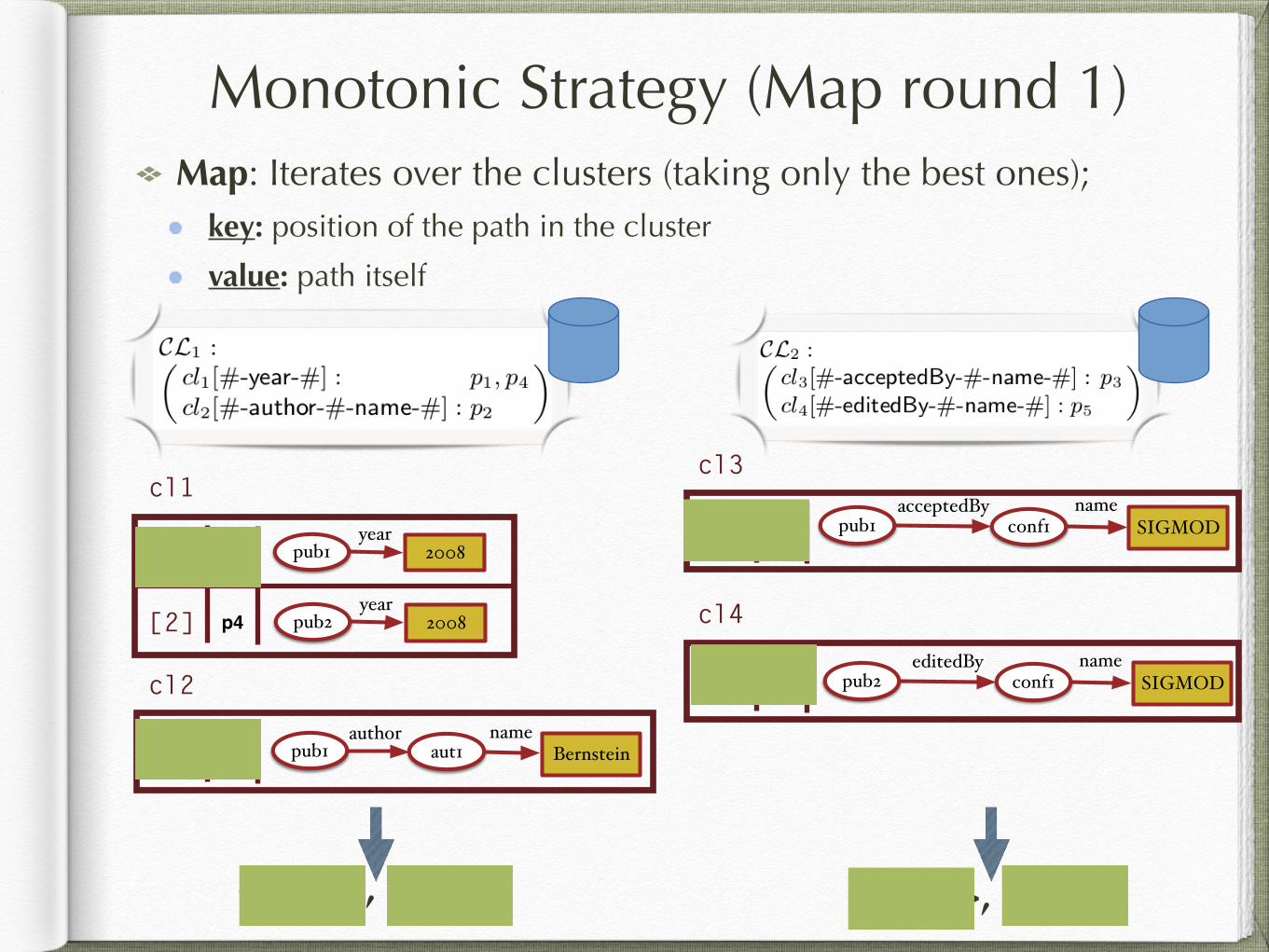
Monotonic Strategy (Map round 1)Map: Iterates over the clusters (taking only the best ones);
key: position of the path in the cluster
value: path itself
<1, p1>, <1, p2> <1, p3>, <1, p5>
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
[1]
[2]
[1]
cl1
cl2
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
[1]
cl3
[1]
cl4

Monotonic Strategy (Reduce round 1)
Reduce: Each machine receives a list of paths out of which it computes global connected components;
key: position of the path in the cluster
value: path itself
<1, p1>, <1, p2>
<1, p3>, <1, p5><1, {p1, p2, p3, p5}>
Then it invokes a new round of MapReduce
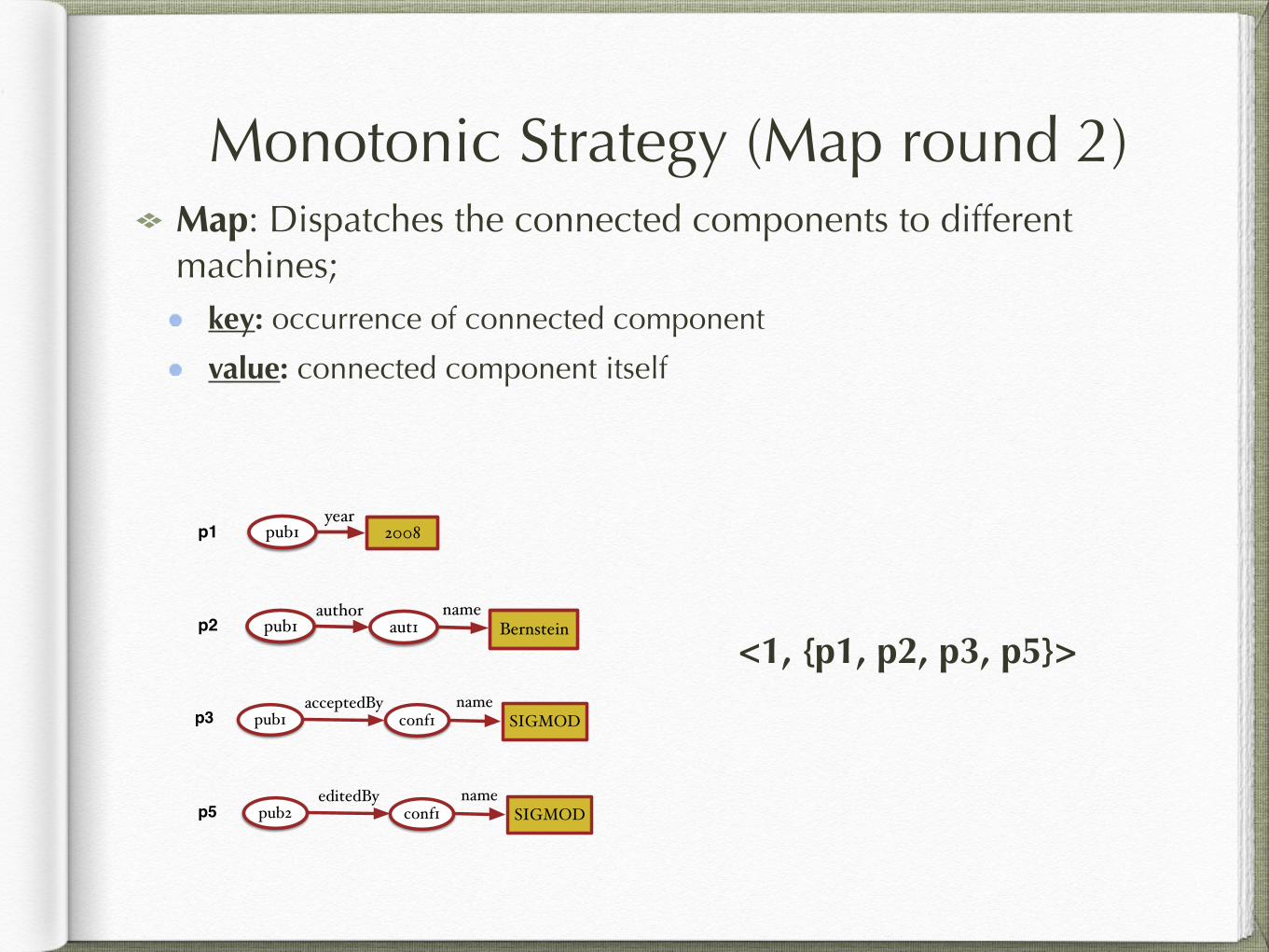
Monotonic Strategy (Map round 2)Map: Dispatches the connected components to different machines;
key: occurrence of connected component
value: connected component itself
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
2008pub1year
Bernsteinpub1 aut1author name
SIGMODpub1 conf1acceptedBy name
2008pub2year
SIGMODpub2 conf1editedBy name
p1
p2
p3
p4
p5
<1, {p1, p2, p3, p5}>

Monotonic Strategy (Reduce round 2)
Reduce: Each machine receives a connected component and iterates on the paths;
tau-test: a variant of the TA algorithm
it determines if some path is exceeding in the connected component
<1, {p1, p2, p3, p5}>
Discarded paths and discarded connected components are reinserted in the clusters
S = {p1, p2, p3}
{p5}

Tau-test
by the most common IR based functions. It is possible to prove that the pivotednormalization weighting method (SIM) [11], which inspired most of the IR scoringfunctions, satisfy Properties 1 and 2. For the sake of simplicity, we discuss theproperties by referring to the data structures used in this paper.
Property 1 Given a query Q and a path p, score(p, Q) = score({p}, Q).
This property states that the score of a path p is equal to the score of thesolution S containing only that same path (i.e. {p}). It means that every pathmust be evaluated as the solution containing exactly that path. Consequently wehave that, if score(p
1
, Q) > score(p2
, Q) then score({p1
}, Q) > score({p2
}, Q).Analogously, extending Property 1 we provide the following.
Property 2 Given a query Q, a set of paths P in which p�
is the more relevantpath (i.e. 8p
j
2 P we have that score(p�
, Q) > score(pj
, Q)) and P ⇤ is its powerset, we have score(S = P
i
, Q) score(S = {p�
}, Q) 8Pi
✓ P ⇤.
In other words, given the set P containing the candidate paths to be includedin the solution, the scores of all possible solutions generated from P (i.e. P ⇤) arebounded by the score of the most relevant path p
�
of P . This property is coherentand generalizes the Threshold Algorithm (TA) [6]. Contrarily to TA, we do notuse an aggregative function, nor we assume the aggregation to be monotone. TAintroduces a mechanism to optimize the number of steps n to compute the bestk objects (where it could be n > k), while our framework produces k optimasolutions in k steps. To verify the monotonicity we apply a so-called ⌧ -test todetermine which paths of a connected component cc should be inserted into anoptimum solution optS ⇢ cc. The ⌧ -test is supported by Theorem 1. Firstly,we have to take into consideration the paths that can be used to form moresolutions in the next iterations of the process. In our framework they are stillwithin the set of clusters CL. Then, let us consider the path p
s
with the highestscore in CL and the path p
y
with the highest score in cc r optS. Then we definethe threshold ⌧ as ⌧ = max{score(p
s
, Q), score(py
, Q)}. The threshold ⌧ can beconsidered as the upper bound score for the potential solutions to generate inthe next iterations of the algorithm. Now, we provide the following:
Theorem 1. Given a query Q, a scoring function satisfying Property 1 andProperty 2, a connected component cc, a subset optS ⇢ cc representing anoptimum solution and a candidate path p
x
2 cc r optS, S = optS [ {px
} is stilloptimum i↵ score(S, Q) � ⌧.
Necessary condition. Let us assume that S = optS [ {px
} is an optimumsolution. We must verify if the score of this solution is still greater than ⌧ .Reminding to the definition of ⌧ , we can have two cases:– ⌧ = score(p
s
, Q) > score(py
, Q).In this case score(p
s
, Q) represents the upper bound for the scoringof the possible solutions to generate in the next steps. Recalling theProperty 1, we have score(p
s
, Q) = score(S0 = {ps
}, Q). Referring to
by the most common IR based functions. It is possible to prove that the pivotednormalization weighting method (SIM) [11], which inspired most of the IR scoringfunctions, satisfy Properties 1 and 2. For the sake of simplicity, we discuss theproperties by referring to the data structures used in this paper.
Property 1 Given a query Q and a path p, score(p, Q) = score({p}, Q).
This property states that the score of a path p is equal to the score of thesolution S containing only that same path (i.e. {p}). It means that every pathmust be evaluated as the solution containing exactly that path. Consequently wehave that, if score(p
1
, Q) > score(p2
, Q) then score({p1
}, Q) > score({p2
}, Q).Analogously, extending Property 1 we provide the following.
Property 2 Given a query Q, a set of paths P in which p�
is the more relevantpath (i.e. 8p
j
2 P we have that score(p�
, Q) > score(pj
, Q)) and P ⇤ is its powerset, we have score(S = P
i
, Q) score(S = {p�
}, Q) 8Pi
✓ P ⇤.
In other words, given the set P containing the candidate paths to be includedin the solution, the scores of all possible solutions generated from P (i.e. P ⇤) arebounded by the score of the most relevant path p
�
of P . This property is coherentand generalizes the Threshold Algorithm (TA) [6]. Contrarily to TA, we do notuse an aggregative function, nor we assume the aggregation to be monotone. TAintroduces a mechanism to optimize the number of steps n to compute the bestk objects (where it could be n > k), while our framework produces k optimasolutions in k steps. To verify the monotonicity we apply a so-called ⌧ -test todetermine which paths of a connected component cc should be inserted into anoptimum solution optS ⇢ cc. The ⌧ -test is supported by Theorem 1. Firstly,we have to take into consideration the paths that can be used to form moresolutions in the next iterations of the process. In our framework they are stillwithin the set of clusters CL. Then, let us consider the path p
s
with the highestscore in CL and the path p
y
with the highest score in cc r optS. Then we definethe threshold ⌧ as ⌧ = max{score(p
s
, Q), score(py
, Q)}. The threshold ⌧ can beconsidered as the upper bound score for the potential solutions to generate inthe next iterations of the algorithm. Now, we provide the following:
Theorem 1. Given a query Q, a scoring function satisfying Property 1 andProperty 2, a connected component cc, a subset optS ⇢ cc representing anoptimum solution and a candidate path p
x
2 cc r optS, S = optS [ {px
} is stilloptimum i↵ score(S, Q) � ⌧.
Necessary condition. Let us assume that S = optS [ {px
} is an optimumsolution. We must verify if the score of this solution is still greater than ⌧ .Reminding to the definition of ⌧ , we can have two cases:– ⌧ = score(p
s
, Q) > score(py
, Q).In this case score(p
s
, Q) represents the upper bound for the scoringof the possible solutions to generate in the next steps. Recalling theProperty 1, we have score(p
s
, Q) = score(S0 = {ps
}, Q). Referring to
by the most common IR based functions. It is possible to prove that the pivotednormalization weighting method (SIM) [11], which inspired most of the IR scoringfunctions, satisfy Properties 1 and 2. For the sake of simplicity, we discuss theproperties by referring to the data structures used in this paper.
Property 1 Given a query Q and a path p, score(p, Q) = score({p}, Q).
This property states that the score of a path p is equal to the score of thesolution S containing only that same path (i.e. {p}). It means that every pathmust be evaluated as the solution containing exactly that path. Consequently wehave that, if score(p
1
, Q) > score(p2
, Q) then score({p1
}, Q) > score({p2
}, Q).Analogously, extending Property 1 we provide the following.
Property 2 Given a query Q, a set of paths P in which p�
is the more relevantpath (i.e. 8p
j
2 P we have that score(p�
, Q) > score(pj
, Q)) and P ⇤ is its powerset, we have score(S = P
i
, Q) score(S = {p�
}, Q) 8Pi
✓ P ⇤.
In other words, given the set P containing the candidate paths to be includedin the solution, the scores of all possible solutions generated from P (i.e. P ⇤) arebounded by the score of the most relevant path p
�
of P . This property is coherentand generalizes the Threshold Algorithm (TA) [6]. Contrarily to TA, we do notuse an aggregative function, nor we assume the aggregation to be monotone. TAintroduces a mechanism to optimize the number of steps n to compute the bestk objects (where it could be n > k), while our framework produces k optimasolutions in k steps. To verify the monotonicity we apply a so-called ⌧ -test todetermine which paths of a connected component cc should be inserted into anoptimum solution optS ⇢ cc. The ⌧ -test is supported by Theorem 1. Firstly,we have to take into consideration the paths that can be used to form moresolutions in the next iterations of the process. In our framework they are stillwithin the set of clusters CL. Then, let us consider the path p
s
with the highestscore in CL and the path p
y
with the highest score in cc r optS. Then we definethe threshold ⌧ as ⌧ = max{score(p
s
, Q), score(py
, Q)}. The threshold ⌧ can beconsidered as the upper bound score for the potential solutions to generate inthe next iterations of the algorithm. Now, we provide the following:
Theorem 1. Given a query Q, a scoring function satisfying Property 1 andProperty 2, a connected component cc, a subset optS ⇢ cc representing anoptimum solution and a candidate path p
x
2 cc r optS, S = optS [ {px
} is stilloptimum i↵ score(S, Q) � ⌧.
Necessary condition. Let us assume that S = optS [ {px
} is an optimumsolution. We must verify if the score of this solution is still greater than ⌧ .Reminding to the definition of ⌧ , we can have two cases:– ⌧ = score(p
s
, Q) > score(py
, Q).In this case score(p
s
, Q) represents the upper bound for the scoringof the possible solutions to generate in the next steps. Recalling theProperty 1, we have score(p
s
, Q) = score(S0 = {ps
}, Q). Referring to
Roberto De Virgilio, Antonio Maccioni, Paolo Cappellari: A Linear and Monotonic Strategy to Keyword Search over RDF Data. ICWE 2013:338-353
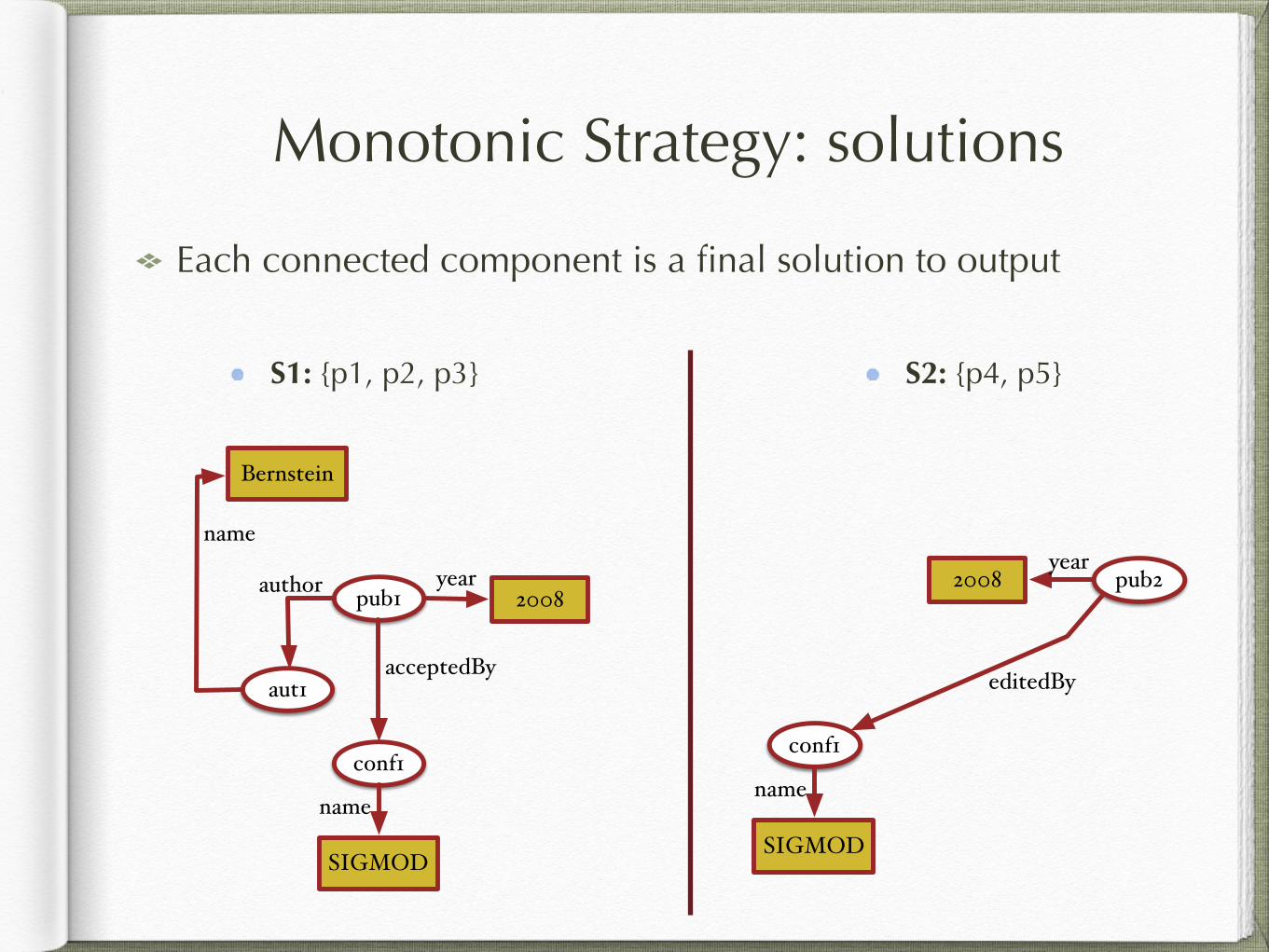
Monotonic Strategy: solutions
Each connected component is a final solution to output
S2: {p4, p5}S1: {p1, p2, p3}
Bernstein
SIGMOD
2008pub1
conf1
aut1
name
author year
name
acceptedBy
SIGMOD
2008 pub2
conf1
year
name
editedBy

Experiments
We deployed YaaniiMR on EC2 clusters.
cc1.4xlarge: 10, 50 and 100 nodes.
YaaniiMR is provided with the Hadoop file system (HDFS) version 1.1.1 and the HBase data store version 0.94.3
The performance of our systems has been mea-sured with respect to data loading, memory footprint, and query execution.

Data Loading
0"
100"
200"
300"
400"
10 nodes 50 nodes
100 nodes
45,49% 50,49% 56,43%
314,26% 348,84%389,88%
Uploa
d"Time"(sec)"DBPedia" Billion"
300M triples
2008 edition: 1200M triples
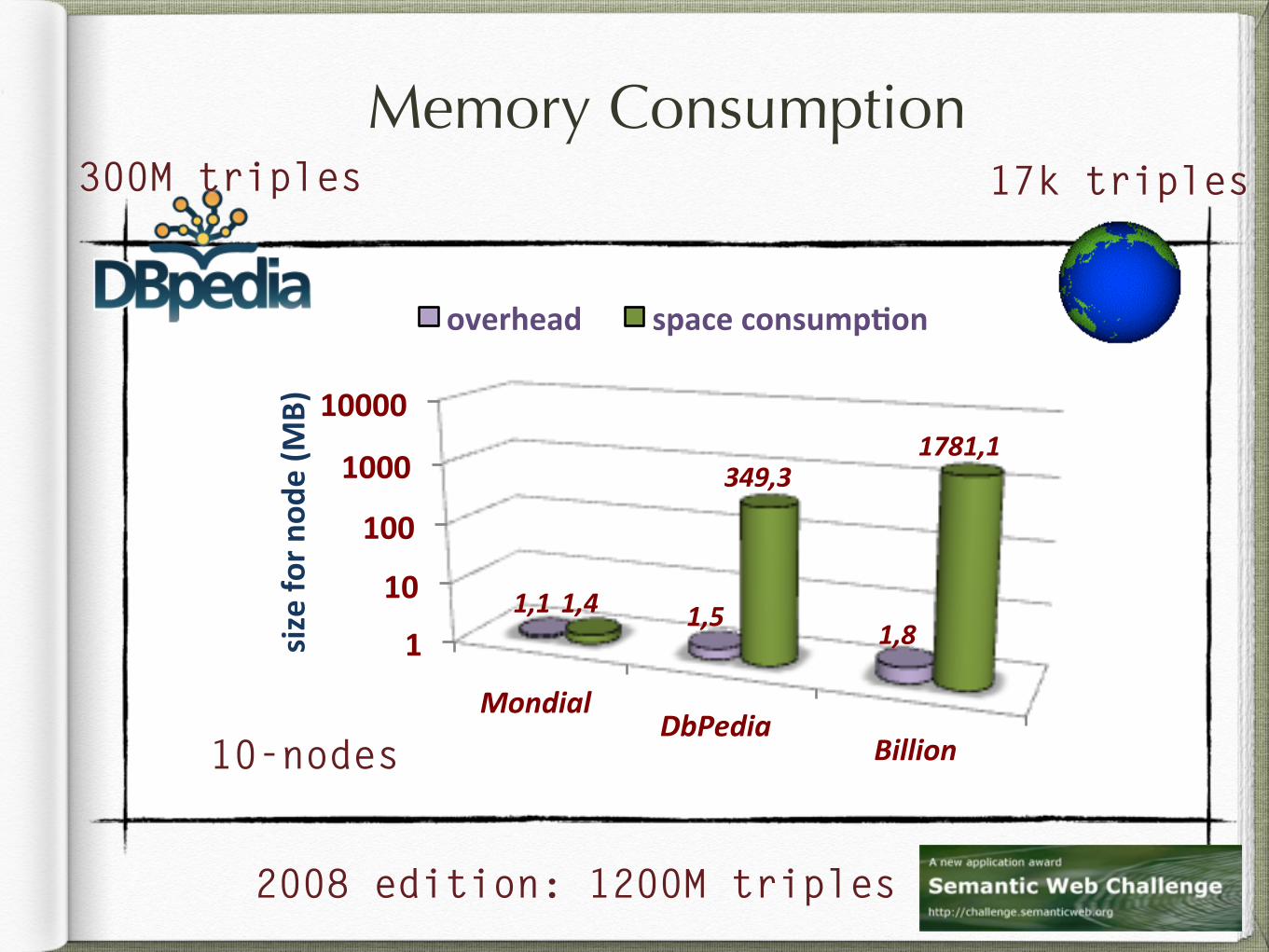
Memory Consumption
1"
10"
100"
1000"
10000"
Mondial(DbPedia(
Billion(
1,1( 1,5( 1,8(1,4(
349,3(1781,1(
size"fo
r"nod
e"(M
B)"
overhead" space"consump8on"
300M triples
2008 edition: 1200M triples
17k triples
10-nodes
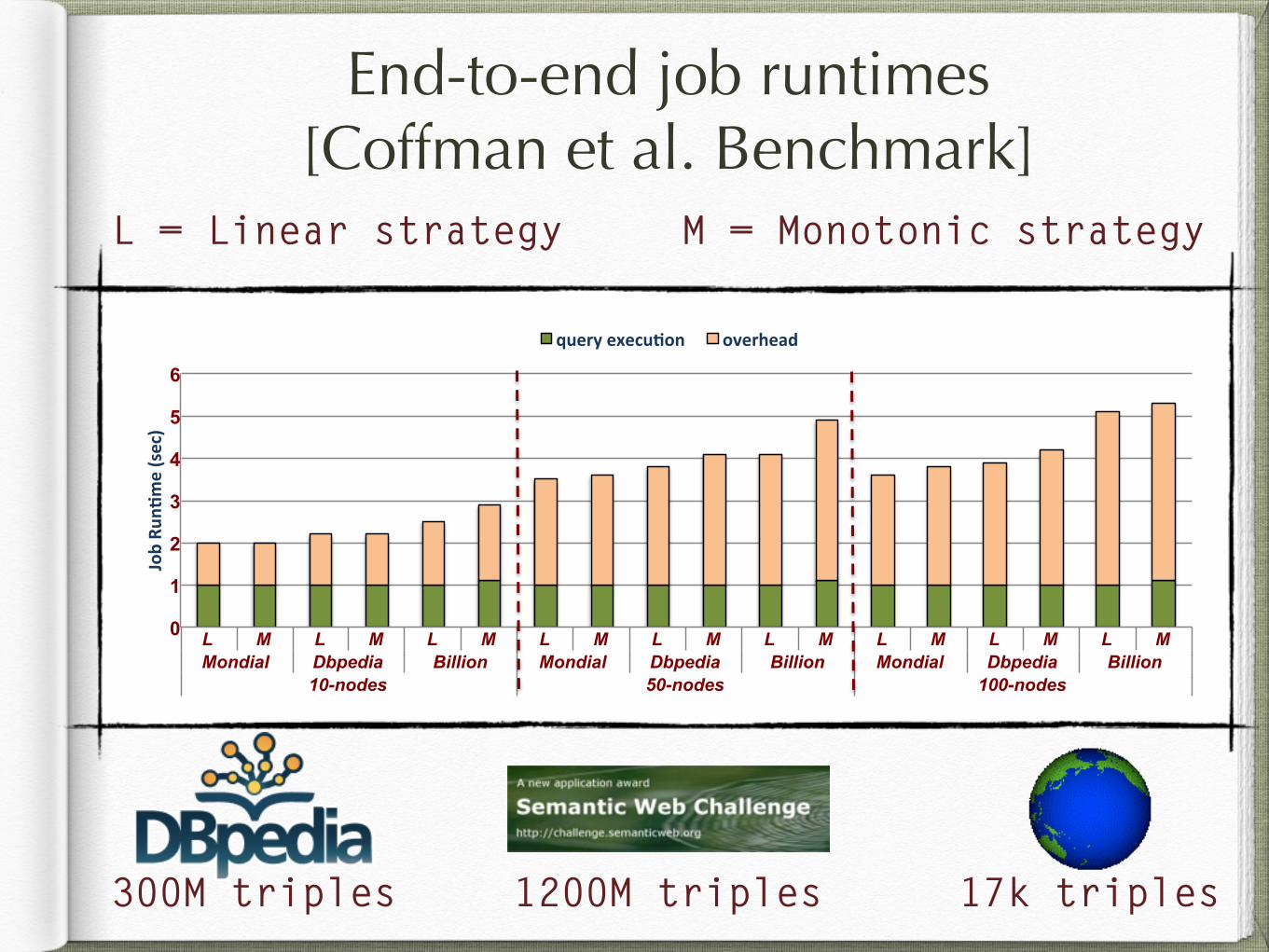
End-to-end job runtimes [Coffman et al. Benchmark]
300M triples 17k triples1200M triples
L = Linear strategy M = Monotonic strategy
0
1
2
3
4
5
6
L M L M L M L M L M L M L M L M L M Mondial Dbpedia Billion Mondial Dbpedia Billion Mondial Dbpedia Billion
10-nodes 50-nodes 100-nodes
Job$Ru
n(me$(sec)$
query$execu(on$ overhead$

Questions?